

Source: Longhash Community
Rollups are developing rapidly. Initially, classic rollups provided a short-term solution to Ethereum's scalability challenges. Now, with technological advancements, we are building the next generation of rollups, which not only further scale Ethereum but also retain decentralization, security, and economic sustainability.
In a four-part series titled "Decoding the Next-Gen L2s", we explore some new rollup types - Based rollups, Booster rollups, gigagas rollups, native rollups - and aim to introduce these designs to a broad audience. These rollups represent the future of Ethereum scaling, and given @2077Research's commitment to making Ethereum research and development (R&D) accessible, we believe it is important to educate the community on the updated L2 designs.
Our goal is to quickly introduce these technologies and elucidate the relevant concepts. In this series, we will break down each rollup type, discuss their designs, advantages, trade-offs, and the overall impact on Ethereum's roadmap. Whether you are an Ethereum enthusiast, a developer, or curious about blockchain scalability, this series is for you.
The first article focuses on Based Rollups - a proposed approach to building rollups that aims to mitigate the issues of classic rollups, such as centralized sequencers, lifecycle risks, and censorship resistance. We will explore how Based Rollups work, the benefits they provide, and the barriers to the adoption of Based Rollups.
What are Based rollups?
If a rollup uses a sequencing-based approach to process transactions, it is referred to as a Based (or sequencing-based) rollup. Sequencing refers to how transactions are ordered for execution within the rollup. Based sequencing utilizes the validator set of the Layer 1 (L1) chain to order transactions, rather than relying on a centralized entity ("sequencer") to order transactions.
Today, traditional rollups have centralized sequencers, which has led to several issues. These issues include censorship of user transactions, single points of failure, and MEV extraction (centralized sequencers can extract MEV (maximum extractable value) from users due to their private access to the mempool).
Given the issues with centralized sequencing, the Ethereum community has been seeking alternatives. Importantly, these alternative sequencing designs must meet a key design goal: they must be as efficient and fast as their predecessors.
Based sequencing and Based Rollups are a positive step in this direction, as they provide a new way of ordering transactions for rollups, inheriting Ethereum's censorship resistance, eliminating single points of failure, and avoiding sacrificing speed for decentralization. We describe how Based Rollups work below.
How do Based rollups work?
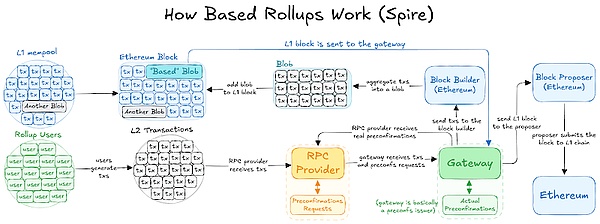
The key difference between Based rollups and any other type of rollup is the way transactions are ordered. In Based rollups, the ordering of transactions is managed by the underlying L1 blockchain (in this case, Ethereum). Specifically, in Based rollups, "any next L1 proposer can freely include subsequent rollup blocks in the next L1 block along with L1 lookups and builders, without any special permissions."
In the Based rollup architecture, user transactions are directed to L1 builders who have agreed to construct blocks for Ethereum and the L2-based. Users indicate their maximum transaction fee, and the L2 captures the base fee (set according to L2 network congestion) and forwards the priority fee (paid to incentivize including the transaction) to the validators, who then decide the transaction order.
This arrangement allows Ethereum not only to capture all the fees from its ecosystem but also to collect a portion of the L2 tips, as well as the fees for transaction settlement. Returning value to L1 creates a symbiotic relationship between Based Rollups and Ethereum, and eliminates the notion of rollups being parasitic to Ethereum. Another benefit of leveraging L1 proposers to order L2 transactions is that it eliminates the intermediary step in the transaction flow. This can potentially lead to lower transaction costs by avoiding the need to verify signatures from a centralized or decentralized sequencer.
It's worth noting that this cost reduction is not unique to Based Rollups; any rollup using shared sequencing is likely to see similar benefits. Due to the permissionless nature of the L1 proposal blocks, this fosters a competitive environment among block builders, which may further reduce user fees.

Description of the Taiko Based rollup architecture
Since Based rollups submit their proofs directly to Ethereum, their settlement is inherently on Ethereum. This means that anyone can access the verified state of the L2 chain on Ethereum. Based rollups cannot settle outside of their underlying L1.
Based rollups publish the data required to reconstruct their chain state on Ethereum, making Ethereum their data availability (DA) layer. This allows anyone to verify block hashes and retrieve transaction data from the blocks. Based Rollups use Ethereum's consensus layer for transaction ordering, eliminating the need for their own consensus mechanism.
Transaction execution in Based rollups happens within their own ecosystems in a layer-2 fashion, meaning Based rollups themselves serve as their own execution layer. For example, existing Based Rollups, such as Taiko and SpireLabs, while settling on Ethereum, run on the same L1 but maintain their own distinct execution layer to execute transactions.
What are the pros and cons of the Based rollup design?
The advantages of Based Rollups include inheriting Ethereum's security and liveness, potentially lowering transaction costs by eliminating an additional sequencing step, enabling atomic composability of L2 transactions with L1 state, simplifying the architecture by not requiring a separate consensus, ensuring all data availability on Ethereum, and providing strong censorship resistance.
However, as with anything in crypto, the Based design also has its concerns. Based Rollups rely on Ethereum's performance, which may limit scalability due to Ethereum's block space constraints. L2 operations are still gas-cost related, which can be quite substantial. There are also MEV concerns, where L1 validators may influence transaction ordering. The tight coupling with Ethereum's consensus and data layers may limit customization for specific use cases.
Based Rollups FAQ
In this section, we address some common questions about Based Rollups. Our goal is to dispel specific misconceptions about Based Rollups and provide clear information on various aspects of the Based rollup architecture.
How do Based rollups manage MEV?
Most MEV benefits L1 validators, as the incentive for L1 searchers and block builders is to include the rollup blocks in their L1 blocks to capture this value, incentivizing L1 proposers to include these blocks. Currently, around 80% of Ethereum's MEV comes from congestion, and 20% from extracting. If L2 MEV reflects this, a significant portion may remain in L2.
Are Based rollups cheaper for users compared to alternatives?
Using L1 proposers as L2 sequencers can save an intermediary step by potentially reducing costs through the elimination of sequencer signature verification. This cost-saving approach applies not only to Based rollups but also to shared sequencing rollups, as the permissionless block proposals foster competition, which may lower fees.
Are Based rollups' speeds limited to Ethereum's block time?
Yes, the transaction confirmation time of Based rollups is related to the L1 block time, which is currently 12 seconds. However, Based rollups can achieve instant pre-confirmation. This can be done through a mechanism similar to heavy staking, where a portion of L1 validators commit to including the Based rollup blocks in their future L1 blocks. This is feasible because validators can know 32 blocks in advance who will be the proposer of each block.
How "live" are Based rollups' liveness?
Based on shared sequencing, Based rollups inherit Ethereum's liveness guarantees, fully inheriting its uptime. Even a slight liveness drop (e.g., from 100% to 99%) would be exploited under adversarial conditions, leading to significant disruption and toxic MEV.
What is the difference between based sorting and shared sorting?
Based sorting can be seen as a specialized version of shared sorting. Shared sorting, as a cross-multiple rollup transaction sorting system, aims to achieve economic efficiency, higher throughput, and faster confirmation than L1. The difference from rollup-based is that it uses its own operators to reach consensus, making it more complex and not entirely dependent on the liveness of Ethereum.
Conclusion
In the first article of our "Rollups 2.0" series, we explored rollup-based, which leverages Ethereum's validators for transaction ordering, providing a path to decentralization, security, and cost-efficiency.
As we continue this series, we will delve deeper into enhanced rollups, native rollups, and hyper-scale rollups - exploring how these types of rollups address different aspects of Ethereum's scalability.






