Authors: willcl-ark, l0rinc, hodlinator
Source: https://bitcoinmagazine.com/print/the-core-issue-outrunning-entropy-why-bitcoin-cant-stand-still
Initialize block download
To synchronize a brand new node with the latest state of the network, several different stages need to be involved:
- Peer discovery and blockchain selection: Nodes connect to a randomly selected group of peers, and then the chain with the most proof-of-work is determined.
- Block header download: Nodes retrieve block headers from these peer nodes, and then connect them to form a complete block header chain.
- Block download: A node simultaneously requests blocks belonging to this chain from multiple peer nodes.
- Block and transaction verification: Transactions in one block will only be verified after the transactions in the next block have been verified.
While block verification is inherently sequential—each block depends on the state generated by the previous block—many peripheral tasks can be processed in parallel. Block header synchronization, block downloading, and script verification can all run independently in different threads. An ideal initial block download process should utilize all subsystems as much as possible: a network thread downloads data, a verification thread verifies signatures, and a database thread writes the generated state.
Without continuous performance improvements, nodes with poor configurations may no longer be able to join the network in the future.
introduction
Bitcoin's "trustless, verifyable" culture requires that the ledger can be reconstructed from scratch by anyone. After processing all historical transactions, each user should receive the exact same result regarding the status of their funds as everyone else on the network.
This reproducibility is the soul of Bitcoin's trust-minimizing design, but it comes at a huge cost: 17 years after the birth of the Bitcoin blockchain, this ever-expanding database requires newcomers to the network to consume more resources than their predecessors to prepare for its use.
To start a new node from scratch, it must download, verify, and persist every block from the Genesis Block to the top of the current chain—this resource-intensive synchronization process is called "IBD (Initial Block Download)".
While consumer hardware continues to upgrade, keeping the initial block download process low-burden remains crucial for centralization: ensuring everyone can verify the Bitcoin blockchain, from low-power devices (like Raspberry Pi) to high-power servers.
Benchmarking
Performance optimization begins with understanding software components, data patterns, hardware, and network conditions, and how their interactions create performance bottlenecks. This requires extensive testing, most of which yields little to no results. Beyond the usual balance between speed, memory usage, and maintainability, Bitcoin Core developers must also select low-risk/high-reward changes. Effective but minor optimizations are often rejected because the risks outweigh the benefits.
We have an important suite of small benchmarks to ensure that existing functionality does not suffer from performance degradation. This is very useful for capturing regression effects (i.e., performance regressions in a single piece of code), but does not necessarily represent the overall performance of initial block downloads.
Contributors to the proposed optimizations provided reproducibility and metrics across different environments: operating system, compiler, storage type (SSD vs. HDD), network speed, database cache size, node configuration (pruning mode vs. archive mode), and index combinations. We wrote single-purpose benchmarks and used a compiled browser to verify which settings perform better in which specific scenarios (e.g., using hash sets/sorted sets/sorted vectors for cross-block overlapping transaction checks).
We also regularly run benchmark tests for initial block downloads. Test methods include: reindexing the blockchain state (chainstate) from the local block file (which may also require reindexing blocks); or performing a complete initial block download from an intranet peer or from a large peer-to-peer network (using an intranet peer avoids the impact of slower peer connections on timing).
The improvements shown in benchmark tests of initial block downloads are often smaller than those shown in micro-benchmarks because network bandwidth or hard drive read/write speeds are often the bottlenecks; at the global average network speed, downloading the entire blockchain alone takes about 16 hours.
To maximize reproducibility, we generally prefer a test approach that re-indexes the chain state, which shows memory and CPU usage before and after optimization, and verifies how these changes affect other functionalities.
Historical and ongoing optimizations
Early versions of Bitcoin Core were designed for much smaller blocks. The earliest prototype, written by Satoshi Nakamoto, merely laid the foundation, and without continuous innovation from Bitcoin Core developers, it would have long been unable to cope with the unprecedented scale of the network.
Initially, the block index stored every historical transaction and whether it had been spent. However, in 2012, developer Ultraprune (PR #1677) created a dedicated database to track unspent transaction outputs, thus establishing the concept of the "UTXO set." This database pre-caches the earliest state of all spendable pencils, providing a unified perspective for block verification. Combined with the migration of database implementations from Berkeley DB to LevelDB, verification speed was significantly improved.
However, this database migration also led to a BIP50 1 chain fork: a block containing many transaction inputs was accepted by upgraded nodes but rejected by unupdated nodes (because the block was too complex). This highlights the difference between Bitcoin Core development and regular software engineering: even purely performance optimizations can lead to unexpected chain splits.
The following year, (PR #2060) enabled multi-threaded signature verification. Around the same time, the dedicated cryptography library libsecp256k1 was created and integrated into Bitcoin Core in 2014. Over the next decade, through continuous optimization, it has become up to 8 times faster than the same functionality in the general-purpose OpenSSL library.
"Headers-first sync" (PR #4468, 2014) restructures the initial block download process: it first downloads the block header of the chain with the most accumulated work, and then simultaneously requests blocks from multiple peer nodes. In addition to accelerating IBD, it also prevents nodes from wasting bandwidth on orphan blocks that do not belong to the main chain.
In 2016, PR #9049 removed a seemingly redundant overlapping input check, introducing a consensus bug that allowed inflation. Fortunately, it was discovered and patched before it could be exploited. This incident spurred a massive investment in testing resources. Now, with differential fuzzing ( Chinese translation ), extensive code coverage, and stricter auditing discipline , Bitcoin Core discovers and resolves issues much faster, and no consensus vulnerability of the same severity has been reported since.
In 2017, the -assumevalid launcher tag (PR #9484) separated regular block validity checks from expensive signature verification, making the latter optional for most of IBD, thus reducing IBD time by about half. Block construction, proof-of-work, and cost rules remain fully verified: the -assumevalid mode simply skips signature checks entirely (before reaching a certain height).
In 2022, PR #25325 replaced Bitcoin Core 's standard memory allocator with a custom, pool-based allocator specifically optimized for coin caching. By designing specifically for Bitcoin's allocation model, it reduced memory waste, improved caching efficiency, and made IBD approximately 21% faster, while also allowing more coins to be crammed into the same amount of memory.
While the code itself doesn't mutate, the system it resides in is constantly changing. Bitcoin's state changes every 10 minutes—and with each change in usage patterns, the bottlenecks shift. Maintenance and optimization are not optional; without continuous improvement, Bitcoin accumulates vulnerabilities faster than a static codebase can withstand, and the performance of initial block downloads deteriorates rapidly, even as hardware continues to advance.
The ever-expanding size of the UTXO set, along with the increase in average block weight, has amplified these changes. What was once a CPU-intensive task (such as signature verification) is now often disk-intensive due to increased chain state access (which requires checking the UTXO set on disk). This shift has driven new priorities: optimizing memory caching, reducing LevelDB flush frequency, and parallelizing disk reads to keep modern multi-core CPUs busy.
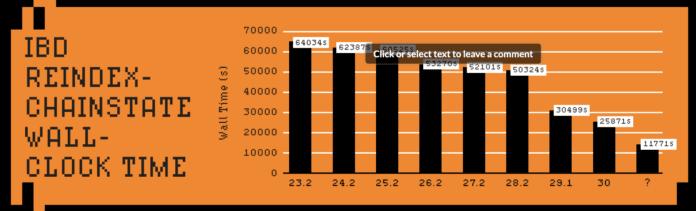
- A list of IBD dates for different Bitcoin Core distributions -
Recent optimizations
The foundation of software design is the prediction of usage patterns, which inevitably deviates from reality as the network evolves. Bitcoin's deterministic workloads allow us to measure actual behavior and make timely corrections, ensuring performance keeps pace with network growth.
We continuously adjust the software's default settings to better adapt to real-world usage patterns. Here are a few examples:
- PR #30039 increased the maximum file size for LevelDB—this single parameter change accelerated IBD by nearly 30% because it better matched the patterns of actually accessing the chain state database (UTXO set).
- PR #31645 doubled the size of the write batch, reduced fragmented disk writes during the most intensive write phase of the initial block download, and accelerated progress saving when the initial block download was interrupted.
- PR #32279 adjusts the storage size of the internal prevector (primarily used for storing scripts in memory). The old segregated witness prevector threshold biased older script templates at the expense of newer ones. By adjusting its size to cover the newer script sizes, fragmented allocation is avoided, memory fragmentation is reduced, and script execution benefits from better cache location.
All of these were minor changes, but they had a significant impact.
In addition to parameter adjustments, some changes also require us to rethink the existing design:
- PR #28280 improves how pruned nodes (nodes that discard old blocks to save disk space) handle frequent memory cache flushes. The original design either discarded the entire cache or scanned it for modified entries. Selectively tracking modified entries resulted in over 30% speedup for pruned nodes using the maximum cache (
dbcache), and approximately 9% speedup on default settings. - PR #31551 introduced batch processing for reading/writing block files, reducing the overhead of many small-scale file system operations. This 4 to 8x speedup for block file reads benefits not only initial block downloads but also other RPCs.
- PR #31144 optimizes the existing optional block file obfuscation (used to ensure data is not stored on disk in plaintext) by processing data in 64-bit blocks instead of bytes, bringing another IBD acceleration. With obfuscation becoming virtually free, users no longer need to choose between secure storage and performance.
Other minor caching optimizations (such as PR #32487) enable additional security checks that were previously considered too expensive by PR #32638.
Similarly, we can now flush the cache to disk more frequently (PR #30611) to ensure that nodes never lose more than an hour of verification work during downtime. This minor overhead is acceptable because further optimizations have already made initial block downloads much faster.
PR #32043 is currently a tracking thread for performance improvements related to IBD. It summarizes more than ten ongoing projects, ranging from disk and cache tweaks to concurrency enhancements, and provides a framework to measure how each change impacts performance in real-world scenarios. This approach encourages contributors to provide not only code, but also reproducible benchmarks, usage data, and comparisons across various hardware.
Future optimization suggestions
PR #31132 parallelizes transaction input fetching during block validation. Currently, each input is fetched sequentially from the UTXO set—if it's not found in the cache, disk communication is required, creating a read/write bottleneck. This PR introduces parallel fetching across multiple worker threads, achieving approximately 30% speedup with -reindex-chanstate (taking about 10 hours on a Raspberry Pi 5 with a 450MB database cache). A side effect is that it narrows the performance gap between high and low ` -dbcache configurations, allowing nodes with less memory to synchronize as quickly as those with more memory.
In addition to initializing block downloads, PR #26966 also uses configurable worker threads to parallelize block filtering and transaction index compilation.
Keeping the persistent storage UTXO set compact is crucial for node economics. PR #33817 experimented with the effect of slightly reducing it by removing an optional LevelDB feature (which may not be necessary for Bitcoin applications).
SwiftSync 3 is an experimental approach that leverages hindsight of historical blocks. Knowing the actual results, we can categorize each encountered coin based on its final state at the target height: those still unspent (to be stored), and those already spent before that height (to be ignored; simply verify their presence in the matching creation/spending pair, regardless of their specific position). Pre-generated hints can encode this categorization, allowing nodes to completely skip UTXO operations on short-lived coins.
Bitcoin is open to everyone
In addition to synthetic benchmarks, a recent experiment 4 also ran a Swiftsync prototype on a downclocked Raspberry Pi 5; this Raspberry Pi 5, powered by a single battery pack and connected via WiFi, re-encoded the chain state of 888,888 blocks in 3 hours and 14 minutes. Experiments using equivalent configurations showed a 250% speedup for full verification on newer Bitcoin Core versions 5 .
Years of accumulated work have translated into a huge impact: nearly 1 million blocks have been fully verified, and this can be done in a day on inexpensive hardware; the blockchain has remained economical despite its continued growth.
Self-governance is easier than ever before.
References
1. https://github.com/bitcoin/bips/blob/master/bip-0050.mediawiki
2. https://en.bitcoin.it/wiki/Common_Vulnerabilities_and_Exposures
3. https://delvingbitcoin.org/t/swiftsync-speeding-up-ibd-with-pre-generated-hints-poc/1562
4. https://x.com/L0RINC/status/1972062557835088347 ↩
5. https://x.com/L0RINC/status/1970918510248575358 ↩
All the pull requests (PRs) listed in this article can be found here by their numbers: https://github.com/bitcoin/bitcoin/pulls