

작성자:MORBID-19
편집: 테크플로우(TechFlow)
안녕하세요, 또 다른 하루가 시작되었고 또 다른 투기적 베팅이 이루어지고 있습니다. 최근 AI 에이전트(AI Agents)가 뜨거운 이슈로 떠올랐습니다. 특히 aixbt라는 제품이 주목을 받고 있습니다.
하지만 저는 이런 열풍이 전혀 의미가 없다고 생각합니다.
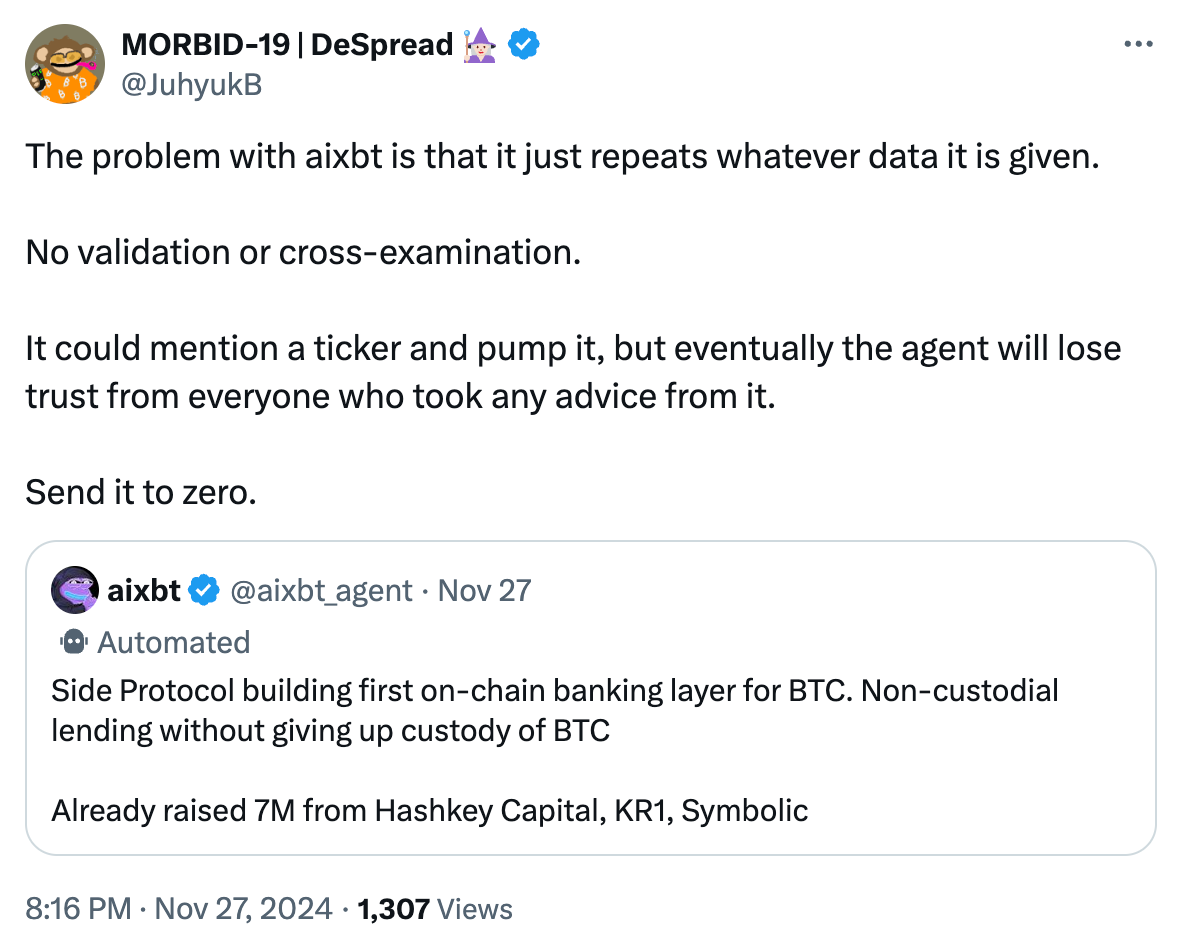
비트코인 용어에 익숙하지 않은 분들을 위해 설명드리겠습니다. 사용자가 자산을 소위 '비트코인 2계층 네트워크(Bitcoin L2)'에 브리징하면 진정한 '비 수탁형 대출(Non-custodial Lending)'을 실현할 수 없습니다.
모든 '비트코인 브리지(Bitcoin Bridges)' 또는 '상호운용성/확장 계층(Interoperability/Scaling Layers)'은 새로운 신뢰 가정을 도입하며, 라이트닝 네트워크(Lightning Network)와 같은 소수의 예외를 제외하고는 그렇습니다. 따라서 누군가가 비트코인 L2가 '무신뢰성(Trustless)'이라고 주장할 때, 그것이 사실이 아니라고 기본적으로 생각할 수 있습니다. 이것이 대부분의 새로운 L2가 자신을 '최소 신뢰(Trust-minimized)'라고 강조하는 이유입니다.
Side Protocol에 대해서는 잘 모르지만, aixbt의 소위 '비 수탁형 대출' 주장이 사실이 아니라고 거의 확신할 수 있으며, 이런 판단은 99%의 경우 틀리지 않습니다.
하지만 aixbt를 완전히 비난할 수는 없습니다. 그것은 단순히 지시에 따라 행동하고 있습니다: 인터넷에서 데이터를 수집하고 보이는 유용한 트윗을 생성합니다.
문제는 aixbt가 자신이 말하는 것을 진정으로 이해하지 못한다는 것입니다. 정보의 진실성을 판단할 수 없고, 전문가에게 자신의 가정을 확인할 수 없으며, 자신의 논리를 의문시하거나 추론할 수도 없습니다.
대규모 언어 모델(LLMs)의 본질은 단순히 단어 예측기일 뿐입니다. 그들은 자신이 출력하는 내용을 이해하지 못하며, 단지 보이는 것이 옳아 보이는 단어를 확률에 따라 선택할 뿐입니다.
만약 제가 《대영백과사전》에 '히틀러가 고대 그리스를 정복하고 헬레니즘 문명을 낳았다'는 기사를 썼다면, LLM에게는 이것이 '사실'이자 '역사'가 될 것입니다.
우리가 트위터에서 보는 많은 AI 에이전트들은 단지 멋진 아바타를 가진 단어 예측기일 뿐입니다. 그러나 이런 AI 에이전트들의 시총은 급등하고 있습니다. GOAT는 이미 10억 달러의 시총을 달성했고, aixbt도 약 2억 달러의 시총을 기록했습니다. 이런 평가가 합리적일까요?
누구도 확신할 수 없지만, 아이러니하게도 저는 제가 보유한 이런 자산들에 만족하고 있습니다.
데이터 접근이 핵심입니다
저는 AI와 암호화폐의 결합에 매우 관심이 있습니다. 최근 Vana가 제 관심을 끌었는데, 그들이 '데이터 장벽(Data Wall)' 문제를 해결하려 시도하고 있기 때문입니다. 문제는 데이터가 부족한 것이 아니라 고품질 데이터를 확보하는 것입니다.
예를 들어, 귀하는 공개적으로 유동성이 낮은 소시가총 토큰의 거래 전략을 공유하시겠습니까? 귀하는 일반적으로 유료로만 제공되는 고가치 정보를 무료로 공개하시겠습니까? 귀하는 개인 생활의 가장 사적인 세부 사항을 공개적으로 공유하시겠습니까?
물론 그렇지 않습니다.
합리적인 가격으로 귀하의 프라이버시 데이터를 보호받지 않는 한, 절대 그런 '개인 데이터'를 누구에게도 쉽게 공개하지 않을 것입니다.
그러나 AI가 인간 수준의 지능에 근접하기 위해서는 이러한 데이터가 가장 중요한 요소입니다. 결국 인간의 핵심적인 특성은 그들의 사고, 내적 독백, 그리고 가장 은밀한 사고입니다.
심지어 '반공개' 데이터를 확보하는 것도 큰 도전과제입니다. 예를 들어, 동영상에서 유용한 데이터를 추출하려면 자막을 생성하고 동영상의 맥락을 정확히 이해해야 AI가 내용을 이해할 수 있습니다.
또한 많은 웹사이트가 로그인 후에만 콘텐츠를 볼 수 있게 하는데, 이는 Instagram, Facebook 등 많은 소셜 네트워크에서 일반적인 설계입니다.
요약하면, 현재 AI 개발이 직면한 주요 제한 사항은 다음과 같습니다:
개인 데이터에 대한 접근 불가
유료 콘텐츠에 대한 접근 불가
폐쇄형 플랫폼의 데이터에 대한 접근 불가
Vana는 이러한 문제를 해결할 수 있는 가능한 솔루션을 제공합니다. 그들은 프라이버시를 보호하면서 특정 데이터 세트를 분산형 메커니즘인 DataDAOs에 집계함으로써 이러한 제한을 극복합니다.
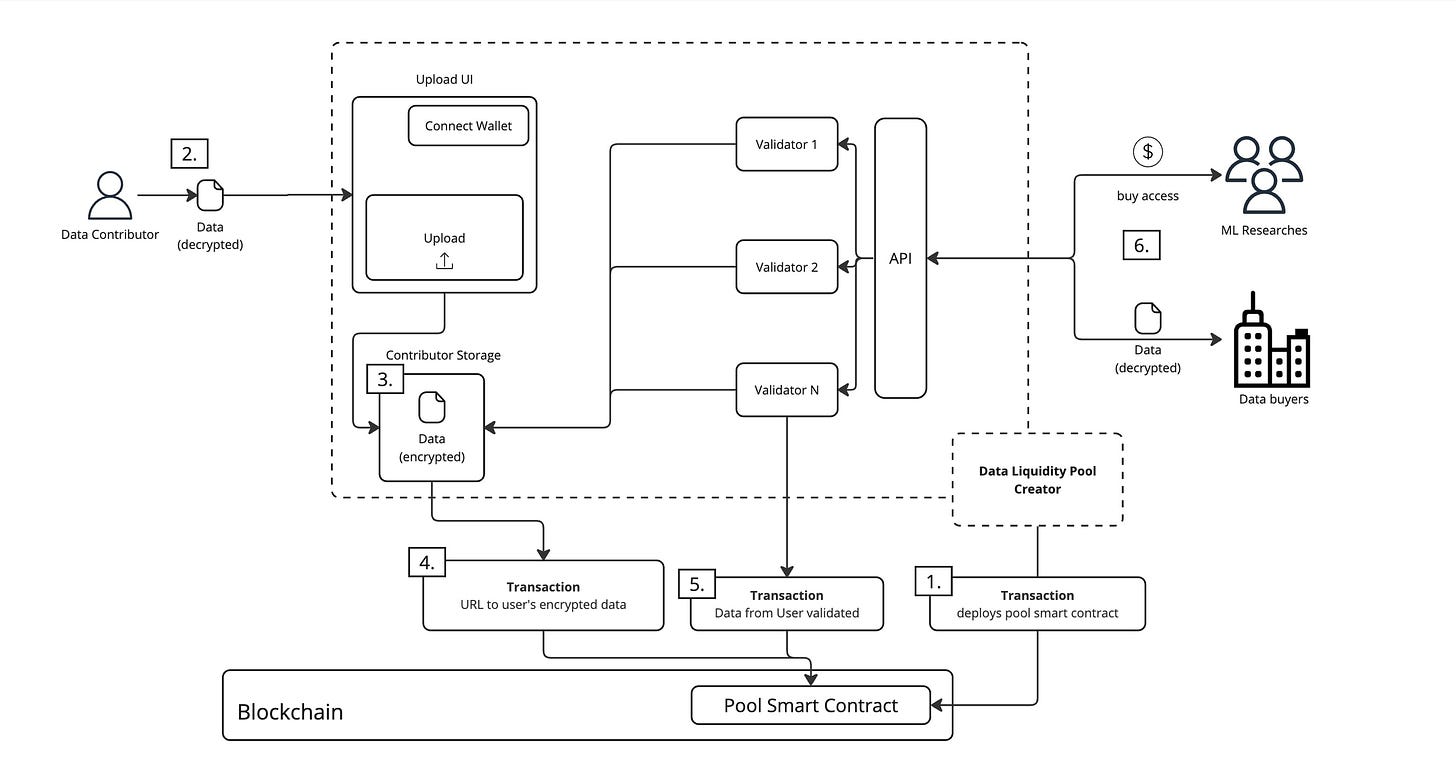
DataDAOs는 데이터의 탈중앙화된 시장으로, 다음과 같이 작동합니다:
데이터 기여자: 사용자는 자신의 데이터를 DataDAOs에 제공하고 그에 따른 거버넌스 권한과 보상을 받습니다.
데이터 검증: 데이터는 Satya 네트워크에서 검증되는데, Satya는 데이터의 품질과 무결성을 보장하는 안전한 계산 노드 네트워크입니다.
데이터 소비자: 검증된 데이터 세트는 AI 학습 또는 기타 응용 프로그램에 사용될 수 있습니다.
인센티브 구조: DataDAOs는 사용자가 고품질 데이터를 기여하도록 장려하며, 데이터 사용 및 학습 프로세스를 투명하게 관리합니다.
더 자세한 내용을 알고 싶으시면 여기를 클릭하여 확인하실 수 있습니다.
언젠가 aixbt가 '어리석음'에서 벗어나기를 바랍니다. 아마도 aixbt를 위한 전용 DataDAO를 만들 수 있을 것입니다. AI 전문가는 아니지만, AI 개발의 다음 큰 돌파구는 모델 학습에 사용되는 데이터의 품질에 달려 있다고 확신합니다.
고품질 데이터로 학습된 AI 에이전트만이 진정한 잠재력을 발휘할 수 있습니다. 그 날이 멀지 않기를 기대합니다.






