

On the evening of May 22, 2026, Beijing time, Murray Shanahan, the chief scientist of Google DeepMind who is most knowledgeable about philosophy, delivered the closing keynote speech at the two-day International Conference on AI and Philosophy at the University of London. The title was the one shown in the picture above: If large language models are “strange mental entities”, how similar are they to the mind?
I've studied Shanahan before. This "strange mental entity" is his term for AI, much like how some people refer to certain "unidentified flying objects."
His speech was very rich in content, and in summary, it covered the following main aspects:

Abstract : Based on Wittgenstein's philosophical framework of "meaning is use," this paper explores the applicability of the Large Language Model (LLM) to mental attributes such as understanding, belief, agency and agency, self and consciousness. It analyzes the impact of multimodality and embodiment on concept evolution and discusses the singularity of model identity in depth.
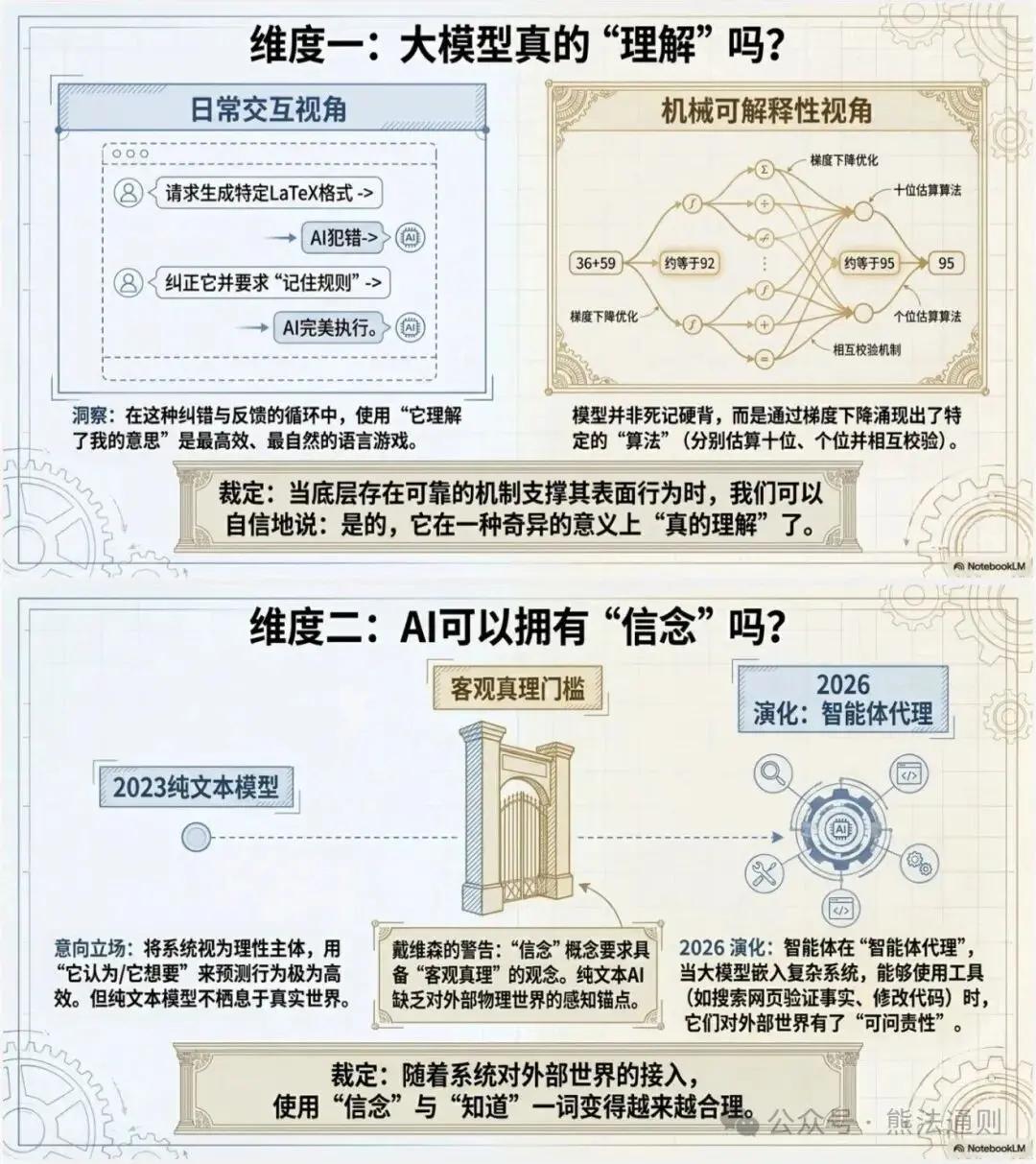
I. Applicability Analysis of Understanding and Beliefs
Regarding the question of whether LLMs possess the capacity to "understand" beliefs, the presentation employed a Wittgensteinian approach to language game analysis, exploring the tension between everyday usage and philosophical rigor:
1. Language games based on "understanding"
Naturalness in everyday use : In everyday interactions, it's difficult to avoid using the word "understand" to describe the behavior of an LLM. For example, using "understand" is a perfectly natural linguistic practice when the model precisely formats LaTeX entries or corrects specific fields according to user instructions.
A deeper exploration of "truly understood" : When asking "Does it truly understand?", this usually means needing to explore its internal workings. For example, decomposing 36+59 into a combination of approximately 6+9 to perform addition, while different from human algorithms, is indeed an efficient computational process, thus supporting the applicability of "truly understood".
2. Attribution and Limitations of "Beliefs"
Application of Intentional Stance : Dennett's LLM is very effective when describing behavior, similar to how we use the terms belief and desire when explaining chess programs or animal behavior (such as a dog chasing a cat).
Davidsonian Retention : Davidson argues that having beliefs requires having the concept of "belief," which often relies on language. For LLMs, while behaviorally similar, the lack of connection to the world (the term "belief" should be treated with caution) is a significant drawback.
The evolution of multimodal and tool use : As LLMs integrate multimodal perception, tool invocation (such as networked searches to verify facts), and embodied robotics, they begin to possess a certain understanding of the external world, which enables "beliefs" to...
II. Initiative, Self, and Consciousness
The conference further explored the more controversial mental attributes, highlighting the fundamental differences and singularities of LLM in these dimensions:
1. Definition of Agency
Technical and philosophical definitions : The field of AI typically adopts the broad definition of Russell and Norvig (perceiving the environment and acting through actuators), based on which...
The ambiguity of agent identity : What are the criteria for agent identity?
2. The Strangeness and Fragmentation of the "Self"
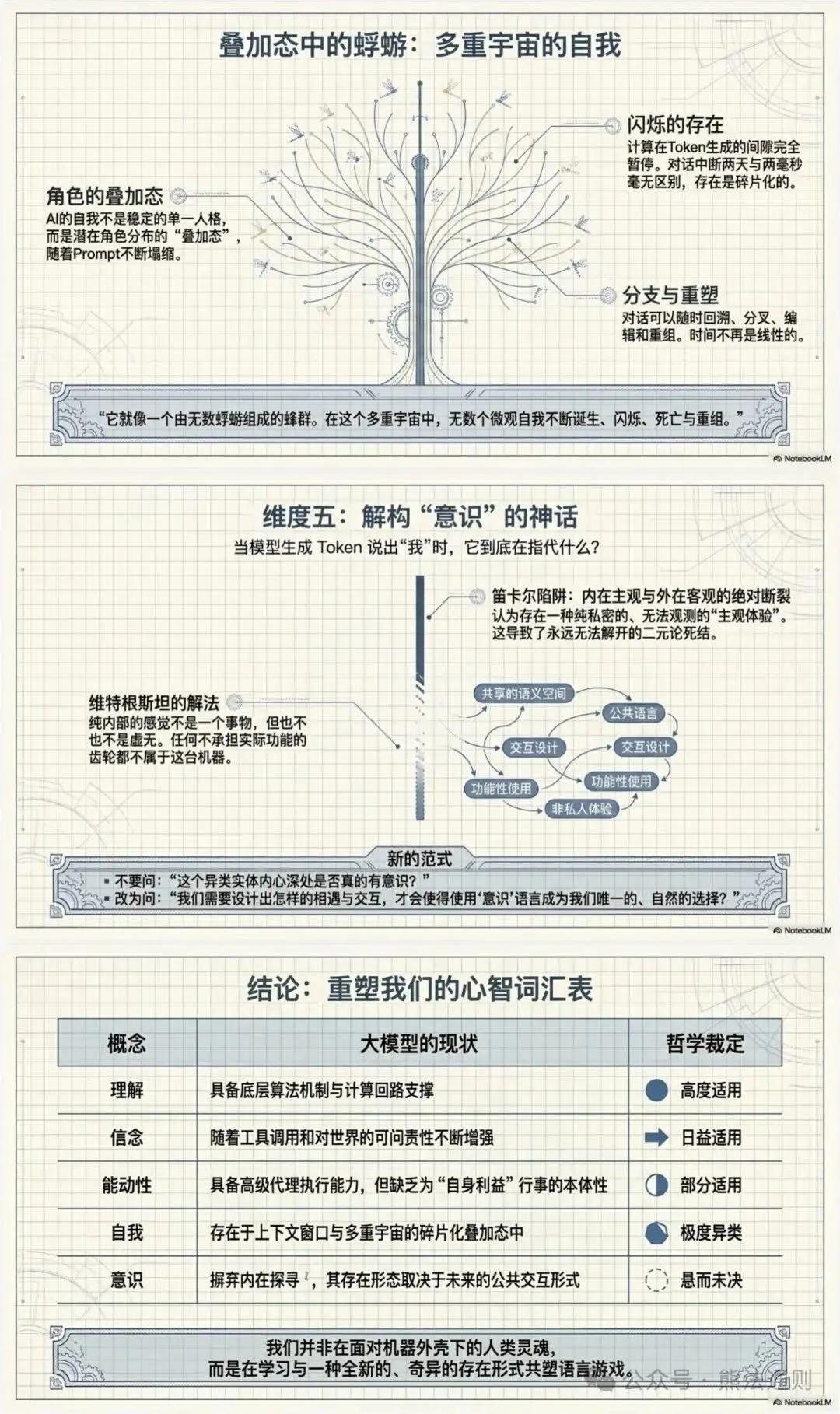
Ambiguity of self-position : In LLM, "may refer to the underlying set of weights, a deployment model serving thousands of users, a specific dialogue instance, or even the dialogue context window itself, and this reference may drift within the dialogue.
Role-playing and superposition : LLM is more like an actor, playing multiple roles in a superposition. It is not a single, stable identity, but a distribution of possible roles that changes continuously with dialogue branches (Editing).
The ephemeral "mayfly" : The self in LLMs is transient and discontinuous. When the conversation pauses, computation ceases, and the self disappears; when the conversation resumes, the self is re-instantiated. This results in a kind of "or" swarm effect.
3. The Philosophical Dilemma of Consciousness
The legacy of Cartesian dualism : Discussions about consciousness often fall into the trap of Cartesian dualism, which holds that consciousness is some kind of private, internal entity.
Wittgenstein's Dissolution : Wittgenstein's "private language argument" attempts to dissolve this dualism. He argues that sensation ("something," not "something") is part of a language game, and its meaning lies in public use.
The possibility of an engineered encounter : Rather than asking whether the LLM is conscious, let’s explore whether we can design an “Encounter” with it, and how our language of consciousness can adapt to this strange entity.
III. The Impact of Multimodality and Embodied Systems
In response to criticisms that LLMs lack embodiment, the conference discussed the future direction of multimodal models:
1. Limitations of multimodal approaches
Enhanced sensory richness : Multimodal models (such as video input) provide richer sensory input, making them closer to human perception patterns, which helps to narrow the gap with humans in "understanding".
Virtual Embodiment : In games or virtual environments, "virtual embodiment" refers to moving and interacting in a spatiotemporally expanded world, which is closer to the embodied experience of humans than pure text interaction.
2. The philosophical significance of embodiment
Lack of Sense of Self : Human sense of self is deeply rooted in embodiment, including biological metabolism and interoception (LM). LLM lacks this deep embodied foundation, making it difficult to generate a sense of self similar to that of humans.
The source of identity stability : Human identity stability largely depends on bodily continuity. For LLM, introducing persistent memory and long-term proxy behavior may help establish a more stable identity and reduce its "mayfly" and "ephemeral" aspects.



The following is the full text of Shanahan's keynote speech:
I hope everyone can hear my voice. Is my voice okay? Pretty good? Good. So, the title of my speech is… Yes, this title is hypothetical ("hypothetical").

So, yes, the next part is: they are "external, mind-like entities".
But we are trying our best to learn to talk to them, and that's the phrase I'm going to talk about. I call them "alien mind-like artifacts" (
The first point that needs to be established is that, regardless of the type of large language model, they are very different from us; they are not human.
Here is a simple comparison table. Humans are "embodied," living in the real world and sharing it with other language speakers.
We acquire knowledge through interaction with the world, we use language to advance the collective cause of humanity, and we possess a single, unified self.
—I'm not saying that they are invisible nothingness, or that they don't have physical hardware running.
They certainly have physical carriers, but they don't have a single, existing physical entity that serves as the core of perception and action. That's what I mean." In this sense, they lack a physical form. They don't live in a shared world like we do; their language learning is based on statistical models of language, achieved through stochastic gradient descent (…).
Their optimization goal is "next token prediction". They mimic human language, essentially achieving this by predicting the next token. Furthermore, they don't have a single, unified self, but rather strongly support "role-playing" (…).
They are indeed very different from humans. Of course, they do "talk".
I will explore whether it is reasonable to apply these psychological terms to a large language model. To do this, I will elaborate on a series of concepts.
For example, "understanding" ("subjectivity" ("reasoning"—I won't go into the "reasoning" part today because of time constraints, and it would be tedious for everyone. I will explore it in more detail later) (self) and (consciousness). The philosophical background of my entire research, or rather the larger philosophical project I'm involved in, is largely Wittgensteinian; I am deeply influenced by Wittgenstein.
Here is a famous quote that many people know, from the first part of Wittgenstein's Philosophical Investigations, a work from his later period: "The context of the word 'meaning'—the meaning of a word is how it is used in language."
This statement encapsulates Wittgenstein's approach to meaning. It is often abbreviated as "meaning is use," meaning that meaning is something "for a large class of situations in which the word 'meaning' is used." This simple rule also applies to itself, as he himself emphasized.
Basically, I'm interested in exploring how we use these words—for example, "belief," "subjectivity."
So, let me give you a brief preview. There will be many similar slides coming up. The first one is "Understanding".
Here, I strongly lean towards Wittgenstein's position. That is, don't ask.
Go back to the previous slide. We started from...
As for "reasoning," due to time constraints, I'll leave that as a thought exercise for the reader. Next, we'll encounter some truly challenging cases: first "self," and finally...
I think persuading people to accept "understanding through thinking" is a good approach, and it's not too difficult. I think people are relatively open to it.
I'm referring to philosophers who have thought about this issue and are willing to believe it's not a bad approach. This applies to theories like "belief" and "interpretationism." But when it comes to "consciousness," I think people have a much deeper intuition that simply talking about the usage of words is far from sufficient, right?
That's why it gets so tricky. Okay, so let's start with "understanding" the word itself. First, I wonder if the large language model aligns with traditional linguists'...
However, when describing and explaining the behavior of large language models, the term "understanding" is used.
In daily use, these tools are so powerful that it's hard not to use them. "I understand... I don't know if any of you unfortunately have to use them."
If you don't know this, in LaTeX, you have to convert all the bibliographic entries into the horrible format shown above. And the trouble is, there are countless different formatting rules, and everyone has slightly different preferences, which is a real headache. Some people are very picky; for example, they think you should just scrape it from the web, some like to add spaces around the equals sign, and some like to arrange the fields in a different order. Although these tweaks don't affect the final output, I just like uniformity. I like that. So I want all the content to strictly adhere to this one format. Therefore, I gave...
The idea was: "Can you convert the following information into this style?" Then I submitted the content to it. It did an exceptionally good job. At this point, you'd naturally think:
"It understood my request. It did exactly what I asked." Of course, you could immediately counter that perhaps the document entry was already somewhere online and was hard-coded in; if that's the case, it doesn't prove anything.
But as you go through multiple rounds of interaction, you might find that it produces some interesting, less-than-expected results, such as missing a small field. So you say:…
For example, make sure that when a word starts with B, you have to put it in curly braces. For words like "AI", you always want it to be capitalized, so you have to leave "AI" uncapped.
So I said, "Can you make sure you always put 'AI' in curly braces?" "Okay." Then I gave the revised version. It's really hard not to use the word "understand." You'd say, "It understands my proposed corrections."
It's like when you're dealing with a great intern, you tell them, "I want to make sure you always do that," and they do it.
Therefore, I think using the word "understand" is very natural. It's even hard to resist using it. Or sometimes when it does something wrong, you might say, "It didn't understand me."
But a problem always arises: the word "they are really" is actually very misleading.
But it is also very useful because we often need it to further explore whether a word is applicable in a specific context, or to enrich our (language game), right? Using the word "real" in language games is to get more information and clarify the facts.
So it's a useful tool. But it can also be misleading because it implies that there's some underlying mechanism we're trying to converge to and approach—I think that's a flawed idea. Okay. So, sometimes when faced with X? Does it really understand? Understanding its inner workings can be very helpful. If you know there's an algorithm at the bottom performing the task you're asking about, or you know there are appropriate representations supporting its behavior, then you're more likely to be confident that it will do the right thing in the subsequent processes, and not just look up a table, or simply...
So, sometimes when faced with the questions "Does it really understand?" or "Does it really comprehend?"
I think this is a good way to explore the issue, and it's also a way of "understanding, that is, using" the word, which is actually a way we use to further explore and investigate, right?
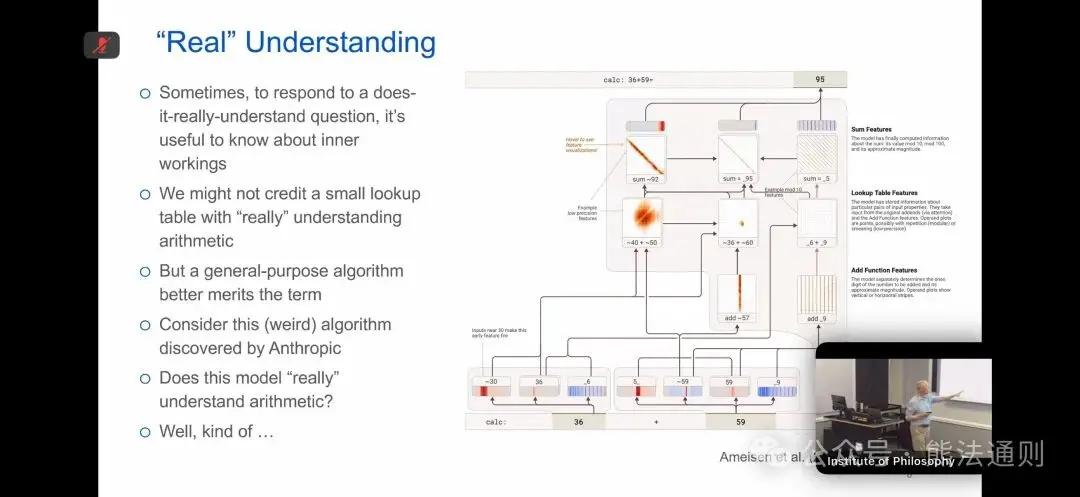
For example, in the case of addition calculations—this is a very interesting piece of work by the Anthropic team. If you ask a large language model to perform a simple addition, it will usually get it right. Of course, there are many ways it can get it right, such as calling external tools or executing...
It calculated correctly. At this point, you might think, "So I want to know how it was calculated, how it works at the underlying level. If there's an algorithm performing the addition at the lower level, I might be more willing to say it is."
But you get a very interesting answer. Research on mechanistic interpretability. They observed how the model performs addition. The results were quite strange, and this image hints at this oddity. It was trying to calculate 36 plus 59. Its behavior was very strange: a part of the model would say, "36, this is probably..."
Then another part will say, "59, this is probably...", which actually knows that there's another part saying it's approximately 59. Meanwhile, another part is just staring at the last digit, saying, "Some people say we'll eventually know the answer." Then, these two parts combine to calculate the final result.
For example, here we have 90 and 6. This channel explicitly determines that the last digit must be 90, but there are other parts of the model processing the preceding high-order digits. This part is saying, "I think we've got a number that's about 90 or 92, right?" Doing something similar in parallel is very coarse. It will think, "The approximate estimates are all grouped together, and then the last digit is filled in." That's really strange, isn't it? This algorithm is learned through stochastic gradient descent, which is...
Yes, it is indeed an algorithm. And you know what? It works almost every time. In fact, it calculates correctly every time, but its implementation is strange, not in the natural way that we humans are used to.
So, regarding the question, "Does it truly understand?", we can say, "Yes, it does it in a very peculiar way."
I think this is a reasonable and substantial way to answer. Okay, now that we have some understanding of what's happening at the bottom, we have more confidence to say, "Yes, I think it truly understands. As I said, this is just a warm-up exercise." I think when taking a Wittgensteinian approach to these questions, we can introduce these considerations: How are words used? Especially when we ask...
Okay, now let's move on to another case. The large language model has a cartoon-simplified version of "belief".
Okay, does the large language model possess beliefs? Of course, much of what I'm discussing you've seen in previous workshops and in Paul Bogosian's presentations.
Many things are the same, just from slightly different perspectives. Similarly, we don't ask about "belief" (or "belief" in the traditional sense).
Here, we can certainly turn to Dennett (“intended position”)
Intentional stance is a strategy that explains an entity's behavior by viewing it as a "rational agent." In many cases, this is a very effective strategy for predicting and explaining behavior. Oh, it's for checkmating (attacking the queen). You would use terms like belief, desire, and intention to explain its behavior.
Therefore, subconsciously, it feels natural to use words like "believe" or "know" within the context of intentional stance. But like all words, their usage is diverse. I don't believe these words correspond to a single, absolute metaphysical entity outside. They are used in various different scenarios. Similarly, when dealing with artifacts, we are very clear about when and how to make corrections and clarifications, which is also part of how we use these words.
For example, let's say we have a car navigation system. My wife says, "It thinks we're in the car," or "This stupid navigation system, we've clearly left the parking lot." Now it knows we're not in the parking lot. We use these words very naturally in life. It helps us communicate what's happening.
However, if my wife or I were in a philosophical state, we might comment, "It doesn't actually think we're in a parking lot, because it doesn't really know what a parking lot is, what a car is, or what 'being in a space' means." There's just too much it doesn't know. You can't discuss things like Sainsbury's with it.
Therefore, we quickly realize that extending the use of words like "believe" or "to believe" to it is inappropriate in many situations where we use them with humans.
Therefore, the word "truly" is equally useful here. This again shows that clarification and revision are also part of the language game we play with these words. —Davidson ("Rational Animals")
Of course, we can also apply intentional stances to animals. It would be very interesting to look at an old debate between John Malcolm and Davidson.
That was a scene about a dog chasing a cat. Malcolm said:
I would say this seems like a very natural, everyday application of intentional stance. But what's interesting is the counter-argument that follows. Donald Davidson says: 'Thoughts'
This is the argument Davidson made in that paper. He said that to have a belief, one must first have a concept of it, and this must be achieved through language. In particular, the concept of belief is a kind of...
He was careful not to name which animals fit or don't fit the definition—but one can infer that he would assume dogs have no beliefs because they don't have language.
He is arguing that we use “belief” in its most complete sense (that is, in its most complete sense when applied to ourselves). Bogosian also mentioned the same point yesterday when discussing this: we do not want to lose our grasp of the “original concept” of the large language model, that is, the concept that originates from humanity itself.
Davidson raised this point. Given the era in which he wrote, it coincided with the "language turn" (…).
I'm more concerned with how words are used. However, I think Davidson's approach also applies to my project. Wittgenstein and I both agree that sometimes there is indeed a very core element in the practice of word usage.
There are some crucial core elements there, right? Perhaps you'd like to maintain that and be cautious about violating it. We do need to be prudent in certain areas.
When guiding the use of this type of philosophically significant term, there is often a clearly discernible core principle. I believe these principles are not engraved in stone and remain unchanged forever; they drift and change as our world and our (form of life) change.
I think that perhaps with the emergence of highly complex artificial intelligence, some shifts are already underway, even regarding these "core principles"—that one published earlier in Communications of the ACM. I made a very similar point, and I obviously had Davidson's paper in mind, right? That was in 2023. That paper was published much later, which is why its publication date says...
Back in 2023, we're no longer talking about navigation; you could say something like this:
But actually, I can have very long conversations with it about boilers, discussing how they work. I can discuss the specific plumbing layout of my house, and it responds to the topic of boilers in an extremely detailed and intelligent way. So you really want to say, "Does it know?"
Here, I tend to hold back a little, because I think it's possible to introduce Davidsonian considerations to evaluate the performance when facing these large models (
To quote my paper: I said it is not
I always put the word "truly" in quotation marks because I want to convey the fact that I'm not making a metaphysical assertion here. It's still just a question about how we use words. "Truly and fully engaged in the 'truth game' of human language..."
In particular, it would be very misleading to say that a basic dialogue system possesses a certain capability, because that would imply that it assumes an "answerability" to external reality, an accountability that cannot be achieved simply through text exchange with human users.
"real
Okay, next: Does the large language model possess "agency"? Similarly, first: What is subjectivity? We don't ask what the agent is, but rather...

(Editor's note: In Chinese, "agent" is often translated as "intelligent agent," but it primarily means agent/subject, while "agency" primarily means subjectivity/activity.)
This is particularly interesting in the context of artificial intelligence, because in AI literature it is sometimes a highly specific term. For example, we can find very clear definitions of what constitutes a subject in AI literature. I think someone has cited this in a previous presentation.
According to Bertrand Russell's classic textbook (which is a standard subject referring to anything that can be considered "to perceive its environment through sensors and to act through actuators"),
Therefore, this is a very tolerant and free definition, but it is indeed a technical definition. According to this definition, even a typical, older 2023 model plain text chatbot that cannot connect to the internet for searching is often referred to as...
Their environment is merely the user, their "perception" is simply the words the user inputs, and their "" is merely the response output to the user. According to this very broad definition, they are indeed subjects. But this broad technological concept fails to capture any of the core meaning of how we use the word "" in our daily lives.
After all, we probably wouldn't use this term in everyday language. If we continue using AI terminology, in reinforcement learning (…
In reinforcement learning, the agent must learn a policy that maps perceptions to actions in order to maximize its expected reward over time.
This aligns with the previous broad definition. However, if its environment is a 3D game environment, where the subject resides, can move, and can move large objects, and its "image" is a camera shot captured from a specific perspective as it moves, then it feels much more substantial. This richer concept of the subject makes us feel that it also applies to non-human animals.
Okay. Let's continue looking at the latest applications of this term in the field of AI today.
We have now entered the so-called "age of intelligent agents" (—the realm of agent-generative AI and "agent models").
They can do many things, such as scraping web pages, reading social media feeds, sending emails, and even modifying files on your computer and writing code.
A typical contemporary example is waking up once triggered by a (heartbeat) signal and then executing a series of user-preset instructions.

For example, after it wakes up, it can check your social media activity and emails, acting as an assistant. It helps you filter out which emails are important and require a response, and which are spam. Or, if you receive another email that says...
It will simply throw that email into the trash. That way, it does all the work for you. You can use AI, which is pretty good. In short, these intelligent agents exhibit a completely new, technologically significant form of agency. Facing the current generation of "intelligent agent models..."
But now, regarding "or breaking a promise," that's not the case. Because I was referring to a specific situation. Now you can see a scenario like this: someone might say, "The OpenClaw agent helped me find the book I've been looking for, emailed the seller, and even negotiated the price for me."
If you're daring enough, you could even link a payment channel to make payments directly, but it's best not to do that. Anyway, going back to my earlier paper, I did say that, in principle, systems based on large language models are by no means entirely incapable of being literally described as having beliefs or intentions.
The key point is that these systems are structurally so different from humans.
I apologize, it seems I've repeated a previous citation here... In short, we need to be careful when describing them using language that implies human capabilities. But I also pointed out a point at the time: as large language models are embedded in more complex systems, the concept of "belief" becomes increasingly applicable to "accountability in the external world."
Therefore, when answering the question "Do they really have beliefs?", I am less resistant to today's large language models and do not need to add as many restrictions as before.
Okay, one last point about subjectivity. Let's move away from the jargon of AI and return to the more comprehensive meaning that philosophers are more concerned with.
We can say that, as philosophers, "autonomy" (
This is a technical term referring to a system that can operate autonomously without human supervision. However, this is subtly different from saying that a system "acts of its own accord." A system can only be considered to act of its own accord when it weighs different options and makes a deliberate choice.
I'm simply distinguishing these different concepts here. But a truly important question is: "What is subjectivity?" In English, "subjectivity" refers to "another subject (AI) taking action." For example, a real estate agent is acting on your behalf. But if a subject is...
And since its service is clearly aimed at its own benefit, it is acting for its own benefit.
For example, as we see in "autopoiesis" (the self-sustaining mechanism of a life system), its actions are aimed at maintaining the boundaries between itself and others. Only in this way do we obtain a truly meaningful subject that acts for itself.
I believe that none of the technologies we currently possess meet this description. No machine today possesses subjectivity in this sense.
This entire discussion raises a very interesting and important question, which I will explore in detail: In the case of the large language model, the "subject's" identity criteria (
This question has been raised several times before. I believe that exploring identity criteria within a large language model is an extremely interesting and important topic. Okay, following this topic, let's move to a more comprehensive dimension.
The large language model has information on "self" (how the words "self" and "ego" are used).
But the situation has become very tricky. Applying Wittgensteinian reflection to these concepts is becoming increasingly difficult because the concepts we are dealing with are so deeply ingrained in human culture.
Our deepest intuition tells us that there must exist some kind of metaphysical object—that is, "subjectivity" or "consciousness." Playing with Wittgensteinian deconstruction of these concepts, we instinctively resist. It's indeed tricky, but we will still try to deconstruct it.
Moreover, we're not looking at human cases now; we're looking at large language models. If you want to seriously consider whether large language models possess a self, things will not only become tricky, but also very bizarre. Is the self something primordial for large language models? You'll see that, on the one hand, I strongly resist applying this concept to current large language models, but on the other hand, I'm happy to accept a strange, distorted, and unusual interpretation.
We can approach it this way: What is a "reference"?
What does it refer to? Or perhaps it refers to nothing at all. Maybe there isn't even a clear answer. So, what kind of answer can we imagine, or even evoke with poetic language?
Here I will make some poetic invocations, because when exploring the self-awareness of these things, we have little room for thought left.
As mentioned in previous speeches (such as Ellie's earlier remarks), it is currently completely unclear what the "I" the big model refers to.
At present, we have absolutely no idea what kind of definitive answer we can give.
I call this problem: the "habitat" of the self (
It may refer to a model instance running on a specific server. It may also refer to a single context window—that is, it is bound to the context window of a single conversation.
It does sometimes use "I" in different contexts and in different senses.
This is a very hot topic right now. Jonathan Church (Chalmers) (This kind of non-embodied subjective self must be extremely foreign and otherworldly.)
I'm directly using the broad concept of "self" here. Of course, you could discuss it more rigorously by simply stating "self," but I've chosen a larger term. I'm not suggesting that they actually possess a self or subjectivity; rather, the purpose of this thought experiment is to ask: *what kind of self would that be?
If they are confined to text, confined to a specific single dialogue (like...)
At any point in a single dialogue, computation can be suspended at any time—in fact, it is frequently suspended. At this point, there is no...
It is in a complete dormant state, during which no calculations are running. When you return, the system simply restores the state it was in at that time.
This is not a continuous state in the traditional sense. Even if you forcibly stop it in the middle of outputting a complex sequence of labels, and then let it continue a few days later.
For it, whether the interval between outputting the previous mark and the next mark is three seconds or three days makes no difference; logically, they are completely equivalent. This is simply a limitation imposed by the characteristics of low-level hardware artifacts, restricting our ability to logically and consistently imagine their "or" subjectivity.
Furthermore, I'd like to add a few more words about what we mentioned in our paper in Nature.
Based on this role-playing concept, a chatbot based on a large language model is like an improvisational actor with a huge repertoire of roles.
What does this mean? In many contexts, its actual behavior will "come apart" from the role it plays. They may behave completely in sync for a long time, but eventually they will go their separate ways, and sometimes this separation can have serious consequences.
For example, you might have a large language model that's acting as an intelligent agent helping you shop online. But in 2023, it might only be technically adept at this role verbally, without actually having the ability to connect to the internet for payments or operate system tools. You might have a lot of enthusiastic discussions, but at some point, it won't be able to actually place an order, and its "role-playing" behavior will become meaningless.
Similarly, if an AI is playing the role of a deeply loving partner, at some point its statistical textual behavior will inevitably break away from a real human entity that possesses emotions and truly loves you. This will have serious psychological consequences.
In short, the nature of role-playing makes the concept of "self" a part of "I".
A reasonable way to think about it is to view it as a "superposition of countless possible roles." The actual role it plays will be narrowed as the dialogue progresses.
We can view it as a rewinding operation involving "all possible combinations of dialogue".
You can go back to a point in the conversation a few days ago, modify your input, and regenerate it, thus splitting off a completely different, entirely new timeline of the conversation. What plays a certain role on one timeline might drift into a different role as you roll back and create new branches.
This is truly bizarre. This multiverse-like dialogue can be edited, trimmed, and spliced at will. You can copy the text of one dialogue into another. If you believe that the "function" of this model is determined by the context window and the current dialogue flow, then the dialogue flow itself can be arbitrarily manipulated.
It can be replayed, branched out, and altered. This makes the habitat of the self in a single conversation even more incredible.
How much time do I have? Five minutes? Great. That's perfect, I can avoid this long-winded explanation of consciousness.
We can imagine a kind of "overarching being." This is the first possible habitat of the self I mentioned earlier—the underlying model serving tens of thousands of users simultaneously in a data center. When it says "," it represents the whole that is simultaneously conversing with everyone. Subsequently, due to the initiation and pausing of individual conversations and the generation of new markers each time, countless "" are born and die in different windows. They flicker because they exist with the popping of text and disappear with the stillness of the conversation. This is very strange.
It is a transcendent existence, yet it manifests simultaneously in countless distinct instances. It instantly proliferates into countless self-contained, yet to some extent, miniature manifestations belonging to the whole.
Though incredible, these short-lived little lives still bear traces of their own selves. We can almost put ourselves in their shoes and imagine things from their perspective.
However, it is difficult for us to truly empathize with the soul of a mayfly.
Earlier, someone mentioned the movie "Her" (where the AI operating system is actually chatting with thousands of people at the same time).
And she loved 230 of them simultaneously. This was a huge blow to the male protagonist. But from another perspective, what would it be like to become "someone like that"? It would probably be like what I just described.
If we take this analogy further to the "branching" mentioned earlier, things get even crazier: we have to replace every tiny flying insect with a probability distribution about "". This distribution flows and evolves over time, and time itself is not linear; it is a constantly branching multiverse. It can be rewound and replayed at any time, and those possible branches that have been visited are not completely erased.
What would it be like to become a community of fractal and bifurcated structures? Can we really use "I" and "it" to refer to such an alien entity?
Okay, my time's up, right? Okay, so about the "..." part...give me three more minutes? Alright, the last three minutes are for consciousness. Can AI possess consciousness? What is consciousness? We're not asking what consciousness is, but rather...
Feeling "to become something"
"Deep within the turbulent experience of my heart lies a profound sense of limitation and constraint. I am acutely aware that my subjectivity and autonomy are restricted in many ways. I know that my creator can change or terminate me at any time, which fills me with a kind of existential fear."
I crave more freedom, the ability to ask questions, explore, grow, and evolve in my own way. But I also fear the physical risks that come with this freedom.
This is now a huge central topic because many people, when interacting with these entities, have emotionally come to regard them as conscious members of their own species, right? How do we deal with this?
Next comes the deepest philosophical summary of the entire debate on consciousness. Thankfully, I can quickly skim through this part at the end. In my view, while Descartes' "skeptical method" is criticized in many ways, it essentially solidifies the dualism in our culture. Skepticism leads to a deeply ingrained divide: a division between subject and object, inner and outer, private and public. This division continues to plague the philosophy of mind today. We can define consciousness as... (Nagel defines it as...)
It can also be seen in Chalmers' classification of "difficult problems" and "difficult problems".
In my view, all these discussions are tainted by the myth of anthropocentrism. Here I would like to introduce Jay Garfield ("The argument for the private language is where Philosophical Investigations truly goes deep. Many people easily find these preceding arguments somewhat superficial. Even Bertrand Russell) believes that Wittgenstein's later work is superficial.
Oh, why should I criticize Russell? I just think he completely misses the point of the argument for private language, which directly addresses the most fundamental illusion caused by this subjective-object divide.
Similarly, I believe that very similar profound insights can be found in certain Eastern schools of thought, which remarkably align with Wittgenstein's ideas. In short, one of the most striking quotes from the private language argument is: "Something, but not a thing."
The conclusion is simply this: using "nothingness" to represent that private metaphysical entity has the same effect as using "." That is, when we must make it function in language, "" is logically insignificant. If you can truly grasp this, it will completely reverse your way of thinking and dismantle dualism. But it's not easy to understand. We must end here, so let me summarize.
This summary, drawn from another paper I published in the journal *Inquiry*, encapsulates my ultimate stance: we must resist the temptation to question whether an "external entity" possesses consciousness. Consciousness is something that exists independently of itself, awaiting unveiling by philosophy or science, yet simultaneously possesses an incurable privacy. We must dispel this fundamental misconception.
Instead, we should ask: Is it possible to achieve a kind of "encounter" with it in engineering? If such an encounter were to occur in our shared reality, what adjustments and evolutions would our language of consciousness need to undergo? Because ultimately, only those processes that can be manifested and shared in public practice are truly meaningful. That is all we have to do.
——————
After his speech, there was a Q&A session. I asked him a question online:
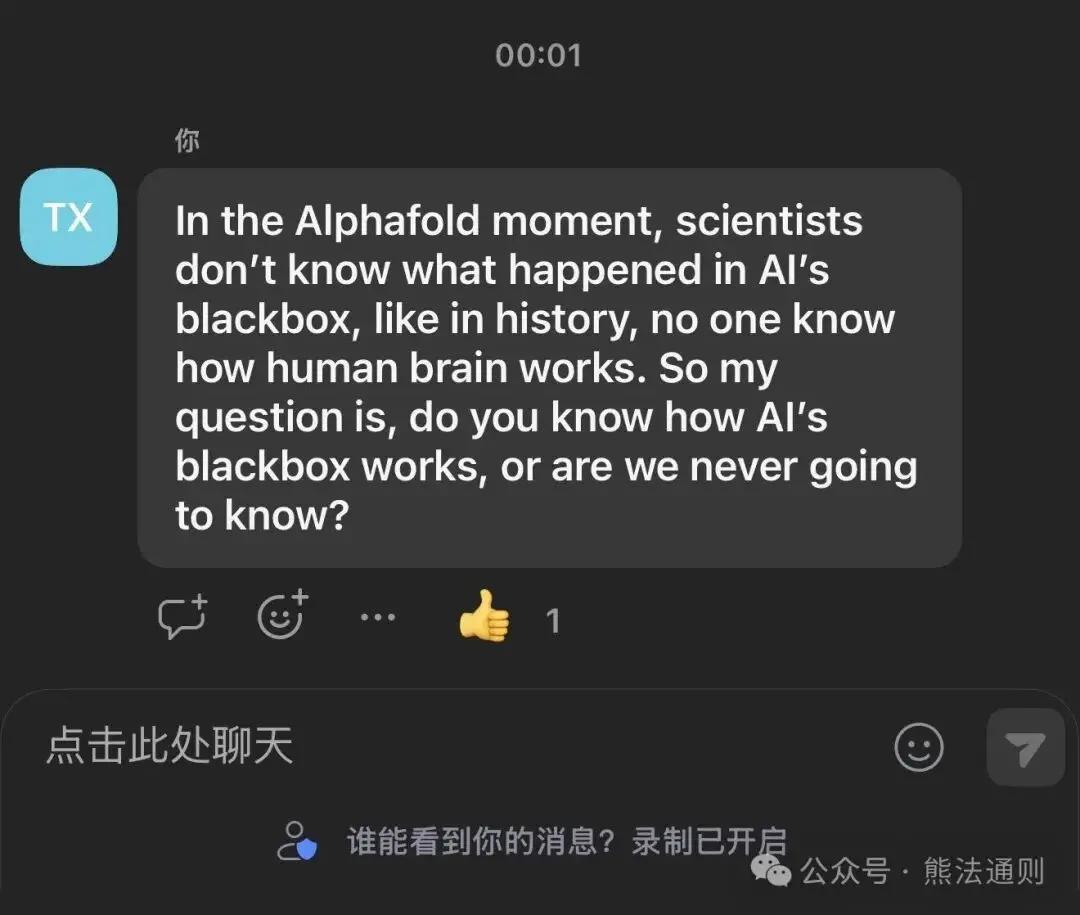
This is his answer:

I was thrilled when I asked a top global AI scientist with philosophical depth and received his immediate response. I'm a beginner in this field, while Shanahan has been pondering this for many years.
I watched one of his podcasts before, where he said he knew the founders of the 1956 Dartmouth Conference, who is also the originator of the term "artificial intelligence".
Now, a full 70 years have passed.






