It's time to scale test time compute in a decentralized way. RL is not only a post training paradigm for llm but a bitter lesson aligned one

Noam Brown
@polynoamial
04-17
Our new @OpenAI o3 and o4-mini models further confirm that scaling inference improves intelligence, and that scaling RL shifts up the whole compute vs. intelligence curve. There is still a lot of room to scale both of these further.
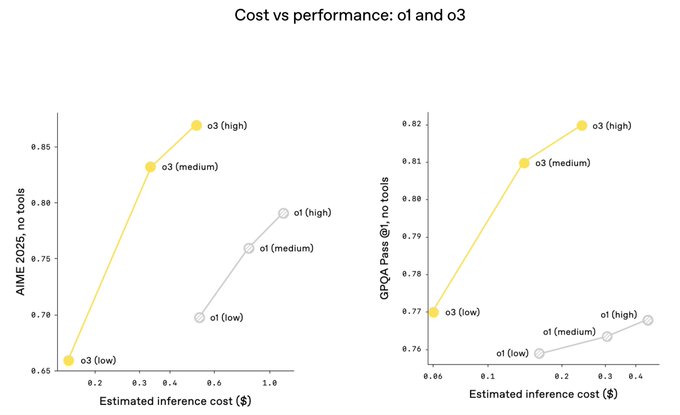
From Twitter
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share
Relevant content