

This article is machine translated
Show original
Last Friday night, updated their deep research capabilities, and after receiving testing qualifications, they were deeply used for a whole day yesterday.
It was found that 's deep research is very impressive in terms of content richness, accuracy, and logical rigor.
Below is a detailed introduction 👇


Unlike other similar recent products, the UMA deep research model is an Agent model trained using their own end-to-end autonomous reinforcement learning technology.
Moreover, they will open-source the basic pre-trained model and the subsequent reinforcement learning model, which is truly exciting.
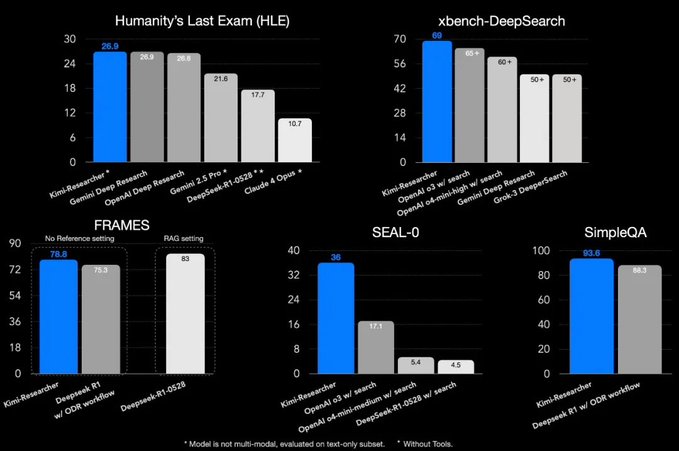
In the (Humanity's Last Exam) and Sequoia's Agent tests, the Kimi deep research model has achieved good results.
I have been thinking about this kind of product or model that produces in-depth research reports recently. What are its core evaluation indicators?
I feel that people are mainly concerned about the quality of its source, the coverage of information and the rigor of logic. Kimi's in-depth research happens to guarantee these indicators in the optimization of two aspects.
He has the ability to independently identify information. He will plan dozens of search keywords and read hundreds of web pages by himself, and then find the most credible content to quote.
Basically, each generated research report will exceed 10,000 words. I have a test with 22,000 words.
Of course, LLM cannot completely avoid illusions. They also let users make their own judgments through embedded text, highlighted jumps, and original text tracing.
Analysis of the Reasons for Labubu's Popularity
He will first conduct a simple search to inquire about the details that need to be analyzed.
He will first broadly search all the content, then draw a general conclusion, and then begin to search each part separately.
He first searched for fan economy, then the reasons for its popularity, and then discovered that the first wave of popularity might be related to overseas dissemination, and then began searching.
I looked at the word count, which is nearly 19,000 words. From the table of contents, I could see that the entire report's logical chain is very complete, covering multiple aspects such as design, product evolution, operational promotion strategies, and fan economy.
First, he described the design concept of the , then the iteration and evolution of the product. After explaining the design, he discussed the operational strategy based on the . At this point, with the background information, readers can better understand why the is operated in this way.
After discussing marketing and promotion, as a product with certain financial attributes, it naturally extends to fan economy and the secondary market.
The analysis and content retrieval here are very strong, from 's own operations and launch to fans' spontaneous UGC content production, especially the most important doll clothing.
Then, after all the information is discussed, he finally begins to summarize the reasons for its popularity, including all the content mentioned above: , designers, market marketing, and secondary market speculation collectively contributed to 's popularity.

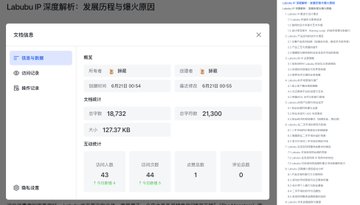


From the above results, we can see that Kimi's in-depth research is not just a pile of information.
Instead, he puts the information where it should be through a logical chain, which shows that he can independently form an analysis framework.
Test 2: Retrieval and analysis of Xiaomi's press conference on June 26
Next, let's take a look at its search accuracy and its data processing capabilities.
Since I am a Mi Boy and Xiaomi will hold what may be their most important press conference this year on June 26, I have basically seen a lot of information, so I use this topic for retrieval, which can reduce the pressure of verifying the information myself.
Prompt words: Sort and search the content of Xiaomi's press conference on June 26, 2025, label different products, and give a credibility percentage for each rumor, compare the estimated specifications of the upcoming products with competing products, output radar charts or heat tables, combine the sales volume of the same period in previous years, the macro consumption index, and the rumors of channel stocking, and give three sales ranges of conservative/benchmark/aggressive, and explain the key assumptions, list the 10 A-share or Hong Kong-listed supply chain companies that are most likely to benefit (with business-related reasons and stock price performance in the past 30 days), and classify them according to high-medium-low sensitivity.
My question is already quite outrageous. Kimi's in-depth research not only needs to find corresponding information, but also needs to find information about competitors and information about similar products in previous years. It also needs to make reasonable predictions based on these data and information, and finally, it needs to retrieve relevant supply chain listed companies.
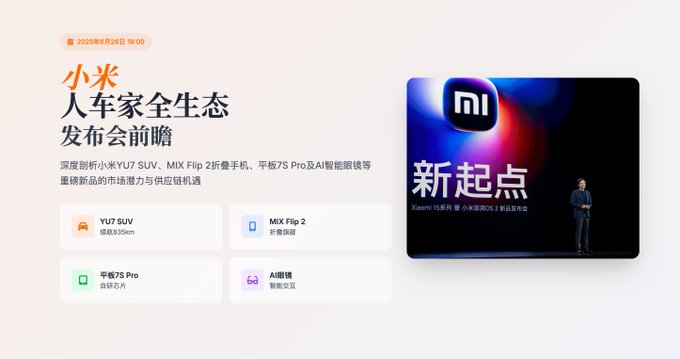
The total word count of the report still reached nearly 17,000 words.
At the same time, through the catalog, we can see that he has basically output the corresponding content for the requirements we mentioned.
There is no problem of laziness on complex issues and long contexts that is common in similar products in the industry.
He first listed the main product information to be released, and also made distinctions according to credibility.
A good design point is that when clicking on the reference source, the cited data will be directly highlighted, which is convenient for users to check, which is very considerate.
Here, the cockpit system Xiaomi YU 7 uses Snapdragon 8 Gen3. This data is very critical, because there are very few cars that currently do not use mobile phone chips on the car machine, and this information was only released in the past few days. It can be seen that Kimi's accuracy and timeliness in content retrieval are very high.
Next, in addition to giving the reasons for each forecast level, the sales forecast also gives the key assumptions of the corresponding sales to help readers make judgments.
Kimi's in-depth research on the comprehensiveness, accuracy and data analysis of complex data retrieval is really amazing.


Injecting aesthetics to make professional reports "live"
No matter how powerful the function is, if it cannot be easily understood and used, its value will be greatly reduced. Kimi's deliverables are unified in "easy to use" and "good-looking".
In addition to generating documents, Kimi will also generate a visual webpage of the research report at the same time.
Kimi's visual webpage is not a toy with completely disproportionate information and reports like other similar products. Their content is very detailed, and basically all the webpages in the outline are available.
And there is a corresponding outline on the left to facilitate switching to specific content.
And the entire webpage layout is clear, which conforms to the aesthetic habits of contemporary users. Mind maps, structured lists and other forms make complex information clear at a glance.
Each chart here can be freely dragged and enlarged and reduced, which solves the problem that the chart content generated by the chart component is not suitable for preview.
They are not a set of templates to eat all the way. Each webpage AI will generate the theme color and design style that conforms to the corresponding brand according to the information it retrieves, such as the orange here for Xiaomi.
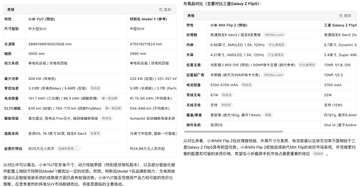
When embedding materials, we don’t just randomly find pictures. Basically, they are related to the current content. When I was researching Plaud ai, a hardware product, he even put a hardware demonstration video in the header! For example, the highlight color of Xiaomi’s webpage comparison with competitors and the yellow and green background colors and charts on the right card show the advantages and disadvantages, which is very intuitive and greatly improves the efficiency of information acquisition.



You can browse the three web pages I generated here:
kimi.com/preview/d1co3df37oq0o...…
kimi.com/preview/d1coajrlmiues...…
kimi.com/preview/d1coefmmu6sal...…
The test and introduction are over here.
Although they are all in-depth studies, Kimi's reinforcement learning-based model still shows very different result tendencies from the common models through prompt words and tool usage, allowing us to see the power of complex retrieval tasks that do not rely on large prompt projects.
Looking forward to Kimi's upcoming open source pre-training and RL weights, which should benefit many products with similar functions.
From Twitter
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share





