

Written by Matthias Plappert
Compiled by: Siqi, Lavida, Tianyi
After launching the video generation model Sora last month, just yesterday, OpenAI released a series of creations made by creative workers with the help of Sora, and the results are extremely stunning. There is no doubt that Sora is the strongest video generation model so far in terms of generation quality. Its emergence will not only have a direct impact on the creative industry, but also affect the solution of some key issues in the fields of robotics and autonomous driving.
Although OpenAI released a technical report on Sora, the presentation of technical details in the report is extremely limited. This article is compiled from the research of Matthias Plappert of Factorial Fund. Matthias once worked at OpenAI and participated in the Codex project. In this research, Matthias discusses In addition to the key technical details of Sora, what are the innovation points of the model and what important impacts it will bring, it also analyzes the computing power requirements of video generation models like Sora. Matthias believes that as the application of video generation becomes more and more widely relied on, the computing requirements of the inference link will quickly exceed the training link, especially for diffusion-based models like Sora.
According to Matthias's estimate, Sora's computing power requirements during the training process are several times higher than LLM. It requires about 1 month of training on 4200-10500 Nvidia H100s, and when the model generates 15.3 million to 38.1 million minutes of video , the computational cost of the inference phase will quickly exceed that of the training phase. For comparison, users currently upload 17 million minutes of video to TikTok and 43 million minutes to YouTube every day. OpenAI CTO Mira also mentioned in a recent interview that the cost of video generation is also the reason why Sora cannot be open to the public for the time being. OpenAI hopes to achieve a cost close to that of Dall·E image generation before considering opening it.
OpenAI’s recently released Sora shocked the world with its ability to generate extremely realistic video scenes. In this post, we’ll dive into the technical details behind Sora, the potential impact of these video models, and some of our current thoughts. Finally, we will also share our insights into the computing power required to train a model like Sora, and show predictions of training computation compared to inference, which is important for estimating future GPU demand.
core ideas
The core conclusions of this report are as follows:
Sora is a diffusion model that is trained based on DiT and Latent Diffusion, and is scaled on the model size and training data set;
Sora proves the importance of scale up in video models, and continuous scaling will be the main driving force in the process of improving model capabilities, which is similar to LLM;
Companies such as Runway, Genmo and Pika are exploring building intuitive interfaces and workflows on diffusion-based video generation models like Sora, which will determine the promotion and ease of use of the model;
Sora's training requires huge computing power. We estimate that it will take 1 month to train on 4200-10500 Nvidia H100s;
In the inference process, we estimate that each H100 can generate up to about 5 minutes of video per hour. The inference cost of diffusion-based models such as Sora is several orders of magnitude higher than LLM;
As video generation models like Sora are widely promoted and applied, the inference link will dominate the computational consumption over model training. The critical point here is after producing 15.3 million to 38.1 million minutes of video. At this time, the amount of money spent on inference The amount of calculation will exceed that of the original training. For comparison, users upload 17 million minutes of video to TikTok and 43 million minutes to YouTube every day;
Assume that AI has been fully applied on video platforms. For example, 50% of videos on TikTok and 15% of videos on YouTube are generated by AI. Taking into account the efficiency and usage of the hardware, we estimate that under peak demand, the inference link will require approximately 720,000 Nvidia H100s.
Overall, Sora not only represents a major advancement in video generation quality and functionality, but also indicates that the demand for GPUs in inference may significantly increase in the future.
01.Background
Sora is a diffusion model. Diffusion models are widely used in the field of image generation. Representative image generation models such as OpenAI's Dall-E or Stability AI's Stable Diffusion are all diffusion-based. Runway, Genmo and Pika have recently Companies that appear to explore video generation most likely use the diffusion model.
Broadly speaking, as a generative model, a diffusion model learns to create data similar to its training data, such as images or videos, by gradually learning to reverse a process of adding random noise to the data. These models initially start with complete noise, gradually removing the noise and refining the pattern until it becomes a coherent and detailed output.

Schematic diagram of the diffusion process:
Noise is gradually removed until detailed video content is revealed
Source: Sora Technical Report
This process is significantly different from the way the model works under the concept of LLM: LLM generates tokens one after another through iteration. This process is also called autoregressive sampling. Once the model generates a token, it will never change. We can see this process when using tools such as Perplexity or ChatGPT: the answer appears word by word, just like someone typing.
02. Technical details of Sora
At the same time as Sora was released, OpenAI also released a technical report on Sora, but the report did not present many details. However, Sora's design seems to be heavily influenced by the paper Scalable Diffusion Models with Transformers. In this paper, the two authors proposed a Transformer-based architecture called DiT for image generation. Sora seems to have expanded the work of this paper into the field of video generation. Combining Sora's technical report and DiT's paper, we can basically accurately sort out the entire logic of Sora.
Three important pieces of information about Sora:
1. Sora did not choose to work at the pixel space level, but chose to diffuse in latent space (latent space, also called latent diffusion);
2. Sora adopts Transformer architecture;
3. Sora seems to use a very large data set.
Detail 1: Latent Diffusion
To understand the latent diffusion mentioned in the first point above, you can first think about how an image is generated. We can generate each pixel through diffusion, but this process will be quite inefficient. For example, a 512x512 image has 262,144 pixels. But in addition to this method, we can also choose to first convert the pixels into a compressed latent representation, then diffuse it on this latent space with a smaller amount of data, and finally convert the diffused result back to pixels layer. This conversion process can significantly reduce the computational complexity. We no longer need to process 262,144 pixles, but only need to process 64x64=4096 latent representations. This method is the key breakthrough of High-Resolution Image Synthesis with Latent Diffusion Models and the basis of Stable Diffusion.

Map the pixels in the left image to the potential representation represented by the grid in the right image
Source: Sora Technical Report
Both DiT and Sora use latent diffusion. For Sora, an additional consideration is that video has a time dimension: video is a time sequence of a series of images, which we also call frames. From Sora's technical report, we can see that the encoding from the pixel layer to the latent sapce occurs both at the spatial level, that is, compressing the width and height of each frame, and in the temporal dimension, that is, across time compression.
Detail 2: Transformer architecture
Regarding the second point, both DiT and Sora replaced the commonly used U-Net architecture with the most basic Transformer architecture. This is critical because the authors of DiT found that predictable scaling can occur by using the Transformer architecture: as the amount of technology increases, whether the model training time increases or the model size changes, or both, the model can power enhanced. Sora's technical report also mentioned the same point, but it was for video generation scenarios, and the report also included an intuitive diagram.

Model quality improves as the amount of training calculations increases: from left to right, the basic calculation amount, 4 times the calculation amount, and 32 times the calculation amount.
This scaling characteristic can be quantified by what we often call scaling law, which is also a very important attribute. Before video generation, scaling law has been studied both in the context of LLM and autoregressive models in other modalities. The ability to obtain better models through scale is one of the key driving forces for the rapid development of LLM. Since image and video generation also have scaling properties, we should expect scaling laws to apply in these fields as well.
Detail 3: Dataset
To train a model like Sora, the last key factor to consider is the labeled data. We believe that the data link contains most of Sora's secrets. To train a text2video model like Sora, we need paired data of videos and their corresponding text descriptions. OpenAI did not discuss the data set much, but they also hinted that the data set is large. In the technical report, OpenAI mentioned: "Based on training on Internet-level data, LLM has gained general capabilities. We have learned from this Got inspired".

Source: Sora Technical Report
OpenAI also announced a method for annotating images with detailed text labels. This method was used to collect the DALLE-3 dataset. Simply put, this method trains an annotation on a labeled subset of the dataset. model (captioner model), and then use this model to automatically complete the labeling of the remaining data posts. Sora's data set should also use similar technology.
03.Sora’s influence
Video models are beginning to be applied in practice
From the perspective of details and temporal coherence, the quality of the video generated by Sora is undoubtedly an important breakthrough. For example, Sora can correctly handle objects in the video that remain motionless when they are temporarily occluded, and can accurately generate water reflection effects. We believe that Sora's current video quality is good enough for certain types of scenarios, and that these videos can be used in some real-world applications. For example, Sora may soon replace some of the need for video libraries.
Video generation domain map
However, Sora still faces some challenges: We still don't know how controllable Sora is. Because the model outputs pixels, editing the generated video content is difficult and time-consuming. For the model to be useful, it is also necessary to build an intuitive UI and workflow around the video generation model. As shown above, Runway, Genmo, and Pika, among other companies in the video generation space, are already solving these problems.
Because of Scaling, we can speed up video generation in anticipation of
As we discussed earlier, a key conclusion in this DiT study is that model quality will directly improve as the amount of calculation increases. This is very similar to the scaling law we have already observed in LLM. We can therefore also expect that the quality of video generation models will rapidly improve further as the models are trained on more computing resources. Sora is a strong validation of this, and we expect OpenAI and other companies to double down on this.
Synthetic data generation and data enhancement
In fields such as robotics and autonomous driving, data is essentially a scarce resource: in these fields there is no "Internet"-like existence where robots are everywhere helping to work or drive. Typically, some problems in these two fields are mainly solved by training in simulated environments, collecting data at scale in the real world, or a combination of both. However, both approaches present challenges, as simulated data are often unrealistic, collecting data at scale in the real world is very expensive, and collecting enough data on low-probability events is also challenging.

As shown in the picture above, the video can be enhanced by modifying some properties of the video, such as rendering the original video (left) into a dense jungle environment (right)
Source: Sora Technical Report
We believe that models like Sora have a role to play in these problems. We believe that models like Sora have the potential to be directly used to generate 100% synthetic data. Sora can also be used for data augmentation, which is to perform various transformations on the presentation of existing videos.
The data augmentation mentioned here can actually be illustrated by the example in the technical report above. In the original video, a red car was driving on a forest road. After Sora's processing, the video turned into a car driving on a tropical jungle road. We can fully believe that using the same technology for re-rendering can also achieve day and night scene transitions or change weather conditions.
Simulations and world models
"World Models" is a valuable research direction. If the models are accurate enough, these world models can allow people to directly train AI agents in them, or these models can be used for planning and search.
Models like Sora learn a basic model of how the real world works from video data in an implicitly learning manner. Although this kind of "emergent simulation" is currently flawed, it is still exciting: it shows that we may be able to train models of the world by using video data at scale. In addition, Sora seems to be able to simulate very complex scenes, such as liquid flow, light reflection, fiber and hair movement, etc. OpenAI even named Sora's technical report Video generation models as world simulators , which clearly shows that they believe this is the most important aspect where the model will have an impact.
Recently, DeepMind also demonstrated a similar effect in its Genie model: just by training on a series of game videos, the model learned the ability to simulate these games and even create new games. In this case, the model can learn to adjust its predictions or decisions based on behavior, even without directly observing the behavior. In Genie's case, the goal of model training is still to be able to learn in these simulated environments.

Video from Google DeepMind’s Genie:
Introduction to Generative Interactive Environments
Taken together, we believe that if we want to train embodied agents like robots on a large scale based on real-world tasks, models like Sora and Genie will definitely be able to perform. Of course, this model also has limitations: because the model is trained in pixel space, the model will simulate every detail, including the wind and grass in the video, but these details are completely irrelevant to the current task. Although latent space is compressed, it still needs to retain a lot of this information because it needs to be mapped back to pixels, so it is not clear whether planning can be done effectively in latent space.
04. Computing power estimation
We are very concerned about the requirements for computing resources during model training and inference. This information can help us predict how much computing resources will be needed in the future. However, estimating these numbers is difficult because there are very few details about Sora's model size and dataset. Therefore, our estimates in this sector do not truly reflect the actual situation, so please refer to it with caution.
Deducing the computing scale of Sora based on DiT
Details about Sora are quite limited, but we can look back at the DiT paper again and use the data in the DiT paper to extrapolate information on the amount of computation required for Sora, since this research is clearly the basis for Sora. As the largest DiT model, DiT-XL has 675 million parameters and uses approximately 1021FLOPS of total computing resources for training. In order to easily understand the size of this calculation, this calculation scale is equivalent to using 0.4 Nvidia H100s to run for 1 month, or a single H100 to run for 12 days.
Currently, DiT is only used for image generation, but Sora is a video model. Sora can generate videos up to 1 minute long. If we assume that the video is encoded at 24 frames per second (fps), then a video contains as many as 1440 frames. Sora compresses both the time and space dimensions in the mapping from pixel to latent space. Assuming that Sora uses the same compression rate as in the DiT paper, that is, 8 times compression, then there are 180 frames in latent space, so , if we simply linearly extrapolate the value of DiT to the video, it means that the calculation amount of Sora is 180 times that of DiT.
In addition, we believe that the number of parameters of Sora far exceeds 675 million. We estimate that the number of parameters on a scale of 20 billion is also possible, which means that from this perspective, we have another guess that the calculation amount of Sora is 30 times that of DiT.
Finally, we believe that the data set used to train Sora is much larger than that used by DiT. DiT was trained for 3 million steps with a batch size of 256, which means a total of 768 million images were processed. However, it should be noted that since ImageNet only contains 14 million images, this involves multiple reuse of the same data. Sora appears to be trained on a mixed dataset of images and videos, but we know next to nothing about the specifics of the dataset. Therefore, we simply assume that Sora's data set is composed of 50% static images and 50% videos, and that this data set is 10 to 100 times larger than the data set used by DiT. However, DiT repeatedly trains the same datapoints, which may be suboptimal when a larger dataset is available. Therefore, it is more reasonable for us to set the multiplier for the increase in calculation amount to 4 to 10 times.
Based on the above information, and taking into account our estimates of different levels of data set calculation scale, the following calculation results can be obtained:
Formula: DiT’s basic calculation amount × model increase × data set increase × increased calculation amount generated by 180 frames of video data (only for 50% of the data set)
Conservative estimate of the size of the data set: 1021 FLOPS × 30 × 4 × (180 / 2) ≈ 1.1×1025 FLOPS
Optimistic estimate of the size of the data set: 1021FLOPS × 30 × 10 × (180 / 2) ≈ 2.7×1025FLOPS
The calculation scale of Sora is equivalent to the calculation amount of 4211-10528 H100 running for one month.
Computing power requirements: model reasoning VS model calculation
Another important part of calculation that we pay attention to is the comparison of the amount of calculation between training and inference. Theoretically speaking, even if the amount of calculation in the training process is huge, the training cost is one-time and only needs to be paid once. In contrast, while inference requires smaller computations relative to training, it is generated every time the model generates content and also increases as the number of users increases. Therefore, model inference becomes increasingly important as the number of users increases and models become more widely used.
Therefore, it is also valuable to find the critical point where inference computation exceeds training computation.
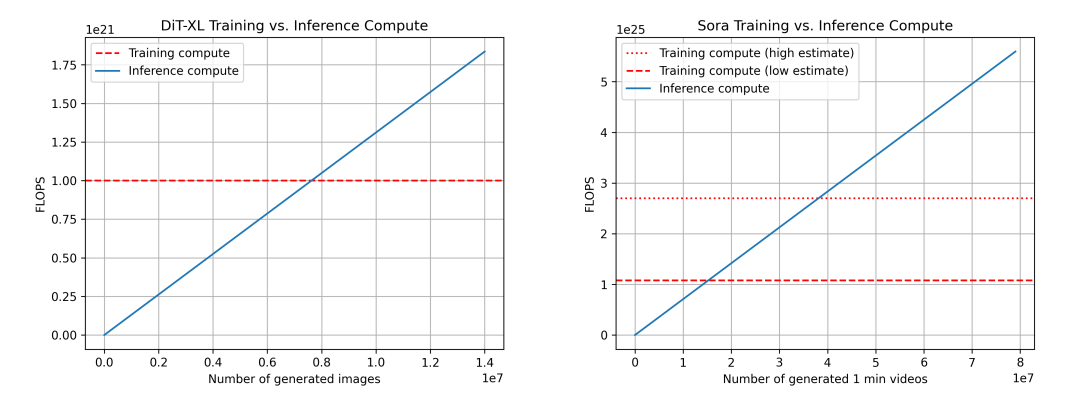
We compare the training and inference calculations of DiT (left) and Sora (right). For Sora, based on the above estimates, Sora's data is not entirely reliable. We also show two estimates of the training calculations: a low estimate (assuming a dataset size multiplier of 4x) and a high estimate (assuming a dataset size multiplier of 10x).
For the above data, we again use DiT to infer the case of Sora. For DiT, the largest model DiT-XL uses 524×109FLOPS for each step of inference, and DiT uses 250 steps of diffusion to generate an image, which is a total of 131×1012FLOPS. We can see that after generating 7.6 million images, the "inference-training critical point" was finally reached. After that, model inference began to dominate the computing requirements. For reference, users upload approximately 95 million images to Instagram every day.
For Sora, we calculate that FLOPS is 524×109FLOPS × 30 × 180 ≈ 2.8×1015FLOPS. If we still assume 250 diffusion steps per video, the total FLOPS per video is 708×1015FLOPS. For reference, this equates to approximately 5 minutes of video per Nvidia H100 per hour. In the case of conservative estimates of the data set, reaching the "inference-training critical point" requires the generation of 15.3 million minutes of video. In the case of optimistic estimates of the size of the data set, in order to reach the critical point, 38.1 million minutes of video need to be generated. video. For reference, approximately 43 million minutes of video are uploaded to YouTube every day.
A few additional caveats to add: FLOPS are not the only thing that matters for inference. For example, memory bandwidth is another important factor. In addition, there are also teams that are actively studying steps to reduce diffusion, which will also reduce model calculation requirements and therefore make inference faster. FLOPS utilization may also differ between training and inference, which is also an important consideration.
Yang Song, Prafulla Dhariwal, Mark Chen and Ilya Sutskever published a study on Consistency Models in March 2023. The study pointed out that the diffusion model has made significant progress in the field of image, audio and video generation, but has limitations such as reliance on iterative sampling processes and slow generation. sex. The study proposes a consistency model that allows multiple sampling exchange calculations to improve sample quality. https://arxiv.org/abs/2303.01469
Computational requirements for different modal model inference links
We also studied the changing trends of inference calculations per unit output of different models in different modes. The purpose of the study is how much the computational intensity of inference increases in different classes of models, which has direct implications for computational planning and requirements. Since they run in different modalities, the output units of each model are different: a single output for Sora is a 1-minute-long video, a single output for DiT is a 512x512 pixel image; while for Llama 2 and GPT- 4. The single output we define is a document containing 1000 tokens of text (for reference, the average Wikipedia article has approximately 670 tokens).
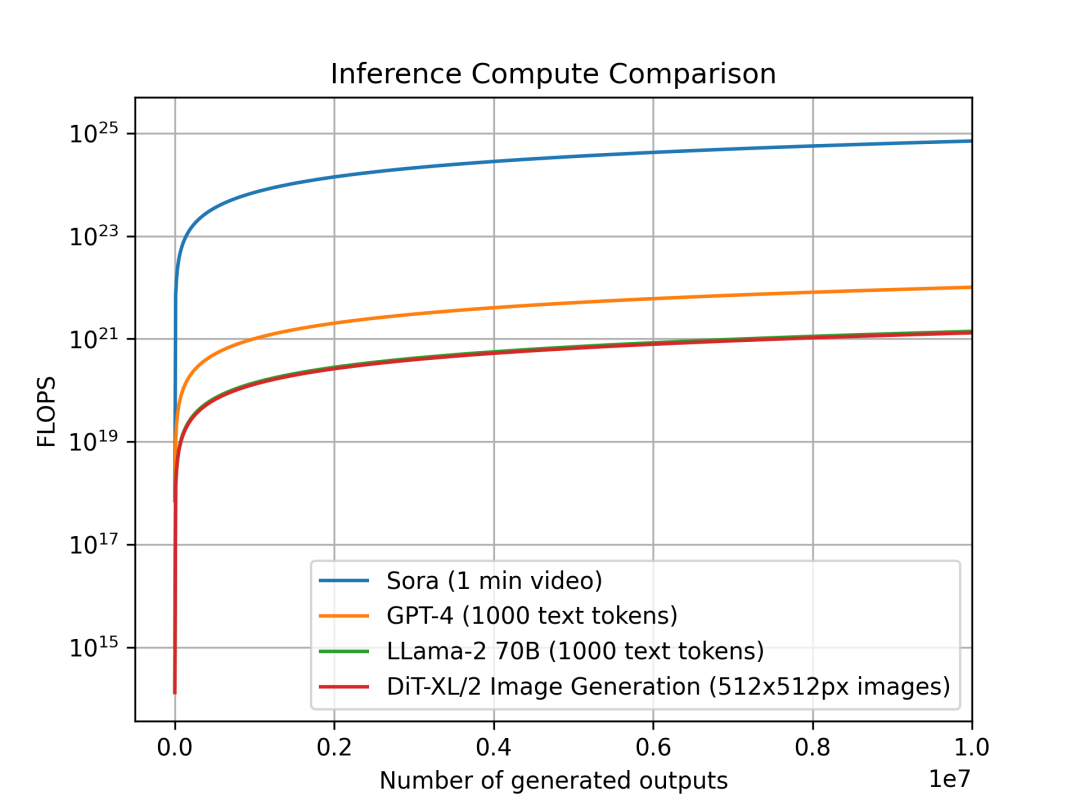
Comparison of inference calculations output by each unit of the model: Sora outputs a 1-minute video per unit, GPT-4 and LLama 2 output 1000 Tokens of text per unit, DiT outputs a 512x512px image per unit, and the image shows Sora's inference estimate It is several orders of magnitude more computationally expensive.
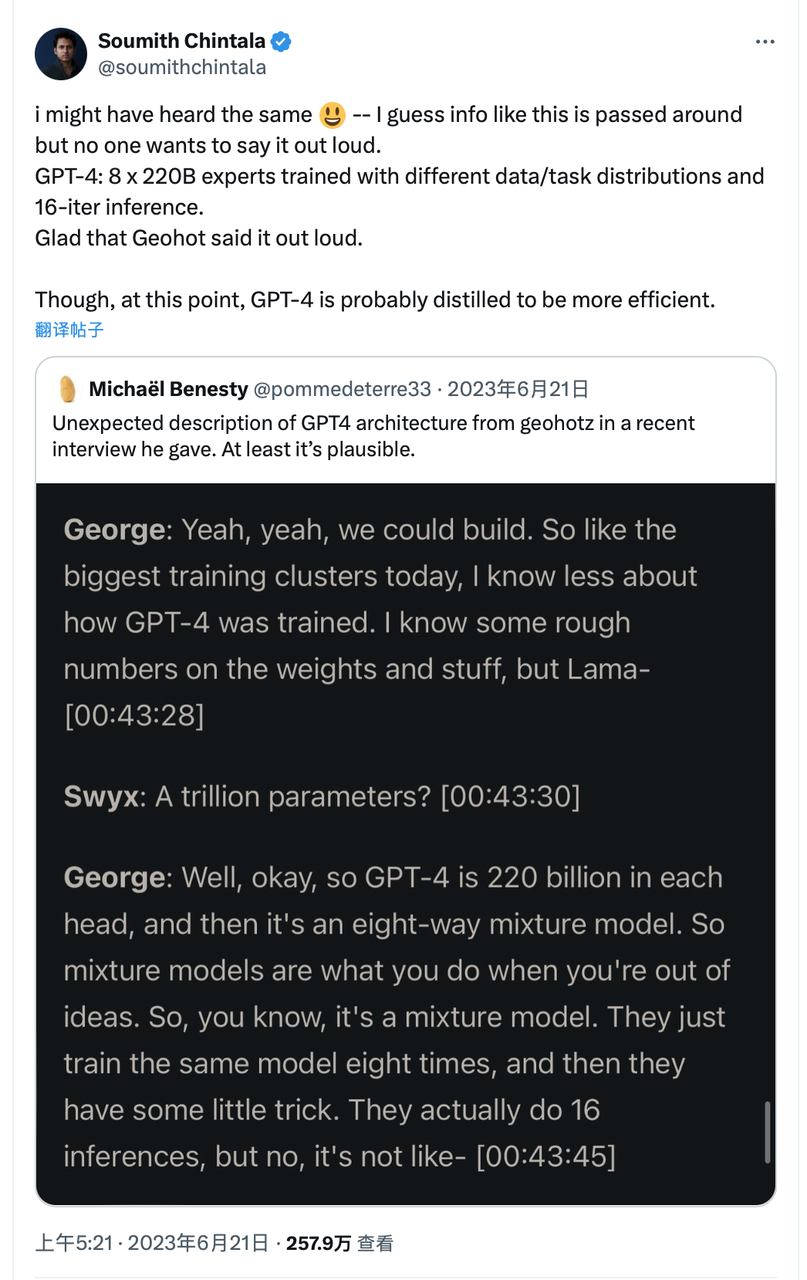
We compared Sora, DiT-XL, LLama2-70B and GPT-4 and plotted their FLOPS comparison graph using log-scale. For Sora and DiT, we use the inference estimation mentioned above. For Llama 2 and GPT-4, we choose to use "FLOPS = 2 × parameter amount × number of generated Tokens" to make a quick estimate based on experience. For GPT-4, we first assume that the model is a MoE model, each expert model has 220 billion parameters, and each forward propagation activates 2 experts. It should be pointed out that the data related to GPT-4 is not the official caliber confirmed by OpenAI and is only for reference.
Source:X
We can see that diffusion-based models like DiT and Sora consume more computing power in the inference phase: DiT-XL with 675 million parameters consumes almost the same amount of computing power in the inference phase as LLama 2 with 70 billion parameters. Further we can see that the inference cost of Sora is several orders of magnitude higher than that of GPT-4.
It should be pointed out again that many of the numbers used in the above calculations are estimates and rely on simplifying assumptions. For example, they do not take into account actual GPU FLOPS utilization, memory capacity and memory bandwidth limitations, as well as more advanced technical methods like speculative decoding.
Forecast of inference computing demand when Sora is widely used:
In this section, we start from Sora's computing needs to calculate: If AI-generated videos have been widely used on video platforms such as TikTok and YouTube, how many Nvidia H100s will be needed to meet these needs.
• As above, we assume that each H100 can produce 5 minutes of video per hour, which is equivalent to each H100 can produce 120 minutes of video per day.
• On TikTok: Current users upload 17 million minutes of videos every day (34 million total videos × average length of 30 seconds), assuming AI penetration of 50%;
• On YouTube: Current users upload 43 million minutes of videos every day, assuming AI penetration of 15% (mainly videos under 2 minutes),
• Then the total amount of videos produced by AI every day: 8.5 million + 6.5 million = 15 million minutes.
• Total number of Nvidia H100s needed to support the creator community on TikTok and YouTube: 15 million / 120 ≈ 89,000.
However, the value of 89,000 may be low because the following factors need to be taken into consideration:
• In our calculation, we assumed 100% FLOPS utilization and did not consider memory and communication bottlenecks. A utilization rate of 50% would be more realistic, which means that the actual GPU demand is 2 times the estimated value;
• Inference requirements are not evenly distributed along the timeline, but are bursty, especially considering peak situations, because more GPUs are needed to ensure service. We believe that if we consider the peak traffic situation, we need to give a 2X multiplier to the number of GPU requirements;
• Creators may generate many videos and then select the best one to upload. If we conservatively assume that each uploaded video corresponds to 2 generations on average, the GPU demand will be multiplied by 2;
In total, under peak traffic, approximately 720,000 H100s are needed to meet inference needs.
This also validates our belief that as generative AI models become more popular and widely relied upon, the computational requirements of the inference phase will dominate, especially for diffusion-based models like Sora. .
At the same time, it should be noted that model scaling will further significantly promote the demand for inference computing. On the other hand, some of this increased demand can be offset by optimization of inference technology and other optimizations of the entire technology stack.
Video content production directly drives demand for models like Sora






