저자: 아이리스 첸(Iris Chen), Ni 박사

1. AI+3D 파이프라인은 비용을 대폭 절감하고 효율성을 높입니다.
2022년 ChatGPT의 폭발은 AIGC의 물결을 촉발시켰으며 게임, 영화, TV, 3D 프린팅 및 기타 시나리오의 3D 콘텐츠 분야도 생성적 AI의 영향으로 산업 구조를 재편하고 있습니다. 일체 포함. 정확성을 추구하는 산업 현장 CAD, 건축 현장 BIM에 비해 이러한 장면의 3D 콘텐츠는 창의성을 더 추구하고 제너레이티브 AI의 활용도가 더 높아질 수 있습니다.
3D 생성 기술은 심층신경망을 이용해 사물이나 장면의 3차원 모델을 학습하고 생성하는 것을 말하며, 3차원 모델을 기반으로 사물이나 장면에 색, 빛, 그림자를 부여해 생성 결과를 더욱 현실감 있게 만드는 AI 모델링 등을 말한다. , AI 뼈 바인딩, 표정, AI 액션, AI 렌더링 등 AI 연구 방향. 3D 콘텐츠 산업 체인은 기술을 제공하는 기본 레이어, 자산을 제공하는 중간 레이어, 자산을 개발하는 애플리케이션 레이어로 구성됩니다. 기본 레이어의 기술 공급자는 주로 3D 생성 기술을 제작하기 위한 기본 도구를 업계에 제공합니다. 이 계층의 기존 생산을 대체하여 업계를 발전시킵니다.

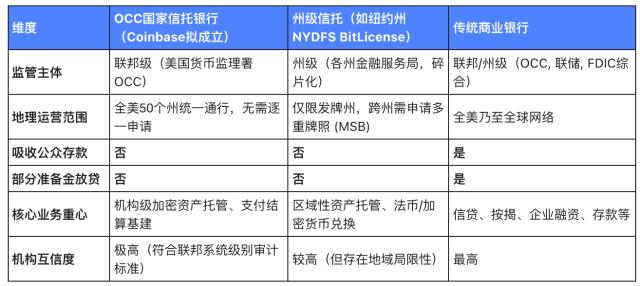
전통적인 3D 파이프라인에는 컨셉 디자인, 원화 제작, 3D 모델링, 텍스처 매핑, 구동 및 렌더링이 포함됩니다. 그 중 원화 제작, 3D 모델링, 텍스처 매핑 등 3D 관련 링크는 제작 주기가 길고 인력 의존도가 높습니다. , 이는 주요 R&D 비용입니다. 3D 게임을 예로 들면, 3D 게임에서 3D 관련 링크는 보통 연구개발 비용의 60~70%를 차지합니다. 그 중 3D 모델링 링크는 제조사가 3D 제작을 아웃소싱하는 경우 비용이 매우 많이 듭니다. 100,000개 이상의 면을 가진 고급 모델 리소스는 가격이 최소 30,000위안 이상이어야 하며 3D 자산 라이브러리에서 구매하는 경우 제한된 옵션 자산 문제 외에도 일반적으로 30~45일이 소요됩니다. 사용하기 전에 청소하려면 하루에 5~10명이 필요합니다. 세계 최대 3D 콘텐츠 기업인 스케치팹(Sketchfab)의 자료에 따르면 3D 모델 제작 비용은 대략 3~40달러 정도이고, 소요 시간은 2~15시간 정도 소요된다.

Generative AI는 기존 3D 파이프라인의 거의 모든 측면에서 역할을 수행할 수 있습니다. 현재 많은 게임 스튜디오에는 Midjourney 및 Stable Diffusion을 갖춘 아트 멤버가 있으며, 대형 모델을 적용하면 3D 모델링에 대한 문턱도 낮아졌습니다. 3D 콘텐츠 제작 비용을 절감하고 제작 효율성을 높일 수 있습니다. 2024년 초 인기 Steam 게임인 'Phantom Parlu'를 예로 들어 보겠습니다. 모델러가 Parlu(게임 속 생물)의 3D 모델을 만드는 데는 한 달이 걸립니다. 각 Parlu에는 하루에 약 20개의 작업이 필요합니다. 기존 3D 파이프라인 제작 방식에 따르면 약 100여 종의 파루가 소요되는데, 스튜디오에서는 제너레이티브 AI를 사용해 3년 만에 작업을 완료했다.
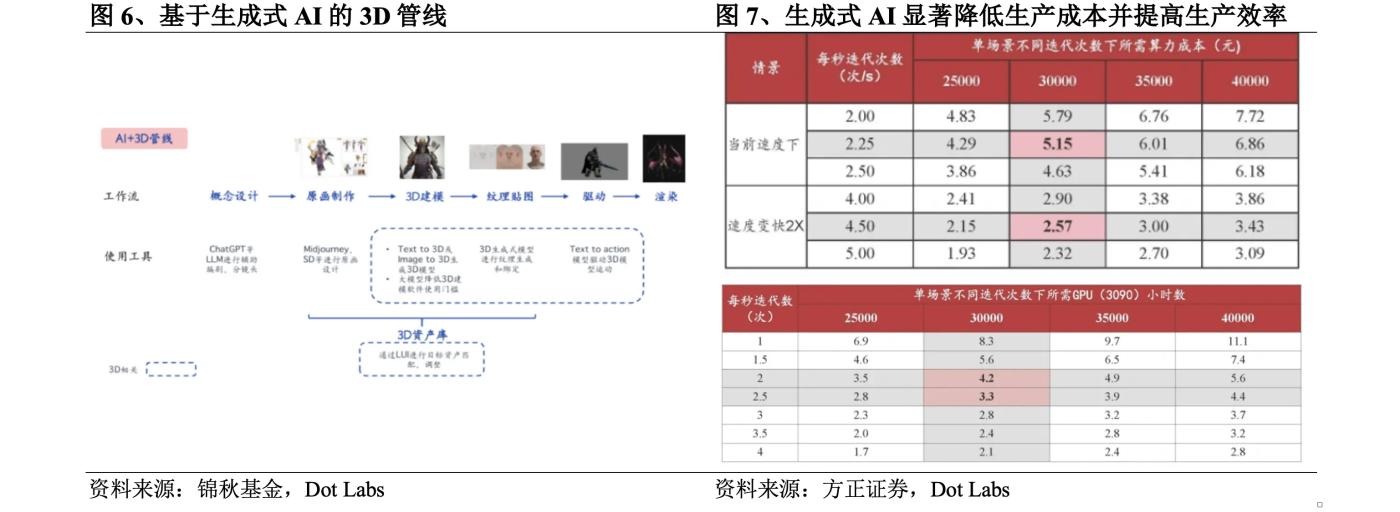
Founder Securities의 계산에 따르면 RTX 3090 그래픽 카드를 사용하여 Zero123 방법으로 30,000회 반복하면 3D 자산을 생성하는 데 드는 비용은 약 5위안입니다. 앞으로 이 방법이 성숙해지고 반복 속도가 2배 빨라집니다. , 비용은 2.6위안으로 떨어지며, 단일 장면은 약 3.3~4.2시간만 소요됩니다. 이전의 3~40달러와 2~15시간에 비해 생성 AI를 적용하면 생산 비용이 크게 절감되고 생산 효율성이 향상됩니다. .
2. 3D 생성 기술 개발
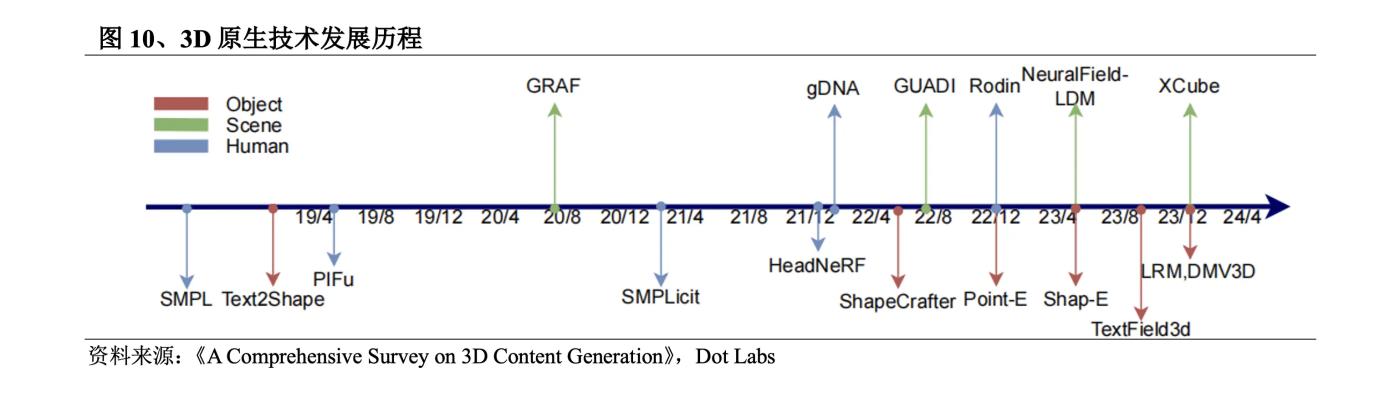
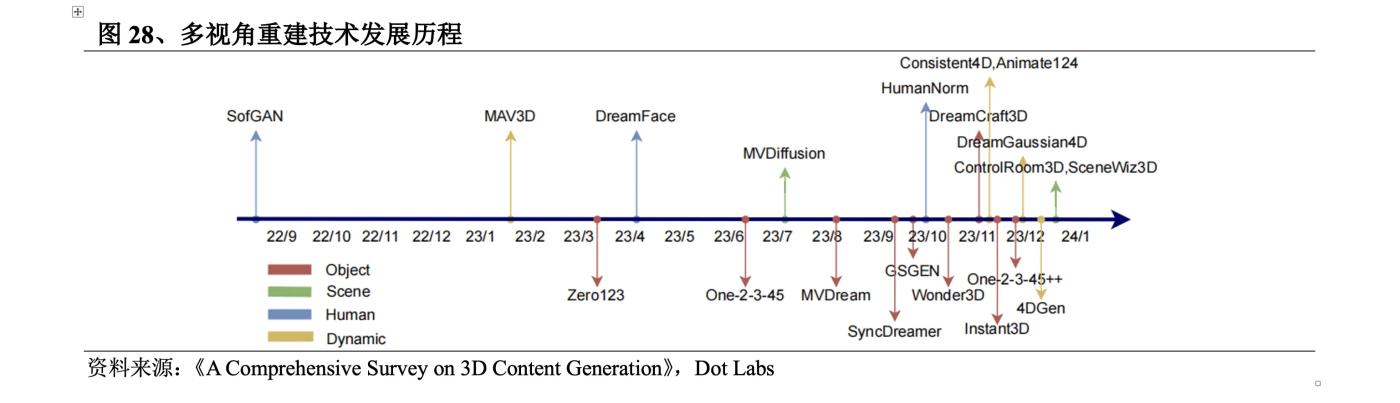
3D 생성 기술에 대한 연구는 이미 1970년 초 MIT 교수인 Berthold KP Horn이 반사된 조명 모델을 이용해 빛과 빛을 기반으로 3D 모델을 복원하는 Shape from shading을 제안한 분야입니다. 이미지의 어두운 정보. 2023년에는 3D 생성 기술이 폭발적으로 발전하고 생성 품질, 속도 및 풍부함이 크게 향상될 것입니다. ① 3D 데이터 세트는 초기 소규모 ShapeNet에서 Objaverse(2022년 12월) 및 Objaverse XL( 2023년 7월), 0bjaverse-XL 데이터 세트에는 Objaverse보다 훨씬 많은 3D 자산이 포함되어 있습니다. ② 3D 콘텐츠를 신경망 매개 변수로 표현하는 신경 분야가 탄생했습니다. 2D 사전 훈련 모델은 다중 뷰 재구성을 촉진합니다.
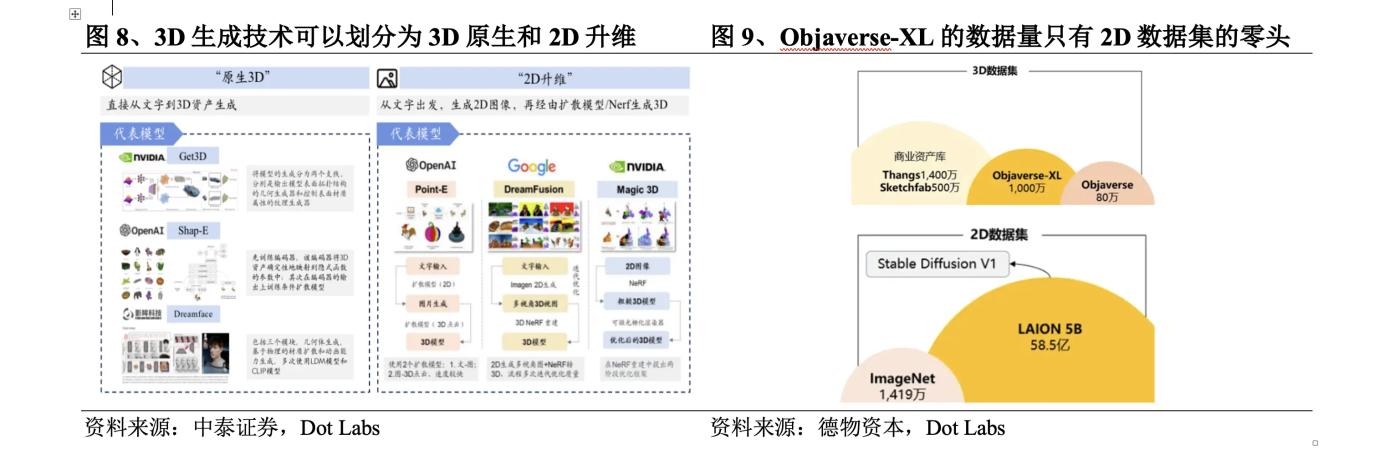
3D 생성 기술은 크게 2가지 개발 경로, 즉 3D 네이티브와 2D 차원 향상으로 나눌 수 있습니다. 3D 네이티브는 일반적으로 훈련부터 추론까지 3D 데이터 세트를 사용하며, 3D 데이터를 기반으로 텍스트/이미지에서 직접 3D 콘텐츠를 생성합니다. 그러나 학습할 수 있는 3D 데이터 세트는 최대 규모의 오픈 소스라도 매우 제한적입니다. 3D 데이터 세트 Objaverse-XL. 데이터 양은 2D 데이터 세트의 일부에 불과합니다. 이 문제를 해결하기 위해 일부 연구에서는 텍스트부터 2D 이미지까지 2D 데이터 세트를 학습에 사용한 다음 확산 모델 또는 NeRF 모델을 통해 3D 콘텐츠를 생성하려고 시도합니다.
1. 3D 기본 경로
3D 기본 경로는 3D 데이터 세트를 사용하여 학습되어 텍스트/그림 입력에서 3D 콘텐츠를 직접 생성합니다. 주요 장점과 단점은 다음과 같습니다.
엘 장점
고품질 생성: 3D 데이터 세트를 사용하기 때문에 특정 범위 내에서 타겟이 높으며 고품질 3D 콘텐츠를 생성할 수 있습니다. 예를 들어 고품질 3D를 통해 4k 이상의 고품질 3D 얼굴을 학습할 수 있습니다. 동시에 2D 차원 증가의 다면적인 문제를 방지합니다.
빠른 생성: 2D 차원은 일반적으로 확산 모델 또는 NeRF 모델을 사용하여 3D 표현의 최적화를 안내합니다. 이는 다단계 반복이 필요하고 시간이 오래 걸리는 반면, 3D 네이티브는 텍스트/그림에서 3D로 직접 생성될 수 있습니다.
강력한 호환성: 형상과 텍스처는 일반적으로 별도로 생성되며 나중에 표준 그래픽 엔진에서 직접 편집할 수 있습니다.
l 단점
풍부함이 부족함: 고품질, 대규모 3D 데이터 세트가 부족하고 데이터 품질 및 일관성이 좋지 않아 모델의 상상력이 제한되고 기존에 볼 수 없었던 항목이나 조합을 생성하기가 어렵습니다. 데이터 세트.
3D 네이티브 초기에 사용되는 방법으로는 VAE 모델, 플로우 모델, GAN 모델, EBM 모델 등이 있다. 그 중 GAN 모델이 효과를 생성하는 장점이 있어 2022년까지 3D 네이티브의 주류 모델이 되고 있다. GAN의 훈련 이환성 문제 때문에 표준화된 좌표계 없이는 데이터를 훈련하는 것이 매우 어렵고 매우 높은 하드웨어가 필요합니다. 2022년 9월 Nvidia는 충실도가 높은 텍스처와 복잡한 기하학적 세부 정보가 포함된 3D 콘텐츠를 생성할 수 있는 Get3D를 출시했습니다. 이후 OpenAI는 Point-E와 Shap-E를 출시하여 3D 데이터 및 자막 수의 한계를 깨고 수백만 개의 3D 리소스와 해당 텍스트 자막을 수집하고 대규모 어휘로 3D 생성을 지원합니다. 최근 인기를 얻고 있는 LRM은 효율적인 신경망 아키텍처와 대규모 다시점 데이터 세트를 결합하여 단일 이미지에서 충실도가 높은 3D 모델로의 신속한 변환을 달성합니다. DMV3D는 LRM을 개선하고 더 높은 수준을 달성하기 위해 T-단계 확산 모델을 제안합니다. 품질의 결과가 생성됩니다.
(1) Get3D는 기하학적인 디테일과 질감이 풍부합니다.
2022년 9월 Nvidia는 Get3D를 출시했습니다. Get3D의 생성 프로세스는 두 부분으로 나뉩니다. ① 임의의 토폴로지 구조로 표면 메시를 출력할 수 있는 형상 분기 부분, ② 표면 점에 대한 쿼리를 가능하게 하는 텍스처 필드를 생성하는 텍스처 분기 부분입니다.

이 방법의 구체적인 혁신은 다음과 같습니다.
l이 방법이 등장하기 전에는 3D 생성 기술로 생성된 콘텐츠에 기하학적인 디테일과 질감이 부족했습니다. Get3D 의 생성 프로세스에서는 3D 콘텐츠의 기하학적 세부 사항이 더욱 풍부해지고 텍스처링될 수 있습니다.
l 당시 가장 발전된 역 렌더링 방법으로는 한 번에 하나의 3D 개체만 만들 수 있었습니다. 단일 Nvidia GPU 에서 훈련할 때 Get3D는 초당 약 20개의 개체를 생성할 수 있으며, 학습하는 훈련 데이터 세트가 더 크고 다양할수록 출력의 다양성과 세부 사항이 더 높아집니다. A100 GPU를 사용하여 약 100 만 개의 이미지에 대한 모델을 훈련하는 데 2 일이 소요됩니다.
l 훈련된 데이터를 기반으로 거의 무제한의 3D 콘텐츠를 생성할 수 있습니다. 예를 들어, 2D 자동차 이미지의 데이터 세트를 학습하기 위해 Get3D는 자동차, 트럭, 경주용 자동차 및 밴의 시리즈 세트를 만들 수 있습니다.

2023년 5월 OpenAI는 Point-E 를 개선하기 위해 Shap-E를 출시했습니다. Shap-E 프로세스는 다음과 같습니다. ① 암시적 표현을 생성하도록 인코더를 학습합니다. ② 인코더에서 생성된 잠재 표현에 대한 확산 모델을 학습합니다.
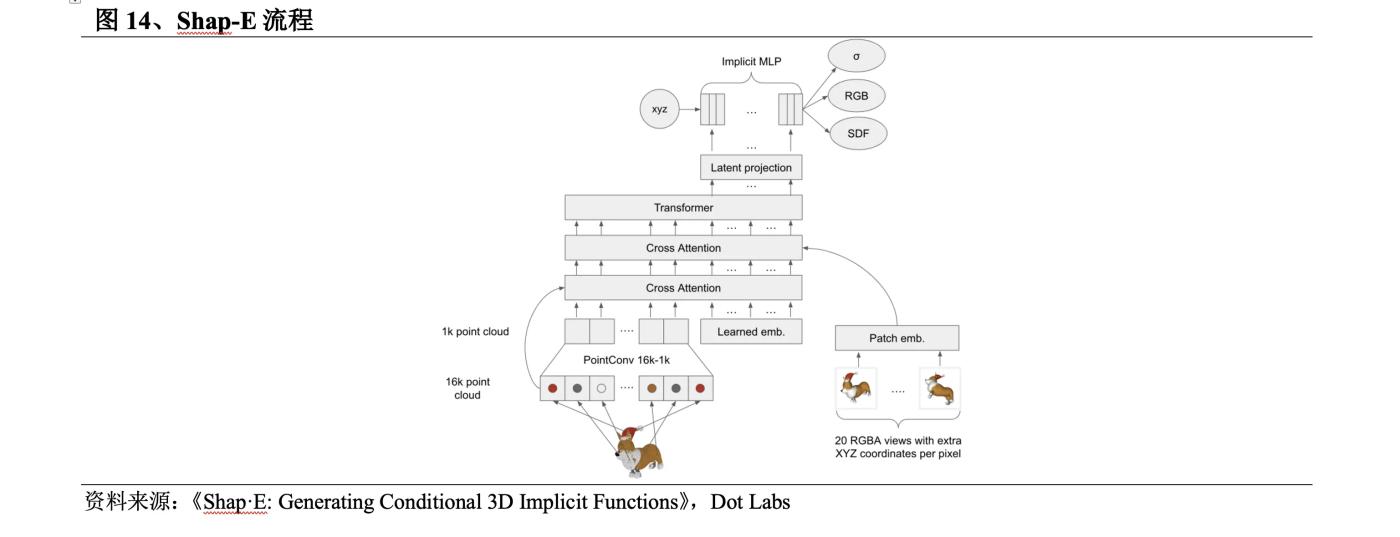
l Shap-E는 암시적 표현을 사용하여 신경장과 텍스처 메시를 모두 포함하는 3D 모델을 생성하며, 이는 후속 처리를 위해 3D 소프트웨어로 쉽게 가져올 수 있습니다. 다른 방법에 비해 Get3D는 메시만 생성할 수 있고 Point-E는 포인트 클라우드만 생성할 수 있습니다.
대규모 3D 및 텍스트 대응 데이터 세트로 훈련한 후 Shap-E는 복잡하고 다양한 3D 모델을 몇 초 만에 생성할 수 있으며 추론 속도가 Point-E 보다 빠르고 다른 방법보다 훨씬 빠릅니다.
그러나 Point-E 의 문제와 마찬가지로 Shap-E 의 샘플은 품질이 좋지 않으며 인코더는 때때로 세부적인 텍스처를 잃습니다.

2023년 11월 Adobe Research와 호주국립대학교 연구팀은 혁신적인 대규모 재구성 모델 LRM을 출시했습니다. 이 방법의 프로세스는 다음과 같습니다. ① 사전 훈련된 시각적 모델 DINO를 적용하여 입력 이미지를 인코딩합니다. ② 이미지 특징은 교차 주의를 통해 대형 Transformer 디코더에 의해 3D 3면 공간에 투영되고 NeRF 모델을 사용하여 표현됩니다. ; ③ 다중 레이어 사용 Perceptron MLP는 볼륨 렌더링을 위한 포인트 색상과 밀도를 예측합니다.
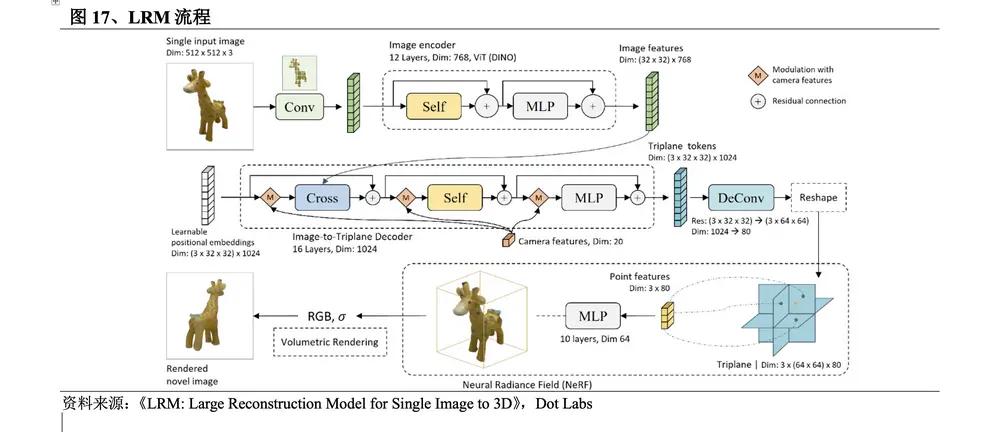
l짧은 시간 소비. 2D 차원 향상은 주로 확산 모델을 사용하여 최적화 알고리즘을 통해 3D 표현을 최적화합니다. 다른 3D 기본 방법은 3D 표현에 대한 확산 모델을 학습하며 추론에는 여러 반복 단계가 필요합니다. 매우 시간이 많이 걸립니다. LRM은 한 단계로 3D 표현을 직접 추론하고 단 5 초 만에 단일 입력 이미지에서 충실도가 높은 3D 개체 모델을 생성할 수 있는 학습 회귀 모델입니다.
l 다양성이 뛰어납니다. 소규모 데이터세트의 특정 범주에 대한 이전 교육 방법과 달리 LRM은 학습 가능한 매개변수가 5억 개에 달하는 확장성이 뛰어난 변환기 기반 아키텍처를 채택하고 Objaverse 및 MVImgNet 데이터세트에서 약 100만 개의 3D 객체를 사용하여 고도로 수행됩니다. 변하기 쉬운.
l 실제 장면 사진을 처리합니다. LRM을 통해 사용자는 스마트폰으로 촬영한 사진에서 고품질 3D 모델을 생성할 수 있으며, 3D 모델링의 민주화를 확대하고 무한한 창의적, 상업적 가능성을 열어줍니다.
LRM 은 최초의 대규모 재구성 모델로 고품질 3D 이미지를 빠르고 효율적으로 생성하여 증강 현실, 가상 현실 시스템, 게임, 영화 및 TV 애니메이션, 산업 분야에 변화를 가져왔습니다. 설계. 생성 속도와 품질의 상당한 이점은 3D 생성 기술 분야에서 재구성 모델의 물결을 일으켰습니다. LRM을 기반으로 많은 작업이 개선되었으며 대량 재구성 모델이 등장했습니다.
2D 차원 향상 경로는 먼저 텍스트에서 2D 이미지로 훈련을 위해 2D 데이터 세트를 사용한 다음 확산 모델 또는 NeRF 모델을 통해 3D 콘텐츠를 생성합니다. 주요 장점과 단점은 다음과 같습니다.
l 장점
강력한 풍부함: 사전 학습에 대량 의 2D 이미지 데이터를 사용할 수 있으며 생성된 3D 모델은 더욱 복잡하고 상상력이 풍부합니다.
l단점
낮은 생성 품질: 샘플 수, 관점 수 및 컴퓨팅 리소스 균형에 의해 제한되며 현재의 2D 차원 향상 방법은 해상도 및 질감 세부 사항이 거칠고 확산 모델의 3D 사전 기능이 부족합니다. 생성된 결과는 기하학적 구조에 대한 불합리한 질문을 받기 쉽습니다.
느린 생성 속도: NeRF 의 교육 및 추론 프로세스에는 대량 컴퓨팅 리소스가 필요하며 3D 공간의 집중적인 샘플링이 필요하므로 시간이 많이 걸립니다.
약한 호환성: NeRF 형식은 Unity 와 같은 3D 엔진에서 직접 편집할 수 없습니다. 매칭 큐브를 통해 3D 메시로 변환한 다음 3D 엔진에서 편집해야 합니다.
2018년에는 3D 콘텐츠를 신경망 매개변수로 표현하는 신경장이 탄생했습니다. 신경장은 여전히 3D 데이터를 표현하고 학습 데이터 부족으로 인해 2018~2020년 동안 천천히 발전했지만 2D 차원의 기술적 기반을 마련했습니다. 증가하다. 2020년 버클리, 구글, UC 샌디에이고의 공동팀은 높은 정확도의 이미지를 생성하고 대규모 장면의 3D 인식 이미지를 생성할 수 있는 NeRF 알고리즘을 제안하여 2D 차원의 개발을 크게 가속화했습니다. 교육 및 하드웨어 요구 사항 높은 요구 사항 및 낮은 발전 효율과 같은 문제로 인해 소규모 범위의 실험 및 레크리에이션 응용 프로그램에만 사용할 수 있습니다. 2022년 에는 Stable Diffusion 과 Dall·E 로 대표되는 2차원 영상 생성 애플리케이션이 빠르게 발전하여 2차원 차원의 상업적 가치를 높이고 기술 개발이 다시 가속화될 것이다. 구체적인 기술 개발 측면에서 2D 차원에 대한 초기 탐색은 구글이 2021년 말 출시한 드림필드(DreamFields) 였다. 이를 기반으로 2022년 9월 Imagen 확산 모델을 사용해 손실을 계산하고 SDS 방식을 사용해 개선된 드림퓨전(DreamFusion)을 출시했다. 샘플링을 통해 텍스트 품질이 크게 향상되었습니다. 이후 Nvidia는 생성 속도와 품질을 향상시키기 위한 2단계 최적화 전략을 도입하는 Magic3D를 출시했습니다. ProlificDreamer는 VSD를 사용하여 SDS 방법의 과포화, 과평활화 및 낮은 다양성 문제를 해결합니다. DreamGaussian은 3D 콘텐츠 생성에 3D Gaussian을 통합했습니다. 그 이후로 지난 6개월 동안 3D Gaussian을 기반으로 한 대량 일련의 개선 사항이 NeRF를 대체했습니다. 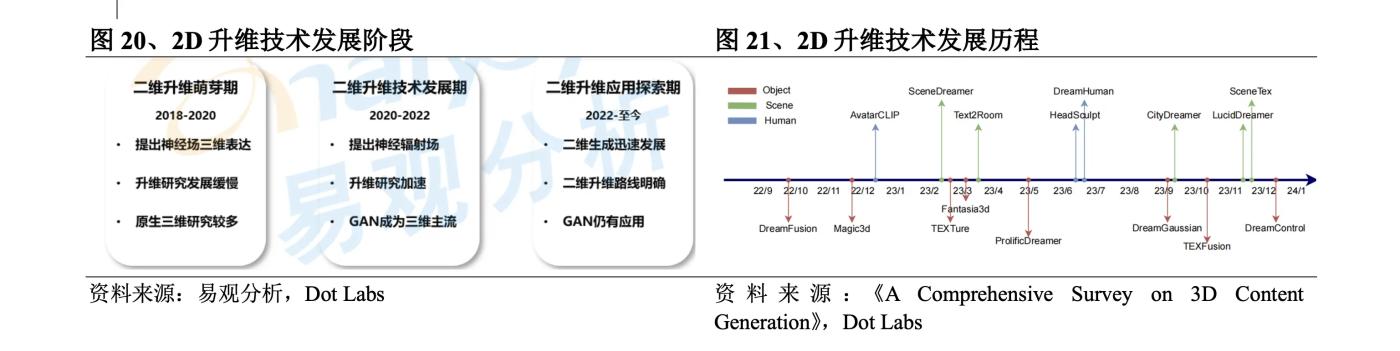
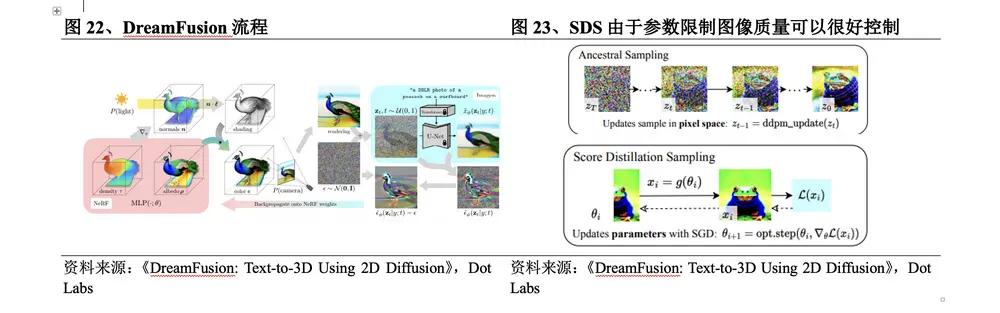
2022년 9월 Google은 DreamFields를 개선하기 위해 DreamFusion을 출시했습니다. DreamFusion 프로세스는 다음과 같습니다. ① NeRF를 사용하여 미리 결정된 카메라 위치에서 이미지를 렌더링하고 이를 가우스 분포와 혼합하여 잡음이 있는 이미지를 얻습니다. ② 이미지를 Imagen 확산 모델에 입력하고 NeRF 와 유사한 임의 가중치를 사용하여 초기화합니다. model; ③ 반복적으로 렌더링된 뷰는 SDS 기능에 대한 주변 Imagen 입력으로 사용됩니다. 이 방법의 구체적인 혁신은 다음과 같습니다.
l 텍스트에서 이미지로의 Imagen 확산 모델을 통해 손실을 계산하여 CLIP을 대체합니다. 이는 확산 모델에 의해 최적화된 NeRF 와 동일하며 3D 모델을 최적화합니다.
l 새로운 이미지 샘플링 방법 SDS를 사용하면 픽셀 공간이 아닌 매개변수 공간에서 샘플링이 수행되므로 생성된 이미지의 품질을 잘 제어할 수 있습니다.
l 이미지 생성 과정에서 매개변수는 확산 모델의 훈련 샘플이 되도록 최적화됩니다. 확산 모델에 의해 훈련된 매개변수는 다중 규모 특성을 가지며 이는 후속 이미지 생성에 더 도움이 되며 확산 모델은 다음과 같은 작업을 수행할 수 있습니다. 업데이트 방향을 직접 예측하는 것이 필요합니다.
DreamFusion은 3D 모델의 구조적 정확성과 렌더링의 신뢰성을 향상시키지만 3D 콘텐츠를 생성하려면 15,000번의 최적화가 필요합니다. 각 모델 생성에는 1.5 시간이 소요되며 이는 규모, 렌더링 및 구조적 세부 사항 측면에서 너무 길기 때문입니다. 산업 수준 애플리케이션의 요구 사항.
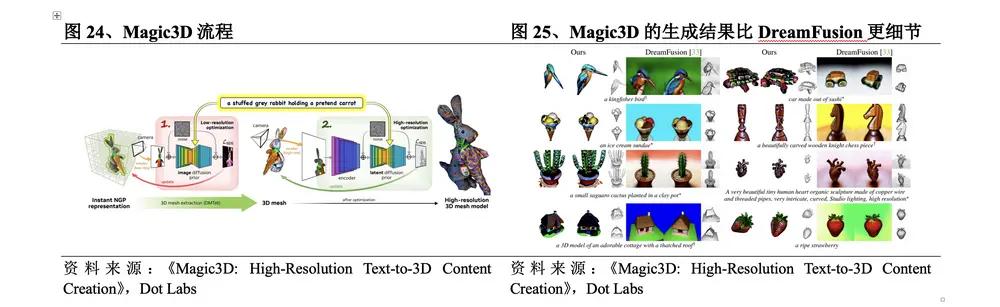
(2) Magic3D 2단계 최적화로 품질과 속도 향상
2022년 11월 Nvidia는 DreamFusion을 기반으로 한 2단계 최적화인 Magic3D를 출시했습니다. Magic3D 프로세스는 다음과 같습니다. ① 저해상도 최적화. 저해상도 이미지를 반복적으로 샘플링하고 렌더링하여 SDS 손실을 계산하고, 3D 재구성 모델인 Instant NGP를 사용하여 결과를 제공하고, DMTet을 사용하여 두 번째 단계의 입력으로 초기 3D 메시를 클레임. ② 고해상도 최적화. 고해상도 이미지는 동일한 방식으로 샘플링 및 렌더링되며, 동일한 방식으로 업데이트되어 최종 결과를 얻습니다. DreamFusion 과 비교하여 이 방법의 구체적인 혁신은 다음과 같습니다.
l 세대 품질이 더 높습니다. Magic3D 의 해상도는 DreamFusion보다 8 배 더 높으며 Magic3D 가 생성하는 특정 효과도 더 세밀합니다.
l더 빠르게 생성됩니다 . Magic3D는 DreamFusion 보다 2 배 빠른 40 분 만에 고품질 3D 메시 모델을 생성할 수 있습니다.
l 연결이 더 좋습니다. Magic3D 의 렌더링 방법은 전통적인 컴퓨터 그래픽과 매우 밀접하게 관련되어 있으며 생성된 결과를 표준 이미지 소프트웨어에서 직접 볼 수 있으므로 전통적인 3D 생성 작업과 더 잘 연결할 수 있으며 산업 응용 가능성이 있습니다.
(3) DreamGaussian은 NeRF를 대체하기 위해 3D Gaussian을 사용합니다.
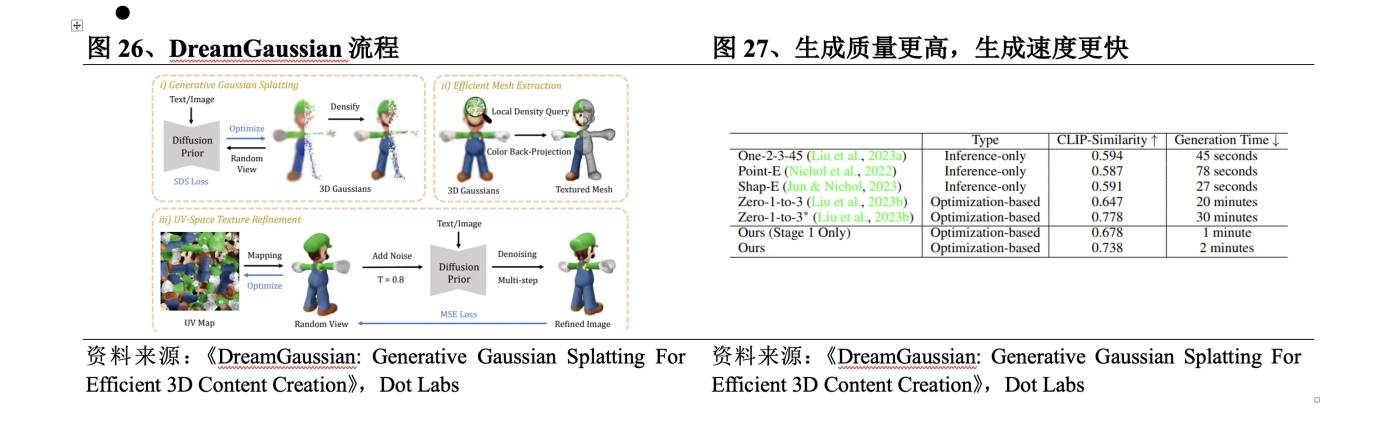
2023년 9월 Baidu, Nanyang Institute of Technology 및 Peking University의 저자가 공동으로 DreamGaussian을 출시했습니다. DreamGaussian 프로세스는 다음과 같습니다. ① UV 공간에서 3D Gaussian Splatting을 사용하여 텍스트 또는 이미지로 표시된 내용을 모델링합니다. ② SDS Loss를 사용하여 텍스처 메시를 최적화하고 클레임. ③ 여러 라운드의 MSE 를 통해 메시의 이미지 텍스처를 다듬습니다. 손실 계산. NeRF 기반 방법과 비교할 때 이 방법의 구체적인 혁신은 다음과 같습니다.
l 세대 품질이 더 높습니다. DreamGaussian은 3D Gaussian에서 메시를 클레임 알고리즘과 UV 공간 텍스처 개선 단계를 설계하여 생성 품질을 더욱 향상시켰습니다.
l더 빠르게 생성됩니다 . 생성 설정에 가우시안 분할을 적용하여 2D 차원 방법의 생성 시간을 크게 줄임으로써 DreamGaussian은 단일 뷰 이미지에서 명시적 메시 및 텍스처 매핑이 포함된 3D 콘텐츠를 기존 방법에 비해 약 10 % 가속화하여 2 분 만에 생성할 수 있습니다. .
초기 2D 차원 향상 방법은 훈련을 위해 주로 2D 데이터 세트를 사용했으며 제한된 3D 기하학적 지식만 정제할 수 있었습니다. 2023년 3월 , 컬럼비아 대학의 Liu Ruoshi 박사는 Zero123을 발표했습니다. 이 책에서는 2D 사전 훈련 모델에 3D 정보를 주입하면 확산 모델의 3D 사전 기능 부족을 효과적으로 보완할 수 있음을 발견했습니다. 따라서 다중 시점으로부터 영상을 생성한 후, 3차원 재구성을 통해 3차원 모델을 얻는 다중 시점 재구성 방법이 대두되었다. 나중에 캘리포니아 대학교 샌디에고의 Su Hao 교수 팀은 Zero123을 기반으로 확산 모델을 사용하여 더 나은 생성 일반화를 달성하는 One-2-3-45 및 One-2-3-45++를 제안했습니다. 제한된 3D 데이터는 상대적으로 정확한 기하학적 구조를 달성하는 데 사용되며 ByteDance는 MVDream을 출시하고 VAST 는 Wonder3D를 출시하며 Meta는 MVDiffusion++를 출시합니다.
(1) Zero123은 다중 뷰 재구성을 가능하게 합니다.
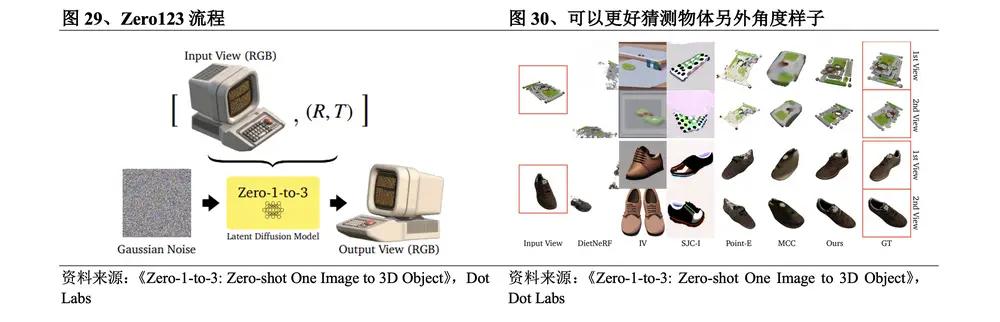
2023년 3월 컬럼비아대학교 연구팀은 Zero123을 출시했다. Zero123 프로세스는 다음과 같습니다. ①인코딩을 위해 단일 RGB 이미지를 입력합니다 . ②노이즈가 있는 이미지를 제거합니다 . ③새로운 원근 이미지를 생성하기 위해 다른 카메라 관점을 선택합니다 . ④교육 및 3D 재구성을 위해 이러한 다중 뷰 이미지를 확산 모델에 추가합니다 . 이 방법의 구체적인 획기적인 점은 3D 재구성과 새로운 뷰 합성의 순서가 바뀌더라도 입력 이미지에 설명된 객체의 동일성이 유지되므로 객체가 회전할 확률을 사용하여 모델을 생성할 수 있다는 것입니다. 확산 모델은 학습 과정 중 여러 각도에서 3D 개체의 실제 모양을 이미 알고 있으며 결정적, 의미론적 및 기하학적 사전 정보를 효과적으로 활용합니다. 다른 각도에서 본 물체의 모습.
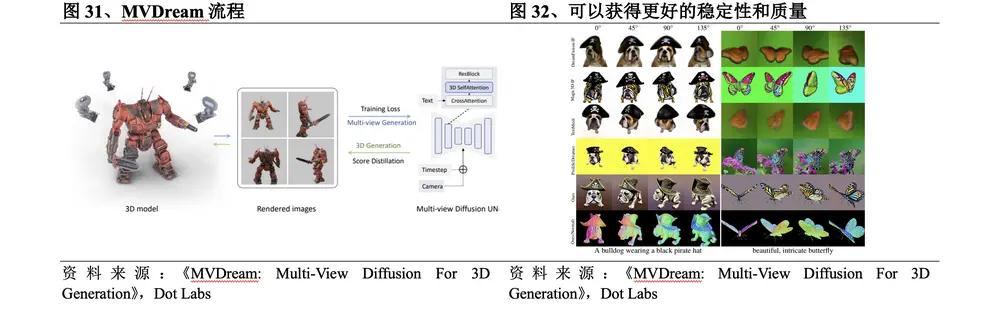
2023년 8월 ByteDance는 MVDream을 출시했습니다. MVDream 프로세스는 다음과 같습니다. ① Self-Attention 레이어의 서로 다른 뷰를 연결하여 원래 2D Self-Attention 레이어를 3D 로 변환하고 각 뷰에 카메라 임베딩을 추가합니다. ② 3D 최적화를 위해 우선적으로 다중 뷰 확산 모델을 사용합니다. SDS를 통해 생성된 3D . 이 방법의 구체적인 혁신은 다음과 같습니다.
l 대규모 네트워크 데이터 세트와 3D 리소스에서 렌더링된 다중 뷰 데이터 세트에 대해 사전 훈련된 이미지 확산 모델을 활용함으로써 결과적인 다중 뷰 확산 모델은 2D 확산의 다양성과 3D 데이터의 일관성을 모두 달성할 수 있습니다. 현재의 오픈 소스 2차원 차원 증가 방법과 비교하여 더 나은 안정성과 품질을 얻을 수 있습니다.
l 다중 뷰 확산 모델은 몇 개의 샘플 설정에서 훈련되고 미세 조정될 수 있으므로 사용자는 개인화된 3D 생성을 수행할 수 있습니다.
3. 2차원 차원 고도화 방식 상용화 기대
지속적인 개발과 개선을 통해 3D 생성 기술은 생성 품질, 속도 및 풍부함 측면에서 큰 발전을 이루었습니다. 다음 문제가 더 잘 해결될 수 있다면 3D 생성 기술은 매우 유망한 미래를 갖게 될 것입니다.
l데이터 세트. 부족한 교육 데이터는 주로 대량 과 같은 이유로 3D 생성 기술 개발을 제한하는 중요한 이유입니다. ① 3D 데이터 세트의 생산 이력이 매우 짧습니다. ③ 사용 시나리오 및 제작자의 스타일이 다르기 때문에 3D 자산은 규모, 품질 및 스타일이 크게 다르므로 3D 데이터의 복잡성이 증가합니다. ④ 3D 데이터를 얻는 것이 불편하고 대량3D 데이터가 게임에 분산되어 있습니다. 회사, 영화 및 TV 특수 효과 회사 및 개인 모델러를 수집하기가 어렵습니다. 3D 생성을 위해 2D 데이터를 활용하는 방법을 탐색하는 것이 하나의 솔루션이지만 대규모의 고품질 3D 데이터 세트는 여전히 매우 필요합니다.
ㅇ 표현수단 . 3D 생성 기술에서 암시적 표현은 복잡한 기하학적 위상 구조를 효과적으로 모델링할 수 있지만 최적화 속도가 느리다. 명시적 표현은 수렴을 빠르게 최적화하는 데 도움이 되지만 복잡한 위상 구조를 캡슐화하기 어렵고 대량 의 저장 자원이 필요하다. 높은 훈련 효율과 높은 정밀도를 동시에 가질 수 있는 표현 방식은 3차원 생성 효과를 한 단계 더 끌어올릴 것입니다.
l평가 시스템. 생성된 3D 콘텐츠를 종합적으로 평가하려면 물리적 특성과 의도한 디자인을 이해해야 합니다. 현재 3D 콘텐츠 품질 평가는 주로 수동 채점에 의존하고 있으며 기하학적 및 질감 충실도를 종합적으로 측정할 수 있는 강력한 지표를 개발하면 3D 최적화를 촉진할 수 있습니다. 세대 기술.
l제어성 . 3D 생성 기술의 목적은 저렴하고 제어 가능한 방식으로 사용자 친화적이고 고품질이며 다양한 3D 콘텐츠를 대량 생성하는 것입니다. 그러나 생성된 3D 콘텐츠를 실제 응용 프로그램에 적용할 때 호환성 문제는 3D 디자이너에게 도움이 되지 않습니다. 상호 작용 및 편집이 가능하고 생성된 콘텐츠의 스타일이 훈련 데이터 세트에 의해 제한되므로 다양한 방법으로 제작된 3D 콘텐츠를 통합하고 기술의 제어 가능성을 높이기 위해 풍부한 편집 기능을 포함하는 툴 체인을 구축해야 합니다.
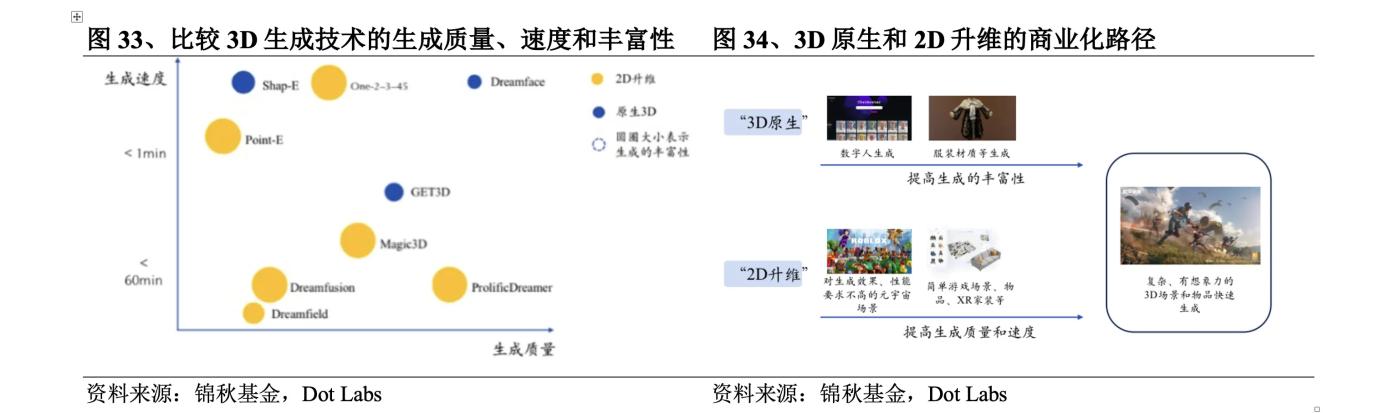
다양한 3D 생성 기술의 생성 품질, 생성 속도 및 풍부함을 비교하면 이러한 방법 사이에 "트릴레마 (Trilemma)"이 있음을 알 수 있습니다. 3D 기본 경로 방법은 기본적으로 품질과 속도를 보장하는 3D 데이터 세트를 사용하지만 데이터 세트가 너무 작기 때문에 풍부함에는 명백한 단점이 있습니다. 2D 데이터 세트 를 사용하면 풍부함 요구 사항을 잘 충족할 수 있습니다. Zero123은 눈길을 끄는 품질을 추구하는 DreamGaussian 과 같은 방법도 있습니다. 세대 속도.
"트릴레마 (Trilemma)"은 3D 생성 기술이 상용화 과정에서 더 큰 도전에 직면하게 만듭니다. 전문가를 위한 시나리오는 생성 품질에 대한 요구 사항이 더 높습니다. 예를 들어 산업, 건설, 의료 분야에서는 매우 정확한 3D 생성이 필요하며 일반 소비자를 위한 장면의 경우 생성 속도가 더 중요합니다. 생성 품질 및 속도 측면에서 3D 기본 방법의 장점은 상용화 요구 사항에 더 가깝고 특정 시나리오에서 사전 상용화를 달성할 수 있습니다. 예를 들어 Shadow Eye Technology의 Dreamface는 이미 게임 분야의 초기 모델링 작업 일부를 대체할 수 있으며 Get3D는 일부 Metaverse 장면에서 간단한 항목을 생성하고 있습니다. 이에 반해 2 차원 차원 향상 방법은 상용화와는 거리가 멀으나, 2023년 하반기부터 2차원 차원 향상과 관련된 학술적 성과가 대량 발표되고 있음을 알 수 있다. 생성 품질 및 생성 속도 측면에서 상당한 개선이 이루어지면 내년에는 Metaverse와 같이 생성 품질에 대한 엄격한 요구 사항이 없는 일부 장면에서 2D 차원 향상이 초기에 구현될 수 있는 기회를 갖게 될 것으로 예상됩니다. VR 가정 장식 등
4. 헤드마운트 디스플레이는 무한한 잠재력을 완성하고 열어줍니다.
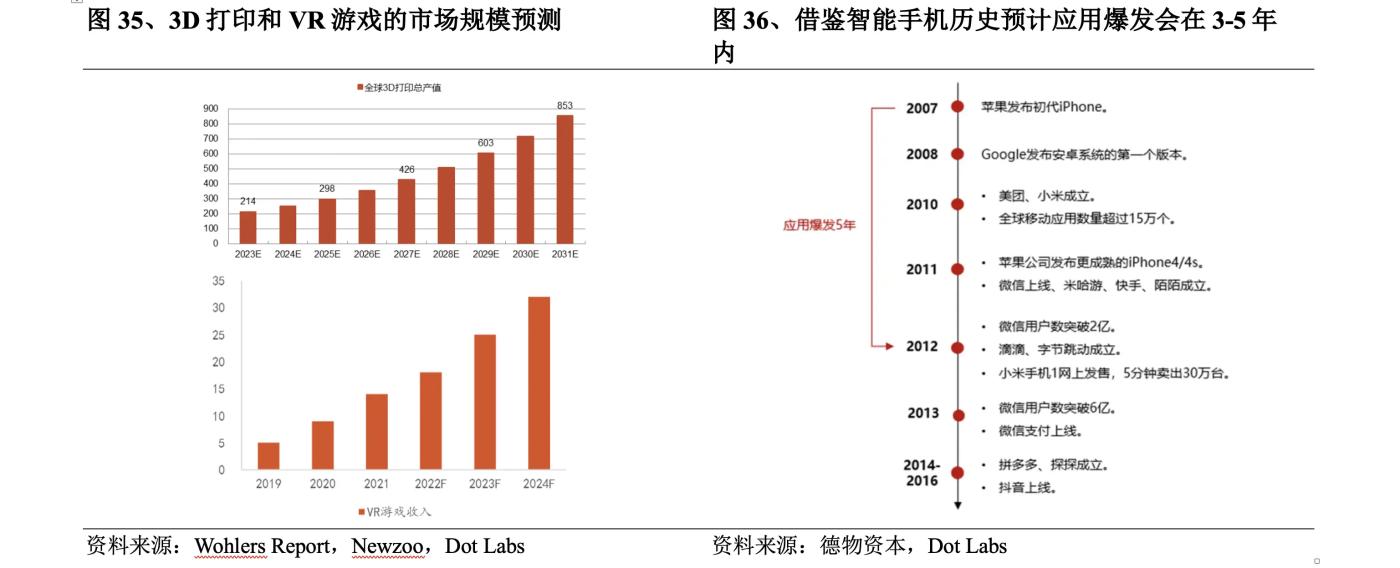
기존 3D 생성 기술에는 여전히 일부 문제가 있지만 향후 3D 생성의 응용 분야가 거대하고 주로 3D 프린팅, 게임, 영화, TV 및 기타 분야에 집중되어 있다는 것은 부인할 수 없습니다. Wohlers Report 의 데이터에 따르면 2022년 전 세계 3D 프린팅 총 생산량은 전년 대비 18% 증가한 182억 달러에 달할 것이며, 시장 규모는 계속해서 높은 수준을 유지할 것으로 예상됩니다. 2031년 에는 853 억 달러에 이를 것으로 예상된다. 뉴주 예측에 따르면 글로벌 VR 게임 시장 규모는 2024년 에는 32 억 달러에 달할 것으로 예상된다. 다운스트림 3D 콘텐츠 응용 분야가 발전함에 따라 3D 생성 기술에 대한 수요와 시장 기대가 광범위해졌습니다.
장기적인 관점에서 볼 때 3D 생성의 더 큰 잠재력은 머리 장착형 디스플레이의 개선에 있습니다. 하드웨어는 기술의 전달체이며, 하드웨어의 발전은 기술의 발전을 촉진합니다. 헤드 마운트 디스플레이 장비의 개선으로 인해 3D 네이티브 애플리케이션이 폭발적으로 증가할 것으로 예상됩니다. 개발자는 3D 생성 기술을 사용하여 헤드 마운트 디스플레이 애플리케이션을 개발하고 헤드 마운트 디스플레이 장비 생태계의 성숙도를 높일 수 있습니다. 사용자들의 피드백으로 볼 때 1세대 디바이스인 Vision Pro는 아직 만족스럽지 못한 품질이 많이 남아있지만, 스마트폰의 개발 이력을 보면 3~5 년 내로 애플리케이션 폭발이 실현될 것으로 예상되며, 향후에는 그것에서 엿본 것은 여전히 흥분할 가치가 있습니다.
5. 3D 세대 스타트업 시장 진출
3D 생성 기술의 문제를 해결하려면 단순히 몇 편의 논문을 출판하는 데에만 의존할 수 없으며, 3D 산업 표준과 전문적인 사용자 요구 사항에 대한 명확한 이해도 필요합니다. Nvidia , OpenAI , Google 과 같은 대형 기술 회사 외에도 3D 세대 분야에서 일부 신흥 3D 세대 스타트업도 사용성 측면에서 많은 작업을 수행했으며 최종 결과가 반드시 거대 기업보다 나쁜 것은 아닙니다. 그리고 미래는 시장의 기대에 부응할 가치가 있습니다.
l CSM ( Common Sense Machines ) : 2020년 미국 매사추세츠주에서 설립된 회사로, 전 구글 딥마인드 수석연구원인 테자스 쿨카르니(Tejas Kulkarni) 와 MIT 박사과정 연구원이자 세쿼이아의 스카우트 투자자 인 맥스 클라이먼-와이너(Max Kleiman-Weiner) 가 공동 창업했다. 수도. 이 회사는 사용자가 사진, 텍스트, 손으로 그린 스케치를 완전히 실현된 3D 세계로 변환할 수 있는 플랫폼 CSM.ai를 제공합니다. CSM은 명시적 게임 엔진과 암시적 게임 엔진이 아닌 제3의 프레임 혁신적으로 제안합니다. 높은 유연성과 제어성을 결합한 암시적 학습 게임 엔진, 확산 기반의 실시간 렌더링 엔진을 개발하고 고화질의 급속한 세대를 시작합니다. 게임 엔진 고해상도 3D 자산 및 사용자 정의 스타일 이미지를 위한 큐브 애플리케이션입니다. 그것 은 세 차례 융자 통해 1010 만 달러 를 모금 했습니다 .
l Luma : 전 Apple AR/CV 엔지니어인 Amit Jain이 2021년 에 공동 설립한 Berkeley Lab의 Alberto Taiuti 와 미국 캘리포니아에 본사를 둔 Alex Yu가 공동 설립했으며 AI를 통해 3D 이미지 및 비디오 생성 프로세스를 단순화하는 것을 목표로 합니다. 기술은 NeRF를 기반으로 합니다. 올해 1월 출시한 지니 1.0 은 텍스트를 기반으로 10 초 만에 3D 모델을 생성할 수 있으며, 이달 출시한 혁신적인 AI 영상 생성기 드림머신은 120 프레임의 빠른 속도로 텍스트와 이미지를 기반으로 고품질의 실감나는 영상을 생성할 수 있다. 120 초. 탁월한 기술력과 광범위한 시장 전망을 바탕으로 Luma는 Andreessen Horowitz , Matrix Partners 및 Amplify Partners 와 같은 유명 벤처 캐피털 회사를 포함한 주요 투자자들과 함께 미화 7천만 달러 이상의 자금을 성공적으로 조달했습니다. 2024년 현재 루마 의 가치는 3억 달러에 이르렀다.
l 폴리캠(Polycam) : 2021 년 미국 캘리포니아에서 설립된 앱 으로 아이폰 의 LiDAR 와 카메라를 활용해 3D 모델을 생성할 수 있다. 3D 텍스처 생성을 위한 AI Texture Generato , 3D 가우스 스퍼터 재구성을 위한 무료 3D 가우스 스퍼터 생성기 및 뷰어를 소개합니다. Polycam은 거의 100,000명의 유료 고객을 보유하고 있으며, APP는 1,000 만 번 이상 다운로드되었으며, 2,000 만 개 이상의 3D 모델이 제작되었으며, 5,000 만 개 이상의 3D 편집 작업이 수행되었습니다. 매출은 2021년 28만달 러에서 2022 년 180 만달러, 2023 년 650 만달러로 급증하고 올해 상반기에는 400만달 러를 넘어설 것으로 예상된다. 수익이 새로운 최고치를 기록할 것입니다. Left Lane Capital , Adjacent , Adobe Ventures 및 YouTube 공동 창립자 Chad Hurley 로부터 1,800 만 달러의 시리즈 A 융자 완료했습니다.
l Yellow : 2023년 에 설립된 3D 캐릭터 생성 회사로, A16z 로부터 500 만 달러의 시드 자금을 지원받았습니다. CEO Mandeep Waraich는 한때 Google의 대형 모델 및 Core ML 제품의 책임자였습니다. 대부분의 팀원은 MIT, Oxford, 스탠포드 및 기타 명문 학교 배경. 첫 번째 제품인 YellowSculpt 가 출시되어 토폴로지 인식 3D 생성이 가능해 사용 및 편집이 더욱 쉬워졌습니다. 대부분의 최신 생성 AI 기술은 견고한 개체를 생성하지만 Yellow 의 구조화된 메쉬 생성은 애니메이션이 쉬운 3D 모델을 생성하고 결과 메쉬는 Unity , Unreal 및 Roblox 와 같은 최고의 게임 엔진 또는 Daz Studio, Seamless와 함께 사용할 수 있습니다. Maya 및 Blender 와 같은 다른 3D 생성 도구와의 통합. Daz Studio 의 개발자인 Tafi 와의 독점 파트너십이 2024년 1월에 확립되어 Yellow는 Daz 의 3D 라이브러리를 활용하여 안전한 방식으로 모델을 교육할 수 있었습니다.
6. 3D 생성 및 코딩 공간 지능 시대
공간지능은 실시간 렌더링을 지원하는 3D 가상 환경으로, 지원으로 신원 인증, 데이터 확인, 자산 거래, 규제 거버넌스 등이 필요하며 Web 3 의 탈중앙화 사고는 안전하고 신뢰할 수 있으며 개방적인 환경을 제공합니다. 시설 환경과 공간 지능 역시 웹 3 의 대규모 적용을 위한 중요한 시나리오가 될 것입니다. 웹 3 와 공간 지능은 상호 강화적인 발전을 이루고 있으며 공간 지능의 중요한 3D 생성 기술은 인터넷 환경에서 폭넓게 응용될 것입니다. Web 3. 및 개발 공간입니다.
1. Lifeform : Visual DID의 선구자가 Web 3의 획기적인 기회를 선도합니다.
Web 3 및 공간 인텔리전스의 최전선에서 디지털 가상 ID는 업계에서 매우 중요하지만 인프라가 부족합니다. Lifeform 은 탈중앙화 디지털 ID( DID ) 솔루션의 선구적인 제공업체로, Web 3 사용자에게 모든 DApp 및 메타버스에 로그인하는 데 사용할 수 있는 디지털 가상 ID를 제공하여 블록체인 상호 운용성을 달성하고 Web 3 에 획기적인 발전을 가져올 것으로 예상됩니다. 개발 기회의. 이 프로젝트는 1년 동안 총 4억 달러 규모의 융자 을 진행했습니다. 투자 기관으로는 Binance, IDG Capital 및 GeekCartel이 있으며, 출시 후 174 일 만에 Twitter 에서 100,000명의 팔로워를 확보했으며 현재 월별 서비스를 제공하고 있습니다. 거래량은 350 만 달러를 넘어 BSC 시장 점유율 의 약 35%를 차지하며 OpenSea 에 이어 두 번째로 올해 5월 Bybit 및 KuCoin 에서 토큰 LFT가 출시되었습니다.
l 심리적 경험을 향상시키는 시각적 DID . 기존 DID는 사용자의 개인정보를 온체인 에 저장하고 NFT 나 SBT를 통해 온체인 ID와 바인딩하는데, Lifeform은 DID 표준과 호환되는 것 외에도 사용자에게 가상 인물 을 제공합니다. DID 프로토콜, 스마트 계약 등을 통해 사용자는 시각화된 3D 가상 캐릭터로 메타버스 활동에 참여할 수 있어 사용자의 시각적, 심리적 경험이 향상됩니다.
l 개인화된 요구 사항을 충족하는 100억 개 이상의 조합. Lifeform 의 제품인 AvatarID에는 UE5 기반의 Hyper-Realistic 과 카툰 스타일의 Cartoon Version의 두 가지 유형이 있습니다. 가상 인간 편집에는 7개의 생성 부분이 포함되어 있으며 각 부분에는 1,000개 이상의 구성 요소가 있으며 사용자는 100 억 개 이상의 아바타 조합을 만들 수 있습니다. 또한, 사용자의 제작 난이도를 줄이기 위해 대량 템플릿을 제공하며, 제작 완료 후 NFT를 형성할 수 있습니다.
l범용 도메인 이름은 체인 간 가용성을 보장합니다. 크로스체인 기능과 애플리케이션 범위를 제한하는 다양한 블록체인을 사용하는 다른 DID 솔루션과 달리 Lifeform 에서 만든 범용 도메인 이름 서비스는 .btc 접미사를 통해 블록체인 간 인증 및 위치 지정을 단순화하고 다중 도메인 이름 확인을 지원하는 최초의 서비스입니다. 블록체인용 플랫폼(Bitcoin, 이더, BNB Chain , Solana , Base , Avalanche , OPBNB 등)을 통해 사용자는 자신의 신원 정보를 완전히 제어할 수 있어 디지털 신원의 글로벌 가용성을 보장할 수 있습니다. 앞으로는 다양한 지갑과 협력하고, .btc 도메인 이름 SDK를 거래소 지갑에 통합하고, 다중 레이어 1 및 레이어 2 네트워크 전반에 걸쳐 원활한 상호 작용을 지원할 계획입니다. 
2. Param Labs : 모듈 연동 시스템으로 혁신적인 Web 3 게임 생태계
Param Labs는 모듈 으로 상호 연결된 Web3 게임 생태계를 만드는 데 전념하는 AAA 게임 및 블록체인 개발 스튜디오입니다. 사용자가 창출한 가치가 반환될 수 있도록 디지털 재산권을 부여함으로써 플레이어와 개발자의 게임 경험을 완전히 변화시킵니다. 이 프로젝트는 현재 Animoca Brands 가 주도하고 Delphi Ventures 와 Cypher Capital 이 참여하여 700 만 달러 융자 완료했습니다. 이 프로젝트는 약 900,000명의 Twitter 팔로어, 500,000명의 Discord 사용자 및 300,000명의 일일 활성 사용자를 보유하고 있습니다. Gate.io와 같은 거래소 PARAM 토큰을 출시했습니다. 주요 제품은 다음과 같습니다.
l Pixel to Poly : 사용자가 업로드한 2D 이미지를 고품질의 게임용 3D 자산으로 변환하는 메타버스 자산의 대량 생산을 위한 플랫폼으로, 이러한 자산은 Fortnite 및 GTAV 와 같은 이슈 게임에 통합될 수 있으며, 게임 개발자의 제작 시간을 단축하고 3D 게임 산업의 자산 생성을 가속화합니다. 또한 플랫폼에는 게임에 사용되는 고유한 NFT가 있어 플레이어와 수집가에게 귀중한 디지털 자산을 제공합니다.
l Kiraverse : 고유한 교차 IP 및 교차 생태계 경험을 위해 사용자 지정 IP를 가져와 사용자가 더욱 개인화할 수 있는 무료 멀티플레이어 슈팅 게임입니다. 올해 5월 에 발표된 게임 생태계 Pixelverse 와의 파트너십을 통해 Pixelverse는 지적 재산과 캐릭터를 Kiraverse 에 통합하여 게임의 내러티브를 강화하고 세계관을 확장할 것입니다. 
3. NeuralAI : Web 3 3D 생성 혁신을 위한 Bittensor 서브넷 개발
NeuralAI는 $NEURAL 생태계와 dapp을 활용하여 사용자에게 3D 자산 생성 서비스를 제공하고, 사용자가 창의적 자산을 원활하게 거래할 수 있는 시장을 제공합니다. 이 프로젝트는 현재 Bittensor 서브넷을 개발 중이며 3D 자산 생성을 위한 최고의 Bittensor 서브넷이 되는 것을 목표로 첫 번째 dapp을 출시할 예정입니다. 이 프로젝트는 세계 최고의 탈중앙화 컴퓨팅 시장 인 Akash Network 와 전략적 협력을 달성했으며 Akash는 필요에 따라 확장할 수 있는 56개의 강력한 A6000 GPU를 제공했습니다.
l LRM 모델은 다각형 수를 최적화합니다. NeuralAI 가 사용하는 주요 모델은 LRM 입니다. 이 모델의 중요한 장점은 더 작은 다각형 수를 유지하면서 세부 정보를 유지하는 최적화된 다각형 수 메쉬를 생성할 수 있다는 것입니다. 모델은 효율적이고 상세하게 유지되어 게임 환경에 이상적이며 3D 아티스트가 소프트웨어를 사용하여 후반 작업에서 메시를 조작 및 개선하거나 게임 엔진에 직접 추가할 수 있습니다.
l Bittensor 서브넷은 3D 생성 비용을 절감합니다 . 3D 자산 생성은 대량 컴퓨팅 성능과 인적 자원이 필요한 리소스 집약적인 프로세스입니다. 분산형 머신러닝(ML) 네트워크인 Bittensor는 글로벌 노드 간에 대량 컴퓨팅 작업을 분산할 수 있습니다. NeuralAI는 3D 자산 생성을 위한 더 나은 솔루션을 제공하기 위해 Bittensor 네트워크에서 전용 서브넷을 개발하고 있습니다. 이 프로젝트에서는 전문 3D 아티스트를 고용하는 비용이 시간당 30~ 100달러, 제작하는 데 10 시간이 걸리는 복잡한 자산의 경우 소프트웨어 및 하드웨어의 추가 간접비를 제외하면 300~ 1,000달러가 소요될 것으로 추산합니다. Bittensor 서브넷에서 Bittensor는 토큰 TAO를 사용하여 검증자와 채굴자에게 보상을 제공합니다. Neural dApp , Neural 플러그인 또는 API 사용자는 네트워크의 인센티브가 3D 자산 생성에 대한 보상을 포함하는 경우 3D 자산을 무료로 생성할 수 있습니다. 비용은 90-100% 절약될 수 있습니다.

7. 리스크 경고
첫 번째 리스크: 가격 변동
- 암호화폐 가격은 변동성이 매우 높으며 미래 가격을 보장하거나 예측할 수 없습니다.
리스크2 : 금융
- 프로젝트가 파산하거나 SWEAT 원금이나 이자를 상환하지 못할 수도 있습니다.
리스크3 : 해커 공격
- SWEAT는 악의적인 행위자에 의해 도난당할 수 있으며, 프로젝트에서 자금을 반환하지 못할 수도 있습니다.
리스크4 : 법적
- 일부 국가 및 지역에서는 이러한 행위를 금지하고 있으며, 프로젝트 당사자는 SWEAT 원금이나 이자를 상환하지 못할 수도 있습니다.