Intel and Microsoft created Wintel, which dominated the computer era for many years.
In a sense, NVIDIA's CUDA is equivalent to the Windows of the CPU era, shouldering the heavy responsibility of building an application ecosystem. The barriers to the ecosystem are more profound than the competitive barriers of chip performance. Therefore, CUDA is NVIDIA's biggest trump card.
In the CPU era, we were suppressed by Wintel for many years. In the AI era, will Nvidia, which integrates GPU and CUDA, be another Wintel that is difficult to break? At present, it seems so.
Due to the US's suppression of China's AI industry, the chip card is being used more and more frequently. Not only the US government, but also Nvidia itself is increasingly inclined to "play cards" for commercial competition. And CUDA is Nvidia's biggest trump card. If China wants to break through the blockade in the field of AI computing, it must not only have its own GPU, but also its own CUDA. To accomplish this, it seems that Huawei is the only one who can do it.
CUDA is Nvidia's deepest moat
In the world of graphics rendering, NVIDIA has won the favor of the market with its superb GPU technology. However, NVIDIA did not stop there. Its sights have long gone beyond the boundaries of graphics rendering and invested in the broader field of computing. In 2006, NVIDIA launched CUDA (Compute Unified Device Architecture), which marked NVIDIA's magnificent transformation from a graphics rendering giant to a computing giant.

There are several key nodes in the development of CUDA:
2007: The release of CUDA 1.0 opened up the general computing power of GPUs and provided developers with the key to enter the world of GPU programming.
2008: CUDA 2.0 adds support for double-precision floating-point operations, which is critical for areas such as scientific computing and engineering simulation.
2010: CUDA 3.0 further expanded the parallel processing capabilities of the GPU, providing support for more complex computing tasks.
2012: CUDA 5.0 introduced dynamic parallelism, allowing GPU kernels to replicate themselves, greatly improving program flexibility and efficiency.
These versions not only promoted the advancement of CUDA technology, but also became important milestones in the development history of GPU parallel computing.

The core of CUDA lies in its innovative parallel computing model. By breaking down computing tasks into thousands of threads, CUDA can achieve unprecedented parallel processing capabilities on the GPU. This model not only greatly improves computing efficiency, but also makes the GPU an ideal platform for solving complex computing problems. From deep learning to scientific simulation, CUDA defines a new era of parallel computing and opens a new chapter in high-performance computing.
With the rise of AI and big data, CUDA's market influence continues to expand. Developers are turning to CUDA to leverage the powerful computing power of GPUs to accelerate their applications. Enterprises have also recognized the value of CUDA and use it as a key technology to improve product performance and competitiveness. According to statistics, CUDA has been downloaded more than 33 million times.
For NVIDIA, CUDA has become its deepest moat. It not only consolidates NVIDIA's leadership in the GPU market, but also opens the door for NVIDIA to enter many cutting-edge fields such as high-performance computing, deep learning, and autonomous driving. With the continuous advancement of technology and the continuous expansion of the market, CUDA will undoubtedly continue to play the role of NVIDIA's deepest moat and lead the future of computing technology.
Can the Da Vinci architecture, which is 12 years later than CUDA, support Huawei's AI ambitions?
Da Vinci architecture, as Huawei's self-developed AI computing architecture, is closely related to Huawei's profound insight into the future application of AI. As early as a few years ago, Huawei predicted that by 2025, the number of smart terminals in the world will reach 40 billion, the penetration rate of smart assistants will reach 90%, and the utilization rate of enterprise data will reach 86%. Based on this prediction, Huawei proposed a full-stack, full-scenario AI strategy at the 2018 All-Connect Conference and designed the Da Vinci computing architecture to provide strong AI computing power under different volume and power consumption conditions.
The development of the Da Vinci architecture can be traced back to 2018, when Huawei's AI chip Ascend 310 made its debut, marking the official application of the Da Vinci architecture. Then, in June 2019, Huawei released the new 8-series mobile phone SoC chip Kirin 810, which adopted the Da Vinci architecture NPU for the first time and achieved industry-leading edge AI computing power. Kirin 810 performed well in the AI Benchmark list, proving the strength of the Da Vinci architecture.
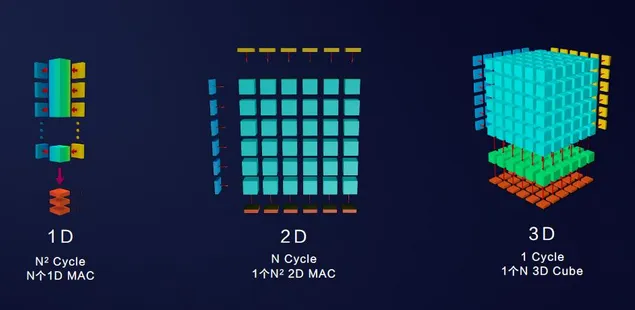
The Da Vinci architecture is a new computing architecture designed specifically for AI computing features, with high computing power, high energy efficiency, and flexible customization. Its core advantage lies in the use of 3D Cube to accelerate matrix operations. Each AI Core can perform 4096 MAC operations in one clock cycle, an order of magnitude improvement over traditional CPUs and GPUs. In addition, the Da Vinci architecture also integrates multiple computing units such as vectors, scalars, and hardware accelerators, and supports multiple precision calculations to support data accuracy requirements for both training and reasoning scenarios.
The Da Vinci architecture has a wide range of applications, covering all-scenario AI applications from the edge to the cloud. On the edge, the AI computing power of the Kirin 810 chip has been applied in smartphones, providing consumers with a rich AI application experience. On the edge and cloud, the Ascend series of AI processors can meet training scenarios ranging from tens of milliwatts to hundreds of watts, providing the best AI computing power. The flexibility and efficiency of the Da Vinci architecture enable it to play an important role in smart cities, autonomous driving, industrial manufacturing and other fields.
Indeed, the Da Vinci architecture occupies a core position in Huawei's AI market layout. It is not only the technical foundation of Huawei's AI chips, but also an important support for Huawei to achieve a full-stack, full-scenario AI strategy. Through the Da Vinci architecture, Huawei can provide a full-stack AI solution from hardware to software, accelerating the industrialization and application of AI technology. In addition, the uniformity of the Da Vinci architecture also brings convenience to developers, reduces development and migration costs, and promotes the innovation and development of AI applications.
Da Vinci VS CUDA, what are the chances of winning?
Compared with CUDA, which was launched in 2006, Huawei Da Vinci was launched 12 years later. During these 12 years, Da Vinci has been catching up. In addition to the time gap, Da Vinci and CUDA also have significant differences in architecture design philosophy, performance, tool chain, developer ecology and other aspects.
In terms of design philosophy, CUDA is a parallel computing platform and API model developed by NVIDIA, which allows developers to use NVIDIA's GPU for efficient parallel computing. The Da Vinci architecture is a new computing architecture developed by Huawei for AI computing features. It uses 3D Cube to accelerate matrix operations, greatly improving AI computing power per unit power consumption. CUDA's design focuses more on versatility, while Da Vinci focuses on the efficiency of AI computing.
In terms of AI computing performance, CUDA and Da Vinci each have their own advantages. With years of technological accumulation, CUDA supports large-scale parallel processing capabilities and is suitable for handling various complex computing tasks. The Da Vinci architecture optimizes matrix operations through its 3D Cube computing engine, achieving a significant increase in AI computing power per unit area. In AI application scenarios such as deep learning, the Da Vinci architecture has demonstrated excellent performance.
CUDA and Da Vinci architectures have different focuses in their applicability in different fields. Due to its versatility, CUDA is widely used in scientific research, medicine, finance and other fields. The Da Vinci architecture is mainly aimed at AI computing, especially in AI application scenarios on the device side, edge side and cloud side, such as smartphones, autonomous driving, cloud services, etc.
From a developer's perspective, CUDA and Da Vinci architectures differ in the ease of use of programming models and tool chains. CUDA provides a complete set of development tool chains, including CUDA compilers, debuggers, performance analysis tools, etc., supporting multiple programming languages and deep learning frameworks. Although the Da Vinci architecture started late, Huawei is also actively building its tool chain and developer ecosystem, providing necessary support to promote developer use and innovation. However, in terms of the completeness and richness of the tool chain, Da Vinci still has a long way to go to CUDA.
CUDA has established a huge developer community and ecosystem through its wide application and mature technology. Building an ecosystem is more difficult than simply improving GPU performance, and this is the real test for Huawei.
Huawei GPU is almost ready, but it is still far from building its own CUDA
Currently, Huawei's GPU development trend is good.
According to public information, Huawei's computing GPU shipments in 2023 will be about 100,000 units. With the increase in production capacity, this number is expected to double to hundreds of thousands of units by 2024. Despite the increase in production capacity, the market demand for orders is still very strong, with orders in January 2024 alone reaching hundreds of thousands of units. At present, the demand for orders has reached millions of units, far exceeding Huawei's current supply capacity.
In terms of domestic purchases, Huawei's computing GPU has been enthusiastically sought after by the market. Huawei's computing GPU customers are mainly divided into three echelons: the first category is the three major operators and government customers, the second category is Internet customers, and the third category is other companies. Due to the shortage of computing GPUs, customers are trying to become first-tier customers in order to get the products as soon as possible, and even take measures such as cooperating with local governments to ensure priority supply.
In terms of price, Huawei's computing GPU has experienced at least two price increases since it was launched in August 2023. The initial listing price was about 70,000 yuan, and the current market price has risen to about 120,000 yuan.
Overall, Huawei GPU has a good development trend and strong market demand. Although the supply is tight, this also reflects the advantages of Huawei GPU in performance and localization, making it a popular choice in the market. With the continuous advancement of technology and further improvement of production capacity, Huawei GPU is expected to occupy a more important position in the future market.
In an interview, Huang Renxun said: "Huawei is a good company." In addition, Nvidia listed Huawei as a major competitor in its financial report, which reflects that Huawei's competitiveness in the field of GPU and related technologies is increasing.
Although Huawei's GPU development is in good shape, CUDA, as the dominant framework in the GPU field, has a much more mature and widely accepted ecosystem than other frameworks, including those developed by AMD. Huawei's AI computing framework still has a long way to go in terms of ecosystem construction, and it needs continuous technological innovation and market promotion to gradually build an ecosystem that rivals CUDA.
However, Nvidia does not want to give Huawei time to grow.
Recently, NVIDIA has adjusted the compatibility policy of its CUDA platform, restricting the operation of CUDA software on non-NVIDIA hardware platforms. This decision began in 2021 and has been gradually strengthened in the following years. Specifically, NVIDIA has updated its End User License Agreement (EULA) to explicitly prohibit the use of translation layers or emulation layers to run CUDA code on non-NVIDIA GPUs.
This policy change mainly affects third-party projects that attempt to achieve CUDA compatibility through translation technology, such as ZLUDA. ZLUDA is a translation library that allows CUDA programs to run on non-NVIDIA hardware. It provides a relatively simple way for developers to run CUDA programs with a slight loss in performance.
Nvidia's move is widely seen as a strategic move to protect its market share and maintain control of its technology. By restricting the use of CUDA software on other chips, Nvidia ensures that its GPUs remain the first choice for developers and businesses that rely on its parallel computing platform.
However, this decision caused quite a stir in the industry and sparked widespread discussion, with many people accusing Nvidia of using the blockade policy to monopolize the market and suppress the development opportunities of its competitors.
Faced with Nvidia's restrictive policies, some domestic GPU companies such as Moore's Threads chose to comply with the EULA regulations and stated that they would recompile the code to be consistent with the EULA to avoid violating Nvidia's restrictive terms.
In addition, other forces in the industry, including AMD, Intel and other manufacturers, have not stopped because of Nvidia's restrictions. They are actively promoting the construction of an open and portable ecosystem in an attempt to break Nvidia's market monopoly.
In the face of Nvidia's move, Huawei needs to rely more on self-developed software tools and development environments when developing its own GPU technology, rather than relying on mature platforms such as CUDA. This means that Huawei needs to invest more resources to build its own software ecosystem, including developing programming tools, libraries, and APIs that match CUDA performance.
It can be foreseen that for a long time in the future, due to the widespread use of CUDA and its profound impact on high-performance computing, AI and other fields, Nvidia's policy may limit the market acceptance of Huawei GPUs, especially in those fields that are already deeply dependent on CUDA.
This has increased the urgency for Huawei to build its own AI computing architecture and AI ecosystem. Just like the Android supply cut made Hongmeng a success, will the tightening of CUDA become a god assist for Huawei's Da Vinci architecture? It is hard to judge now, so let's wait and see.