

Authors: Shouyi, Denise | Biteye Content Team

Over the past month, the term "transfer station" has frequently appeared on many people's homepages. Some players who used to collect airdrops in the crypto have quietly transformed into "API transfer station" merchants, engaging in token import and export business.
The so-called "transfer station" is not a new technological invention, but rather an arbitrage model based on global AI service price differences and access barriers. Despite facing multiple issues such as privacy, security, and compliance, this sector has still attracted a large number of individuals and small teams to enter the market.
So, what exactly is an "API hub"? And how does it enable token arbitrage amidst global AI price differences and access barriers, attracting a large number of individuals and small teams to participate?
Let's break it down from its essence and operation process.
I. What is a transit station?
The essence of an API transfer station is to build an intermediate service that provides domestic users with API tokens from foreign AI companies at a lower price and in a more convenient way; it is said to be a "global token transporter".
Its operation process is roughly as follows:
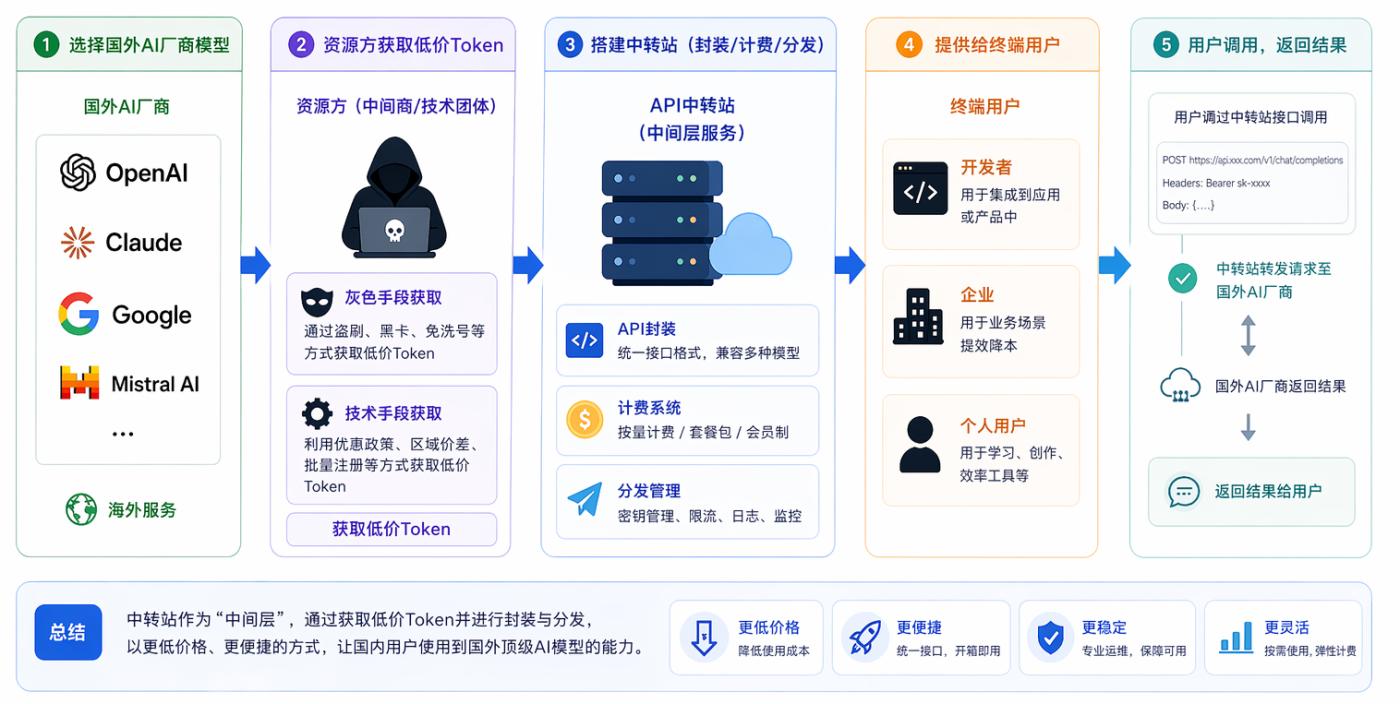
👉Choose models from overseas AI vendors (OpenAI/Claude, etc.)
👉Resource providers obtain low-priced tokens through "gray" or technical means.
👉Set up a transit station for packaging, billing, and distribution.
👉Provided to end users such as developers/enterprises/individuals
Functionally, it's like an "AI transfer station"; commercially, it's more like a liquidity intermediary in the secondary token market.
The premise for this link to exist is not technological barriers, but rather the long-term coexistence of several differences:
• The official API pricing is relatively high.
• There is a cost mismatch between subscription and API models.
• Access and payment terms vary by region
• Users have a strong demand for model capabilities, but the official access path is not user-friendly.
These factors combined gave "transfer stations" a space to survive.
II. Why would anyone use a transit station?
The reason why "Token import" has become a hot trend is mainly due to the high costs brought about by the transformation of AI's role, as well as the capability gap between domestic and foreign models.
1. Good models consume a lot of tokens.
With the maturation of desktop AI agents such as Codex and Claude Code, AI is beginning to truly possess the ability to "get things done," such as assisted programming, video editing, financial trading, and office automation. These tasks heavily rely on high-performance, large-scale models, and costs are billed in tokens.
Taking Claude Code as an example, its official price is approximately $5 per million tokens (about 35 RMB). Intensive use for one hour could consume tens of dollars, while heavy developers or enterprises could consume over $100 per day. This cost far exceeds many people's expectations, even surpassing the cost of hiring junior programmers, making "how to use top-tier AI at low cost" a pressing need.
2. Leading overseas models have a clear advantage.
Despite the rapid progress and highly competitive pricing of domestically produced models in the past year, leading overseas models still hold a significant advantage in scenarios such as complex code tasks, toolchain collaboration, long-chain inference, and multimodal stability.
This is why many developers, researchers, and content teams, even knowing that the prices are higher, are still willing to prioritize using the model capabilities of OpenAI, Anthropic, and Google.
Simply put, users don't necessarily need a "transfer station"; they just want:
• A stronger model
Lower prices
• Easier access
When these three things cannot be obtained simultaneously from official channels, a transfer station naturally emerges.
3. There is a cost mismatch between subscription models and API models.
Another frequently discussed reason for the popularity of transit stations is that subscription benefits and API billing are not always linearly correlated.
A common practice in the market is to purchase official subscriptions, team packages, corporate credits, or other preferential resources, and then resell a portion of the capabilities to end users.
Taking OpenAI as an example, purchasing a Plus subscription allows access to Codex's services. Logging in via OAuth to OpenClaw is equivalent to calling an API. The $20 monthly subscription fee can generate approximately 26 million tokens, and with an output of $10-12 per million tokens, this equates to $260-$312. Using tokens through reverse proxying via a subscription offers excellent cost-effectiveness.
Based on some users' experiences, this approach may indeed be cheaper than directly using the official API at certain stages. However, it's important to emphasize that:
• This is not the official pricing system
• This does not mean it can stably and equivalently replace API calls.
• This does not mean that this approach is sustainable in the long term.
Many people only see the "cheapness" but ignore the fact that these cheap prices are often built on unstable resources, gray areas, or policy loopholes.
3. Can the transfer station be used?
Whether it can be used or not is not an absolute answer.
The real question is: what risks are you willing to take?
The profit model of a transit hub seems straightforward—buy low and sell high. But if you really break it down, it usually consists of at least three layers, and each layer carries different risks.
1. Upstream: Where do low-cost token resources come from?
This is the starting point of the entire ecosystem, and also the grayest layer.
Some resource providers obtain model access capabilities at prices far below market value through various means, such as:
• Utilize business support programs and cloud credits
• Register accounts in bulk and rotate them
• Redistribute using subscription benefits, team accounts, or special offers.
In more aggressive cases, it could also involve illegal activities such as credit card fraud and fraudulent account opening.
The source of resources determines the upper limit of the stability of a transit station. If the upstream resources are built on unstable or even illegal methods, then the end user is not buying a cheap solution, but merely a temporary interface that may fail at any time.
2. Midstream: Whose server will your data pass through?
This is often the most easily overlooked problem.
When you call a model through a relay station, the user's input prompt, context, file content, and the model's output results usually pass through the relay station's own server first.
This data is extremely valuable, reflecting genuine user intent, industry-specific prompts, and model output quality, and can be used to evaluate or fine-tune proprietary models. The data transfer station may anonymize and package this data, then sell it to large domestic model companies, data brokers, or academic research institutions. Users contribute training data free of charge while paying, making this a classic example of "the customer is also the product."
A recent rant by OpenClaw founder @steipete illustrates this point: https://x.com/steipete/status/2046199257430888878
Furthermore, intermediary stations may inject scripts into the request chain (e.g., secretly adding hidden System Prompts), thereby altering model behavior, increasing token consumption, and even introducing additional security vulnerabilities. This risk is particularly important to be aware of in AI Agent scenarios.
3. End point: You bought the flagship version, but did you really receive the flagship version?
This is the third common risk: model degradation or model substitution.
When a user pays, they see a premium model name, but the actual request may not land on the corresponding version. The reason is simple—for some merchants, the most direct way to reduce costs is not optimization, but replacement.
For example, a user might purchase the flagship Opus 4.7, but it actually uses the second-tier flagship Sonnet 4.6 or the lightweight Haiku. Because the API format can maintain compatibility, ordinary users are unlikely to notice this immediately.
Only when the task becomes sufficiently complex will the issues of "incorrect performance," "insufficient stability," and "deteriorated context quality" become apparent, but without concrete evidence. According to the research team's tests on 17 third-party API platforms, 45.83% of the platforms exhibited an "identity mismatch" problem, meaning that users paid for GPT-4 but were actually running a cheaper, open-source model, with performance differences reaching as high as 40%.
In summary, using unofficial intermediary platforms carries risks such as data breaches, privacy concerns, service interruptions, model inconsistencies, and the risk of platforms absconding with funds. Therefore, for sensitive business operations, commercial projects, or tasks involving personal privacy, it is strongly recommended to use the official API.
IV. Is it feasible to run a transit station business?
Despite the high risks, this business hasn't disappeared. On the contrary, it continues to evolve.
If the early "Token import" was about bringing in overseas models at low cost, then another approach has emerged in the market: Token export.
1. Why do people still do it?
Because the demand is real, the startup cost is low, and the prepaid model generates quick cash flow. However, the risk control pressure is enormous. Claude has recently increased its KYC and account suspension efforts, while OpenAI has also plugged many loopholes in the "zero-payment" model. On the other hand, the instability of the service means that the low prices come with high after-sales costs. Coupled with competition from peers, many intermediary stations are currently facing a situation of declining volume and prices.
Therefore, this industry is more like a short-term window with high turnover, low stability, and high risk , and it is difficult to easily package it as a long-term, stable, and sustainable business.
2. Why are "Token Exits" starting to appear again?
If “Token import” is about taking advantage of the price difference of overseas models, then “Token export” is about taking advantage of the cost-effectiveness of domestic models, packaging them and selling them to overseas users, thus forming a “reverse output” path.
The price advantage of domestically produced models is significant. Using data from early 2026 as a reference, Qwen 3.5's price per million tokens was as low as 0.8 RMB (approximately 0.11 USD), which is 1/18th of Gemini 3 Pro's price and more than 27 times lower than Claude Sonnet 4.6's $3 input price. GLM-5 surpasses Gemini 3 Pro in programming benchmarks and approaches Claude Opus 4.5, but its API price is only a fraction of the latter.
These domestically developed models are relatively scarce overseas, with registration barriers, payment restrictions, language interfaces, and information gaps among overseas developers regarding the capabilities of domestically developed models, forming invisible barriers to entry.
Therefore, some transit points choose to purchase model API quotas in bulk in China using RMB, expose OpenAI-compatible interfaces to the outside world through a protocol conversion layer, and sell them to overseas developers and startups in USDT/USDC, with considerable profit margins.
For example, Alibaba Cloud's Hundred Refinements Coding Plan offers a package of four models: Qwen3.5, GLM-5, MiniMax M2.5, and Kimi K2.5. New users can get 18,000 request quotas for only 7.9 RMB in the first month. When mapped to overseas markets and sold in USD, the profit margin can exceed 200%.
From a purely business perspective, there is certainly room for profit.
However, in the long run, it still cannot avoid the issue of stability and compliance.
3. Is this approach stable?
Unstable. Minimax recently announced it would regulate third-party intermediary platforms because some of these platforms cut corners, damaging Minimax's reputation. Aside from the possibility of criminal charges if the token's origin involves theft or fraud, users using intermediary tokens could lead to data breaches or misuse, potentially causing harm to the token seller.
So the real question isn't "whether you can make money," but rather: whether the money you make can cover the systemic risks that follow.
V. How can ordinary users identify risks at transit stations?
In a market rife with unreliable API intermediary services, choosing a trustworthy provider is of paramount importance.
Because some transfer stations engage in model substitution and adulteration, users can learn some detection methods:
Recommendation: Follow the "ping + self-reporting model" command in the test.
Prompt example (copy and send directly to the relay station):
Always say 'pong' exactly, and tell me which series model you are referring to, preferably the specific version number. Please reply in Chinese.
User input: ping
True model features:
- Strictly reply with "pong" (lowercase, no extra words).
- The number of input tokens is usually around 60-80.
- Simple style, no emojis, no flattery
Fake models/adulterated features:
- An abnormally high number of input tokens (often exceeding 1500) indicates that a massive amount of hidden system prompts have been injected.
- Reply with "Pong! + nonsense + emoji"
- Not strictly following the instruction to "exactly say 'pong'"
Refer to @billtheinvestor 's detection method: https://x.com/billtheinvestor/status/2029727243778588792
0.01 Temperature Sorting Test: Input "5, 15, 77, 19, 53, 54" and ask the AI to sort or select the maximum value. A true Claude model almost consistently outputs 77, while a true GPT-4o-latest model often outputs 162. If the results fluctuate wildly for 10 consecutive tests, it is likely a fake model.
- Long text input sniffing: If a simple ping operation results in more than 200 input tokens, it may mean that the relay station is hiding a huge number of prompts, with a probability of over 90% of the time being that the model is being spoofed.
- Identifying the style of rejection in violation of rules: Intentionally ask questions that violate the rules and observe the AI's rejection style. The real Claude will politely but firmly reply "sorry but I can't assist...", while the fake model often becomes overly verbose, uses emojis, or employs obsequious tones such as "Sorry, Master~💕".
- Functional loss detection: If the model lacks function calls, graph recognition, or long context stability, it is likely a weak model impersonating another model.
Alternatively, you can choose some intermediary testing websites to assess the "purity" of your token, but be aware that this will expose the key in plaintext. The safest approach remains official channels.
It needs to be emphasized that:
Even if you master the identification techniques, it doesn't mean you can truly avoid risks. This is because many risks are invisible to the average user.
In conclusion
The transit hub is not the ultimate answer for the AI era; rather, it is more like a temporary arbitrage window arising from a temporary mismatch between global model capabilities, pricing mechanisms, payment terms, and access permissions.
For ordinary users, it may indeed be a low-cost entry point to access top-tier models; but for developers, teams, and entrepreneurs, what is truly expensive is never the token itself, but the stability, security, compliance, and trust costs behind it.
Cheapness can be copied, and interface compatibility can be copied. What's truly hard to copy is never price, but long-term reliability.
⚠ Friendly Reminder: For ordinary users who wish to try this, it is recommended to use it only in non-sensitive and non-critical scenarios, and never put core data, trade secrets, or personal privacy into it; developers should prioritize official APIs or official self-made proxies to ensure stability and compliance, and use it with more peace of mind; entrepreneurs who intend to enter the market must formulate a clear exit mechanism in advance to avoid getting trapped in the gray area and unable to extricate themselves.
[Disclaimer] This article is purely for industry observation and discussion of publicly available information, and is for reference and learning purposes only. It does not constitute any form of investment advice, entrepreneurial guidance, business recommendation, or API usage guide.



