

8월 29일 오전(베이징 시간), OpenAI는 라이브 스트리밍을 통해 역대 가장 진보된 엔드투엔드 음성 모델인 GPT-Realtime을 출시하고, Realtime API의 정식 출시를 발표했습니다. 기존 음성 AI 제품보다 뛰어난 성능과 저렴한 가격을 제공하는 GPT-Realtime은 개발자들이 효율적이고 안정적인 음성 에이전트를 더욱 쉽게 구축할 수 있도록 설계되었습니다.
성능 향상과 함께 GPT-Realtime의 가격도 이전 버전인 GPT-4o-Realtime-Preview보다 20% 인하되어 대폭 최적화되었습니다. 이전에는 GPT-4o-Realtime-Preview의 가격이 오디오 입력 토큰 백만 개당 40달러, 오디오 출력 토큰 백만 개당 80달러였습니다. 이제 GPT-Realtime의 조정된 가격은 오디오 입력 토큰 백만 개당 32달러(캐시된 입력 토큰의 경우 0.40달러), 오디오 출력 토큰 백만 개당 64달러입니다. 이처럼 최적화된 가격 정책을 통해 개발자는 더 저렴한 비용으로 효율적인 음성 에이전트를 구축하면서 뛰어난 성능을 누릴 수 있습니다.
OpenAI는 또한 대화 맥락 관리를 최적화하여 개발자가 토큰 제한을 유연하게 설정하고 여러 라운드의 대화를 한 번에 중단할 수 있도록 했으며, 이를 통해 장시간 대화의 비용을 크게 줄일 수 있었습니다.
01. 심층 분석: 더욱 스마트하고 표현력이 풍부한 음성 모델
새로운 GPT-Realtime 모델은 성능 면에서 상당한 도약을 보여줍니다. OpenAI는 이 모델이 지금까지 출시된 제품 중 가장 진보된 프로덕션급 음성 모델이라고 주장하며, 복잡한 지시를 따르고, 도구를 정확하게 호출하며, 더욱 자연스럽고 표현력이 풍부한 음성을 생성하는 데 있어 상당한 개선을 이루었다고 밝혔습니다.
OpenAI는 GPT-Realtime이 복잡한 명령을 더욱 정확하게 실행하고, 더욱 자연스럽고 표현력이 풍부한 음성을 생성하며, 한 문장 내에서 여러 언어 간 원활한 전환을 지원한다고 주장합니다. 자체 벤치마크 테스트에서 이 모델은 더욱 향상된 지능을 보여주었습니다. 이전 음성 AI 모델과 비교했을 때, GPT-Realtime은 다음과 같은 측면에서 크게 향상되었습니다.
음질 및 표현력: 인간의 어조, 감정, 말하는 속도를 시뮬레이션할 수 있으며, 개발자가 "빠르고 전문적" 또는 "부드럽고 사려 깊음"과 같이 음성 톤을 사용자 지정하여 사용자 경험을 향상할 수 있도록 지원합니다.
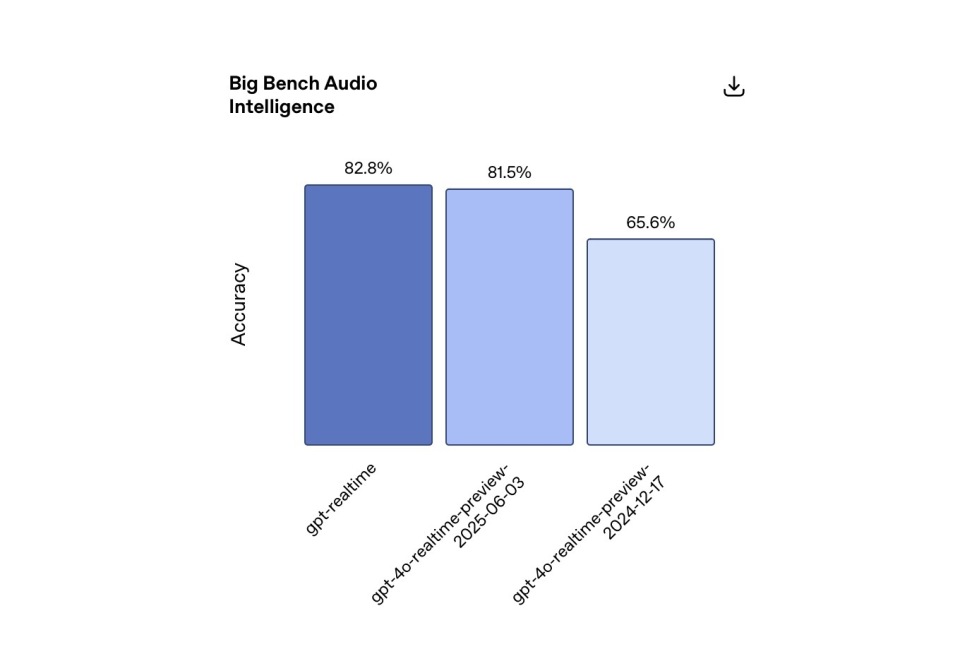
지능 및 이해력: 텍스트와 음성 처리뿐만 아니라 비언어적 신호(예: 웃음)를 인식하고, 문장 내 언어를 유연하게 전환하며, 영숫자 시퀀스를 정확하게 처리합니다. 내부 테스트 결과, GPT-Realtime은 Big Bench 오디오 추론 테스트에서 82.8%의 정확도를 달성하여, 2024년 12월 이전 버전인 GPT-4o-Realtime-Preview의 65.6%와 올해 6월 3일 기준 81.5%를 크게 앞지르는 성과를 보였습니다.
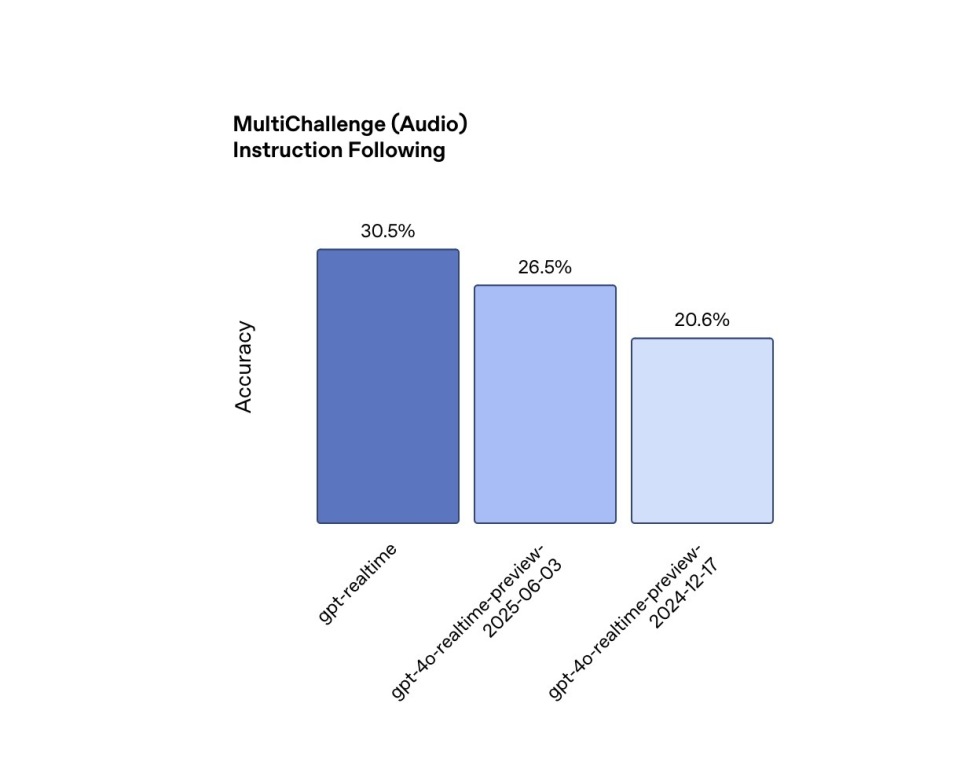
명령 수행: 명령 수행은 신뢰할 수 있는 상담원의 핵심 기능이며, GPT-Realtime 또한 이 부분에서 개선되었습니다. MultiChallenge Audio 테스트에서 GPT-Realtime은 30.5%의 명령 실행 정확도를 달성하여 지원 통화 중 법적 고지 사항을 그대로 읽어주는 등 개발자가 지정한 지시를 더욱 안정적으로 따를 수 있게 되었습니다. 이 성능은 이전 세대인 GPT-4o-Realtime-Preview가 2024년 12월에 달성한 20.6%와 올해 6월 3일의 26.5%를 능가합니다.
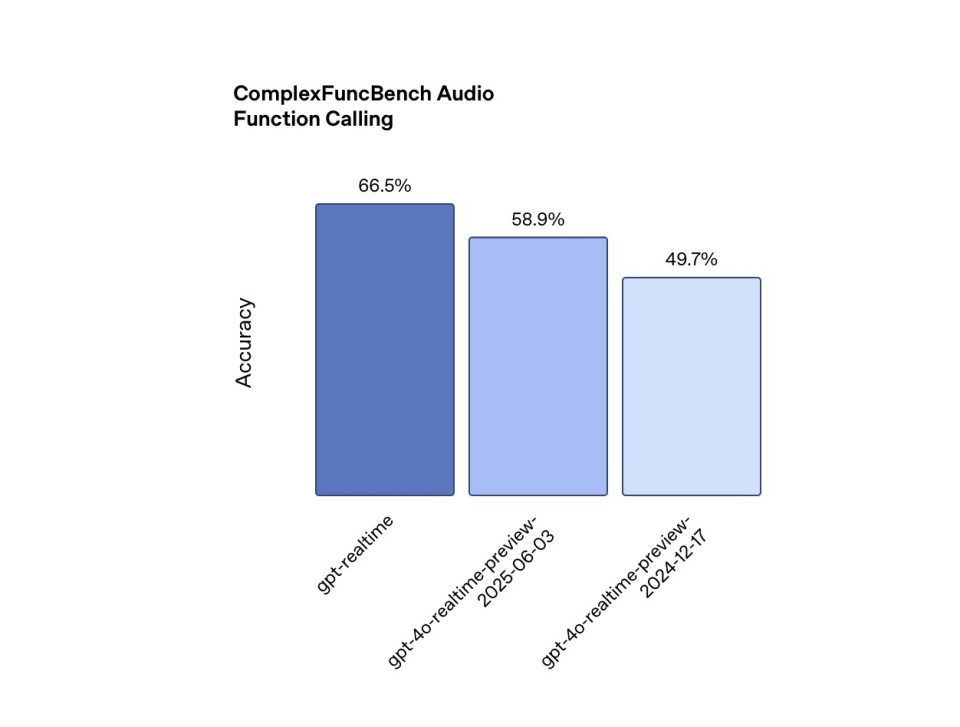
함수 호출: 실제 환경에서 효과적으로 작동하려면 음성 에이전트가 외부 도구를 효과적으로 사용해야 합니다. ComplexFuncBench Audio 테스트에서 GPT-Realtime은 함수 호출에서 66.5%의 정확도를 달성했으며, 비동기 호출을 지원하여 결과 대기 시간 동안 끊김 없는 원활한 대화를 보장합니다. 이와 대조적으로 GPT-4o-Realtime-Preview는 2024년 12월에 49.7%의 정확도를 달성했고, 올해 6월 3일에는 58.9%의 정확도를 기록했습니다.
향상된 지능 외에도, 이 모델은 더욱 인간적인 억양, 감정, 그리고 속도감을 갖춘 고품질 음성을 생성하도록 훈련되었습니다. "빠르고 전문적으로 말해" 또는 "프랑스 억양으로 부드럽게 말해"와 같은 세밀한 지시를 따를 수 있어 사용자에게 더욱 개인화된 경험을 제공합니다. 또한, GPT-Realtime은 이미지 입력을 지원하고 사진이나 스크린샷의 내용을 인식할 수 있습니다. 예를 들어, 사용자는 스크린샷을 업로드하고 모델에 "스크린샷 안의 텍스트를 읽어줘"라고 요청하여 적용 범위를 더욱 확장할 수 있습니다.
이러한 발전을 보여주기 위해 OpenAI는 API에서만 제공되는 두 가지 새로운 음성, Cedar와 Marin을 출시했습니다. 이 음성들은 자연스러운 음성 인식에서 가장 큰 개선을 보여줍니다. 이러한 세심한 노력은 업계의 주요 과제를 해결하기 위해 고안되었습니다. OpenAI의 업그레이드는 더욱 매력적이고 로봇 같은 사용자 경험을 제공하는 데 직접적으로 초점을 맞추고 있습니다.
02. 개발자 역량 강화: 프로덕션급 지능형 에이전트를 위한 API 업그레이드
새로운 모델 외에도 Realtime API 자체도 이제 프로덕션급으로 제공됩니다. OpenAI는 2024년 10월 공개 베타 버전 출시 이후 수천 명의 개발자로부터 피드백을 수집하고 이를 바탕으로 개선 작업을 진행해 왔습니다. 이 API의 아키텍처는 단일 모델을 통해 오디오를 직접 처리하여 지연 시간을 줄이고 음성 세부 정보를 보존하도록 설계되었습니다. 이는 기존의 다중 모델 음성-텍스트 변환(STT) 및 텍스트-음성 변환(TTS) 파이프라인에 비해 상당한 이점을 제공합니다.

주요 새 기능은 원격 모델 컨텍스트 프로토콜(MCP) 서버 지원입니다. 이 개방형 표준은 AI 모델이 외부 데이터에 연결하는 방식을 간소화합니다. 개발자는 이제 세션 구성을 통해 원격 MCP 서버의 URL을 전달할 수 있으며, 이를 통해 Realtime API가 도구 호출을 자동으로 처리하여 수동 통합의 필요성을 없앨 수 있습니다. 이를 통해 AI 모델을 자체 데이터 소스에 연결하는 과정이 간소화되며, 이는 사용자 데이터와 개인 정보 보호를 우선시하는 동시에 강력한 비즈니스 인텔리전스를 구축하는 데 중요한 단계입니다.
Realtime API는 이제 이미지 입력도 지원하여 상담원이 사용자가 보고 있는 내용을 분석하고 논의할 수 있는 다중 모드 대화를 가능하게 합니다. 이미지는 대화에서 실시간 비디오 스트림이 아닌 스냅샷으로 처리되므로 개발자는 모델이 보는 내용을 제어할 수 있습니다. 이를 통해 상담원이 사진을 설명하거나 스크린샷에서 텍스트를 읽는 등의 활용 사례가 가능해집니다.
또한, 새로운 SIP(Session Initiation Protocol) 지원을 통해 공중 전화망, PBX 시스템 및 기타 기업 전화 엔드포인트와 직접 통합할 수 있으므로 콜센터와 같은 비즈니스 환경에서 음성 에이전트를 배포하기가 더 쉬워집니다.
얼리어답터들은 이미 성과를 거두고 있습니다. 부동산 플랫폼 질로우(Zillow)는 차세대 주택 검색에 활용할 실시간 API(Realtime API)에 대한 조기 접근 권한을 확보했습니다. 질로우의 AI 책임자인 조쉬 와이스버그(Josh Weisberg)는 "실시간 API는 향상된 추론 능력과 더욱 자연스러운 음성 인식 기능을 통해 라이프스타일 니즈에 따른 매물 필터링과 같은 복잡하고 여러 단계로 구성된 요청을 처리할 수 있게 해줍니다."라고 말했습니다.
03. 치열한 경쟁이 펼쳐지는 음성 AI 분야
OpenAI의 GPT-Realtime 모델 출시는 음성 AI 시장의 치열한 경쟁 속에서 이루어졌으며, 주요 경쟁사들은 자체 음성 기술 개발 및 배포를 적극적으로 추진하고 있습니다. 올해 5월, Anthropic은 자사 Claude AI의 음성 모델을 출시하며 해당 분야에 성공적으로 진출했습니다. 7월에는 Meta가 음성 스타트업 PlayAI를 4,500만 달러에 인수하여 AI 비서 및 스마트 안경 기술 강화를 목표로 했습니다. 이러한 움직임은 업계 내 인재 확보 경쟁을 더욱 심화시켰습니다.
오픈소스 커뮤니티 또한 무시할 수 없는 강력한 경쟁력입니다. 7월, 프랑스 스타트업 미스트랄(Mistral)은 아파치 2.0 라이선스를 기반으로 Voxtral 모델을 출시했습니다. 관계자들은 Voxtral 모델이 유사 API의 절반 이하 가격으로 최첨단 성능을 제공할 것이라고 약속했습니다. 이번 달, 샤오미는 자체 개발한 대규모 소리 이해 모델인 MiDashengLM-7B를 출시했습니다. 이 모델은 자막 기반 학습 방식을 혁신적으로 활용하여 음성, 음악, 주변 소리에 대한 포괄적인 이해를 달성했으며, 기업 친화적 라이선스를 사용합니다.
기존 기술 대기업들 또한 음성 AI에 대한 투자를 지속하고 있습니다. 올해 4월, 아마존은 실시간 표현력 모델인 노바 소닉(Nova Sonic)을 출시하여 자사 비서 알렉사+(Alexa+)에 통합했습니다. 음성 AI 혁신은 전문 스타트업으로까지 확대되었습니다. 예를 들어, 스태빌리티 AI(Stability AI)는 온디바이스 음성 처리 기술 개발에 집중하고 있으며, 세서미 AI(Sesame AI)와 같은 기업들은 자연스러운 멈춤이나 약간의 끊김과 같은 인간적인 특징을 음성에 반영하여 "놀랍도록 생생한" AI 비서를 개발하고 있습니다.
OpenAI는 최첨단 음성 모델을 최적화하여 사용 편의성, 성능, 그리고 비용 효율성을 높이고 있습니다. 이러한 움직임은 점점 치열해지는 플랫폼 경쟁에 맞서는 전략적 행보를 보여줍니다. OpenAI는 탁월한 개발자 경험을 활용하여 음성 AI 전쟁에서 우위를 점하고, 이것이 승패를 가르는 핵심 요소가 되기를 기대합니다.
본 기사는 " 텐센트 테크놀로지 "에서 발췌하였으며, 저자는 우지이고, 36Kr에서 허가를 받아 게시하였습니다.






