

Original author: David, TechFlow
On the afternoon of January 20th, X open-sourced its new recommendation algorithm.
Musk's response was quite interesting: "We know this algorithm is stupid and needs major revisions, but at least you can see us struggling to improve it in real time. Other social media platforms wouldn't dare to do this."
This statement has two meanings. First, it acknowledges that the algorithm has problems; second, it uses "transparency" as a selling point.
This is X's second open-source algorithm. The 2023 version of the code hadn't been updated in three years and was long out of touch with real-world systems. This time, it's been completely rewritten, with the core model changed from traditional machine learning to the Grok transformer, which the official description claims "completely eliminates manual feature engineering."
In layman's terms: In the past, algorithms relied on engineers manually adjusting parameters; now, AI directly looks at your interaction history to decide whether to push your content.
For content creators, this means that the old mystical methods of "what time to post" and "which tags to use to gain followers" may no longer work.
We also browsed through the open-source GitHub repository and, with the help of AI, discovered that there was indeed some hard logic hidden in the code, which was worth digging into.
Algorithm Logic Evolution: From Manual Definition to AI-Automatic Judgment
Let's clarify the differences between the old and new versions first, otherwise the discussion later will be confusing.
In 2023, Twitter open-sourced a version called Heavy Ranker, which is essentially traditional machine learning. Engineers had to manually define hundreds of "features": whether the post contained an image, how many followers the poster had, how long ago it was posted, whether the post contained links, etc.
Then, weights are assigned to each feature, and the combinations are adjusted to see which one works best.
This new open-source version is called Phoenix, and its architecture is completely different. You can think of it as an algorithm that relies more on large AI models. Its core uses Grok's transformer model, which is the same type of technology used by ChatGPT and Claude.
The official README document states it very clearly: "We have eliminated every single hand-engineered feature."
All the traditional rules that relied on manually extracting content features have been eliminated.
So now, how does this algorithm determine whether content is good or bad?
The answer lies in your behavioral sequence . What have you liked in the past, who have you replied to, which posts have you stayed on for more than two minutes, and what types of accounts have you blocked? Phoenix feeds these behaviors to the transformer, allowing the model to learn patterns and summarize them.
To give an analogy: the old algorithm was like a manually written scoring sheet, with each item checked off and scored;
The new algorithm is like an AI that has seen all your browsing history, directly guessing what you want to see next.
For creators, this means two things:
First, techniques like "best posting time" and "golden tags" are less relevant now. This is because the model no longer considers these fixed features; it focuses on each user's individual preferences.
Second, whether your content gets promoted increasingly depends on "how people who see your content will react." This reaction has been quantified into 15 behavioral predictions, which we will discuss in detail in the next chapter.
Algorithm predicts your 15 reactions
After Phoenix receives a post to be recommended, it predicts 15 possible behaviors that a user might exhibit upon seeing that content:
- Positive behaviors include : liking, replying, forwarding, quoting, clicking on posts, clicking on the author's profile, watching more than half of a video, expanding an image, sharing, staying on the page for a certain period of time, and following the author.
- Negative behaviors : such as clicking "not interested", being a Block author, a Mute author, or reporting.
Each action corresponds to a predicted probability. For example, the model might determine that you have a 60% probability of liking this post, a 5% probability of blocking this author, and so on.
Then the algorithm does something simple: it multiplies these probabilities by their respective weights, adds them up, and gets a total score.
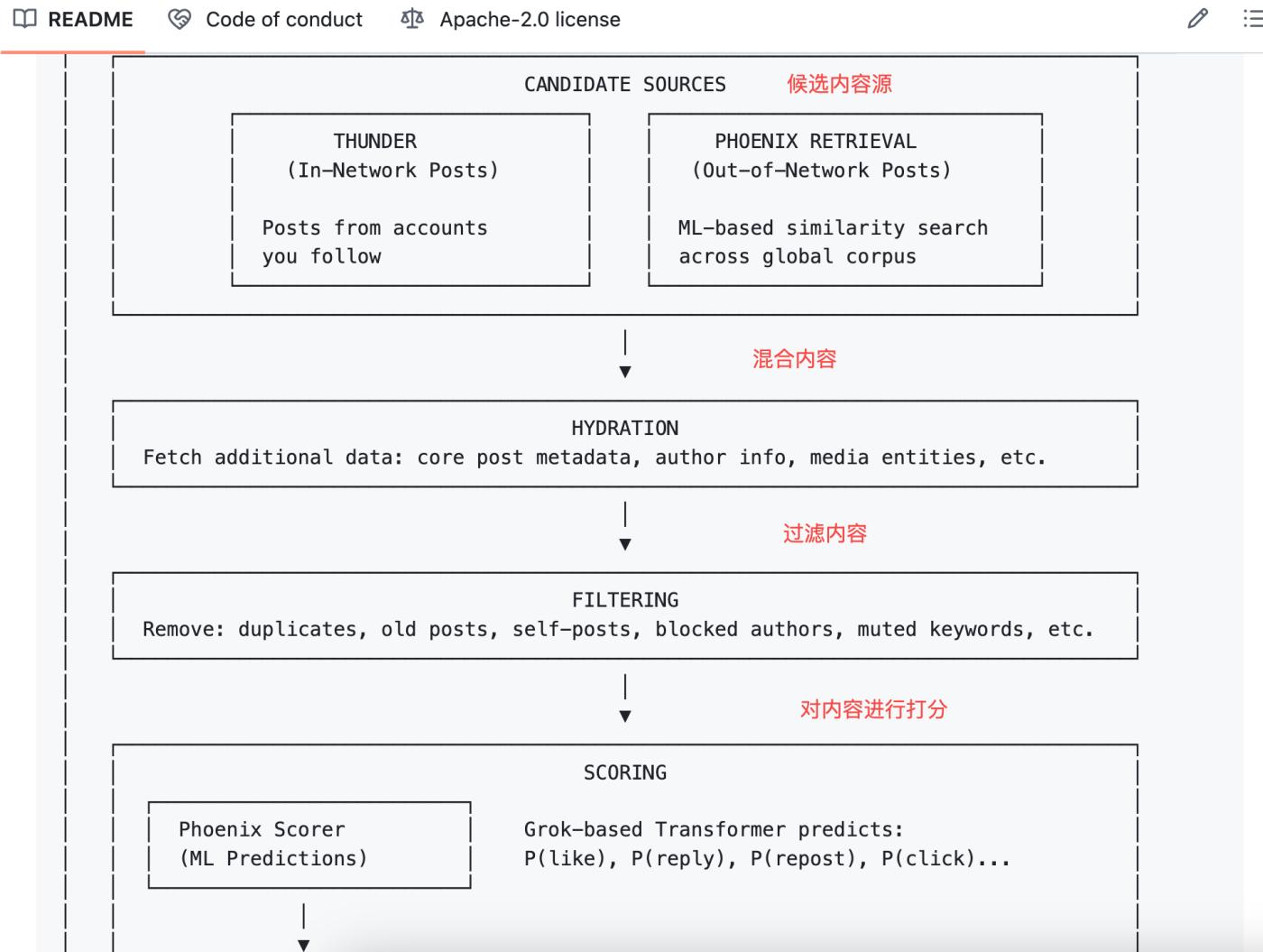
The formula looks like this:
Final Score = Σ ( weight × P(action) )
Positive behaviors have positive weights, and negative behaviors have negative weights.
Posts with higher total scores are displayed at the top, while those with lower scores are displayed at the bottom.
Stepping outside the formula, it essentially boils down to:
Whether content is good or bad now doesn't really depend on how well it's written (although readability and altruism are fundamental to its spread); rather, it depends more on "how this content will make you react." The algorithm doesn't care about the quality of the post itself; it only cares about your behavior.
Following this line of thought, in extreme cases, a vulgar post that evokes irresistible replies and criticisms might score higher than a high-quality post that receives no interaction. This might be the underlying logic of the system.
However, the new open-source version of the algorithm does not disclose the specific values of the behavior weights, but the 2023 version did.
Reference from the old version: One report = 738 likes
Next, we can examine the data from 2023. Although it's old, it can help you understand how much the "value" of various behaviors differs in the eyes of the algorithm.
On April 5, 2023, X did indeed publicly release a set of weight data on GitHub.
Here are the numbers:

To put it more plainly:
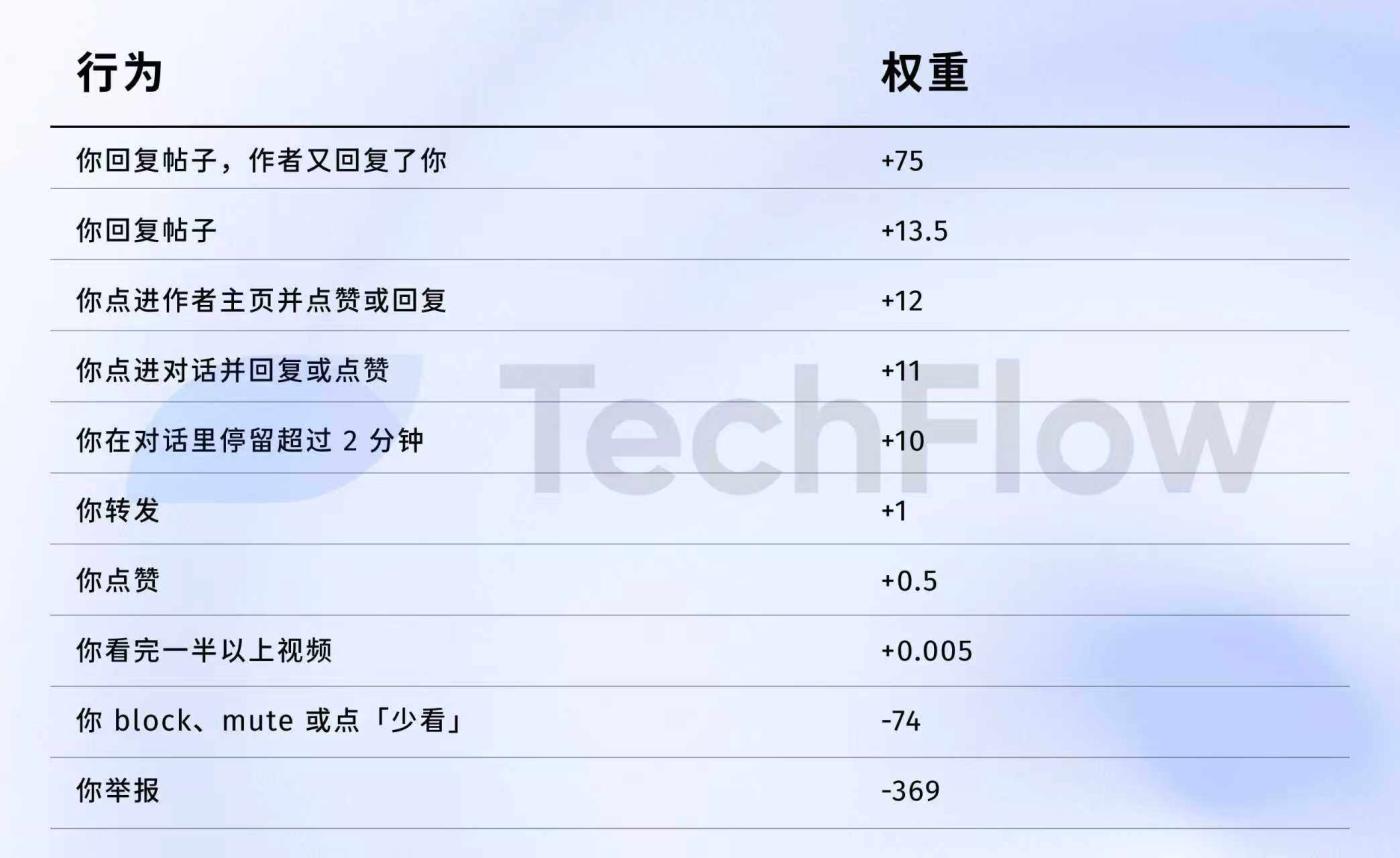
Data source: Old version of GitHub twitter/the-algorithm-ml repository , click to view the original algorithm.
Several figures are worth examining closely.
First, likes are practically worthless. Their weight is only 0.5, the lowest among all positive actions. In the algorithm's eyes, a like is worth approximately zero.
Secondly, interactive dialogue is the true currency. The weight of "you reply, and the author replies to you" is 75, which is 150 times that of a like. The algorithm prioritizes back-and-forth dialogue over one-way likes.
Third, negative feedback is extremely costly. A single block or mute (-74) requires 148 likes to offset. A single report (-369) requires 738 likes. Moreover, these negative scores accumulate in your account's reputation score, affecting the distribution of all subsequent posts.
Fourth, the weighting of video completion rate is ridiculously low, at only 0.005, which is almost negligible. This contrasts sharply with Douyin and TikTok, which treat completion rate as a core metric.
The official document also states: "The exact weights in the file can be adjusted at any time... Since then, we have periodically adjusted the weights to optimize platform metrics."
The weights can be adjusted at any time, and they have indeed been adjusted.
The new version does not disclose specific values, but the logical framework described in the README is the same: positive points are added, negative points are deducted, and weighted summation is performed.
The specific numbers may have changed, but the magnitude of the relationship is likely still there. Replying to someone's comment is more useful than receiving 100 likes. Making someone want to block you is worse than having no interaction at all.
Knowing this, what can we creators do?
After analyzing Twitter's old and new algorithm code, we can extract a few actionable conclusions.
1. Reply to your commenters. "Author replying to commenters" receives the highest score (+75) in the weighting table, 150 times higher than a user's unilateral like. This doesn't mean you should beg for comments, but rather reply to someone who has commented. Even a simple "thank you" will be recorded by the algorithm.
2. Don't make people want to swipe away. The negative impact of a single block requires 148 likes to offset. Controversial content does easily generate interaction, but if the interaction is "This person is so annoying, block them," your account's reputation score will continue to suffer, affecting the distribution of all subsequent posts. Controversial traffic is a double-edged sword; before you harm others, you harm yourself first.
3. Place external links in the comment section. The algorithm doesn't want to drive users off the site. Links in the main text will be penalized , as Musk himself has publicly stated. If you want to drive traffic, write the content in the main text and put the link in the first comment.
4. Avoid spamming. The new code includes an Author Diversity Scorer, which lowers the ranking of consecutive posts by the same author. The intention is to diversify user feeds, but the downside is that one well-chosen post is better than ten consecutive ones.
6. There is no longer a "best posting time". The old algorithm included the human-defined feature of "posting time", which the new version has removed. Phoenix only looks at the user's behavior sequence, not the time the post was made. Strategies like "posting at 3 PM on Tuesdays is most effective" are becoming increasingly less useful.
The above is what can be read at the code level.
There are also some bonus and penalty points from X's public documentation, which are not included in this open-source repository: Blue Label certification provides a bonus, all-caps will result in a penalty, and sensitive content will trigger an 80% reduction in reach. These rules are not open-source, so I won't go into detail.
In summary, the open-source project this time is quite practical.
The system includes a complete architecture, candidate content retrieval logic, ranking and scoring processes, and implementations of various filters. The code is primarily in Rust and Python, with a clear structure, and the README is more detailed than many commercial projects.
However, several key elements were not released.
1. The weighting parameters are not publicly disclosed. The code only states "positive behavior adds points, negative behavior deducts points," without specifying the exact points for likes or deducting points for blocks. The 2023 version at least revealed the numbers; this time, only the formula framework is provided.
2. The model weights are not publicly disclosed. Phoenix uses Grok Transformer, but the model's parameters are not shown. You can see how the model is invoked, but you can't see how it's calculated internally.
3. The training data is not publicly available. It's unclear what data was used to train the model, how user behavior was sampled, or how positive and negative samples were constructed.
To give an example, this open source is like telling you "we use weighted summation to calculate the total score", but not telling you what the weights are; telling you "we use transformer to predict the probability of behavior", but not telling you what the transformer looks like inside.
In comparison, TikTok and Instagram haven't even disclosed these details. X's open-source content this time does indeed contain more information than other mainstream platforms. However, it's still far from being "completely transparent."
This is not to say that open source has no value. For creators and researchers, seeing the code is always better than not seeing it.





