Tang Jie (@jietang) is a professor at Tsinghua University and the chief AI scientist at Zhipu (the company behind the GLM series models), and one of the most knowledgeable people about large-scale models in China. He recently posted a long Weibo post (see comments) discussing his insights on large-scale models in 2025.
Interestingly, Tang Jie and Andrej Karpathy's observations resonate with each other, but also have some different emphases. Looking at the perspectives of these two top experts side-by-side reveals a more complete picture.
The content is quite long, but I want to highlight one sentence at the beginning:
> The first principle of AI model application should not be creating new apps; its essence is AGI replacing human work. Therefore, developing AI that replaces different jobs is key to application.
If you are developing AI applications, you should repeatedly consider this sentence: The first principle of AI application is not creating new products, but replacing human work. Once you understand this, the priorities of many things become clear.
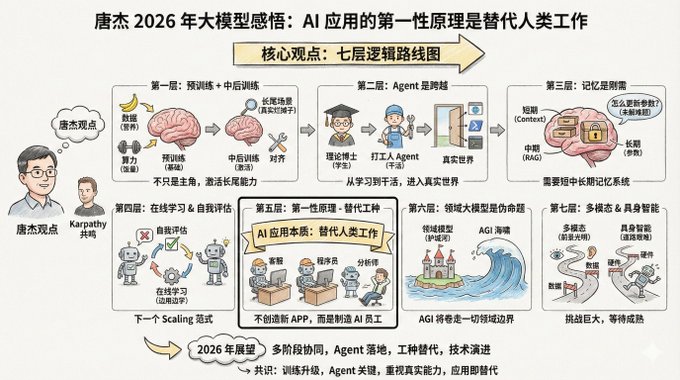
Tang Jie's core viewpoint has seven layers of logic.
--- Layer 1: Pre-training Isn't Dead, It's Just No Longer the Sole Protagonist
Pre-training remains the foundation for models to acquire world knowledge and basic reasoning abilities.
More data, larger parameters, and more saturated computation are still the most efficient ways to improve a model's intelligence. This is like a growing child; their food intake (computing power) and nutrition (data) must be sufficient—this is a physical law that cannot be circumvented.
But intelligence alone isn't enough. Current models have a problem: they tend to be "unbalanced." To improve benchmark scores, many models focus on specific problems, leading to poor performance in complex real-world scenarios. This is like a child who, after completing nine years of compulsory education (pre-training), must be thrown into the real workplace to intern and handle the messes not covered in textbooks—that's where real skills are developed.
Therefore, the next focus is on "mid and post training." These two stages are responsible for "activating" the model's capabilities, especially its ability to align with long-tail scenarios.
What are long-tail scenarios? They are those uncommon but real needs. For example, helping lawyers organize special contracts or helping doctors analyze images of rare diseases. These scenarios represent a small percentage of the general test set, but are crucial in real-world applications.
General benchmarks evaluate model performance, but they can also lead to overfitting in many models. This aligns with Karpathy's view that "training on the test set is a new art." Everyone is trying to climb the leaderboard, but a high score doesn't equate to solving real-world problems.
--- Second Layer: Agents represent the leap from "student" to "worker"
Tang Jie used a vivid analogy:
> Without agent capabilities, a large model is just a "theoretical PhD." No matter how many books someone reads, even reaching a PhD level, if they can't solve problems, they're merely a container of knowledge, unable to generate productivity.
This analogy is accurate. Pre-training is like attending classes, and reinforcement learning is like practicing problems, but these are still in the "learning stage." Agents are the key to making the model truly "work," the threshold for entering the real world and generating practical value.
Generalization and transfer across different agent environments are not easy. The skills you develop in a code environment may not work well in a browser environment. The simplest approach now is to continuously accumulate data from more environments and perform reinforcement learning for different environments.
Previously, when we developed agents, we plugged various tools into the model. The current trend is to directly embed the data from using these tools into the model's "DNA" for training.
This sounds a bit cumbersome, but it's indeed the most effective path right now.
Karlpathy also listed agents as one of the most important changes this year. Using Claude Code as an example, he emphasized that agents should be able to "live in your computer," calling tools, executing loops, and solving complex problems.
--- Third Layer: Memory is a Basic Need, but How to Implement It Isn't Clear Yet
Tang Jie devoted considerable space to discussing memory. He believes that memory capability is essential for models to be effective in real-world environments.
He divides human memory into four layers:
- Short-term memory, corresponding to the prefrontal cortex
- Medium-term memory, corresponding to the hippocampus
- Long-term memory, distributed in the cerebral cortex
- Human historical memory, corresponding to Wikipedia and historical records
AI also needs to mimic this mechanism. Large-scale models might correspond to:
- Context window → Short-term memory
- RAG retrieval → Medium-term memory
- Model parameters → Long-term memory
One approach is "compressed memory," storing important information concisely within the context. Current "ultra-long contexts" only address short-term memory, essentially lengthening the usable "sticky notes." If the context window is long enough in the future, short, medium, and long-term memory may all be achievable.
But there's a more difficult problem: how to update the model's own knowledge? How to modify the parameters? This remains an unsolved problem.
--- Fourth layer: Online learning and self-assessment, possibly the next Scaling paradigm
This section is the most forward-looking part of Tang Jie's viewpoint.
Current models are "offline," meaning they remain unchanged after training. This presents several problems: the model cannot truly iterate on its own, retraining wastes resources and results in the loss of a lot of interactive data.
Ideally, the model could learn online, becoming smarter with each use.
However, achieving this requires a prerequisite: the model must know whether it is correct or not. This is "self-evaluation." If the model can judge the quality of its output, even probabilistically, it knows its optimization objective and can improve itself.
Tang Jie believes that building a model's self-evaluation mechanism is a difficult problem, but it may also be the direction for the next scaling paradigm. He used several terms: continuous learning, real-time learning, and online learning.
This echoes Karpathy's mention of RLVR. RLVR is effective precisely because it has "verifiable rewards," allowing the model to know whether it is correct or not. If this mechanism can generalize to more scenarios, online learning may become a possibility.
--- Fifth Layer: The First Principle of AI Applications is "Job Replacement"
This is the sentence that inspired me the most:
> The first principle of AI model application shouldn't be creating new apps; its essence is AGI replacing human work. Therefore, developing AI that replaces different jobs is key to its application.
The essence of AI is not creating new apps, but replacing human work.
Two paths:
1. AI-enable software that previously required human intervention.
2. Create AI software aligned with a specific human job, directly replacing human work.
Chat has already partially replaced search and also incorporated emotional interaction. The next step is to replace customer service, junior programmers, and data analysts.
Therefore, the breakthrough point in 2026 lies in "AI replacing different jobs."
Entrepreneurs should not think about "what software I want to develop for users," but rather "what kind of AI employee I want to create to help the boss cut labor costs for a certain position."
In other words, don't always think about creating a new "AI+X" product; first think about which human jobs can be replaced, and then work backward to determine the product form.
This echoes Karpathy's observation about "Cursor for X." Cursors are essentially the "AI-ization of the programmer profession," so similar things will appear in various industries.
--- Sixth Layer: Domain-Specific Models are a "False Proposition"
This viewpoint might make some people uncomfortable, but Tang Jie puts it bluntly: Domain-specific models are a false proposition. With AGI already in place, what kind of "domain-specific AGI" is there?
The reason domain-specific models exist is because application companies are unwilling to admit defeat to AI model companies, hoping to build a moat with domain know-how and tame AI into a tool.
But the essence of AI is a "tsunami," sweeping everything in its path. Domain companies will inevitably step out of their moats and be swept into the world of AGI. Domain data, processes, and agent data will gradually enter the main model.
Of course, before AGI is fully realized, domain models will exist for a long time. But how long will this window be? It's hard to say; AI development is incredibly rapid.
--- Layer Seven: Multimodal and Embodied Intelligence – A Bright Future but a Difficult Path
Multimodal intelligence is undoubtedly the future. However, the current problem is that it offers limited help in raising the intelligence ceiling of AGI (Automatic Generative Intelligence).
Text, multimodal, and multimodal generation may still be more efficient developed separately. Of course, exploring a combination of the three requires courage and funding.
Embodied intelligence (robots) is even more difficult. The difficulty is the same as with agents: versatility. You teach a robot to work in scenario A, but it doesn't work in another scenario. What to do? Data collection and data synthesis are both difficult and expensive.
What to do? Data collection or data synthesis. Both are difficult and expensive. But conversely, once the data scale increases and general capabilities emerge, a barrier to entry will naturally form.
Another problem is often overlooked: the robot itself is also a problem. Instability and frequent malfunctions are hardware issues that also limit the development of embodied intelligence.
Tang Jie predicts that significant progress will be made in these areas by 2026.
--- Connecting Tang Jie's article reveals a fairly clear roadmap:
Currently, pre-training scaling remains effective, but greater emphasis should be placed on alignment and long-tail capabilities.
In the near term, agents are the key breakthrough, enabling models to evolve from "talking" to "doing."
In the medium term, memory systems and online learning are essential; models must learn self-evaluation and iteration.
In the long term, job substitution is the essence of applications, and domain moats will be eroded by AGI.
In the long term, multimodal and embodied models will develop independently, awaiting the maturation of technology and data.
--- Comparing Tang Jie's and Karpathy's viewpoints reveals several points of consensus:
First, the core change in 2025 will be the upgrade of the training paradigm, shifting from "pre-training-centric" to "multi-stage collaboration."
Second, agents are a milestone, a crucial leap for models from learning to doing.
Third, the gap between benchmark scores and real-world capabilities is increasingly recognized.
Fourth, the essence of AI applications is to replace or enhance human jobs, not to create apps for the sake of creating apps.
The different focuses are also interesting. Karpathy focuses more on the philosophical question of "what shape is AI intelligence?", while Tang Jie focuses more on the engineering problem of "how to implement the model in real-world scenarios." One leans towards "understanding," the other towards "implementation."
Both perspectives are needed. A clear understanding is essential to determine if the direction is correct; adequate engineering is crucial to turning ideas into reality.
2026 will be exciting.
twitter.com/dotey/status/20035...