

저자: 강신령,AI를 위한 전력

이미지 출처: 무한 AI에 의해 생성됨
DeepSeek는 어떻게 R1 추론 모델을 학습시켰는가?
이 글은 DeepSeek가 발표한 기술 보고서를 바탕으로 DeepSeek - R1의 학습 과정을 해석합니다. 추론 모델 구축 및 향상을 위한 4가지 전략을 중점적으로 다룹니다.
원문은 연구원 Sebastian Raschka가 작성하여 다음 사이트에 게재되었습니다:
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
이 글에서는 R1 추론 모델의 핵심 학습 부분을 요약합니다.
먼저 DeepSeek가 발표한 기술 보고서를 바탕으로 R1의 학습 과정을 나타낸 그림이 있습니다.
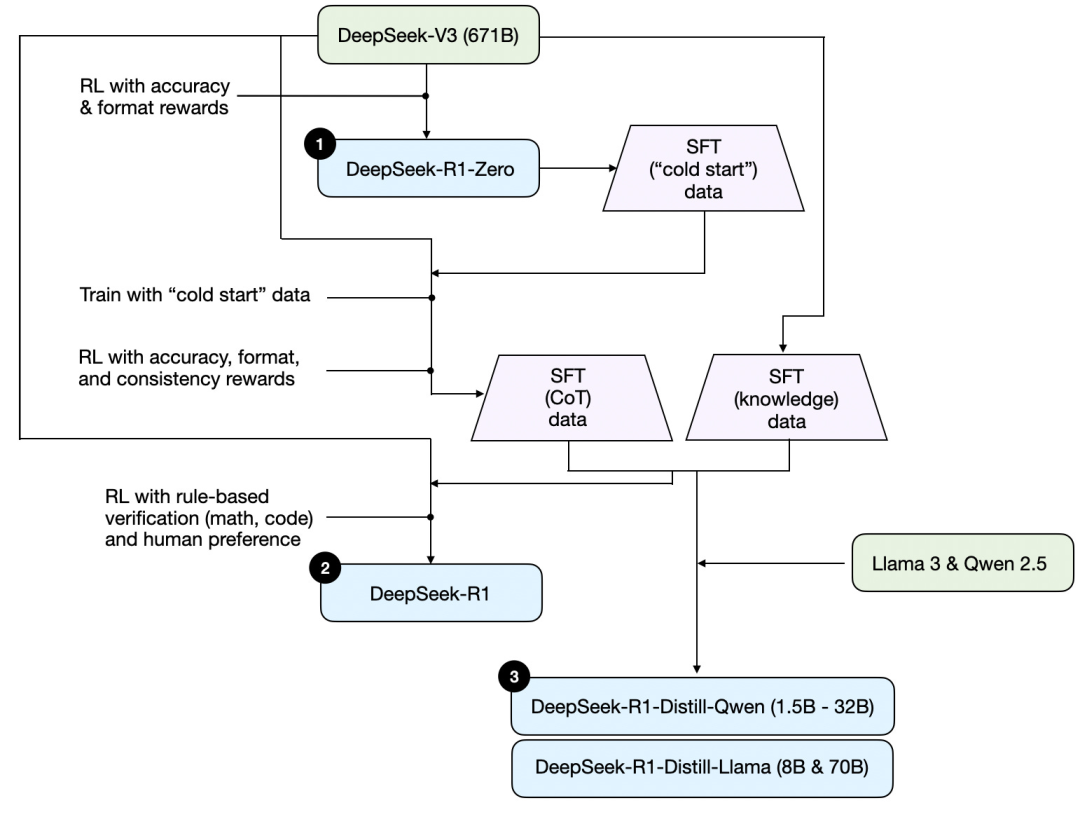
위 그림의 과정을 정리하면 다음과 같습니다:
(1) DeepSeek - R1 - Zero: 이 모델은 지난해 12월 공개된 DeepSeek - V3 기반 모델을 토대로 합니다. 두 가지 보상 메커니즘을 가진 강화 학습(RL)으로 학습시켰습니다. 이는 감독 미세 조정(SFT) 단계가 없는 "콜드 스타트" 학습 방식입니다. 일반적으로 SFT는 인간 피드백 강화 학습(RLHF)의 일부입니다.
(2) DeepSeek - R1: 이는 DeepSeek의 주력 추론 모델로, DeepSeek - R1 - Zero를 기반으로 구축되었습니다. 팀은 추가적인 감독 미세 조정 단계와 강화 학습 훈련을 통해 "콜드 스타트" R1 - Zero 모델을 개선했습니다.
(3) DeepSeek - R1 - Distill: DeepSeek 팀은 이전 단계에서 생성된 감독 미세 조정 데이터를 활용하여 Qwen과 Llama 모델을 Fine Tuning하여 추론 능력을 강화했습니다. 이는 전통적인 증류(Distillation)는 아니지만, 671B 규모의 DeepSeek - R1 모델의 출력을 활용하여 더 작은 Llama 8B, 70B 및 Qwen 1.5B - 30B 모델을 학습시켰습니다.
다음에서는 추론 모델 구축 및 향상을 위한 4가지 주요 방법을 소개합니다.
1. 추론 시 확장 / Inference-time scaling
LLM의 추론 능력(또는 일반적인 능력)을 높이는 한 가지 방법은 추론 시 확장입니다. 즉, 추론 과정에서 계산 자원을 늘려 출력 품질을 높이는 것입니다.
비유하자면, 사람이 복잡한 문제를 더 오랫동안 생각할수록 더 좋은 답변을 할 수 있는 것과 같습니다. 마찬가지로 LLM이 답변을 생성할 때 "더 깊이 생각"하도록 하는 기술을 활용할 수 있습니다.
추론 시 확장을 구현하는 한 가지 간단한 방법은 프롬프트 엔지니어링입니다. 대표적인 예가 사고 과정 프롬프트(CoT Prompting)로, 입력 프롬프트에 "단계적으로 생각하라"와 같은 문구를 추가합니다. 이를 통해 모델이 최종 답변을 바로 생성하는 것이 아니라 중간 추론 단계를 생성하게 되며, 더 복잡한 문제에서 더 정확한 결과를 얻을 수 있습니다. (단, "프랑스의 수도는 무엇인가?"와 같은 비교적 단순한 지식 기반 질문에는 이 전략이 적합하지 않습니다. 이는 주어진 입력 쿼리에 대해 추론 모델이 적합한지 판단할 수 있는 실용적인 경험 법칙입니다.)

위에서 설명한 사고 과정(CoT) 방법은 추론 시 확장으로 간주할 수 있습니다. 더 많은 출력 토큰을 생성함으로써 추론 비용을 늘리기 때문입니다.
추론 시 확장의 다른 방법은 투표 및 검색 전략을 사용하는 것입니다. 간단한 예로 다수결 투표법을 들 수 있습니다. 즉, LLM에게 여러 개의 답변을 생성하게 한 후 다수결로 정답을 선택하는 것입니다. 또한 빔 검색 및 기타 검색 알고리즘을 사용하여 더 나은 답변을 생성할 수 있습니다.
이와 관련하여 《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters》 논문을 추천합니다.
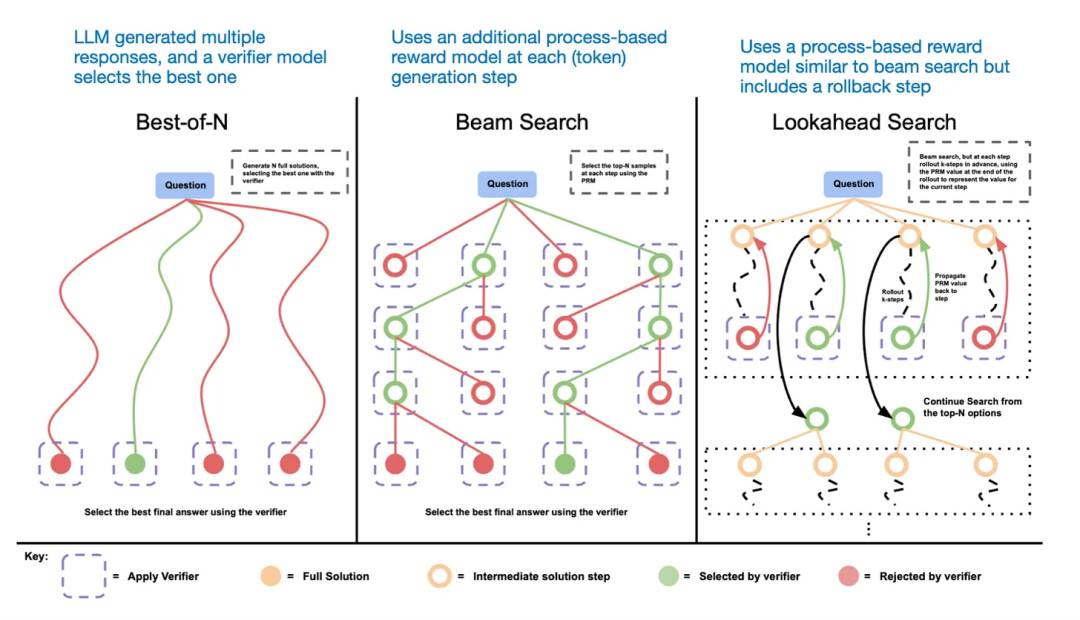
다양한 검색 기반 방법은 프로세스 보상 기반 모델을 활용하여 최적의 답변을 선택합니다.
DeepSeek R1 기술 보고서에 따르면 해당 모델은 추론 시 확장 기술을 사용하지 않았습니다. 그러나 이 기술은 일반적으로 LLM 위의 응용 계층에서 구현되므로, DeepSeek가 자사 애플리케이션에서 이 기술을 사용했을 가능성이 있습니다.
추측컨대 OpenAI의 o1 및 o3 모델은 추론 시 확장 기술을 사용했을 것 같습니다. 이는 GPT-4o와 같은 모델에 비해 상대적으로 높은 사용 비용을 설명할 수 있습니다. o1과 o3은 DeepSeek R1과 유사한 강화 학습 프로세스를 통해 학습되었을 가능성이 높습니다.
2. 순수 강화 학습 / Pure RL
DeepSeek R1 논문에서 특히 주목할 만한 점은 추론 능력이 순수 강화 학습에서 자연스럽게 발현될 수 있다는 것입니다. 이것이 무엇을 의미하는지 살펴보겠습니다.
앞서 언급했듯이, DeepSeek는 3가지 R1 모델을 개발했습니다. 첫 번째는 DeepSeek - R1 - Zero로, DeepSeek - V3 기반 모델을 토대로 합니다. 일반적인 강화 학습 프로세스와 달리, 보통 강화 학습 전에 감독 미세 조정(SFT)이 수행되지만, DeepSeek - R1 - Zero는 순수 강화 학습으로만 학습되었으며 초기 SFT 단계가 없습니다. 다음 그림을 참고하세요.
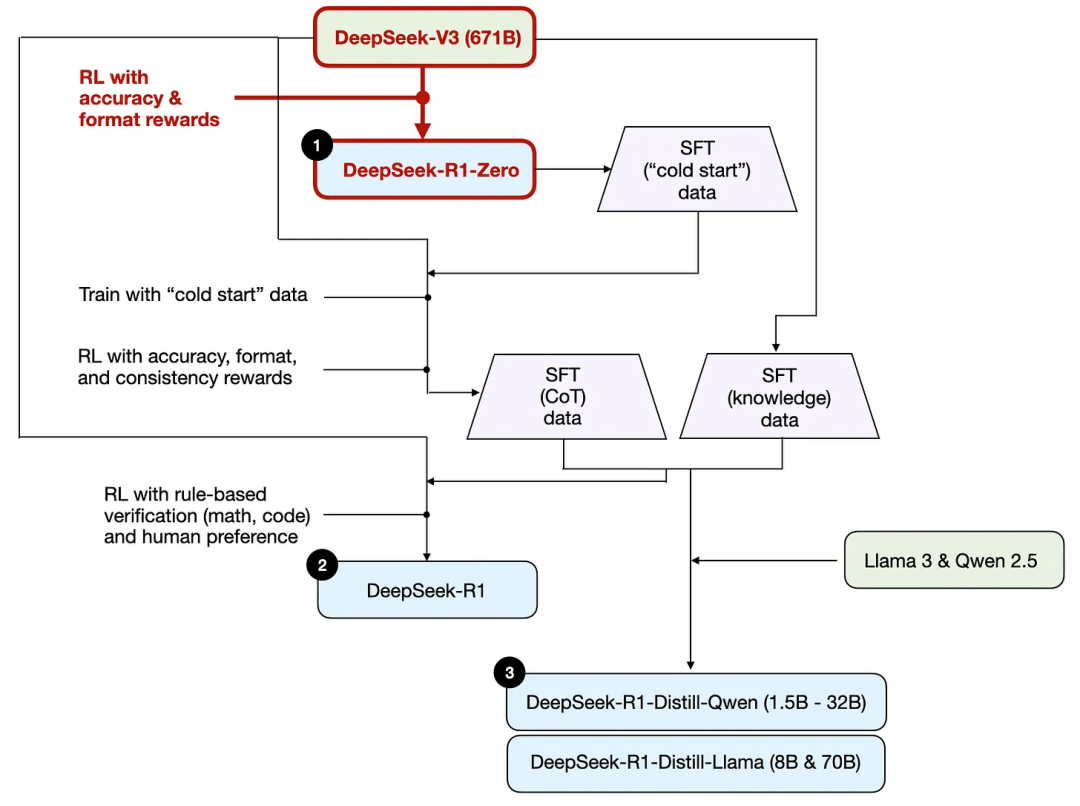
그럼에도 불구하고, 이 강화 학습 프로세스는 LLM의 선호도 미세 조정에 일반적으로 사용되는 인간 피드백 강화 학습(RLHF) 방법과 유사합니다. 그러나 앞서 언급했듯이, DeepSeek - R1 - Zero의 핵심 차이점은 지시 조정을 위한 감독 미세 조정(SFT) 단계를 생략했다는 것입니다. 이것이 그들이 "순수" 강화 학습이라고 부르는 이유입니다.
보상 측면에서, 그들은 인간 선호도 기반 보상 모델을 사용하지 않고 두 가지 보상 유형을 사용했습니다: 정확성 보상과 형식 보상.
정확성 보상 / accuracy reward는 LeetCode 컴파일러를 사용하여 프로그래밍 답변의 정확성을 검증하고, 결정론적 시스템을 사용하여 수학 답변을 평가합니다.
형식 보상 / format reward는 LLM 평가기를 활용하여 답변이 예상 형식을 따르도록 합니다. 예를 들어 추론 단계를 라벨 내에 배치하는 것 등입니다.
놀랍게도 이러한 방법만으로도 LLM이 기본적인 추론 기술을 발전시킬 수 있었습니다. 연구진은 모델이 자신의 답변에 추론 과정을 생성하기 시작하는 "아하" 순간을 관찰했는데, 이는 명시적인 관련 학습이 없었음에도 불구하고 일어났습니다. 다음 그림은 R1 기술 보고서에서 발췌한 것입니다.

R1 - Zero가 최고의 추론 모델은 아니지만, 위 그림에서 볼 수 있듯이 중간 "사고" 단계를 생성하며 추론 능력을 보여주었습니다. 이는 순수 강화 학습을 통해 추론 모델을 개발할 수 있다는 것을 증명했으며, DeepSeek가 이를 최초로 보여준(또는 적어도 관련 성과를 발표한) 팀입니다.
3. 감독 미세 조정과 강화 학습(SFT + RL)
이제 DeepSeek의 주력 추론 모델인 DeepSeek - R1의 개발 과정을 살펴보겠습니다. 이는 추론 모델 구축의 교과서적인 사례라고 할 수 있습니다. 이 모델은 DeepSeek - R1 - Zero를 기반으로 하며, 추가적인 감독 미세 조정(SFT)과 강화 학습(RL)을 통해 추론 성능을 향상시켰습니다.
주목할 점은 강화 학습 전에 감독 미세 조정 단계를 추가한 것인데, 이는 표준 인간 피드백 강화 학습(RLHF) 프로세스에서 일반적으로 볼 수 있는 방식입니다. OpenAI의 o1 모델도 유사한 방법으로 개발되었을 것으로 추정됩니다.
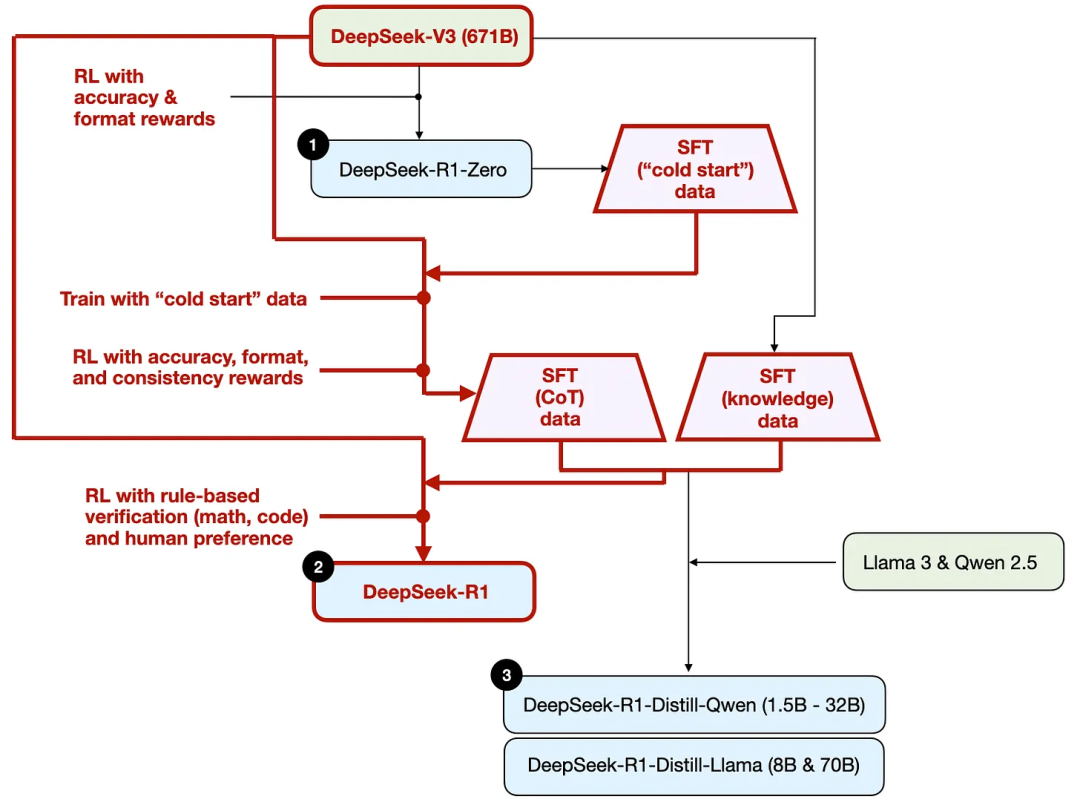
위 그림에 나와 있듯이, DeepSeek 팀은 DeepSeek - R1 - Zero를 활용하여 그들이 "콜드 스타트" 감독 미세 조정(SFT) 데이터라고 부르는 데이터를 생성했습니다.
그런 다음 이 60만 + 20만 개의 SFT 샘플이 DeepSeek - V3 기본 모델의 지침 미세 조정/instruction finetuning을 위해 사용되었으며, 그 후 마지막 RL 라운드가 수행되었습니다. 이 단계에서 수학 및 프로그래밍 문제의 경우 정확성 보상을 결정하기 위해 다시 규칙 기반 방법을 사용했으며, 다른 유형의 문제의 경우 인간 선호도 레이블을 사용했습니다. 전반적으로 이는 일반적인 인간 피드백 강화 학습(RLHF)과 매우 유사하지만 SFT 데이터에 (더 많은) 사고 체인 예시가 포함되어 있다는 점이 다릅니다. 또한 RL에는 인간 선호도 기반 보상 외에도 검증 가능한 보상이 있습니다.
최종 모델 DeepSeek - R1은 추가 SFT 및 RL 단계로 인해 DeepSeek - R1 - Zero에 비해 상당한 성능 향상을 보였습니다.
4. 순수 감독 미세 조정(SFT) 및 증류
지금까지 우리는 추론 모델 구축 및 개선을 위한 세 가지 핵심 방법을 소개했습니다:
1/ 추론 시 확장 - 기저 모델을 훈련하거나 달리 수정하지 않고도 추론 능력을 높일 수 있는 기술입니다.
2/ 순수 RL - DeepSeek - R1 - Zero에서 사용된 순수 강화 학습(RL)으로, 추론이 감독 미세 조정 없이도 습득 가능한 행동으로 나타날 수 있음을 보여줍니다.
3/ 감독 미세 조정(SFT) + 강화 학습(RL) - 이를 통해 DeepSeek의 추론 모델 DeepSeek - R1이 생성되었습니다.
남은 것은 - 모델 "증류"입니다. DeepSeek는 또한 그들이 증류 프로세스라고 부르는 것을 통해 훈련된 더 작은 모델을 출시했습니다. LLM 컨텍스트에서 증류는 반드시 딥러닝에서 사용되는 고전적인 지식 증류 방법을 따르지 않습니다. 전통적으로 지식 증류에서는 더 작은 "학생" 모델이 더 큰 "교사" 모델의 논리적 출력과 대상 데이터 세트에 대해 훈련됩니다.
그러나 여기서의 증류는 더 큰 LLM이 생성한 감독 미세 조정(SFT) 데이터 세트에서 더 작은 LLM(예: Llama 8B 및 70B 모델, Qwen 2.5B(0.5B - 32B))에 대한 지침 미세 조정/instruction finetuning을 의미합니다. 구체적으로 말하면, 이러한 더 큰 LLM은 DeepSeek - V3 및 DeepSeek - R1의 중간 체크포인트입니다. 사실, 이 증류 프로세스에 사용된 감독 미세 조정 데이터/SFT 데이터는 이전 섹션에서 설명한 DeepSeek - R1 훈련에 사용된 데이터 세트와 동일합니다.
이 프로세스를 설명하기 위해 아래 그림에서 증류 부분을 강조했습니다.
그들은 왜 이러한 증류 모델을 개발했을까요? 두 가지 핵심 이유가 있습니다:
1/ 더 작은 모델은 효율성이 더 높습니다. 즉, 운영 비용이 더 낮고 저사양 하드웨어에서도 실행할 수 있어 많은 연구자와 애호가들에게 특히 매력적입니다.
2/ 순수 감독 미세 조정(SFT)의 사례 연구. 이러한 증류 모델은 강화 학습 없이 순수 감독 미세 조정만으로 모델이 어느 수준까지 달성할 수 있는지를 보여주는 흥미로운 벤치마크입니다.
아래 표는 이러한 증류 모델의 성능을 다른 인기 모델과 DeepSeek - R1 - Zero 및 DeepSeek - R1과 비교합니다.
우리가 보듯이, 증류 모델은 DeepSeek - R1보다 몇 배 작지만 DeepSeek - R1 - Zero보다 훨씬 강력합니다. 그러나 DeepSeek - R1에 비해서는 약합니다. 또한 o1 - mini와 비교해 볼 때, 이 모델들의 성능도 꽤 좋습니다(o1 - mini 자체가 o1의 유사한 증류 버전일 수 있다고 의심됩니다).
언급할 만한 또 다른 흥미로운 비교가 있습니다. DeepSeek 팀은 DeepSeek - R1 - Zero에서 나타난 돌발적인 추론 행동이 더 작은 모델에서도 나타나는지 테스트했습니다. 이를 연구하기 위해 그들은 DeepSeek - R1 - Zero에서 사용된 동일한 순수 강화 학습 방법을 Qwen - 32B에 직접 적용했습니다.
아래 표는 이 실험 결과를 요약한 것으로, QwQ - 32B - Preview는 Qwen 팀이 개발한 Qwen 2.5 32B 기준 추론 모델입니다. 이 비교는 순수 강화 학습만으로도 DeepSeek - R1 - Zero보다 훨씬 작은 모델에서 추론 능력을 유도할 수 있는지에 대한 추가 통찰을 제공합니다.
흥미롭게도 결과는 더 작은 모델의 경우 증류가 순수 강화 학습보다 훨씬 효과적임을 보여줍니다. 이는 순수 강화 학습만으로는 이러한 규모의 모델에서 강력한 추론 능력을 유도하기에 충분하지 않을 수 있으며, 작은 모델을 다룰 때 고품질 추론 데이터에 대한 감독 미세 조정이 더 효과적인 전략일 수 있다는 견해와 일치합니다.
결론
우리는 추론 모델 구축 및 개선을 위한 네 가지 다른 전략을 살펴보았습니다:
추론 시 확장: 추가 훈련 없이도 성능을 높일 수 있지만 추론 비용이 증가합니다. 사용자 수나 쿼리 볼륨이 늘어나면 대규모 배포 비용이 더 높아질 수 있습니다. 그러나 기존 강력한 모델의 성능을 높이는 데에는 여전히 간단하고 효과적인 방법입니다. o1이 추론 시 확장을 활용했을 것이라고 강력히 의심되며, 이는 o1이 DeepSeek - R1보다 토큰 생성 비용이 더 높은 이유를 설명합니다.
순수 강화 학습 Pure RL: 연구 관점에서 매우 흥미로운데, 추론이 출현 행동으로 어떻게 학습되는지 깊이 있게 이해할 수 있기 때문입니다. 그러나 실제 모델 개발에서는 감독 미세 조정과 강화 학습의 결합(RL + SFT)이 더 나은 선택이 되는데, 이 방식으로 더 강력한 추론 모델을 구축할 수 있기 때문입니다. o1 역시 RL + SFT를 통해 훈련되었다고 강력히 의심됩니다. 더 정확히 말하면, o1은 DeepSeek - R1보다 약하고 규모가 더 작은 기본 모델에서 시작했지만 RL + SFT와 추론 시 확장을 통해 격차를 메웠을 것입니다.
앞서 설명한 바와 같이, RL + SFT는 고성능 추론 모델 구축의 핵심 방법입니다. DeepSeek - R1은 이 목표를 달성하는 훌륭한 청사진을 보여줍니다.
증류: 특히 더 작고 효율적인 모델을 만드는 데 매력적인 방법입니다. 그러나 한계는 증류가 혁신을 추동하거나 차세대 추론 모델을 생성할 수 없다는 것입니다. 예를 들어 증류는 항상 기존의 더 강력한 모델에 의해 생성된 감독 미세 조정(SFT) 데이터에 의존합니다.
다음으로 기대되는 흥미로운 방향은 RL + SFT(방법 3)와 추론 시 확장(방법 1)을 결합하는 것입니다. 이것이 바로 OpenAI의 o1이 하고 있는 것일 가능성이 높으며, 단지 o1이 DeepSeek - R1보다 약한 기본 모델을 기반으로 하고 있어 DeepSeek - R1이 추론 성능이 뛰어나면서도 비용이 상대적으로 낮은 것으로 보입니다.




