

PANDAS: Ethereum에서 차세대 데이터 가용성 샘플링을 위한 실용적인 접근 방식
저자: Onur Ascigil1, Michał Król2, Matthieu Pigaglio3, Sergi Reñé4, Etienne Rivière3, Ramin Sadre3
요약
- PANDAS는 32MB 이상의 블롭을 지원하는 댄크샤딩을 지원하는 네트워크 계층 프로토콜입니다.
- PANDAS는 무작위 표본 추출에 대한 4초 마감일을 달성하는 것을 목표로 합니다( 타이트 포크(Fork) 선택 모델 에 따라).
- 제안자-빌더 분리(PBS) 에 따라, 수완이 뛰어난 빌더는 샘플을 노드에 초기 분배(즉, 시딩)합니다.
- PANDAS는 각 슬롯 동안 두 단계로 진행됩니다. 1) 시딩 단계: 슬롯을 만든 선택된 빌더가 2차원 인코딩된 블롭 의 행과 열의 하위 집합을 검증 노드에 배포합니다. 2) 행/열 통합 및 샘플링 단계: 노드가 무작위 셀을 샘플링하고 동시에 할당된 행/열을 검색하여 재구성하여 셀의 데이터 가용성을 높입니다.
- PANDAS는 시딩 및 샘플링 단계 모두에 대해 DHT나 가십 기반 멀티홉 방식이 아닌, 1홉, 즉 지점 간 통신을 의미하는 직접 통신 방식을 사용합니다.
PANDAS를 설계할 때 우리는 다음과 같은 가정을 합니다.
가정 1) 자원이 풍부한 빌더: PANDAS에서 PBS(Proposer-Builder Separation) 방식에 따라 500Mbps 이상의 충분히 높은 업로드 대역폭을 갖춘 클라우드 인스턴스와 같은 자원이 풍부한 빌더 세트가 네트워크에 시드 샘플을 배포합니다.[1]
가정 2) 빌더 인센티브: 빌더는 DAS가 성공하는 경우에만 블록 수락되기 때문에 블롭 데이터를 사용할 수 있는 인센티브를 갖습니다. 그러나 다른 빌더는 다른 양의 리소스를 가질 수 있습니다. 합리적인 빌더의 관심사는 최소한의 리소스를 사용하면서 데이터가 사용 가능한 것으로 간주되도록 보장하는 것입니다.
가정 3) 검증 노드(VN)는 DAS 프로토콜의 주요 엔티티입니다. 단일 검증 노드(VN)는 호스팅하는 검증기 수에 관계없이 단일 샘플링 작업(단일 엔티티)만 수행합니다.
가정 4) 부정직한 다수: VN과 빌더의 다수(또는 압도적 다수)는 악의적일 수 있으며, 따라서 프로토콜을 올바르게 따르지 않을 수 있습니다.
가정 5) Sybil 저항 VN : 정직한 VN은 검증 증명 체계를 사용하여 최소한 한 명의 검증자를 호스팅한다는 것을 증명할 수 있습니다. 여러 노드가 동일한 증명을 재사용하려고 하면 다른 정직한 노드와 빌더가 차단 목록에 추가할 수 있습니다.
PANDAS의 목표는 다음과 같습니다.
목표 1) 엄격한 포크(Fork) 선택: 정직한 검증자 노드(VN)는 대다수의 VN이 악의적 일지라도 블록 에 투표하기 전에 무작위 샘플링을 완료합니다.*.* 따라서 우리는 엄격한 포크(Fork) 선택 모델을 목표로 합니다. 즉, 슬롯 위원회에 있는 정직한 VN은 해당 슬롯을 시작한 후 4초 이내에 투표하기 전에 무작위 샘플링을 완료해야 합니다.
목표 2) 유연한 빌더 시딩 전략: 빌더마다 리소스가 다를 수 있으므로, 이 설계는 블록 빌더가 다양한 블롭 배포 전략을 구현할 수 있는 유연성을 제공하며, 각 전략은 보안과 리소스 사용 간에 다른 트레이드오프를 갖습니다. 더 높은 보안을 위해 빌더는 블롭 셀의 사본을 더 많이 검증자 노드로 보내 더 높은 가용성을 보장할 수 있습니다. 반대로 리소스 사용을 최소화하기 위해 빌더는 각 셀의 단일 사본을 최대로 배포하여 보안을 낮추는 대가로 대역폭 사용을 줄일 수 있습니다. 이 유연한 접근 방식을 통해 빌더는 블록 이 검증자 노드에서 사용 가능한 것으로 간주되는 인센티브를 받으면서 데이터 가용성을 보장하고 대역폭을 최적화하는 트레이드오프를 탐색할 수 있습니다.
목표 3) 일관되지 않은 노드 뷰 허용: 우리의 목표는 VN과 빌더가 VN 목록에 대한 합의 에 도달할 필요가 없도록 하는 것입니다. VN과 빌더가 시스템의 VN 세트에 대해 일반적으로 동의하도록 하는 것이 목표이지만, VN이 엄격하게 일관된 뷰를 유지하거나 빌더와 VN의 뷰가 완전히 동기화될 필요는 없습니다.
판다스 디자인
지속적인 피어 발견: 목표 3을 달성하기 위해 시스템의 노드는 아래 프로토콜 단계와 병렬로 지속적인 피어 발견을 수행하여 다른 피어를 포함하는 최신 "뷰"를 유지합니다. 빌더 와 VN은 유효한 Proof-of-Validator가 있는 모든 VN을 발견하는 것을 목표로 합니다. 빌더와 VN은 모두 시스템의 모든 VN에 대한 가깝지만 완벽하지는 않은 뷰를 가질 것으로 예상합니다.
피어 디스커버리 프로토콜을 실행하는 멤버십 서비스는 새로운(검증된) VN을 뷰에 삽입하고 결국 완전한 VN 세트로 수렴합니다. 피어 디스커버리 메시지는 샘플 요청 메시지에 피기백되어 디스커버리 오버헤드를 줄입니다.
PANDAS 프로토콜에는 각 슬롯 동안 반복되는 두 개의 (조정되지 않은) 단계가 있습니다.
1단계 ) 시딩,
2단계) 행/열 통합 및 샘플링
시딩 단계에서 빌더는 행/열의 하위 집합을 VN에 직접 푸시합니다. 여기서 행/열 할당은 결정적 함수에 기반합니다. VN이 빌더로부터 샘플을 받으면 할당된 전체 행/열을 통합하고(해당 행/열에 할당된 다른 VN에서 누락된 셀을 요청하여) 동시에 무작위 샘플링을 수행합니다.
VN은 통합 및 샘플링을 시작하기 위해 조정하지 않습니다. 따라서 1단계를 완료한 노드는 다른 노드와 조정하지 않고도 2단계를 즉시 시작할 수 있습니다. 슬롯의 위원회 멤버인 VN은 슬롯에 들어간 후 4초 이내에 시딩 및 무작위 샘플링을 완료해야 합니다.
아래에서 프로토콜의 두 단계를 자세히 설명하겠습니다.
1단계 - 시딩 : 빌더는 아래에서 설명하는 해시 공간을 사용하는 결정적 함수를 사용하여 개별 행/열에 VN을 할당합니다. 개별 행/열에 대한 VN의 이 매핑은 동적이며 각 슬롯에서 변경됩니다. 이 매핑을 통해 노드는 노드의 수 또는 전체 목록을 알 필요 없이 로컬 및 결정적으로 노드를 행/열에 매핑할 수 있습니다.
건설업체는 다음과 같이 VN에 종자 샘플을 준비하여 배포합니다.
1.a) 해시 공간의 정적 영역에 행/열 매핑: 개별 행과 열은 그림 1의 위쪽 부분에 표시된 것처럼 해시 공간의 정적 영역에 할당됩니다.
1.b) 해시 공간에 VN 매핑 : 빌더는 정렬 함수 FNODE(NodeID, epoch, slot, R)를 사용하여 각 VN을 해시 공간의 키에 할당합니다. 이 함수는 노드의 식별자(즉, 피어 ID), epoch 및 slot 번호, 이전 슬롯의 블록 헤더 헤더에서 파생된 난수 값 R과 같은 매개변수를 사용합니다.
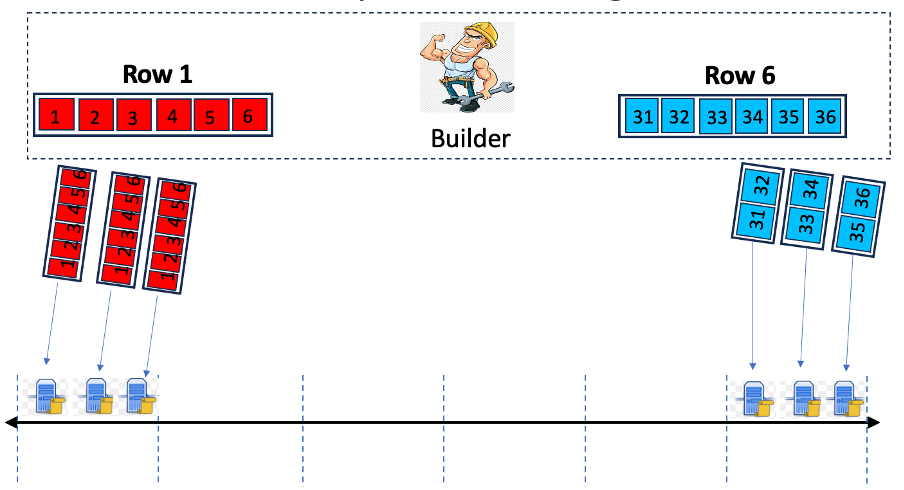
그림 1: VN에 대한 행 샘플 할당. 열 샘플도 비슷하게 매핑됩니다.
행의 영역에 할당된 VN은 빌더로부터 해당 행에 속하는 셀의 하위 집합을 받습니다. VN이 FNODE를 사용하여 각 슬롯 동안 해시 공간에 다시 매핑되므로 행/열 할당도 변경될 수 있습니다.
참고: 행과 열을 슬롯별로 동적으로 VN에 할당하는 것은 가십 기반 시딩 방식에서 불가능합니다. 이 방식에서는 행별 및 열별 가십 채널이 시간이 지나도 비교적 안정적으로 유지되어야 합니다.
1.c) 행/열 샘플 분배: 각 행과 열에 대해 빌더는 최선의 노력 분배 전략을 적용하여 각 행/열의 하위 집합을 해당 행/열의 영역에 매핑된 VN으로 푸시합니다. 빌더는 직접 통신 방식, 특히 UDP 기반 프로토콜을 사용하여 각 행/열의 셀을 VN으로 직접 분배합니다.
직접적인 의사소통의 근거 *:* 우리는 투표하기 전에 위원회 위원들이 무작위 표본 추출을 완료할 시간을 갖도록 하기 위해 시딩 단계를 가능한 한 빨리 완료하는 것을 목표로 합니다(목표 1).
행/열 분배 전략: 빌더가 목표 2에 따라 리소스 가용성에 따라 분배 전략을 선택할 수 있도록 합니다. 리소스 사용과 데이터 가용성 간에는 다른 분배 전략에 대한 상충 관계가 있습니다. 두 행을 분배하는 그림 2의 예를 고려해 보겠습니다. 한 극단적인 경우(왼쪽) 빌더는 행 1 전체를 행의 영역에 있는 각 VN에 분배하여 리소스 사용량을 높이는 대가로 데이터 가용성을 높입니다. 또 다른 극단적인 경우 빌더는 행 6의 겹치지 않는 행 조각을 해당 행의 영역에 있는 각 VN에 보내는데, 이는 리소스가 덜 필요하지만 개별 셀의 가용성이 낮아집니다.
우리는 현재 다양한 배포 전략을 평가하고 있는데, 여기에는 행/열의 개별 셀을 행/열 영역의 개별 VN에 결정적으로 매핑할 수 있는 전략이 포함됩니다.
참고사항 : 빌더는 시딩 단계에만 참여합니다.
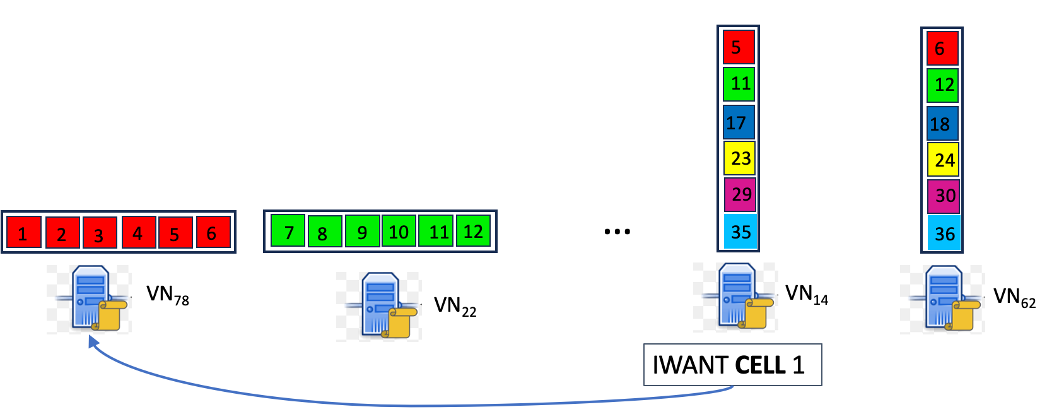
그림 2: 해당 행의 영역에 있는 VN에 행 샘플을 분배하는 두 가지(극단적인) 전략.
2단계 - 행/열 통합 및 샘플링 : 현재 슬롯의 위원회에 속한 VN은 슬롯의 처음 4초(즉, 투표 마감일) 내에 임의 샘플링을 완료하는 것을 목표로 합니다. 특히 4초 내에 (임의) 샘플링을 수행해야 하는 슬롯의 위원회 구성원을 위해 셀의 가용성을 높이기 위해 VN은 또한 통합합니다. 즉, 행/열 샘플링의 일부로 FNODE 매핑을 기반으로 할당된 전체 행과 열을 검색합니다.
2.a) VN 무작위 샘플링: 현재 슬롯 위원회의 VN은 빌더로부터 시드 샘플을 받는 즉시 무작위로 선택된 73개 세포를 검색하려고 시도합니다.
결정적 할당 FNODE를 사용하면 VN은 주어진 행이나 열을 결국 보관할 것으로 예상되는 노드를 로컬하게 결정할 수 있습니다.
샘플링 알고리즘: 이러한 노드 중 일부는 오프라인이거나 응답하지 않을 수 있습니다. 셀에 대한 요청을 순차적으로 보내면 위원회 구성원의 4초 마감일을 놓칠 위험이 있습니다.
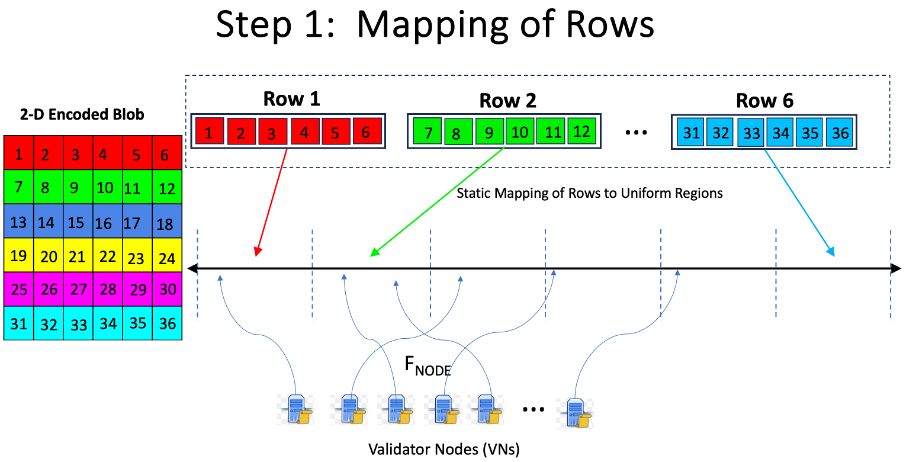
그림 3: 샘플 페치 예: 각 VN에 할당된 행과 열은 해당 VN의 맨 위에 표시됩니다. VN14는 매핑 FNODE에 대한 지식을 기반으로 셀 1을 검색하기 위해 VN78에 요청을 보내는 것을 알고 있습니다.
동시에, 사본을 보유한 모든 피어에게 요청을 보내면 네트워크에서 메시지가 폭발적으로 늘어나 혼잡의 위험이 있습니다. 따라서 페칭은 한편으로는 병렬 및 중복 요청 사용과 다른 한편으로는 지연 제약 사이에서 균형을 찾아야 합니다. 저희의 접근 방식은 UDP 기반(연결 없음) 프로토콜을 통해 노드 간 직접 통신을 사용하는 적응형 셀 페칭 전략을 사용합니다. 페칭 알고리즘은 손실과 오프라인 노드를 허용할 수 있습니다.
2.b) VN 행/열 통합: VN이 빌더로부터 할당된 행 또는 열의 셀의 절반 미만을 수신하는 경우(빌더가 선택한 분배 전략의 결과로), 다른 VN에서 누락된 셀을 요청합니다. VN은 행/열 통합 중에 동일한 행/열의 영역에 할당된 VN에서만 셀을 요청합니다. VN이 행 또는 열의 셀의 절반을 가지고 있는 경우 전체 행 또는 열을 로컬로 재구성할 수 있습니다.
행/열 통합의 근거:
- 누락된 셀 재구성 : 행/열 샘플링을 수행하는 동안 VN은 누락된 셀을 재구성합니다.
- 셀의 가용성을 높이기 위해: 결정적 매핑(FNODE)이 주어지면 빌더는 행과 열의 하위 집합을 VN으로 보내기 위해 모든 배포 전략을 선택할 수 있습니다. 행/열 통합은 무작위 샘플링을 제때 완료할 수 있도록 샘플의 가용성을 개선하는 것을 목표로 합니다.
이상적으로 빌더는 VN이 행과 열을 효율적으로 통합할 수 있는 시드 샘플 배포 전략을 선택해야 합니다. 이를 용이하게 하기 위해 빌더는 빌더의 배포 전략의 일부로 행/열의 개별 셀이 해당 행/열의 영역 내 VN에 할당되는 방식을 자세히 설명하는 맵(시드 샘플과 함께)을 각 VN에 푸시할 수 있습니다. 이 맵을 사용하면 VN이 누락된 셀을 신속하게 식별하고 검색하여 완전한 행을 재구성할 수 있으므로 데이터 가용성이 향상됩니다.
참고: 일부 DAS 접근 방식에서 '행/열 샘플링'이라는 용어는 노드가 블롭의 가용성에 투표하기 전에 여러 행과 열을 검색하는 것을 말합니다. 저희 접근 방식에서 노드는 행과 열을 검색하여 데이터 가용성을 향상시키고, 투표하기 전에 무작위 샘플링을 수행해야 하는 검증자를 지원합니다.
PANDAS에서 위원회 구성원은 무작위 표본 추출을 기반으로 투표하고 전체 행이나 열을 직접 표본 추출하지 않기 때문에 우리는 이것을 '행/열 표본 추출' 대신 '행/열 통합'이라고 부릅니다.
일반 노드(RN)는 어떻습니까?
VN과 달리 RN은 빌더로부터 시드 행/열 샘플을 얻지 않습니다. 빌더는 Proof-of-Validator 방식을 사용하는 Sybil 저항 VN 그룹에 초기 시드 샘플을 보냅니다. 현재 RN이 Sybil이 아니라는 것을 증명할 수 있는 메커니즘은 없습니다. 따라서 빌더의 초기 샘플 배포는 VN만 사용합니다.
공개 결정적 함수 FNODE를 사용하면 RN을 개별 행/열 영역에 유사하게 매핑할 수 있습니다. 영역에 매핑되면 RN은 (선택적으로) 행/열 통합을 수행하여 전체 행과 열을 검색하고 할당된 영역 내의 셀에 대한 쿼리에 응답할 수 있습니다.
다른 노드와 마찬가지로 RN은 피어 발견을 수행해야 합니다. 일반적으로 RN은 모든 VN을 발견하는 것을 목표로 하며 다른 RN을 발견하려고 할 수도 있습니다. 피어 발견을 통해 다른 피어에 대한 지식을 얻은 RN은 직접 통신을 통해 무작위 샘플링을 수행할 수 있습니다. VN과 달리 RN은 샘플링을 완료하는 데 엄격한 시간 제약을 받지 않습니다. 예를 들어 현재 슬롯에 대한 블록 헤더를 수신한 후 VN 이후에 샘플링을 시작할 수 있습니다.
토론 및 진행 중인 작업
우리는 합리적인 빌더가 비용을 절감할 인센티브(그리고 공급 부족)를 가지고 있다고 가정하지만, 동시에 블록을 사용 가능하게 하는 것을 목표로 합니다(보상). 이는 빌더가 행/열 통합을 가능한 한 효율적으로 하는 것을 목표로 한다는 것을 의미합니다. 즉, 효율적인 통합으로 셀의 가용성이 향상되고 빌더는 시딩 단계에서 각 셀의 사본을 덜 보내 비용을 절감할 수 있습니다.
현재 우리는 샘플을 숨기고 피어 발견을 방해하려는 악의적인 VN을 사용하여 다양한 배포 전략을 실험하고 있습니다. DAS 시뮬레이션 코드는 DataHop GitHub 저장소 에서 사용할 수 있습니다.
[1] 영국 랭커스터 대학교(Lancaster University)
2 City, University London, 영국
3 Université catholique de Louvain (UCLouvain)
4 DataHop 랩





