

My initial research shows that it is possible to gain a further 30% storage reduction for contract code, on top of contract deduplication and compressing code at storage time.
Of necessity, the solidity compiler and every other compiler will create bytecode with patterns of opcodes. When compressing an individual contract, an ideal compression algorithm learns these patterns after they have occurred once in the individual contract, and can then refer to them in shortened ways throughout the rest of the contact.
However, this means that the compression algorithm is always surprised by the first occurrence of a pattern in an individual contract, because the algorithm has no idea that this is common to many smart contracts, and so can only learn from the individual contract that it is working on.
The solution to this is built into most compression algorithm libraries - you can provide a small pre-trained “dictionary” that encodes common patterns already seen in historical data. This allows immediate compression of common patterns the first time they appear in new data.
As a second benefit, when a pretrained dictionary is used, it also remembers large patterns from the over represented spam/spam contracts. For those contracts that have been spammed tens of thousands of times with minor variations, a dictionary can reduce these to single digit percentages of their original size.
Here’s the results:
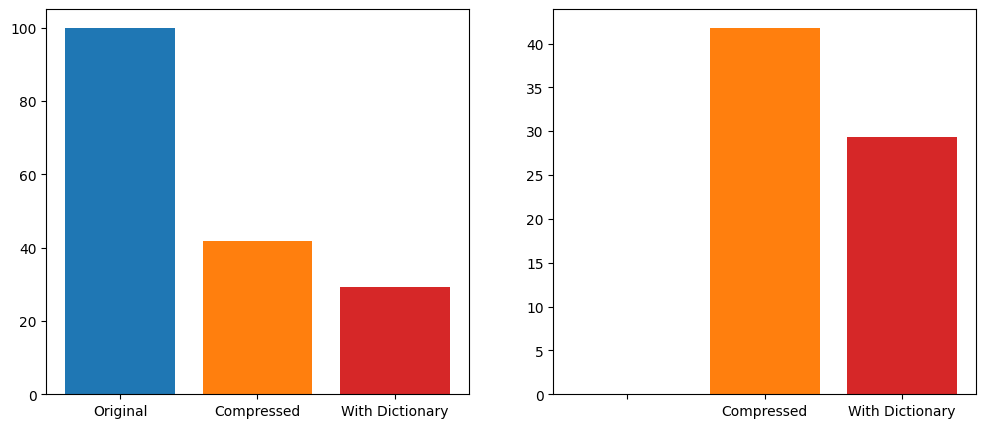
Using the zelliac dataset of all contract bytecode deployed up to early 2025, there are 1,539,858 deduplicated deployed bytecode sets.
Using the Zstandard compression library at its default fast compression level of 3, and compressing each individual bytecode set, the total size goes from 100% to 41.8% of original size. Adding in a 100KB dictionary, trained at the default settings for compression level results in bytecode taking up 29.3% of the original size, a 30% reduction from the compressed size.
Increasing the compression dictionary size or increasing the compression level further reduces the final size. I kept this optimized for speed. It’s also quite possible that further tuning of dictionary training parameters could result in even smaller sizes.
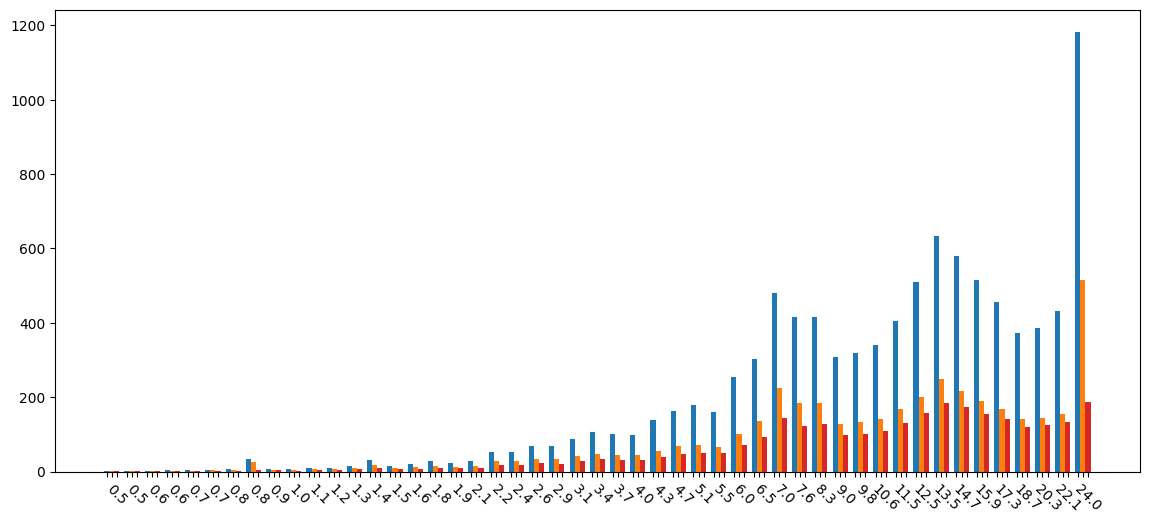
Total storage space required across different sized contract byte codes:
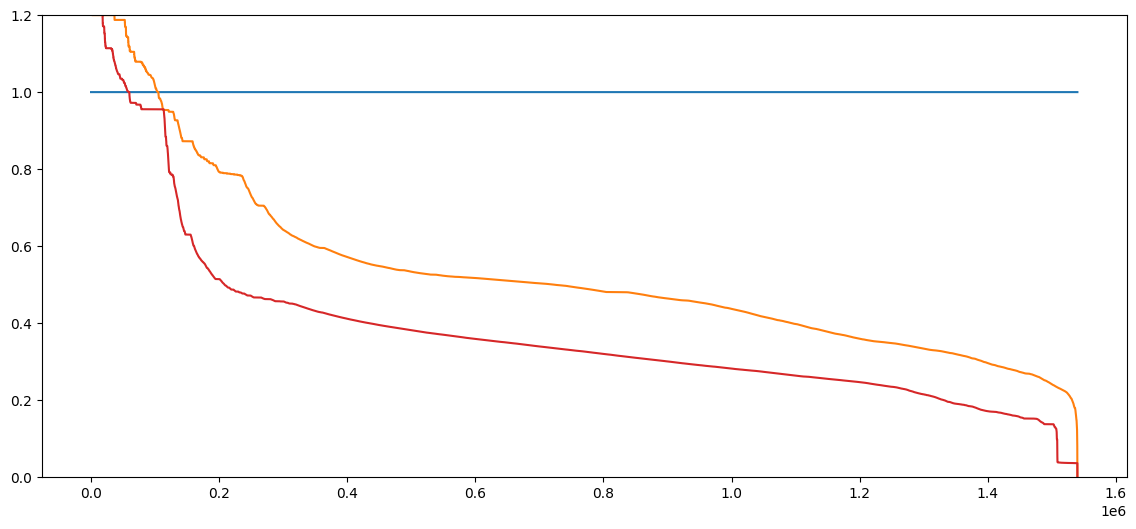
Worst to best performance across all contracts.
Final notes:
- If using this in a client, I would presume storing a single byte that would tell if a contract was compressed at all, and if so which dictionary / algo was used. This would allow for smooth upgrades to better dictionaries in the future, as well as not compressing files that compression makes worse.
- I used zstandard as a compression library simply because I’ve had good experiences with it in the past. I’ve not compared different compression libraries or algorithms at this point.





