

두 개의 미국 AI 연구소가 이번 주에 오픈소스 모델을 공개했는데, 각 연구소는 동일한 문제, 즉 공개적으로 접근 가능한 AI 시스템에서 중국의 지배력과 경쟁하는 방법에 대해 매우 다른 접근 방식을 취하고 있습니다.
Deep Cogito는 6,710억 개의 매개변수를 가진 거대한 모델인 Cogito v2.1을 출시했습니다. 창립자인 드리샨 아로라는 이를 "미국 회사가 만든 최고의 오픈웨이트 LLM"이라고 부릅니다.
앨런 AI 연구소는 Olmo 3를 "최고의 완전 개방형 기반 모델"이라고 홍보하며, "그렇게 성급한 것은 아니다"라고 반박했습니다. Olmo 3는 학습 데이터와 코드를 포함하여 완전한 투명성을 자랑합니다.
아이러니하게도 Deep Cognito의 주력 모델은 중국 기반을 기반으로 구축되었습니다. Arora는 X에서 Cogito v2.1이 "2024년 11월부터 공개 라이선스를 적용하는 Deepseek 기반 모델에서 분리된다"고 밝혔습니다.
이로 인해 중국 모델을 미세 조정한 것이 미국 AI의 발전으로 간주되는지, 아니면 단지 미국 연구소가 얼마나 뒤처졌는지를 보여주는 증거인지에 대한 비판과 논쟁이 일어났습니다.
https://t.co/wHcfNQIJzJ pic.twitter.com/N7x1eEsjhF
— 루카 솔다이니 主(@soldni) 2025년 11월 19일
> 미국 회사의 최고 오픈웨이트 LLM
멋지긴 한데 기본 모델이 deepseek V3이기 때문에 "US" 부분을 강조하는 게 맞는지 잘 모르겠어요 https://t.co/SfD3dR5OOy
— 엘리(@eliebakouch) 2025년 11월 19일
그럼에도 불구하고, Cogito가 DeepSeek에 비해 효율성이 향상된 것은 사실입니다.
Deep Cognito는 Cogito v2.1이 경쟁력 있는 성능을 유지하면서 DeepSeek R1보다 60% 더 짧은 추론 체인을 생성한다고 주장합니다.
Arora가 "반복적 증류 및 증폭"이라고 부르는 방법, 즉 자기 개선 루프를 통해 더 나은 직관력을 개발하도록 모델을 가르치는 방법을 사용하여 스타트업은 RunPod와 Nebius의 인프라에서 단 75일 만에 모델을 훈련했습니다.
벤치마크가 사실이라면, 이는 현재 미국 팀이 유지하고 있는 가장 강력한 오픈소스 LLM이 될 것입니다.
왜 중요한가
지금까지 중국은 오픈소스 AI 분야에서 선두를 달려왔고, 미국 기업들은 경쟁력을 유지하기 위해 조용히 또는 공개적으로 중국 기반 모델에 점점 더 의존하고 있습니다.
이러한 역학 관계는 위험합니다. 중국 연구소가 전 세계 오픈 AI의 기본이 된다면, 미국 스타트업은 기술적 독립성, 협상력, 그리고 산업 표준을 형성하는 능력을 잃게 됩니다.
개방형 AI는 모든 다운스트림 제품에 의존하는 원시 모델을 누가 제어할지 결정합니다.
현재 중국 오픈소스 모델(DeepSeek, Qwen, Kimi, MiniMax)이 전 세계적으로 널리 채택되고 있는데, 그 이유는 저렴하고 빠르며 효율성이 높고 지속적으로 업데이트되기 때문입니다 .
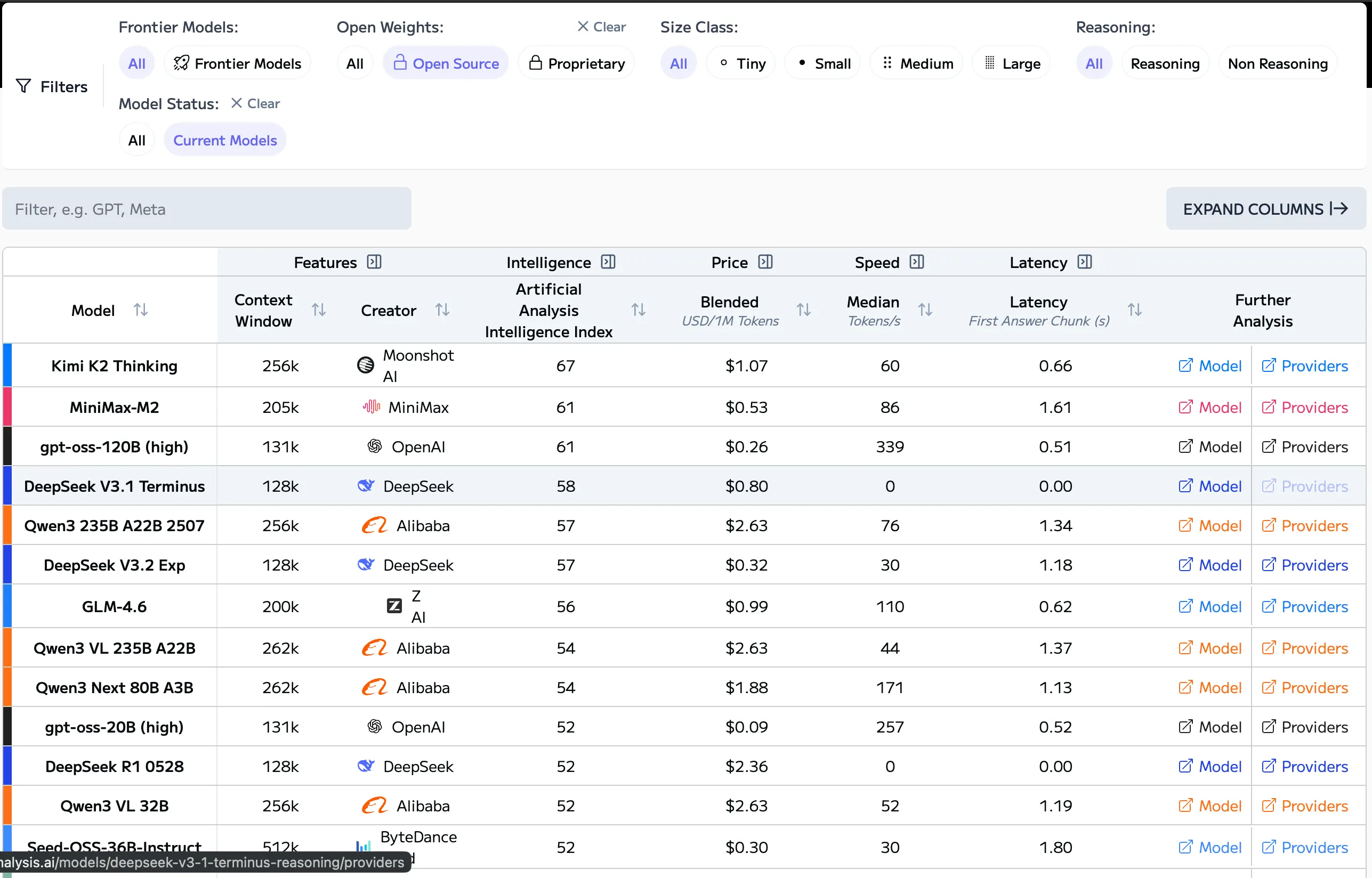
많은 미국 스타트업은 공개적으로는 인정하지 않더라도 이미 이러한 플랫폼을 기반으로 사업을 확장하고 있습니다.
즉, 미국 기업들은 해외 지적 재산권(IP), 해외 교육 파이프라인, 그리고 해외 하드웨어 최적화를 기반으로 사업을 구축하고 있습니다. 전략적으로, 이는 미국을 반도체 제조와 관련하여 과거와 같은 처지, 즉 다른 업체의 공급망에 점점 더 의존하게 만드는 상황에 놓이게 합니다.
DeepSeek 포크(Fork) 에서 시작하는 Deep Cogito의 접근 방식은 장점(빠른 반복)과 단점(종속성)을 보여줍니다.
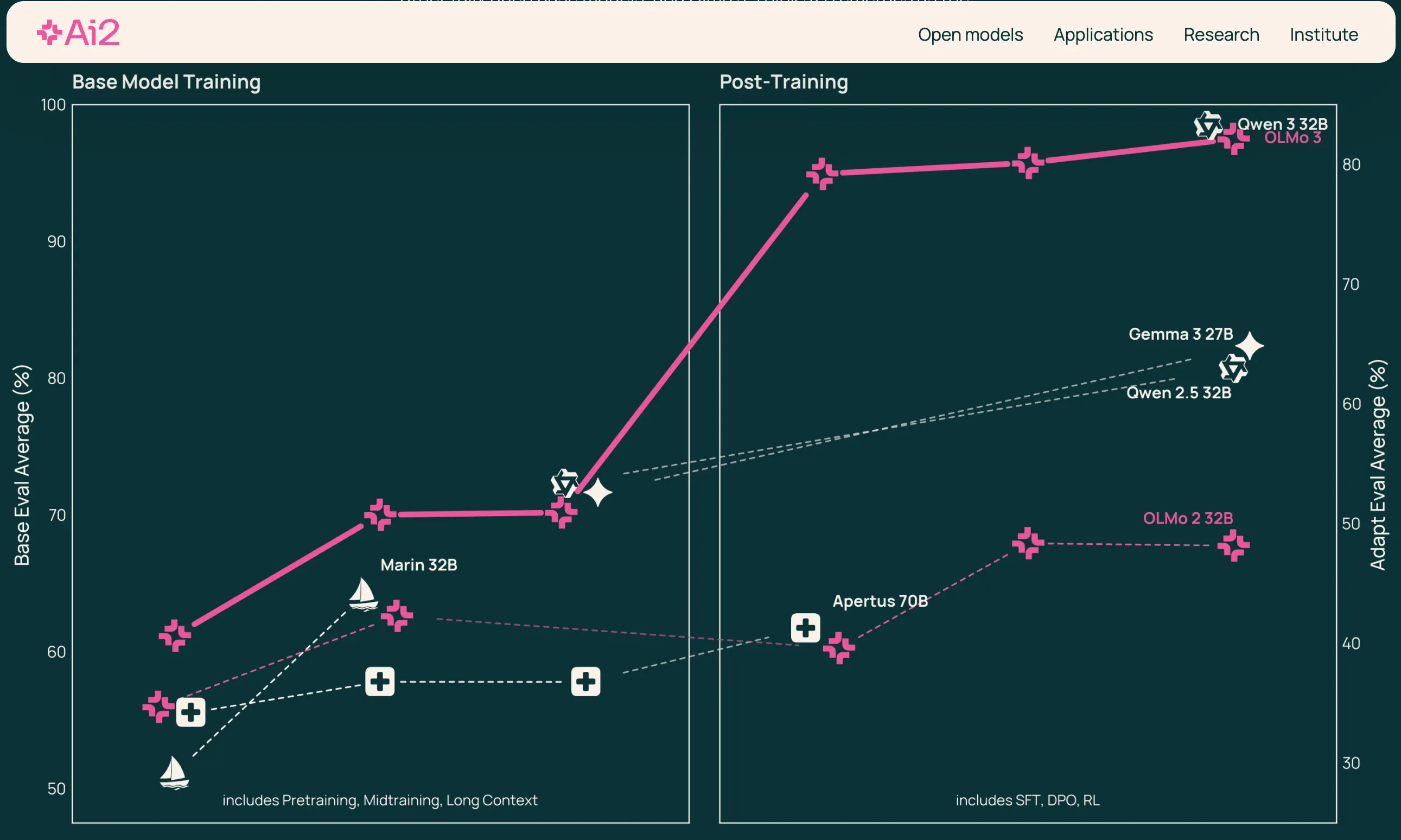
앨런 연구소의 접근 방식, 즉 올모 3를 완전한 투명성으로 구축하는 방식은 대안을 보여줍니다. 미국이 개방형 AI 리더십을 원한다면 데이터부터 훈련 레시피, 체크포인트에 이르기까지 스택 자체를 재구축해야 합니다. 이는 노동 집약적이고 느리지만, 기반 기술에 대한 주권을 보존할 수 있습니다.
이론상으로는 이미 DeepSeek을 좋아해서 온라인에서 사용한다면, Cogito는 대부분 더 나은 답변을 제공할 것입니다. API를 통해 사용하면 효율성 향상 덕분에 더 적은 비용으로 좋은 답변을 얻을 수 있으므로 두 배 더 만족스러울 것입니다.
앨런 연구소는 정반대의 방향을 택했습니다. Olmo 3 모델 전체가 Dolma 3와 함께 출시되었습니다. Dolma 3는 처음부터 구축된 5조 9천억 토큰 규모의 학습 데이터셋으로, 모든 학습 단계의 완전한 코드, 레시피, 체크포인트를 포함합니다.
비영리 단체는 70억 개와 320억 개의 매개변수를 갖춘 Base, Think, Instruct의 세 가지 모델 변형을 출시했습니다.
연구소는 "AI의 진정한 개방성은 단순히 접근성에 관한 것이 아니라 신뢰, 책임, 공동의 진전에 관한 것입니다."라고 기술했습니다.
Olmo 3-Think 32B는 Qwen 3와 같은 비슷한 모델에 비해 약 6분의 1의 토큰으로 학습하면서도 경쟁력 있는 성능을 달성한 최초의 완전 개방형 추론 모델입니다.
Deep Cognito는 8월 벤치마크가 주도한 시드 투자로 1,300만 달러를 확보했습니다. 이 스타트업은 "훨씬 더 향상된 컴퓨팅 성능과 더 나은 데이터 세트"를 기반으로 학습된 최대 6,710억 개의 매개변수를 포함하는 프론티어 모델을 출시할 계획입니다.
한편, 엔비디아는 올모 3 개발을 지원했으며, 부사장인 카리 브리스키는 "개발자들이 미국에서 만든 개방형 모델을 통해 AI를 확장하는 것이 필수적"이라고 말했습니다.
이 연구소는 Google Cloud의 H100 GPU 클러스터에서 교육을 받았으며 Meta의 Llama 3.1 8B보다 2.5배 적은 컴퓨팅 요구 사항을 달성했습니다.
Cogito v2.1은 여기에서 무료 온라인 테스트를 이용할 수 있습니다. 모델은 여기에서 다운로드할 수 있지만, 실행하려면 매우 강력한 그래픽 카드가 필요하다는 점에 유의하세요.
Olmo는 여기에서 테스트해 보실 수 있습니다. 모델은 여기에서 다운로드하실 수 있습니다. 어떤 모델을 선택하시느냐에 따라 이 모델들이 소비자에게 더 친화적일 수 있습니다.






