

인공지능이 자신의 "스푸트니크 순간"을 맞이했습니다.
지난주, 중국의 대형 언어 모델(LLM) 스타트업 DeepSeek이 조용히 운영되다 공식적으로 등장하여 미국 시장을 놀라게 했습니다.
DeepSeek은 ChatGPT 등 다른 LLM보다 더 빠르고 지능적이며 자원 사용량이 적습니다. 콘텐츠 창작이나 기본 검색에서도 이전 모델보다 훨씬 빠릅니다. 더 중요한 것은 이 모델이 "자율적 사고" 능력을 갖추고 있어 이전 모델보다 훈련 비용이 더 낮다고 알려져 있습니다.
들리기에는 굉장하지 않습니까? 하지만 미국 AI 산업에 투자한 기술 기업이라면 그렇지 않을 수 있습니다. 시장은 월요일 이 진전에 격렬하게 반응했습니다. 기술주가 집단적으로 폭락하여 시가총액이 1조 달러 이상 증발했는데, 이는 비트코인 시가총액의 절반에 해당합니다. 이 중 엔비디아(Nvidia) 주가는 하루 만에 17% 폭락하며 5,890억 달러의 시가총액 손실을 기록했는데, 이는 미국 주식 시장 역사상 최대 단일 거래일 시가총액 손실입니다. 엔비디아와 다른 기술주의 하락으로 나스닥 종합지수도 3.1% 하락했습니다.
시장의 매도 압력은 기술주에 국한되지 않았습니다. 에너지주도 큰 타격을 받았는데, 텍사스에 대규모 사업을 운영하는 천연가스, 원자력 및 재생 에너지 기업 Vistacorp의 주가가 약 30% 폭락했고, 마이크로소프트 데이터 센터에 전력을 공급하기 위해 쓰리마일 섬 원전을 재가동 중인 Constellation Energy의 주가도 20% 이상 하락했습니다.
시장이 DeepSeek에 대해 우려하는 점은 간단합니다. LLM의 계산 효율성 향상 속도가 예상을 크게 웃돌면서 GPU, 데이터 센터 및 에너지에 대한 수요가 줄어들 것이라는 것입니다. 흥미롭게도 이 모델이 폭발적으로 인기를 끈 시점은 전 대통령 트럼프가 5,000억 달러 규모의 "스타게이트 프로젝트"를 발표한 지 며칠 후였습니다. 이 프로젝트는 미국의 AI 인프라 구축을 가속화하는 것을 목표로 합니다.
DeepSeek의 영향에 대해 전문가들의 의견은 엇갈립니다. 일부는 이것이 AI 산업의 중대한 호재이지 재앙이 아니라고 생각합니다. 내연기관 효율성 향상이 자동차 수요를 줄이지 않고 오히려 산업 성장을 이끌었듯이 말입니다.
반면 소셜미디어에 퍼진 DeepSeek 훈련 비용 데이터는 오해의 소지가 있을 수 있습니다. 새로운 모델이 비용을 줄였지만, 소문만큼 극적이지는 않습니다.
DeepSeek 알아보기
DeepSeek은 2023년 5월 중국 엔지니어 Liang Wenfeng이 설립했으며, 2016년 그가 설립한 회사에 투자한 헤지펀드 High-Flyer로부터 투자를 받았습니다. DeepSeek은 1월 20일 첫 번째 모델 DeepSeek-R1을 오픈소스로 공개했고, 지난 주말 갑자기 인기를 끌었습니다.
DeepSeek-R1은 다음과 같은 독특한 기능을 갖추고 있어 다른 모델과 구별됩니다:
- 의미 이해: DeepSeek은 "이면의 의미를 읽어낼" 수 있는 능력을 갖추고 있습니다. 의미 임베딩 기술을 사용하여 질문의 의도와 더 깊은 맥락을 추론하여 더 세부적인 답변을 제공합니다.
- 멀티모달 검색: 텍스트, 이미지, 동영상, 오디오 등 다양한 유형의 미디어 콘텐츠를 분석하고 교차 참조할 수 있습니다.
- 자동 적응: DeepSeek은 지속적으로 학습하고 자체 훈련할 수 있습니다. 입력 데이터가 많아질수록 적응력이 높아져 정기적인 재훈련 없이도 안정적으로 작동할 수 있습니다.
- 대용량 데이터 처리: PB(페타바이트) 수준의 데이터를 처리할 수 있다고 알려져 있어, 다른 LLM이 다루기 어려운 거대 데이터셋도 처리할 수 있습니다.
- 더 적은 매개변수: DeepSeek-R1의 총 매개변수 수는 671억 개이지만, 추론 시 370억 개의 매개변수만 사용합니다. 반면 ChatGPT는 추론 시 5,000억 개에서 1,000억 개 사이의 매개변수를 사용하는 것으로 추정됩니다(OpenAI는 정확한 수치를 공개하지 않았습니다).
이러한 특징 외에도 DeepSeek의 가장 매력적인 점은 자기 조정 및 자율 학습 능력입니다. 이 기능은 시간과 자원을 절약할 뿐만 아니라 로봇, 자율 주행, 물류 등 자율 AI 시스템에 활용될 수 있는 기반을 마련합니다.
Pastel의 창립자이자 CEO인 Jeffrey Emmanuel은 "엔비디아 주식 숏 포지션 이유"라는 글에서 이 혁신에 대해 다음과 같이 요약했습니다:
"R1을 통해 DeepSeek은 AI 분야의 '성배'라고 할 수 있는 과제, 즉 대규모 감독 데이터셋 없이도 점진적 추론을 달성했습니다. DeepSeek-R1-Zero 실험은 놀라운 성과를 보여줍니다. 강화 학습과 정교하게 설계된 보상 함수를 통해 모델이 복잡한 추론 능력을 완전히 자율적으로 개발했습니다. 이는 단순히 문제를 해결하는 것 이상입니다. 모델이 자연스럽게 장기 추론 과정을 생성하고 자체 검증하며, 더 어려운 문제를 처리할 때 더 많은 계산 자원을 할당할 수 있습니다."
DeepSeek이 월가를 공포에 떨게 한 진짜 이유
DeepSeek은 확실히 ChatGPT의 강화된 버전이지만, 지난주 금융계를 충격에 빠뜨린 진짜 이유는 이것이 아닙니다. 투자자들을 공포에 떨게 한 진짜 이유는 이 모델의 훈련 비용입니다.
DeepSeek 팀은 이 모델의 훈련 비용이 560만 달러에 불과하다고 주장했습니다. 하지만 이 데이터의 신뢰성은 의문시됩니다.
GPU 시간(즉, 각 GPU의 시간당 계산 비용)을 기준으로 보면, DeepSeek 팀은 2,048개의 엔비디아 H800 GPU를 사용했고, 총 278.8만 GPU 시간이 소요되었으며, 사전 훈련, 문맥 확장 및 후속 훈련에 약 2달러/GPU 시간의 비용이 들었다고 주장합니다.
반면 OpenAI CEO 샘 알트만(Sam Altman)은 GPT-4의 훈련 비용이 1억 달러를 넘었다고 밝혔습니다. GPT-4 훈련에는 90-100일이 소요되었고, 25,000개의 엔비디아 A100 GPU가 사용되었으며, 총 5,400만-6,000만 GPU 시간이 소요되었고, 시간당 계산 비용은 약 2.50-3.50달러/GPU 시간이었습니다.
따라서 DeepSeek의 훈련 비용 "가격표"가 OpenAI에 비해 크게 낮아 시장에 공포감을 불러일으켰습니다. 투자자들은 DeepSeek이 OpenAI의 훈련 비용 일부로도 더 강력한 LLM을 만들어냈다면, 우리는 왜 미국에서 수십억 달러를 들여 AI 계산 인프라를 구축해야 하는지 의문을 제기하고 있습니다. 이른바 "필수적"인 컴퓨팅 파워 투자가 과연 의미가 있을까요? AI/HPC 데이터 센터에 대한 투자 수익률(ROI)과 수익 모델은 어떻게 될까요?
아래 차트는 DeepSeek과 ChatGPT 훈련에 필요한 데이터 센터 GW당 수익을 보여줌으로써 이 문제를 더 잘 보여줍니다.
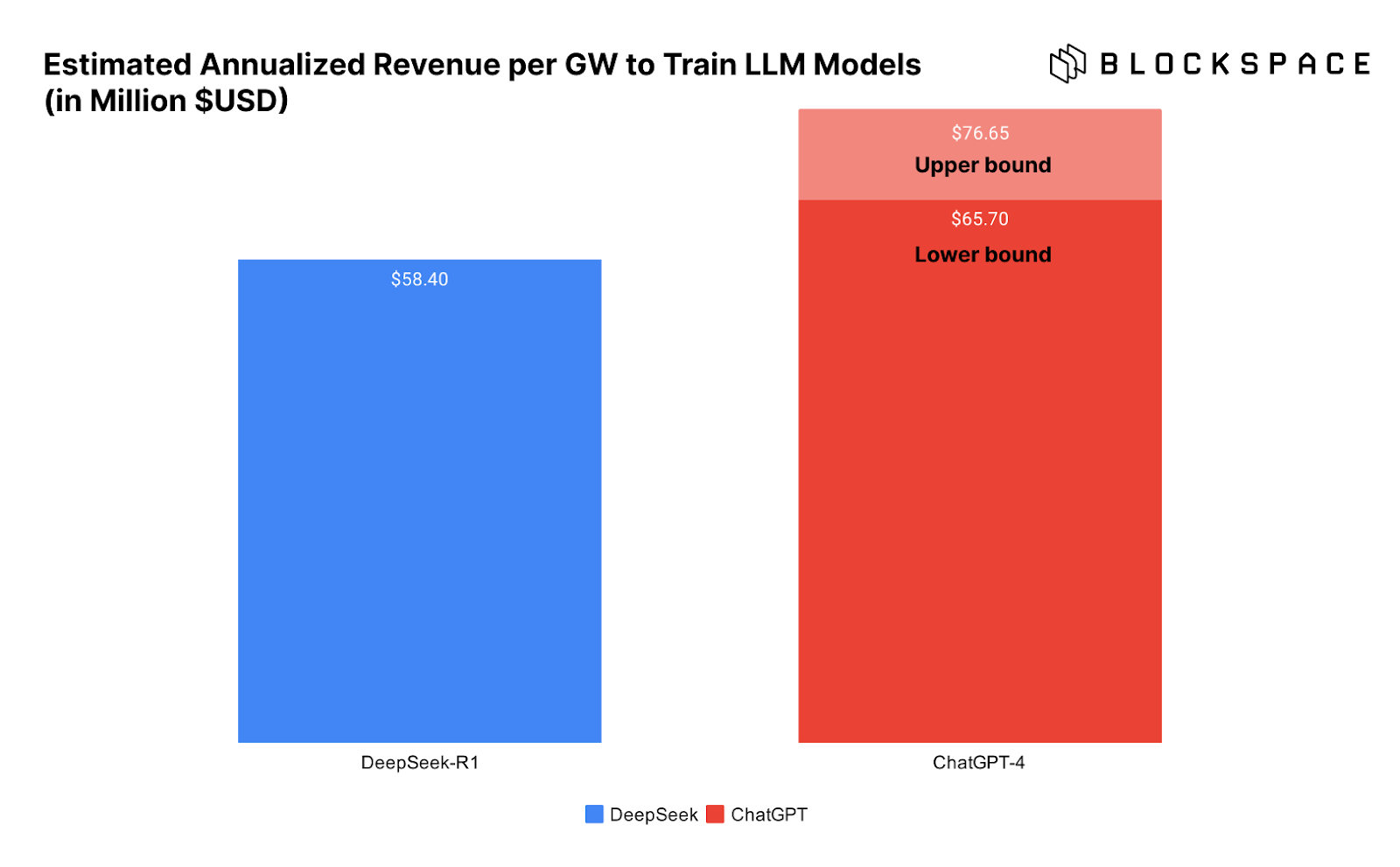
문제는 DeepSeek이 정말로 그렇게 낮은 비용으로 모델 훈련을 완료했는지 확실하지 않다는 것입니다.
DeepSeek의 훈련 비용이 정말 그렇게 낮을까?
그렇다면 DeepSeek은 정말 560만 달러만으로 모델을 훈련했을까요? 업계 관계자들 사이에서 이에 대한 의문이 제기되고 있으며, 그 이유는 충분합니다.
먼저 DeepSeek의 기술 백서에서 팀은 "언급된 훈련 비용은 DeepSeek-V3의 공식 훈련만을 포함하며, 이전 모델 아키텍처, 알고리즘 또는 데이터에 대한 연구와 실험 비용은 포함되지 않는다"고 명시했습니다. 즉, 560만 달러는 최종 훈련 비용일 뿐, 모델 최적화 과정에서 더 많은 자금이 투입되었다는 것입니다.
따라서 Atreides Management의 CIO 가번 베이커는 "560만 달러의 비용 데이터는 매우 오해의 소지가 있다"고 직언했습니다.
"换句话说,如果一个实验室已经在前期研究上投入了数亿美元,并且拥有更大规模的计算集群,那么确实可以用 560 万美元完成最终训练。但 DeepSeek 显然不止使用了 2,048 块 H800 GPU——他们早期的一篇论文就提到了一个由 10,000 块 A100 组成的集群。因此,一个同样优秀的团队如果想要从零开始,仅凭 2,000 块 GPU 训练出类似 R1 的模型,根本不可能只花 560 万美元。"
此外,贝克指出,DeepSeek 采用了一种名为"知识蒸馏"(distillation)的方法,从 ChatGPT 汲取经验来训练自己的模型。
"DeepSeek 很可能无法在没有 GPT-4o 和 GPT-4o1 完全开放访问的情况下完成训练。"
DeepSeek、能源消耗与杰文斯悖论
尽管 DeepSeek 训练成本仅为 560 万美元的说法存疑,但加文·贝克(Gavin Baker)指出,该模型的多项突破——如自学习、参数更少等——确实使其训练和推理(即 AI 运行成本,行业术语称之为"推理")变得更加低廉。
贝克声称,使用 DeepSeek-R1 的成本比 ChatGPT 的 o1 版本低 93%,每次 API 调用的费用大幅下降。尽管 93% 这一具体数字是否准确仍有争议,但关键在于,DeepSeek 的推理成本更低,甚至可以在 Mac Studio Pro 等本地硬件上运行。
这才是 DeepSeek 的真正突破——AI 变得更加经济可用。正如一位匿名评论者所说,这感觉就像微软开源了互联网浏览器,从而彻底摧毁了 Netscape 的付费访问模式。
DeepSeek 彻底打开了 AI 的新模式,使 AI 发展进入了一个全新的竞争阶段——"现在的竞争重点已经从 AI 训练转向 AI 推理",借用 Chamath Palihapitiya 的话来说。
AI 驱动的数据中心与电力行业热潮何去何从?
正如我们在文章前面所提到的,更高效的发动机是否减少了汽油需求,或者对依赖汽车的行业造成了负面影响?
杰文斯悖论(Jevons Paradox)认为,当技术进步提升了资源利用效率时,资源本身的需求反而会上升,因为更低的成本会促使更广泛的应用。比特币矿工对此深有体会——尽管 ASIC 矿机的能效逐年提升,但比特币网络的算力仍然持续增长。
从目前来看,市场迎来了一个更强大的竞争者,但游戏规则并未改变。如果 AI 推理和训练成本下降(而这本就是必然趋势),那么它将解锁更多应用场景,并进一步推动 AI 产业需求增长。






