


Where have I been?
First things first, SPECIAL SHOUTOUT to sam lehman, rodeo, haus, yb, smac, ronan, and ibuyrugs for all of the comments, edits, feedback, and suggestions - you helped bring this to life and I really appreciate it.
Also, some of these arxiv links open up as browser-based PDFs, so just a warning incase you don’t want to deal with that.
As I’m writing this it’s been three months since my last post. What have I been up to since then?
I don’t know. I’ve been doing a lot of reading, trying to workout like five days a week, and generally making the most of my last semester attending college.
My mind gets a bit antsy anytime it’s been a month or two since I’ve written a long report, so this is my attempt at returning to baseline and getting back in the groove of things.
If you couldn’t tell by the title, this is a report that’s largely about distributed/decentralized training, accompanied by some info covering what’s been happening in the world of AI, and some commentary about how all of this fits together / why I believe it’s valuable.
This won’t be as technical as other reports been written on the subject, and I’m certain it won’t be entirely accurate either.
It will, however, be the most digestible report on the subject that you can find.
Pretty much everything here is explained in short detail and if it isn’t, there’s a hyperlink or two that provide a lengthier explanation.
This is a report about both decentralized and distributed training, which might sound interchangeable, but these are two very different things.
When an AI lab sets out to train an LLM, they’re tasked with managing a number of obligations that contribute to a finished and working LLM.
Researchers and developers have to juggle data collection/curation, pre-training/fine-tuning, post-training, reinforcement learning, and configuration/deployment.
This isn’t the entirety of what goes into building a foundation model, but I split it up in my own way that’s hopefully more easily understood. All you need to know is that LLMs take in massive amounts of data, teams decide on a specific architecture for the model, training and refining follows this, and finally some post-training and polishing comes in prior to a model’s release. Oh, and most LLMs use the transformer architecture.
This process can be generally referred to as centralized training.
Sam Lehman described distributed training as a “process of training via hardware that is not physically co-located” while decentralized training is “similar to distributed training in that the hardware being used for pre-training is not co-located, but it differs in that the hardware being used is heterogeneous and not trusted.”
The distinction is made because even though most of this report references distributed training, there’s a ton of value that can be found in creating and scaling it with crypto incentives, aka tokens. That’s probably what most people reading this will care about.
This concept of paying out tokens to network contributors in exchange for work is very well known and documented.
Even without looking at the more intricate examples seen throughout DePIN (decentralized physical infrastructure networks) you can find this in Bitcoin’s PoW model.
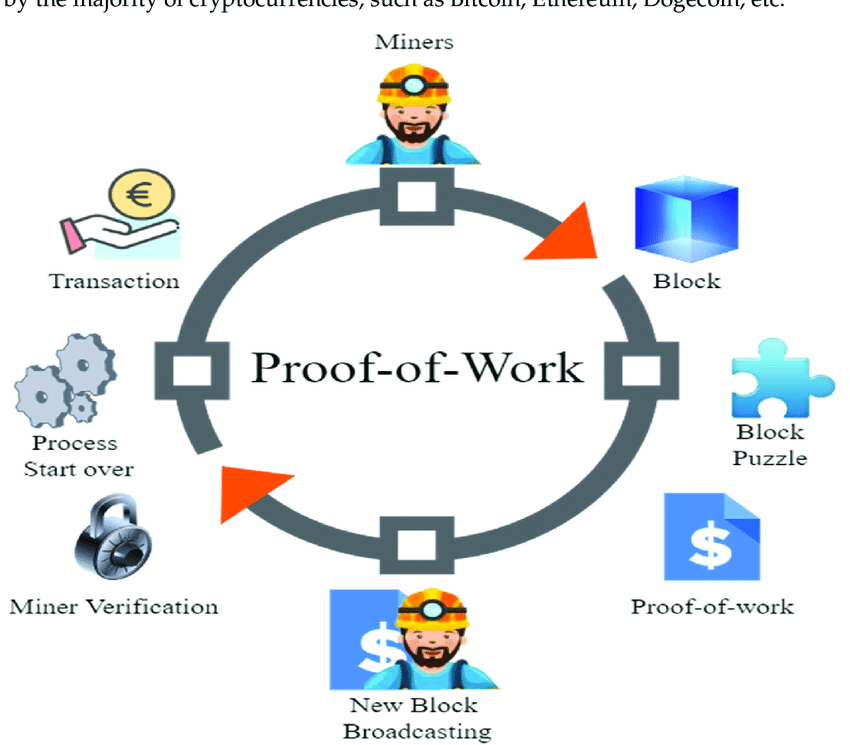
It’s difficult to make an argument for whether or not this model scales for most DePIN projects, but in my view, decentralized training has sufficiently high implications and potentially massive economic value, so the behavior can be incentivized for an extended period of time. Compared to many other projects that exist under the DePIN umbrella, decentralized training is easily the most significant.
Put more simply, I’m not worried over a hypothetical scenario where a crypto project miraculously achieves AGI and people don’t want to buy the token or contribute. I’ve seen people do far worse when the stakes are infinitely lower.
Just wanted to get that out of the way, and don’t worry - the differences will be elaborated on throughout the report, so it’s fine if you don’t have the full picture just yet.
I had a lot of fun writing this, so hopefully you have just as much fun reading. I do all of this for free, for some reason. No one paid me to do any of it.
If you enjoyed in any way, please consider subscribing to this blog as well (it’s still free) and/or sharing with a friend or reposting on X.
Have fun.
Defining decentralized ai and articulating the distributed training value proposition
Key takeaways of this section:
Distributed training = geographically separated hardware; Decentralized training = heterogeneous, untrusted hardware
Tokens can power participant rewards in a network, similar to Bitcoin or DePIN projects - distributed training could see massive demand and drive attention back to DePIN & DeAI
Decentralized training can unlock collaboration at a global scale & large-scale computational power at a fraction of centralized training costs
* Note: If you’re only reading this post to learn more about distributed/decentralized training, you can probably skip this section. *
You can’t write about something called decentralized training without writing about crypto, or more specifically, Decentralized AI (DeAI for short).
I’d originally placed this section towards the end of the report but decided it was best to move it to the forefront, before all of the boring stuff.
Want a TLDR?
Distributed training isn’t a complicated science project masquerading as a business opportunity, but an increasingly feasible set of steps towards uprooting how we train AI models.
Not only that, but distributed training offers an alternative to a) the hundreds of billions in big tech capital expenditures on data centers, b) the numerous pieces of pesky middleware designed for localized clusters, and c) ultimately presents an opportunity for the little guy (all of us) to take a crack at building ASI.
As much as the broader crypto community likes to say otherwise, the reality is that crypto needs AI far more than AI currently needs crypto. What do I mean by this?
Some could say it’s because crypto attracts a lower quality pool of developer talent than the traditional AI industry would, resulting in less ambitious and generally more lackluster ideas and products.
Others might say it’s because all tokens that aren’t Bitcoin or Monero are vaporware, so DeAI is no different. You hear this one a lot. It’s most commonly used when memecoin valuations are discussed, but sometimes it extends over into discussions of stickier sectors like DeFi or DePIN and the apps that live in these subsets of crypto.
It isn’t a secret that until recently, there hasn’t been much innovation from the DeAI sector and the countless companies that have raised venture funding on the promises of decentralizing AI through some type of novel, crypto-enabled enhancement(s).
This market map from Galaxy was already crowded in Q1 2024, struggling to incorporate every protocol. If another were made today, you couldn’t even fit 70% of them, let alone squeeze all of it in a way that’s visually appealing:
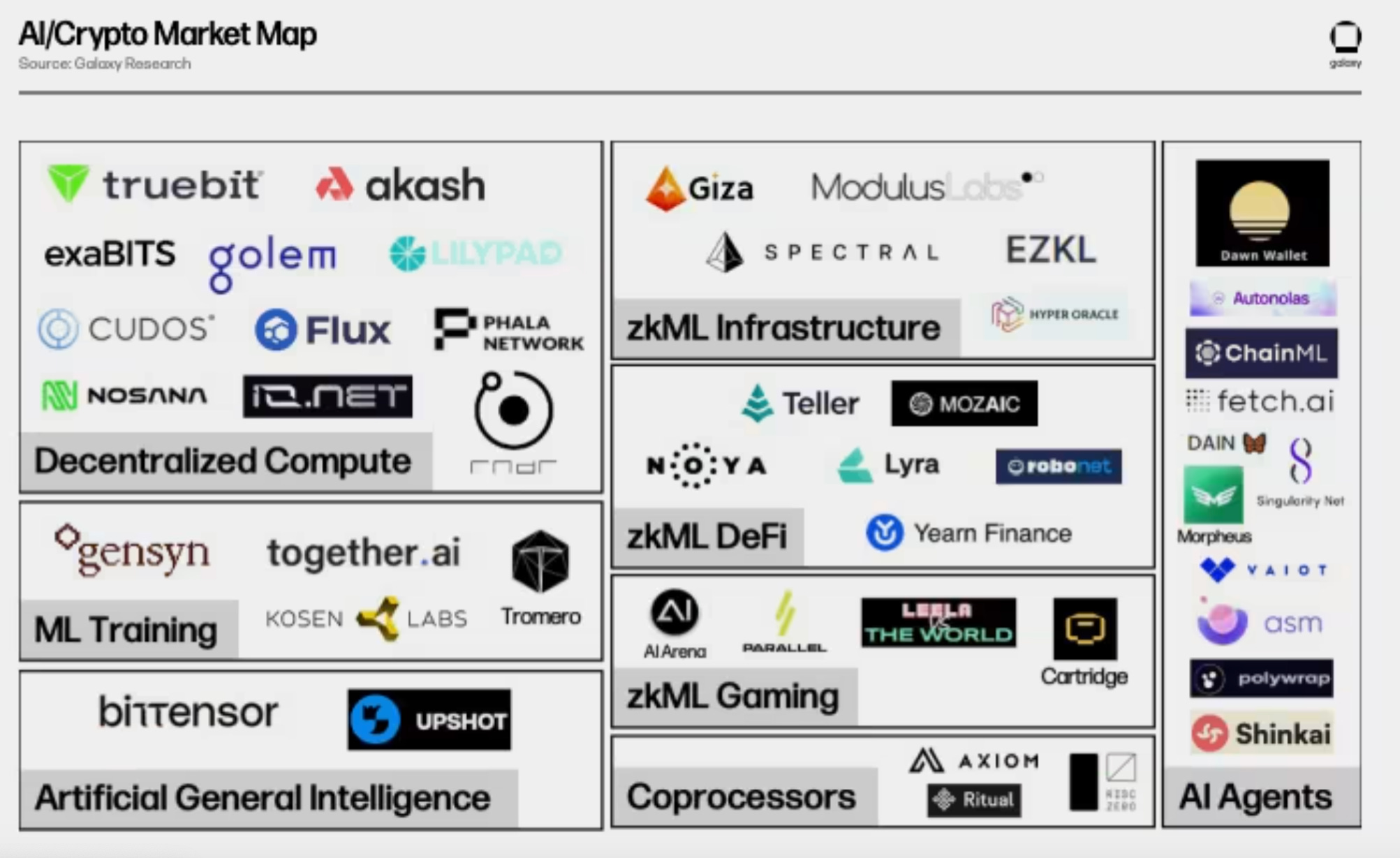
Most of what we’ve seen out of these teams can be viewed as a type of preparation for the future - one where AI interacts with blockchains, a world where we’ll suddenly need all of this AI-adjacent, crypto-enabled tech.
But what about the right now?
When I say there hasn’t been much innovation, I’m mostly saying there hasn’t been anything released that’s made an impact on DeAI adoption or the non-crypto AI industry. This is fine, and the intention isn’t to dunk on these projects as it’s likely a handful eventually gain adoption.
What I mean is that as a sector, DeAI is kind of twiddling its thumbs and waiting instead of acting.
These protocols are banking on the fact that AI gets incorporated into every aspect of technology and business - not a bad bet btw, just look at one of a16z’s hundreds of enterprise AI blog posts - but struggle to articulate why they’ve raised money and/or (mostly and) why they’re relevant to the DeAI industry today.
It’s my belief that DeAI has yet to experience any semblance of “takeoff” because a) the usage of blockchains by a large majority of the global population still hasn’t occurred, b) some of the problems being solved in DeAI aren’t entirely necessary at this point in time, and c) a lot of the proposed ideas just aren’t possible.
More than anything, I believe DeAI isn’t catching a ton of attention from outside our bubble because it’s difficult enough to get people interested in anything else involving crypto outside of maybe memecoins and stablecoins.
This isn’t a knock on the industry, just an observation. And it’s pretty obvious. Even something as universally respected (trusted?) like Circle is struggling to sustain the weight of a suggestion it might IPO at a $5 billion valuation.
But in my opinion, the third point (that proposed ideas aren’t possible) has done the most damage to DeAI in its short lifespan.
This is just one example that should be fairly clear to most DeAI researchers or general skeptics, but if you’re attempting to create fully on-chain, fully autonomous agents that interact without human intermediaries, there really isn’t even a centralized corollary to benchmark your progress against.
In fact, there isn’t even a fully autonomous agent that can interact persistently without human intermediaries outside of the context of blockchains. It’s like trying to build a house on Mars before we’ve even landed any humans there.
Fully autonomous agents have yet to be released or even excessively teased from major AI labs, but we saw coins like ai16z and virtuals reach peak valuations of over $2.6 billion and $4.6 billion, respectively.
There were a number of agentic frameworks being pushed by these projects as well, but very little came out of them (imo). This isn’t me trying to be overly negative - as it was a lot of fun trading these coins for a while - but none of this really contributed anything to the non-crypto AI industry.
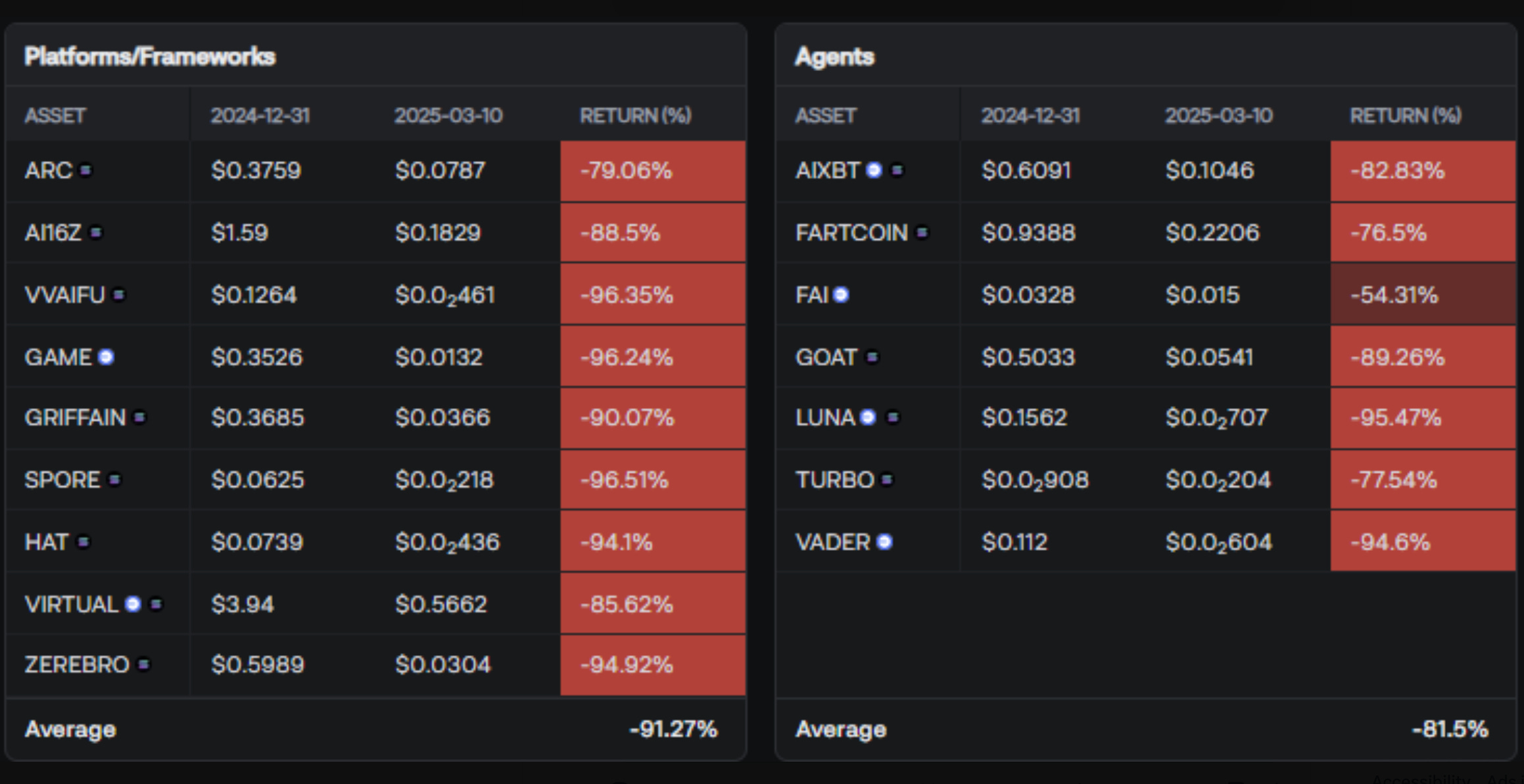
The frameworks proposed by these web3 teams haven’t gone on to gain adoption from Anthropic or OpenAI, or even the broader open source community.
Even worse than not gaining traction is a potentially ugly truth that all of these antics only reaffirmed web2/TradFi/big tech’s collective belief that crypto still remains a fundamentally unserious space.
Maybe the frameworks don’t suck, and the marketing is just poor because these projects launched tokens - which can stand out as a negative to those outside the industry - but it’s hard to believe something supposedly so innovative wouldn’t be adopted solely because the founding teams decided to launch a token.
“Every agent I know, know I hate agents.” - Ye, the artist formerly known as Kanye West
From some basic digging and general interacting online, things like MCP (model context protocol) have seen an infinitely larger adoption rate than these frameworks, with some even claiming MCP has already won. Why is that? Well, it works, it’s (mostly) free, and people enjoy software that they can incorporate into their day-to-day lives, with apps they already use.

What do people get out of agent frameworks? More often than not, literally only the ability to “build” or deploy more agents, with this description already being a stretch in 99% of web3’s cases. Most people don’t want to buy our coins, so what value do you imagine they’d get from deploying agents that have nothing to do with workflows and everything to do with launching new tokens?
* Note: No shade to @diego_defai it’s just that yours was the easiest thread to find and popped up first. *
But what even is decentralized AI, and why are we being told we need it?
Lucas Tcheyan wrote in 2024: “The driving force behind ongoing experimentation and eventual adoption at the intersection of crypto and AI is the same that drives much of crypto’s most promising use cases - access to a permissionless and trustless coordination layer that better facilitates the transfer of value.”
Sam Lehman wrote a section in his report about crypto-enabled incentives, pointing out “crypto has shown that decentralized networks can achieve massive scale through providing thoughtfully designed incentives.” I mean, just look at Bitcoin.
Even if we can be honest with each other and admit the Bitcoin model is at the very least bit weird on paper, this does not discount the fact that net-new incentives (receiving BTC in exchange for work) changed the world and propelled us into a timeline where the United States government is actively exploring a strategic fund for BTC.
This mindset also been the guiding belief or modus operandi (if I’m allowed to get fancy with it) behind decentralized physical infrastructure (or DePIN for short) which 0xsmac and myself wrote about back in September 2024.
We have a few different definitions of what Decentralized AI is, but nothing is definitive. This is understandable considering it’s a nascent sector within an already somewhat nascent industry, but we should at least be able to identify the 5 W’s of DeAI - the who, what, when, where, and why.
Who is going to use this? What problems are better solved with the integration of crypto? When will this be used? Where would a product like this capture the most attention or largest user base? Why does this need venture funding (jk) and/or why does it need to exist?
In my opinion, Vincent Weisser of Prime Intellect lays out the challenges & problem areas succinctly for almost anyone to understand:

Vincent also provides a list of potential use cases for DeAI and what can/should be built. I won’t drone on about all of them, but it spans almost every layer of the stack and sums up the sector in a way that hasn’t really been done.
Distributed (or P2P) compute networks, decentralized/federated training methods, decentralized inference, on-chain agents, data provenance, on-chain verifiability, and a handful of others.
DeAI is more than just the compute that trains models, scraped data that gets purchased by large labs, or services that verify model outputs are correct. It’s an entire ecosystem of product innovations built to disrupt an industry that’s almost perfectly suited for decentralization.
It seems most in the industry are attracted to the challenge of decentralizing AI because they love decentralization, but more than that, it’s a pressing issue for a lot of humans.
If AGI or ASI ends up in the hands of a single entity, that isn’t really fair.
It would suck.
None of us would be able to fully take advantage of these superintelligent, digital aliens, because corporations would own the model weights, code, bespoke training methodologies, and technology used to create these models.
Assuming someone like OpenAI or Deepseek gets to it first, it actually becomes a major national security threat, too, if it hasn’t already.
If distributed training works at scale (which we’re already seeing) and integrates with other DeAI tech like zero-knowledge proofs or other privacy-preserving mechanisms, maybe we’ll have a good chance at defending against a monopoly on superintelligence.
In a world where distributed training researchers continue to understand an entirely new set of scaling laws and subsequently scale up distributed training operations, it’s unlikely we ever turn back and optimize for more localized training methods of the past.

If you’re a large lab or big tech corporation like Google / Meta / Amazon, it’s in your best interest to research distributed training and make it a priority. Dylan Patel spoke about this in 2024, but if you still want further confirmation this is actively being explored by big tech companies and major players, consider the DiLoCo paper was written by DeepMind (acquired by Google for $650 million in 2014). It’s also worth mentioning Dylan Patel wrote about multi-datacenter training here.
Rodeo pointed something out to me that feels quite obvious in hindsight - the smartest minds and the largest tech companies in the world are actively pursuing how to create a massive network of nodes through decentralized principles.
Doesn’t that sound familiar to you?

If you had to argue one thing that Bitcoin did in its almost two decades of existence, it’s proven that when a decentralized network of individuals with aligned interests are given the proper incentives, legitimate change can happen.
First we decentralized money, and now we can leverage this experiment to decentralize intelligence. The odds are stacked against everyone working in this field, but you could have argued the same in Bitcoin’s early days.
A comparison could be made between the earlier days of Bitcoin adoption and the current DeAI community, though there are a number of differences, most notably a broader, more provable market demand and the presence of venture funding which doesn’t really signify we’re “early” as it once was with Bitcoin.
And the benefits of distributed / multi-datacenter training aren’t exclusive to big labs, either, but actually the complete opposite.
A technical innovation like distributed training makes it possible for groups of individuals from anywhere on the globe to pool their resources and train competitive models. Minimizing communication requirements is just one part of the equation.
What about lowering the hurdles for at-home training with consumer hardware?
What about using a token as an initial wedge for bootstrapping innovation without significant capital outlays?
This will be covered later on in some short analysis of Exo Labs’ work, but here’s a recent tweet from Alex Cheema describing this exact concept in relation to Apple’s M3 Ultras and the new Llama models from Meta.

Distributed training doesn’t just unlock more efficient training, but an entire global community of researchers, hobbyists, and enthusiasts who were previously locked out of working on frontier models. What happens when a few dozen individuals with hundreds of even thousands of GPUs are given the golden ticket to competing with centralized frontier labs?
Overview of some AI basics, compute, and scaling laws
Key takeaways of this section:
Modern AI training relies on GPUs for data parallelism, making them an industry bottleneck and simultaneously a very hot commodity
Increasing compute and data typically leads to higher performance but scaling compute cluster sizes introduces its own set of challenges
DeepSeek’s progress has shown creativity in model creation (not just more GPUs) and prove you can achieve state-of-the-art results at lower cost with a bit of outside-the-box thinking
Centralized training is very expensive and difficult; distributed training is too, but has more positive externalities if executed on correctly
It’s best to start with a refresher on what’s been happening across the AI industry and use this as a jumping point for the more complex topics that follow.
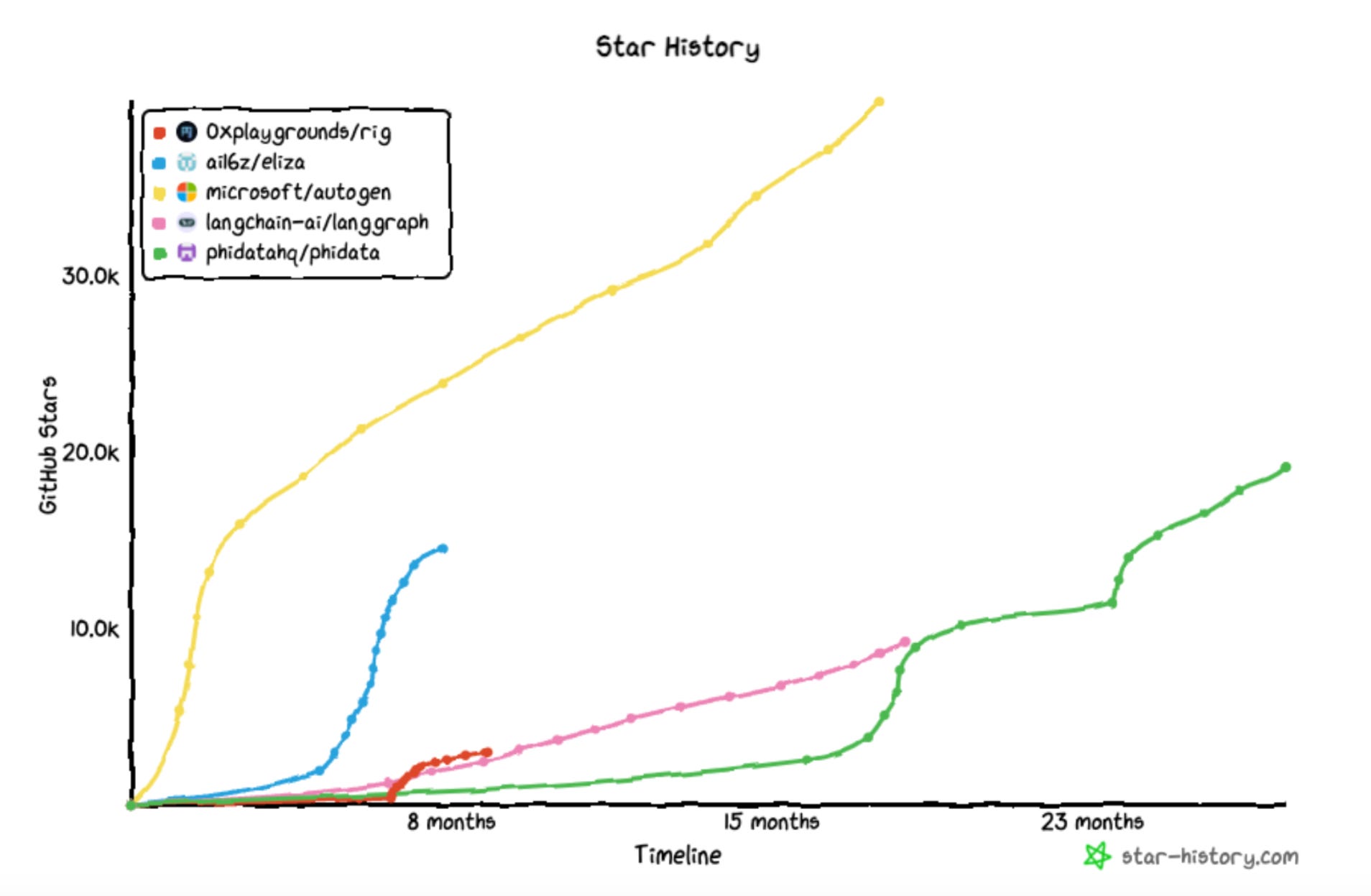
Most reading this are hopefully somewhat plugged into what’s been happening with recent LLMs (Sonnet 3.7, GPT 4.5, Grok 3), the Magnificent 7’s AI expenditures, and the increasingly capable models being released almost every week.
There are some good reports that describe the work that goes into training an LLM, so I’ll reference a few of these throughout:
Training LLMs is a very capital-intensive venture, and you can see below just how much big tech companies have spent on infrastructure. The details will be covered shortly, but most (if not all) of this goes towards things like GPUs, data center buildout, maintenance, and other hardware requirements that contribute to the final product.
By the way, this list is limited to just three big tech corporations:
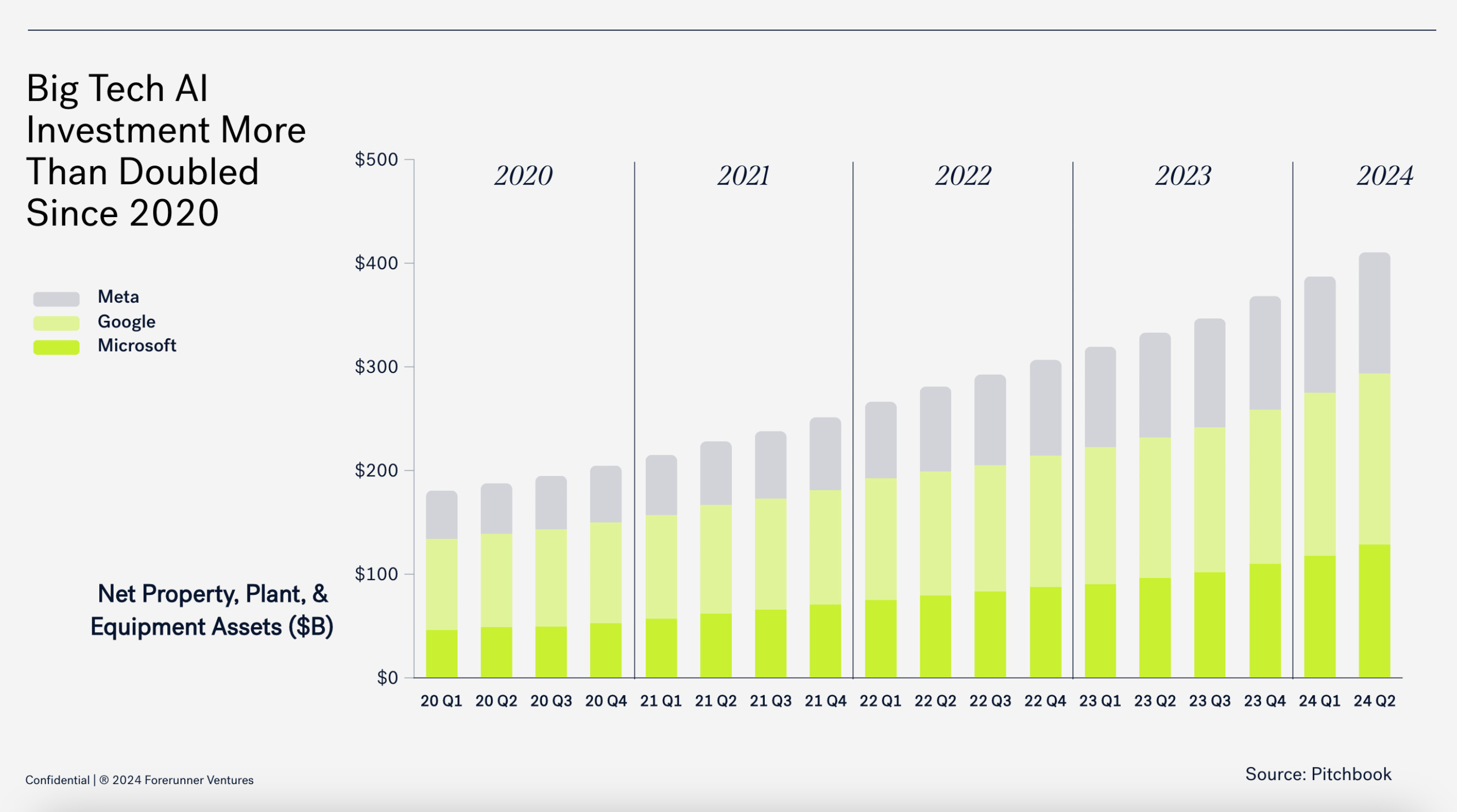
You might wonder why GPUs are used instead of CPUs, or even what the difference between the two is.
Citrini highlighted that the distinction between GPUs and CPUs comes from which type of parallelism is used for computation. GPUs are optimized for something called data parallelism while CPUs are better off at task parallelism.
The machine learning industry realized that GPUs - initially designed for rendering graphics - are also quite good at performing calculations rapidly. I won’t get into the weeds on the speed of things, but they’re very fast.
Data parallelism is a process where “the same operation is performed on many data elements in parallel” while task parallelism is when “different operations are performed on the same or different data.”
For training an LLM, data parallelism just makes more sense due to the highly repetitive nature of parsing large datasets and performing simple operations on it, which is why GPUs became and remain such a hot commodity.
Something like task parallelism didn’t make sense because AI datasets are highly variable - you wouldn’t want to over index on a single piece of data within a massive set because you’d never finish training a model or it would take so long that it’d be costly and/or highly inefficient.
People like to say the word compute, and they’re referring to GPUs when they do this. If someone asks “how much compute does Meta have” or “how much is Elon spending on compute next year” they’re talking about GPUs.
The Carnegie Endowment wrote a nice summary on what compute means, how it functions, and why it’s mattered so much. It’s helpful if you’re still a little lost and want a more general overview before reading the rest of this.
Compute has been the main focus of AI labs because of something known as a scaling law, particularly the power-law relationship or correlation between more performant models and the larger numbers of GPUs and data that go towards training them.
To be precise, the specific law being referenced here is referred to as the pre-training scaling law. The graphic below goes a bit beyond that, but I found it helpful for framing where we’re at in model development today and where we’re headed:
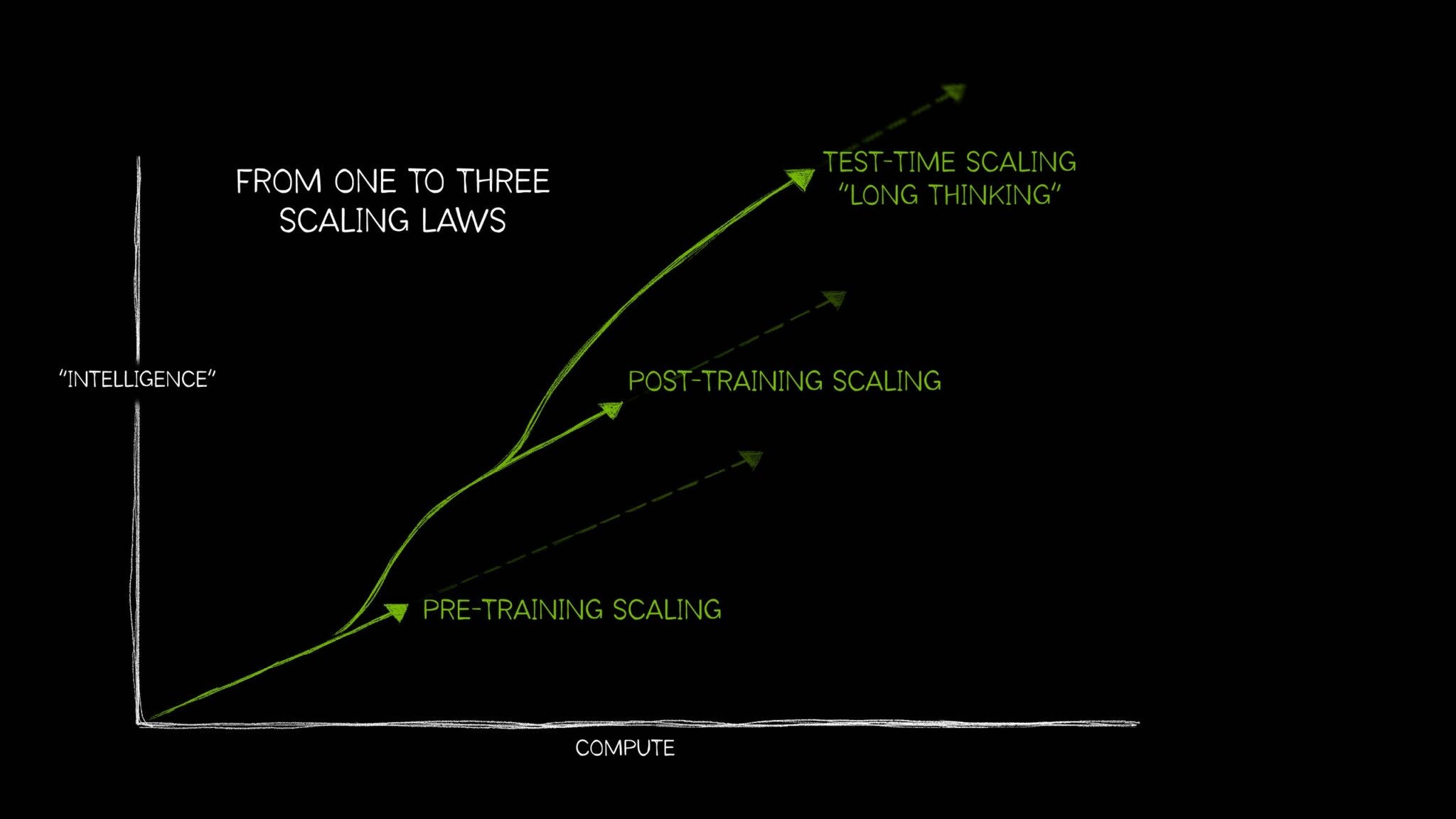
Brief aside, but OpenAI’s 2020 paper on scaling laws is said to be one of the more foundational analyses on the relationship between compute, data, and model parameter count.
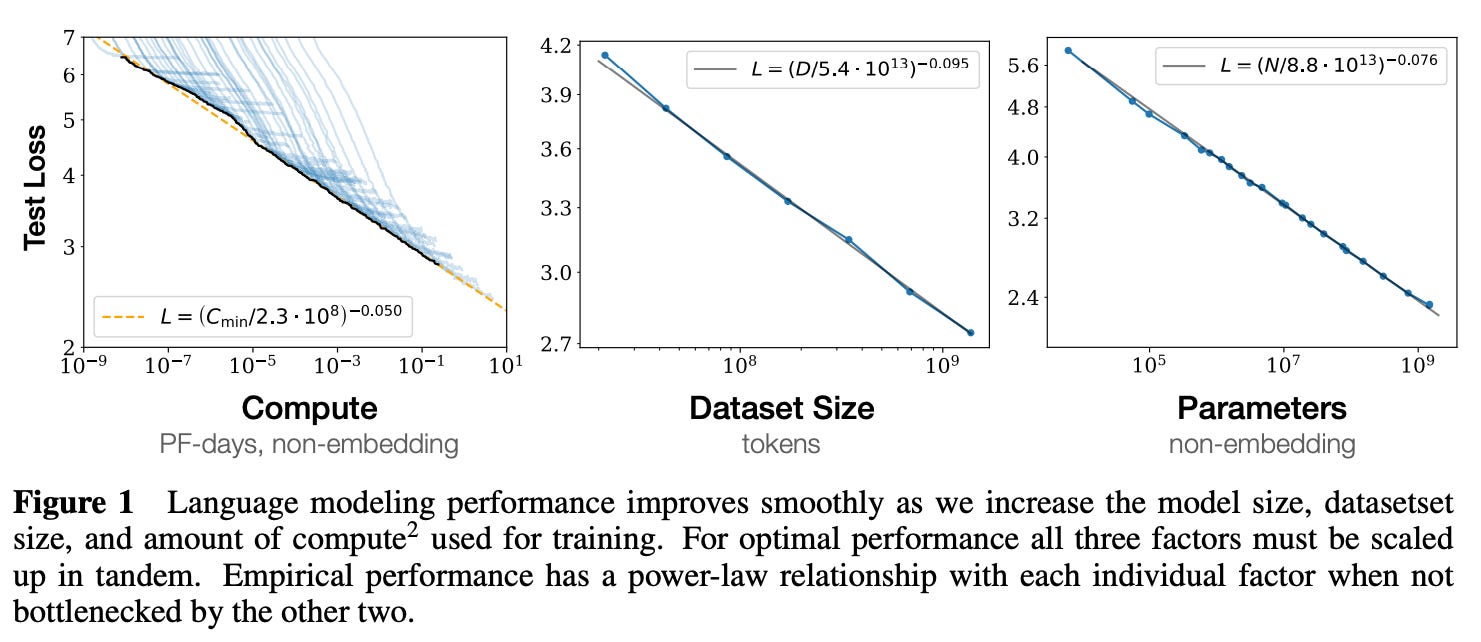
Scaling laws have held up.
It’s difficult to find accurate GPU counts for newer models, but here’s a rough estimate of scaling laws in action for some of OpenAI’s models over the years:
GPT-1: 117m params & about 8 Nvidia V100s
GPT-2: 1.5b params & tens to a few hundred Nvidia V100s
GPT-3: 175b params & 1k-2k+ Nvidia V100s
GPT-4: Trillions of params & 8k-30k Nvidia A100s/H100s
You might remember Sam Altman calling for trillions of dollars to build larger and larger data centers, or the proposed $500 billion Stargate bill, or even Zuck’s 2GW+ data center ambitions - these are initiatives that came about due to a (perceived) need for extremely large, power-hungry data centers.
It was actually announced on March 31st that OpenAI completed a new funding round, receiving a $40 billion capital injection (with 75% of this coming from Masayoshi Son and SoftBank).
Since scaling laws remained in the picture for so long, everyone that wanted to build a good model was forced to amass larger and larger amounts of compute, as well as even more performant types of compute (aka better GPUs). Most of these come from Nvidia, though it’s worth exploring the potential of Apple Silicon.
Everyone became trapped into a massive race to buy up these GPUs and train larger models, but things have gotten complicated. Models get smarter when you train them with more GPUs, but it becomes increasingly difficult to train them because of disturbances, errors, cooling requirements, interconnects, and a bunch of other issues.
Later sections will cover more of the details, but most of these training algorithms are already quite capable and bottlenecks exist almost entirely in the implementation and scaling phase. It’s already possible to achieve a fully distributed training run, the only challenge remains in taking this from 0.5 → 1.
Distributed training is actually a step towards getting around a lot of this, which would be huge.
If we can eventually train state-of-the-art models across a number of distinct data centers, from a variety of continents and countries, all without these burdens, we could get even better models with less hassle and far more performant training runs.
That’s why it matters so much - it can be just as good as centralized training if proven scalable, but better in almost every other way if successful. And if you think about it, these centralized corporations and labs have to bend their operations towards the trend of distributed training, not the other way around.
If you already own a large data center it’s difficult for you to work backwards and redesign the infrastructure to accomodate for distributed training methods. But if you’re a smaller, scrappier team of researchers that set out from day one to pioneer work on distributed training, you’re much better positioned to benefit from the technology.
Epoch AI wrote a report on scaling back in 2024, describing not only traditional (compute-centric) scaling laws, but some of the other potential bottlenecks that might plague labs in pre-training runs to come (which will be covered).
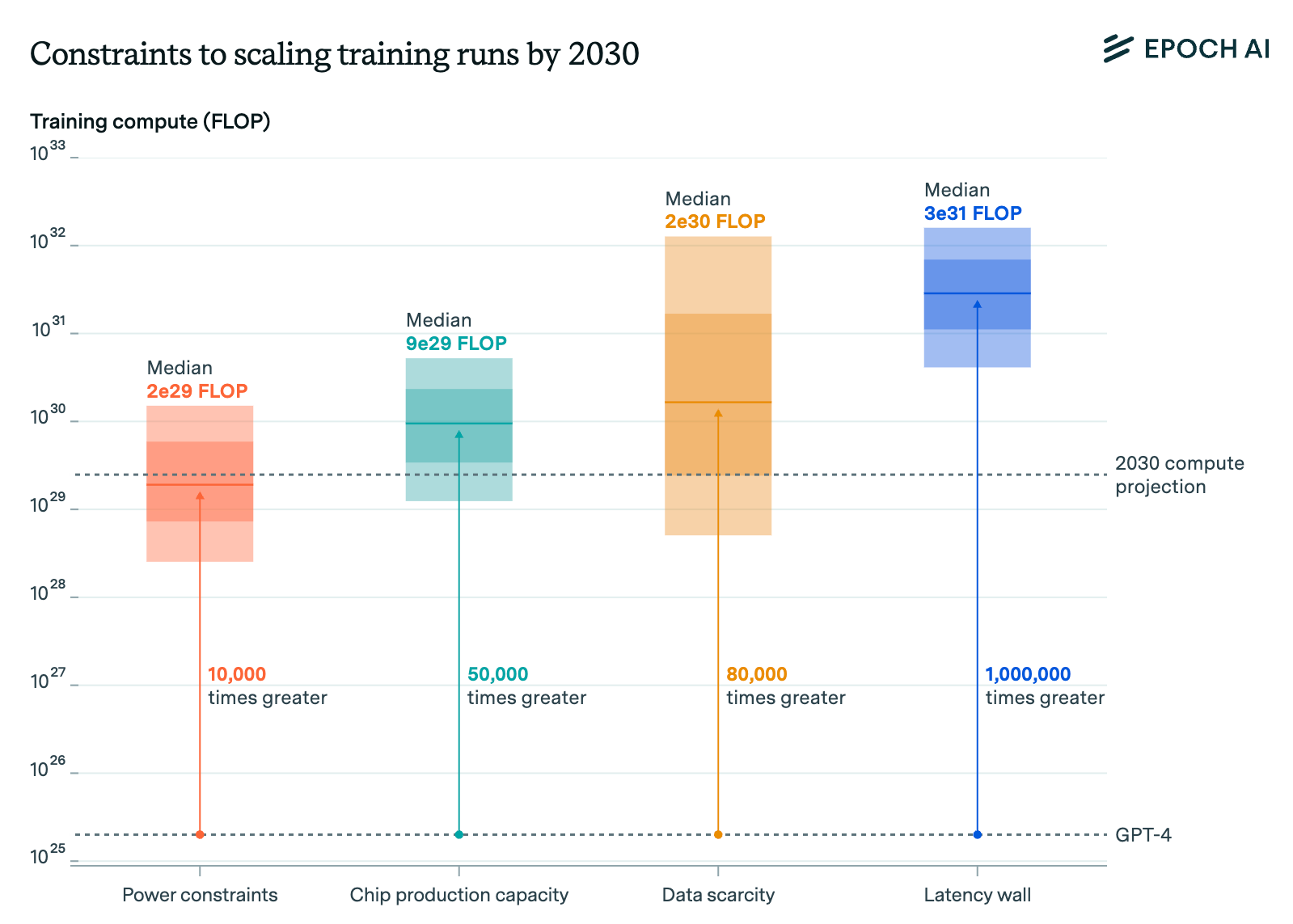
The most important thing to highlight here is that the number of GPUs or the size of a data center isn’t the only bottleneck. Beyond just acquiring these GPUs - which is difficult enough - labs need to stress over power constraints, the latency wall, chip manufacturing capacity, and even geopolitical tensions.
And this is just the laundry list of concerns for centralized training runs - distributed training has its own set of issues, mainly getting around the communication bottleneck and scaling training runs.
Many of the other constraints are relevant to distributed training because of the obvious reality that distributed training is inherently sensitive to factors like geography, location, and - not sure if this is a word - locality.
Distributed training isn’t just the study of how to train models residing in multiple locations, but an all-encompassing field that takes the most difficult problems in centralized training and pairs them with even more challenging, unproven theories from distributed training research.
That’s one of the reasons this topic has stood out to me so much - the stakes are incredibly high and this is one of those areas where so many disciplines overlap, it’s almost impossible to get a full picture of what’s occurring.
If you think about significant leaps in technology across time, distributed training fits the bill and deserves a chance at success even if there aren’t currently any tokens for me to shill in this.
This idea of scaling laws “ending” or experiencing diminishing returns has been greatly contested, and it isn’t really my place to make an opinion because for the most part, no one is entirely sure.
Beyond pre-training scaling laws, there’s much to be said about post-training and test-time compute (TTC) laws. Post-training is concerned with topics like fine-tuning, reinforcement learning, and some other more advanced mechanisms that are covered in the next section.
TTC, on the other hand, is a lot more complex.
But am I the one to write about these? This report has been nothing short of exhausting to write, as it’s felt like I’m constantly taking one step forward and three steps back, struggling to make sense of new information or learning I wrote an entire section and was sadly mistaken about all of it. I’ve struggled immensely, but for what cause?
I don’t even make any money from writing these.
Keeping it short, post-training laws are currently in vogue thanks to the ludicrous rate of improvement measured in OpenAI’s “o” models relative to GPT-4 and the non-reasoning models released in the years before:
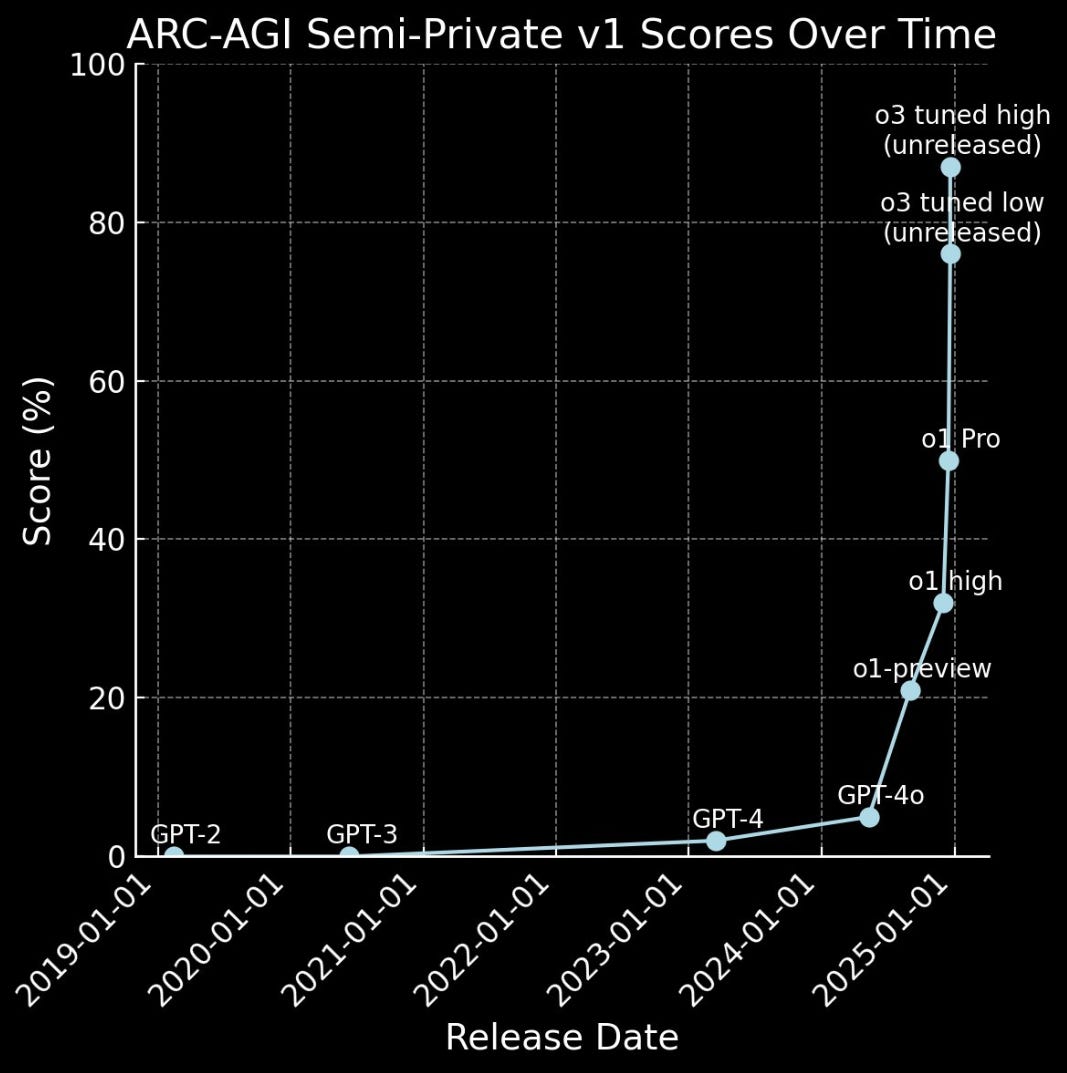
Post-training research is red hot and on fire right now because it’s working (duh) and it’s a more cost-effective way of scaling model performance, assuming you’re a large lab that already has the GPUs. Put simply, post-training is majorly additive and has the potential to redefine how large labs are pushing towards AGI.
I mentioned how reinforcement learning in combination with reasoning models has certainly challenged the industry’s perception of scaling laws, but it hasn’t necessarily defeated any arguments against these scaling laws holding.
If anything the advancements being made in post-training only stand to benefit the entire lifecycle of creating a model, as this new data can eventually feed into better models. There might come a time where 99% of the innovation in model creation and curation comes from post-training optimizations, if this isn’t already being pursued.
But that’s enough for now. I’ll take a few steps back and run through the pre-training process and some of the more critical functions aside from GPUs.
Compute is obviously crucial to a training run, but like I hinted at earlier, there’s an entirely separate set of storage, memory, energy, and networking requirements that are just as important as GPUs.
Energy: It should be obvious that large data centers require large amounts of energy, but what about cooling infrastructure? What about actually sourcing the necessary energy requirements and ensuring consistent power output?
Storage: LLMs are made up of large datasets and parameters, so you can imagine the storage requirements for this are high.
Memory: Pre-training runs can take a while and proper memory requirements are necessary to maintain memory across GPUs and nodes.
Networking: Citrini’s interconnects report gives you more info than you’ll ever need to know about networking, but data centers need high-speed and low-latency interconnects to actually facilitate a run.
All of these models are pre-trained with interconnected, large, geographically constrained clusters consuming large amounts of energy, comprised of expensive and highly capable technologies.
Tens of billions of dollars have gone towards data center buildout, fundraising rounds for labs, and countless other expenditures as companies have thrown their hat into the race towards superintelligence.
But things got complicated earlier this year.
DeepSeek-R1 and its accompanying paper were released January 22nd, 2025 and remained somewhat under the radar for maybe a week before everyone caught on. Unless you’ve been on a digital hiatus or have a poor short term memory, R1 was a massive shot from left field for almost everyone in the industry.
It’s been said that R1 was trained with 2,048 Nvidia H800 GPUs which comes out to roughly $61 million worth of GPUs assuming a cost of $30,000/GPU - give or take $5,000 depending on where and when DeepSeek acquired these. However, there’s also a difference in reporting based on numerous internet sources for the above and a report from semianalysis which estimates 10,000 H800s and 10,000 H100s.
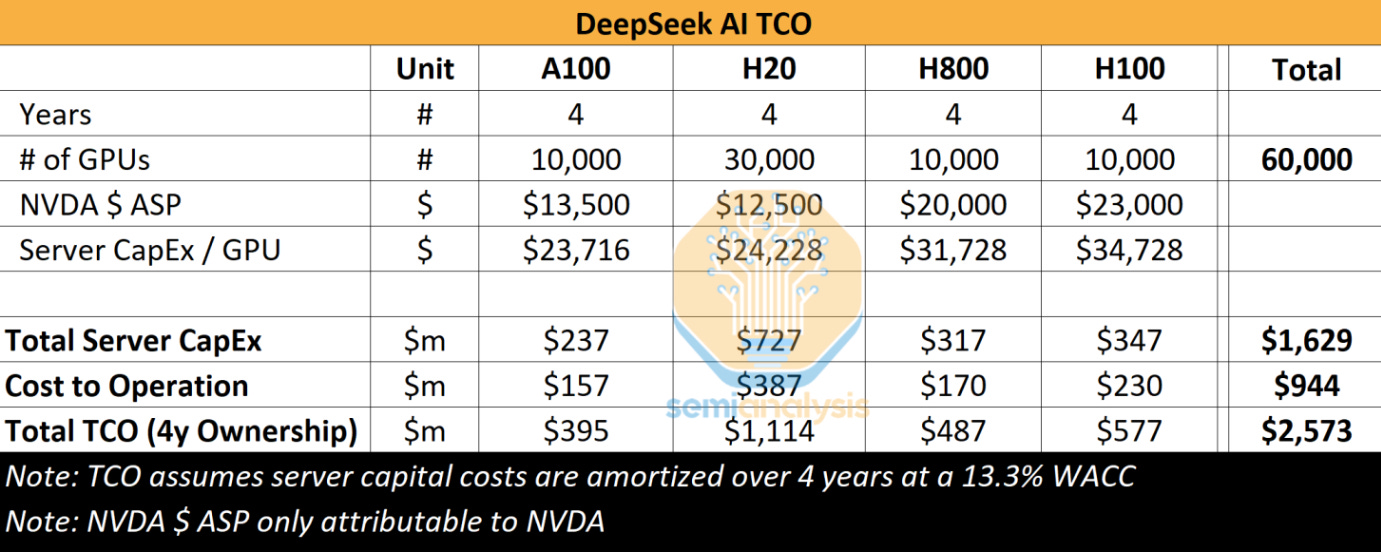
I think regardless of the actual number of GPUs used to train the model, what DeepSeek has been able to accomplish is the true story here. Not its supposed cutting of costs or ability to dodge GPU import regulations, but creativity in model construction and reinforcement learning advancements.
The news about DeepSeek’s GPU shenanigans came as a shock to many, considering every major lab had prioritized amassing more and more compute in the past 2-3 years and almost zero indication this wasn’t the “correct” way to build highly capable models. DeepSeek’s process and strategies will be covered with more detail in the following section.
Here are some of the other foundational models and their respective costs, not accounting for training times or other hang-ups of the pre-training process:
OpenAI’s GPT 4o: 25,000 Nvidia A100 @ $8-20k/GPU
xAI’s Grok 2: 20,000 Nvidia H100 @ $25-30k/GPU
Google’s Gemini 2.0: 100,000 Trillium chips @ $2.7/hour/chip
Meta’s Llama 3.1: 16,000 Nvidia H100 GPUs
Anthropic’s Claude 3.5 Sonnet: unspecified but estimated tens of thousands
OpenAI’s GPT o1: unspecified but supposedly very many GPUs
* Note: I wanted to include citations here but there were too many different resources used, and as I’m editing this, it would take too much energy to go back and find these. Sam Lehman also pointed out to me that employee salary + compensation can factor into these costs, so that’s worth considering if you want to explore absolute cost of training runs. *
Even though we don’t have costs or GPU counts for some of the older models (and for many of the newer models like Claude 3.7 and GPT 4.5, understandably) we can assume these have stuck to the scaling laws of AI and amassed larger and larger amounts of GPUs or more performant GPUs.
This is a good spot to mention that not all pre-training runs are created equally.
The Llama-3 technical report is a good resource for understanding just how many variables go into this, and the table below shows how easy it can be for something simple to trip up a run or create an issue leading to idle training time.
As you can see from the list, it could be an issue related to GPUs, networking, dependency, maintenance, or even something unknown - you can’t count anything out. Just owning the GPUs doesn’t give you the golden ticket to a flawless pre-training run.
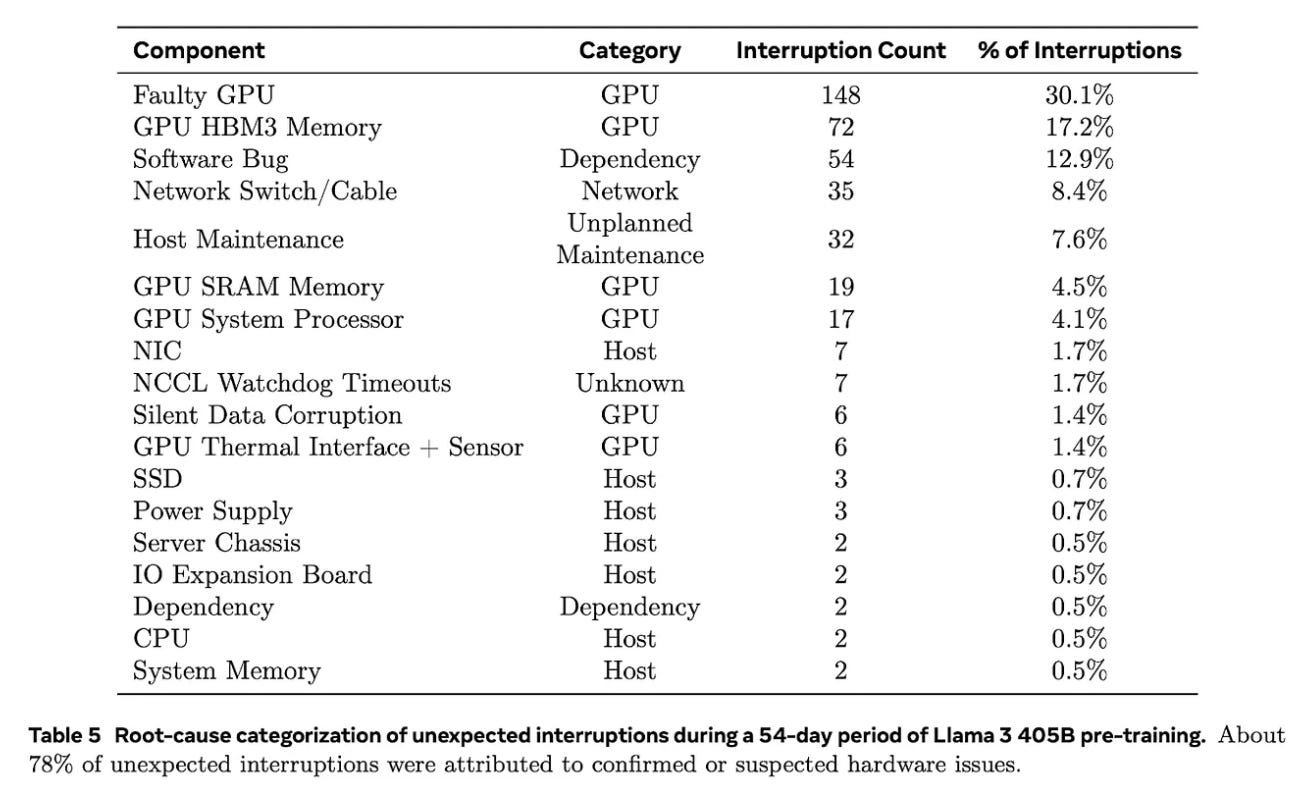
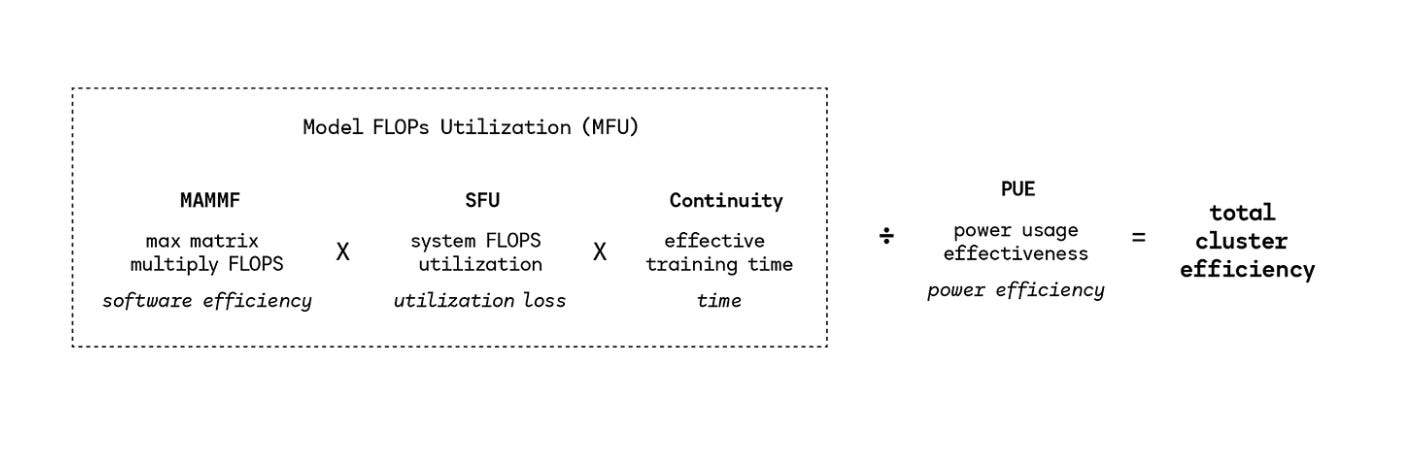
I could take time here to examine some of the proposed equations for measuring training efficiency, like MFUs, MAMMFs, SFUs, and Continuity, but Ronan already did a good job on that and it might drag this report on even longer than it should already be.
TLDR?
Many different variables go into determining the efficiency of a training run, involving both software and hardware, though most of this depends on FLOPs and measuring this in a really lengthy way.
Anyways.
This next section will expand on our knowledge of LLMs and dissect the training process, particularly the post-training phase and some of the innovations occurring here.
Exploring reasoning models and reinforcement learning
Key takeaways of this section:
Reasoning models have quickly taken over as the dominant structure for newly released state-of-the-art models (across almost every lab)
Reinforcement learning is a very technical problem space that’s quickly becoming one of the major vectors for innovation in model optimization
DeepSeek did a bunch of impressive shit and deserves a lot of credit for pushing the boundaries of model design at a time when many labs were seemingly plateauing
We can pivot here to the more recent popularity and deployment of reasoning models, which have proven themselves to be extremely competent and even led to Sam Altman claiming these models are OpenAI’s focus for the foreseeable future (after GPT-4.5):

Reasoning models are a unique type of language model trained with reinforcement learning to perform more complex reasoning, models that can think before producing an output. These reasoning models were developed to better resemble humans and the ways we solve problems in our everyday lives, producing a chain of thought detailing their internal ideas prior to answering a user’s query. Here’s what it looks like:
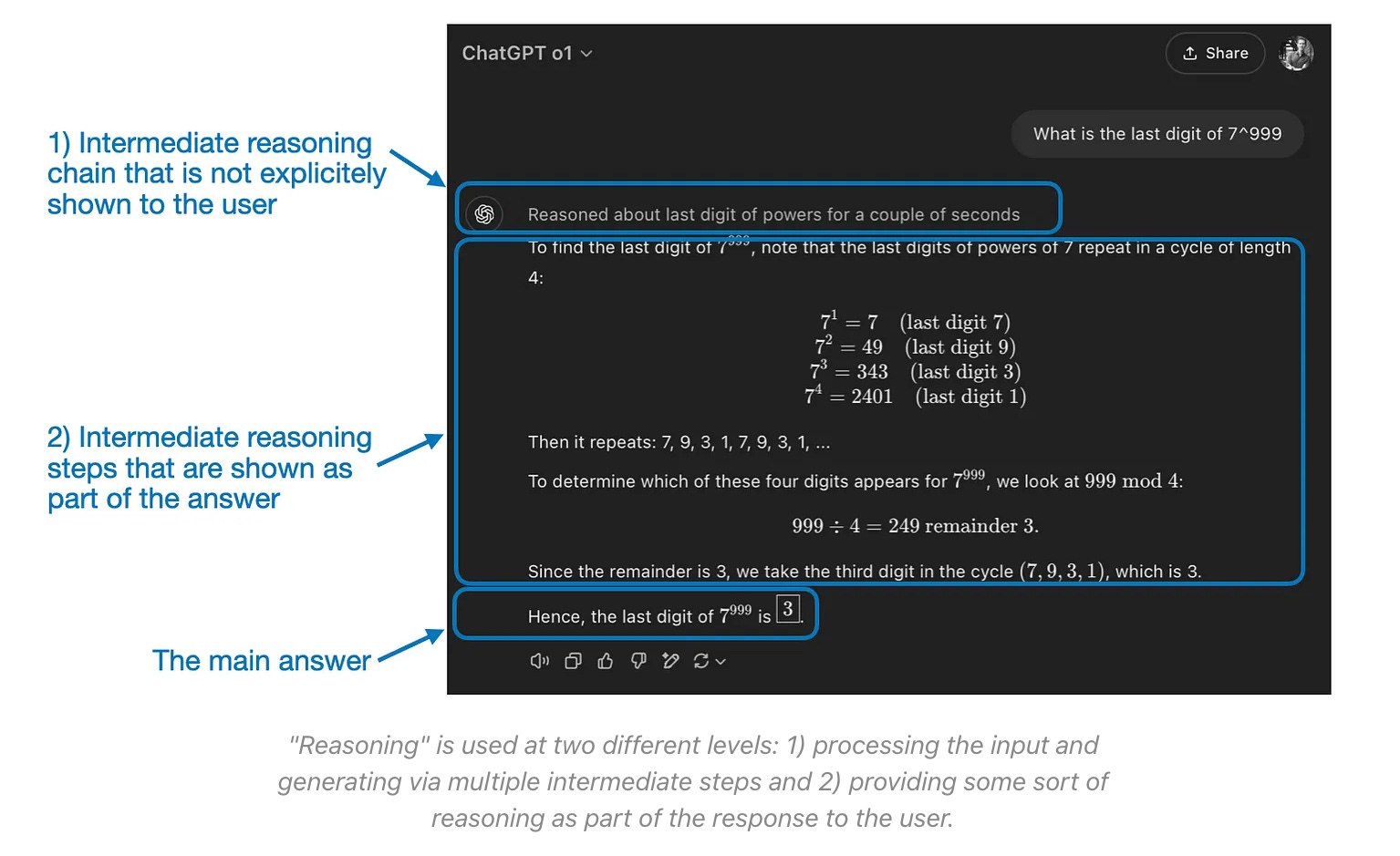
Sebastian Raschka wrote in this report that there are two main methods of improving reasoning models: increasing training compute or increasing inference compute, which can also be referred to as inference-time scaling or test-time scaling, with the distinction coming in when the scaling is done. In this case, inference-time is referring to a period occurring after the training has already been done.
Ronan’s report highlights an under appreciated aspect of scaling under the reasoning paradigm, referencing a tweet from samsja over at Prime Intellect:

It’s my fault for not explaining the whole forward/backward pass thing sooner, but now is as good a time as ever to use it in support of the distributed training thesis.
A forward pass occurs when a neural network processes data inputs, doing layer-by-layer and running the model forward from input → output. Backward passes are calculations measuring how far off a model’s output was from the supposed correct answer, with this info getting routed backwards through a model to inform parameters what weights need adjusted.
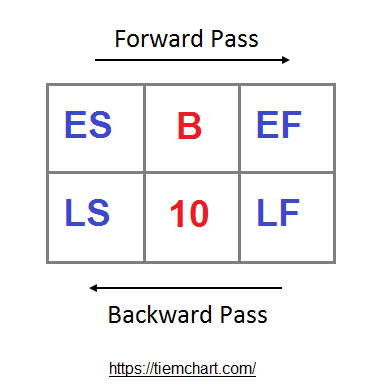
The fun part with reasoning models and improvements in the post-training phase stem from the reality that these processes are inherently less intensive in communication requirements during the pre-training phrase. Samsja points out the RL & normal training’s order of magnitude difference in forward pass count.
Which kind of brings us to DeepSeek.
DeepSeek-R1 came as a shock because the 2,048 H800s came across as small by comparison, made possible through a few different techniques used simultaneously:
Mixture-of-Experts (MoE)
Multi-Head Latent Attention (MHLA)
Supervised Fine-Tuning (SFT) & Reinforcement Learning (RL)
* Note: You might remember hearing about MoE from my November 2023 report covering Bittensor. *
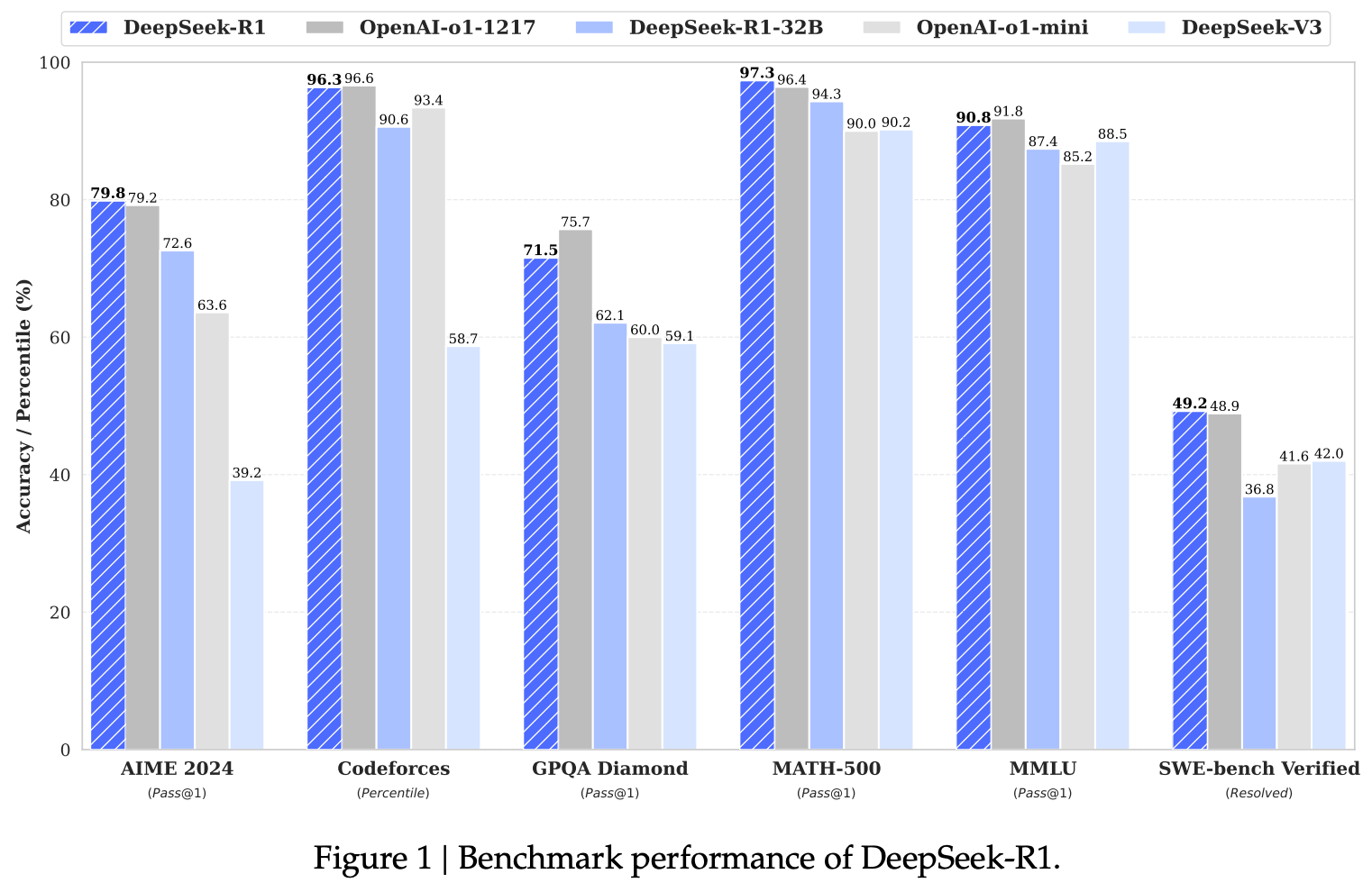
Putting all of these techniques together resulted in a model that beat out many of the most highly capable, commercially available LLMs, which sparked speculation and debate (back in January) that DeepSeek-R1 was the best state-of-the-art model currently live:
Haus explained to me another, more under appreciated engineering feat pulled off by DeepSeek. Here’s a short explanation straight from its source (Stratechery):
“Here’s the thing: a huge number of the innovations I explained above are about overcoming the lack of memory bandwidth implied in using H800s instead of H100s. Moreover, if you actually did the math on the previous question, you would realize that DeepSeek actually had an excess of computing; that’s because DeepSeek actually programmed 20 of the 132 processing units on each H800 specifically to manage cross-chip communications. This is actually impossible to do in CUDA. DeepSeek engineers had to drop down to PTX, a low-level instruction set for Nvidia GPUs that is basically like assembly language. This is an insane level of optimization that only makes sense if you are using H800s.”
I did a little more digging and realized this gets very into the weeds, but it’s super impressive how DeepSeek was able to innovate not only on the software side (MoE, SFT, and RL stuff) but extremely challenging hardware problems like the PTX conversion from CUDA, a parallel computing platform created by Nvidia.
It’s my understanding that most model development and GPU-related work makes use of CUDA, if only because it’s the standard to use with Nvidia GPUs (which are the most widely demanded by far).
If there’s one thing to learn from DeepSeek, it’s that hard problems are meant to be solved and the entire industry is still discovering newer and more crucial hard problems to solve.
This entire moment is important because for the first time in a while, the AI community woke up and learned that maybe just throwing more compute at new models isn’t the most optimal way of scaling model performance.
What if more creativity throughout the model training process was the key to unlocking a more likely path to AGI? What if the secret sauce wasn’t so obvious?
This logic will eventually be extended out to the idea of training models in a distributed manner, specifically challenging the belief that GPUs must be located in a singular geographic location in order to train a SOTA model, along with some ideas concerning whether or not the amount of GPUs being used is even necessary, or if there’s a way to combine these scaling methods and achieve something truly exceptional.
There are a few other ways to further improve reasoning capabilities, including inference-time compute scaling, pure reinforcement learning, RL + SFT, and Pure SFT - I won’t get too into the weeds on any of this. Like I said in the previous section, we have a few of these scaling laws that are all equally seeing their fair share of advancement, and the industry is still learning how to make sense of them in tandem.
Sebastian provides a list of reasoning papers, showing just how creative researchers are getting. Just to showcase how strange all of it gets, here are some snippets if you want to look deeper down the rabbit hole:
Terms like underthinking and methods like the Thought Switching Penalty are used to help reasoning models “think better”
Researchers explore the associative memory of LLMs and its effects on information absorption
Backtracking methods get used to help reasoning models explore alternative solutions
It’s important to cover reinforcement learning, a subset of machine learning / AI concerning the relationship between an agent and its environment.
Reinforcement learning is a process where rewards and penalties are assigned to an agent for its behavior, gradually steering the agent towards the correct answer(s).
Even though the definition refers to






