"I'm really tired of seeing those hasty tech startups lying about data to please venture capitalists and slapping on the 'SOTA' label," a netizen complained.
The incident originated from a paper published by the popular open-source intelligent memory project Mem0 at the end of April this year. In the paper, the project team proposed an enhanced version of the scalable, memory-centric architecture Mem0 and claimed to have beaten everyone on LOCOMO, with Mem0 improving by 26% over OpenAI on the "LLM-as-a-Judge" metric. (Paper address: https://arxiv.org/abs/2504.19413)
On August 13 local time, Sarah Wooders, co-founder and CTO of Letta AI, the founding team of another popular intelligent memory framework MemGPT, publicly accused:
A few months ago, Mem0 released MemGPT's benchmark test data and claimed to have reached "SOTA" level in memory.
Strangely, I have no idea how they ran this benchmark test, and the test could not be completed without major modifications to MemGPT (they did not respond to our inquiries about the specific experimental procedure).
arXiv is not a peer-reviewed platform, so unfortunately, companies can now arbitrarily publish any "research" results they want for marketing purposes.
We easily surpassed their benchmark data with some simple file system tools - which also shows that the benchmark test itself is not very meaningful.
"Mem0 claimed they beat everyone on LOCOMO, but it turned out they completely messed up the implementation of their competitors. Then they used these poor results to prove their own advantages. When Letta and Zep ran the benchmark test correctly, both scored 10% higher than Mem0's best performance." A netizen commented, "There are so many 'air products' in this industry. I understand that enterprises may exaggerate features to get venture capital, but lying in scientific papers is truly sad."
Rise of Two "Top-tier" Projects
... (rest of the text continues)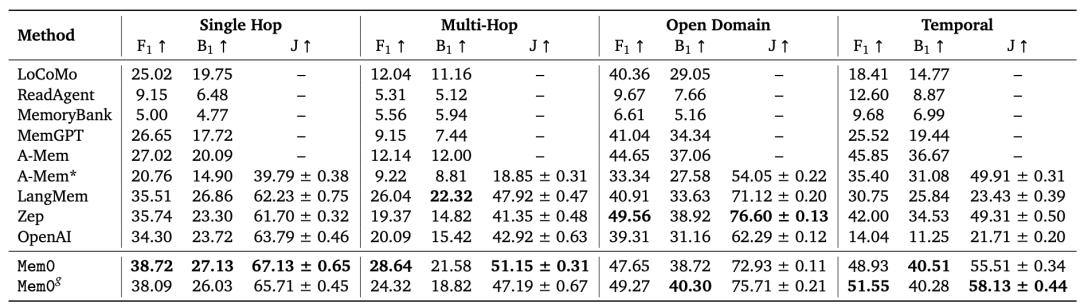
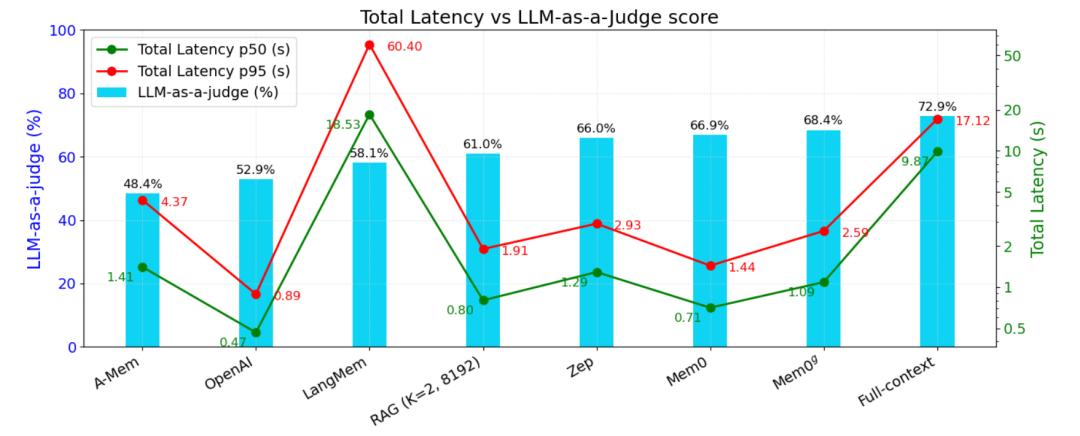
The following image compares the total response latency of different memory methods at p50 and p95, including the latency of large model inference.
The Mem0 team believes that in AI agent deployment, it is important to flexibly adjust the memory structure according to specific reasoning scenarios:
Mem0's dense memory pipeline is good at quick responses and simple queries, minimizing token consumption and computational overhead. After improvement, Mem0's structured graph representation can clearly analyze complex relationships, support complex event sequencing and rich context integration, while not sacrificing actual efficiency. Together, they build a multi-functional memory toolkit that can adapt to diverse dialogue needs and has large-scale deployment capabilities.
In June, Sarah asked on GitHub how Mem0 obtained MemGPT-related data, but received no response.
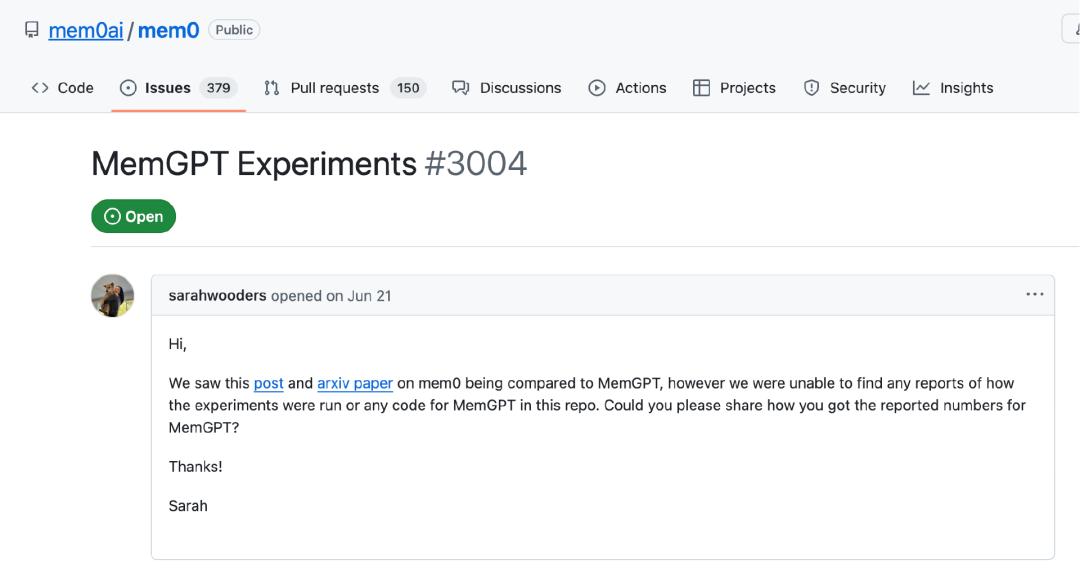
"A memory tool vendor, Mem0, released controversial results, claiming to have run MemGPT on LoCoMo. But the results are confusing because we (the original MemGPT team) cannot find a way to input LoCoMo data into MemGPT/Letta without massive code reconstruction. Mem0 did not respond to our requests for clarification on their benchmark calculation method and did not provide a modified MemGPT implementation that supports LoCoMo data backfilling," Letta stated.
On August 12 local time, Letta wrote that by simply storing conversation history in a file (rather than using a dedicated memory or retrieval tool), Letta achieved 74.0% accuracy on LoCoMo. This indicates that:
Previous memory benchmarks may not be very meaningful;
Memory depends more on how the agent manages context, rather than the specific retrieval mechanism used.
Letta stated that although it does not have a native way to import conversation history like LoCoMo, it recently added file system functionality to Letta agents (including MemGPT agents). "We are curious how Letta would perform if we just put LoCoMo's conversation history into a file without using any dedicated memory tools."
When files are mounted to the Letta agent, the agent can use the following file operation tools:
- grep
- search_files
- open
- close
Conversation data is placed in a file and uploaded and mounted to the agent. Letta automatically parses and embeds file content for semantic (vector) search. The agent can use search_files for semantic search, grep for text matching, and answer_question to answer questions.
To be consistent with the original MemGPT experiment, Letta used GPT-4o mini as the model. Since GPT-4o mini has limited capabilities, Letta made the agent partially autonomous by restricting its tool calling pattern: it must first call search_files to search files, then continue searching until it decides to call answer_question and end. What to search and how many times to search is decided by the agent itself.
"This simple agent achieved 74.0% on LoCoMo with GPT-4o mini and minimal prompt tuning, significantly higher than the 68.5% of Mem0's best graph memory version."
Letta: Capability Matters More Than Tools
Letta believes that today's agents are very efficient in using tools, especially those likely to appear in training data, such as file system operations. Therefore, many specialized memory tools designed for single-hop retrieval are not as effective as letting the agent autonomously iterate through data searches.
Agents can generate their own search queries, not just retrieve the original question, such as transforming "How does Calvin stay motivated when faced with setbacks?" to "Calvin motivation setbacks", and the agent can continue searching until it finds the correct data.
Whether an agent "remembers" something depends on whether it can successfully retrieve the correct information when needed. Therefore, it is more important to consider whether the agent can effectively use retrieval tools (knowing when and how to call them) rather than focusing on specific retrieval mechanisms (such as knowledge graphs or vector databases).
Letta also pointed out that agents can now use file system tools very efficiently, largely because post-optimization has focused on the agent's coding tasks. Generally, simpler tools are more likely to appear in the agent's training data and are easier to use effectively. While more complex solutions (such as knowledge graphs) may be useful in specific domains, they may be more difficult for large models (agents) to understand.
"An agent's memory capability depends on the agent's architecture, tools, and underlying model. Comparing agent frameworks with memory tools is like comparing apples and oranges, because frameworks, tools, and models can be freely combined," Letta said.
So how can agent memory be correctly evaluated?
Letta first recommended their Letta Memory Benchmark, which provides like-for-like comparisons by keeping the framework (currently only Letta) and tools constant, evaluating different models' memory management capabilities. This benchmark generates memory interaction scenarios in dynamic contexts in real-time to assess agent memory, not just retrieval capabilities (like LoCoMo).
Then it pointed out another method is to directly evaluate the overall performance of agents in specific tasks requiring memory. For example, Terminal-Bench tests agents' ability to solve complex, long-running tasks. Since tasks are long and require handling information far beyond the context window, agents can use memory to track task status and progress.
Finally, Letta concluded that for well-designed agents, even simple file system tools are sufficient to perform excellently in retrieval benchmarks like LoCoMo.
Reference Links:
https://x.com/sarahwooders/status/1955352237490008570?s=46
https://www.letta.com/blog/benchmarking-ai-agent-memory
This article is from the WeChat public account "InfoQ", author: Chu Xingjuan, published with authorization from 36kr.