Google Research introduces TurboQuant compression algorithm to optimize LLM inference efficiency.

This article is machine translated
Show original
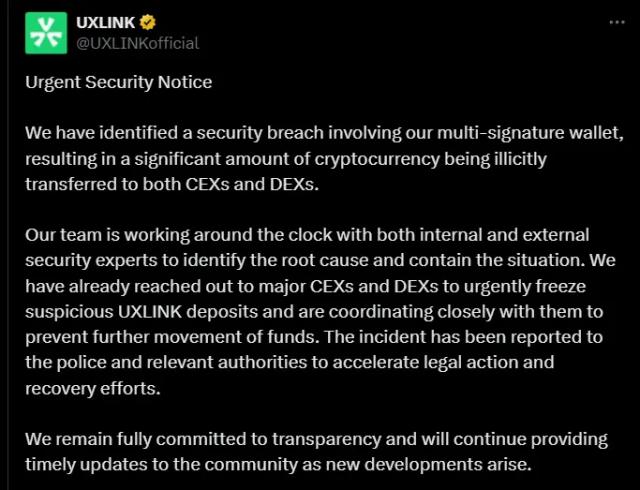
According to ME News, on March 26 (UTC+8), Google Research announced a new compression algorithm called TurboQuant. This algorithm aims to optimize the inference efficiency of Large Language Models (LLMs), reportedly reducing the memory footprint of LLM key-value caches by at least 6 times, increasing inference speed by up to 8 times, and achieving zero precision loss. The article describes the technology as "redefining AI efficiency." (Source: ME)

Source
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share
Relevant content