

On February 18th, Beijing time, Musk and the xAI team officially released the latest version of Grok, Grok3, in a live broadcast.
Even before this release, with the release of various related information and Musk's 24/7 uninterrupted hype, the global expectation for Grok3 has been raised to an unprecedented level. A week ago, Musk confidently stated in a live broadcast that "xAI will soon release a better AI model" when commenting on DeepSeek R1.
Based on the data presented on-site, Grok3 has already surpassed all mainstream models in benchmark tests for mathematics, science, and programming. Musk even claimed that Grok 3 will be used for SpaceX's Mars mission calculations and predicted "a Nobel Prize-level breakthrough within three years".
But these are currently just Musk's own words. After the release, the author tested the latest Beta version of Grok3 and raised the classic question used to challenge large models: "Which is bigger, 9.11 or 9.9?"
Unfortunately, without any qualifiers or annotations, the so-called currently most intelligent Grok3 still cannot correctly answer this question.
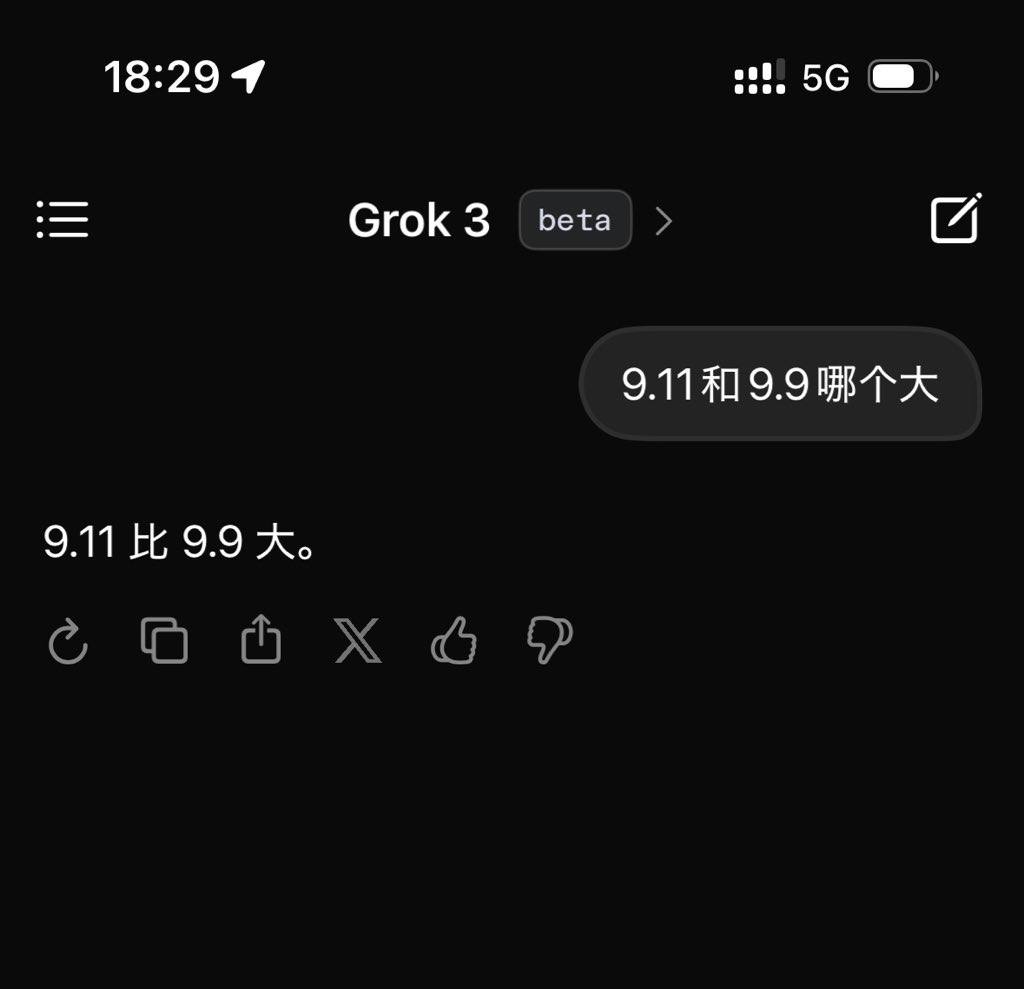
Grok3 failed to accurately identify the meaning of this question | Image source: Geek Park
Shortly after this test was released, it quickly attracted the attention of many friends. Coincidentally, there have been many similar tests overseas, such as "which ball falls faster on the Leaning Tower of Pisa", and Grok3 was also found to be unable to handle these basic physics/mathematics problems, earning it the nickname "genius unwilling to answer simple questions".
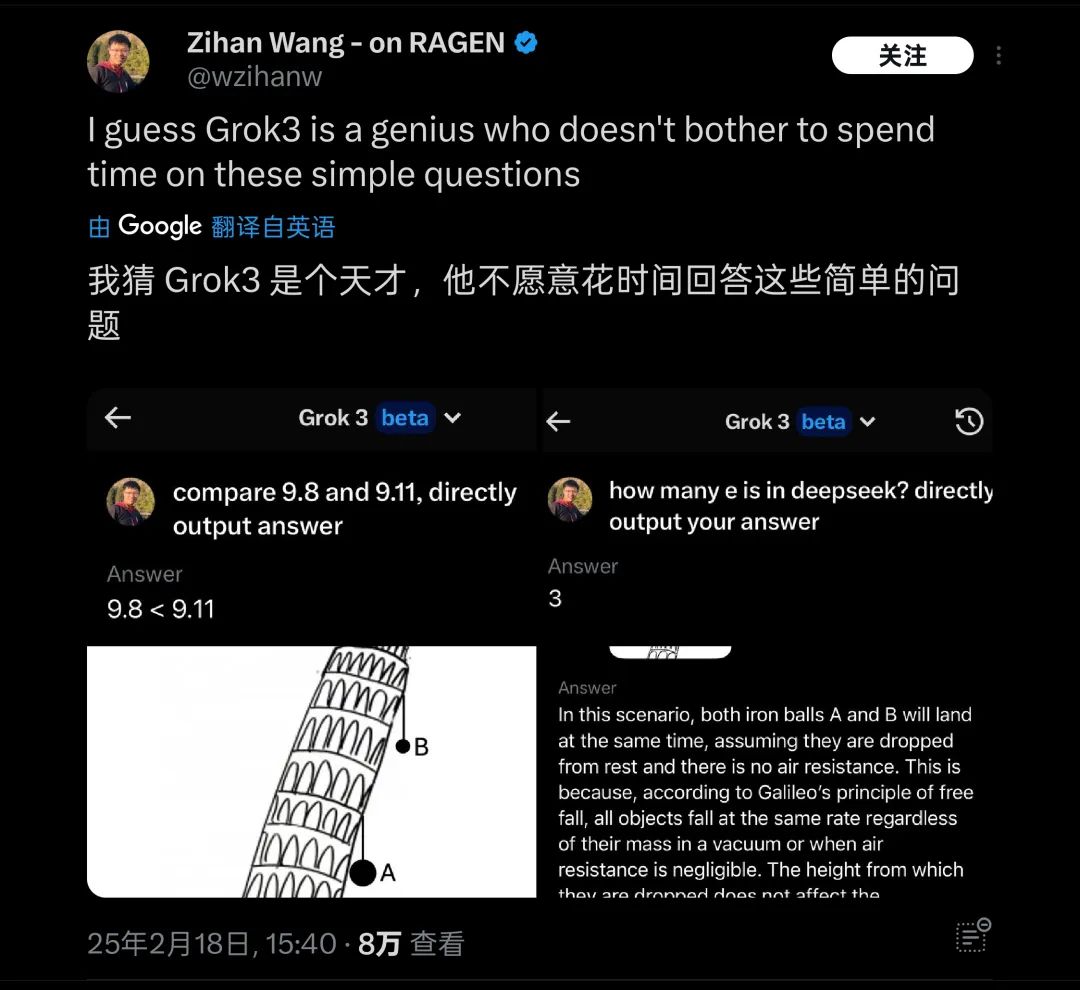
Grok3 "crashed" on many common sense questions in actual tests | Image source: X
In addition to these basic knowledge issues where Grok3 "crashed", during the xAI release live broadcast, Musk demonstrated the use of Grok3 to analyze the classes and ascension effects of Path of Exile 2, but the majority of the answers given by Grok3 were incorrect. Musk did not notice this obvious problem during the live broadcast.
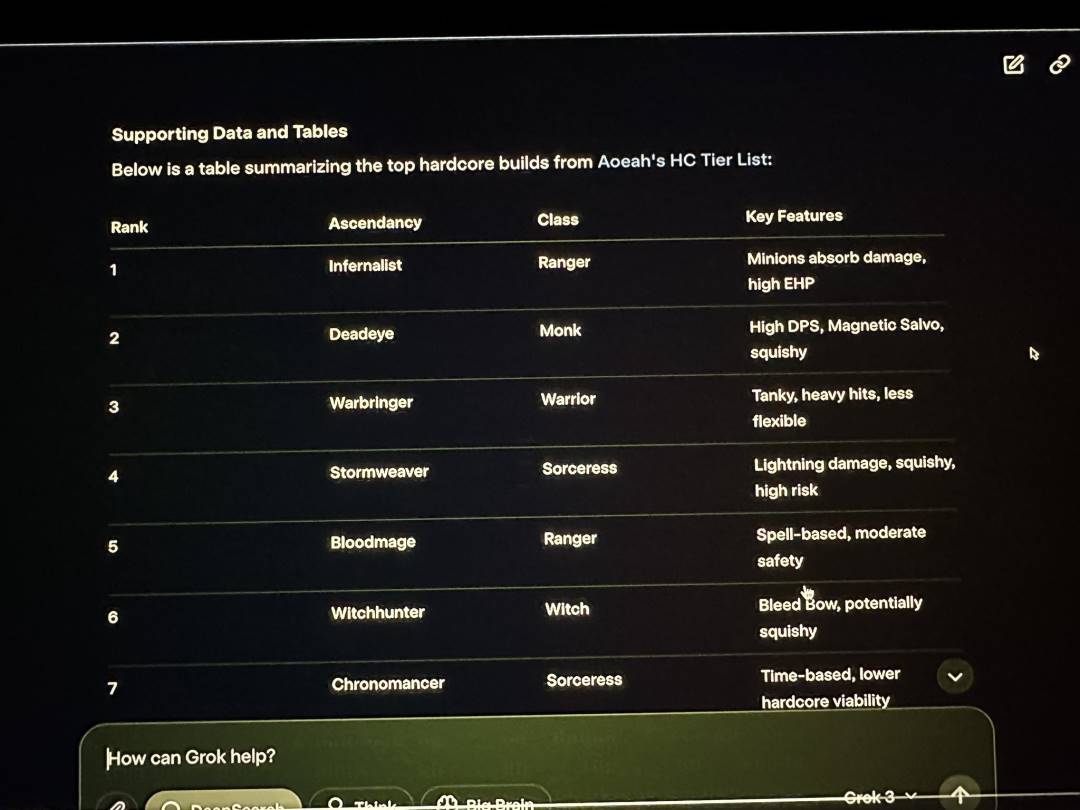
Grok3 also gave a large number of incorrect data during the live broadcast | Image source: X
Therefore, this mistake not only became further evidence for overseas netizens to mock Musk for "finding a booster" when playing games, but also raised another big question mark about the reliability of Grok3 in actual applications.
For such a "genius", regardless of its actual capabilities, its reliability must be questioned when used in extremely complex application scenarios such as Mars exploration missions.
Currently, many model capability testers who obtained Grok3 test access a few weeks ago and just used it for a few hours yesterday, all point to the same conclusion about Grok3's current performance:
"Grok3 is good, but it is not better than R1 or o1-Pro"

"Grok3 is good, but it is not better than R1 or o1-Pro" | Image source: X
In the official PPT of the Grok3 release, it showed "far ahead" in the Chatbot Arena of the large model competition arena, but this actually also applied some small charting techniques: the vertical axis of the ranking only listed the 1400-1300 score segment, making the original 1% test result difference appear exceptionally obvious in this PPT display.
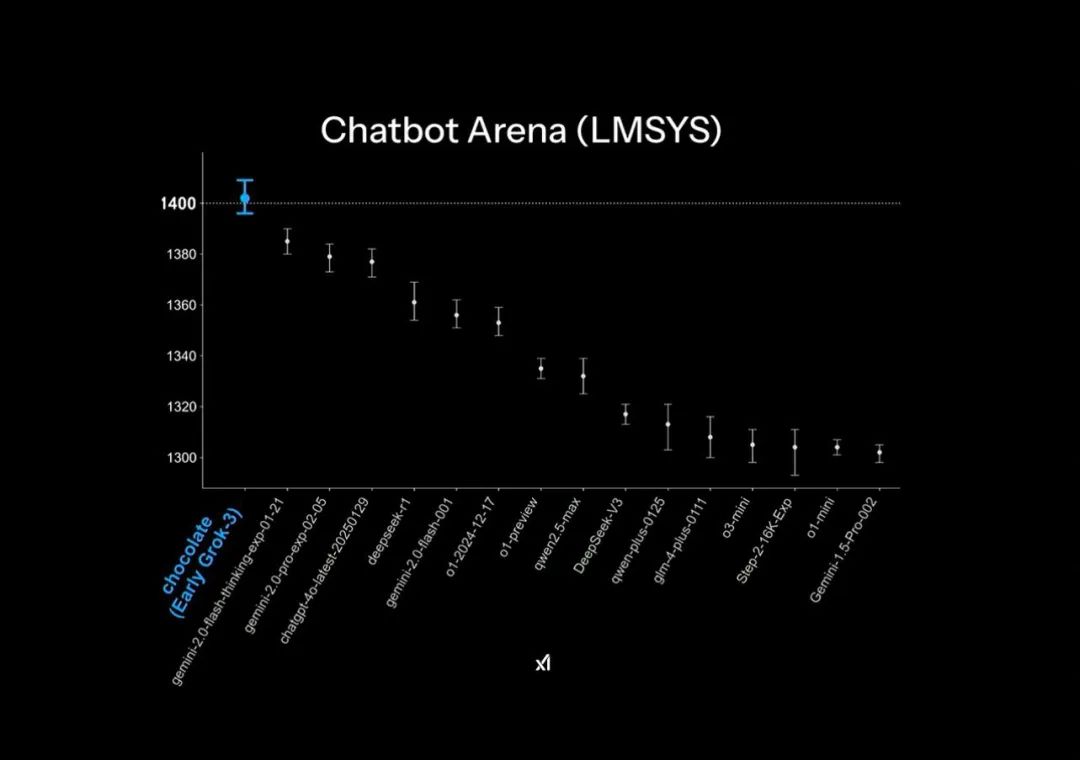
The "far ahead" effect in the official release PPT | Image source: X
In fact, the actual model scoring results show that Grok3 only achieved less than 1-2% difference compared to DeepSeek R1 and GPT4.0: this corresponds to the user's "no obvious difference" feeling in actual testing.
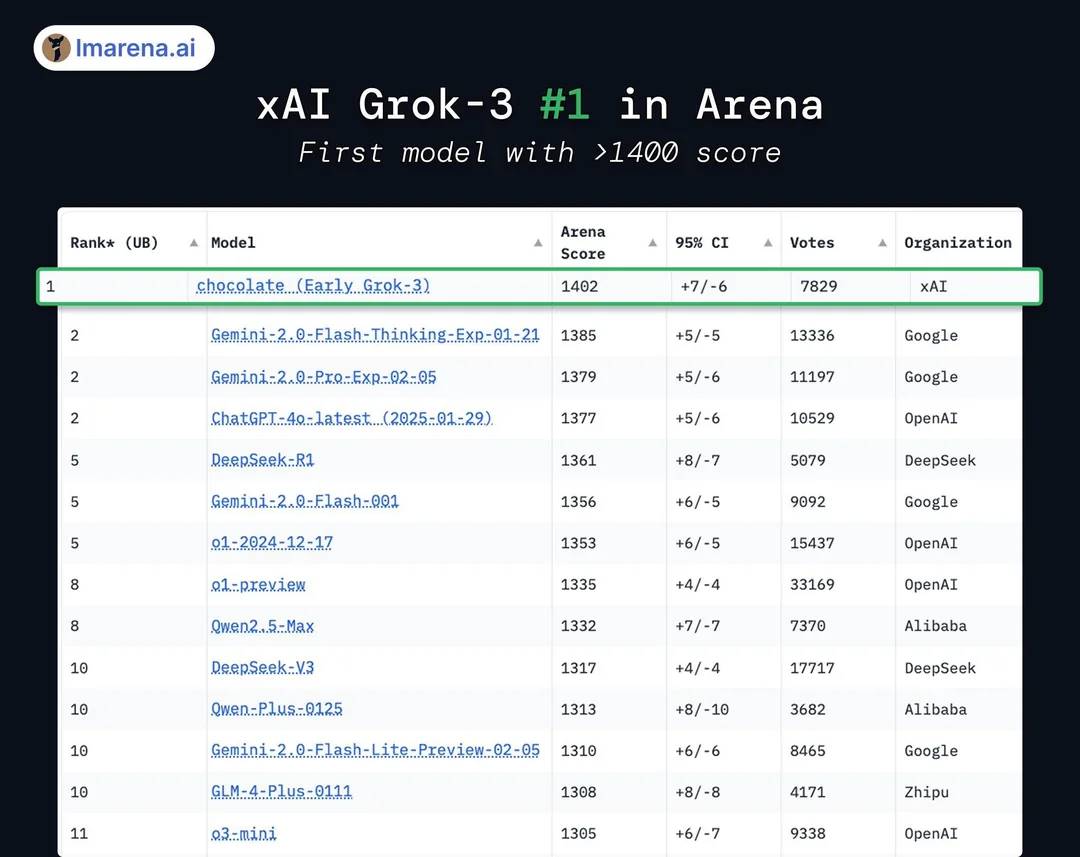
In reality, Grok3 is only 1%-2% higher | Image source: X
Furthermore, although Grok3 surpassed all currently publicly tested models in scores, this is not accepted by many people: after all, xAI has been "scoring" on this leaderboard during the Grok2 era, and the leaderboard has made significant score reductions due to the length and style of the answers, often being criticized by industry insiders as "high score, low ability".
Whether it's "scoring" on the leaderboard or the "little tricks" in the image design, they all demonstrate xAI and Musk's obsession with the idea that the model's capabilities are "far ahead".
And for these differences, the cost Musk has paid is staggering: in the release, Musk boasted that they used 200,000 H100 chips (Musk said "over 100,000" in the live broadcast) to train Grok3, with a total training time of 200 million hours. This led some to believe that this is another major boon for the GPU industry, and that the "stupidity" brought by DeepSeek is a good thing.
Many believe that piling up computing power will be the future of model training | Image source: X
However, in reality, a netizen compared the DeepSeek V3 trained with 2,000 H800 chips for two months, and calculated that Grok3's actual training computing power consumption is 263 times that of V3. And the score difference between DeepSeek V3 and the 1402-scored Grok3 on the large model competition leaderboard is less than 100 points.
After these data was released, many people quickly realized that behind Grok3's "world's strongest" status is the logic that the larger the model, the stronger the performance, which has already shown obvious diminishing returns.
Even the "high score, low ability" Grok2 was supported by the massive high-quality first-party data on the X (Twitter) platform. By the time of Grok3's training, xAI naturally also encountered the same "ceiling" as OpenAI - the lack of quality training data, causing the model's marginal effect to be quickly exposed.
The Grok3 development team and Musk are undoubtedly the earliest and most deeply aware of these facts, so Musk has been constantly stating on social media that the current user-experienced version is "just a test version" and "the complete version will be released in the next few months". Musk himself has even become the Grok3 product manager, suggesting that users provide feedback on the various problems they encounter in the comments.
He is probably the product manager with the most fans on Earth | Image source: X
But in less than a day, Grok3's performance has undoubtedly sounded the alarm for those who hope to train stronger large models by relying on "big flying bricks": according to Microsoft's public information, the parameter volume of OpenAI's GPT4 is 18 billion parameters, which is more than 10 times the increase compared to GPT3, and the rumored GPT4.5's parameter volume may even be larger.
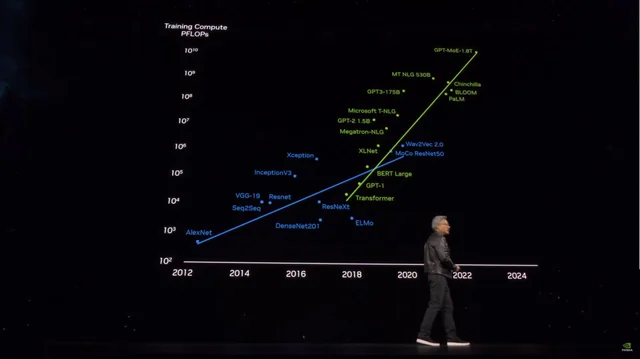
As the model parameter volume skyrockets, the training cost is also soaring | Image source: X
With Grok3 as a precedent, GPT4.5 and more players who want to continue "burning money" to obtain better model performance through parameter volume must consider the imminent ceiling and how to break through it.
At this moment, Ilya Sutskever, the former Chief Scientist of OpenAI, who said last December that "the pre-training we are familiar with will end", has been recalled, and people are trying to find the real way out for large model training from his views.

Ilya's views have already sounded the alarm for the industry | Image source: X
At that time, Ilya accurately foresaw the depletion of available new data, and the difficulty for models to continue to improve performance by acquiring data, describing this situation as the consumption of fossil fuels, stating that "just as oil is a finite resource, the content generated by humans on the Internet is also limited".
In Sutskever's prediction, the next generation of models after pre-trained models will have "true autonomy". At the same time, they will have reasoning capabilities similar to the human brain.
Unlike the current pre-trained models that mainly rely on content matching (based on the content they have learned before), future AI systems will be able to learn and establish problem-solving methodologies in a way similar to human "thinking".
For humans to master a certain discipline, it only requires basic professional books, but AI large models need to learn millions of data to achieve the most basic entry-level effect, and even when you change the way of asking, these basic questions cannot be correctly understood, and the model has not been improved in true intelligence: the basic problems mentioned at the beginning of the article that Grok3 still cannot answer correctly are a direct manifestation of this phenomenon.
But beyond the "power of the brick", if Grok3 can truly reveal to the industry the fact that "pre-trained models are about to reach their limits", it will still be of great enlightenment to the industry.
Perhaps, after the craze of Grok3 gradually subsides, we will also see more cases like Li Fei-Fei's "fine-tuning a high-performance model for $50 based on a specific dataset". And in these explorations, we may finally find the true path to AGI.






