

Arrangement: New

On the evening of June 2, NVIDIA CEO Jensen Huang demonstrated NVIDIA's latest achievements in accelerated computing and generative AI at the ComputeX 2024 conference in Taipei, and also outlined the development blueprint for future computing and robotics technology.

This speech covered everything from basic AI technologies to future applications of robots and generative AI in various industries, fully demonstrating NVIDIA's outstanding achievements in driving changes in computing technology.

Huang Renxun said that NVIDIA is at the intersection of computer graphics, simulation and AI, which is the soul of NVIDIA. Everything shown to us today is simulated. It is a combination of mathematics, science, computer science, and amazing computer architecture. These are not animations, but homemade, and NVIDIA has integrated it all into the Omniverse virtual world.
Accelerated Computing and AI
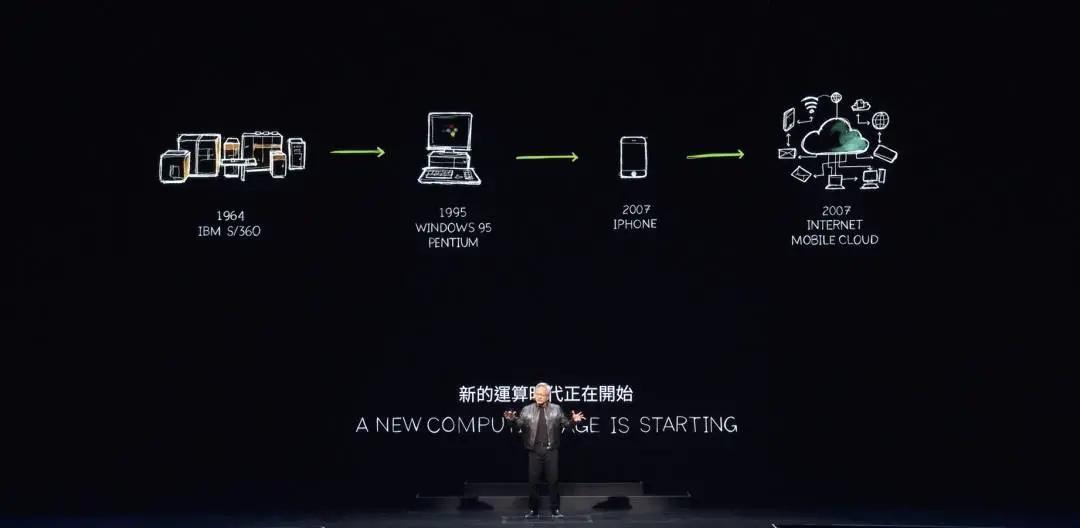
Huang Renxun said that the foundation of everything we see is two basic technologies, accelerated computing and AI running inside the Omniverse, these two basic forces of computing will reshape the computer industry. The computer industry has a 60-year history. In many ways, everything that is done today was invented in 1964, a year after Huang Renxun was born.
The IBM System 360 introduced the central processing unit, general purpose computing, separation of hardware and software through the operating system, multitasking, IO subsystems, DMA, and all the technologies used today. Architectural compatibility, backward compatibility, family compatibility, most of what we know about computers today were described in 1964. Of course, the PC revolution democratized computing, putting it in everyone's hands and homes.
In 2007, the iPhone introduced mobile computing, putting computers in our pockets. Since then, everything has been connected and running all the time through the mobile cloud. In the past 60 years, we have only seen two or three, not many, but two or three, major technological changes, two or three tectonic shifts in computing, and we are about to see it happen again.

There are two fundamental things going on. The first is that the performance gains of processors, the engines that run the computer industry, the central processing units, have slowed dramatically. Yet the amount of computing that we need to do is still growing rapidly, exponentially. If the demand for processing, the amount of data that needs to be processed continues to grow exponentially but performance does not, compute inflation is going to happen. In fact, we're seeing this right now. The amount of electricity used by data centers around the world is growing dramatically. The cost of computing is also growing. We're experiencing compute inflation.
Of course, this can't continue. Data volumes will continue to grow exponentially, and CPU performance gains will never recover. There's a better way. NVIDIA has been working on accelerated computing for nearly two decades. CUDA enhances the CPU, offloading and speeding up work that specialized processors can do better. In fact, the performance is so good that it's now clear that as CPU performance gains slow and eventually stop significantly, everything should be accelerated.

Huang predicted that all applications that require a lot of processing will be accelerated, and certainly every data center will be accelerated in the near future. Accelerated computing is very reasonable now. If you look at an application, here 100t represents 100 units of time, it could be 100 seconds, it could be 100 hours. In many cases, as you know, AI applications are being studied now that run for 100 days.
1T code refers to code that needs to be processed sequentially, where single-threaded CPUs are critical. Operating system control logic is very important and needs to be executed one instruction after another. However, there are many algorithms, such as computer graphics processing, that can be fully parallelized. Computer graphics processing, image processing, physical simulation, combinatorial optimization, graph processing, database processing, and of course the very famous linear algebra in deep learning, these algorithms are very suitable for acceleration through parallel processing.
So an architecture was invented that does this by adding a GPU to the CPU. A dedicated processor that can accelerate tasks that take a long time to extremely fast speeds. Because the two processors can work side by side, they are both autonomous and independent, and can accelerate tasks that would otherwise take 100 time units to 1 time unit, the speed increase is incredible, the effect is very significant, 100 times faster, but the power consumption has only increased by about three times, and the cost has only increased by about 50%. This is done all the time in the PC industry, Nvidia takes a $500 GeForce GPU and puts it on a $1,000 PC, and the performance will increase significantly. Nvidia does this in the data center, a billion-dollar data center, add a $500 million GPU, and all of a sudden it becomes an AI factory, and this is happening all over the world.
The cost savings are staggering. For every dollar spent, you get 60 times the performance, 100 times the speed, for only three times the power and only 1.5 times the cost. The savings are incredible. The cost savings can be measured in dollars.
It's clear that many companies spend hundreds of millions of dollars processing data in the cloud. If these processes were accelerated, it's not hard to imagine that hundreds of millions of dollars could be saved. This is because there has been inflation in general-purpose computing for a long time.

Now that we have finally decided to accelerate computing, there are a lot of captured losses that can now be recovered, and a lot of retained waste can be released from the system. This will translate into savings in money and energy, which is why Huang Renxun often says "the more you buy, the more you save."
Huang Renxun also said that accelerated computing does bring extraordinary results, but it is not easy. Why can it save so much money, but people have not done it for so long? The reason is because it is very difficult. There is no software that can be run through a C compiler and suddenly the application is 100 times faster. It is not even logical. If this could be done, they would have modified the CPU long ago.
The fact that the software had to be rewritten was the hardest part. The software had to be completely rewritten to be able to re-express the algorithms that were written on the CPU so that they could be accelerated, offloaded, and run in parallel. This exercise in computer science was extremely difficult.

Huang Renxun said that in the past 20 years, NVIDIA has made the world easier. Of course, the very famous cuDNN, which is a deep learning library for processing neural networks. NVIDIA has an AI physics library that can be used in fluid dynamics and many other applications where neural networks must obey the laws of physics. NVIDIA has a new great library called Arial Ran, which is a CUDA accelerated 5G radio that can define and accelerate telecommunications networks like the world network Internet. The ability to accelerate enables us to transform all telecommunications into the same type of platform as the cloud computing platform.
cuLITHO is a computational lithography platform that handles the most computationally intensive part of chip manufacturing - making masks. TSMC is using cuLITHO for production, saving a lot of energy and money. TSMC's goal is to accelerate their stack to be ready for further algorithms and computations on deeper and narrower transistors. Parabricks is Nvidia's gene sequencing library, it's the highest throughput gene sequencing library in the world. cuOpt is an incredible library for combinatorial optimization, route planning optimization, used to solve the traveling salesman problem, which is very complex.
Scientists generally agree that a quantum computer is needed to solve this problem. NVIDIA has created an algorithm that runs on accelerated computing, which runs extremely fast and has set 23 world records. cuQuantum is a simulation system for a quantum computer. If you want to design a quantum computer, you need a simulator. If you want to design quantum algorithms, you need a quantum simulator. If quantum computers don't exist, how do you design these quantum computers and create these quantum algorithms? You use the fastest computer in the world today, which is of course NVIDIA CUDA. On top of it, NVIDIA has a simulator that can simulate quantum computers. It is used by hundreds of thousands of researchers around the world and is integrated into all leading quantum computing frameworks and is widely used in scientific supercomputing centers.
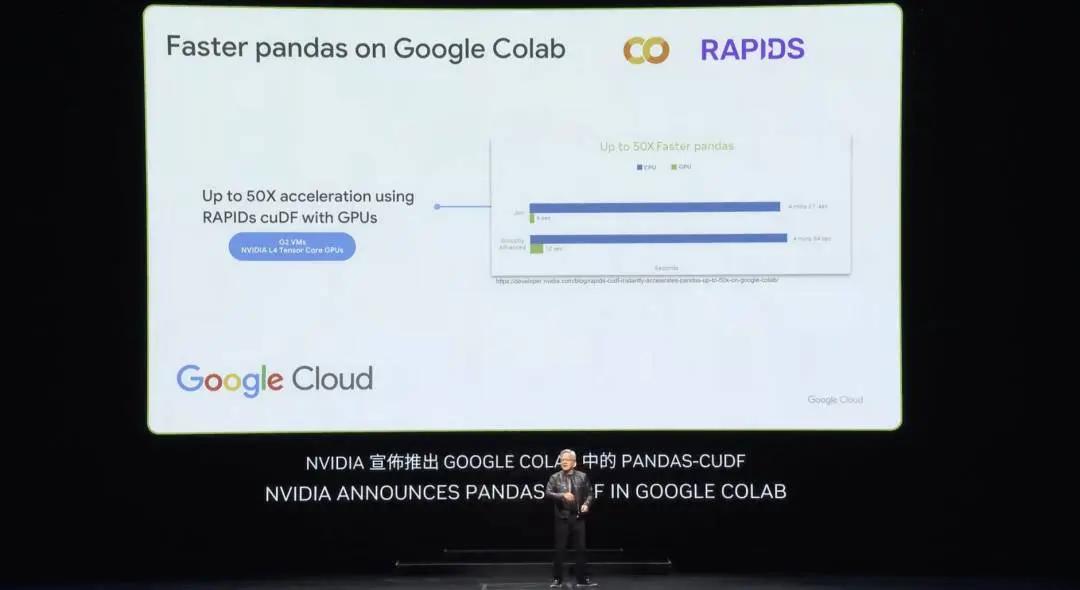
cuDF is an incredible data processing library. Data processing consumes the vast majority of cloud spending today, and all of that should be accelerated. cuDF accelerates major libraries used in the world, like Spark, which many companies are probably using, Pandas, a new library called Polars, and of course NetworkX, a graph processing database library. These are just a few examples, there are many others.
Huang Renxun said that NVIDIA had to create these libraries so that the ecosystem could take advantage of accelerated computing. If NVIDIA had not created cuDNN, it would be impossible for CUDA alone to be used by deep learning scientists around the world because the distance between the algorithms used in CUDA, TensorFlow, and PyTorch is too far. It's almost like doing computer graphics without OpenGL, or data processing without SQL. These domain-specific libraries are NVIDIA's treasures, and there are 350 libraries in total. It is these libraries that enable NVIDIA to open up so many markets.
Last week, Google announced the acceleration of Pandas, the world’s most popular data science library, in the cloud. Many of you may already be using Pandas, which is used by 10 million data scientists worldwide and downloaded 170 million times per month. It is the spreadsheet of data scientists. Now, with just one click, you can use Pandas accelerated by cuDF in Colab, the data center platform of Google Cloud, and the acceleration effect is really amazing.
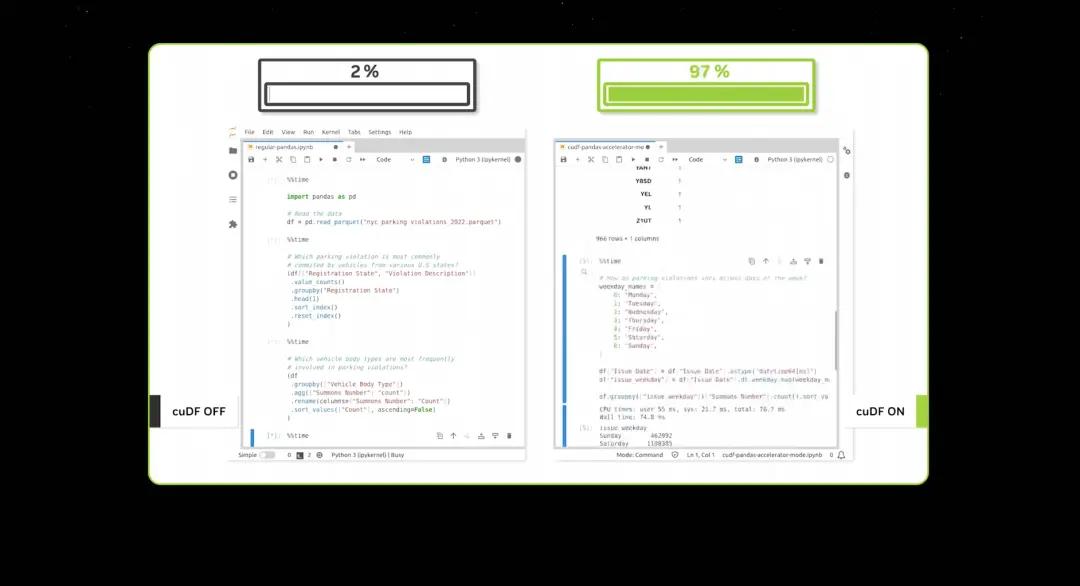
When you accelerate data processing to such a high speed, demonstrations really don't take long. Now CUDA has reached what people call a tipping point, but it's even better. CUDA has now achieved a virtuous cycle.
This rarely happens. If you look at all the computing architecture platforms throughout history. Take the microprocessor CPU, for example, it has been around for 60 years and has not changed at this level. This type of computing, accelerated computing, already exists, and it is extremely difficult to create a new platform because it is a chicken and egg problem.
If there are no developers using your platform, then of course there will be no users. But if there are no users, there will be no install base. If there is no install base, developers will not be interested in it. Developers want to write software for a large install base, but a large install base requires a large number of applications to attract users to create an install base.
This chicken-and-egg problem is rarely solved. NVIDIA spent 20 years developing libraries in one field after another, and acceleration libraries after acceleration libraries, and now 5 million developers use NVIDIA's platform worldwide.
NVIDIA serves every industry, from healthcare, financial services, the computer industry, the automotive industry, almost every major industry, almost every field of science, and because of NVIDIA's architecture, there are so many customers, OEMs and cloud service providers interested in building NVIDIA's systems. Excellent system manufacturers like the ones here in Taiwan are interested in building NVIDIA's systems, which makes the market have more systems to choose from, which of course creates greater opportunities for us to expand our scale, our R&D scale, and thus further accelerate applications.
Every time you speed up an application, the cost of computing goes down. A 100x speedup translates to 97%, 96%, 98% savings. So as we go from 100x speedup to 200x speedup to 1,000x speedup, the marginal cost of computing continues to go down.
NVIDIA believes that by significantly reducing the cost of computing, the market, developers, scientists, and inventors will continue to discover more and more algorithms that consume more and more computing resources, and eventually a qualitative leap will occur, and the marginal cost of computing will be so low that a new way of using computing will emerge.
In fact, this is exactly what we are seeing now. Over the years, Nvidia has reduced the marginal computational cost of a particular algorithm by a million times in the last 10 years. So now it is very reasonable and common sense to train an LLM containing the entire internet of data, and no one doubts it. The idea that you can create a computer that can process so much data that you can write your own software. AI came about because of the absolute belief that if you make computing cheaper and cheaper, someone will always find a great use for it.
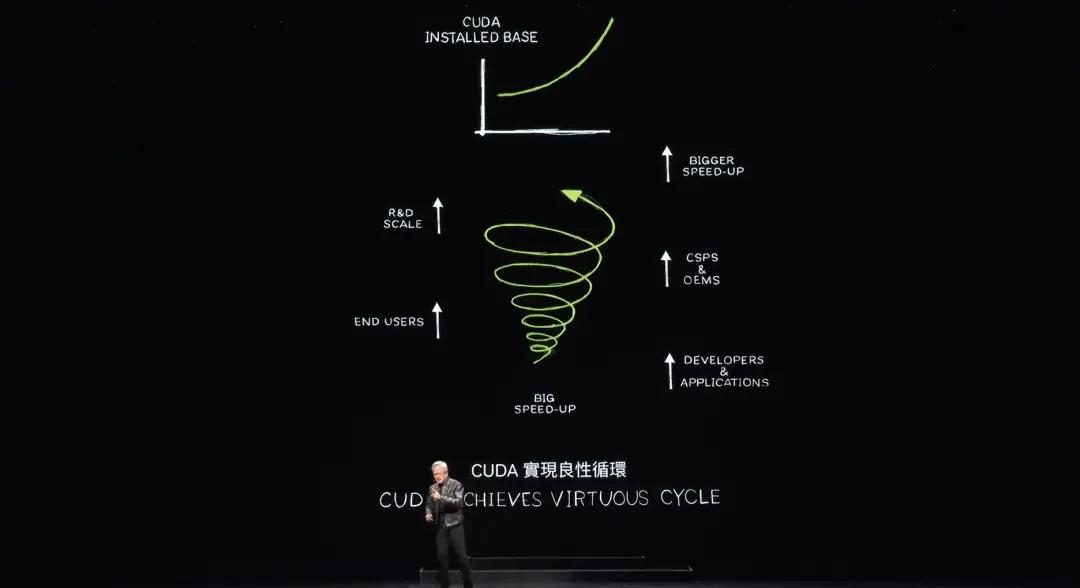
Today, CUDA has achieved a virtuous cycle. The installed base is growing, and the cost of computing is falling, which leads to more developers coming up with more ideas, which drives more demand. Now we are at a very important starting point.
Huang then mentioned the idea of Earth 2, which will create a digital twin of the Earth. By simulating the Earth, we can better predict the future, thereby better avoiding disasters, and better understand the impacts of climate change so that we can better adapt.

NVIDIA first came into contact with AI in 2012 when researchers discovered CUDA. It was a very important day. I was lucky to work with scientists to make deep learning possible.
AlexNet was a huge computer vision breakthrough. But more importantly, take a step back and understand the context, the foundations, and the long-term impact and potential of deep learning. Nvidia realized that this technology had huge potential to scale. An algorithm invented and discovered decades ago, all of a sudden, because of more data, bigger networks, and very importantly, more computing resources, deep learning is doing things that human algorithms can't do.
Now imagine what could be achieved if the architecture was extended further, with larger networks, more data, and more compute resources. After 2012, Nvidia changed the architecture of the GPU and added Tensor cores. Nvidia invented NVLink, that was 10 years ago, CUDA, then TensorRT, NCCL, the acquisition of Mellanox, TensorRT-ML, Triton inference server, all of which were integrated into a brand new computer. No one understood, no one asked for it, no one understood the significance of it.
In fact, Huang was so convinced that no one wanted to buy it that Nvidia announced it at GTC that OpenAI, a small company in San Francisco, asked Nvidia to provide them with one.
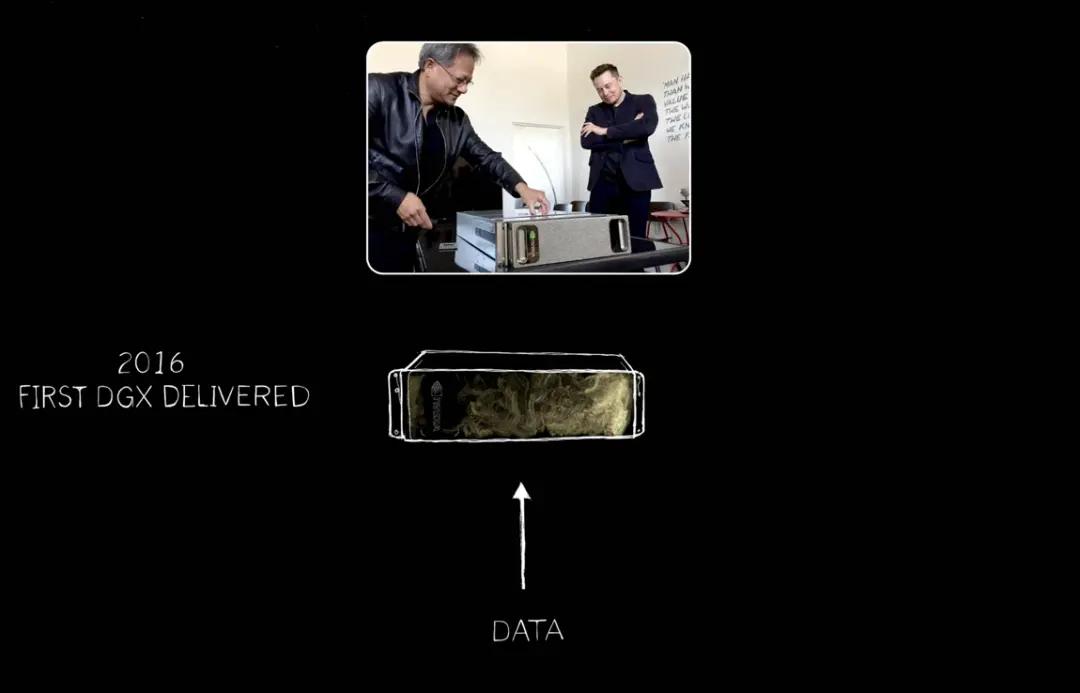
In 2016, Huang Renxun delivered the first DGX to OpenAI, the world's first AI supercomputer. After that, it continued to expand from an AI supercomputer, an AI device, to a large supercomputer, and even larger.
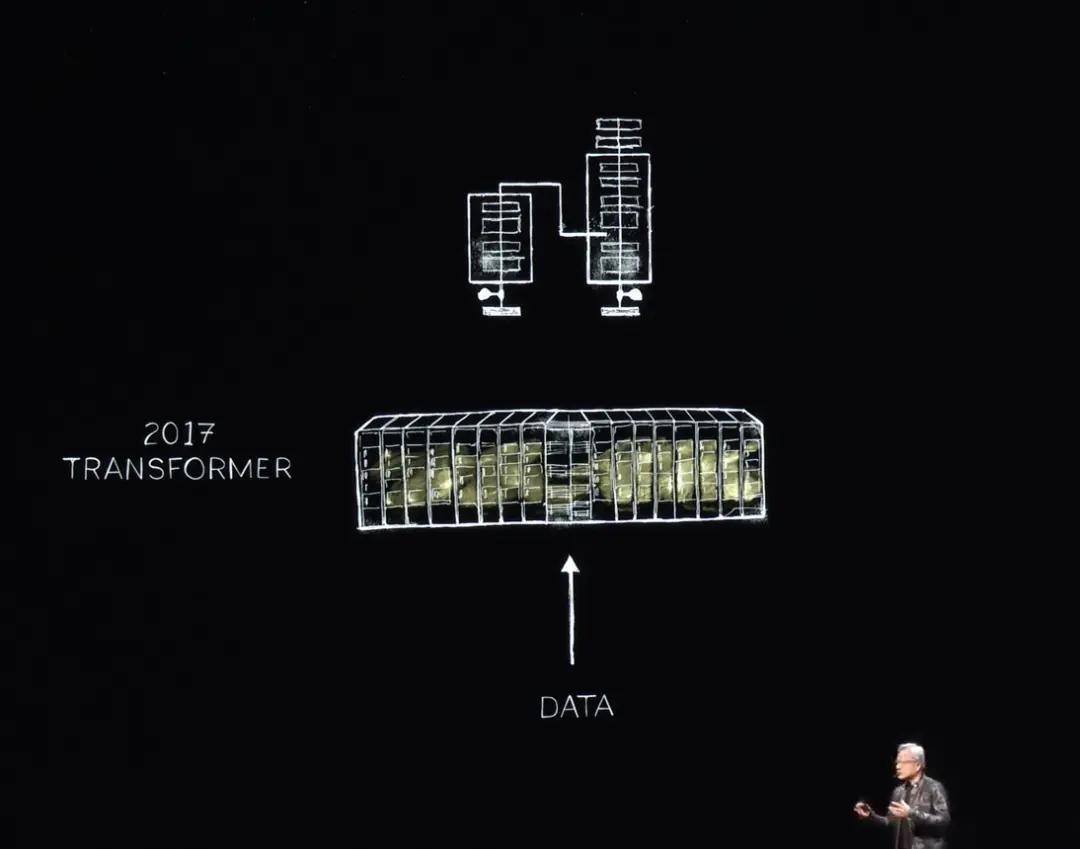
By 2017, the world discovered the Transformer, which enabled training of large amounts of data to identify and learn long-term sequential patterns. Now, Nvidia could train these LLMs to understand and achieve breakthroughs in natural language understanding. Moving forward, larger systems were built.
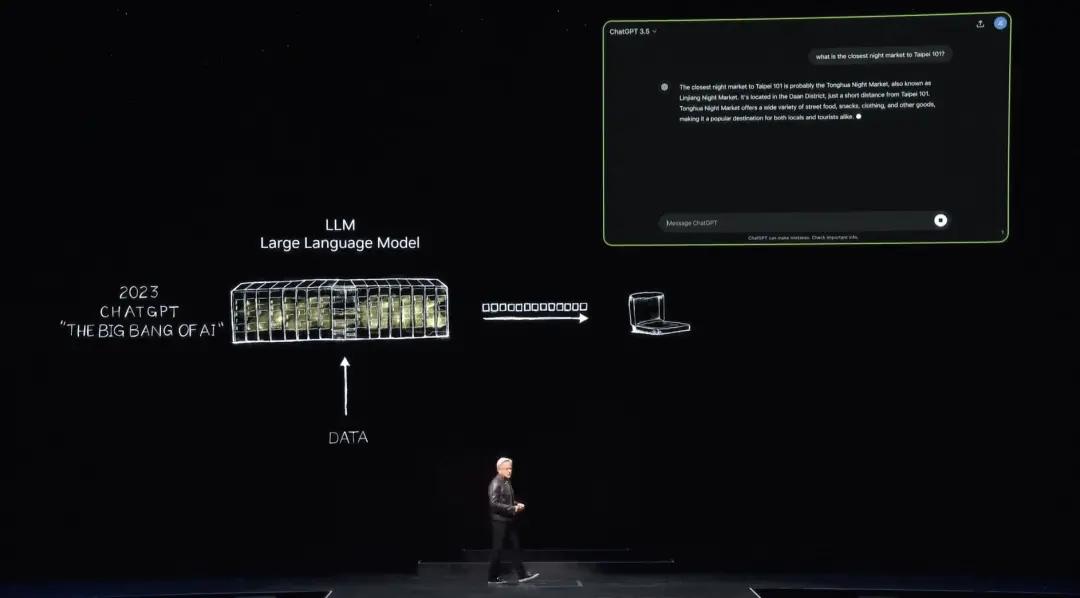
Then in November 2022, using thousands of Nvidia GPUs and very large AI supercomputers for training, OpenAI released ChatGPT, which reached one million users in five days and 100 million in two months, becoming the fastest growing application in history.
Before ChatGPT showed the world, AI was all about perception, natural language understanding, computer vision, speech recognition. It was all about perception and detection. This is the first time that the world has solved generative AI, generating tokens one by one, and these tokens are words. Of course, some tokens can now be images, charts, tables, songs, words, speech, videos. These tokens can be anything that you can understand the meaning of, they can be tokens for chemicals, tokens for proteins, tokens for genes. What you saw before in the Earth 2 project was generating tokens for weather.
We can understand, we can learn physics. If you can learn physics, you can teach AI models physics. AI models can learn what physics means, and then they can generate physics. We're shrinking it down to a kilometer, not by filtering, but by generating. So we can generate almost any valuable token this way. We can generate steering wheel controls for cars, generate motion for robot arms. Everything we can learn, we can now generate.
AI Factory
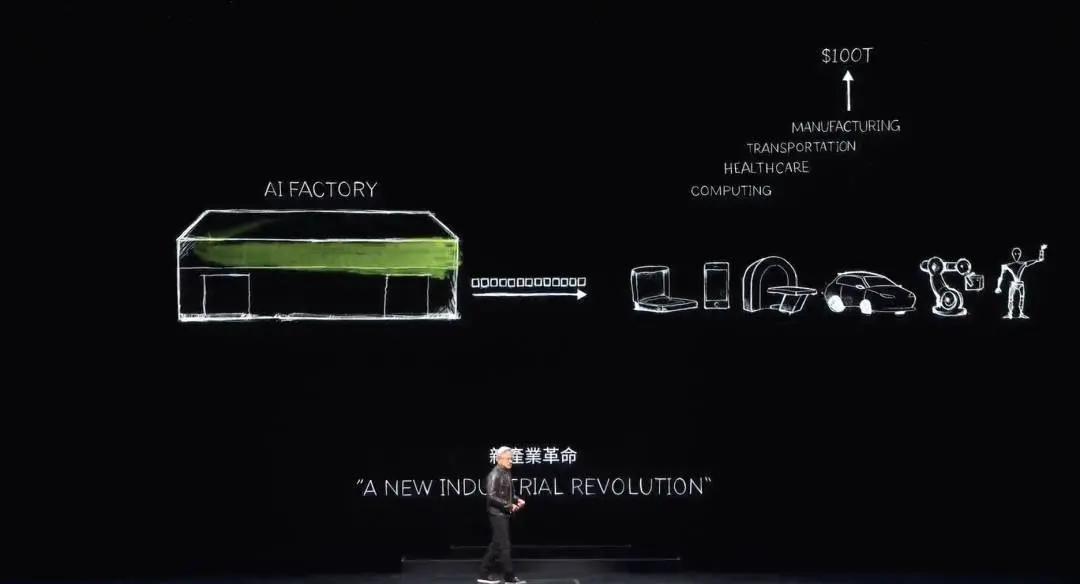
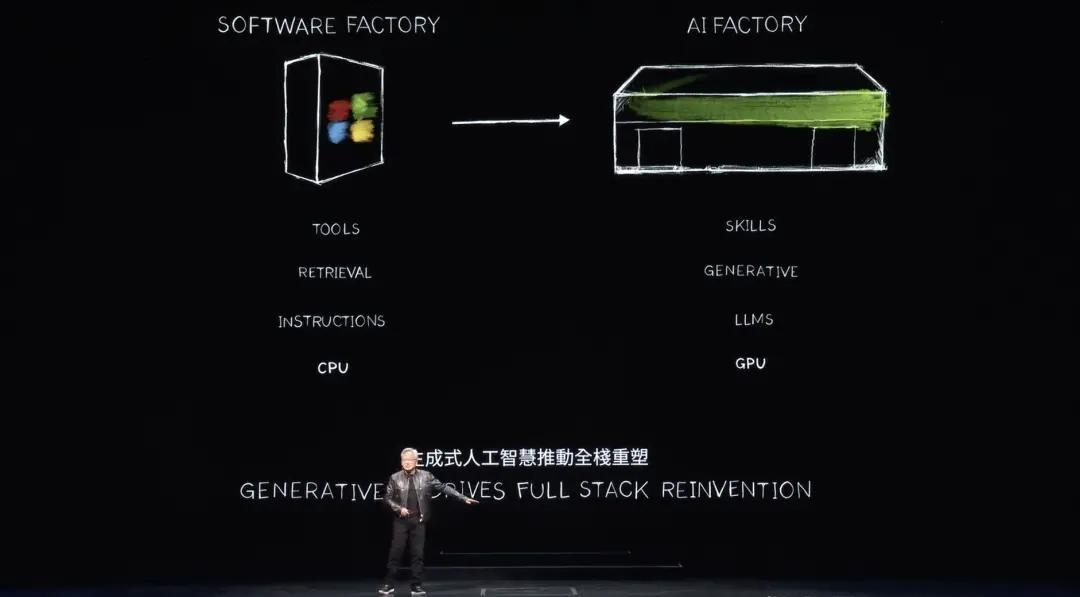
We have now entered the era of generative AI. But what is really important is that this computer that started out as a supercomputer has now evolved into a data center that generates only one thing, which is tokens. It is an AI factory that is generating, creating and producing a new commodity of great value.
In the late 1890s, Nikola Tesla invented the AC generator, and Nvidia invented the AI generator. The AC generator generates electrons, and the Nvidia AI generator generates tokens. Both of these things have huge opportunities in the market and are completely replaceable in almost every industry, which is why this is a new industrial revolution.
Nvidia now has a new factory that produces a new commodity for each industry, a commodity that has extraordinary value. This approach is highly scalable, and the repeatability of this approach is also very high.
Notice how many different generative AI models are being invented every day. Every industry is now flooding in. For the first time, the $3 trillion IT industry is creating something that can directly serve a $100 trillion industry. No longer just a tool for information storage or data processing, but a factory that generates intelligence for every industry. This will become a manufacturing industry, but not manufacturing with computers, but manufacturing with computers.
This has never happened in history. Accelerated computing has brought AI, generative AI, and now the industrial revolution. The impact on the industry is also very significant. It can create a new commodity, a new product, called token, for many industries, but the impact on our own industry is also very far-reaching.
Over the past 60 years, every layer of computing has changed, from CPU general computing to accelerated GPU computing, computers need instructions. Now computers process LLM, AI models. And the computing model in the past was based on retrieval. Almost every time you touch your phone, some pre-recorded text, images or videos are retrieved for you, recombined and presented to you based on the recommendation system.
Huang Renxun said that in the future, computers will generate as much data as possible and retrieve only necessary information. The reason is that the generated data requires less energy to obtain information. The generated data is also more contextual. It will encode knowledge and understand you. Instead of asking the computer to obtain information or files, you will ask it to answer your questions directly. Computers will no longer be tools we use, but will generate skills and perform tasks.
NIMs, NVIDIA Inference Microservices

Rather than an industry that produces software, which was a revolutionary idea in the early 90s. Remember the idea of software packaging that Microsoft created revolutionized the PC industry. What would we do with PCs without packaged software? It drove the industry, and now NVIDIA has a new factory, a new computer. We're going to run a new kind of software on it, called NIMs, NVIDIA Inference Microservices.
The NIM runs inside this factory, and this NIM is a pre-trained model, it's an AI. This AI itself is very complex, but the computing stack that runs the AI is extremely complex. When you use ChatGPT, the stack behind it is a lot of software. The prompt behind it is a lot of software, extremely complex because the model is huge, with billions to trillions of parameters. It runs not only on one computer, but on multiple computers. It has to distribute the workload across multiple GPUs, using tensor parallelism, pipeline parallelism, data parallelism, all kinds of parallelism, expert parallelism, all kinds of parallelism, to distribute the workload across multiple GPUs to process it as quickly as possible.
Because if you're running a plant, your throughput is directly related to revenue. Your throughput is directly related to the quality of service, your throughput is directly related to the number of people who can use your service.
We are now in a world where data center throughput utilization is critical. It was important in the past, but not as important as it is now. It was important in the past, but people didn't measure it. Today, every parameter is measured, start time, run time, utilization, throughput, idle time, etc., because it's a factory. When something is a factory, its operation is directly related to the company's financial performance, which is extremely complex for most companies.

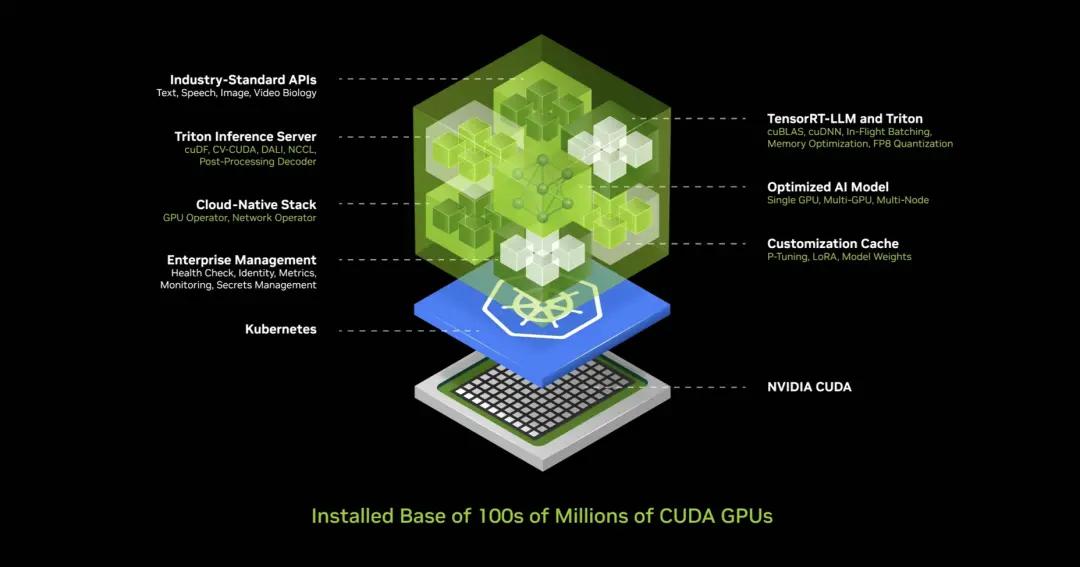
So what did Nvidia do? Nvidia created this AI box, this container filled with a ton of software, inside this container it has CUDA, cuDNN, TensorRT, Triton inference service. It's cloud native, it can scale automatically in a Kubernetes environment, it has management services and hooks to monitor your AI. It has a universal API, a standard API, and you can talk to this box. You download this NIM, you can talk to it, and as long as you have CUDA on your computer, which of course is now ubiquitous. It's available in every cloud, from every computer manufacturer. It's available on hundreds of millions of PCs, and all the software is integrated together, 400 dependencies are all integrated into one.
Nvidia tested this NIM, and every single pre-trained model was tested on the entire installed base, all different versions of Pascal, Ampere, and Hopper, and all sorts of different builds. I even forgot some of the names. Incredible invention, this is one of my favorites.
Huang said Nvidia has all these different versions, whether it's language-based or vision-based or image-based, or versions for healthcare, digital biology, there are versions for digital humans, just go to ai.nvidia.com.
Huang Renxun also said that NVIDIA has just released a fully optimized Llama3 NIM on HuggingFace today, where it is available for you to try and you can even take it away. It is provided to you for free. You can run it in the cloud, in any cloud. You can download this container, put it in your own data center, and make it available to your customers.
Nvidia has versions for all sorts of different domains, physics, some for semantic retrieval called RAGs, vision languages, all sorts of different languages. The way you use them is you connect these microservices into your larger application.
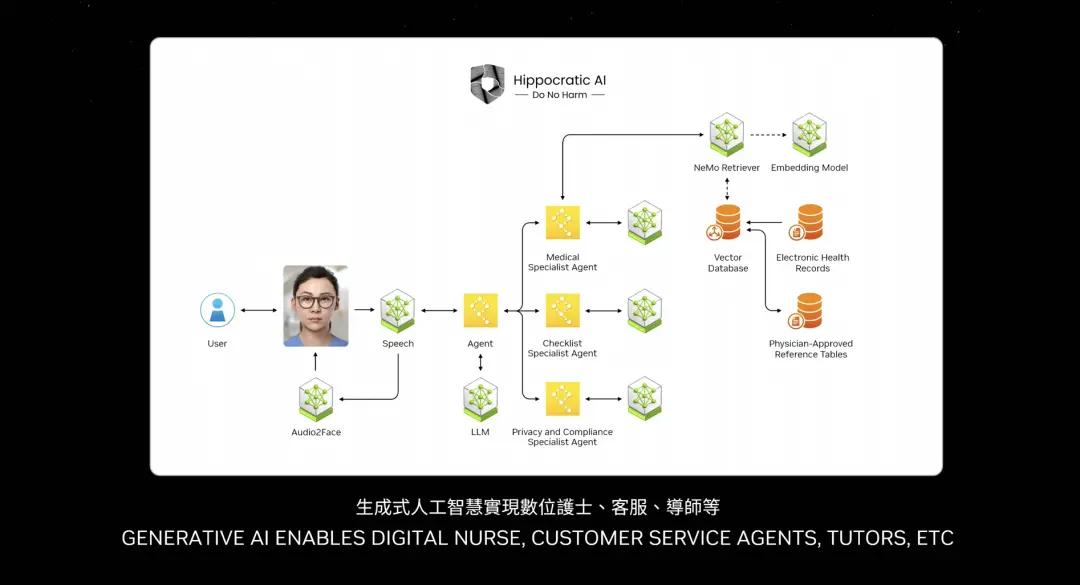
One of the most important applications of the future is certainly customer service. Almost every industry needs agents. This represents trillions of dollars of customer service. Nurses are also customer service agents in some ways, and some over-the-counter or non-diagnostic nurses are basically customer service in retail, quick service food, financial services, insurance. Tens of millions of customer services can now be enhanced by language models and AI. So these boxes you see are basically NIMs.
Some NIMs are reasoning agents, given a task, determining the task, breaking it down into plans. Some NIMs retrieve information. Some NIMs might do searches. Some NIMs might use tools, like cuOpt, which Huang mentioned earlier. It can use tools that run on SAP. So it has to learn a specific language called ABAP. Maybe some NIMs have to do SQL queries. So all of these NIMs are experts, and now they are assembled into a team.
So what has changed? The application layer has changed. Applications that used to be written with instructions are now applications that assemble AI teams. Few people know how to write programs, but almost everyone knows how to break down a problem and assemble a team. I believe that in the future every company will have a large collection of NIMs. You will download the experts you want, connect them into a team, and you don’t even have to know exactly how to connect them. You just give the task to an agent, a NIM, and let it figure out how to distribute the task. That team leader agent will break down the task and assign it to the various team members. The team members will perform the task and return the results to the team leader, who will reason about the results and present the information to you, just like a human, this is the near future, the future form of application.
Of course, you can interact with these large AI services through text prompts and voice prompts. However, there are many applications where you want to interact with the human form. Nvidia calls this digital human and has been working on digital human technology.
Huang went on to say that digital humans have the potential to be great agents that interact with you, making interactions more engaging and more empathetic. Of course, we have to cross this huge reality gap to make digital humans appear more natural. Imagine a future where computers are able to interact with us like humans. That’s the amazing reality of digital humans. Digital humans will revolutionize industries from customer service to advertising and gaming. The possibilities for digital humans are endless.
Using scans of your current kitchen, they become an AI interior designer through your phone, helping to generate beautiful photorealistic suggestions and providing sources for materials and furniture.
NVIDIA has generated several design options for you to choose from. They will also become AI customer service agents, making interactions more vivid and personalized, or digital medical workers, examining patients and providing timely and personalized care. They will even become AI brand ambassadors, setting the next wave of marketing and advertising trends.
New breakthroughs in generative AI and computer graphics allow digital humans to see, understand, and interact with us in a human-like way. From what I can see, it looks like you are in some kind of recording or production setting. The foundation of digital humans is an AI model built on multilingual speech recognition and synthesis, and LLM models that can understand and generate conversations.
These AIs are connected to another generative AI to dynamically animate a realistic 3D facial mesh. Finally, the AI model recreates a realistic look, implementing real-time path-traced subsurface scattering, which simulates how light penetrates the skin, scatters, and exits at different points, giving the skin a soft and translucent appearance.
Nvidia Ace is a set of digital human technologies packaged into fully optimized microservices or NIMs that are easy to deploy. Developers can integrate Ace NIMs into their existing frameworks, engines, and digital human experiences, and Nematons SLM and LLM NIMs understand our intent and orchestrate other models.
Riva Speech Nims for interactive speech and translation, Audio to Face and Gesture NIMs for facial and body animation, and Omniverse RTX with DLSS for neural rendering of skin and hair.
Pretty incredible. These Aces can run in the cloud as well as on PCs, and with the inclusion of tensor core GPUs in all RTX GPUs, Nvidia is already shipping AI GPUs in preparation for this day. The reason is simple, in order to create a new computing platform, you first need an installed base.
Eventually, the applications will come. How can applications come if you don't create an installed base? So if you build it, they may not come. But if you don't build it, they can't come. So Nvidia put a tensor core processor in every RTX GPU. Now Nvidia has 100 million GeForce RTX AI PCs in the world, and Nvidia is shipping 200.
At Computex, Nvidia showed off four new amazing laptops. They are all capable of running AI. The laptop, the PC of the future will become an AI. It will constantly help you and assist you in the background. The PC will also run applications enhanced by AI.
Of course, all your photo editing, writing tools, everything you use will be enhanced by AI. Your PC will also host AI applications with digital humans. So AI will manifest and be used in PCs in different ways. The PC will become a very important AI platform.
So where do we go from here? I talked about scaling in data centers earlier. Every time we scale, we find a new leap forward. When scaling from DGX to large AI supercomputers, NVIDIA enabled Transformer to train on very large datasets. In the beginning, data was human supervised and required human annotation to train AI. Unfortunately, human-annotated data is limited.
Transformer makes unsupervised learning possible. Now, Transformer only needs to look at a large amount of data, videos or images, and it can find patterns and relationships by studying large amounts of data on its own.

The next generation of AI needs to be based on physics. Most AI today does not understand the laws of physics, they are not rooted in the physical world. In order to generate images, videos and 3D graphics and many physical phenomena, we need AI that is based on physics and understands the laws of physics. You can do this through video learning, which is one source.
Another way is to have synthetic data, simulated data, another way is to have computers learn from each other. This is really no different than AlphaGo playing against itself, where they get smarter over a long period of time by playing against each other of equal ability. You're going to start to see this type of AI emerge.
If AI data is generated synthetically and reinforcement learning is used, the rate at which data is generated will continue to increase. Every time data generation grows, the amount of compute that needs to be provided also grows.
We are about to enter a stage where AI can learn the laws of physics and become rooted in data about the physical world. Therefore, Nvidia expects that the models will continue to grow and we will need larger GPUs.
Blackwell

Blackwell was designed for this generation and has several very important technologies. The first is the size of the chip. Nvidia made the largest chip at TSMC and connected two chips together with a 10TB per second connection, and the world's most advanced SerDes connected the two chips together. Then Nvidia put the two chips on a computing node, connected by the Grace CPU.
Grace CPU can be used for a variety of purposes. In training situations, it can be used for fast checkpoints and restarts. In reasoning and generation situations, it can be used to store contextual memory so that the AI understands the context of the conversation you want to have. This is NVIDIA's second-generation Transformer engine, which allows the accuracy to be dynamically adjusted according to the accuracy and range required by the computing layer.
This is the second generation of GPUs with secure AI, which can require service providers to protect the AI from theft or tampering. This is the fifth generation of NVLink, which allows multiple GPUs to be connected together, and I'll talk more about this in a moment.
This is NVIDIA's first generation of GPUs with a reliability and availability engine. This RAS system allows testing of every transistor, flip-flop, on-chip memory, and off-chip memory to determine in the field if a chip is faulty. The mean time between failures for a supercomputer with 10,000 GPUs is measured in hours. The mean time between failures for a supercomputer with 100,000 GPUs is measured in minutes.
So it's almost impossible to run a supercomputer for a long time and train models for months without inventing technology to improve reliability. Reliability improves uptime, which directly affects costs. Finally, the decompression engine, data processing is one of the most important things that must be done. NVIDIA added a data compression engine and decompression engine that allows NVIDIA to extract data from storage 20 times faster than is possible today.

Blackwell is in production, with a lot of technology, you can see every Blackwell chip, two connected together. You see this is the largest chip in the world. Then two chips are connected together through 10TB per second, the performance is amazing.
Nvidia's floating-point computing power has increased 1,000 times with each generation of computing. Moore's Law has increased by about 40 to 60 times in eight years. In the past eight years, the growth rate of Moore's Law has slowed down significantly. Even at the best of Moore's Law, it cannot compare with Blackwell performance.
The amount of computation is staggering. Every time you increase computing power, the cost goes down. Nvidia has reduced the energy requirement for training GPT-4 from 1000 GWh to 3 GWh by increasing computing power. Pascal requires 1000 GWh of energy. 1000 GWh means a GW data center is needed. There is no GW data center in the world, but if you have a GW data center, it takes a month. If you have a 100 MW data center, it takes about a year. Therefore, no one will build such a facility.
That's why eight years ago, LLMs like ChatGPT were impossible. By improving performance, along with the energy efficiency improvements, Nvidia has now reduced the energy requirements of Blackwell from 1,000 GWh to 3 GWh, which is an incredible progress. If it were 10,000 GPUs, for example, it would take a few days, maybe 10 days or so. The progress made in just eight years is amazing.
This section is about reasoning and generating tokens. Generating a GPT-4 token requires two light bulbs running for two days. Generating a word requires about three tokens. So the energy required for Pascal to generate GPT-4 and have a ChatGPT experience with you is almost impossible. But now each token only uses 0.4 joules, and tokens can be generated with extremely low energy.

Blackwell was a huge leap forward. Even so, it wasn't big enough. So bigger machines had to be built. Hence Nvidia's approach to building something called DGX.

This is a DGX Blackwell, this is air cooled, and there are 8 GPUs inside. Look at the size of the heat sinks on these GPUs, about 15 kilowatts, completely air cooled. This version supports x86 and goes into the Hoppers infrastructure that Nvidia has been shipping, and Nvidia has a new system called MGX, which means modular system.
Two Blackwell boards, four Blackwell chips in a node. These Blackwell chips are liquid cooled, and the 72 GPUs are connected together through the new NVLink. This is the 5th generation NVLink switch, and the NVLink switch itself is a technological marvel, it's the most advanced switch in the world, the data rate is amazing, and these switches connect every Blackwell together, so there is a huge 72 GPU Blackwell.
The benefit of that is that in a domain, a GPU domain now looks like a GPU that has 72 of them versus eight in the previous generation. So a nine-fold increase in bandwidth. An 18-fold increase in AI floating point performance, a 45-fold increase. And the power consumption is only increased by 10 times, that's 100 kilowatts versus 10 kilowatts. This is a.
Of course, you can always connect more of these together, and I'll show you how to do that in a moment. But the magic is this chip, this NVLink chip. People are starting to realize how important this NVLink chip is, because it connects all these different GPUs. Because LLMs are so large that they can't just fit on one GPU, and they can't just fit on one node. It takes an entire rack of GPUs, like the new DGX that I was just standing next to, which can accommodate trillions of parameters of LLMs.
The NVLink switch itself is a technological marvel, with 50 billion transistors, 74 ports, 400Gbps per port, and 7.2Tbps of cross-sectional bandwidth. But the important thing is that it has mathematical computing power inside the switch, which is very important in deep learning, and can perform reduction operations on the chip. So this is the DGX now.
Huang Renxun said that many people asked, and some people were confused about Nvidia's work, why Nvidia became so big by making GPUs. So some people thought that this is what a GPU looks like.
Now this is a GPU, this is one of the most advanced GPUs in the world, but this is a gaming GPU. You and I know this is what a GP looks like. This is a GPU, ladies and gentlemen, a DGX GPU. You know that on the back of this GPU is the NVLink backbone. The NVLink backbone has 5,000 wires, two miles long, and it connects the two GPUs together, and it's an electrical, mechanical marvel. The transceivers enable the ability to drive the entire length on copper wire, which can save 20 kilowatts of power in a rack.

Huang Renxun said there are two types of networks. InfiniBand is widely used in supercomputing and AI factories around the world, and its growth rate is amazing. However, not every data center can handle InfiniBand because they have invested too much Ethernet in their ecosystem, and managing InfiniBand switches and networks requires some expertise.
So Nvidia brought InfiniBand capabilities to the Ethernet architecture, which was very difficult. The reason is simple. Ethernet is designed for high average throughput because every node, every computer is connected to different people on the Internet, and most of the communication is between the data center and the person on the other side of the Internet.
However, deep learning and AI factories, GPUs are mostly communicating with each other. They communicate with each other because they are collecting partial products and then reducing and redistributing them. Partial product collection, reduction and redistribution. This traffic is very bursty, and it's not the average throughput that matters, it's the last one to arrive. So NVIDIA created several technologies, created an end-to-end architecture to enable the network interface cards and switches to communicate, and applied four different technologies to do this. First of all, NVIDIA has the most advanced RDMA in the world, and now is able to do network-level RDMA on Ethernet, which is amazing.
Second, Nvidia has congestion control. The switches are constantly doing fast telemetry, and when a GPU or a network interface card is sending too much information, it can tell them to back off so they don't create hot spots.
Third, adaptive routing. Ethernet needs to be transmitted and received in order. Nvidia sees congested or unused ports and sends to available ports regardless of the order. BlueField reorders on the other end to ensure the order is correct. Adaptive routing is very powerful.
Finally, noise isolation. There are always multiple models training or other things going on in the data center, and their noise and traffic may interfere with each other and cause jitter. Therefore, when the noise of one training model causes the last one to arrive too late, the overall training speed will be significantly reduced.
Remember, you've built a $5 billion or $3 billion data center to train on. If network utilization is reduced by 40% and training takes 20% longer, a $5 billion data center is effectively the equivalent of a $6 billion data center. So the cost impact is very large. Ethernet with Spectrum X allows for a massive performance increase, and the network is essentially free.
Nvidia has a whole Ethernet product line. This is the Spectrum X800, 51.2Tbps, 256 ports. Next up is 512 ports, coming next year, called the Spectrum X800 Ultra, and then the X16. The important idea is that the X800 is designed for tens of thousands of GPUs, the X800 Ultra is designed for hundreds of thousands of GPUs, and the X16 is designed for millions of GPUs, and the multi-million GPU data center era is coming.
In the future, almost every interaction you have with the internet or a computer will have a generative AI running somewhere. This generative AI works with you, interacts with you, generates videos, images or text, or even a digital human. You are almost always interacting with a computer, and there is always a generative AI connected, some locally, some on your device, and most of it may be in the cloud. These generative AIs will also perform a lot of reasoning capabilities, not just a one-time answer, but improving the quality of the answer through multiple iterations. So the amount of content generated in the future will be amazing.
Blackwell is of course the first generation of NVIDIA's platform, released just as the world was realizing the age of generative AI was coming. Just as the world was realizing the importance of the AI factory, and at the beginning of this new industrial revolution. NVIDIA has the support of almost every OEM, computer manufacturer, cloud service provider, GPU cloud, sovereign cloud, and even telco. The success, adoption, and enthusiasm for Blackwell is really incredible. I want to thank everyone.
Huang Renxun continued, "During this amazing period of growth, NVIDIA must ensure that it continues to improve performance, continues to reduce training costs and inference costs, and continues to expand AI capabilities so that every company can accept it. The more NVIDIA drives performance up, the more costs go down. The Hopper platform is of course the most successful data center processor in history, and it's really an incredible success story."
However, Blackwell has arrived, and each platform, as you can see, consists of several things. You have the CPU, you have the GPU, you have NVLink, you have the network interface, and you have the NVLink switch that connects all the GPUs, as large a domain as possible. Whatever can be done, Nvidia connects it to a large, very high-speed switch.
With each generation, you're not just looking at the GPU, you're looking at the entire platform. Building the entire platform. Integrating the entire platform into an AI factory supercomputer. But then breaking it down and offering it to the world. The reason for doing that is because all of you can create interesting and innovative configurations and adapt to different data centers and different customer needs, some for edge computing, some for telecom. All of the different innovations are possible if you open up the system and enable you to innovate. So NVIDIA designed it integrated, but broke it down and offered it to customers so that you can create modular systems.
The Blackwell platform has arrived, and Nvidia's basic philosophy is very simple: build an entire data center every year, break it down and sell it in parts, push everything to the limit of technology, whether it's TSMC's process technology, packaging technology, memory technology, SerDes technology, optical technology, everything is pushed to the limit. Then, make sure all the software can run on the entire installed base.
Software inertia is one of the most important things in computers. You can get to market much faster when computers are backwards compatible and compatible with all the software architectures that have been created. So when you're able to leverage the entire installed base of software that's been created, the speed is amazing.

Huang Renxun said that Blackwell has arrived, and next year is Blackwell Ultra, just like there are H100 and H200, you may see some exciting new generation Blackwell Ultra, pushing the limit. The next generation Spectrum switch I mentioned is the first time to achieve this leap, and the next generation platform is called Ruben, and there will be Ruben Ultra platform in a year.
All of these chips that were shown are in full-speed development, 100% development. That's Nvidia's one-year cadence, all 100% architecture compatible, all the rich software that Nvidia is building.
AI Robots

Let me talk about what's coming next, the next wave of AI is physical AI, understanding the laws of physics, being able to work among us. So they have to understand the world model, understand how to interpret the world, how to perceive the world. And they certainly also need excellent cognitive abilities in order to understand our problems and perform tasks.
Robotics is a much broader concept. Of course, when I say robots, I usually mean humanoid robots, but that's not entirely correct. Everything will be robotic. All factories will be robotized, factories will coordinate robots, these robots will make robotic products, robots will collaborate with each other to make robotic products. In order to achieve this, some breakthroughs are needed.
Next, Huang Renxun showed a video that said:
The age of robots has arrived. One day, everything that moves will be autonomous. Researchers and companies around the world are developing robots powered by physical AI models that can understand instructions and autonomously perform complex tasks in the real world. Multimodal LLM is the breakthrough that enables robots to learn, perceive and understand the world around them, and plan their actions.
Through human demonstration, robots can now learn the skills needed to interact with the world using gross and fine motor skills. A key technology in advancing robotics is reinforcement learning. Just as LLM requires RLHF to learn a specific skill, generative physics AI can learn skills in a simulated world using physical feedback. These simulated environments are where robots learn to make decisions by performing actions in a virtual world that follows the laws of physics. In these robotic gyms, robots can safely and quickly learn to perform complex and dynamic tasks, improving their skills through millions of trial and error behaviors.
Nvidia built Nvidia Omniverse as an operating system for physical AI. Omniverse is a virtual world simulation development platform that combines real-time physical rendering, physical simulation, and generative AI technologies. In Omniverse, robots learn how to be robots. They learn how to manipulate objects autonomously and precisely, such as grasping and handling objects, or autonomously navigate the environment to find the best path while avoiding obstacles and hazards. Learning in Omniverse minimizes the gap between simulation and reality and maximizes the transfer of learned behaviors.
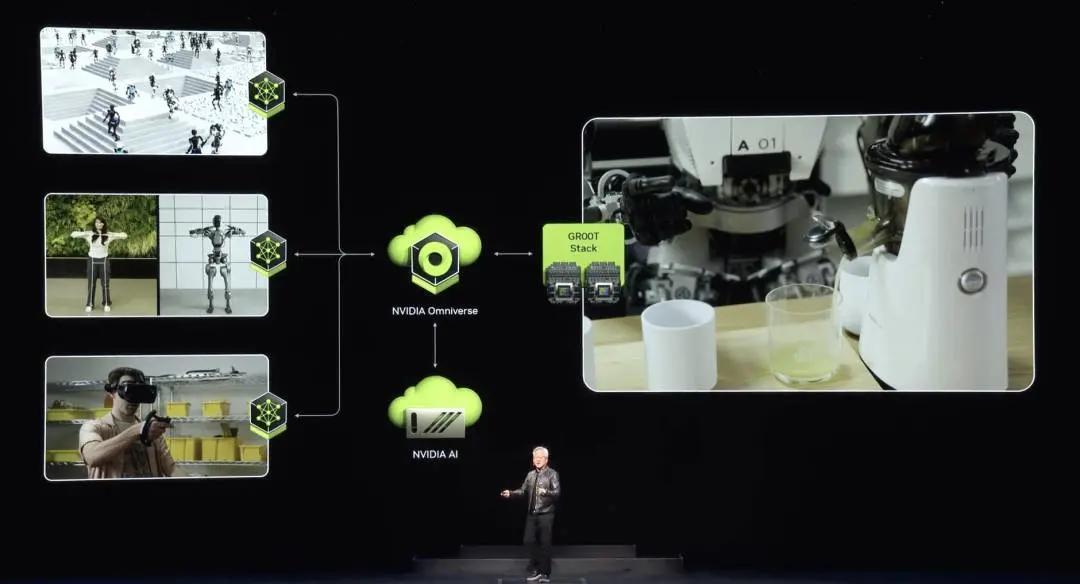
Building a robot with generative physical AI requires three computers: Nvidia AI supercomputers to train the models, Nvidia Jetson Orin and next-generation Jetson Thor robotics supercomputers to run the models, and Nvidia Omniverse, where the robots can learn and improve their skills in a simulated world. We built the platform, acceleration libraries, and AI models that developers and companies need, and allow them to use the stack that works best for them. The next wave of AI is here. Robots powered by physical AI will revolutionize every industry.
Huang mentioned that this is not the future, this is happening now. Nvidia will serve the market in several ways. First, Nvidia will create platforms for each type of robotic system, one for robotic factories and warehouses, one for robots that manipulate objects, one for mobile robots, and one for humanoid robots. So each robotic platform is like almost everything Nvidia does, a computer, acceleration libraries, and pre-trained models. Computers, acceleration libraries, pre-trained models. Everything is tested, trained, and integrated in Omniverse, where, as the video says, robots learn how to be robots.
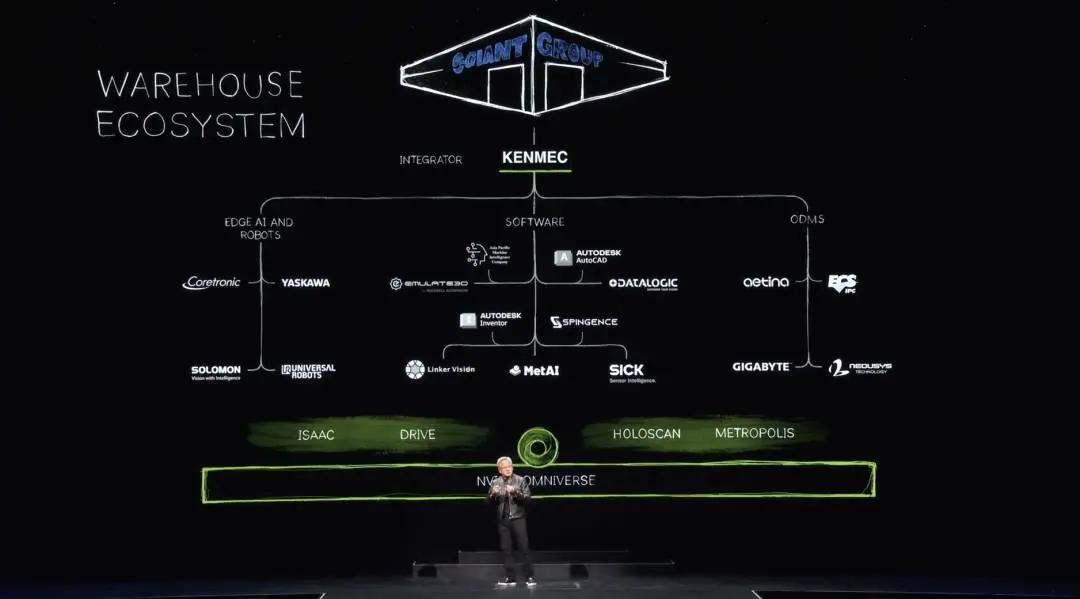
Of course, the ecosystem of robotic warehouses is very complex. It takes many companies, many tools, and many technologies to build a modern warehouse, and warehouses are becoming increasingly automated. One day, they will be fully automated. So in each ecosystem, there are SDKs and APIs that connect to the software industry, SDKs and APIs that connect to the edge AI industry and companies, and system integrations for PLCs and robotic systems designed for Odms. These are ultimately integrated by integrators to build warehouses for customers. Here is an example of a robotic warehouse built by Kenmac for Giant Group.
Huang Renxun went on to say that there is a completely different ecosystem for factories, and Foxconn is building some of the most advanced factories in the world. Their ecosystem again includes edge computers and robots, software for designing factories, workflows, programming robots, and PLC computers that coordinate digital factories and AI factories. Nvidia has SDKs that connect to each ecosystem, and this is happening throughout Taiwan.

Foxconn is building a digital twin of its factories. Delta is building a digital twin of its factories. Half real, half digital, half Omniverse, by the way. Pegatron is building a digital twin of its robotics factories, Quanta is building a digital twin of its robotics factories.
Huang Renxun continued to demonstrate a video, which mentioned:

As the world modernizes traditional data centers into generative AI factories, demand for Nvidia accelerated computing is soaring. Foxconn, the world’s largest electronics manufacturer, is preparing to build a robotic factory to meet this demand with Nvidia Omniverse and AI. Factory planners use Omniverse to integrate facility and equipment data from leading industry applications such as Siemens Team Center X and Autodesk Revit into digital twins.
In the digital twin, they optimized floor layouts and production line configurations and located optimal camera locations to monitor future operations using visual AI powered by Nvidia Metropolis. Virtual integration saved planners huge physical change order costs during construction. Foxconn teams use the digital twin as the source of truth for accurate equipment layouts for communication and verification.
The Omniverse digital twin also serves as a robotics gym, where Foxconn developers train and test Nvidia Isaac AI applications for robotic perception and manipulation, and Metropolis AI applications for sensor fusion.
Huang Renxun went on to say that in Omniverse, Foxconn simulated two robotic AIs before deploying the runtime to the Jetson computers on the assembly line. They simulated the Isaac Manipulator library and AI models for automatic optical inspection for object recognition, defect detection, and trajectory planning. They also simulated the Isaac Perceptor-driven Ferrobot AMRS, which perceive and move their environment through 3D mapping and reconstruction. Through Omniverse, Foxconn has built a factory of robots running on Nvidia Isaac, which build Nvidia AI supercomputers, which in turn train Foxconn's robots.
A robot factory is designed with three computers. First, AI is trained on Nvidia AI, then robots are run on PLC systems to coordinate factory operations, and finally everything is simulated in Omniverse. The same is true for the robot arm and the robot AMRS. The difference between the three computer systems is that the two Omniverses will be combined together to share a virtual space. When they share a virtual space, the robot arm will enter the robot factory. Once again, three computers, providing computers, acceleration layers, and pre-trained AI models.
Nvidia connected Nvidia Manipulator and Nvidia Omniverse with Siemens, the world's leading industrial automation software and systems company. It's really a great collaboration and they are working in factories around the world.
Semantic Pick AI now integrates Isaac Manipulator, and Semantic Pick AI runs and operates ABB, Kuka, Yaskawa, Fanuc, Universal Robotics, and Techman. So Siemens is a great integration.
Huang Renxun continued to demonstrate a video, which mentioned:
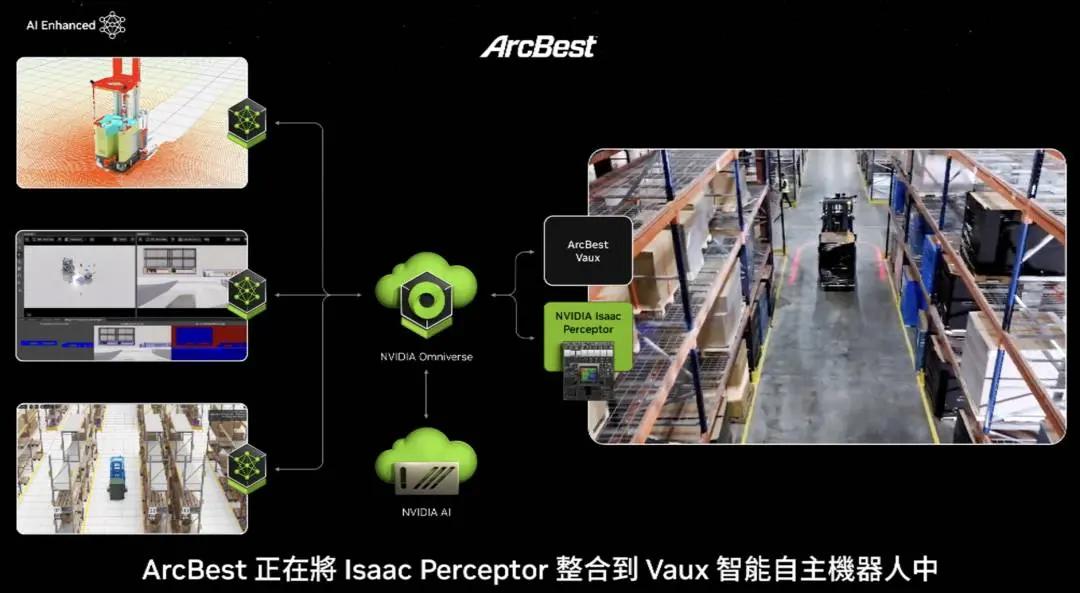
Arcbest is integrating Isaac Perceptor into its Fox intelligent autonomous robot to enhance object recognition and human motion tracking and material handling. BYD Electronics is integrating Isaac Manipulator and Perceptor into their AI robots to improve manufacturing efficiency for global customers. Ideal Works is integrating Isaac Perceptor into their iOS software for AI robots in factory logistics.
Gideon is integrating Isaac Perceptor into its pallet AI-driven forklift to advance AI-driven logistics. Argo Robotics is adopting Isaac Perceptor’s perception engine for advanced vision AMRS. Solomon is using Isaac Manipulator AI models in their Acupic 3D software for industrial operations. Techman Robot is integrating Isaac Sim and Manipulator into TM Flow to accelerate automated optical inspection. Teradine Robotics is integrating Isaac Manipulator into Polyscope X for collaborative robots and Isaac Perceptor into MiR AMRS.
Vention is integrating Isaac Manipulator into Machine Logic for AI-operated robots. Robotics is here, physical AI is here.
Huang Renxun continued, "This is not science fiction, it is being widely used throughout Taiwan, it is really very exciting. This is the factory, the robots inside, and of course all the products will also be robotized."
There are two very high volume robotics products. One is of course the self-driving car or the car with highly autonomous capabilities. And again, Nvidia built the entire stack.
Next year, Nvidia will go into production with Mercedes. After that, in 2026, it will be JLR. Nvidia offers the entire stack to the world. However, you can choose any part of the Nvidia stack, any layer, just like the entire Drive stack is open.
The next high-volume robotic product to be manufactured by robots in robotic factories may be humanoid robots. Huge advances have been made in cognitive abilities and world understanding in recent years, thanks to foundational models and technologies being developed by Nvidia.
Huang said he is very excited about this area because obviously the easiest robots to adapt to the world are humanoid robots, because we build this world for ourselves and we can provide a lot of training data through demonstrations and videos, far more than other types of robots. So Nvidia will see a lot of progress in this area.

The next wave of AI. Taiwan doesn't just make computers with keyboards, it makes computers for pockets, it makes computers for data centers. In the future, you're going to make computers that walk around, and computers that roll around. These are all computers. It turns out that the technology to build these computers is very similar to the technology for all the other computers you've built today, and it's going to be a pretty extraordinary journey.





