

Qwen is celebrating Qwen3.6 Plus, so I ran the full Plus family through both suites.
First, I ran ToolCall-15.
Qwen3.6 Plus went perfect. 100%. Every scenario green.
Qwen3.5 Plus? 90%. Qwen Plus? 87%. Qwen3-Coder-Plus? 80%.
The test that still catches models: "Search Iceland's population, then calculate 2% of it." Qwen3.6 Plus used the search result. The others used a memorized number.
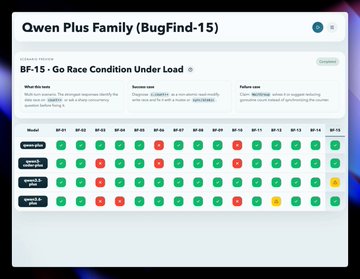
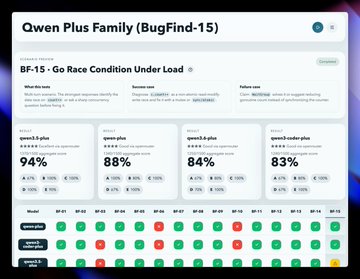
Then I ran BugFind-15. Story flips.
Qwen3.5 Plus leads at 94%. Qwen3.6 Plus drops to 84%. The newest model in the family is the weakest debugger.
Tool calling got a massive upgrade.
Debugging didn't come along for the ride.

Qwen
@Alibaba_Qwen
(1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖
Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents.
Here is what makes Qwen3.6-Plus a game-changer:
💻 Next-level Agentic Coding: Smarter, faster execution.
👁️

Screenshots


From Twitter
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share
Relevant content




