Episode 217: Psionic: Fast Qwen 3.5
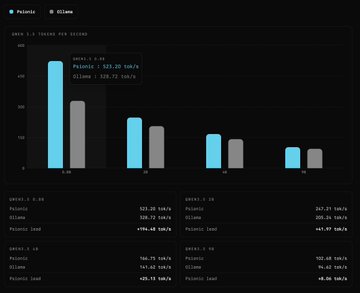
We add Qwen 3.5 (0.8B/2B/4B/9B) support to Psionic and beat @ollama's inference speed across all four models.
Tokens per second on one NVIDIA 4080:
🏆 0.8B: Psionic 523.20, Ollama 328.72
🏆 2B: Psionic 247.21, Ollama 205.24
🏆 4B: Psionic 166.75, Ollama 141.62
🏆 9B: Psionic 102.68, Ollama 94.62
Thank you @Alibaba_Qwen for the awesome model and @OpenAIDevs for Codex's help to pretend we are ML engineers. 😆
Analysis & instructions to reproduce: github.com/OpenAgentsInc/psion...…
We are happy to take more feature or model requests for Psionic, the worst and best ML library ever!
twitter.com/OpenAgentsInc/stat...