본 보고서는 ACD가 이더리움 개선 제안(EIP)-7907에 대한 결정을 내리는 데 도움이 될 수 있는 자료 모음을 목표로 합니다.
또한, 이를 통해 EIP 또는 제안서를 최대한 많은 데이터로 뒷받침하는 새로운 방법론이 정립되기를 바라며, 이는 포크의 범위를 설정할 때 더 나은 정보에 기반한 결정을 내리는 데 확실히 도움이 될 것입니다.
Geth에 메트릭을 추가하는 PR을 제출해 주신 @rjl493456442 님께 감사드립니다. 벤치마크 데이터 수집 과정에서 주신 조언과 지원은 매우 유용했습니다. 향후 모든 클라이언트에서 이 메트릭을 표준화하여 데이터를 쉽게 비교하고 수집하여 가격 재조정 및 확장에 대한 의사 결정을 내릴 수 있도록 하고 싶습니다.
관련 문제:** 이더리움 개선 제안(EIP)-7907
날짜: 2026년 1월 13일
벤치마크 환경: 메인넷 규모 데이터베이스(약 2400만 블록)를 사용하는 Geth(개발 모드), 내부 캐시 비활성화
테스트 구성: 블록 당 약 18,106개의 EXTCODESIZE 연산 (모두 다른 바이트코드 계약), 약 5천만 가스
하드웨어: WD Black SN850X NVMe (8TB)
요약 보고서
이 보고서는 Geth의 내부 코드 캐시가 비활성화된 상태에서 바이트코드 크기가 다양한(0.5KB~64KB) 컨트랙트를 읽을 때 EXTCODESIZE 오퍼코드의 성능을 분석합니다. 이는 공격자가 수천 개의 고유한 컨트랙트를 배포하여 디스크 읽기 작업을 강제하는 최악의 시나리오를 나타냅니다.
또한 이 반복 방식은 CREATE2 결정론적 주소 생성 방식을 활용하여 오버헤드를 최소화합니다.
이와 관련한 자세한 정보는 다음에서 확인할 수 있습니다.
- 기능: CPerezz가 EXTCODESIZE 벤치마크 계약 배포를 위한 extcodesize_setup 시나리오를 추가했습니다. · 풀 리퀘스트 #161 · ethpandaops/spamoor · GitHub
- feat(benchmark): CPerezz가 콜드 액세스 테스트를 위해 EXTCODESIZE 바이트코드 크기 벤치마크를 추가했습니다. · 풀 리퀘스트 #1961 · ethereum/execution-specs · GitHub
주요 결과
| 발견 | 값 |
|---|---|
| 코드 읽기 시간 범위 | 107ms - 904ms (약 18,000회 코드 읽기 기준) |
| 통화별 지연 시간 범위 | 5.9µs - 49.9µs |
| 코드 읽기 시간 스케일링 | 8.5배 증가 (0.5KB → 64KB) |
| 64KB 블록 실행 시간 | 약 1006ms |
| 코드 읽기 시간 (블록 시간) 비율 | 51% (0.5KB) → 90% (64KB) |
| Geth 효율성 대 순수 NVMe 효율성 | 24-51% |
이더리움 개선 제안(EIP)-7907 판결
| 크기 | 블록 시간 | 1초 예산의 % | 평결 |
|---|---|---|---|
| 24KB (현재) | 535ms | 54% | 안전한 |
| 32KB | 685ms | 69% | 안전한 |
| 64KB | 1006ms | 약 100% | 60M 가스에서 실행 가능 |
| 128KB+ | 예상 소요 시간 1.5초 이상 | 100% 초과 | 주유 가격 재조정이 필요할 수도 있습니다. BAL 및 ePBS 이후 추가 데이터가 필요합니다. |
권장 사항: 새로운 최대 계약 크기를 64KB로 설정하십시오. 64KB를 초과하는 경우, BAL 및 ePBS 최적화 기능이 모든 클라이언트에 적용된 후 새로운 데이터 수집이 필요합니다.
위에서 언급한 데이터 수집 후 가격 재조정이 필요한 경우, 나머지 고객들을 벤치마킹하고 EXTCODE* opcode의 나머지 부분도 고려해야 합니다.
1. 방법론 및 벤치마크 설정
1.1 테스트 환경
| 매개변수 | 값 |
|---|---|
| Geth 버전 | v1.16.8-불안정 버전 (다양한 수정 사항 포함) |
| 데이터 베이스 | 메인넷 동기화 완료(~2400만 블록) |
| Geth 캐시 | 비활성화됨 (디스크 읽기 강제) |
| 테스트된 계약 규모 | 0.5, 1, 2, 5, 10, 24, 32, 64 KB |
| EXTCODESIZE 작업 | 블록 당 약 18,106개 |
| 블록 당 가스 | 약 5천만 |
| 배포된 계약 | 규모별로 18,100개 이상의 고유 계약 |
| 크기별 반복 횟수 | 8 |
| 하드웨어 | WD 블랙 SN850X NVMe 8TB |
1.2 공격 시나리오 설계
이 벤치마크는 EXTCODESIZE 에 대한 최악의 공격 사례를 나타냅니다.
- 크기별로 18,100개 이상의 고유 계약이 배포됨(코드 캐시 미스 발생)
- 각 블록 모든 고유한 계약의 바이트코드를 정확히 한 번씩 읽습니다.
- 코드 캐시 적중률: 2% 미만 (사실상 비활성화됨)
- 벤치마크 실행 사이에 OS 페이지 캐시가 지워졌습니다.
1.3 원시 디스크 기준선(fio)
이론상 최대 성능을 확인하기 위해 NVMe의 기본 성능을 측정했습니다.
| 블록 크기 | 아이옵스 | 처리량 | 평균 지연 시간 |
|---|---|---|---|
| 512B | 337K | 172MB/s | 95마이크로초 |
| 1KB | 320K | 328MB/s | 100마이크로초 |
| 4KB | 272K | 1.1 GB/s | 117마이크로초 |
| 24KB | 171K | 4.2 GB/s | 185마이크로초 |
| 32KB | 15만 5천 | 5.1 GB/s | 204마이크로초 |
| 64KB | 85K | 5.6 GB/s | 366마이크로초 |
2. 벤치마크 결과
2.1 코드 읽기 시간 대 바이트코드 크기
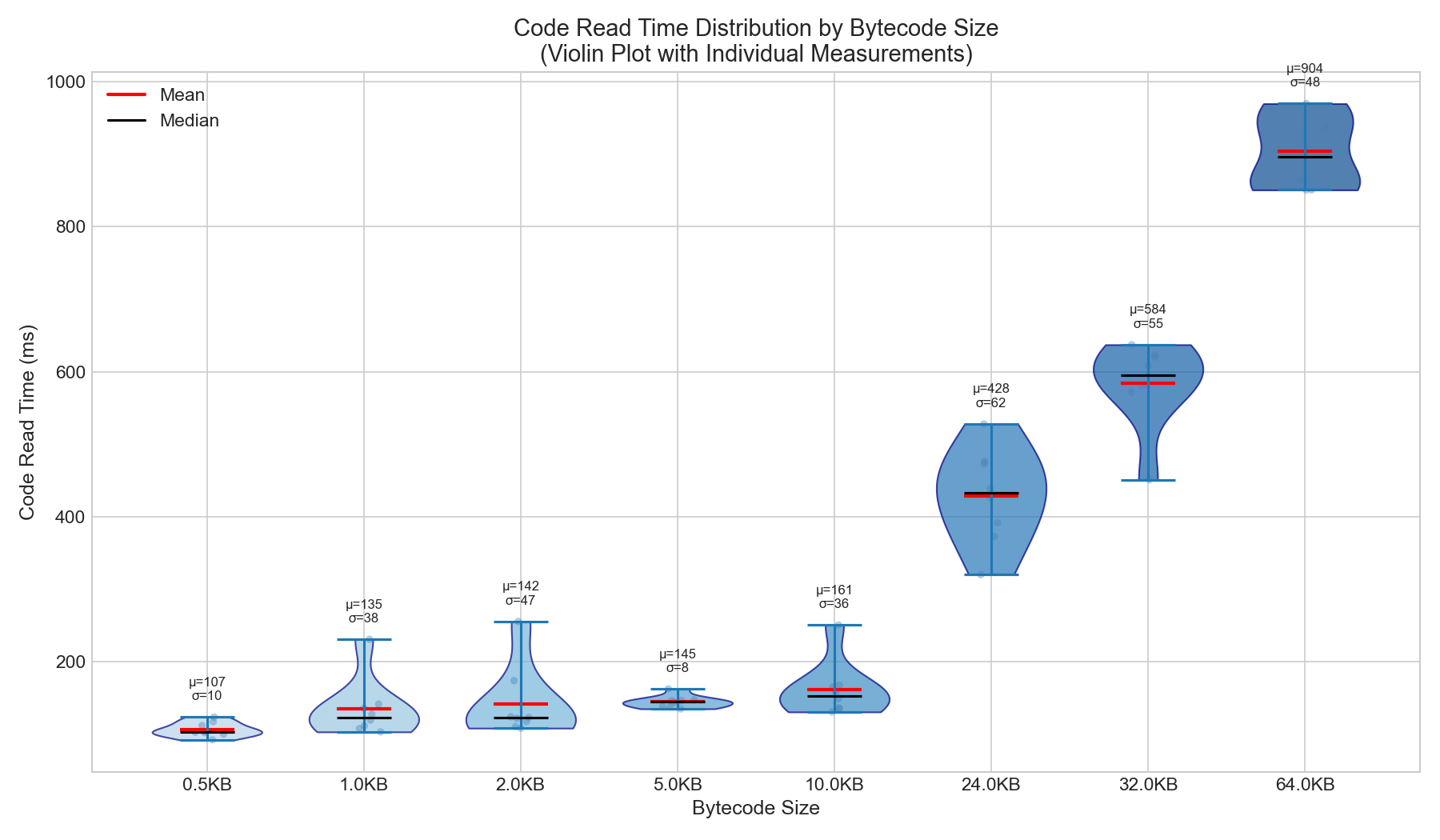
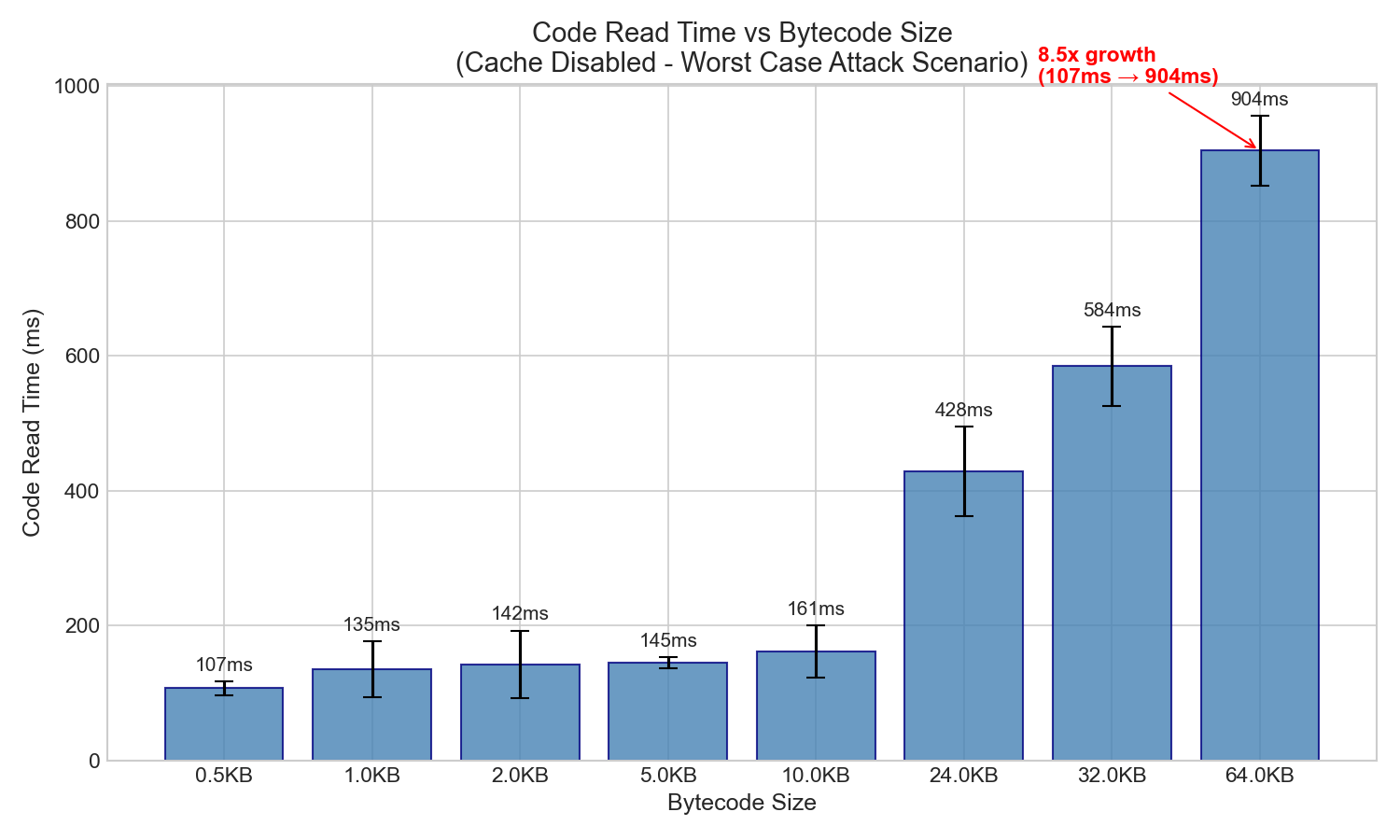
핵심 결과: 캐시가 비효율적일 경우 코드 읽기 시간은 바이트코드 크기에 비례합니다.
| 크기 | 코드 판독 시간(밀리초) | 성장률 대 0.5KB |
|---|---|---|
| 0.5KB | 107ms | 1.0배 (기준값) |
| 1KB | 135ms | 1.3배 |
| 2KB | 142ms | 1.3배 |
| 5KB | 145ms | 1.4배 |
| 10KB | 161ms | 1.5배 |
| 24KB | 428ms | 4.0x |
| 32KB | 584ms | 5.5배 |
| 64KB | 904ms | 8.5배 |
핵심 통찰: 바이트코드 크기가 128배 증가할 때 코드 읽기 시간은 8.5배 증가합니다. 이는 1:1이 아닌 비선형적인 증가이지만, 절대적인 시간 영향은 상당합니다.
2.2 바이트 읽기 vs 코드 읽기 시간 (상관관계)
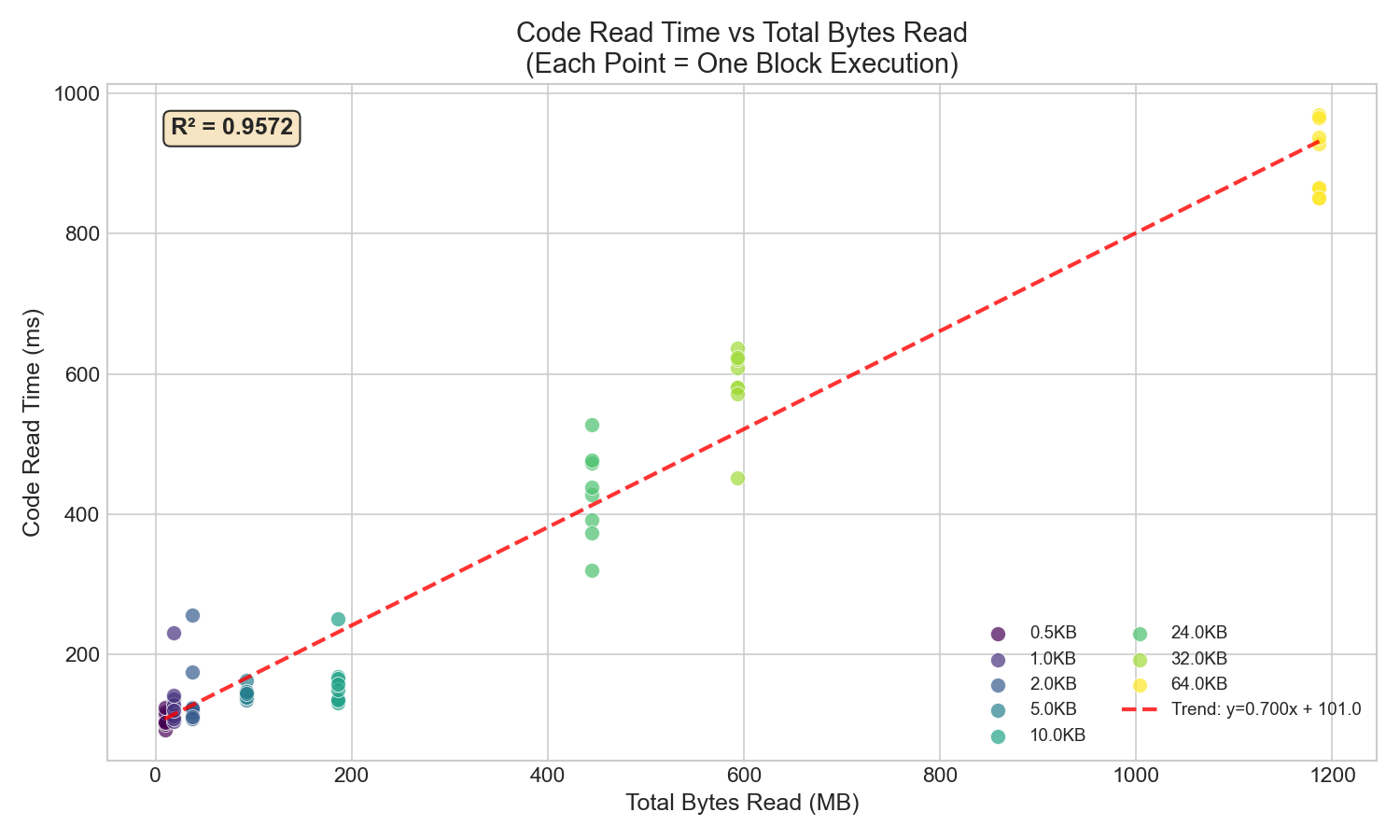
높은 양의 상관관계(R² ≈ 0.96)는 캐시가 비효율적일 때 코드 읽기 시간이 읽은 총 바이트 수에 비례한다는 것을 확인시켜 줍니다.
2.3 통화당 지연 시간
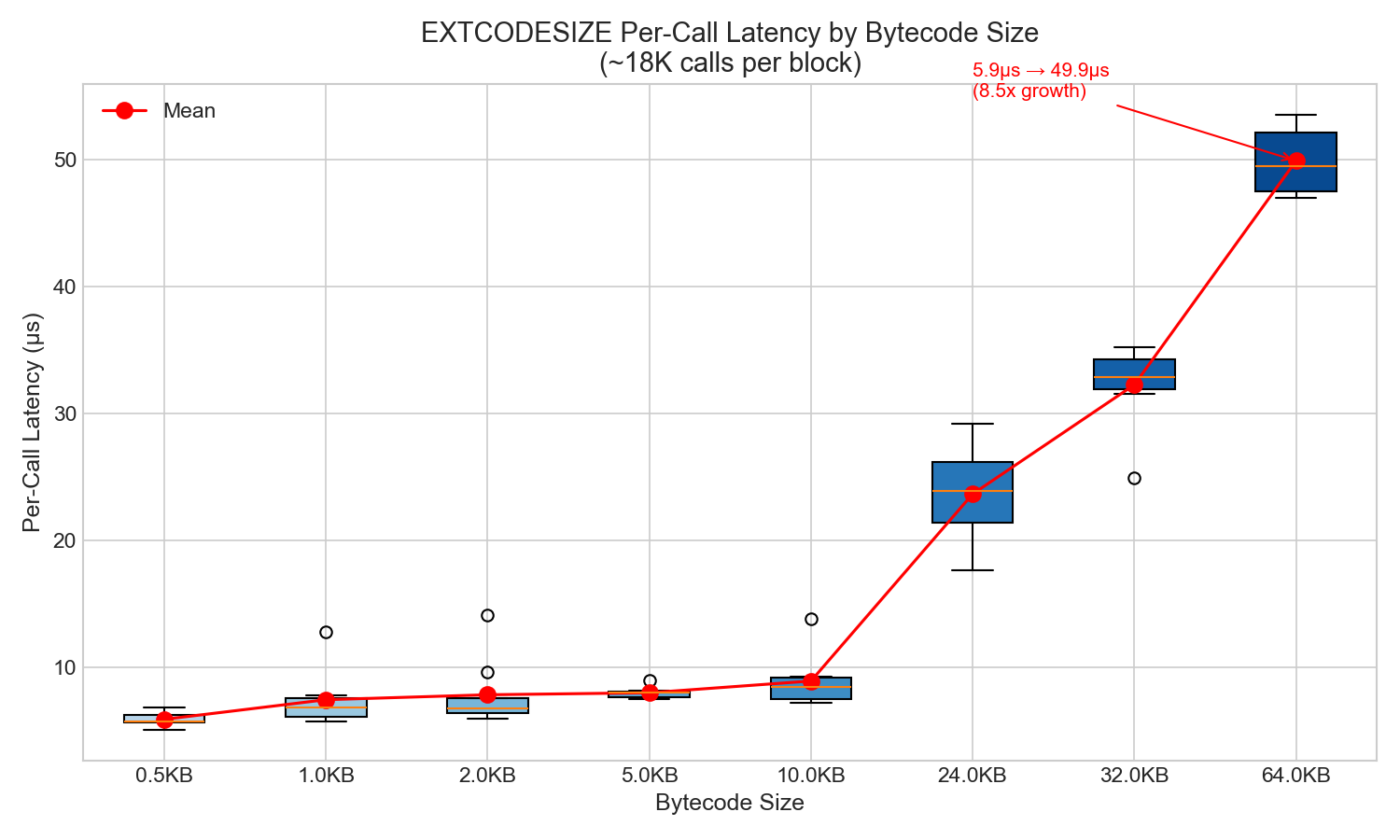
바이트코드 크기가 커질수록 호출당 지연 시간이 증가합니다.
| 크기 | 통화당 지연 시간 | 성장 |
|---|---|---|
| 0.5KB | 5.9 µs | 1.0x |
| 1KB | 7.5 µs | 1.3배 |
| 10KB | 8.9 µs | 1.5배 |
| 24KB | 23.7 µs | 4.0x |
| 32KB | 32.3 µs | 5.5배 |
| 64KB | 49.9 µs | 8.5배 |
3. 실행 시간 분석
3.1 구성 요소 분석
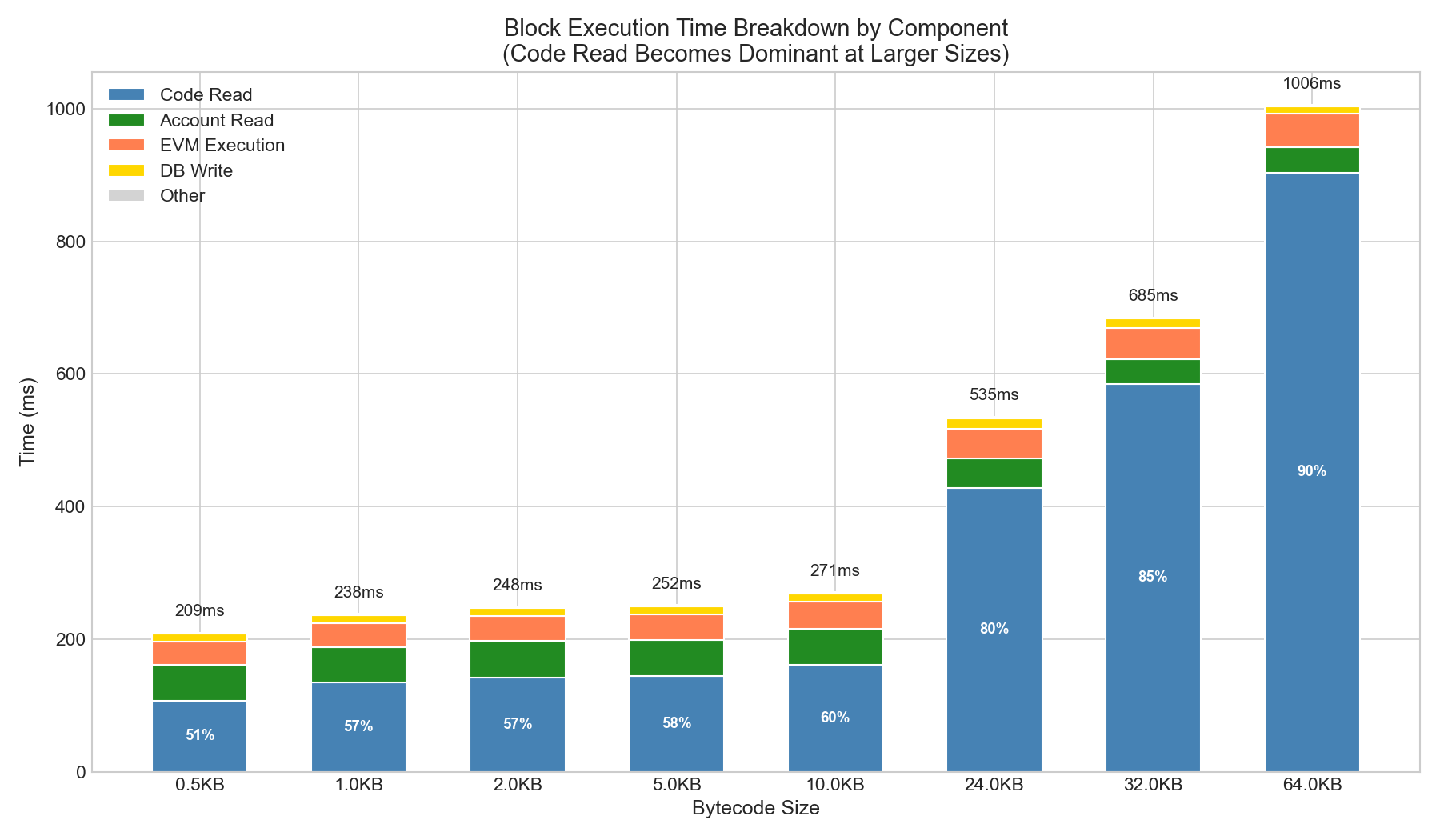
바이트코드 크기가 커질수록 코드 읽기 속도가 주요 요인이 됩니다.
| 크기 | 코드 읽기 | 계정 읽기 | 이더리움 가상 머신(EVM) 실행 | DB 쓰기 | 다른 | 총 |
|---|---|---|---|---|---|---|
| 0.5KB | 107ms (51%) | 54ms | 34ms | 12ms | 2ms | 209ms |
| 1KB | 135ms (57%) | 53ms | 37ms | 12ms | 1ms | 238ms |
| 10KB | 161ms (59%) | 53ms | 40ms | 12ms | 5ms | 271ms |
| 24KB | 428ms (80%) | 44ms | 46ms | 15ms | 2ms | 535ms |
| 32KB | 584ms (85%) | 38ms | 47ms | 13ms | 3ms | 685ms |
| 64KB | 904ms (90%) | 38ms | 51ms | 12ms | 1ms | 1006ms |
관찰 결과: 64KB 캐시 크기에서 코드 읽기가 블록 실행 시간의 90%를 차지합니다. 이는 코드 읽기가 8~10%에 불과한 캐시가 따뜻한 상태일 때와는 현저히 다른 결과입니다.
4. 블록 시간 예산 분석 (이더리움 개선 제안(EIP)-7907 중점 사항)
4.1 시간 대 예산 목표
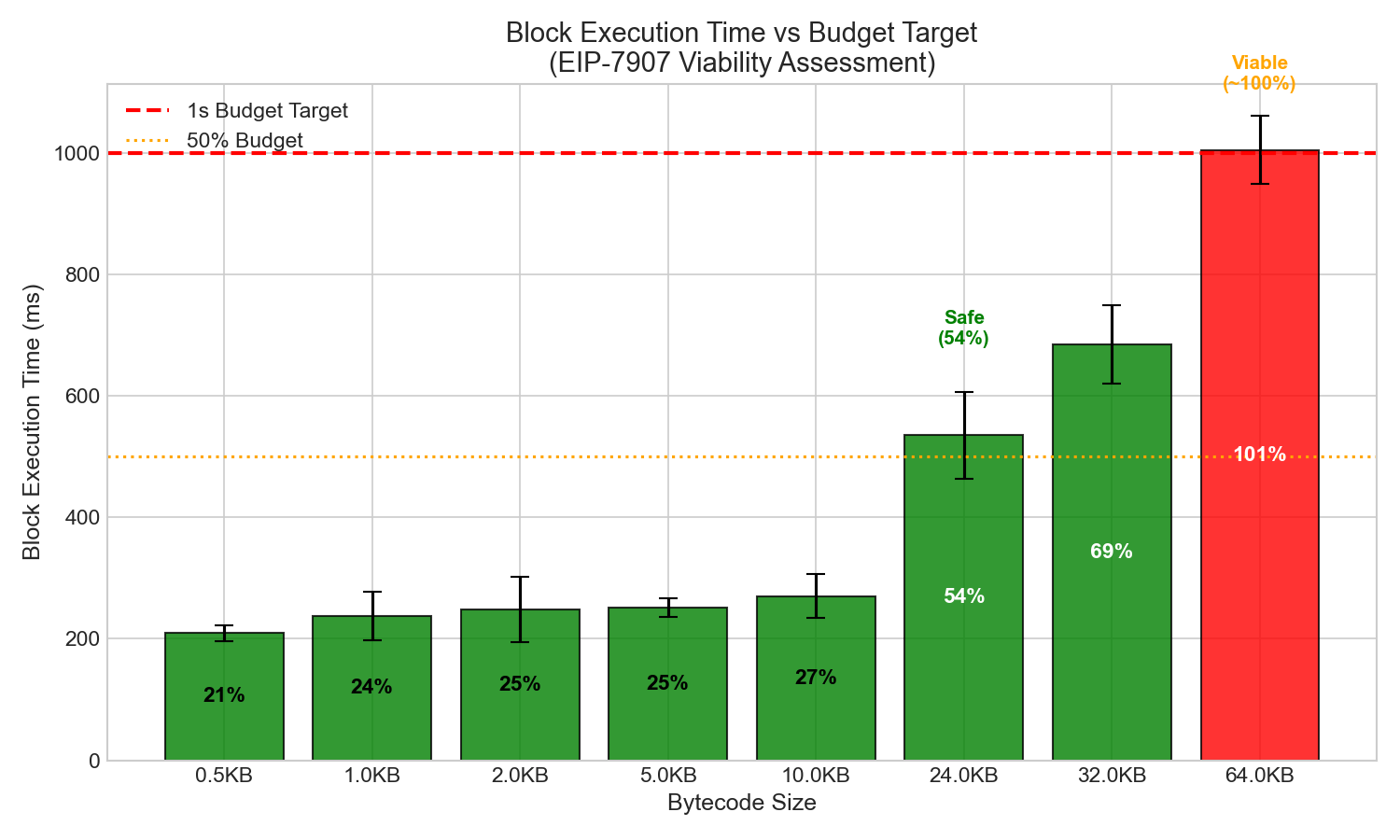
블록 실행 목표 시간을 1초로 설정하여 사용합니다.
| 크기 | 블록 시간 | 1초 예산의 % | 상태 |
|---|---|---|---|
| 0.5KB | 209ms | 21% | 예산보다 훨씬 적게 지출했습니다. |
| 1KB | 238ms | 24% | 예산보다 훨씬 적게 지출했습니다. |
| 2KB | 248ms | 25% | 예산보다 훨씬 적게 지출했습니다. |
| 5KB | 252ms | 25% | 예산보다 훨씬 적게 지출했습니다. |
| 10KB | 271ms | 27% | 예산보다 훨씬 적게 지출했습니다. |
| 24KB | 535ms | 54% | 예산보다 적게 |
| 32KB | 685ms | 69% | 예산보다 적게 |
| 64KB | 1006ms | 약 100% | 한계점에서 |
결론: 64KB 크기의 컨트랙트는 6천만 가스 블록을 사용하는 최악의 공격 상황에서도 실행 가능합니다. 실행 시간은 약 1초로 예산 한도에 가깝지만 허용 가능한 수준입니다. 다만, 이는 향후 ePBS 및 BAL 도입으로 인해 안전한 예산 범위가 재편될 가능성을 고려했을 때 상당히 보수적인 수치입니다.
4.2 가스 처리 속도 (가격 오류 분석)
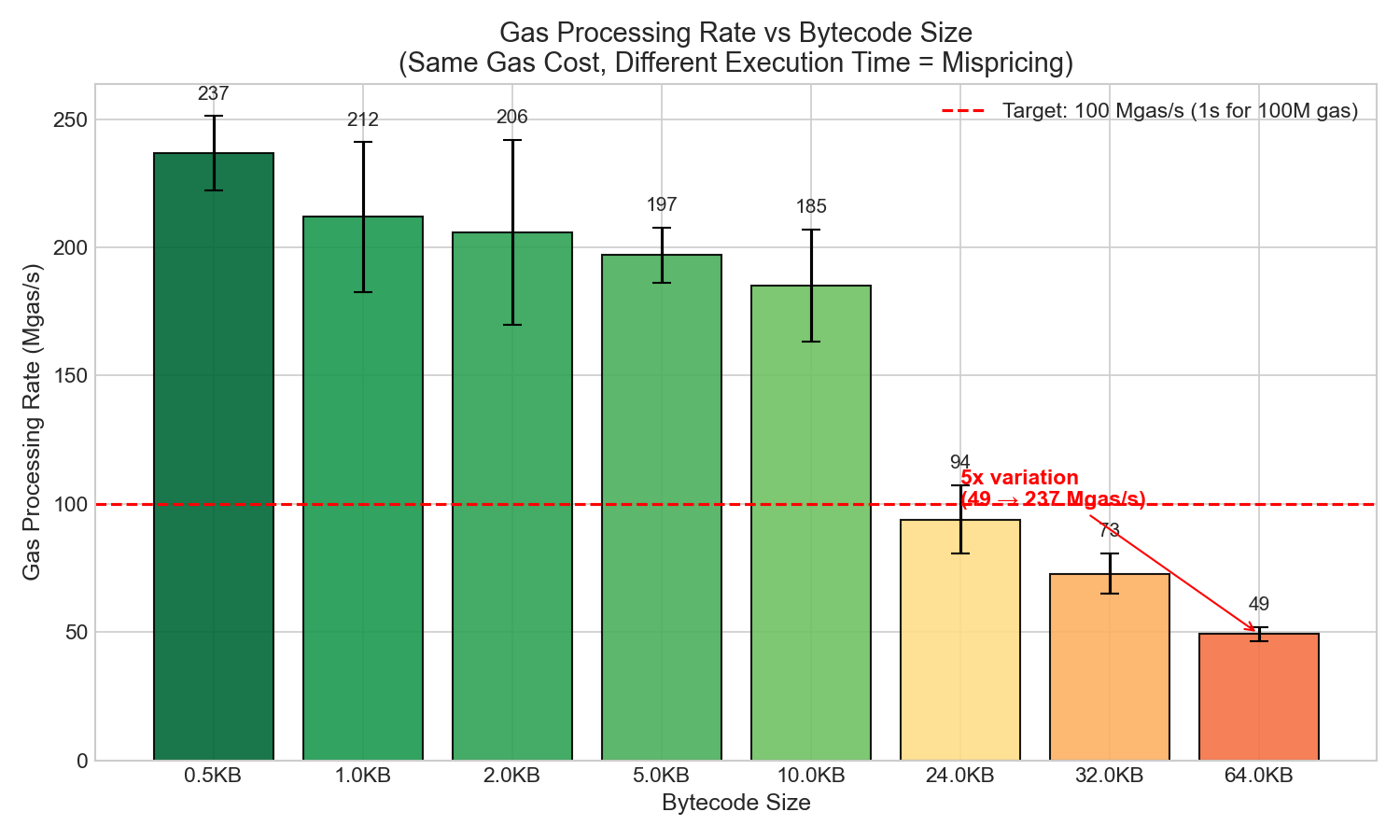
| 크기 | 가스 사용 | 블록 시간 | Mgas/s |
|---|---|---|---|
| 0.5KB | 4940만 | 209ms | 236 |
| 1KB | 4940만 | 238ms | 208 |
| 10KB | 4940만 | 271ms | 182 |
| 24KB | 4940만 | 535ms | 92 |
| 32KB | 4940만 | 685ms | 72 |
| 64KB | 4940만 | 1006ms | 49 |
가격 불일치 현상 발견: 동일한 가스 비용에도 불구하고 실행 시간이 5배 차이 발생(236 Mgas/s → 49 Mgas/s). 이는 최악의 경우, 규모가 큰 계약일수록 검증자에게 불균형적으로 높은 비용을 부과한다는 것을 보여줍니다.
128KB 이상에 대한 시사점: 64KB를 초과하는 경우 가스 모델 조정이 필요할 수 있으며, 이는 기본 비용에 크기에 따른 구성 요소를 더하는 방식일 가능성이 높습니다.
이는 상당히 보수적인 추정치입니다. 네트워크를 "중단"시키거나 "느린 검증자에게 상당한 타격"을 주려면 18,000개의 고유 계약보다 수백 배나 많은 설정이 필요합니다. 이는 막대한 비용을 초래합니다(첫 번째 블록 실행 후 캐시되므로 재사용할 수 없습니다).
5. 원시 디스크 기준선 (Geth vs NVMe 효율성)
5.1 효율성 비교
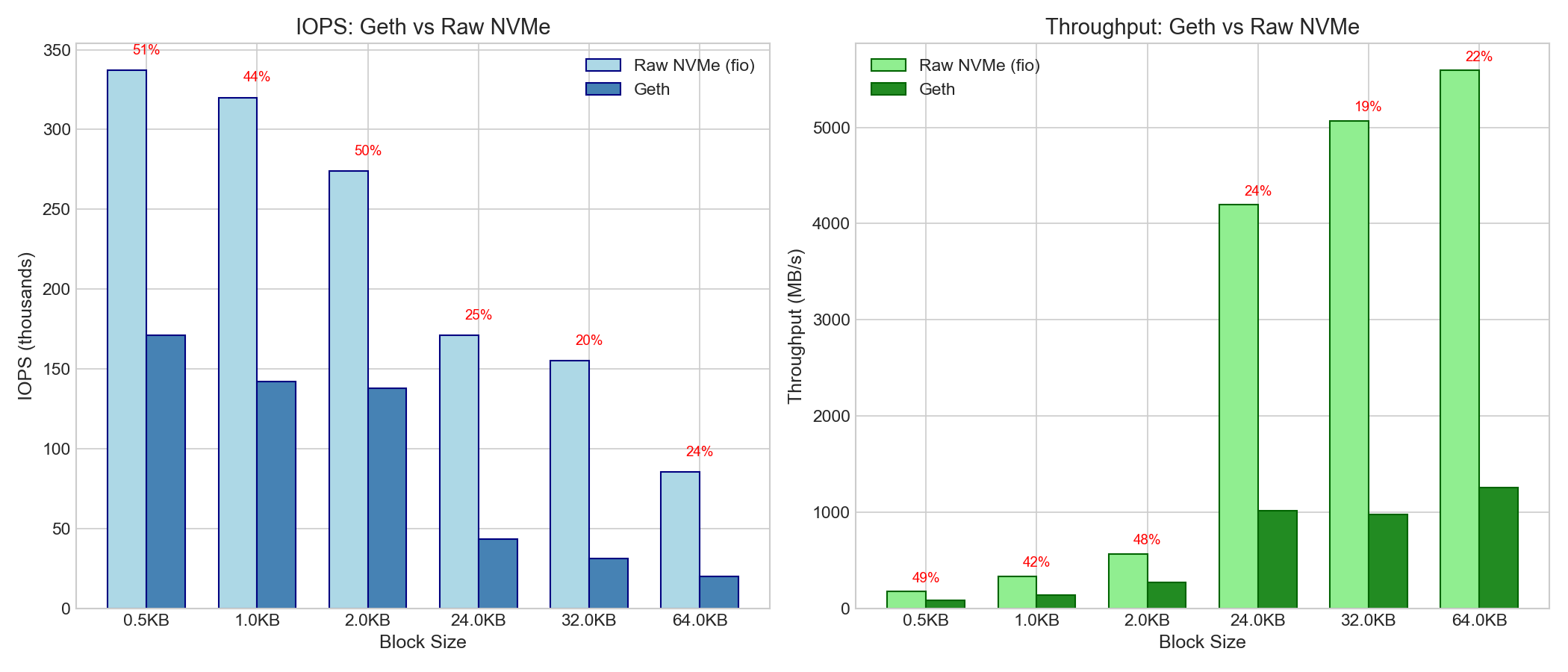
| 크기 | 게스 IOPS | 원시 NVMe IOPS | 능률 | Geth 처리량 | Raw NVMe | 능률 |
|---|---|---|---|---|---|---|
| 0.5KB | 171K | 337K | 51% | 83MB/s | 172MB/s | 48% |
| 1KB | 142K | 320K | 44% | 139MB/s | 328MB/s | 42% |
| 24KB | 43K | 171K | 25% | 1.0 GB/s | 4.2 GB/s | 24% |
| 32KB | 3만 1천 | 15만 5천 | 20% | 979MB/s | 5.1 GB/s | 19% |
| 64KB | 20K | 85K | 24% | 1.26 GB/s | 5.6 GB/s | 23% |
관찰 결과: Geth는 원시 디스크 성능의 20~51%를 달성합니다. 이러한 차이는 다음과 같은 이유 때문일 가능성이 높습니다.
- Pebble/LevelDB 오버헤드(인덱스 순회, 블룸 필터)
- 키 해싱 및 조회
- 값 역직렬화
6. 웜 캐시 시나리오와의 비교
6.1 캐시된 성능과 캐시되지 않은 성능 비교
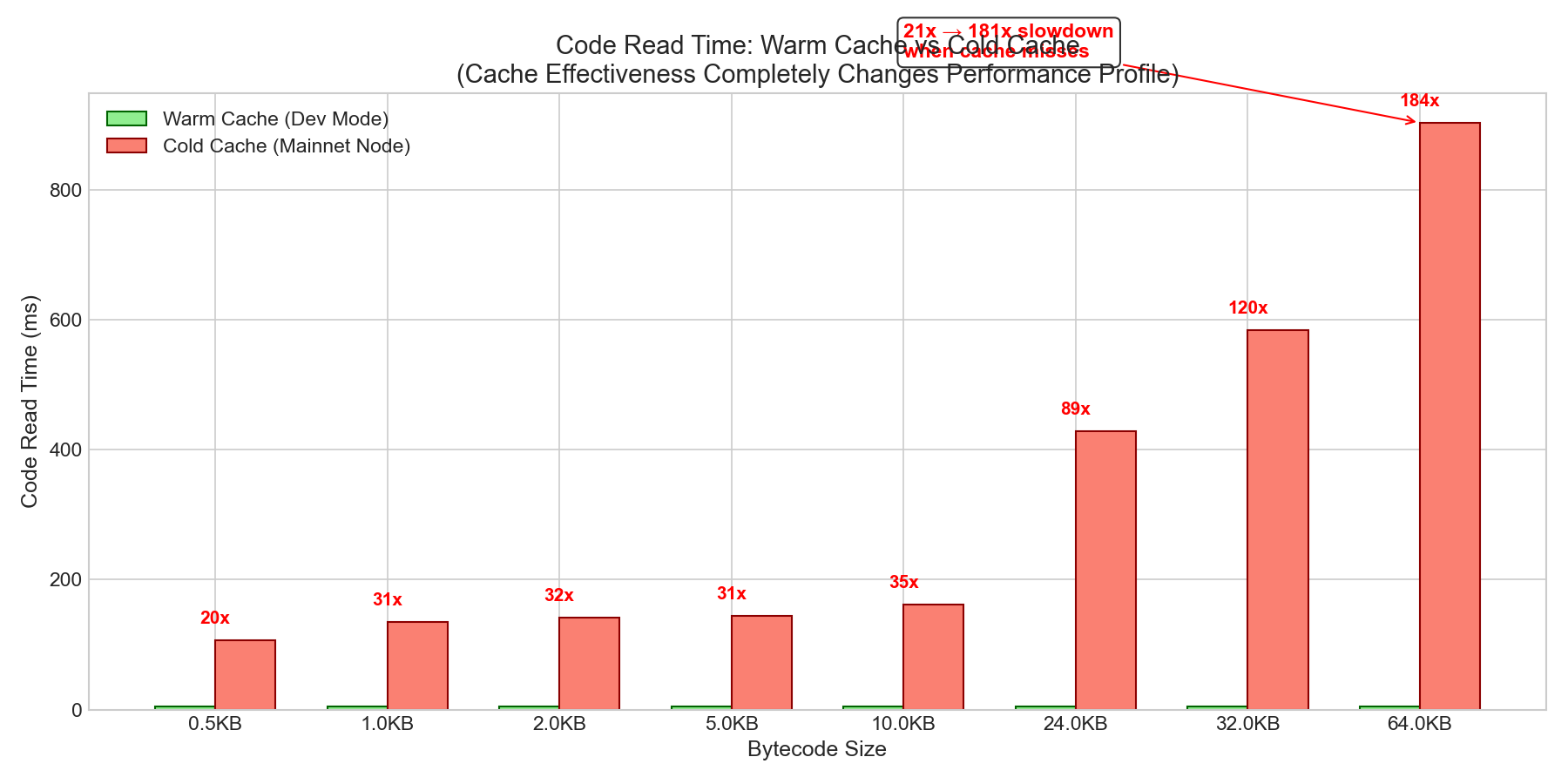
| 크기 | 웜 캐시 | 콜드 캐시 | 감속 |
|---|---|---|---|
| 0.5KB | 5.3ms | 107ms | 21배 |
| 1KB | 4.4ms | 135ms | 31x |
| 2KB | 4.5ms | 142ms | 32배 |
| 5KB | 4.6ms | 145ms | 31x |
| 10KB | 4.7ms | 161ms | 34배 |
| 24KB | 4.8ms | 428ms | 89x |
| 32KB | 4.9ms | 584ms | 119x |
| 64KB | 4.9ms | 904ms | 181x |
웜 캐시 벤치마크에서 얻은 "고정 비용" 결과는 정상적인 작동 환경에서는 유효합니다. 콜드 캐시 환경에서는 극단적인 공격 시나리오(18,000개 이상의 고유 계약)가 필요합니다.
7. 이더리움 개선 제안(EIP)-7907에 대한 시사점 및 권고사항
7.1 연구 결과 요약
- 공격 상황에서 코드 읽기 시간은 크기에 비례하여 증가합니다 (0.5KB에서 64KB까지 8.5배 증가).
- 64KB는 6천만 가스 블록에서 실행 가능하며 , 최악의 경우에도 약 1초 정도의 실행 시간이 소요되어 예산 범위 내에 있습니다.
- 이는 최악의 경우를 나타냅니다. 18,000개 이상의 고유한 계약을 배포하고 유지 관리하는 것은 현실적으로 불가능합니다(공격을 실행하려는 각 블록 마다 새로운 계약 세트가 필요합니다).
- 정상적인 작동에는 영향이 없으며 , 캐시가 따뜻한 상황에서도 비용은 약 5ms로 일정하게 유지됩니다.
- 가스 가격 책정 오류가 공격받고 있습니다 (동일한 가스 사용량에 대해 실행 시간이 5배까지 차이남).
7.2 이더리움 개선 제안(EIP)-7907 권고 사항
| 행동 | 추천 |
|---|---|
| 64KB 제한 | 진행 - 최악의 공격 상황에서도 실행 가능. 이더리움 개선 제안(EIP) 는 필요 없음 |
| 128KB 이상 제한 | BAL과 ePBS를 이용한 재측정이 필요합니다. |
프로토콜을 64kB 제한 및 초기화 코드 크기 증가 외에는 변경하지 않고도 스마트 계약 개발자들에게 코드 크기 제한에 대한 훌륭한 업그레이드를 제공하는 방식으로 "간단하게" 진행할 수 있을 것 같습니다.
BAL과 ePBS가 보다 준비된 상태가 되면, 데이터를 기반으로 가격 재조정 또는 256kB로의 전환 여부에 대한 더 나은 결정을 내릴 수 있을 것입니다.
하지만 최악의 경우에도 가격 조정이 실제로 필요하지 않은 것을 지금 가격 조정하는 것은 불필요해 보입니다.
7.3 64KB가 허용되는 이유
공격의 비현실성: 18,000개 이상의 고유한 64KB 계약을 배포하려면 다음이 필요합니다.
- 계약 배포당 약 1,300만 가스 소모 (기본 32,000 + 64,000 × 바이트당 200 가스)
- 설치에만 수백 개의 블록이 필요합니다.
- 공격 표면을 유지하는 데 상당한 지속적인 비용이 소요됩니다.
예산 내 블록 시간: 최악의 경우에도 6천만 가스 블록의 경우 약 1초는 허용 가능한 수준입니다.
실제 캐시 효율성: 실제 메인넷 블록은 컨트랙트를 재사용하며, 코드 캐시 적중률은 일반적으로 높습니다.
비선형적 확장: 128배 크기 증가에 8.5배의 시간이 소요된다는 것은 상각이 여전히 도움이 된다는 것을 나타냅니다.