이제 분산화된 방식으로 컴퓨트 테스트 시간을 확장할 시간입니다. RL은 대규모 언어 모델을 위한 사후 훈련 패러다임일 뿐만 아니라 조정된 쓰라린 교훈입니다.
이 기사는 기계로 번역되었습니다
원문 표시

Noam Brown
@polynoamial
04-17
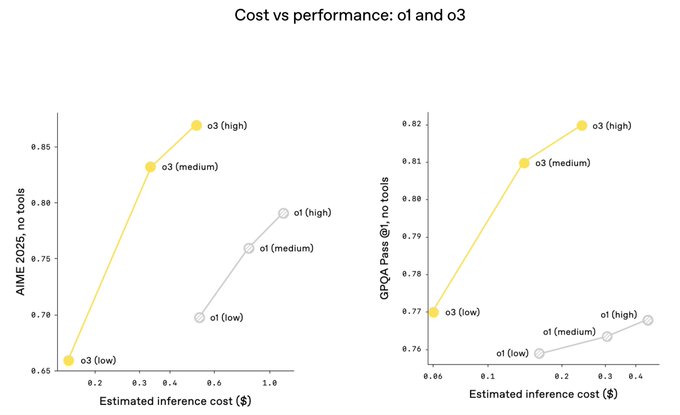
Our new @OpenAI o3 and o4-mini models further confirm that scaling inference improves intelligence, and that scaling RL shifts up the whole compute vs. intelligence curve. There is still a lot of room to scale both of these further.
Twitter에서
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유