The article's core argument is that the focus of competition in financial AI is not on who can create a more chatty "financial version of ChatGPT," but on who can deeply integrate into the daily work tools (such as Excel, PPT, and Word) and core business processes (such as due diligence and approval) of financial professionals, and directly output formal "deliverables" that can be reviewed and archived.
Article by: Resonant Ones
Article source: Suichu.AI
The competition in financial AI is not about "who can chat," but about "who can access Excel, PPT, and approval workflows."
Many people believe that the competition in financial AI is about training a larger model that understands finance better.
But Claude for Financial Services reveals the real answer: the core of financial AI is not the model, but the workflow.
It's not about having AI chat with users about stocks, but about integrating AI into Excel, PPT, Word, investment research, investment banking, due diligence, compliance, reconciliation, and approval processes.
This is crucial for domestic entrepreneurs. If you're still working on a "financial version of ChatGPT," you'll likely be swallowed up by large companies, data terminals, and office suites. But if you can take over the repetitive Excel, PPT, Word, and approval packages produced daily by financial institutions, the opportunity is just beginning.
A real-life scenario
Last month, I talked to a friend who works in private equity. Their team was doing due diligence on a consumer company and received a Data Room containing 17 folders and more than 400 documents—contracts, audit reports, bank statements, order details, interview notes, and management materials.
Previously, it would take a VP and two analysts two weeks to produce a decent first draft of IC Memo.
Now what? If someone (or an agent) could complete the data sorting, risk labeling, missing item identification, and draft generation within 24 hours—do you think the client would buy it?
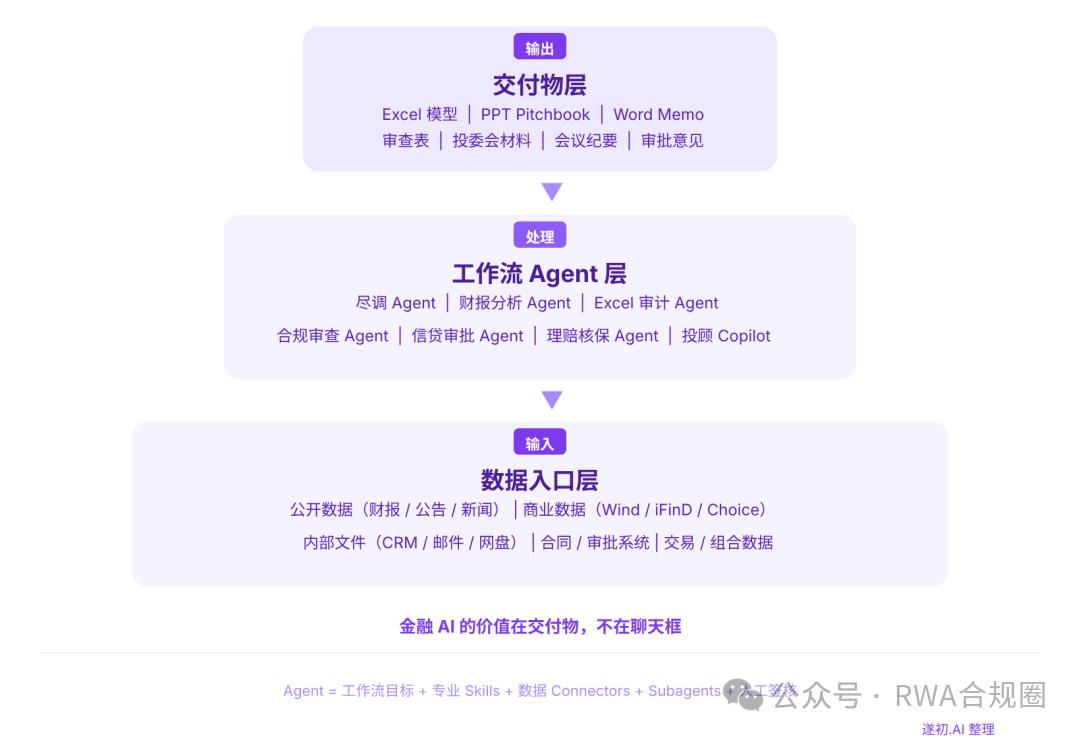
This isn't science fiction. Claude for Financial Services is already doing this. And what it's open-sourcing isn't just an app, but a product paradigm of "Agent + Skill + Connector + Deliverables + Human Verification".
Let's start with the first discovery. Claude for Financial Services' product structure is actually quite simple: Agents handle end-to-end tasks, Skills refine professional financial processes, Connectors access financial data and internal enterprise systems, and Excel, PowerPoint, and Word deliver the final deliverables. In addition, permissions, referencing, auditing, and manual review ensure that financial institutions can use it.
In the past, financial AI took the form of asking a question and receiving an answer from AI. But what financial institutions truly need is a deliverable: you give me a pile of data, and I want a document that can be reviewed, cited, archived, and integrated into their business systems. The difference between these two is enormous. The value of financial AI lies in the deliverable, not in the chat window.
Another noteworthy change is that domestic financial institutions are no longer in a wait-and-see mode.
From 2025 to 2026, I observed that the implementation progress can be roughly divided into three tiers. Banks are moving the fastest; China Construction Bank completed its private deployment of DeepSeek, covering hundreds of scenarios. CITIC Securities Investment Fund used DeepSeek for REITs due diligence, reducing the workload of 5 employees for 70 days to 1 person for 10 days—an efficiency improvement of 30 times.
Securities firms and PICC Property & Casualty Insurance have also followed suit. CITIC Securities provides investment advisory services based on multi-agent technology, PICC Property & Casualty Insurance has integrated with DeepSeek to build a professional knowledge base, and Ping An's big data model has been called 818 million times in six months.
But what's truly interesting is the third tier—PE, asset management, and wealth management. They have abundant data, ample budgets, and significant delivery pressures, yet most are still in the Proof-of-Concept (POC) stage. This isn't about being behind the times; it's about the window of opportunity for startups.
When it comes to startups entering this market, many people's first thought is to create a financial version of ChatGPT. However, this is a very risky endeavor, as it will encounter three types of formidable competitors simultaneously.
Model vendors will make general-purpose capabilities increasingly cheaper. Financial data terminals like Wind, Choice, iFinD, and Tonghuashun already have data and user access points; once AI is embedded, it's difficult to charge independently for general financial Q&A. Large financial institutions prefer to build their own internal AI platforms, integrating general-purpose capabilities into their own permission systems.
Startups are fighting head-on, but are attacked from three fronts.
However, if you change your perspective and look beyond the entry point to the operational layer, the situation changes. What is a vertical operational layer? It's about deeply integrating AI around a specific role, a specific process, and a specific deliverable. Examples include structuring PE/investment banking due diligence materials, auditing Excel financial models, initial review of loan approval materials, automatic generation of compliance review forms, auxiliary review of insurance claims and underwriting materials, and automatic compilation of client manager meeting minutes.
These directions may not seem as grand as the "big financial model," but they are closer to the client's budget.
What kinds of products are worth making?
In summary, four conditions must be met simultaneously.
Able to receive data
Truly high-value scenarios often involve handling internal client documents, CRM systems, cloud storage, emails, contracts, and approval systems. Simply processing public web pages offers very limited value.
Runnable process
Financial users won't change their work habits for AI. Products need to be integrated into their existing systems like Excel, PowerPoint, Lark, WeChat Work, DingTalk, WPS, and CRM.
Documents can be delivered
Financial institutions don't pay for answers, they pay for materials. They are only willing to pay if the applicant can provide review forms, memos, decks, and Excel spreadsheets.
Leave room for boundaries of responsibility
AI must support referencing, logging, permissions, auditing, and human review. It should not provide investment advice, automate transactions, or replace final approval.
If any one of these four conditions is missing, it will be difficult for the product to enter a real production environment.
If we broaden our perspective and look at the next 24 months, I think there are seven sub-sectors that deserve the most attention.
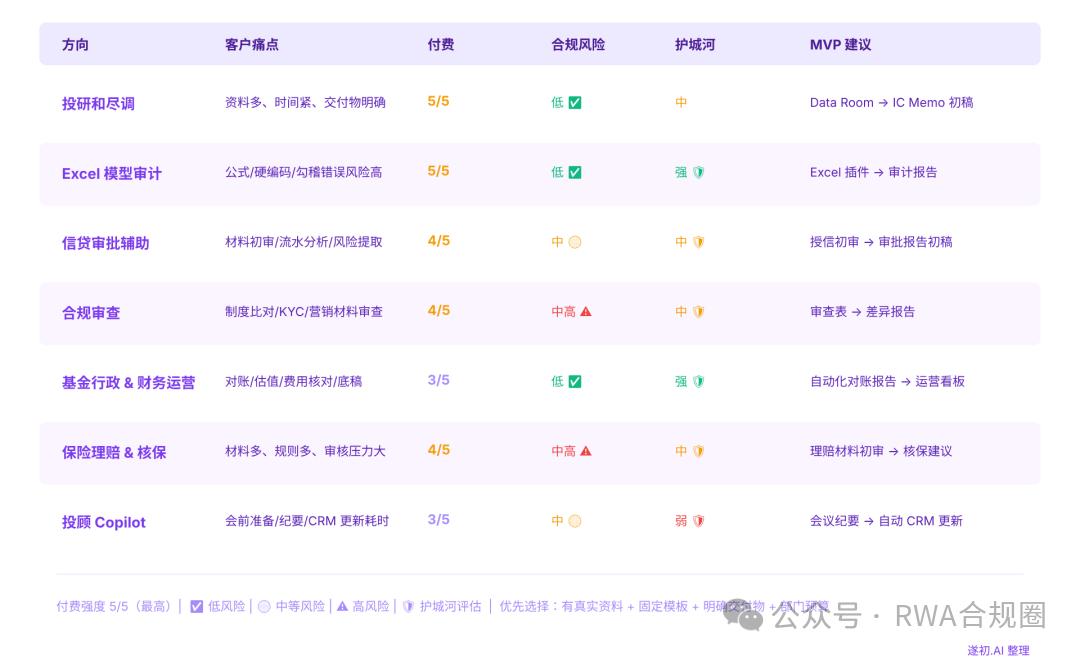
Investment research and due diligence are ranked first. With abundant data, tight deadlines, and clearly defined deliverables, this is the approach closest to Hebbia and Rogo.
Secondly, there's the auditing of Excel models —investment banks, private equity firms, credit firms, and asset management firms all have a large number of Excel files containing formula errors, hard-coded data, and inconsistent assumptions, leaving ample room for AI assistance.
Credit approval assistance ranks third, as both banks and non-bank financial institutions require initial review of materials, transaction analysis, risk assessment, and credit report generation. Compliance review ranks fourth, with system comparison, marketing material review, and KYC checks all suitable for use as referable and traceable AI assistants.
Fund administration and financial operations involve highly procedural processes for reconciliation, valuation, expense verification, and audit working papers, and errors in these processes are costly.
Insurance claims and underwriting involve numerous documents, rules, and significant review pressure, yet manual confirmation is essential.
Finally, there's the account manager and investment advisor Copilot. Instead of AI directly providing investment advice, Copilot helps advisors with pre-meeting preparation, product explanations, meeting minutes, and CRM updates.
These seven directions share a common premise: the product must be auditable, referable, and privatable.
Financial institutions won't accept "AI, roughly speaking." Where does the data come from? Where is it referenced? Who reviewed it? Has the data left the domain? These are prerequisites for procurement decisions. Therefore, from the very beginning, citation traceability, manual approval, data isolation, and operational logs must be designed. This isn't a compliance cost; it's a product barrier.
There's an even bigger trend. Once model capabilities are commoditized, opportunities will shift to workflows, connectors, and governance layers. Just as cloud computing turned IT infrastructure into APIs, a new generation of entrepreneurs built SaaS on top of it. The same applies to today's large models—whoever can encapsulate industry workflows on top of them will create a competitive advantage.
The financial industry's knowledge work is characterized by high information density, stringent formatting requirements, and strong accountability. These characteristics mean that it cannot be quickly covered by general AI. This is precisely the safe zone for startups.
How can startups get started?
Don't build a platform from the start.
Find a narrow scenario : with real data, a fixed template, clear deliverables, manual review, departmental budget, and the ability to verify ROI within 60-90 days.
Don't say that:
I want to create an AI platform for financial institutions.
It should be said like this:
I first helped the PE/FA team automatically structure the Data Room data, outputting due diligence Q&A, risk list, and initial draft of IC Memo.
The more specific the information, the easier it is to close a deal.
The biggest risk is being replaced by a major company?
General entry points will be replaced. General financial Q&A, ordinary research report summaries, and simple data queries can easily be overtaken by large models and data terminals.
However, this does not apply to vertical deep processes.
Because large companies are unwilling to do the dirty work for every specific role. The real challenge lies in: integrating with the client's internal systems, understanding job processes, adapting to client templates, and accompanying the client from POC to production.
These are issues that a single model API cannot resolve automatically.