

Early checkpoint of our biggest LFM2 model to date 🎉 It shows good scaling and extremely fast inference vs. gpt-oss-20b and Qwen3-30B-A3B We'll release an LFM2.5 version with more pre-training and RL in a few months

Liquid AI
@liquidai
02-24
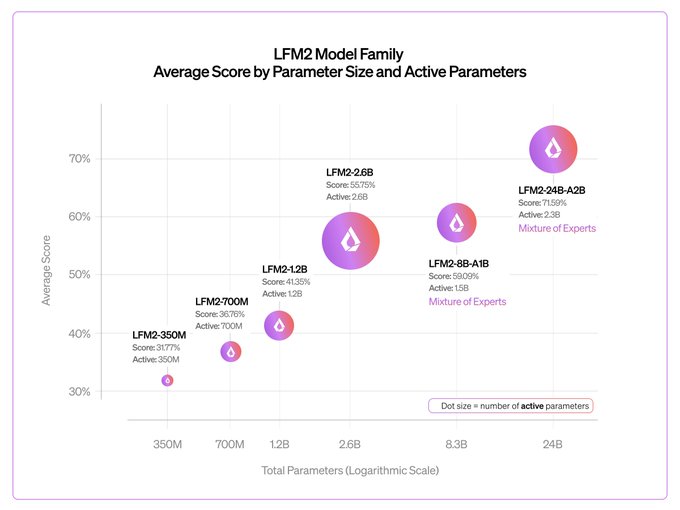
Today, we release our largest LFM2 model: LFM2-24B-A2B 🐘
> 24B total parameters
> 2.3B active per token
> Built on our hybrid, hardware-aware LFM2 architecture
It combines LFM2’s fast, memory-efficient design with a Mixture of Experts setup, so only 2.3B parameters activate
From Twitter
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share
Relevant content




