Author: Iris Chen, Dr. Ni

1. AI+3D pipeline significantly reduces costs and increases efficiency
The popularity of ChatGPT in 2022 triggered a wave of AIGC. Generative AI has had a disruptive effect on many industries. The 3D content fields in scenarios such as games, film and television, and 3D printing are also reshaping the industry landscape under the influence of generative AI. Compared with the industrial scene CAD and architectural scene BIM that pursue accuracy, the 3D content in these scenarios pursues creativity more, and generative AI can have a greater place to play.
3D generation technology refers to the use of deep neural networks to learn and generate 3D models of objects or scenes, and to give colors and light and shadows to objects or scenes based on the 3D models to make the generated results more realistic, including research directions such as AI modeling, AI skeleton binding, AI expressions, AI actions, and AI rendering. The 3D content industry chain includes a basic layer that provides technology, an intermediate layer that provides assets, and an application layer for asset development. The technology providers of the basic layer provide the industry with basic tools for producing 3D content. 3D generation technology mainly replaces traditional production tools at this layer to promote industry development.

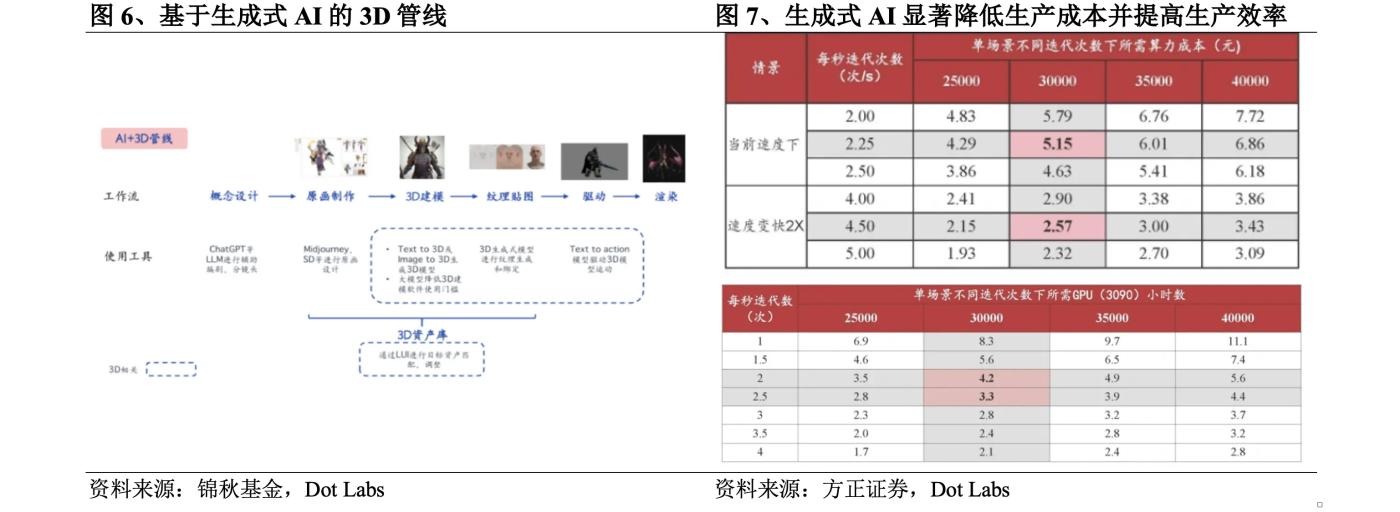
The traditional 3D pipeline includes concept design, original painting production, 3D modeling, texture mapping, driver and rendering. Among them, the production cycle of 3D related links such as original painting production, 3D modeling, texture mapping is long and highly dependent on manual labor, which is the main source of R&D costs. Taking 3D games as an example, 3D related links in 3D games usually account for 60-70% of the R&D costs, among which the cost of 3D modeling is extremely high. If a manufacturer entrusts an outsourcing team to produce a 3D high-poly resource with more than 100,000 faces, the price will be at least 30,000 yuan, and it will take 30-45 days. If purchased in the 3D asset library, in addition to the problem of limited optional assets, it usually takes 5-10 people/day to clean it before it can be used. According to data from Sketchfab, the world's largest 3D content company, the cost of producing a 3D model is about US$3-40 and the time required is about 2-15 hours.

Generative AI can play a role in almost all aspects of the traditional 3D pipeline. Many game studios now have a Midjourney and Stable Diffusion for each art member. The application of large models has also lowered the threshold for 3D modeling. The 3D pipeline based on generative AI can reduce the production cost of 3D content and improve production efficiency. Take the Steam game "Phantom Beast Palu" which was a big hit in early 2024 as an example. It takes a modeler one month to make a 3D model of a Palu (a creature in the game). Each Palu requires about 20 actions, and it takes an additional 20 days to calculate one action per day. There are about 100 types of Palu in the game. According to the production method of the traditional 3D pipeline, it takes a total of about 5,000 days. The studio uses generative AI to complete the work within 3 years.
According to Founder Securities' estimates, the cost of generating a 3D asset by iterating the Zero123 method 30,000 times using an RTX 3090 graphics card is about 5 yuan. In the future, as the method matures and the iteration speed becomes twice as fast, the cost will drop to 2.6 yuan, and a single scene will only take about 3.3-4.2 hours. Compared with the previous 3-40 US dollars and 2-15 hours, the application of generative AI has significantly reduced production costs and improved production efficiency.
2. Development of 3D Generation Technology
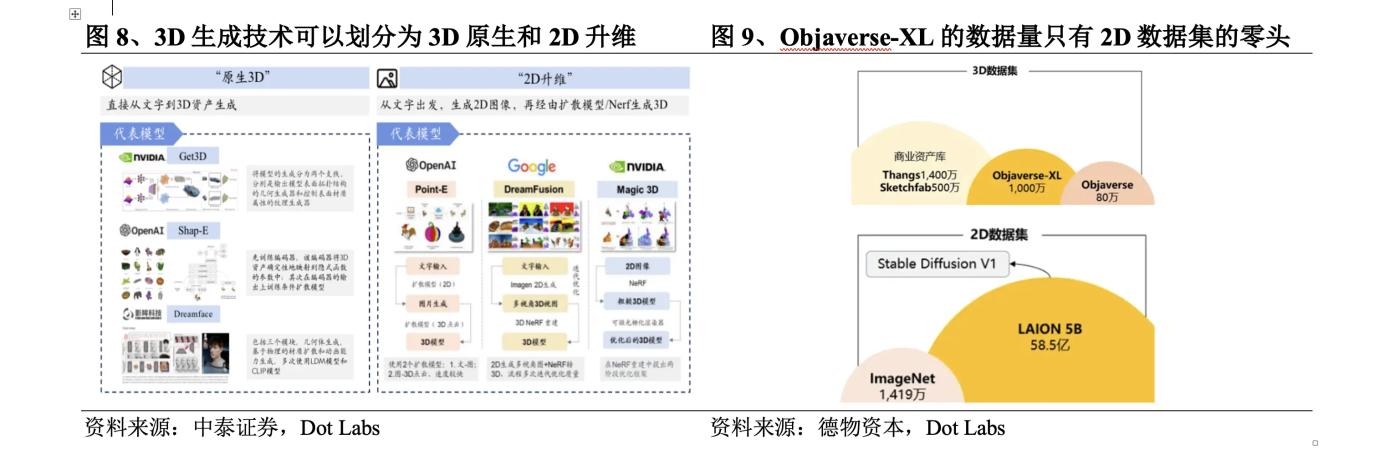
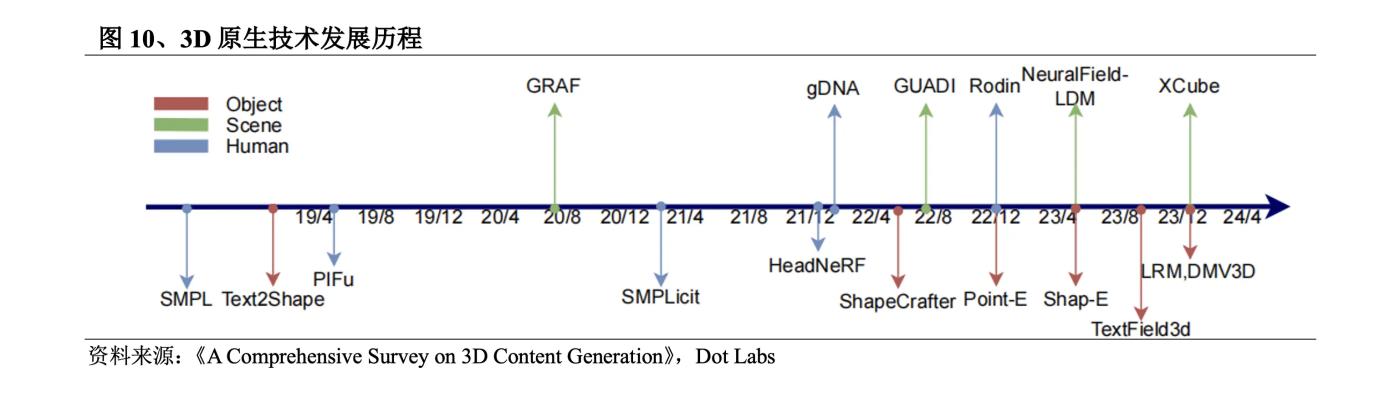
The research on 3D generation technology was initially carried out in the fields of computer vision and graphics. As early as 1970, MIT professor Berthold KP Horn proposed Shape from shading, which restored the 3D model based on the light and shade information in the image with the help of the reflected lighting model. In 2023, 3D generation technology has experienced a blowout development, and the generation quality, speed and richness have been greatly improved. The opportunities are: ① 3D datasets have grown from the early small-scale ShapeNet to Objaverse (December 2022) and Objaverse XL (July 2023), of which the Objaverse-XL dataset contains 10.2 million 3D assets, an order of magnitude more than Objaverse; ② The birth of neural fields that express 3D content as neural network parameters; ③ The development of 2D pre-trained models promotes multi-view reconstruction.
3D generation technology can be divided into two development routes: 3D native and 2D dimensionality upgrade. 3D native usually uses 3D data sets for training. From training to reasoning, it is based on 3D data, and 3D content is directly generated from text/images. However, the 3D data sets that can be learned are very limited. Even the largest open source 3D data set Objaverse-XL has only a fraction of the data volume of 2D data sets. To solve this problem, some studies have tried to use 2D data sets for training, from text to 2D images, and then generate 3D content through diffusion models or NeRF models. This is 2D dimensionality upgrade.
1. 3D native route
The 3D native route uses 3D datasets for training, enabling the generation of 3D content directly from text/image input. The main advantages and disadvantages are:
Advantages
High generation quality: Since 3D datasets are used, they are highly targeted within a specific range and can generate high-quality 3D content. For example, high-quality 3D face data can be used to train high-quality 3D faces of 4k or above, while avoiding the multi-faceted problems of 2D dimensionality increase.
Fast generation speed: 2D dimensionality upgrading usually uses diffusion models or NeRF models to guide the optimization of 3D representation, which requires multiple iterations and is time-consuming. 3D native can generate 3D directly from text/pictures.
Strong compatibility: Geometry and textures are usually generated separately, and can be subsequently edited directly in standard graphics engines.
Disadvantages
Insufficient richness: There is a lack of high-quality, large-scale 3D datasets, and the data quality and consistency are poor, which restricts the model's imagination and makes it difficult to generate objects or combinations that have not been seen in the dataset.
The methods used in 3D native in the early days include VAE models, flow models, GAN models, EBM models, etc. Among them, the advantages of the GAN model in terms of generation effect have made it the mainstream model of 3D native before 2022. However, due to the training pathology problem of GAN, it is difficult to train on data that does not have a standard coordinate system. The training is extremely difficult and has extremely high hardware requirements. In September 2022, Nvidia released Get3D, which can generate 3D content with high-fidelity textures and complex geometric details. After that, OpenAI released Point-E and Shap-E, breaking the quantitative restrictions on 3D data and subtitles, collecting millions of 3D resources and corresponding text subtitles, and supporting 3D generation with a large vocabulary. The recently popular LRM combines an efficient neural network architecture with a large-scale multi-view dataset to achieve a rapid conversion from a single image to a high-fidelity 3D model. DMV3D proposed a T-step diffusion model to improve LRM and achieve higher-quality result generation.
(1) Get3D rich geometric details and textures
In September 2022, Nvidia released Get3D. The generation process of Get3D is divided into two parts: ① The geometry branch part can output the surface mesh of arbitrary topology; ② The texture branch part generates the texture field to realize the query on the surface point.

The specific breakthroughs of this method are:
Before this method, the content generated by 3D generation technology lacked geometric details and textures. Under the generation process of Get3D , the 3D content has richer geometric details and can be textured.
The most advanced reverse rendering method at the time could only build one 3D object at a time. When trained on a single Nvidia GPU , Get3D can generate about 20 objects per second, and the larger and more diverse the training data set, the more diverse and detailed the output. The Nvidia research team said that it took only two days to train the model on about 1 million images using the A100 GPU .
It can generate a virtually unlimited amount of 3D content based on the data it was trained on. For example, given a dataset of 2D car images, Get3D can create a collection of cars, trucks, race cars, and vans.

(1) Shap-E greatly improves the generation speed
In May 2023 , OpenAI released Shap-E , which was improved on Point-E . The Shap-E process is: ① Train an encoder to generate implicit representations; ② Train a diffusion model on the latent representations generated by the encoder.
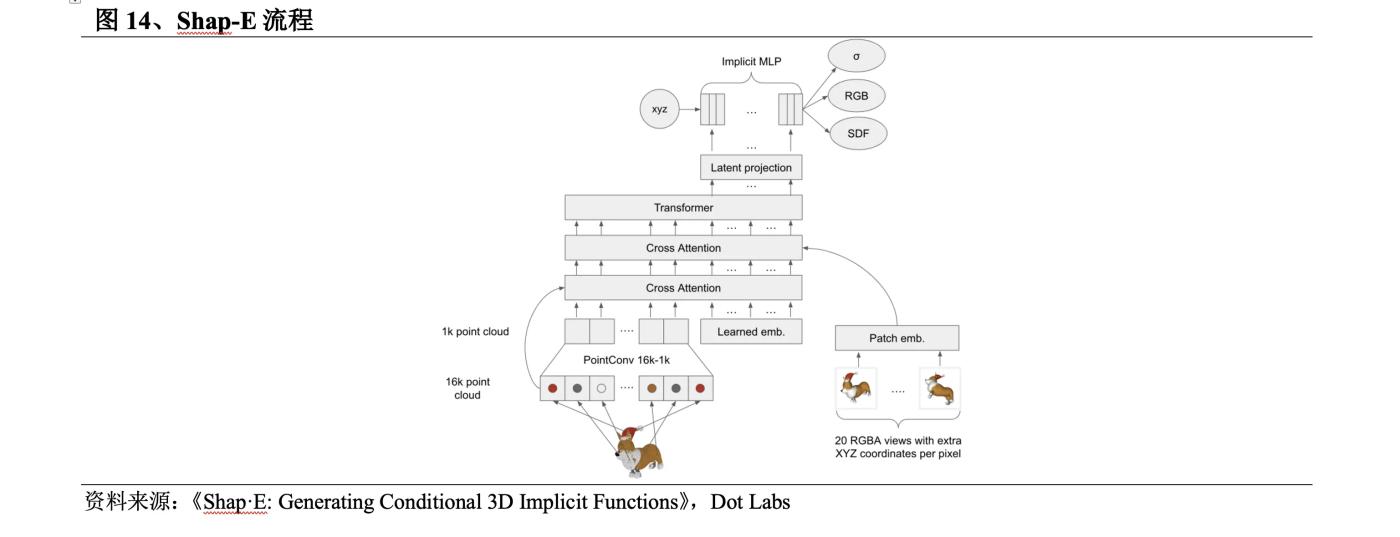
l Shap-E uses implicit representation to generate 3D models with both neural fields and textured meshes, which can be easily imported into 3D software for subsequent processing. Compared with other methods, Get3D can only generate meshes and Point-E can only generate point clouds.
After training with a large dataset of 3D and text correspondences, Shap-E can generate complex and diverse 3D models in seconds, is faster than Point-E in inference speed, and is orders of magnitude faster than other methods.
But like Point-E , Shap-E 's samples are of poor quality, and the encoder sometimes loses detailed textures.

(1) LRM sets off a wave of model reconstruction
In November 2023 , a research team from Adobe Research and the Australian National University introduced an innovative large-scale reconstruction model LRM . The method flow is: ① Apply the pre-trained visual model DINO to encode the input image; ② The image features are projected into the 3D three-plane space by the large Transformer decoder through cross attention and represented using the NeRF model; ③ Use the multi-layer perceptron MLP to predict the point color and density of volume rendering.
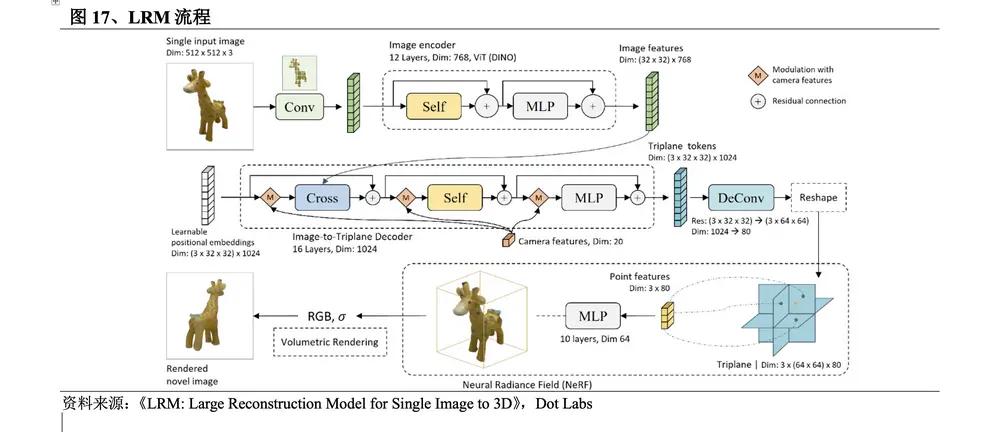
l Short time consumption. 2D dimensionality enhancement mainly uses the diffusion model to optimize the 3D representation through the optimization algorithm. Inference is training, which takes a long time. Other 3D native methods train the diffusion model on the 3D representation. Inference requires multiple iterations and takes a long time. LRM is a training regression model that directly infers the 3D representation in one step. It can generate a high-fidelity 3D object model from a single input image in just 5 seconds.
l Strong versatility. Unlike previous methods that were trained on specific categories on small datasets, LRM uses a highly scalable transformer -based architecture with 500 million learnable parameters and is end-to-end trained using about 1 million 3D objects in the Objaverse and MVImgNet datasets, which makes it highly versatile.
l Processing real-world images. LRM enables users to generate high-quality 3D models from photos taken with smartphones, expanding the democratization of 3D modeling and opening up unlimited creative and commercial possibilities.
LRM is the first large-scale reconstruction model. Its breakthrough lies in its ability to quickly and efficiently generate high-quality 3D images, which has brought changes to the fields of augmented reality, virtual reality systems, games, film and television animation, and industrial design. Its significant advantages in generation speed and quality have set off a wave of reconstruction models in the field of 3D generation technology. Many works have been improved on the basis of LRM , and a large number of reconstruction models have emerged.
The 2D dimensionality upgrade route uses 2D data sets for training, first from text to 2D images, and then generates 3D content through diffusion models or NeRF models. The main advantages and disadvantages are:
Advantages
Rich in richness: A large amount of 2D image data can be used for pre-training, and the generated 3D models are more complex and imaginative.
Disadvantages
Low generation quality: Limited by the balance between the number of samples, the number of viewing angles and computing resources, the current 2D dimensionality upscaling method is relatively rough in terms of resolution and texture details, and the 3D prior capabilities of the diffusion model are insufficient, and the generation results are prone to unreasonable geometric structures.
Slow generation speed: Both the training and inference processes of NeRF require a lot of computing resources and dense sampling of 3D space, which is time-consuming.
Weak compatibility: The NeRF format cannot be directly edited in 3D engines such as Unity . It needs to be converted into 3D meshes through Matching cubes and then edited in the 3D engine. It has weak compatibility.
In 2018 , the neural field that expresses 3D content as neural network parameters was born. Although the neural field still expresses 3D data and developed slowly during 2018-2020 due to the lack of learning data, it laid the technical foundation for 2D dimensionality upgrade. In 2020 , a joint team from Berkeley, Google, and UC San Diego proposed the NeRF algorithm, which generates images with high accuracy and can generate 3D perception images of large scenes, greatly accelerating the development of 2D dimensionality upgrade. However, due to the difficulty of training, high hardware requirements, and low generation efficiency, it can only be used in a small range of experimental and entertaining applications. In 2022 , 2D image generation applications represented by Stable Diffusion and Dall·E developed rapidly, which increased the commercial value of 2D dimensionality upgrade, and technological development accelerated again. In terms of specific technological development, the initial exploration of 2D dimensionality upgrading was DreamFields released by Google at the end of 2021. In September 2022 , it released DreamFusion , which was improved on this basis. It used the Imagen diffusion model to calculate the loss and the SDS method for sampling, which significantly improved the quality of text to 3D . Later, Nvidia released Magic3D , introducing a two-stage optimization strategy to improve generation speed and quality. ProlificDreamer uses VSD to solve the problems of oversaturation, oversmoothing and low diversity of the SDS method. DreamGaussian integrates 3D Gaussian into the creation of 3D content. Since then, 3D Gaussian has largely replaced NeRF . In the past six months, a large number of series of improvements based on 3D Gaussian have appeared. 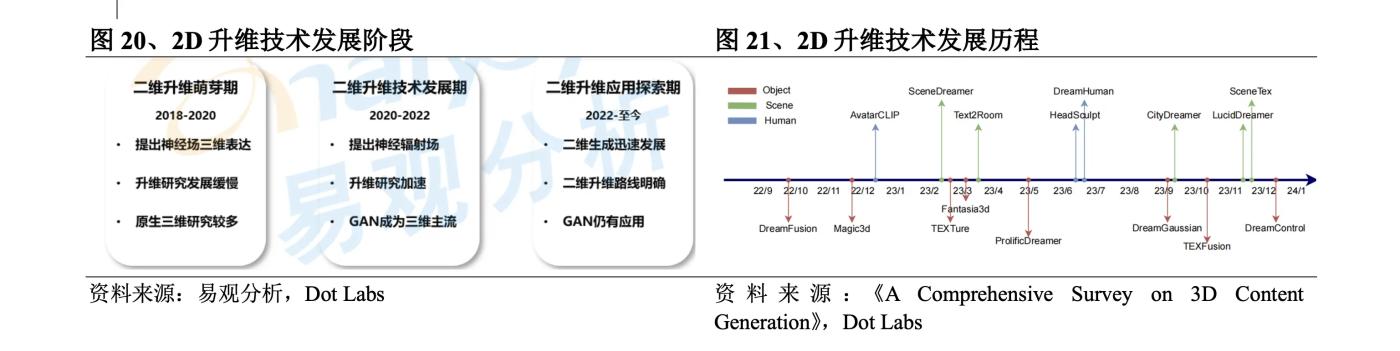
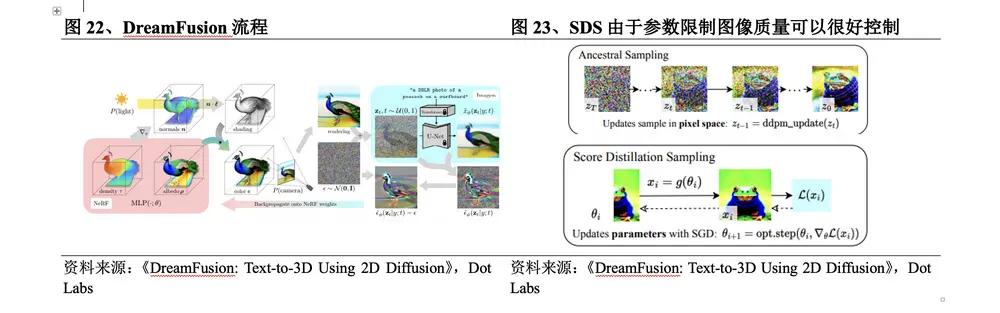
(1) Dreamfusion develops a new type of loss calculation
In September 2022 , Google released DreamFusion , which was improved on the basis of its DreamFields . The DreamFusion process is: ① Use NeRF to render the image at a predetermined position, and mix it with the Gaussian distribution to obtain a noisy image; ② Input the image into the Imagen diffusion model, and use a random weight initialization model similar to NeRF ; ③ The repeatedly rendered view is used as the input of the SDS function surrounding Imagen . The specific breakthroughs of this method are:
The loss is calculated through the Imagen diffusion model from text to image to replace CLIP , which is equivalent to a NeRF optimized by the diffusion model, and the 3D model is optimized.
l Using the new image sampling method SDS , sampling is performed in parameter space rather than pixel space. Due to parameter constraints, the quality trend of the generated image can be well controlled.
In the process of generating images, the parameters will be optimized to become a training sample of the diffusion model. The parameters after the diffusion model training have multi-scale characteristics, which is more conducive to the subsequent image generation. In addition, the diffusion model can directly predict the update direction without the need for back propagation.
Although DreamFusion improves the structural accuracy of 3D models and the realism of rendering, it requires 15,000 optimizations to generate 3D content, and each model takes 1.5 hours to generate, which is too time-consuming and cannot meet the requirements of industrial-level applications in terms of scale, rendering and structural details.
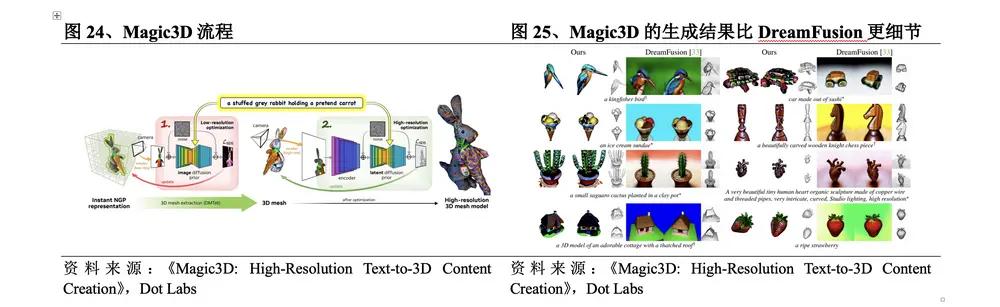
(2) Magic3D two-stage optimization to improve quality and speed
In November 2022 , Nvidia released Magic3D , which performs two-stage optimization based on DreamFusion . The Magic3D process is: ① Low-resolution optimization. The SDS loss is calculated by repeatedly sampling and rendering low-resolution images, and the results are given using its 3D reconstruction model Instant NGP . DMTet is used to extract the initial 3D mesh as input for the second stage; ② High-resolution optimization. The high-resolution image is sampled and rendered in the same way, and the final result is updated using the same method. Compared with DreamFusion , the specific breakthroughs of this method are:
lHigher quality. The resolution of Magic3D is 8 times higher than DreamFusion , and the results generated by Magic3D are more detailed.
Faster generation speed. Magic3D can create high-quality 3D mesh models in 40 minutes, 2 times faster than DreamFusion .
lBetter connection. Since Magic3D 's rendering method is closely related to traditional computer graphics, and its generated results can be directly viewed in standard image software, it can be better connected with traditional 3D generation work and has the ability to carry out industrial applications.
(3) DreamGaussian uses 3D Gaussian instead of NeRF
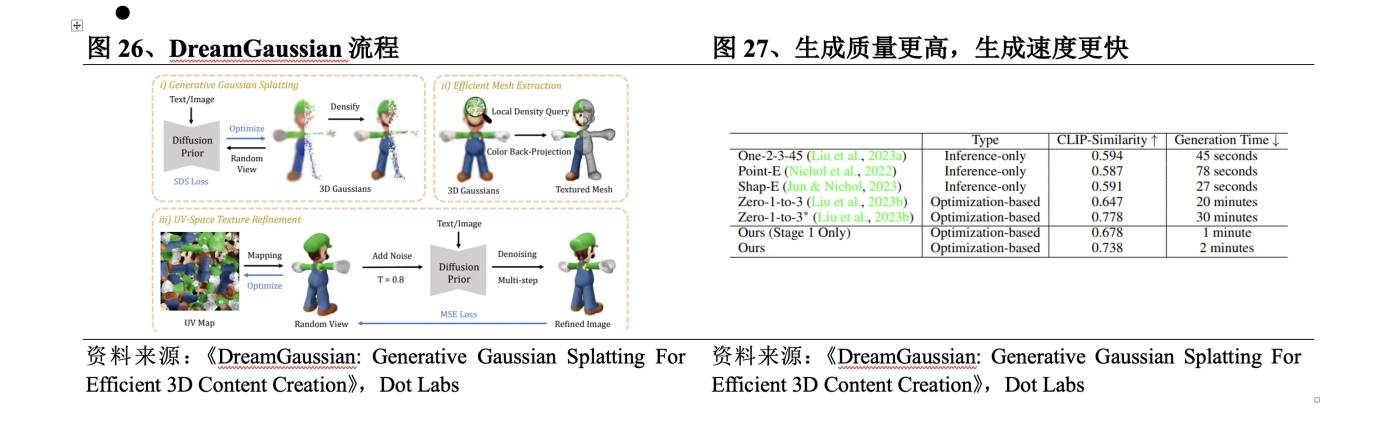
In September 2023 , authors from Baidu, Nanyang Technological University and Peking University jointly released DreamGaussian . The DreamGaussian process is: ① Use 3D Gaussian Splatting in UV space to model the content indicated by text or image; ② Use SDS Loss to optimize and extract texture mesh; ③ Refine the texture of the image on the mesh through multiple rounds of calculation of MSE Loss . Compared with the NeRF -based method, the specific breakthroughs of this method are:
lHigher generation quality. DreamGaussian has designed an algorithm for extracting meshes from 3D Gaussians and a UV space texture refinement stage to further improve generation quality.
l Faster generation. By adapting Gaussian segmentation to the generation setting, the generation time of 2D dimensionality-raising methods is significantly reduced. DreamGaussian can generate 3D content with clear meshes and texture mapping from a single-view image in 2 minutes, which is about 10 times faster than existing methods.
Early 2D dimensionality-enhancing methods mainly used 2D data sets for training, and could only extract limited 3D geometric knowledge. In March 2023 , Dr. Liu Ruoshi of Columbia University published Zero123 , exploring that injecting 3D information into 2D pre-trained models can effectively make up for the problem of insufficient 3D prior capabilities of diffusion models. As a result, a multi-perspective reconstruction method of 3D models obtained by 3D reconstruction after generating images from multiple perspectives has emerged. Later, based on Zero123 , Professor Su Hao's team at the University of California, San Diego proposed One-2-3-45 and One-2-3-45++ , using diffusion models to achieve better generation generalization, while using limited 3D data to achieve relatively correct geometric structures, as well as ByteDance's release of MVDream , VAST 's release of Wonder3D , and Meta 's release of MVDiffusion++ .
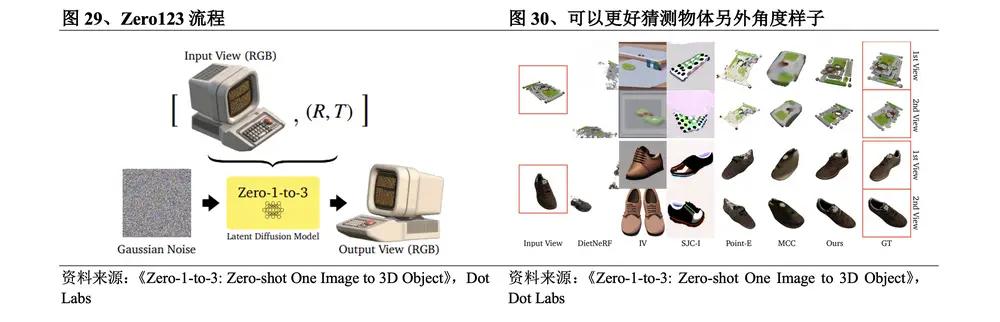
(1) Zero123 enables multi-view reconstruction
In March 2023 , the research team at Columbia University released Zero123 . The Zero123 process is: ① Input a single RGB image for encoding; ② De-noise the noisy image; ③ Select another camera perspective to generate a new perspective image; ④ Add these multi-perspective images to the diffusion model for training and 3D reconstruction. The specific breakthrough of this method is that although the order of 3D reconstruction and new view synthesis is reversed, the identity of the object described in the input image is retained, so that the probability generation model when rotating the object can be used to simulate the random uncertainty caused by self-occlusion, and the semantics and geometric priors learned by the diffusion model are effectively utilized. The diffusion model already knows the true appearance of 3D objects from multiple angles during the training process, and can better guess the appearance of the object from other angles.
(2) MVDream fine-tuning supports personalized generation
In August 2023 , ByteDance released MVDream . The MVDream process is: ① Convert the original 2D self-attention layer to 3D by connecting different views in the self-attention layer, and add camera embedding for each view; ② Use the multi-view diffusion model as a priori for 3D optimization and perform 3D generation through SDS . The specific breakthroughs of this method are:
By utilizing the image diffusion model pre-trained on a large-scale network dataset and a multi-view dataset rendered from 3D resources, the resulting multi-view diffusion model can achieve both the universality of 2D diffusion and the consistency of 3D data. Compared with the current open source 2D dimensionality increase method, better stability and quality can be achieved.
The multi-view diffusion model can be trained and fine-tuned in a few-shot setting, allowing users to perform personalized 3D generation.
3. Commercialization of 2D dimensionality-enhancing methods is expected
Through continuous development and improvement, 3D generation technology has made great progress in generation quality, speed and richness. If the following problems can be better solved, 3D generation technology will have a promising future:
l Dataset. Insufficient training data is an important reason that restricts the development of 3D generation technology, mainly due to: ① The production history of 3D datasets is very short; ② 3D assets usually require 3D designers to spend a lot of time using professional software to create; ③ Due to different usage scenarios and creator styles, 3D assets vary greatly in scale, quality and style, which increases the complexity of 3D data; ④ 3D data is inconvenient to obtain, and a large amount of 3D data is scattered in the hands of game companies, film and television special effects companies and individual modelers, making it difficult to collect. Exploring how to use 2D data for 3D generation is one of the solutions, but large-scale, high-quality 3D datasets are still very necessary.
l Representation method. In 3D generation technology, implicit representation can effectively model complex geometric topological structures, but the optimization speed is slow. Explicit representation helps to quickly optimize convergence, but it is difficult to encapsulate complex topological structures and requires a lot of storage resources. Developing a representation method that can have both high training efficiency and high precision will take the 3D generation effect to a higher level.
l Evaluation system. Comprehensive evaluation of generated 3D content requires understanding of its physical properties and intended design. Currently, the evaluation of 3D content quality mainly relies on manual scoring. Developing robust indicators that can comprehensively measure geometric and texture fidelity can promote the optimization of 3D generation technology.
l Controllability. The purpose of 3D generation technology is to generate a large amount of user-friendly, high-quality and diverse 3D content in a cheap and controllable way. However, when the generated 3D content is embedded in practical applications, compatibility issues are not conducive to 3D designer interaction and editing, and the style of the generated content is limited by the training data set. It is very necessary to unify 3D content produced by different methods and establish a tool chain with rich editing functions to enhance the controllability of the technology.
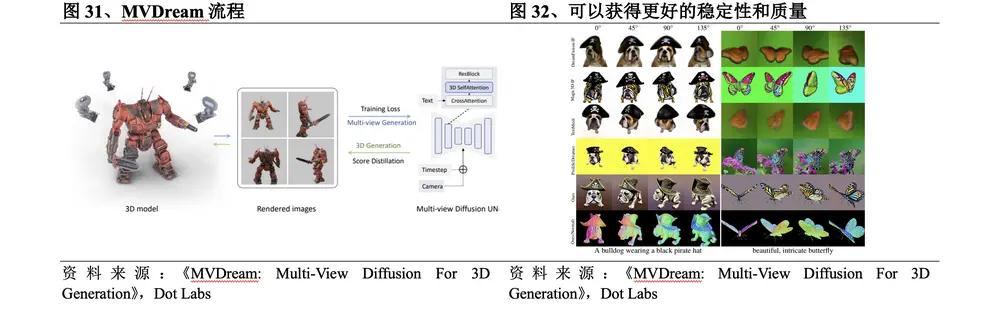
By comparing the generation quality, generation speed and richness of different 3D generation technologies, it can be found that these methods have an "Blockchain Trilemma" between the above three: The 3D native route method uses 3D data sets, which basically guarantees the quality and speed, but has obvious shortcomings in richness due to the small data set. The 2D dimensionality upgrade route method uses 2D data sets, which can well meet the richness requirements. There are methods such as Zero123 with impressive generation quality, and there are also methods such as DreamGaussian that pursue the ultimate in generation speed.
The "Blockchain Trilemma" poses great challenges to 3D generation technology in the process of commercialization. For scenarios targeting professionals, there are high requirements for generation quality. For example, industry, construction and medical care require highly accurate 3D generation. For scenarios targeting ordinary consumers, more emphasis is placed on generation speed. The advantages of 3D native methods in generation quality and speed are closer to commercial requirements, and can achieve advance commercialization in specific scenarios. For example, Dreamface of Yingmou Technology can already replace part of the pre-modeling work in the game field, and Get3D is generating simple items in some metaverse like scenes. In contrast, the 2D dimensionality-upgrading method is further away from commercialization, but we can see that a large number of 2D dimensionality-upgrading related academic results have been released since the second half of 2023. The 2D dimensionality-upgrading method has significantly improved in generation quality and generation speed to varying degrees. It can be expected that in the next year, 2D dimensionality-upgrading will have the opportunity to be initially implemented in some scenarios that do not require strict generation quality, such as the metaverse and VR home improvement.
4. Improvement of head-mounted displays opens up unlimited potential
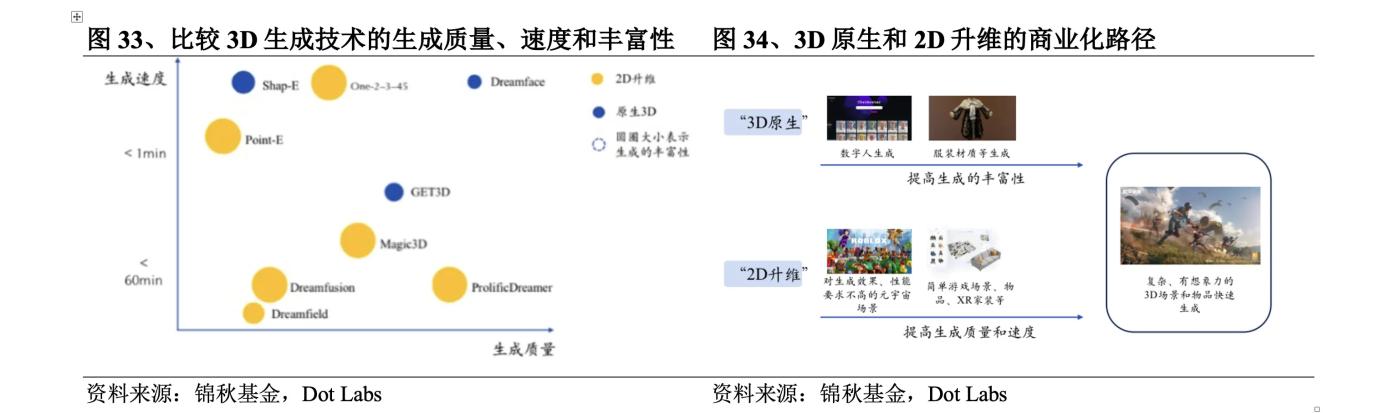
Although there are still some problems with the existing 3D generation technology, it is undeniable that the future application space of 3D generation is huge, mainly concentrated in the fields of 3D printing, games, film and television. According to data from Wohlers Report , the total output value of global 3D printing in 2022 is 18.2 billion US dollars, an increase of 18% year-on-year, and the growth rate continues to remain high. It is expected that the market size will reach 85.3 billion US dollars in 2031. According to Newzoo 's forecast, the global VR game market size will reach 3.2 billion US dollars in 2024. With the development of its downstream 3D content application field, 3D generation technology has broad demand and market expectations.
From a long-term perspective, the greater potential of 3D generation lies in the improvement of head-mounted display devices. Hardware is the carrier of technology, and the development of hardware will promote the development of technology. The improvement of head-mounted display devices is expected to bring about an explosion of 3D native applications. Developers can use 3D generation technology to develop head-mounted display applications and promote the maturity of the head-mounted display device ecosystem. Although judging from user feedback, the first-generation device Vision Pro still has many unsatisfactory aspects, but drawing on the development history of smartphones, it is expected that the application explosion will be realized within 3-5 years, and the future that can be glimpsed from it is still worth being excited about.
5. 3D generation startups enter the market
Solving the problem of 3D generation technology cannot simply rely on publishing a few papers, but also requires a clear understanding of 3D industry standards and professional user needs. In addition to large technology companies such as Nvidia , OpenAI , and Google , in the field of 3D generation, some emerging 3D generation startups have also done a lot of work in terms of usability. The final effect may not be worse than that of the giants. Their performance and future are worth the market's expectations.
l CSM ( Common Sense Machines ): Founded in Massachusetts, USA in 2020 , it was co-founded by Tejas Kulkarni, a former senior research scientist at Google DeepMind , and Max Kleiman-Weiner , a doctoral researcher at MIT and a scout investor at Sequoia Capital. The company provides a platform, CSM.ai , that allows users to transform photos, text, and hand-drawn sketches into fully realized 3D worlds. CSM innovatively proposed a third framework that is different from explicit game engines and implicit game engines - an implicit learning game engine that combines high flexibility and controllability, developed a diffusion-based real-time rendering engine, and launched the Cube application that quickly generates high-resolution 3D assets and custom style images. It has raised $ 10.1 million in three rounds of financing.
l Luma : Co-founded in 2021 by former Apple AR/CV engineer Amit Jain , Berkeley Lab head Alberto Taiuti and Alex Yu , it is headquartered in California, USA, and aims to simplify the creation process of 3D images and videos through AI . Its core technology is based on NeRF . Its Genie 1.0 released in January this year can generate 3D models based on text within 10 seconds. Its revolutionary AI video generator Dream Machine launched this month can create high-quality, realistic videos based on text and images, and the speed is as fast as 120 frames in 120 seconds. With outstanding technical strength and broad market prospects, Luma has successfully raised more than US$ 70 million in funds. Major investors include well-known venture capital firms such as Andreessen Horowitz , Matrix Partners and Amplify Partners . As of 2024 , Luma 's valuation has reached US$ 300 million.
l Polycam : Founded in California, USA in 2021 , its APP allows users to generate 3D models using the iPhone 's LiDAR and camera. Launched AI Texture Generato for creating 3D textures, and a free 3D Gaussian sputtering creator and viewer for 3D Gaussian sputtering reconstruction. Polycam has nearly 100,000 paying customers, the APP has been downloaded more than 10 million times, more than 20 million 3D models have been produced, and more than 50 million 3D editing tasks have been performed. Its revenue increased from US$ 280,000 in 2021 to US$ 1.8 million in 2022 , soaring to US$ 6.5 million in 2023 , and exceeded US$ 4 million in the first half of this year. It is expected that full-year revenue will set a new record. It has completed an $ 18 million Series A financing round, with investors including Left Lane Capital , Adjacent , Adobe Ventures , and YouTube co-founder Chad Hurley .
l Yellow : A 3D character generation company founded in 2023 , backed by $ 5 million in seed funding from A16z . Its CEO Mandeep Waraich was once the head of Google's large models and Core ML products. Most of the team members have backgrounds from prestigious universities such as MIT, Oxford, and Stanford. The first product, YellowSculpt , has been released, which enables topology-aware 3D generation, making it easier to use and edit. Although most current generative AI technologies produce rigid objects, Yellow 's structured mesh generation produces 3D models that are easy to animate, and the generated meshes can be seamlessly integrated with top game engines such as Unity , Unreal , and Roblox , or other 3D creation tools such as Daz Studio , Maya , and Blender . In January 2024 , an exclusive partnership was established with Tafi , the developer of Daz Studio , allowing Yellow to use Daz 's 3D library to train models in a safe manner.
6. 3D generation adds to the era of spatial intelligence
Spatial intelligence is a 3D virtual environment that supports real-time rendering. It requires identity authentication, data rights confirmation, asset trading, regulatory governance, etc. as support. The decentralized idea of Web 3 provides it with a safe, reliable and open infrastructure environment. Spatial intelligence will also become an important scenario for large-scale application of Web 3. Web 3 and spatial intelligence are developing in a mutually reinforcing way. The important 3D generation technology in spatial intelligence will have broad application and development space in the Internet environment of Web 3 .
1. Lifeform : Visual DID pioneer leads Web 3 breakthrough opportunities
In the trend of Web 3 and spatial intelligence, digital virtual identity has become a key and lacking infrastructure in the industry. Lifeform is a pioneering provider of decentralized digital identity ( DID ) solutions, providing digital virtual identities for Web 3 users and using them to log in to any DApp and metaverse, which is expected to achieve blockchain interoperability and bring breakthrough development opportunities to Web 3. The project has completed two rounds of financing with a total valuation of US$ 400 million in one year. Investors include Binance, IDG Capital , and GeekCartel . It has gained 100,000 followers on Twitter within 174 days of its launch. The current monthly transaction volume has exceeded US$ 3.5 million, accounting for about 35% of the BSC market share, second only to OpenSea . Its token LFT was launched on Bybit and KuCoin in May this year.
l Visual DID to enhance psychological experience. Existing DIDs store users’ personal information on the chain and use NFT or SBT to bind wallets to on-chain identities. Lifeform uses visual DID . In addition to being compatible with DID standards, it also provides users with a virtual human editor and corresponding DID protocols, smart contracts, etc., allowing users to participate in metaverse activities with visual 3D virtual characters, enhancing users’ visual and psychological experience.
l Over 10 billion combinations to meet personalized needs. Lifeform 's product AvatarID has two types : Hyper-Realistic based on UE5 and Cartoon Version in cartoon style. Its virtual human editor includes 7 creation components, each with more than 1,000 components. Users can create more than 10 billion avatar combinations, and it also provides a large number of templates to reduce the difficulty of user production. After the production is completed, it supports the formation of NFT .
lUniversal domain name ensures cross-chain availability. Unlike other DID solutions that rely on different blockchains and limit cross-chain capabilities and application scope, the universal domain name service created by Lifeform simplifies cross-blockchain identity authentication and positioning through the .btc suffix. It is the first domain name resolution platform that supports multiple blockchains (Bitcoin, Ethereum, BNB Chain , Solana , Base , Avalanche , OPBNB , etc.). Users can fully control their identity information and ensure the global availability of digital identities. In the future, we plan to cooperate with various wallets to connect the .btc domain name SDK to exchange wallets, and support seamless interaction across multiple layer 1 and layer 2 networks. 
2. Param Labs : Modular interconnection system innovates Web 3 game ecology
Param Labs is a AAA game and blockchain development studio dedicated to creating a modular, interconnected Web3 game ecosystem that completely changes the gaming experience for players and developers by giving users digital property rights to ensure that the value they create can be returned. The project has now completed $ 7 million in financing, led by Animoca Brands , with participation from Delphi Ventures and Cypher Capital . It has about 900,000 Twitter followers, 500,000 Discord users and 300,000 daily active users, and will soon launch its token PARAM on exchanges such as Bitget and Gate.io. Its main products are:
l Pixel to Poly : A platform for mass production of metaverse assets that converts user-uploaded 2D images into high-quality, game-ready 3D assets that can be integrated into popular games such as Fortnite and GTAV , greatly reducing the production time of game developers and accelerating asset creation in the 3D gaming industry. The platform also has unique NFTs used in games, providing valuable digital assets for players and collectors.
l Kiraverse : A free-to-play multiplayer shooter that can be further personalized by importing custom IPs for a unique, cross- IP , and cross-ecosystem experience. In May , the company announced a partnership with the gaming ecosystem Pixelverse , which will integrate its intellectual property and characters into Kiraverse , thereby enhancing the game’s narrative and expanding its universe. 
3. NeuralAI : Developing Bittensor subnet to innovate Web 3 3D generation
NeuralAI uses its $NEURAL ecosystem and dapp to provide users with 3D asset generation services, and provides a market that allows users to seamlessly trade their creations. The project is developing the Bittensor subnet and is about to release the first dapp , aiming to become the premier Bittensor subnet for 3D asset generation. The project has reached a strategic partnership with Akash Network, the world's top decentralized computing market, which has provided it with 56 powerful A6000 GPUs that can be expanded on demand.
l LRM model optimizes polygon count. The main model used by NeuralAI is LRM , which has the significant advantage of being able to generate optimized polygon count meshes with fewer polygon counts while retaining details, suitable for running at high FPS (frames per second), ensuring that the model is efficient and remains detailed, which is very suitable for game environments and allows 3D artists to use software to manipulate and refine the mesh in post-production, or add it directly to the game engine.
l Bittensor subnet reduces the cost of 3D generation. Generating 3D assets is a resource-intensive process that requires a lot of computing power and human resources. Bittensor , as a decentralized machine learning network, can distribute a large number of computing tasks among global nodes. NeuralAI is developing a dedicated subnet in the Bittensor network to provide a better solution for 3D asset generation. According to the project's calculations, it costs $ 30-100 per hour to hire a professional 3D artist, and $ 300-1000 for a complex asset that takes 10 hours to create, and does not include additional management costs for software and hardware. In the Bittensor subnet, Bittensor will use the token TAO to reward validators and miners. Users of Neural dApp , Neural plugins or APIs can generate 3D assets for free. If the network's incentives cover the rewards for generating 3D assets, the cost can be saved by 90-100% .

VII. Risk Warning
Risk 1: Price Fluctuation
- Cryptocurrency prices fluctuate greatly and future prices cannot be guaranteed or predicted
Risk 2 : Financial
- The Project may become insolvent or be unable to repay the principal or interest to SWEAT
Risk 3 : Hacker Attack
- SWEAT may be stolen by malicious actors and the project may not be able to return the funds
Risk 4 : Legal
- Some countries and regions prohibit such behavior, and the project owner may not be able to repay SWEAT principal or interest