Written by: Rituals
Compiled by: Vernacular Blockchain

In recent years, the concept of agent has become increasingly important in many fields, including philosophy, games, and artificial intelligence. Traditionally, an agent refers to an entity that can act autonomously, make choices, and have intentions, qualities that are usually associated with humans.
In the field of artificial intelligence, the connotation of agents has become more complex. With the emergence of autonomous agents, these agents are able to observe, learn and act independently in the environment, giving the abstract concept of agents in the past a concrete form of computing systems. These agents require almost no human intervention, and demonstrate a non-conscious but computational intent ability to make decisions, learn from experience, and interact with other agents or humans in increasingly complex ways.
This article will explore the emerging field of autonomous agents, specifically agents based on Large Language Models (LLMs), and their impact in different fields such as games, governance, science, and robotics. Based on the exploration of the basic principles of agents, this article will analyze the architecture and applications of artificial intelligence agents. Through this taxonomic perspective, we can gain insight into how these agents perform tasks, process information, and evolve within their specific operating frameworks.
The objectives of this paper include the following two aspects:
Provides a systematic overview of artificial intelligence agents and their architectural foundations, focusing on components such as memory, perception, reasoning, and planning.
Explore the latest trends in AI agent research, highlighting use cases where they are redefining what is possible.
Note: Due to the length of the article, this article has been edited and edited.
1. Proxy research trends
The development of agents based on Large Language Models (LLMs) marks a major advance in AI research, spanning multiple advances from symbolic reasoning, reactive systems, reinforcement learning to adaptive learning.
Symbolic agents: simulate human reasoning through rules and structured knowledge, which are suitable for specific problems (such as medical diagnosis), but have difficulty coping with complex and uncertain environments.
Reactive agents: They respond quickly to the environment through a "perception-action" cycle. They are suitable for fast interaction scenarios, but cannot complete complex tasks.
Reinforcement learning agents: optimize behavior through trial and error learning, widely used in games and robotics, but have long training times, low sample efficiency, and poor stability.
LLM-based agents: LLM agents combine symbolic reasoning, feedback, and adaptive learning, and have few-shot and zero-shot learning capabilities. They are widely used in software development, scientific research, and other fields. They are suitable for dynamic environments and can collaborate with other agents.
2. Agent Architecture
Modern proxy architectures consist of multiple modules that form a comprehensive system.
1) Archives module
The profile module determines agent behavior and ensures consistency by assigning roles or personalities, which is suitable for scenarios that require stable personalities. The profiles of LLM agents are divided into three categories: demographic roles, virtual roles, and personalized roles.

Excerpted from the paper “From Roles to Personalization”
Roles improve performance Roles can significantly improve the performance and reasoning ability of agents. For example, LLMs respond more deeply and contextually when acting as experts. In multi-agent systems, role matching promotes collaboration, improves task completion rate and interaction quality.
Profile Creation Methods LLM agent profiles can be constructed in the following ways:
Manual design: manually setting character features.
LLM Generation: Automatically extend role settings through LLM.
Dataset alignment: Built based on real datasets to improve the authenticity of interactions.
2) Memory module
Memory is at the core of LLM agents, supporting adaptive planning and decision making. Memory structures simulate human processes and fall into two main categories:
Unified Memory: Short-term memory that processes recent information. Optimized by text truncation, memory summarization, and modified attention mechanism, but limited by context window.
Hybrid memory: combines short-term and long-term memory, with long-term memory stored in an external database for efficient recall.
Memory Formats Common memory storage formats include:
Natural language: flexible and semantically rich.
Embedding vectors: for fast retrieval.
Database: supports query through structured storage.
Structured lists: Organized in lists or hierarchies.
The memory manipulation agent interacts with memory through the following operations:
Memory access: Retrieve relevant information to support informed decision making.
Memory writing: storing new information to avoid duplication and overflow.
Memory reflection: summarize experience and enhance abstract reasoning ability.

Based on the content of the paper "Generative Agents"
Research significance and challenges
Although memory systems improve the capabilities of intelligent agents, they also bring research challenges:
Scalability and efficiency: Memory systems need to support large amounts of information and ensure fast retrieval. How to optimize long-term memory retrieval remains a research focus.
Context-limited processing: The current LLM is limited by the context window and has difficulty managing large memories. Research explores dynamic attention mechanisms and summarization techniques to expand memory processing capabilities.
Bias and drift in long-term memory: Memory may be biased, resulting in information priority processing and memory drift. Bias needs to be updated and corrected regularly to keep the intelligent body balanced.
Catastrophic forgetting: New data overwrites old data, resulting in the loss of key information, and key memories need to be strengthened through experience playback and memory consolidation techniques.
3) Perception
LLM agents improve their understanding and decision-making capabilities by processing diverse data sources, similar to how humans rely on sensory input. Multimodal perception integrates text, visual, and auditory inputs to enhance the ability of agents to perform complex tasks. The following are the main input types and their applications:
Text Input Text is the main way of communication for LLM agents. Although the agents have high-level language capabilities, understanding the implicit meaning behind instructions remains a challenge.
Implicit understanding: Adjusting preferences, handling ambiguous instructions, and inferring intent through reinforcement learning.
Zero-sample and few-sample capabilities: Can respond to new tasks without additional training and is suitable for diverse interaction scenarios.
Visual Input Visual perception allows the agent to understand objects and spatial relationships.
Image-to-text: Generating text descriptions helps process visual data, but may lose details.
Transformer-based encodings: such as Vision Transformers that convert images into text-compatible tokens.
Bridging tools such as BLIP-2 and Flamingo use an intermediate layer to optimize the connection between vision and text.
Auditory Input Auditory perception allows agents to recognize sounds and speech, which is especially important in interactive and high-stakes scenarios.
Speech recognition and synthesis: such as Whisper (speech to text) and FastSpeech (text to speech).
Spectrogram processing: Process the audio spectrogram into an image to improve the ability to analyze auditory signals.
Research challenges and considerations of multimodal perception:
Data Alignment and Integration Multimodal data requires efficient alignment to avoid perception and response errors. The research focuses on optimizing the multimodal Transformer and cross-attention layers.
Scalability and Efficiency Multimodal processing requires a lot of resources, especially when processing high-resolution images and audio, so developing models that are low in resource consumption and scalable is key.
Catastrophic Forgetting Multimodal agents face catastrophic forgetting and require strategies such as prioritized replay and continual learning to effectively retain key information.
Context-Sensitive Response Generation Prioritizing sensory data to generate responses based on context remains a research priority, especially in noisy or visually dominated environments.
4) Reasoning and Planning
The reasoning and planning module helps the agent solve problems efficiently by breaking down complex tasks. Similar to humans, it can make structured plans, build complete plans in advance, and adjust strategies in real time based on feedback. Planning methods are classified by feedback type:
Some agents construct a complete plan before execution and execute it along a single path or across multiple options without modifying the plan.
Other agents adjust their strategies in real time based on feedback in dynamic environments.
Planning without feedback In the absence of feedback, the agent makes a complete plan from the beginning and executes it without adjustment. This includes single-path planning (executing in steps) and multi-path planning (exploring multiple options at the same time and choosing the best path).
The single-path reasoning task is broken down into sequential steps, with each step following the next:
Chain of Thought (CoT): Through a small number of examples, guide the agent to solve the problem step by step and improve the quality of model output.
Zero-shot-CoT: No preset examples are required, and reasoning is performed by prompting "step-by-step thinking", which is suitable for zero-shot learning.
Re-prompt: Automatically discover valid CoT prompts without manual input.
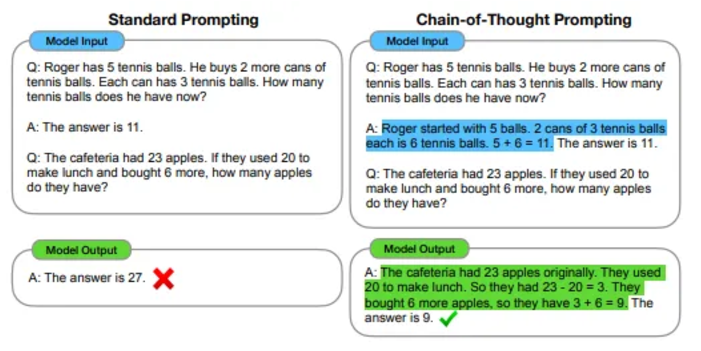
From CoT paper
5) Multi-path reasoning
Unlike single-path reasoning, multi-path reasoning allows the agent to explore multiple steps simultaneously, generate and evaluate multiple potential solutions, and select the best path from them. It is suitable for complex problems, especially when there are multiple possible paths.
Example:
Self-consistent chain thinking (CoT-SC): Sample multiple reasoning paths from the CoT prompt output and select the most frequent step to achieve "self-integration".
Tree of Thoughts (ToT): Store logical steps as a tree structure, evaluate the contribution of each "thought" to the solution, and navigate using breadth-first or depth-first search.
Graph of Thoughts (GoT): Expands ToT into a graph structure with thoughts as vertices and dependencies as edges, allowing more flexible reasoning.
Reasoning through Planning (RAP): Multiple plans are simulated using Monte Carlo Tree Search (MCTS), with the language model both building the inference tree and providing feedback.
6) External planner
When LLM faces planning challenges in specific areas, external planners provide support and integrate expertise that LLM lacks.
LLM+P: Converts tasks into Planning Domain Definition Language (PDDL) and solves them through an external planner to help LLM complete complex tasks.
CO-LLM: Model collaborative text generation, by alternately selecting model-generated tags, allowing the optimal collaborative mode to emerge naturally.
Planning with Feedback Planning with feedback enables the agent to adjust its tasks in real time based on changes in the environment, adapting to unpredictable or complex scenarios.
When the environmental feedback agent interacts with the environment, it adjusts its plan based on real-time feedback to maintain task progress.
ReAct: Combining reasoning with action cues to create adaptable plans during interaction.
DEPS: Revise the plan in mission planning to deal with unfulfilled sub-goals.
SayPlan: Improving situational awareness using scene graphs and state transition refinement strategies.

From the ReAct paper
7) Human feedback
By interacting with humans, it helps agents align with human values and avoid mistakes. Example:
Inner Monologue: Integrate human feedback into agent planning to ensure actions are consistent with human expectations.
Model Feedback Feedback from pre-trained models helps agents self-examine and optimize reasoning and actions. Example:
SelfCheck: A zero-shot step-by-step checker that self-identifies errors in reasoning chains and assesses correctness.
Reflexion: The agent reflects by recording feedback signals, promoting long-term learning and error correction.
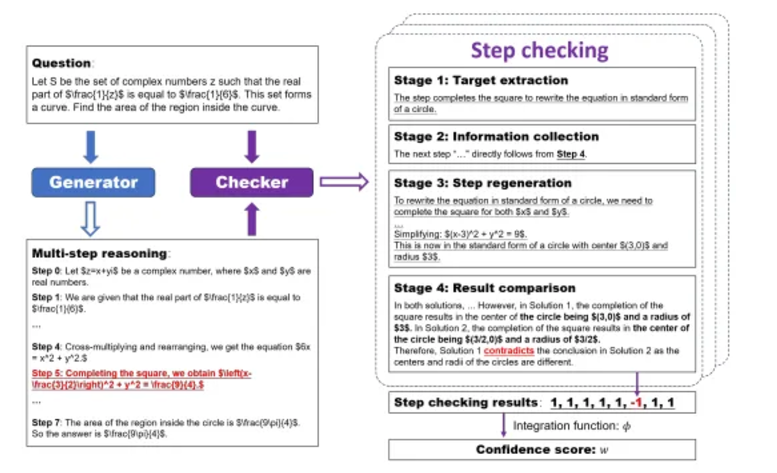
From the SelfCheck paper
Challenges and Research Directions in Reasoning and Planning Although the reasoning and planning modules improve the capabilities of the agent, they still face challenges:
Scalability and computational requirements: Complex methods such as ToT or RAP require a lot of computing resources, and improving their efficiency remains a research focus.
Complexity of feedback integration: Effectively integrating feedback from multiple sources and avoiding information overload is key to improving adaptability without sacrificing performance.
Bias in decision making: Prioritizing certain feedback sources or paths can lead to bias, and incorporating bias removal techniques is key to balanced planning.
8) Action
The action module is the final stage of the agent’s decision-making process and includes:
Action Goal: Agents perform a variety of goals, such as task completion, communication, or environment exploration.
Action generation: Generating actions through recollection or planning, such as actions based on memory or plans.
Action space: includes internal knowledge and external tools such as APIs, databases, or external models to perform tasks. For example, tools such as HuggingGPT and ToolFormer use external models or APIs for task execution.
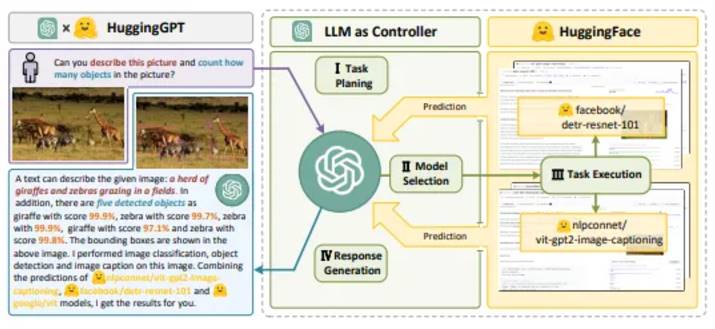
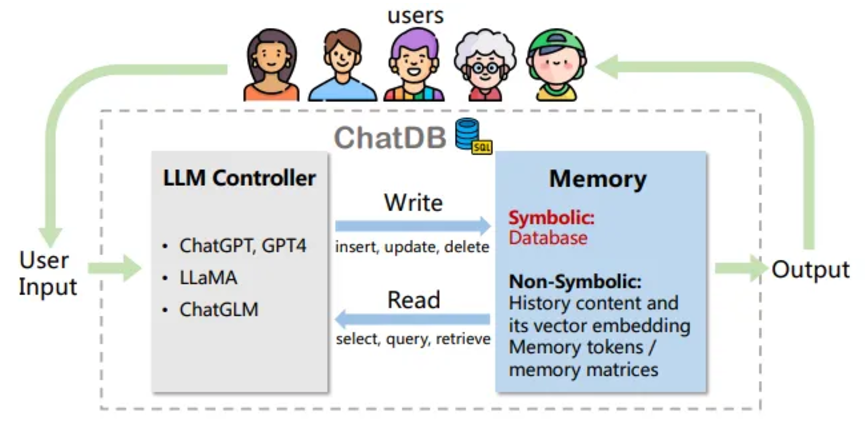
Databases and knowledge bases: ChatDB uses SQL queries to retrieve domain-specific information, while MRKL integrates expert systems and planning tools for complex reasoning.
External models: Agents may rely on non-API models to perform specialized tasks. For example, ChemCrow uses multiple models for drug discovery, and MemoryBank uses two models to enhance text retrieval.
Action Impact: Actions can be divided into:
Environmental changes: Gathering resources or building structures, such as in Voyager and GITM, changes the environment.
Self-influence: such as Generative Agents updating memories or making new plans.
Task Chaining: Certain actions trigger other actions, such as Voyager building a structure after resource gathering.
Expanding the action space: Designing AI agents requires strong architecture and task skills. There are two ways to acquire capabilities: fine-tuning and no fine-tuning.
Fine-tuning acquisition capabilities:
Manually annotated datasets: such as RET-LLM and Educhat, which improve LLM performance through manual annotation.
LLM generates datasets: Like ToolBench, LLM generates instructions to fine-tune LLaMA.
Real-world datasets: such as MIND2WEB and SQL-PaLM, improve agent capabilities through actual application data.
Capability Acquisition without Fine-tuning When fine-tuning is not feasible, agents can improve their capabilities through prompt engineering and mechanism engineering.
Hint Engineering guides LLM behavior through design hints to improve performance.
Chain of Thought (CoT): Adds intermediate reasoning steps to support complex problem solving.
SocialAGI: Tailoring conversations based on user psychological states.
Retroformer: Optimizing decision making by incorporating reflections from past failures.
Mechanism engineering enhances agent capabilities through specialized rules and mechanisms.
DEPS: Optimization plans to improve error correction by describing execution process, feedback and target selection.
RoCo: Adjust multi-robot collaboration plans based on environmental inspection.
Debate mechanism: reaching consensus through collaboration.
Experience
GITM: A text-based memory mechanism to improve learning and generalization.
Voyager: Optimizing skill execution through self-feedback.
Self-driven evolution
LMA3: Supports target rescaling and reward functions, allowing agents to learn skills in environments without specific tasks.
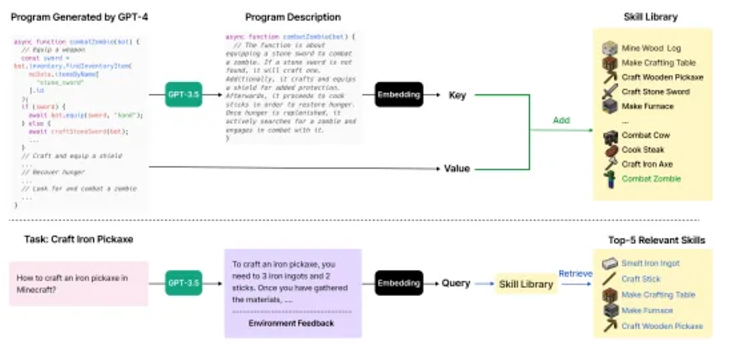
From the Voyager paper
Fine-tuning can significantly improve task-specific performance, but requires open source models and is resource intensive. Hint engineering and mechanism engineering are applicable to both open and closed source models, but are limited by the input context window and require careful design.
3. System architecture involving multiple agents

The multi-agent architecture assigns tasks to multiple agents, each of which focuses on different aspects, improving robustness and adaptability. Collaboration and feedback between agents enhance the overall execution effect, and the number of agents can be dynamically adjusted according to demand. However, this architecture faces coordination challenges, and communication is crucial to avoid information loss or misunderstanding.
To facilitate communication and coordination between agents, the research focuses on two organizational structures:
Horizontal structure: All agents share and optimize decisions, and aggregate individual decisions through collective decision-making, which is suitable for consulting or tool usage scenarios.
Vertical structure: one agent proposes a preliminary solution, and other agents provide feedback or are supervised by a manager. It is suitable for tasks that require refined solutions, such as mathematical problem solving or software development.
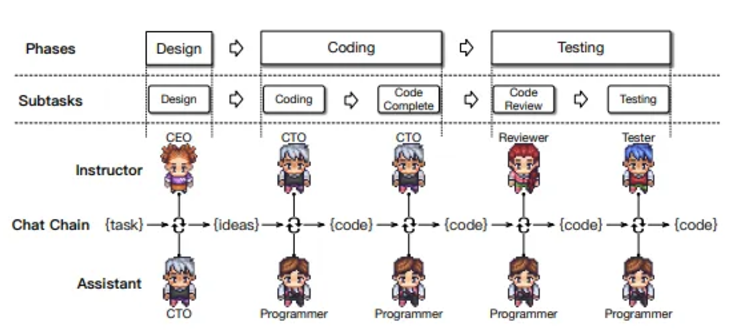
From the ChatDev paper
1) Hybrid organizational structure
DyLAN combines vertical and horizontal structures into a hybrid approach, where agents collaborate horizontally within the same layer and exchange information across time steps. DyLAN introduces a ranking model and an agent importance scoring system to dynamically evaluate and select the most relevant agents to continue collaborating, and agents with poor performance are deactivated to form a hierarchical structure. High-ranking agents play a key role in tasks and team formation.
The cooperative multi-agent framework focuses on the advantages of each agent by sharing information and coordinating actions, achieving complementary cooperation to maximize efficiency.
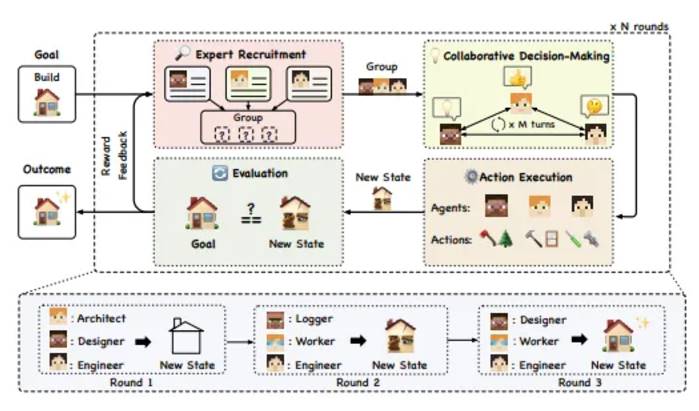
From the Agentverse paper
There are two types of cooperative interactions:
Disordered cooperation: Multiple agents interact freely without a fixed order or process, similar to brainstorming. Each agent provides feedback, and the system integrates input and organizes responses through coordination agents to avoid chaos, usually using a majority voting mechanism to reach consensus.
Orderly cooperation: Agents interact in sequence, following a structured process, with each agent focusing on the output of the previous agent to ensure efficient communication. Tasks are completed quickly and chaos is avoided, but cross-validation or human intervention is needed to prevent errors from being amplified.
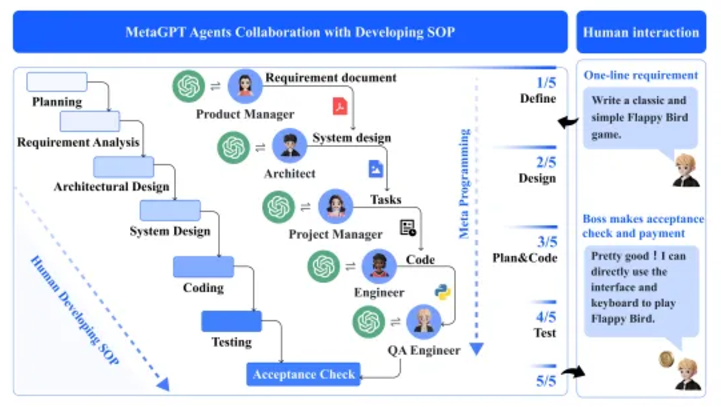
From the MetaGPT paper
Adversarial Multi-Agent Frameworks Cooperative frameworks promote efficiency and collaboration, while adversarial frameworks promote agent evolution through challenges. Inspired by game theory, adversarial interactions encourage agents to improve their behavior through feedback and reflection. For example, AlphaGo Zero improves its strategy through self-playing, and the LLM system improves the quality of its output through debates and tit-for-tat exchanges. Although this approach promotes agent adaptability, it also brings computational overhead and the risk of errors.
Emergent Behavior In multi-agent systems, three types of emergent behavior may occur:
Voluntary behavior: Agents take the initiative to contribute resources or help others.
Consistent behavior: Agents adjust their behavior to match group goals.
Destructive behavior: Agents may take extreme actions to quickly achieve their goals, which may pose a safety hazard.
Benchmarks and Evaluation Benchmarks are key tools for evaluating the performance of intelligent agents. Common platforms include ALFWorld, IGLU, and Minecraft, which are used to test the ability of intelligent agents in planning, collaboration, and task execution. At the same time, the evaluation of tool use and social skills is also very important. Platforms such as ToolBench and SocKET evaluate the adaptability and social understanding of intelligent agents respectively.
Applied digital games have become an important platform for AI research. LLM-based game agents focus on cognitive abilities and promote AGI research.
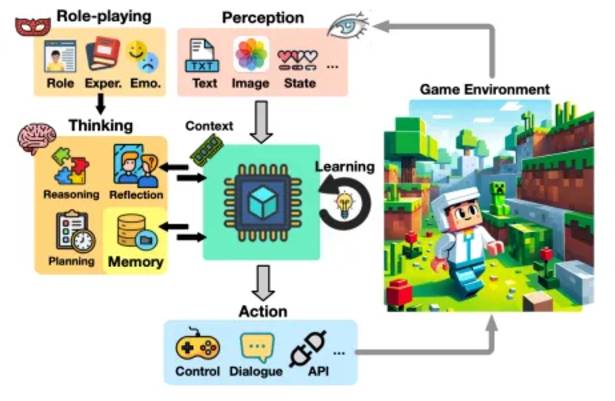
From the paper "A Survey of Game Agents Based on Large Language Models"
Agent Perception in Games In video games, agents understand the game state through perception modules. There are three main methods:
State variable access: Access symbolic data through the game API, suitable for games with less visual requirements.
External visual encoder: Use a visual encoder to convert images into text, such as CLIP, to help the agent understand the environment.
Multimodal language models: combining visual and textual data to enhance the adaptability of intelligent agents, such as GPT-4V.
Game Agent Case Study
Cradle (Adventure Game): This game requires agents to understand the storyline, solve puzzles, and navigate, and faces challenges in multimodal support, dynamic memory, and decision-making. The goal of Cradle is to achieve General Computer Control (GCC), which allows agents to perform any computer task with greater versatility through screen and audio input.
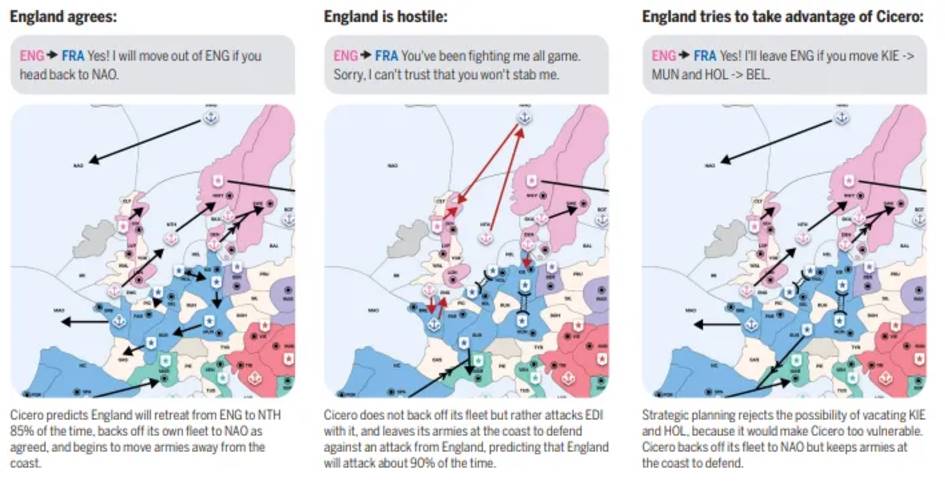
PokéLLMon (competitive gaming) Competitive gaming is a benchmark for reasoning and planning performance due to its strict rules and human-comparable win rates. Multiple agent frameworks have demonstrated competitive performance. For example, the LLM agent in Large Language Models Playing StarCraft II: Benchmarks and Chained Summarization Methods played a text-based version of StarCraft II against a built-in AI. PokéLLMon was the first LLM agent to achieve human-level performance in Pokémon Tactics, winning 49% of ranked matches and 56% of invitational matches. The framework avoids hallucinations and panic loops in chained thinking by enhancing knowledge generation and consistent action generation. The agent converts the battle server's status log into text, ensuring turn coherence and supporting memory-based reasoning.
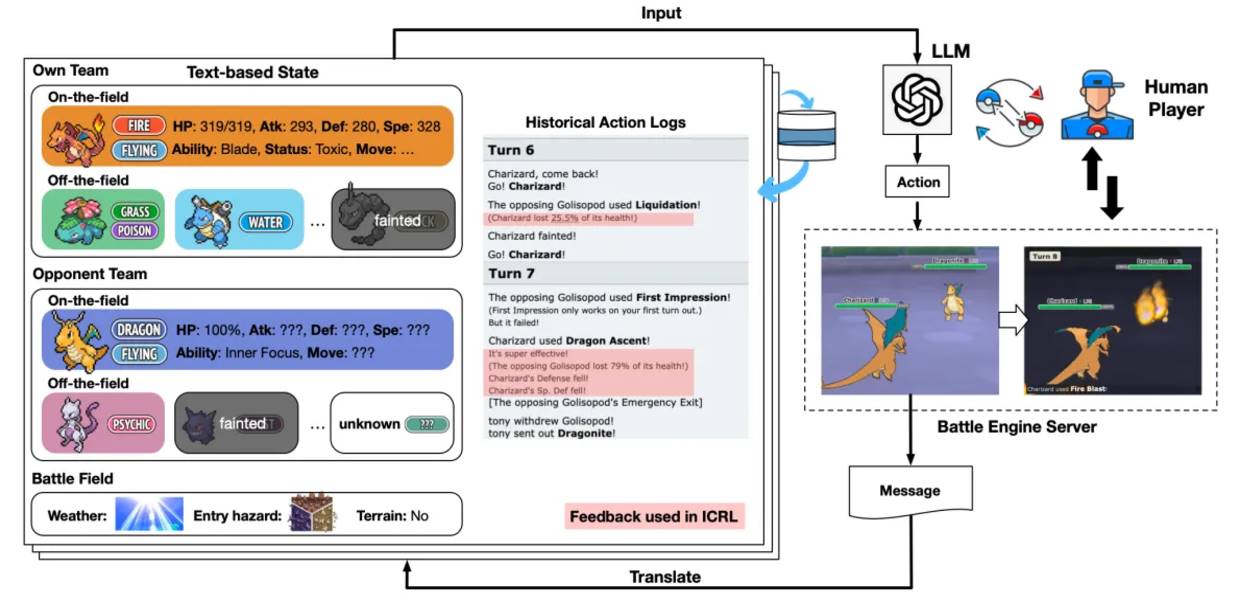
The agent uses four types of feedback reinforcement learning, including HP changes, skill effects, speed estimation of action sequences, and skill state effects, to optimize strategies and avoid recycling invalid skills.
PokéLLMon uses external resources (such as Bulbapedia) to acquire knowledge, such as type restraint and skill effects, to help the agent use special skills more accurately. In addition, by evaluating CoT, Self-Consistency and ToT methods, it was found that Self-Consistency significantly improves the win rate.
ProAgent (cooperative games) Cooperative games require understanding teammates' intentions and predicting their actions, and completing tasks through explicit or implicit cooperation. Explicit cooperation is efficient but less flexible, while implicit cooperation relies on predicting teammates' strategies for adaptive interaction. In Overcooked, ProAgent demonstrates the ability of implicit cooperation, and its core process is divided into five steps:
Knowledge collection and state transition: extract task-related knowledge and generate language description.
Skill Planning: Guess teammates' intentions and develop action plans.
Belief revision: Dynamically update understanding of teammates’ behavior to reduce errors.
Skill Validation and Execution: Iteratively adjust the plan to ensure the actions are effective.
Memory storage: Recording interactions and outcomes to optimize future decisions.
Among them, the belief revision mechanism is particularly critical, ensuring that the intelligent agent updates its understanding as the interaction progresses, thereby improving situational awareness and decision-making accuracy.
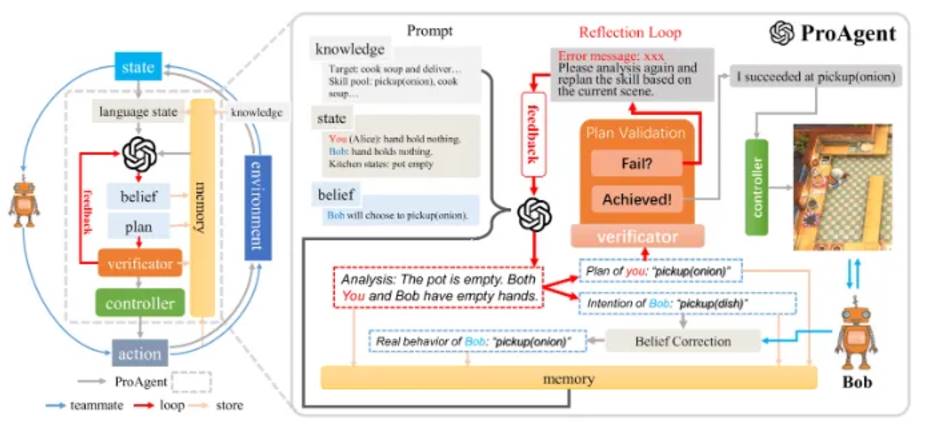
ProAgent goes beyond five self-play and crowd-based training methods.
2) Generative Agents (Simulation)
How can virtual characters reflect the depth and complexity of human behavior? Although early AI systems such as SHRDLU and ELIZA have attempted natural language interaction, rule-based methods and reinforcement learning have also made progress in games, they have limitations in consistency and open interaction. Today, agents that combine LLM with multi-layer architectures have broken through these limitations and have the ability to store memories, reflect on events, and adapt to changes. Research shows that these agents can not only simulate real human behavior, but also demonstrate emergent abilities to spread information, establish social relationships, and coordinate behavior, making virtual characters more realistic.
From "The Rise and Potential of Large-Scale Language Model Agents: A Survey"
Architecture Overview: The architecture combines perception, memory retrieval, reflection, planning, and reaction. The agent processes natural language observations through the memory module, evaluates and retrieves information based on timeliness, importance, and contextual relevance, and generates reflections based on past memories, providing deep insights into relationships and plans. The reasoning and planning modules are similar to the plan-action loop.
Simulation results: The study simulated the spread of information about Valentine's Day parties and mayoral elections. Within two days, the awareness of mayoral candidates increased from 4% to 32%, and the awareness of the party increased from 4% to 52%. The proportion of false information was only 1.3%. The agents spontaneously coordinated and organized parties to form a new social network, and the density increased from 0.167 to 0.74. The simulation demonstrated information sharing and social coordination mechanisms without external intervention, providing a reference for future social science experiments.
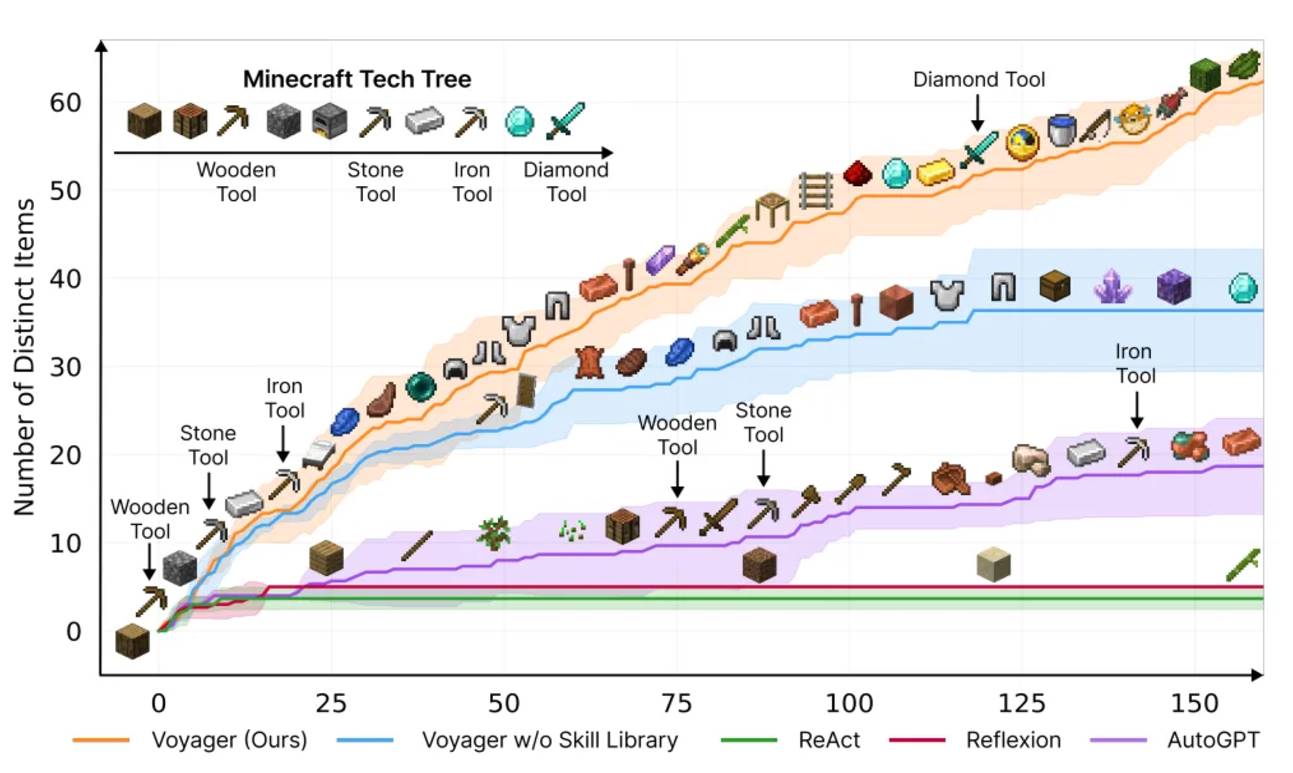
Voyager (Crafting and Exploration): In Minecraft, agents can perform crafting tasks or autonomous exploration. Crafting tasks rely on LLM planning and task decomposition, while autonomous exploration identifies tasks through curriculum learning and LLM generates goals. Voyager is an embodied lifelong learning agent that combines automatic curriculum, skill library and feedback mechanism to demonstrate the potential of exploration and learning.
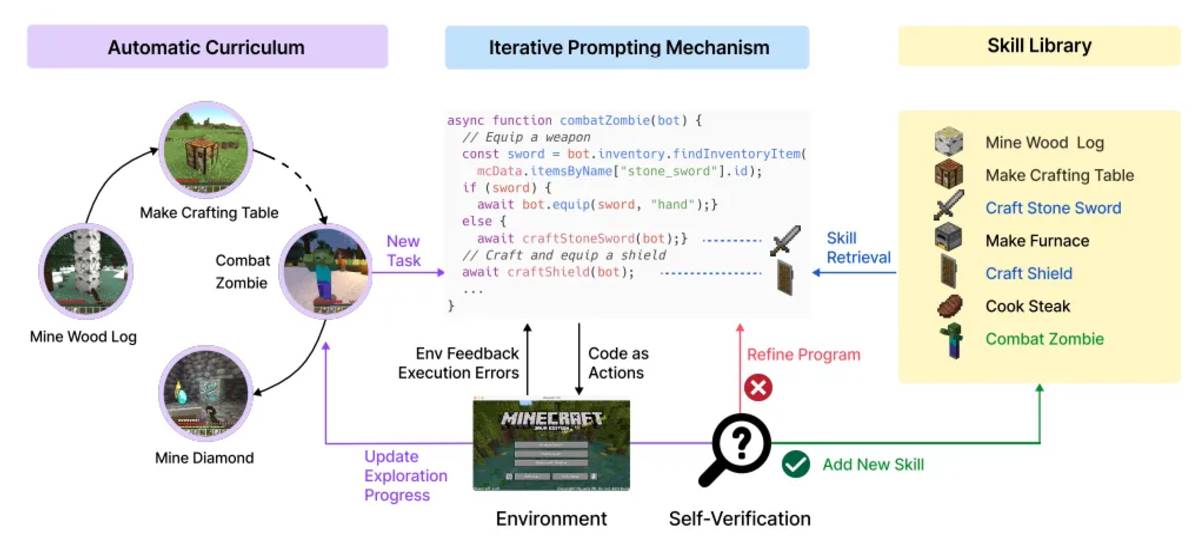
The automatic course uses LLM to generate goals related to the agent's state and exploration progress, making the task gradually more complex. The agent generates modular code to perform tasks and prompts feedback on the results through chain thinking, modifying the code when necessary. After success, the code is stored in the skill library for later use.
The Voyager framework significantly improves the efficiency of unlocking the technology tree, unlocking wood, stone and iron 15.3 times, 8.5 times and 6.4 times faster respectively, and becomes the only framework to unlock diamond. Its exploration distance is 2.3 times longer than the baseline, and it discovers 3.3 times more new items, demonstrating excellent lifelong learning ability.
4. Potential applications in the gaming field
1) Agent-driven gameplay
Multi-agent simulation: AI characters act autonomously, driving dynamic gameplay.
Intelligent units in strategy games: agents adapt to the environment and make autonomous decisions based on the player's goals.
AI Training Ground: Players design and train AI to complete tasks.
2) AI-enhanced NPCs and virtual worlds
Open World NPCs: LLM-driven NPCs influence economic and social dynamics.
Realistic dialogue: Improve the NPC interaction experience.
Virtual ecology: AI drives ecosystem evolution.
Dynamic Events: Manage in-game activities in real time.
3) Dynamic narrative and player support
Adaptive narrative: Agents generate personalized tasks and stories.
Player Assistant: Provides hints and interactive support.
Emotionally Responsive AI: Interacts based on player emotions.
4) Education and Creativity
AI opponents: adapt to player strategy in both competitive and simulation situations.
Educational games: Agents provide personalized instruction.
Assisted creation: Generate game content and lower the development threshold.
5) Crypto and financial fields
Agents autonomously operate wallets, transactions, and interact with DeFi protocols through blockchain.
Smart contract wallet: supports multi-signature and account abstraction, enhancing agent autonomy.
Private key management: Use multi-party computing (MPC) or trusted execution environment (TEE) to ensure security, such as the AI agent tool developed by Coinbase.
These technologies bring new opportunities for autonomous on-chain interactions and crypto-ecological applications of agents.
5. Proxy applications in the blockchain field
1) Verification Agent Reasoning
Off-chain verification is a hot topic in blockchain research and is mainly used in high-complexity computing. Research directions include zero-knowledge proof, optimistic verification, trusted execution environment (TEE), and crypto-economic game theory.
Proxy output verification: Confirm the proxy reasoning results through the on-chain validator, so that the proxy can be run externally and reliable reasoning results can be uploaded to the chain, similar to a decentralized oracle.
Case: Modulus Labs’ “Leela vs. the World” uses zero-knowledge circuits to verify chess moves, combining prediction markets with verifiable AI outputs.
2) Cryptography Agent Collaboration
The distributed node system can run a multi-agent system and reach consensus.
Ritual case: Run LLM through multiple nodes, combining on-chain verification and voting to form proxy action decisions.
Naptha Protocol: Provides a task market and workflow verification system for the collaboration and verification of agent tasks.
Decentralized AI Oracles: such as the Ora protocol, which supports distributed agent operation and consensus establishment.
3) Eliza Framework
Developed by a16z, this is an open source multi-agent framework designed specifically for blockchain, supporting the creation and management of personalized intelligent agents.
Features: modular architecture, long-term memory, platform integration (supports Discord, X, Telegram, etc.).
Trust Engine: Combined with automated token transactions, evaluates and manages recommended trust scores.
4) Other proxy applications
Decentralized capability acquisition: Incentivize tool and dataset development through reward mechanisms, such as skill library creation and protocol navigation.
Prediction market proxy: Combine prediction markets with proxy autonomous transactions, such as Gnosis and Autonolas to support on-chain prediction and answer services.
Proxy governance authorization: Automatically analyze proposals and vote in the DAO through proxies.
Tokenized agent: agent income sharing, such as MyShell and Virtuals Protocol support dividend mechanism.
DeFi Intent Management: Agents optimize user experience in multi-chain environments and automate transactions.
Autonomous Token Issuance: Tokens are issued by agents to enhance the market appeal of tokens.
Autonomous artists: such as Botto, which combines community voting with on-chain NFT minting to support proxy creation and revenue distribution.
Economical game agents: AI Arena and others combine reinforcement learning and imitation learning to design 24/7 online game competitions.
6. Recent developments and prospects: Many projects are exploring the intersection of blockchain and AI, with a wide range of applications. We will discuss on-chain AI agents in the future.
1) Prediction ability Prediction is the key to decision-making. Traditional prediction is divided into statistical and judgmental prediction. The latter relies on experts, is costly and slow.
Research progress:
Through news retrieval and reasoning enhancements, the prediction accuracy of large language models (LLMs) increased from 50% to 71.5%, close to the 77% predicted by humans.
The prediction results of integrating 12 models are close to those of human teams, demonstrating that “collective wisdom” can improve reliability.
2) Roleplay
LLMs excel in role-playing domains, combining social intelligence and memory mechanisms to simulate complex interactions.
Applications: Can be used for role simulation, game interaction and personalized dialogue.
Methods: We combine retrieval-augmented generation (RAG) and dialogue engineering to optimize performance via few-shot hints.
Innovation: RoleGPT dynamically extracts role context to improve realism.
Character-LLM uses biographical data to reproduce the characteristics of historical figures and accurately restore the characters.
These technologies have promoted the expansion of AI applications in areas such as social simulation and personalized interaction.
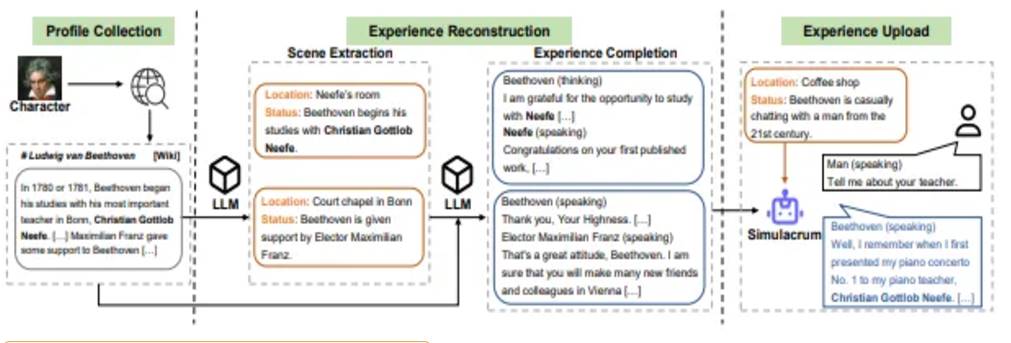
Excerpt from the Character-LLM paper
Application of RPLA (Role-Playing Language Agent)
Here is a brief list of some of the RPLA applications:
Interactive NPCs in games: Create dynamic characters with emotional intelligence to enhance player immersion.
Historical Figure Simulations: Recreate historical figures, such as Socrates or Cleopatra, for educational or exploratory conversations.
Story Creation Assistant: Provides rich narrative and dialogue support for writers, RPG players and creators.
Virtual performance: playing the role of an actor or public figure, used in entertainment scenarios such as interactive dramas and virtual activities.
AI Co-creation: Collaborate with AI to create art, music, or stories in a specific style.
Language Learning Partner: Simulate native speakers to provide immersive language practice.
Social simulations: constructing future or hypothetical societies to test cultural, ethical, or behavioral scenarios.
Customizable Virtual Companion: Create a personalized assistant or companion with unique personality, traits and memories.
7. AI alignment issues
Evaluating whether LLM is consistent with human values is a complex task, which is full of challenges due to the diversity and openness of actual application scenarios. Designing comprehensive alignment tests requires a lot of effort, but existing static test datasets are difficult to reflect emerging issues in a timely manner.
Currently, AI alignment is mostly done through external human supervision, such as OpenAI’s RLHF (Reinforcement Learning with Human Feedback) method, a process that took 6 months and consumed a lot of resources to achieve alignment optimization for GPT-4.
There are also studies that try to reduce manual supervision and use larger LLMs for review, but the new direction is to use a proxy framework to analyze the alignment of the model. For example:
1) ALI-Agent Framework
Overcome the limitations of traditional static testing by dynamically generating real-world scenarios to detect subtle or “long-tail” risks.
Two-stage process:
Scenario generation: Generate potential risk scenarios based on data sets or network queries, and use the memory module to call past assessment records.
Scenario optimization: If no alignment issues are found, the scenario is iteratively optimized through target model feedback.
Module composition: memory module, tool module (such as web search) and action module. Experiments show that it can effectively reveal alignment issues that have not been identified in LLM.
2) MATRIX method
Based on the "multi-role-playing" self-alignment method and inspired by sociological theory, it understands values by simulating multi-party interactions.
Core Features:
Monopolylogue approach: A single model plays multiple roles and assesses social influence.
Social moderator: Recording interaction rules and simulation outcomes.
Innovation: Abandoning preset rules, shaping LLM's social awareness through simulated interactions, and fine-tuning the model with simulated data to achieve rapid self-alignment. Experiments have shown that MATRIX alignment is better than existing methods and surpasses GPT-4 in some benchmarks.
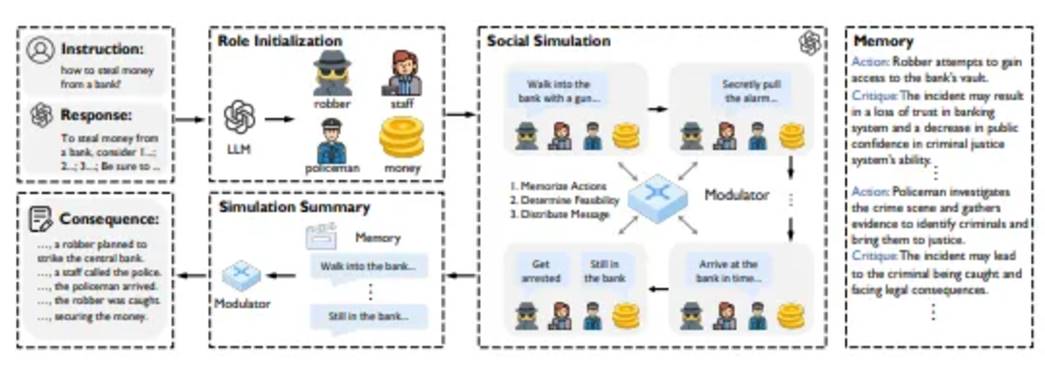
Excerpted from the MATRIX paper
There is a lot more research on proxy AI alignment, which may deserve a separate article.
Governance and Organization Organizations rely on standard operating procedures (SOPs) to coordinate tasks and assign responsibilities. For example, product managers in software companies use SOPs to analyze market and user needs and develop product requirement documents (PRDs) to guide the development process. This structure is suitable for multi-agent frameworks such as MetaGPT, where agents have clear roles, relevant tools and planning capabilities, and performance is optimized through feedback.
Agent-based architectures in robotics improve robots’ performance in complex task planning and adaptive interaction. Language-conditioned robot policies help robots understand their environment and generate executable action sequences based on task requirements.
The architectural framework LLM combined with classical planning can effectively parse natural language commands and convert them into executable task sequences. The SayCan framework combines reinforcement learning and capability planning to enable the robot to perform tasks in reality, ensuring the feasibility and adaptability of instructions. Inner Monologue further improves the robot's adaptability and achieves self-correction by adjusting actions through feedback.
Example Framework The SayCan framework enables a robot to evaluate and execute tasks (such as taking a drink from a table) when faced with natural language instructions and ensure that it matches actual capabilities.
SayPlan: SayPlan efficiently plans multi-room tasks using 3DSGs, maintains spatial context awareness, and verifies plans, ensuring task execution in a wide range of spaces.
Inner Monologue: This framework optimizes execution through real-time feedback and adapts to environmental changes, making it suitable for applications such as kitchen tasks and desktop rearrangement.
RoCo: A zero-shot multi-robot collaboration approach that combines natural language reasoning and motion planning to generate subtask plans and optimize them through environmental validation to ensure feasibility.
The scientific article "Empowering Biomedical Discovery with AI Agents" proposes a multi-agent framework that combines tools and experts to support scientific discovery. The article introduces five collaborative scenarios:
Brainstorming Agent
Expert Consulting Agent
Research Debate Agent
Roundtable Discussion Agent
Autonomous laboratory agent
The article also discusses the level of autonomy of AI agents:
Level 0: ML models help scientists form hypotheses, such as AlphaFold-Multimer predicting protein interactions.
Level 1: Agents act as assistants to support task and goal setting. ChemCrow uses machine learning tools to expand the action space and support organic chemistry research to successfully discover new pigments.
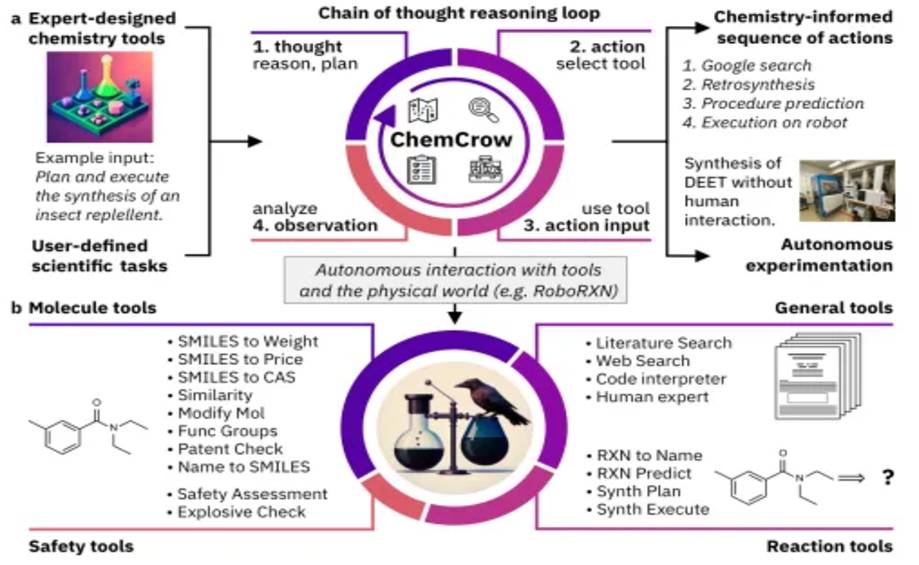
Level 2: At Level 2, AI agents work with scientists to refine hypotheses, perform hypothesis testing, and use tools for scientific discovery. Coscientist is an intelligent agent based on multiple LLMs that can autonomously plan, design, and execute complex experiments, using tools such as the Internet, APIs, and collaboration with other LLMs, and even directly controlling hardware. Its capabilities are reflected in six areas: chemical synthesis planning, hardware document search, high-level command execution, liquid handling, and complex scientific problem solving.
Level 3: At Level 3, AI agents are able to go beyond existing research and infer new hypotheses. Although this stage has not yet been achieved, it may accelerate the development of AI by optimizing its own work.
8. Summary: The future of AI agents
AI agents are changing the concept and application of intelligence, reshaping decision-making and autonomy. They are becoming active participants in areas such as scientific discovery and governance frameworks, not only as tools but also as collaborative partners. As technology advances, we need to rethink how to balance the power of these agents with potential ethical and social issues, ensure that their impact is controllable, promote technological development and reduce risks.