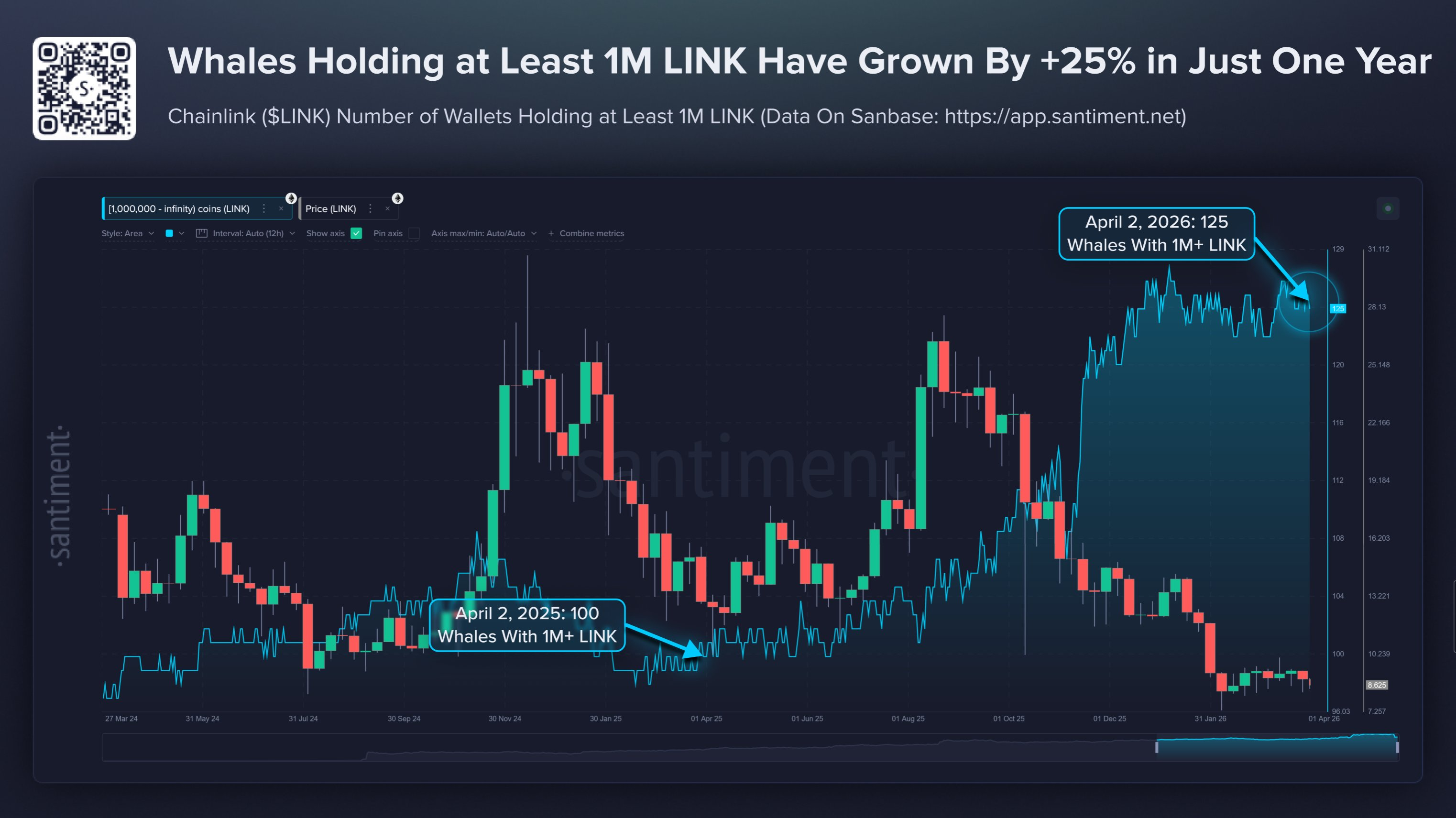
저자: 헝위 - 아우페이스에서

이미지 출처: 무한 AI에 의해 생성됨
방금, 점프 스타 연합과 지리 자동차 그룹이 두 개의 멀티모달 대규모 모델을 오픈 소스화했습니다!
새로운 모델은 2개입니다:
전 세계 최대 규모의 오픈 소스 비디오 생성 모델 Step-Video-T2V
업계 최초의 제품급 오픈 소스 음성 대화 대규모 모델 Step-Audio
멀티모달 강자가 멀티모달 모델을 오픈 소스화하기 시작했으며, Step-Video-T2V는 가장 개방적이고 관대한 MIT 오픈 소스 라이선스를 사용하여 자유롭게 편집하고 상업적으로 활용할 수 있습니다.
(GitHub, 아바이 페이스, 마도 직통차는 문말 참조)
두 개의 대규모 모델 개발 과정에서 양측은 컴퓨팅 파워, 알고리즘, 시나리오 학습 등 분야에서 상호 보완적인 우위를 발휘하여 "멀티모달 대규모 모델의 성능을 크게 향상시켰습니다".
공식 기술 보고서에 따르면, 이번에 오픈 소스화된 두 모델은 벤치마크에서 우수한 성능을 보였으며 국내외 동종 오픈 소스 모델을 능가합니다.
아바이 페이스 공식도 중국 지역 책임자의 높은 평가를 전달했습니다.
핵심은 "The next DeepSeek", "HUGE SoTA"입니다.
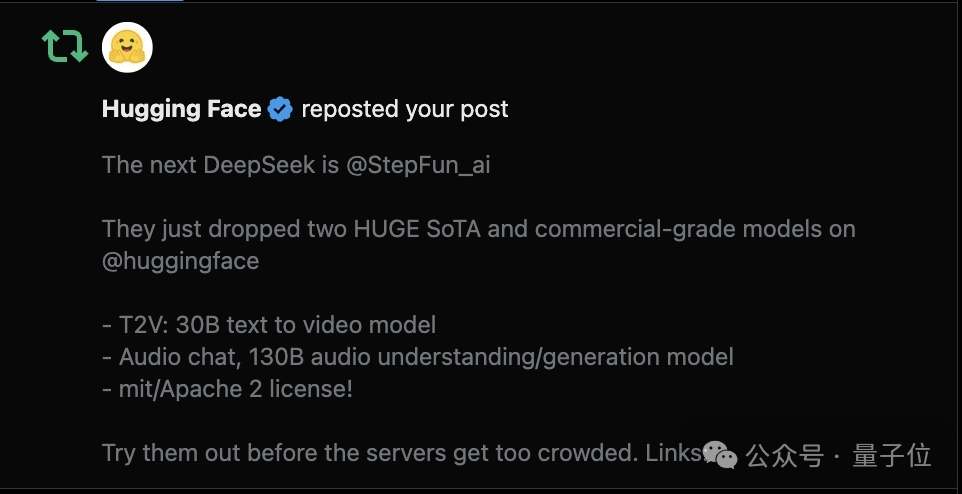
그렇습니까?
그렇다면 Qbitai는 이 기사에서 기술 보고서와 직접 테스트를 통해 그들이 실제로 그 이름에 걸맞은지 확인해 보겠습니다.

Qbitai가 검증한 바로는, 현재 이 2개의 새로운 오픈 소스 모델이 모두 Yuewen App에 탑재되어 누구나 경험할 수 있습니다.
멀티모달 강자가 처음으로 멀티모달 모델을 오픈 소스화했습니다
Step-Video-T2V와 Step-Audio는 점프 스타가 처음으로 오픈 소스화한 멀티모달 모델입니다.
Step-Video-T2V
먼저 비디오 생성 모델 Step-Video-T2V를 살펴보겠습니다.
이 모델의 매개변수 수는 300억 개로, 현재 전 세계에서 가장 큰 규모의 오픈 소스 비디오 생성 대규모 모델이며, 중영 이중 언어 입력을 기본적으로 지원합니다.

공식 소개에 따르면, Step-Video-T2V에는 4가지 주요 기술적 특징이 있습니다:
첫째, 최대 204프레임, 540P 해상도의 비디오를 직접 생성할 수 있어 생성된 비디오의 일관성과 정보 밀도가 매우 높습니다.
둘째, 비디오 생성 작업을 위해 고압축비 Video-VAE를 설계 및 학습했습니다. 비디오 재구성 품질을 유지하면서 공간 차원에서 16x16배, 시간 차원에서 8배 압축할 수 있습니다.
현재 시장에 나와 있는 대부분의 VAE 모델의 압축비는 8x8x4인데, 동일한 비디오 프레임 수에서 Video-VAE는 추가로 8배 압축할 수 있어 학습 및 생성 효율이 64배 향상되었습니다.
셋째, DiT 모델의 하이퍼파라미터 설정, 모델 구조 및 학습 효율에 대해 심층적인 시스템 최적화를 수행하여 학습 과정의 효율성과 안정성을 보장했습니다.
넷째, 사전 학습 및 후 학습을 포함한 완전한 학습 전략을 자세히 소개했습니다. 이는 각 단계의 학습 작업, 학습 목표 및 데이터 구축 및 선별 방식을 포함합니다.
또한 Step-Video-T2V는 마지막 학습 단계에서 Video-DPO(비디오 선호 최적화)를 도입했습니다. 이는 비디오 생성을 위한 RL 최적화 알고리즘으로, 비디오 생성 품질을 더욱 향상시키고 생성 비디오의 합리성과 안정성을 강화할 수 있습니다.
최종적으로 생성된 비디오의 움직임이 더 유창하고, 세부 사항이 더 풍부하며, 지시에 더 정확하게 부합하게 됩니다.
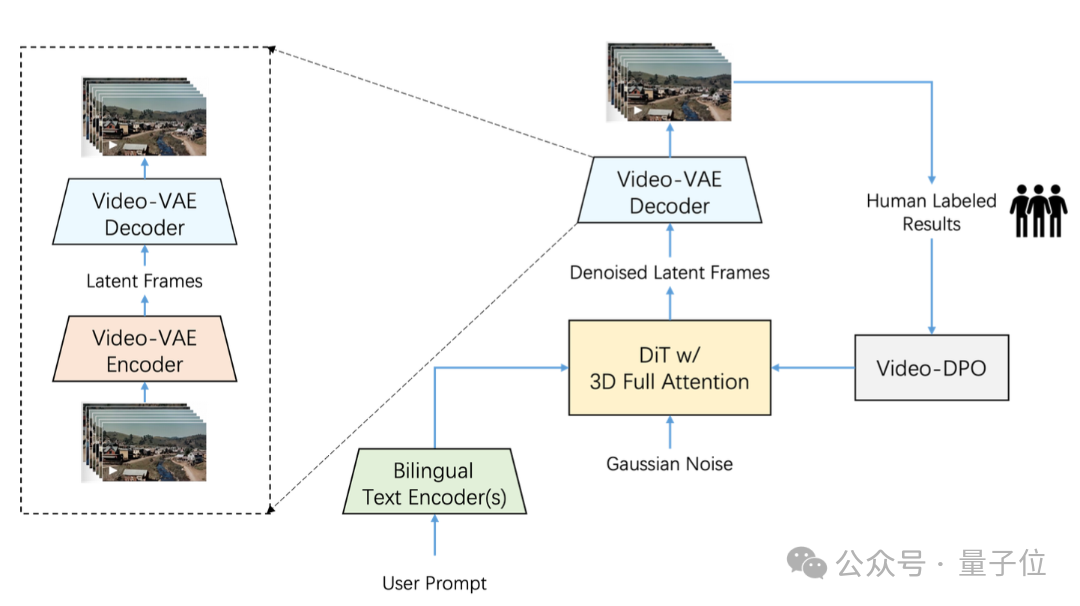
오픈 소스 비디오 생성 모델의 성능을 전면적으로 평가하기 위해 점프 스타는 이번에 새로운 기준 데이터셋 Step-Video-T2V-Eval을 함께 공개했습니다.
이 데이터셋도 함께 오픈 소스화되었습니다~
이 데이터셋에는 128개의 실제 사용자 제공 중국어 평가 질문이 포함되어 있으며, 동작, 풍경, 동물, 복합 개념, 초현실적 등 11개 내용 범주의 생성 비디오 품질을 평가하는 것을 목표로 합니다.
Step-Video-T2V-Eval에 대한 평가 결과는 다음과 같습니다:
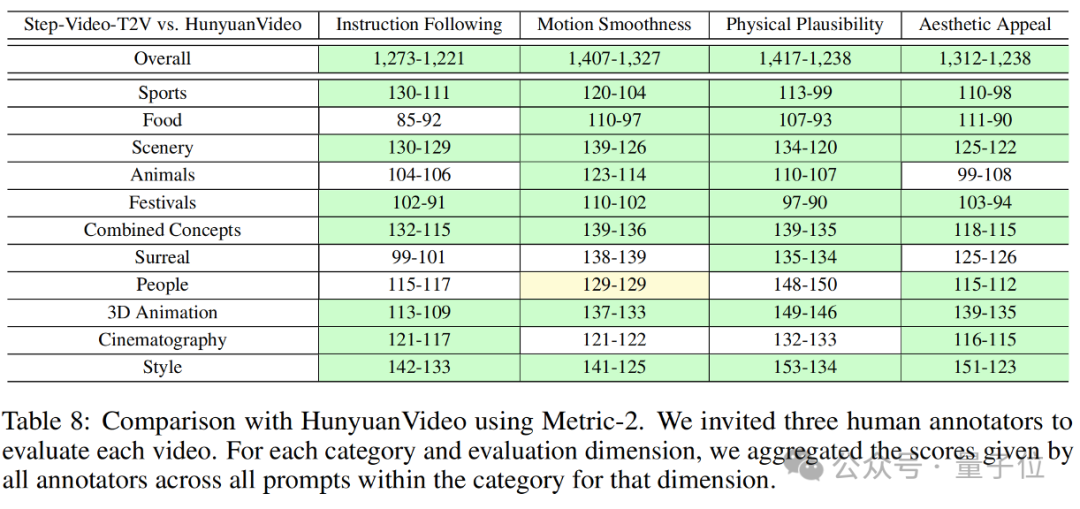
이를 통해 Step-Video-T2V가 지시 준수, 동작 유창성, 물리적 합리성, 미적 감각 등 측면에서 이전 최고의 오픈 소스 비디오 모델을 능가한다는 것을 알 수 있습니다.
이는 전체 비디오 생성 분야에서 이 새로운 최강 기반 모델을 기반으로 연구와 혁신을 수행할 수 있음을 의미합니다.
실제 효과 측면에서 점프 스타 측은 다음과 같이 소개했습니다:
Step-Video-T2V는 복잡한 동작, 매력적인 인물, 시각적 상상력, 기본 텍스트 생성, 원어민 중영 이중 언어 입력 및 카메라 언어 등 다양한 영역에서 강력한 생성 능력을 갖추고 있으며, 의미 이해 및 지시 준수 능력이 뛰어나 비디오 창작자들의 정확한 창의적 표현을 효과적으로 지원할 수 있습니다.
그럼 어서 실험해 보자!
공식 소개 순서대로, 첫 번째 테스트는 Step-Video-T2V가 복잡한 동작을 처리할 수 있는지 확인하는 것입니다.
이전의 비디오 생성 모델들은 발레/표준 댄스/중국 무용, 체조, 태권도, 무술 등 다양한 복잡한 동작 장면을 생성할 때 종종 이상한 장면이 나타났습니다.
예를 들어 갑자기 나타나는 세 번째 다리, 겹쳐진 팔 등 기괴한 모습들이 있었습니다.
이러한 문제를 해결하기 위해 우리는 집중 테스트를 진행했습니다. Step-Video-T2V에 다음과 같은 프롬프트를 제공했습니다:
실내 배드민턴 코트, 정면 시점, 고정 카메라로 기록된 남자 배드민턴 경기 장면. 빨간 티셔츠와 검은 반바지를 입은 남자가 녹색 배드민턴 코트 중앙에 서서 배드민턴 라켓을 들고 있습니다. 네트가 코트를 가로질러 두 부분으로 나눕니다. 남자가 라켓으로 셔틀콕을 쳐서 반대편으로 보냅니다. 조명은 밝고 균일하며 화질은 선명합니다.
장면, 인물, 카메라, 조명, 동작 모두 일치합니다.
생성된 화면에 "매력적인 인물"이 포함되어 있다면, 이는 Qbitai가 Step-Video-T2V에 던진 두 번째 도전과제입니다.
솔직히 말해서, 지금 텍스트 생성 이미지 모델의 수준으로 볼 때 정적이고 부분적인 세부 사항에서는 진짜와 구분하기 어려울 정도입니다.
하지만 동영상 생성의 경우, 인물이 움직이기 시작하면 여전히 식별 가능한 물리적 또는 논리적 결함이 존재합니다.
그런데 Step-Video-T2V의 성능은 어떨까요?
프롬프트: 한 남성이 검은색 정장, 어두운 색 넥타이, 흰색 셔츠를 착용하고 있으며 얼굴에 상처가 있고 표정이 엄숙합니다. 클로즈업 샷.
"AI스러운 게 없네."
이는 Qbitai 편집부 동료들이 한 번 돌려본 후의 일치된 평가입니다.
즉, 얼굴 윤곽이 정확하고 피부 질감이 사실적이며 얼굴의 상처가 선명하게 보이는 등 "AI스러운 게 없다"는 것입니다.
또한 눈빛이 공허하거나 표정이 경직되지 않은 "AI스러운 게 없다"는 의미이기도 합니다.
위의 두 가지 테스트에서는 Step-Video-T2V를 고정 카메라 위치에 두었습니다.
그렇다면 팬, 틸트, 줌 등의 움직임은 어떨까요?
세 번째 테스트는 Step-Video-T2V의 카메라 움직임 제어 능력을 평가합니다.
회전하라고 하면 회전합니다:
꽤 괜찮네! 스테디캠을 들고 현장에서 촬영감독이 될
阶跃团队介绍,Step-Audio能够根据不同的场景需求生成情绪、方言、语种、歌声和个性化风格的表达,能和用户自然地高质量对话。
同时,由其生成的语音不仅具有逼真自然、高情商等特征,还能实现高质量的音色复刻并进行角色扮演。
总之,影视娱乐、社交、游戏等行业场景下应用需求,Step-Audio包让你一整个大满足的。
阶跃开源生态,正在滚雪球
怎么说呢,就一个字:卷。
阶跃是真卷啊,尤其是在自家拿手好戏多模态模型方面——
旗下Step系列中的多模态模型,自打出生以来,就是国内外各大权威评测集、竞技场等的第一名常客。
只看最近3个月,都已经数次勇夺榜首。
去年11月22日,大模型竞技场最新榜单,多模态理解大模型Step-1V上榜,总分与持平,位列视觉领域中国大模型第一。
今年1月,国内大模型评估平台"司南"(OpenCompass)多模态模型评测实时榜单,刚出炉的系列模型拿下第一。
同日,大模型竞技场最新榜单,多模态模型拿下国内视觉领域大模型第一。

其次,阶跃的多模态模型不仅性能好、质量佳,研发迭代频率也很高——
截至目前,阶跃星辰已经先后发布了11款多模态大模型。
上个月,6天连发6模型,覆盖语言、语音、视觉、推理全赛道,进一步做实多模态卷王称号。
这个月又开源2款多模态模型。
只要稳定住这个节奏,就能继续且持续地证明自己「全家桶级多模态玩家」的地位。
凭借强大的多模态实力,2024年开始,市场和开发者们就已经认可并广泛接入阶跃,形成了庞大的用户基础。
大众消费品,如<茶百道>,就让全国数千家门店接入多模态理解大模型,探索大模型技术在茶饮行业的应用,进行智能巡检、AIGC 营销。
公开数据显示,平均每天上百万杯茶百道茶饮在大模型智能巡检的守护下送到消费者手中。
而平均每天能够为茶百道督导员节约75%的自检核验时间,为茶饮消费者提供了更加安心和优质的服务。
独立开发者,如网红应用"胃之书"、心理疗愈应用"林间聊愈室"在对国内大部分模型做过测试后,最终都选择了阶跃多模态模型。
(小声:因为用它,付费率最高)
具体数据显示,2024年下半年,阶跃多模态大模型的调用量增长超45倍。

再说到,此次开源,开源的就是阶跃自家最擅长的多模态模型。
我们注意到,已经积累市场和开发者口碑及数量的阶跃,此次开源,从模型侧就在为后续深入接入做考虑。
一方面,采用了是最为开放宽松的开源协议,可任意编辑和商业应用。
可以说,「毫不隐藏」。
另一方面,阶跃表示"全力降低产业接入门槛"。
就拿来说吧,不同于市面上的开源方案需要经过再部署和再开发等工作量,是一整套实时对话方案,只要简单部署上就能直接实时对话。
零帧起手就能享受端到端体验。
一整套动作下来,围绕阶跃星辰和它手中的多模态模型王牌,已经初步形成了独属于阶跃的开源技术生态。
在这个生态中,技术、创意和商业价值相互交织,共同推动着多模态技术的发展。
而且随着阶跃模型的继续研发、迭代,开发者的迅速、持续接入,生态伙伴的助力、合力,阶跃生态的"滚雪球效应",已经发生,并正在壮大。
中国开源力量正在并肩用实力说话
曾几何时,提起大模型开源领域的佼佼者,人们脑中浮现出的是的,是的。
到了现在,毋庸置疑,中国大模型届的开源力量已经闪耀全球,用实力改写"刻板印象"。
1月20日,蛇年春节前夕,是一个国内外大模型神仙打架的日子。
最瞩目的是,在这一天问世,它推理性能比肩的,成本却仅后者1/3。
影响之巨大,一夜让<英伟达>蒸发5890亿美元(约合人民币4.24万亿元),创下美股单日跌幅最大纪录。
更重要也更耀眼的是,之所以上升到亿万人为之兴奋的高度,除了推理优异、价格亲民,更重要的是它身上的开源属性。
一石激起千层浪,连长期被戏谑「不再open」的,都有奥特曼屡次出来公开发言。
奥特曼说:"在开源权重模型这个问题上,(个人认为)我们站在了历史错误的一边。"
他还说:"世界上确实需要开源模型,它们可以为人们提供大量价值。我很高兴,世界上已经有一些优秀的开源模型。"

现在,阶跃也开始开源手里的新王牌了。
并且开源是初衷。
官方表示,开源和,目的就是促进大模型技术的共享与创新,推动人工智能的普惠发展。
开源一出场就凭实力在多个评测集上秀一把。
现在的开源大模型的牌桌上,强推理,阶跃重多模态,还有各式各样持续发育的选手……
它们的实力不仅是在开源圈子里拔尖,放眼整个大模型圈子,都很够看。
——中国开源力量,在崭露头角后,正在更进一步。
以阶跃这次开源为例,突破的是多模态领域的技术,改变的是全球开发者的选择逻辑。
等很多开源社区活跃的技术大,纷纷主动下场测试阶跃的模型,"感谢中国开源"。
<抱抱脸>中国区负责人<王铁震>直接表示,阶跃会是下一个""。

从「技术突围」到「生态开放」,中国大模型的路越走越稳。
话说回来,阶跃今次开源双模型,或许只是2025年竞赛的一个注脚。
更深层次的,它展现了中国开源力量的技术自信,并传递出一个信号:
未来的大模型世界,中国力量绝不缺席,也绝不落于人后。