Welcome to the 458 newly Not Boring people who have joined us since our last essay! Join 260,170 smart, curious folks by subscribing here:
Hi friends 👋 ,
Happy Wednesday!
A few months ago, Pim DeWitte and Kent Rollins invited me to their office right here in New York City to show me what they’ve been cooking up at General Intuition. I’d heard about the company, from the announcement of their leet $133.7 million Seed round, and I’d heard about the class of product they were building, World Models, but I didn’t know much beyond that.
What they showed me that day, models that learn to predict the near future from action-labeled gaming clips, and what I’ve learned from many conversations and dozens of hours of research since, has changed my perception of what models can do. I am on the record as being skeptical that LLMs will take us to superintelligence, but I think there is a real shot that World Models will drive superhuman, complementary machines that do things that we can’t, or don’t want to, do.
Since that first meeting, the World Models space has heated up. Fei-Fei Li’s World Labs raised $1 billion. Yann LeCun’s AMI raised $1.03 billion. World Models were one of the stars of this week’s NVIDIA GTC. But the field is so nascent and there is so much going on, so many geniuses pursuing competing and collaborative approaches, that it’s hard to make sense of it all.
So I asked Pim to team up with me on a co-written essay about the history, theory, progress, and potential of World Models. He agreed, and both he and the General Intuition team have been incredibly generous with their time and human intelligence in helping me get up to speed, so that I can help you get up to speed.
I have the coolest job in the world. Over the past couple of months, I’ve gotten a front row seat to the future of embodied AI, of Models and Agents, trained in dreams, that direct machines to do things for us in the physical world.
I’m thrilled to share the fruit of that exploration, what I think is the most comprehensive guide to World Models that exists. Obviously, Pim and the GI team have a perspective on the best way to build World Models, but I was impressed with how careful they were to present the pros and cons to every approach, including theirs, and with their admission that the future is not yet determined.
The space continues to change and progress incredibly fast. I hope this will help you navigate and make sense of all of the exciting news that continues to drop.
Let’s get to it.
Today’s Not Boring is brought to you by… Framer

Framer gives designers superpowers.
Framer is the design-first, no-code website builder that lets anyone ship a production-ready site in minutes. Whether you’re starting with a template or a blank canvas, Framer gives you total creative control with no coding required. Add animations, localize with one click, and collaborate in real-time with your whole team. You can even A/B test and track clicks with built-in analytics.
Launch for free at Framer dot com. Use code NOTBORING for a free month on Framer Pro.
World Models: Computing the Uncomputable
A Co-Written Essay with Pim DeWitte

“I wanted to fall asleep last night. Instead, I started imagining all of the scenarios I might run into the next day, and how I might react to them.”

This is a common experience. As humans, we imagine easily, whether it’s complex sports stadiums, potential romance, or heated discussions. We don’t have to work harder to imagine ourselves at the next Manchester United game than we do to imagine talking to a friend we’ve known for years, even though imagining a Manchester game includes simulating and modeling the behavior of thousands of people, something that would take years for traditional computers and game engines today1.
Think about writing the code to describe the Man U match: at any moment, a fan might bring a random, home-crafted flag. The entire stadium starts singing a song related to it. Only some will sing, though; others will jump with their kids, while an old couple sits still, wondering if this is their last game together, soaking in every second in silence.
The world is a place where unexpected futures unfold, but in somewhat predictable ways. As humans, we can envision almost all of them with roughly the same amount of effort with a very similar amount of time given to each thought. Computers can’t.
It’s no wonder traditional computing struggles with this complexity. Imagine anticipating and coding each and every action, as well as the interactions between all of those actions. Mathematically, in a traditional engine, simulating N fans is at least an O(N) or O(N2) problem. Each person, flag, chair, and ball must be explicitly calculated — and really, the interactions between them need to be calculated, too.
In robotics, machines must respond to situations in the real world in the same amount of time, regardless of their complexity, even though, in traditional computing, different situations can take wildly different amounts of time to simulate. This has been a major bottleneck for robotics and embodied AI progress.
World Models are a solution to that problem.
World Models learn to predict those dynamics from video and, often, the actions taken in them. They reduce situations that are dynamic and computationally difficult to simulate at scale — including stochastic, action-dependent group behavior like soccer games — into a single fixed cost operation in a neural network.
In a World Model, the entire stadium is simulated as a fixed cost forward pass through the neural network. The complexity of the scene doesn’t exponentially slow down the ‘engine’ during inference because the weights have already absorbed the patterns of the world in training.
How? Actions.
Actions act as a form of compression to predict unfolding dynamics: they hold the information to unroll future states in an environment, until more actions take place and add new inputs into the environment. Each action carries enough information to predict what happens next, until the next action updates the picture.

This action-conditioned approach allows models to learn and plan interactively. Today, this is intractable in even the best simulation engines, and definitely not at predictable compute costs. Actions help models interact with the world like we do.
Over and over again, every single day, you observe, you compute, you decide what to do, you act. This is life. At any point, all gathered information about space and time collapses into the action you take.
For computers, actions are a cheat code around the costs of simulation. If human brains are much more efficient than best-in-class LLMs, then we can get all of that computation practically for free by observing how humans respond to the countless variables in their environments. This gives us a way to do non-deterministic computing efficiently and create simulations that shouldn’t be possible under traditional compute constraints.
This ability to compute the uncomputable is why we believe World Models will unlock progress in embodied AI in a way that current model architectures can’t.
Think about models like dreams.
Have you ever had a dream where you simply stood and watched what was happening without the ability to intervene? That’s a video model.
The real world is different. It responds to what you do or instruct to do, and predicts the full range of things that could happen as a result, not just the single most likely or most entertaining next frame.
Have you ever had a lucid dream in which you were able to shape the story inside the mind-generated dreamscape? That’s a World Model.
I coded up a comparison that you can play with here.
More formally, while a standard video model predicts the next frame based on probability, P(xt+1 | xt), a World Model predicts the next state based on intervention, P(st+1 | st, at).
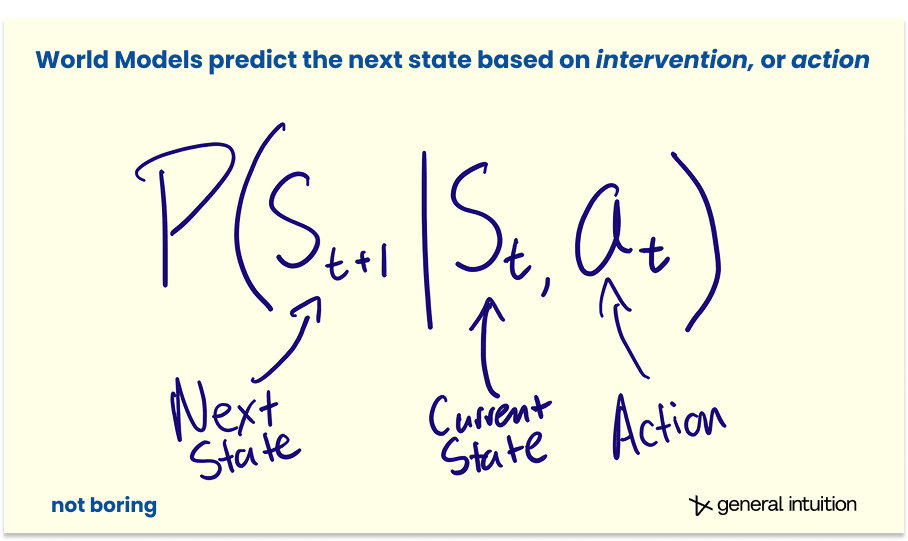
That at, the action at time t, is the magic.
At General Intuition, we believe (and are seeing early signs) that World Models are a new and potentially more powerful class of foundation model than LLMs for environments that require deep spatial and temporal reasoning. Environments like our real world.
World models — these systems that learn from watching the world and the actions taken in it — are a fundamentally new kind of foundation model. They can compute what was previously uncomputable.
They will matter far more than anyone currently realizes, because they offer a path to general intelligence that language and code alone cannot. Being human, after all, is spending a lifetime taking actions based on what we experience, observe, and learn.
Pause. You might be confused by that claim, that World Models offer a path to general intelligence that LLMs cannot. Understandably so.
World Models are getting a lot of attention as of late. Yann LeCun, who has been skeptical that LLMs are the path to general intelligence, just announced that he raised $1.03 billion for AMI. Fei-Fei Li’s World Labs has also raised more than $1 billion to pursue World Models. Google DeepMind, which has the closest thing to an infinite money printer in tech, is betting money on World Models too. But what we’ve seen so far from that investment are cool videos and 3D worlds.
LLMs can quote Shakespeare and solve Erdős Problems. World Models, on the other hand, still seem more like a path to the Metaverse than a path to general intelligence.
But part of the reason World Models don’t yet have the hype of LLMs is that their definitions are still shaky.
What are World Models? We’ve already said that video models don’t fit the definition. 3D space models don’t, either. That said, both may be paths to World Models. Are the models that animate robots today World Models? Not really, although some are, and even the ones that aren’t share features with World Model architectures.
As always, hype adds to confusion. “My prediction is that ‘World Models’ will be the next buzzword,” Alexandre LeBrun, the CEO of AMI Labs (which is definitely a World Model company) told TechCrunch. “In six months, every company will call itself a World Model to raise funding.”
Hype is a small part of it. What we — and everyone else building in this space — believe is that World Models are the path to controlling machines in the physical world. There are differences in what we believe this path will look like. But all of us believe that the future runs through World Models.
“...very few understand how far-reaching this shift is…,” NVIDIA Director of Robotics and Distinguished Scientist Jim Fan said recently. “Unfortunately, the most hyped use case of World Models right now is AI video slop (and coming up, game slop). I bet with full confidence that 2026 will mark the first year that Large World Models lay real foundations for robotics, and for multimodal AI more broadly.”
Today, we’d like to welcome you into the group of the “very few” who “understand how far-reaching this shift is.” We are going to share the history of World Models, the state of the field as it stands today, broad explanations of the approaches each major lab is taking, and the convictions that drive General Intuition’s directions.
Whether you come with us is up to you. You take the blue pill, the story ends. You wake up in your bed and believe whatever you want to believe. You take the red pill... you stay in Wonderland, and we show you how deep the rabbit hole goes.
For example…. how can you be sure that you’re not an Agent operating inside of a World Model yourself?
Can Agents Learn Inside of Their Own Dreams?
Wake up, Neo.

World models aren’t a new idea. They are one of our oldest. Since humans gained the ability to think about our place in the universe, to ask why we are here, we have pondered whether our reality is just a simulation.
In 380 BC, Plato, via Socrates, offered The Allegory of the Cave. Imagine human beings who live underground in a cave, necks chained, forced to look ahead at the shadows on the wall. Those humans would believe those shadows to be reality, when in fact they are mere shadows of reality. This was Plato’s metaphor. He suggests that we are all stuck in the cave, necks chained, mistaking our perception for true reality.
Eighty years later, Chinese Daoist philosopher Zhuangzi contemplated similar questions in a passage of his Butterfly Dream:
Once Zhuang Zhou dreamt he was a butterfly, a butterfly flitting and fluttering around, happy with himself and doing as he pleased. He didn’t know he was Zhuang Zhou. Suddenly, he woke up and there he was, solid and unmistakable Zhuang Zhou. But he didn’t know if he was Zhuang Zhou who had dreamt he was a butterfly, or a butterfly dreaming he was Zhuang Zhou. Between Zhuang Zhou and a butterfly there must be some distinction! This is called the Transformation of Things.
As the centuries passed and our technological capabilities evolved, sci-fi writers joined the long lineage of thinkers inquiring about the true nature of reality. Frederik Pohl’s 1955 The Tunnel Under the World. Daniel F. Galouye’s Simulacron-3. Stanislaw Lem’s Non Serviam. Vernor Vinge’s True Names. William Gibson’s Neuromancer. Neal Stephenson’s Snow Crash. All painted textual pictures of simulated worlds.
During a 1977 speech in Metz, France, sci-fi legend Philip K. Dick confidently told the audience: “We are living in a computer-programmed reality, and the only clue we have to it is when some variable is changed2, and some alteration in our reality occurs.”
Your first interaction with the simulation was probably The Matrix. Ours was. In the original script for The Matrix, the Wachowskis conceived of the Matrix as a simulation collectively produced by human brains chained into a neural network.

The studio thought humans-as-computers was too confusing a concept for mass-market audiences, so they made the thermodynamically questionable decision to turn humans into batteries that powered the simulation. That was probably the right commercial call. The Matrix franchise has done nearly $2 billion in worldwide gross. More impactfully, it introduced the masses to the idea of a simulated world generated indistinguishable from the “real” one.
It’s no wonder that this idea has taken hold of our collective imagination. It’s certainly the right kind of weird but it’s also surprisingly hard to disprove. If the observations are the same, and the actions are the same, then the computation is the same. If what you see is the same and what you do is the same, it doesn’t matter whether you’re in a simulation or reality. It doesn’t matter whether you’re walking down a real street or a simulated one. Your brain processes both identically. Neo had no idea he was in the Matrix until Morpheus woke him up.
Christopher Nolan, throwing audience confusion to the wind — savoring it, even — released Inception3 in 2010. Dreams within dreams within dreams.

Nolan’s central premise is that the dream is a controllable space from which information can be extracted or, more importantly, into which information can be implanted.
But it’s all just sci-fi, right?
In 1990, Jürgen Schmidhuber, a young researcher at the Technical University of Munich, published Making the World Differentiable.
The paper proposed building a recurrent neural network (RNN), a neural network with two jobs: first, learn to predict what happens next in a simulated world and second, use that simulated world to train an Agent to act in it.
The Agent wouldn’t need to interact with a “real” environment at all. It could learn inside the model. Inside a dream.

The following year, Richard Sutton, of Bitter Lesson fame, dreamt up a similar idea. In Dyna, an Integrated Architecture for Learning, Planning, and Reacting, he argued that learning, planning, and reacting shouldn’t be separate systems. They should be unified in a single architecture. Which would mean that it’s technically possible to build a model of the world, practice inside it, and transfer what you learn back to reality.
Both papers were visionary. They would have a lasting impact as progress in the field enabled the researchers’ visions to become reality. But coming when they did, both papers may as well have been sci-fi.
In 1990, the world had something like 100 trillion to 1 quadrillion times less compute than we have today. Back then, the entire world had maybe 10-100 gigaFLOPS of total capacity. Tens of zettaflops (10^22 FLOPS) of computing power were sold in 2024 alone. In 1990, the global digital datasphere was approximately 10 petabytes, a volume so small it could barely hold 0.005% of the video data we now use for a single training run. By 2026, that volume has exploded by a factor of 22 million to 221 zettabytes.
But technology improves, and the most powerful dreams do not die.
Nearly three decades later, in March 2018, David Ha (then at Google Brain) and Schmidhuber published a paper titled World Models.4

The paper asked: Can agents learn inside of their own dreams?
To answer their own question, Ha and Schmidhuber built a fictional system with three components: a vision model (V) that compressed raw pixel observations into a compact representation, a memory model (M), a recurrent neural network that learned to predict what happens next, and a tiny controller (C) that decided what to do based only on V and M’s outputs.
The World Model was V + M: it could take in observations and imagine plausible futures. The controller was the Agent or policy: it chose which actions to take.
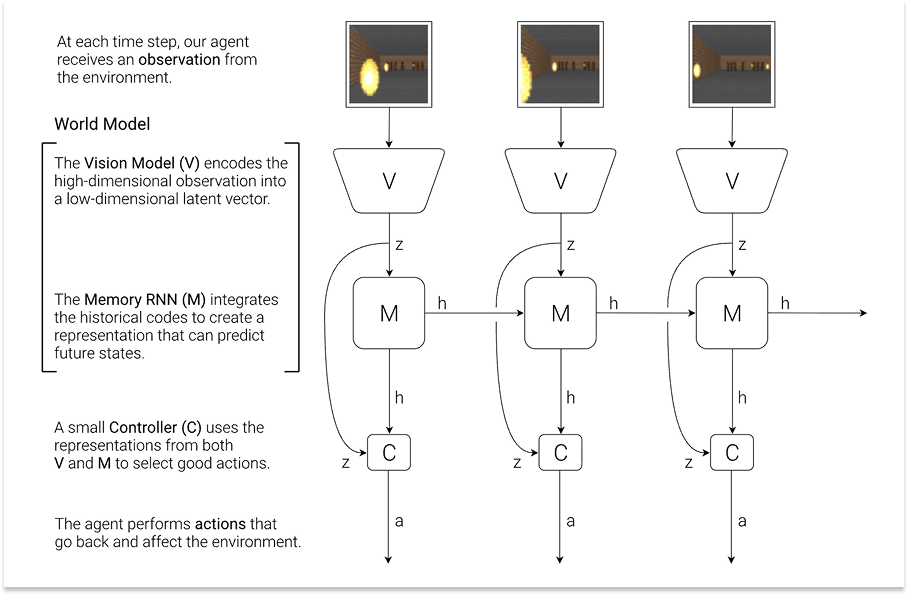
The paper joined in conversation with those centuries of thought experiments, novels, and movies. A dream might be reality, reality might be dreams. But what if we could actually act in our dreams? What would that do to reality?
Ha and Schmidhuber trained their World Model on observations from a car racing game and a first-person shooter game. The World Model generated new digital worlds. Then, they let the Agent practice entirely inside the World Model’s hallucinated dreams. Afterwards, they transferred the learned policy back to the actual environment.
And... it worked. The Agent could solve tasks it had never encountered in reality. The dream was real enough.
It was shocking, from a computer science perspective. But was it really so surprising? Isn’t this how humans navigate the world?
Ha and Schmidhuber noted that humans constantly run World Models in their heads. A baseball player facing a 100 mph fastball has to decide how to swing before the visual signal of the ball’s position even reaches their brain. The reason that every at-bat doesn’t result in a strikeout is that batters don’t react to reality, but to their brain’s “internal World Model’s” prediction of where the ball will be.
Donald Hoffman, Professor of Cognitive Sciences at University of California, Irvine, takes that idea a million steps further. He believes that we all walk around wearing “reality headsets” that simplify the staggering complexity of the quantum world into a user-friendly interface. Reality is too rich, so we navigate it via a sort of persistent waking dream.
This rabbit hole goes as deep as you want it to. But it’s World Models all the way down.
Ha and Schmidhuber showed that computers might be able to approach the world like we do: creating simulations to predict future states based on actions, acting based on those predictions, updating, and looping.
Actions, not words.
Language is Not Enough (Neither is Code)
Let’s play a game.
Clap your hands five times.
Now, instead of physically clapping your hands, I want you to describe clapping your hands using just words.
Where they are positioned in space, where they are relative to each other, by the picosecond. The points of contact. The sounds. What your hands look like as they move closer to each other, make contact, and pull apart. How they squish each other. What happens to the air between your two palms. What you see while your hands clap. Don’t forget your arms. How do they bend to facilitate the claps? Remember to do this by the picosecond, too. How does the fabric on your sleeve respond? What is happening in the background? Did the person next to you notice you clapping? How did they respond? Did you get fired for clapping in the middle of the meeting, following the instructions of an essay you shouldn’t have been reading while you should have been paying attention to work? Describe to me the vein on your boss’ forehead. Is it popping?
You can’t, can you? OK, stop. The point is made.
Language is an incredibly lossy compression of reality.
Language is important, of course. It is how we communicate and coordinate. The game Charades illustrates that to communicate ideas, language can be much more efficient than actions. LLMs are important in that capacity. But language alone is not enough.
What about code? Code is a form of very precise language that makes machines do things.
I asked Claude to “code me a simulation of hands clapping five times in a realistic environment.” It built me this. Which looks very painful.

There is a belief that, with scale, language and code will be able to solve all spatial-temporal intelligence challenges and produce Artificial General Intelligence (AGI) or Artificial Superintelligence (ASI).
Some argue that code is the key to solving many real-world intelligence challenges because it can perfectly instruct all physical form-factors with precision.
We do not share that belief. A code-based simulation is a poor version of a dream. It is rule-bound and unable to handle the stochastic messiness of reality.
To know the world, you must interact with it.
In The Glass Bead Game (Das Glasperlenspiel), a novel by Herman Hesse that won him the Nobel Prize for Literature in 1946, readers are introduced to Castalia, a future intellectual utopia devoted to pure thought. At Castalia’s center is an elaborate game, the titular Glass Bead Game, that synthesizes all human knowledge into a single formal language. Players compose “games” the way one might compose a fugue. A move might link a Bach cantata to a mathematical proof to a passage from Confucius. The game is the ultimate abstraction: all of human culture compressed into symbolic manipulation.

The protagonist, Joseph Knecht, rises to become Magister Ludi, Master of the Game, the highest position in Castalia. But he grows disillusioned. The game, for all its beauty, is sterile. Castalia’s intellectuals have retreated so far into abstraction that they’ve lost touch with the world. They can represent reality with extraordinary elegance, but they cannot act in it.
Knecht ultimately decides he must leave Castalia, and becomes a simple tutor. He chooses the messy, embodied, unpredictable world over the perfect symbolic one. He dedicated his life to the Game, the mastery of which involves operating on a level of abstraction beyond words, something closer to world modeling. But it wasn’t enough. Symbols alone, without contact with reality, eventually run dry.
Large Language Models are our Castalians. They are exquisite manipulators of symbols, capable of drawing connections across the entirety of human textual knowledge. They can discuss physics, compose poetry, write code, and explain the rules of baseball. They are, genuinely, one of the great intellectual achievements in human history.
But they operate entirely in the realm of representation. They can describe clapping, but they cannot clap. They can talk about gravity, but they do not know gravity the way a toddler knows gravity. They do not learn, the way a body learns, through thousands of falls and stumbles, what “down” means.
Language models predict the next token extraordinarily well. The only problem is that tokens are like shadows on Plato’s cave wall. And you cannot code your way to a realistic stadium crowd any more than you can describe your way there.
The real world is — or was — uncomputable.
If language and code, two of mankind’s most powerful inventions, are inadequate to represent our world, what do we have left?
The Answer is World Models
World Models offer another approach on the path to AGI. They offer a path to compute the things that are, today, uncomputable. They learn from the messy contact with reality that Knecht sought.
World Models offer a way to do non-deterministic compute efficiently, and to run simulations that shouldn’t be possible under traditional compute constraints.
World models are not a replacement for LLMs. Language remains essential; text can be used to condition World Models, to tell them what scenario to imagine, what goal to pursue, to give them a long-term goal. The thinking and the doing work together. But the doing has to come from somewhere other than text.
Joseph Knecht must come down from Castalia.
Real intelligence must come from observation of the world; from understanding actions and their consequences; from the things that language can only point at.
The Dao that can be told is not the eternal Dao.
In the beginning was the Word. Then came humans, to act imperfectly and unpredictably.
Maybe this is the way of things. In the beginning were LLMs. Then came World Models.
What Are World Models?
A World Model simulates environments and responds when you act inside them.
More formally, a World Model is an interactive predictive model that simulates spatial-temporal environments in response to actions.
While LLMs predict the next word in a sentence, World Models predict the next state (as in, the immediate future), conditioned on the current state and control input.
More succinctly: LLMs learn the structure of language. World Models learn the structure of causality.
This is a simple definition of World Models. It is accurate, but it’s not enough to understand how World Models work. For that, you’ll need to know four things:
What World Models do,
How they’re built,
Why “action” is so important, and
The relationship between World Models and policies.
What World Models Do
Think about what happens when you catch a ball. Your eyes take in a scene: the thrower’s arm, the ball in flight, the wind, the sun in your eyes, all of it. From that flood of sensory data, your brain builds a compressed model of what’s happening and, crucially, what’s about to happen. It predicts the ball’s trajectory a few hundred milliseconds into the future. Then it sends a motor command to your hand. You catch the ball. The whole loop — observe, predict, act — takes a fraction of a second and involves no language or “thinking” whatsoever.
A World Model does the same thing, computationally. It takes in observations (often video frames, though it can use any sensory data), builds a compressed internal representation of the environment’s state, and predicts how that state will change in response to actions.
It is, in essence, a learned physics engine, but one that doesn’t rely on hand-written equations. Instead of calculating gravity, collision, and friction from first principles, it has watched gravity, collision, and friction billions of times and learned the patterns.
This makes World Models a powerful tool for building Agents, AI systems that act in environments. World Models help Agents in three ways:
They serve as surrogate training grounds. An Agent can practice inside the World Model (basically, inside a dream) and transfer what it learns back to reality. This is important for safety (some things should not be tested or trained in the real world) and cost or sample/data efficiency (real world data is expensive, costly to gather, not available, you need a lot of it, etc.).
They enable planning over longer time horizons. An Agent can “imagine” the consequences of different actions before committing to one, the way a chess player thinks several moves ahead, except here, the board can be any environment or the real world.
They provide rich representations of the world for Agents to learn behaviors from. An Agent trained on a World Model’s internal representations learns to “see” the world in terms of the features that matter for acting in it, rather than raw pixels.
For these three reasons, the promise of World Models is that they are a path towards generalization. If you can create worlds that respond to actions the way the real world does, you can use them to safely, economically, and efficiently train embodied agents that can act in any virtual world, or the real one.
To be clear, this is the massive question in World Models: whether the simulated environments are faithful enough to reality that you can train on them and have that training transfer to the real world or more generally, whether you can “pre-train in sim.” Increasingly, the answer seems to be yes.
Ai2, the Allen Institute for AI, is a non-profit founded and funded by the late Microsoft co-founder, Paul Allen. It does great open source research and tooling, including its recent release of MolmoBot, an “open model suite for robotics, trained entirely in simulation.”
“Our results show that sim-to-real zero shot transfer for manipulation is possible,” they tweeted.
Dhruv Shah, a Princeton professor and Google DeepMind researcher who worked on the project, shared: “Within the scope of easily simulate-able tasks, a purely sim-trained policy outperforms SOTA VLAs trained on thousands of hours of real data!”
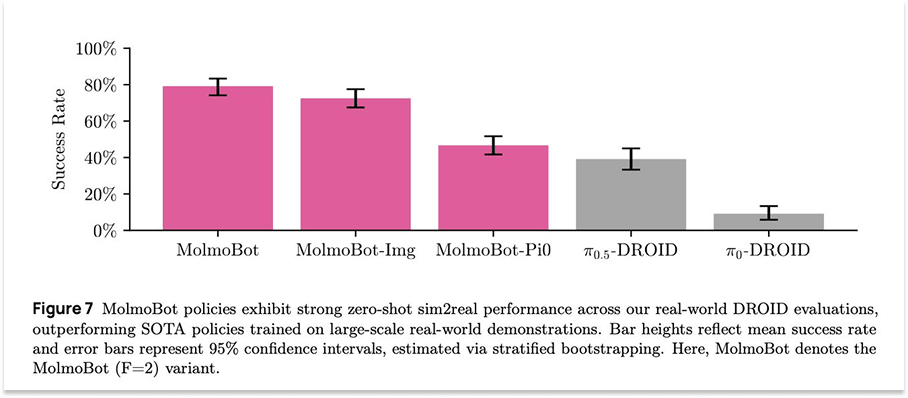
It is a pretty astonishing finding. A big focus of ours, and of the broader World Models field, is to expand the scope of tasks that are easy to simulate.
This is how it works. First, World Models imagine realistic environments and future states, ideally that respond to actions or instructions in the way the real and virtual worlds they’ve been trained on do. Next, the Agents are let loose inside of the generated worlds to train. Then, the Agents are brought back into real environments and are tested on what they’ve learned.
This is what Ha and Schmidhuber demonstrated in 2018. It remains the central promise of the field.
How World Models Are Built
World Models are fairly young. No single approach or combination thereof has proved superior, which means that the final architecture for general World Models is still an open question. There are, however, repeatable ingredients for training.
Start with data; massive quantities of observation data. Often, observations are paired with the actions taken to produce them. This pairing can come about in several ways. Observations (typically video) are collected in advance and actions are either recorded alongside them, or inferred via another model after the fact. Alternatively, the model learns by taking actions itself, generating its own observations and action data through direct interaction with an environment.
When the training data is observations or videos, the raw frames serve as observations of an environment unfolding over time. These videos are ideally labeled with the actions that produced them (either because they were recorded together or inferred with a separate AI model). The actions provide the causal link: what someone did that made the environment change. A gameplay clip where a player turns left and the camera pans to reveal a hallway. A driving recording where the wheel turns and the car follows a curve. A teleoperation session where a robotic arm reaches and a cup moves. In each case, the model sees a before, an action, and an after.
When the model learns through interaction, the same structure applies — before, action, after — but the data is generated on the fly rather than collected in advance, and the actions come from the model’s own developing policy rather than from an external source.
The World Model’s core objective remains the same: given the current state and an action or instruction, predict the next state. It sees frame t and action a, and tries to produce state frame t+1.
But predicting raw pixel worlds for everything can be expensive and often wasteful. Most of what’s in a video frame doesn’t change from one moment to the next; the walls stay where they are, the sky remains the sky. And most of the details within a frame are redundant; the color of the sky, the texture of a wall. They could be described in a more compact form.
So modern World Models involve a latent space: a compressed, learned representation where only the most essential information is retained.
The visual encoder compresses each frame down to a compact vector (a mathematical fingerprint of the scene) and the model learns to predict the next fingerprint — not every pixel in the 4K frame — in response to actions. This is where the computational efficiency comes from.
To accurately model the evolution of the world, World Models must also learn to represent the full set of possible outcomes. This uncertainty in outcomes is usually referred to as the stochasticity of the environment.
World Models have to learn to navigate what they don’t know yet (epistemic uncertainty: for example, a model that has never seen a traffic light will not know that red follows after yellow) and the inherently unknowable (aleatoric uncertainty: the randomness, like rolling dice5).
Even when the model has learned all that’s possible to know about the behavior of the environment (it has reduced its “epistemic” uncertainty to a minimum), there will almost always be some inherent uncertainty (“aleatoric” uncertainty) in what happens next. This is in contrast to pure entertainment video models, which only need to be able to predict a common evolution of the world state to perform well.
If you use a straightforward prediction approach (for example, a model naively trained with Mean Squared Error, or MSE) to predict a car turning a corner, the model can become ‘blurry’ because it averages every possible outcome. The car could turn and stay in the left lane, or it could merge into the right lane. The trajectory that actually minimizes the error is the implausible one where the car stays in the middle of the two lanes. That’s the blurriness, and different models handle it differently.
Diffusion models avoid this problem by gradually diffusing towards the outcome, enabling the model to commit to a specific mode of the outcome distribution, sampling a sharp, plausible future rather than averaging all possibilities.
Autoregressive models with multiple tokens per outcome also handle multimodality; by sampling one token after the other, they ensure that future token predictions are consistent with previous ones.
JEPA-style architectures, by contrast, address blurriness by simply sidestepping it. JEPA largely avoids having to model that distribution explicitly by never decoding back to pixel space at all. It operates in a space where averaging is less catastrophic, because we don’t expect these models to predict frames, but rather to develop representations that are useful for downstream tasks.
What comes out of this process depends on what you need. If you’re building a visual world simulator — something you can watch or explore — you decode the latent predictions back into pixels through a visual decoder, producing imagined video of plausible futures. This is what makes the demos from Google DeepMind and World Labs look realistic and impressive.
There are a number of approaches used to train World Models. We will cover them and how they evolved and built on each other through the lens of the brief eight-year modern history of the field shortly.
For now, keep this in mind: observation data in, paired with the actions that caused what’s happening in those observations, train World Models to predict the next state, Agents train to predict the next action in those Worlds.
Why Actions are the Ultimate Form of Compression
Here is a key insight behind World Models: actions are the ultimate form of compression.
Consider what happens when you decide to step left to avoid a puddle. Your brain processes the visual scene (the sidewalk, the puddle, the people around you, the curb, the approaching bus), predicts the immediate future (the puddle won’t move, the bus will pass, the person behind you will keep walking), evaluates options (step left, step right, jump, accept wet shoes), and selects one.
An outside observer can’t see inside your head, can’t know exactly what you were thinking, can’t know what you’re processing subconsciously. They don’t know if you’re tired or if you’re in a rush. They don’t know your moral code, how you, specifically, would answer the Trolley Problem. They don’t need to. They see the output of all of that near-instantaneous calculation: step left.
That, to me, is magic.
Of course, not everyone makes the right decisions. Play the video forward and you are able to learn the consequences, too. Step left, into an even bigger puddle. Step left, and get clipped by a car. Step left, and knock a baby out of its stroller. Over billions and billions of observations and instructions and actions, we learn not just how humans decide to respond based on inputs, but the consequences of those decisions. The collective World Model learns to act smarter than any individual.
Zoom back into the individual. If you could perfectly reconstruct someone’s stream of observations and actions, you would have a nearly complete record of their interaction with reality. You would know what they saw and what they did about it. The World Model learns exactly this mapping. It compresses space and time into a compact representation, and then uses actions to unroll what happens next. That’s what makes World Models so computationally efficient.
It’s also the same reason why World Models can handle stochasticity that traditional simulation cannot. To understand why, let’s revisit our Man U match with our new understanding of how World Models work.
In a traditional simulation engine, every possible behavior must be coded. If you want a thousand soccer fans to react realistically to a goal, you need to write rules for each type of reaction. The computational cost scales with the number of Agents and the complexity of their interactions.
In a World Model, the cost is fixed to one neural network pass. The stochastic, messy, human reality is already baked into the learned weights and absorbed from the millions of hours of video the model was trained on. The model doesn’t calculate what a crowd should do. It has seen what crowds actually do and it uses this information to make probable predictions.
This is what I mean when I call World Models compute for the uncomputable. Traditional computing is deterministic: known inputs, known rules, known outputs. The real world is not deterministic, so World Models don’t even try to code these things in. They watch, learn, and do, at a fixed computational cost, regardless of how complex the scenario gets.
World Models and Policies
There is one more distinction to make before we go further, one that gets muddled in typical conversations about World Models.
A World Model is a simulation of the environment; it takes in actions and produces predicted observations; it shows you what will happen if you do something.
A Policy is the brains of the Agent that acts within that environment. It takes in observations (and often instructions) and produces actions; it decides what to do.
The World Model is the dream. The Policy is the dreamer. The dreamer acts, and the dream responds. The dream responds, and the dreamer acts.
In practice, the relationship between the two turns out to be even more intimate and intertwined than that distinction suggests. Recent research has investigated training policies on top of World Model foundations or building them together from the get go. Start with the weights of a World Model — a system that has learned how to predict what happens next — and then, instead of training the model to predict future frames, or states, you train it to predict future actions.
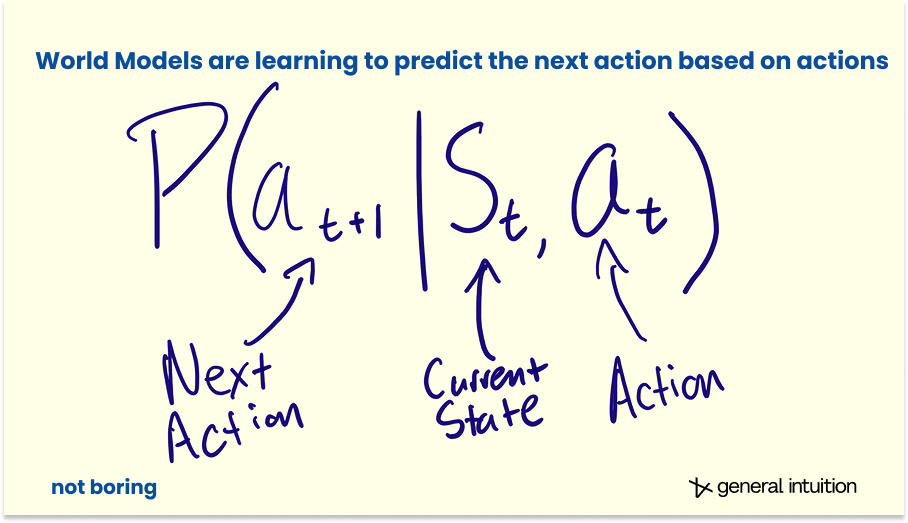
A system that learns to predict the world can also learn much faster how to act in it. Understanding and doing aren’t two separate skills bolted together. They are the same skill, seen from different angles. At least this is what our research, and that of other labs, is starting to suggest.
That means that if you build a good enough World Model, you can also more effectively train a policy to act in the worlds it generates.
This is one of many important things the field has learned in a very short amount of time. Turns out intuition and imagination are two sides of the same coin.
A (Very Brief) History of World Models
On one hand, it should be very easy to summarize the modern history of World Models. It has only been eight years since Ha and Schmidhuber published World Models.
On the other hand, an awful lot has happened in just eight years. In that time, the field has gone through four waves: major periods when the field shifted its focus to prioritizing new questions. We highlight some of the most important papers here, and not boring world subscribers can find a full downloadable list of key papers at the end of the essay.

Wave 0, in 1990-1991, was the pre-deep learning era. Researchers first articulated the idea that Agents could learn internal models of the world and use them for prediction and planning. They asked, and answered, the question: what would a World Model do?
This is Richard Sutton and Dyna. This is Jürgen Schmidhuber and Making the World Differentiable. Before we had the compute, the data, or the architecture, we had the dream, waiting in dreamspace for reality to catch up.
Wave 1, in 2018-2019, asked: “Can this even work?”
Based on Ha and Schmidhuber’s work, the first paradigm involved using Video Auto-Encoders (VAE) to compress frames, model dynamics with Recurrent Neural Networks (RNN), and train policies inside the resulting dreams. So: compress what you see, predict what comes next, and train Agents to act inside that simulation.
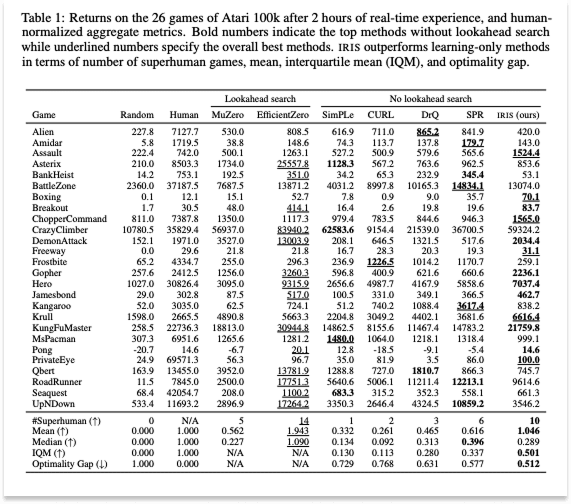
At the time, the question was whether learning in imagination — dreams — was feasible. Researchers attempted to answer it using small models and simple environments to generate proof-of-concept results. Quite literally, the next big thing started out looking like a toy. Model Based Reinforcement Learning for Atari introduced the Atari 100k benchmark: whether the SimPLe algorithm could learn Atari games with only 100,000 real environment steps, or about two hours of gameplay.
The answer was yes. SimPLe learned how to play 26 Atari games and beat a competitor model on sample efficiency, or how many steps it took to reach a given score.
But could it play as well as humans?
That was the question that drove Wave 2 (2020-2022): “Can the World Model match human performance?”
DreamerV2, developed by Danijar Hafner at Google DeepMind, reached an answer quickly. They used a Recurrent State-Space Model (RSSM) with discrete latent representations — a system that maintains a compressed, running memory of the world and updates it with each observation. DreamerV2 became the first World Model Agent to achieve human-level performance across the 55-game Atari benchmark6. It was trained entirely in imagination, on a single GPU.
That same year, another DeepMind team published Mastering Atari, Go, chess and shogi by planning with a learned model in Nature. The paper described its MuZero model, which also beat Atari games (and others like Go), but did so by taking almost the exact opposite philosophical approach.

Whereas DreamerV2 generated observable dream environments and trained inside of them, MuZero never generated anything observable at all, planning entirely in abstract latent representations it invented for itself, and it did well.
It did so well, in fact that it leapfrogged the Go-specific models. In 2016, DeepMind’s AlphaGo beat human Go Champion Lee Sedol 4-1. It had been trained on a large database of human expert games plus self-play, with the rules of the game hard-coded in. The next year, AlphaGoZero beat AlphaGo 100-0 after being trained entirely from self-play with no human game data at all, just the rules. That same paper season, AlphaZero generalized AlphaGoZero’s approach to other games, like chess and shogi, both of which it came to dominate within hours. Then in 2019 (pre-print), MuZero learned everything, including the rules, the game dynamics, and the value function, from scratch, purely from observation and outcome. It matched AlphaZero on Go, chess, and shogi (where AlphaZero knew the rules) while also generalizing to 57 Atari games (where “rules” aren’t even a well-defined concept).
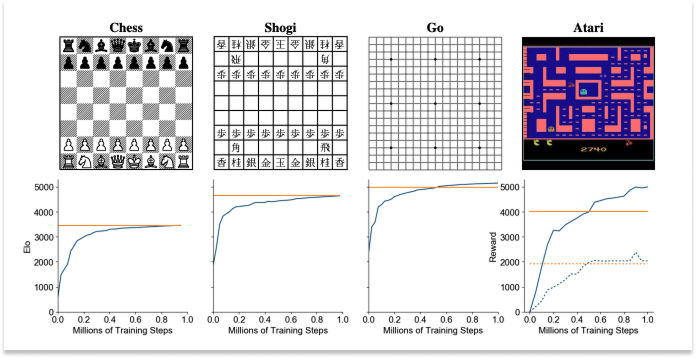
With each new model, something that humans had previously hard-coded — the rules, the strategy, the value of a position — was removed. The model learned each from scratch instead. MuZero was the terminus of that progression, entirely learned.
And MuZero did this without imagining future board states at all. It imagined hidden states, or abstract vectors it invented for itself during training that have no guaranteed correspondence to anything human-observable or interpretable. A human looking at MuZero’s internal representation of “three moves from now” would have absolutely no idea what it was thinking. And yet… it outperformed all previous models.
With MuZero’s success, the field now had two opposing schools of thought: generative World Models that produce observable futures, and latent World Models that predict in abstract space, even if they weren’t called “latent” yet.
From then on, progress in World Models has happened in both directions, generative and latent.
On the latent side, in 2022, Yann LeCun published a sweeping position paper from his dual positions at Meta and NYU Courant proposing a fundamentally different philosophy from generative models, one that looked more like MuZero: A Path Towards Autonomous Machine Intelligence. His new World Models company, AMI, is named after this paper.

LeCun’s Joint Embedding Predictive Architecture (JEPA) argued against generating pixels entirely. Similar to MuZero, instead of predicting what the world will look like, JEPA predicts what it will mean. It forecasts abstract representations of future states, deliberately discarding unpredictable visual details.
That same year, on the generative side, IRIS (2022), developed by Vincent Micheli and Eloi Alonso, two of General Intuition’s future co-founders, reframed World Modeling as language modeling over a learned vocabulary of image tokens. Instead of recurrent state-space models, IRIS used a GPT-style autoregressive transformer over discrete visual tokens. Basically, IRIS borrowed the machinery of language models and applied it to World Modeling.
In doing so, IRIS filled a number of previous gaps. The IRIS World Model was, in effect, a language model, but its vocabulary was images and actions instead of words. This brought the scaling properties of LLMs directly into World Modeling: efficient attention, scaling laws, and all the engineering infrastructure that had been built for large language models could now be applied to learning about the physical world.
Where Dreamer was missing the ability to model the joint law of the next latent state (for example, to handle multimodality), IRIS represented the next latent state as a series of discrete tokens to predict autoregressively, which meant that it was now able to predict multiple outcomes. And while Dreamer beat humans by using much more data than they do, IRIS was the first learning-in-imagination approach to beat humans with the same amount of available gameplay data (two hours).
JEPA aside, practically all of the work up to this point in World Models happened