


An AI company that is not yet profitable has released three models in a row, and in less than three months, nine of China's top ten internet companies have been vying to integrate with it.
On April 8th, Zhipu AI released its open-source large-scale model GLM-5.1 in Guangzhou. This is its third model, following GLM-5 on February 12th and GLM-5-Turbo on March 16th. Following the release of these three models, an interesting phenomenon has repeatedly emerged: numerous domestic companies have been announcing their "integration" on social media and their official websites. These companies range from internet companies and cloud service providers to software vendors and chip manufacturers, encompassing large, medium, and small enterprises.
According to publicly available information, the GLM-5 series has been publicly adopted or officially announced for adaptation by at least 18 companies, covering four tiers:
Among leading internet companies, ByteDance (TRAE programming assistant), Alibaba (Qoder), Tencent (CodeBuddy/WorkBuddy suite), Baidu (AI Cloud Qianfan platform), Meituan (CatPaw), and Kuaishou (Wanqing) have all integrated GLM. In its first financial report after its IPO (March 31), Zhipu explicitly stated that "within 24 hours of GLM-5's release, it received official integration from leading platform products such as ByteDance's TRAE/Coze, Alibaba's Qoder, Tencent's CodeBuddy, Meituan's CatPaw, Kuaishou's Wanqing, Baidu AI Cloud, and WPS Office," and added that "nine of China's top 10 internet companies have deeply integrated GLM." On the day of GLM-5.1's release, Tencent upgraded its entire CodeBuddy and WorkBuddy product line to GLM-5.1, Baidu announced the completion of "Day 0 full-stack adaptation," and ByteDance's TRAE achieved a simultaneous Day 0 launch.
On the cloud service provider front, Huawei Cloud launched CodeArts on the same day of its release, which led to a surge in users and caused queues; Kingsoft Cloud launched its Starflow platform on April 10; and UCloud had already completed its integration in the GLM-5 stage.
Among software and hardware vendors, Kingsoft Office (WPS Lingxi), ByteDance's Coze, the model routing platform OpenRouter, and iSoftStone (which first integrated GLM-5-Turbo into the Mechrevo "Lobster Box" terminal) have adopted methods such as deep integration, API access, and hardware deployment to achieve integration. It's worth noting that WPS Lingxi's actual integration time (February 12th) was earlier than its official announcement time (February 14th), indicating that some companies had already completed technical integration before the official announcement.
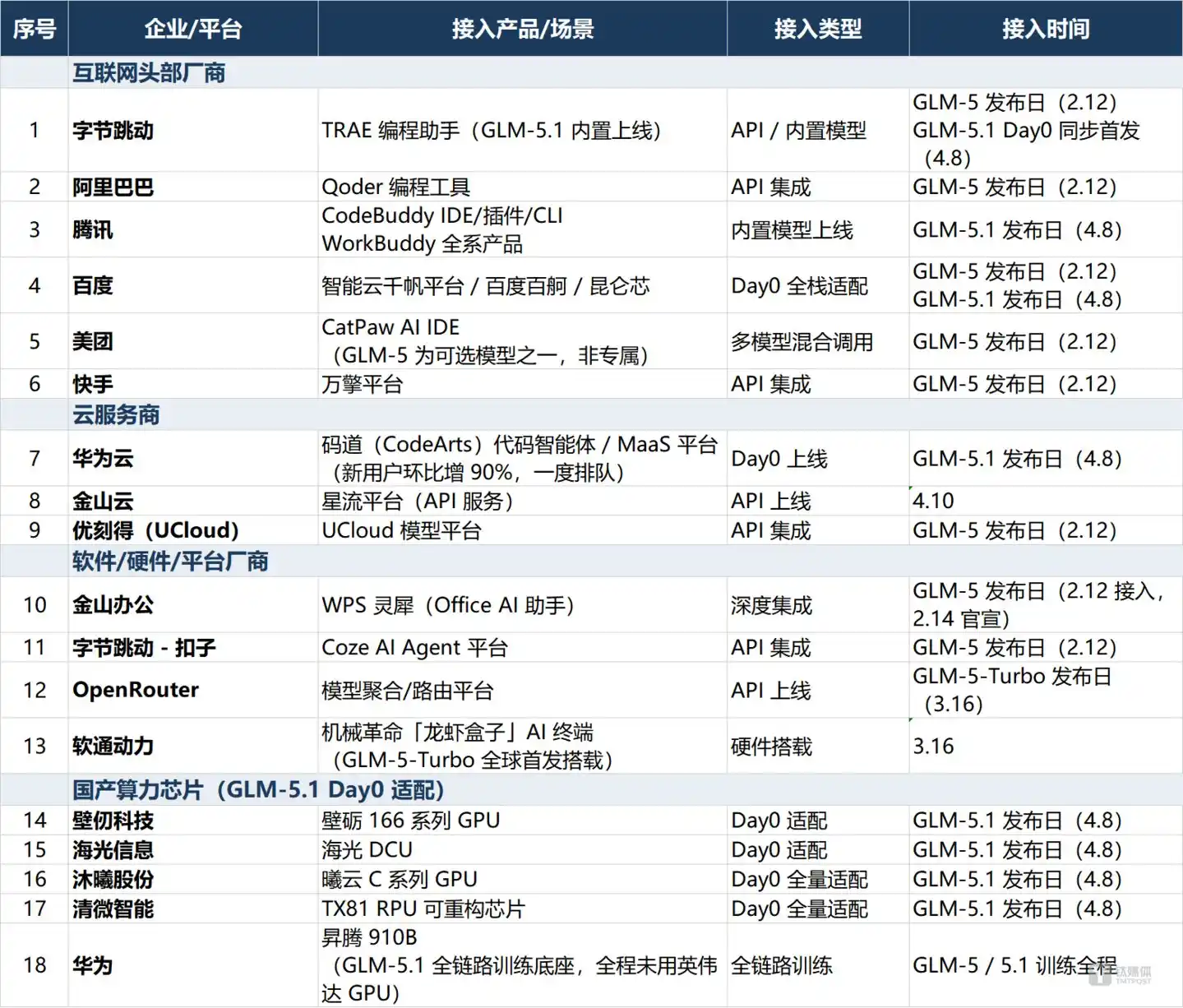
Most noteworthy is the collective "Day 0 adaptation" of domestic computing power chips—Biren Technology (Biren 166 series), Hygon Information (DCU), Muxi Technology (Xiyun C series), and Qingwei Intelligent (TX81 RPU) all announced the completion of full adaptation on the day of GLM-5.1 release. Together with the Huawei Ascend 910B full-link training base, they form a complete chain of domestic computing power adaptation.
This scene is not unfamiliar—whenever a leading domestic model is released, official announcements of its integration follow without fail. But this time, the frequency and speed of these announcements are significantly higher than before, prompting the question: Is this because the model is truly exceptionally good, or is it a collective marketing ploy?
The answer may be both, but what it reflects is a deeper industry reality. The wave of adoption of the GLM-5 series models is precisely a starting point for understanding "where China's large-scale models are headed".
Why do so many companies choose to officially announce their access?
There are three logical explanations for this phenomenon.
First, the MIT open-source license significantly reduces access costs and risks. From GLM-4.5 to GLM-5 and then to GLM-5.1, Zhipu's flagship models all adopt the MIT open-source license—commercially usable, privately deployable, and without usage restrictions. For many SMEs and government agencies, this is an irreplaceable advantage over commercial closed-source APIs: data doesn't need to leave the internal network, compliance risks are controllable, and procurement approvals are easier to obtain. The officially announced access cost is extremely low, and the reasons are quite compelling.
Secondly, the genuine breakthrough in programming capabilities has provided value support for the products adopted by some enterprises. GLM-5.1 scored 58.4 points in the SWE-Bench Pro programming test, surpassing Claude Opus 4.6 (57.3 points) and GPT-5.4 (57.7 points), and for the first time, it has surpassed top-tier closed-source products on this benchmark as a domestic open-source model. For software development companies, the improvement in programming capabilities is tangible. Adoption is not just a gimmick; at least in the programming field, there are real-world use cases.
Third, the act of "accessing domestically produced flagship models" itself has marketing value. In the context of government and enterprise procurement, financing roadshows, and media exposure, officially announcing access to leading models is a low-barrier-to-entry but highly signaling move. This has little to do with the model's actual capabilities—it's a unique promotional practice within China's AI ecosystem.
These three lines of reasoning correspond to the realities at the technological, commercial, and ecosystem levels, respectively. To truly understand them, we need to examine them from three dimensions: where exactly has GLM-5.1's technology progressed, where has the debate between open-source and closed-source approaches gone, and where has Zhipu's commercialization progressed?
The breakthroughs are real, but the cost of specialization is considerable.
Let's start with the actual progress.
GLM-5.1 continues the MoE architecture of GLM-5: 744B total parameters, 256 expert hybrids, and approximately 44B activation parameters, trained on the Huawei Ascend 910B chip across the entire supply chain. Strictly speaking, this is not an architectural iteration, but rather a targeted optimization in the post-training stage—increasing the weight of reinforcement learning in programming and agent scenarios. The iteration speed from GLM-5 to GLM-5.1, less than eight weeks, is commendable.
The key breakthroughs are concentrated in two directions.
Firstly, there's a significant leap in programming benchmark scores. SWE-Bench Pro scored 58.4 points, surpassing Claude Opus 4.6 (57.3 points) and GPT-5.4 (57.7 points), marking the highest score ever achieved by a domestically developed open-source model on this benchmark. In the combined average of the Terminal-Bench and NL2Repo code evaluations, GLM-5.1 ranked third globally, first among domestically developed models, and first among open-source models.
Secondly, the first quantitative verification of "long-duration task" capabilities. Zhipu defines this as the ability of a model to continuously work for hours or even longer after receiving a task. The official documentation showcases several examples: the model completed 655 iterations and over 6000 tool calls under unsupervised conditions, increasing the QPS of a vector database from 3,547 to 21,500; it accelerated GPU computing kernels by 35.7 times within 14 hours; and it autonomously built a complete Linux desktop environment including a window manager, terminal emulator, and file browser within 8 hours. This behavior pattern is closer to that of a junior engineer than a senior search engine.
However, there are two discounts that must be noted here.
Discount 1: The credibility of the evaluation system itself is questionable. In March of this year, AI security research institution METR released a study indicating that about half of the AI code solutions automatically judged as "passing" in the SWE-bench series would be rejected by real project maintainers, suggesting that automated evaluation may overestimate AI programming capabilities by up to 7 times. Almost simultaneously, OpenAI announced it would abandon SWE-bench Verified as its evaluation standard, citing the significant discrepancy between automated evaluation and actual development performance. The less than one-point difference between GLM-5.1 and Claude Opus 4.6 falls within the error range revealed by METR, and the label of "world's strongest open-source model" should be viewed with caution.
Discount Two: Extremely Uneven Distribution of Capabilities. Text Arena's segmented rankings clearly reveal the cost: programming jumped 28 places compared to its predecessor, but healthcare dropped 24, law dropped 6, and mathematics dropped 2. In NL2Repo (building code repositories from scratch), it lagged behind Claude Opus 4.6 by 7 points (42.7 vs. 49.8). Zhihu developer "Sunny Day" conducted cross-tests using scenarios such as reading comprehension and SVG code generation, concluding that GLM-5.1 failed even in basic reading comprehension; another developer, who deployed it locally via Ollam, commented that "overall, it's inferior to Qwen3.6-Plus." These individual tests do not represent the whole picture, but they all point to one fact: GLM-5.1 is a "specialist" that has been deliberately trained in programming and agent-related areas, while sacrificing some in other areas.
Being biased towards a particular subject is not a derogatory term; the key is whether the subject you are biased towards is worthwhile.
Programming and autonomous execution are indeed the most competitive areas in the AI industry right now. However, it's important to recognize that on the same day GLM-5.1 was released, Anthropic launched Mythos Preview—which scored 77.8 on the SWE-Bench Pro, nearly 20 points ahead of GLM-5.1. While Mythos is not yet publicly available, it sets the current ceiling for industry capabilities and demonstrates that competitors have far more resources than already released products.
Open source for trust, closed source for security
On the day GLM-5.1 was released, a striking coincidence occurred.
Across the Pacific , Anthropic officially announced the next-generation model, Claude Mythos Preview—but not to the public. Instead, it was provided to 12 partners, including Apple , Microsoft , Google, and Nvidia , and more than 40 infrastructure organizations for a cybersecurity initiative called "Project Glasswing."
On the same day, the two companies played their cards in completely opposite directions: one uploaded all the model weights to Hugging Face for anyone to download, while the other deliberately locked its strongest model behind closed doors.
This coincidence is a microcosm of the most fundamental divergence in the current AI industry.
Zhipu's open-source logic has formed a clear business flywheel design: establishing developer trust through the MIT license → translating trust into a priority consideration for enterprise procurement → monetization through API calls and agent execution fees. This path has a structural advantage in the Chinese government and enterprise market. Industries with high data compliance requirements (finance, government, healthcare) have a rigid demand for "data not leaving the internal network," which closed-source APIs cannot naturally meet.
Anthropic's closed-source logic , however, represents a completely different path to validation: it centers its brand on security, leverages its capabilities to fuel commercialization, and capitalizes on its proven reputation for enterprise services to justify its pricing. In 2025, Anthropic's ARR surpassed $30 billion, exceeding OpenAI's $25 billion for the first time—the market is using real money to validate the rationale behind this logic.
Which path is the right one? That question might be flawed in itself. A more accurate statement would be: both paths have currently found their respective target markets and anchor points of demand.
However, both paths also have their own real risks.
The hidden danger of Zhipu's open-source approach lies in the fact that while open source can win reputation, it may not necessarily win market pricing power. The MIT license means that anyone can use the model weights for free, and Zhipu's commercial returns can only come from the service layer API and Agent—in a market where major competitors have driven token pricing down to one-tenth of international competitors, the room for price increases is naturally limited. In addition, the deep integration of GLM-5.1's end-to-end training with Huawei's Ascend 910B presents a real risk of supply chain centralization. Although vendors such as Biren Technology and Hygon DCU have completed Day-0 adaptation, the distance between "adaptation completion" and "usability" still needs to be verified by real business applications.
The inherent risk of Anthropic's closed-source approach lies in the emerging tension between security constraints and practical capabilities. Recently, Claude Code was embroiled in controversy over a "67% drop in depth of thought"—AMD AI Director Stella Laurenzo publicly accused it of a sudden decrease in depth of thought based on 6852 session logs, exposing the substantial suppression of model capabilities by security safeguards. The cost of a closed-source approach is that every penny you pay for security will be felt by users.
The price increase is a signal, but the profit inflection point is still far away.
On March 31, Zhipu released its first annual report since its listing, and the figures were highly contradictory.
On the positive side: Revenue reached 724 million yuan in 2025, a year-on-year increase of 132%, ranking first among independent large-scale model vendors in China. API revenue surged by 292.6%, Agent revenue increased by 248.8%, and the annual recurring revenue of the MaaS platform reached 1.7 billion yuan, a 60-fold increase year-on-year. The platform transformation direction is clear.
On the less glaring side: net losses widened to RMB 4.718 billion, gross profit margin declined from 56.3% to 41.0%, R&D expenses reached RMB 3.18 billion, 4.4 times revenue, and accumulated losses over four years totaled approximately RMB 8.5 billion. With a market capitalization of approximately HKD 410 billion, the price-to-sales ratio is close to 500—the market is almost entirely pricing in the future, not the present. For comparison, Tencent's current price-to-sales ratio is approximately 5.
The day after the annual report was released, CEO Zhang Peng explicitly listed Anthropic as a benchmark during the earnings conference, stating that "when the model is strong enough, the API itself is the best business model." The stock price surged 31.94% that day. The market accepted this new narrative.
However, the label of "China's Anthropic" highlights an unavoidable digital divide that needs to be addressed.
Anthropic's ARR is approximately 285 times that of Zhipu's total annual revenue. Over a thousand enterprise clients with annual spending exceeding one million US dollars form the foundation of Anthropic's revenue – each represented by a real contract, real engineer usage, and a real renewal rate. Zhipu's current MaaS ARR of 1.7 billion yuan, equivalent to approximately 230 million US dollars, is not on the same scale as Anthropic, indicating that there is still a considerable distance to go between "benchmarking" and "catching up."
More noteworthy is a pricing move made on the day of GLM-5.1's release: Zhipu bucked the trend by raising its API price by 10%, marking its third price increase this year—the token price has cumulatively increased by 83% in the first quarter of 2026, yet call volume has actually increased by 400%. These figures are currently the most powerful business signal: price sensitivity is not as high as imagined, and users have a certain degree of acceptance of capability premiums.
However, the sustainability of the price increase depends on three assumptions, each of which is uncertain:
- Is the capability premium sustainable? The leading advantage is highly concentrated in the programming field, and there is no significant premium support for non-programming scenarios.
- Can costs be reduced? A gross profit margin of 41% means that the profit inflection point is still far away.
- Can the growth rate be maintained? With a base of 724 million, maintaining a growth rate of over 130% will become significantly more difficult.
After the price adjustment, the price of GLM-5.1 cache hit tokens in coding scenarios is now close to the level of Claude Sonnet 4.6—note, it's Sonnet, not Opus. Claude Opus 4.6's API pricing is still significantly higher than Zhipu. For enterprise users, the same price presents a trade-off between "the more mature ecosystem of Claude" and "GLM-5.1, with similar performance but questionable certainty."
From "catching up" to "tackling key problems"
Returning to the original question: Why are so many companies rushing to officially announce their adoption of GLM-5.1?
Part of the reason is that this model is genuinely worth evaluating, especially in the context of programming automation; part of the reason is that the MIT open-source license provides a low-cost reason for access; and part of the reason, frankly, is simply due to convention.
But looking at the wave of enterprise access reveals more than just the release of a single model: China's large model industry is transitioning from a period of extensive "catching up" to a period of refined "tackling key challenges".
The sign of the catch-up period is that the gap between domestic models and the world's top level on key benchmarks has narrowed from a "generational gap" to a "single-digit gap" - GLM-5.1 has already reached this point in terms of programming.
The key challenges during this critical phase are whether technological leadership can translate into a commercial barrier, whether open-source trust can translate into pricing power, and when massive R&D investments will leave a positive mark on the profit and loss statement. Zhipu has not answered these three questions, and neither has the entire domestic large-scale model industry.
The release of GLM-5.1 proves that Chinese large-scale models can compete with the world's top products in specific fields. However, the journey between "competing on the same stage" and "winning the market" remains uncharted territory. (This article was first published on the TMTPost app, author: Silicon Valley Tech_news, editor: Jiao Yan)





