활동 상태를 1년만 유지한다면 어떨까요?
이 글을 검토해 주신 게리 롱, 가브리엘 로슐로, 기욤 발레에게 특별히 감사드립니다.
이더리움 상태 증가에 대한 장기적인 해결책으로 상태 만료 에 대해 많이 논의했지만, 이것이 일상적인 노드 운영에 어떤 영향을 미칠지에 대한 데이터는 거의 없었습니다.
논의를 보다 구체적으로 하기 위해 실제 메인넷 워크로드를 사용하여 간단한 실험을 실행했습니다. (1) 전체 상태를 가진 노드 와 (2) 블록 실행 중에 실제로 변경된 내용을 기반으로 1년 동안의 활성 상태만 유지하는 노드에서 약 1년 동안의 블록을 실행했습니다.
면책 조항: 이는 상태 만료에 대한 완전한 프로토콜 구현이 아닙니다(복구 증인이나 네트워크 검색 기능은 없음). 이는 "만약" 성능 실험으로, 데이터베이스에 해당 기간 동안 실제로 변경한 상태만 저장될 경우 실행 성능이 어떻게 달라지는지를 살펴보는 것입니다.
요약
- 주(州)의 규모가 약 78% 감소했습니다.
- 블록 재실행 시간이 메인넷 블록의 약 1년치 대비 약 15% 개선되었습니다.
- 읽기 성능 향상이 가장 큰 부분을 차지하며, 특히 스토리지 읽기 성능이 향상되었습니다( P50 -46% , P99 -36% ).
- 꼬리 지연 시간이 개선되어 부하 시 헤드 근처에 머무르는 데 중요합니다( P99 블록 삽입 -21% ).
벤치마크 설정
이 실험에서는 전체 상태를 저장하는 노드와 1년치 활성 상태 만 저장하는 노드를 비교합니다.
- 클라이언트: go-ethereum v1.16.5
- 장비: 이더리움 개선 제안(EIP)-7870 사양을 준수합니다.
- 작업량: 19,999,256 에서 22,627,956 까지의 블록 실행 (약 1년)
- 실행 횟수: 3회, 평균값을 보고하세요.
1년 활성 상태 데이터베이스는 어떻게 구축되었습니까?
- 블록 19,999,256에서 22,627,956으로 노드를 동기화합니다(“추적” 노드).
- 블록 처리 중에 상태 요소(계정, 저장 슬롯, 트라이 노드)에 접근할 때마다 해당 요소를 '접근됨'으로 표시합니다.
- 블록 19,999,256의 DB에서 시작하여 추적 노드의 마킹을 사용하여 표시되지 않은 상태를 삭제합니다. 이렇게 하면 가지치기된 DB가 생성됩니다.
- 정리된 DB는 상태 삭제 후 수동으로 압축되지 않습니다.
참고: 실패한 트랜잭션도 실행 시도 중에 상태를 변경하기 때문에 마킹을 유발합니다. 실제 만료 구현에서는 실패한 트랜잭션에 대해 마킹이 고려되지 않을 수 있으며, 이로 인해 비활성 상태 집합이 증가합니다.
결과
1. 주 규모
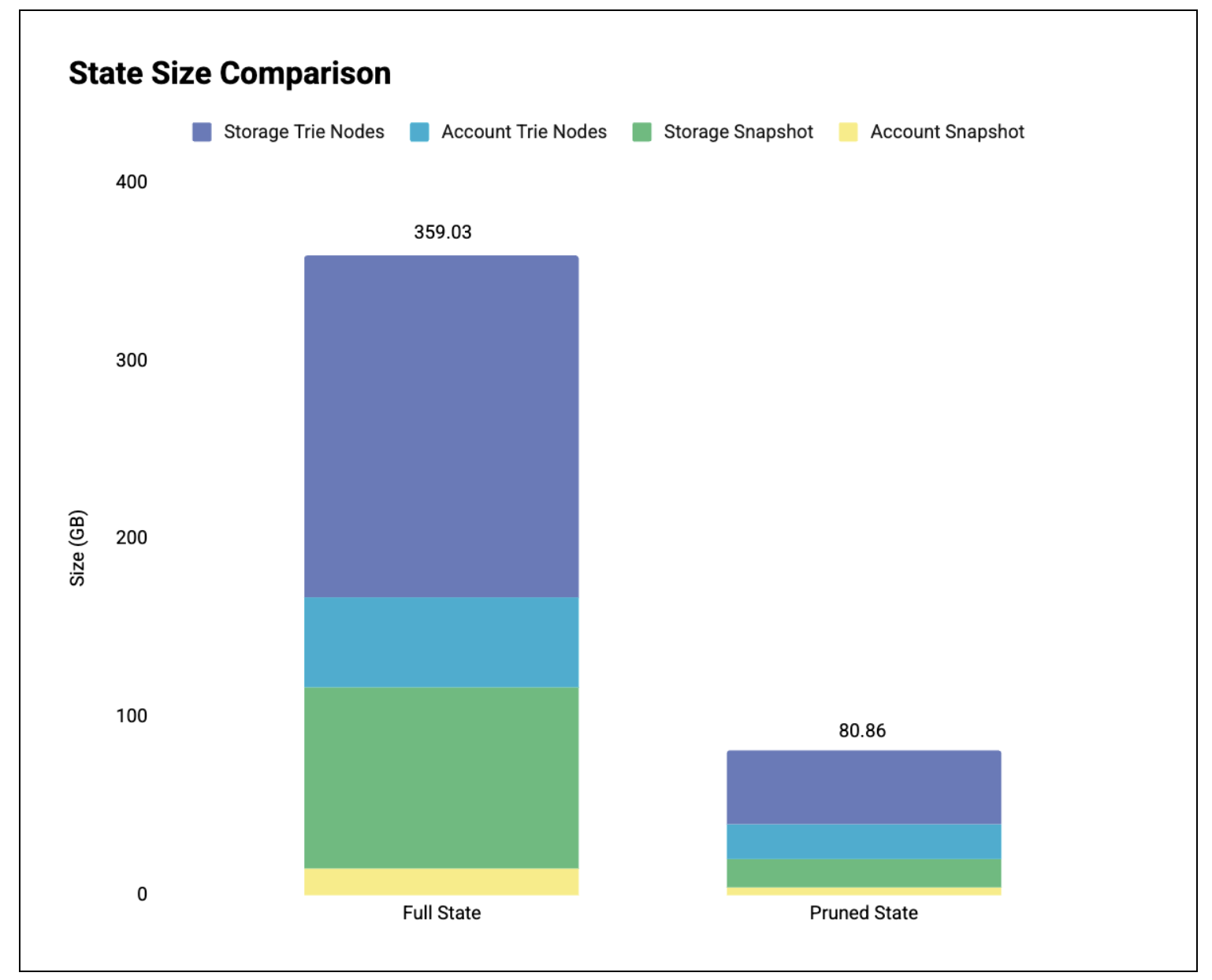
그림 1: 데이터베이스 내 상태 크기 비교.
표의 세부 내역 (GB):
| 전체 상태 | 가지치기된 상태 | 절감 | |
|---|---|---|---|
| 계정 스냅샷 | 14.65 | 3.60 | 75.43% |
| 계정 트라이 노드 | 50.34 | 19.89 | 60.49% |
| 저장소 스냅 스냅샷 | 101.87 | 15.95 | 84.34% |
| 스토리지 트라이 노드 | 192.17 | 41.42 | 78.45% |
| 총 | 359.03 | 80.86 | 77.48% |
결과: 디스크 용량이 크게 줄어듭니다.
- 전체 용량: 359.03GB
- 정리된 상태: 80.86GB ( -77.5% )
대부분의 메모리 사용량 감소는 스토리지 트라이 노드에서 발생합니다. 이는 스토리지 크기가 계정 트라이보다 훨씬 크기 때문에 정리할 부분이 더 많다는 사실을 반영합니다. 계정 트라이는 크기가 작기 때문에 접근 밀도가 더 높습니다. 즉, 각 계정 접근은 트라이의 더 많은 부분을 활성 상태로 유지합니다. 이러한 결과는 이전 상태 분석 결과 와도 일치합니다.
geth에서 "스냅샷"이란 무엇인가요?
geth에서 스냅샷은 트라이 리프(계정 및 스토리지)를 평면화하여 표현한 것으로, 트라이 경로를 탐색하지 않고도 읽기 속도를 향상시키는 데 사용됩니다. 주로 읽기 최적화를 위한 구조입니다.
2. 전체 실행 시간
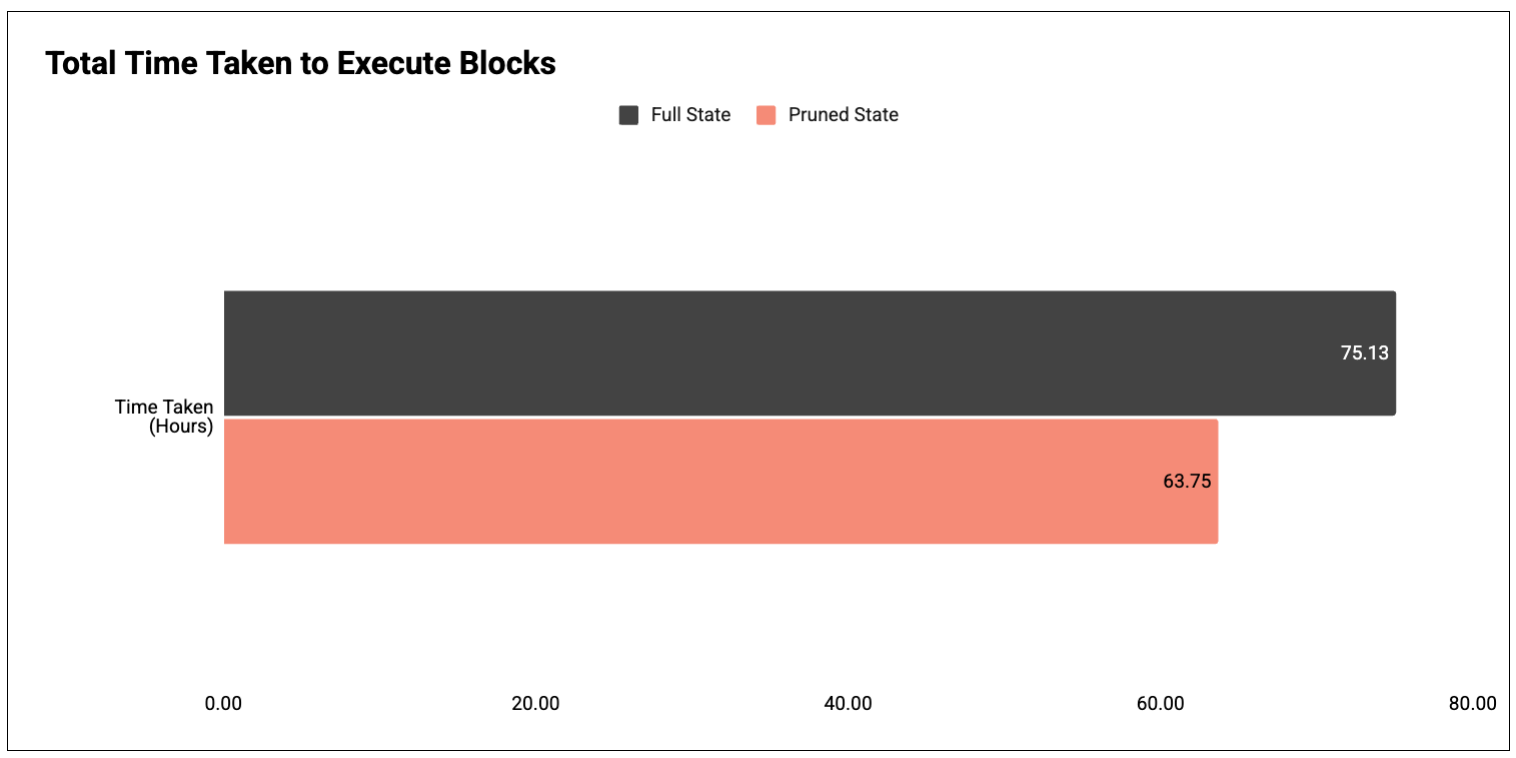
그림 2: 19,999,256번째 블록부터 22,627,956번째 블록까지 실행하는 데 걸린 총 시간.
결과: 가지치기를 한 노드가 가지치기를 하지 않은 노드보다 처리 속도가 약 15% 더 빠릅니다 .
- 완전 충전 상태: 75.13시간
- 가지치기 후 상태: 63.75시간 ( -15% )
3. 블록 삽입 및 프리페치
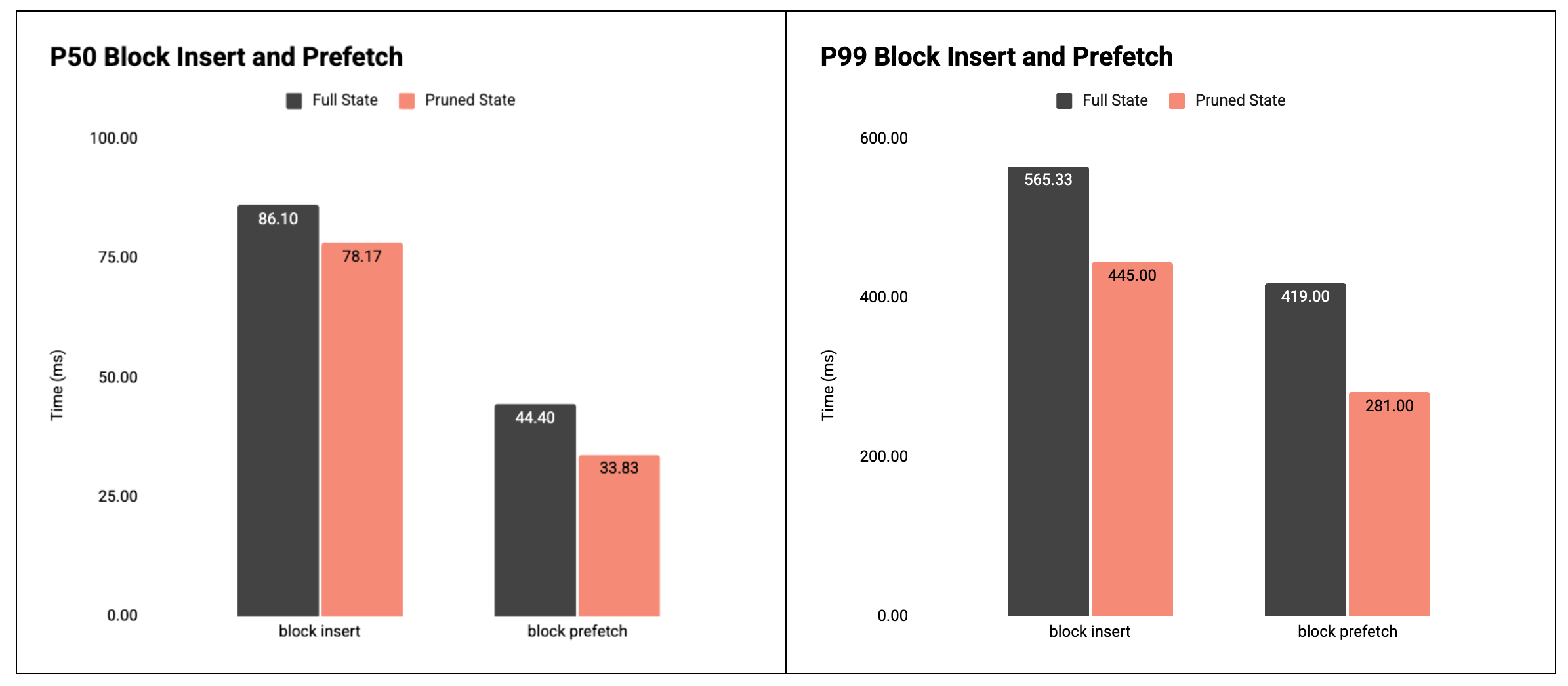
그림 3: 블록 삽입 및 블록 사전 가져오기에 소요되는 P50 및 P99 시간.
결과: 특히 P99에서, 가지치기된 데이터베이스를 사용했을 때 블록 삽입과 프리페치 모두 더 빨라졌습니다.
- 블록 삽입(실행 경로):
- P50: 86.10ms → 78.17ms ( -9% )
- P99: 565.33ms → 445.00ms ( -21% )
- 블록 사전 가져오기:
- P50: 44.40ms → 33.83ms ( -24% )
- P99: 419.00ms → 281.00ms ( -33% )
geth에서 "prefetch"란 무엇인가요?
Geth는 병렬 프리페처를 실행하여 트랜잭션을 수행하고 필요한 상태를 파악한 다음 해당 객체를 메모리로 가져오고 변경 사항을 폐기합니다. 목표는 캐시를 미리 로드하여 실제 실행(상태 루트 계산 포함)이 메모리에 더 자주 접근하고 디스크 I/O를 줄이는 것입니다.
실제로 geth에서는 프리페치 성능이 특히 중요합니다. 프리페처는 트랜잭션을 동시에 실행하며, 기본 데이터베이스에서 상태를 자주 가져와야 하는데, 이는 블록 수준 액세스 목록(BAL)에서 예상되는 액세스 패턴과 유사합니다. 반면 블록 실행 중에는 대부분의 상태 액세스가 캐시를 적중하기 때문에 미미한 성능 향상을 관찰하기가 더 어렵습니다.
전반적으로, 프리페칭 성능 향상은 데이터베이스에서 비활성 상태를 제거하는 것의 이점을 잘 보여줍니다.
4. 상태별 읽기 및 업데이트
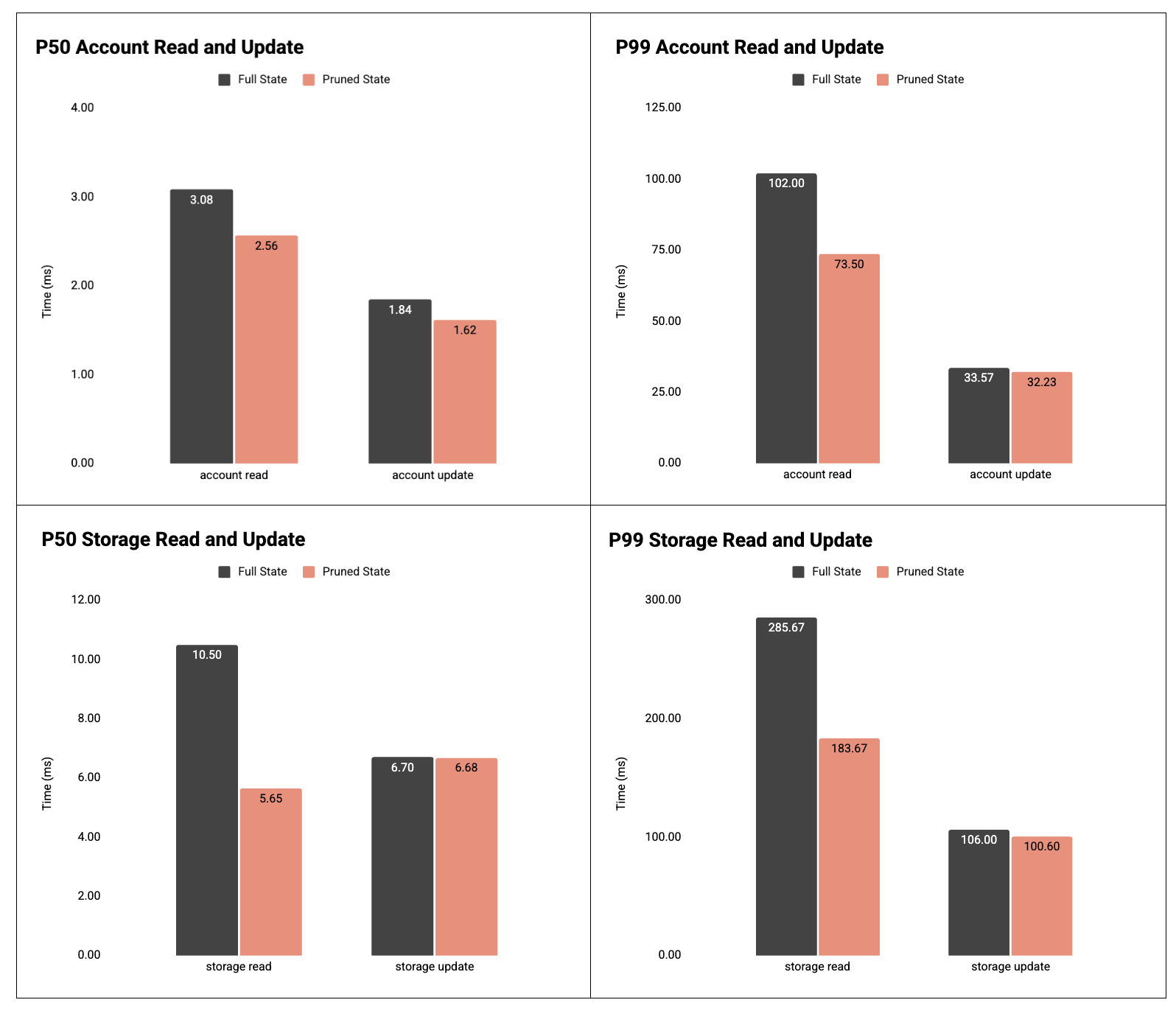
그림 4: P50 및 P99 계정 및 저장 슬롯 읽기/업데이트 시간.
결과: 계정 및 저장소 읽기 속도가 크게 향상되었습니다.
- 계정 읽기 완료:
- P50: 3.08ms → 2.56ms ( -17% )
- P99: 102.00ms → 73.50ms ( -28% )
- 계정 업데이트:
- P50: 1.84ms → 1.62ms ( -12% )
- P99: 33.57ms → 32.23ms ( -4% )
- 저장소 읽기:
- P50: 10.50ms → 5.65ms ( -46% )
- P99: 285.67ms → 183.67ms ( -36% )
- 저장소 업데이트:
- P50: 6.70ms → 6.68ms (거의 평탄함)
- P99: 106.00ms → 100.60ms ( -5% )
이는 블록 삽입/사전 가져오기 결과와 일치합니다. 업데이트 성능 향상이 제한적인 이유는 geth가 트랜잭션 실행 중에 필요한 트라이 노드를 미리 가져오고 사전 가져오기가 완료될 때까지 블록되기 때문입니다. 결과적으로 트라이 업데이트는 전적으로 메모리에서 수행되며, 단순히 상태 변경 사항을 트라이의 적절한 위치에 배치합니다.
주요 결과 및 시사점
- 주(州)의 규모가 급격히 줄어든다
가지치기된 상태는 약 4.4배 작아져 359GB에서 81GB로 줄어듭니다. 이러한 크기 감소는 노드 운영자의 스토리지 및 I/O 부담을 크게 줄여주며, "합리적인 하드웨어"라는 기준을 더욱 접근 가능한 방향으로 이끌어줍니다.
감소폭이 스토리지 트라이 노드와 스토리지 스냅샷에 집중되어 있다는 것은 이더리움 상태의 상당 부분이 콜드 컨트랙트 스토리지라는 것을 시사합니다. 만약 절감 효과의 대부분이 스토리지에서 비롯된다면, 상태 만료를 위한 한 가지 잠재적인 해결책은 만료되는 컨트랙트 스토리지를 우선시하는 솔루션에 집중하는 것입니다. 이 방식은 계정에는 영향을 미치지 않으므로 (예: 예기치 않게 계정 복구가 필요한 경우) 눈에 띄는 사용자 경험(UX) 위험을 피하면서 만료로 인한 이점을 크게 확보할 수 있습니다. 단점은 사용자들이 만료를 피하기 위해 계정을 컨트랙트 스토리지처럼 사용하게 될 수 있으며, 결국 계정 및 슬롯 수준의 만료를 모두 적용하게 될 가능성이 있다는 것입니다.
- 상태 크기가 줄어들면 실행 속도가 빨라집니다.
상태 크기를 줄이면 디스크에서 상태를 검색하는 비용이 감소하여 블록 처리 속도가 향상됩니다. 동일한 1년치 메인넷 블록 대비 전체 실행 시간은 약 15% 단축됩니다. 세부적인 지표에서도 이러한 결과가 나타나는데, 특히 읽기, 그중에서도 스토리지 읽기에서 가장 큰 성능 향상이 확인됩니다.
이는 LSM 기반 데이터베이스에서 예상할 수 있는 결과와 일치합니다. 데이터셋 크기가 작을수록 지역성이 향상되는 경향이 있습니다. 실질적으로 이는 두 가지 방향으로 여유 공간을 확보해 줍니다. 가스 사용량 제한을 높일 수 있고, 상태 크기를 적절하게 관리하면 상태 연산 비용을 줄일 수 있습니다.
- 꼬리 지연 시간을 개선합니다
평균 속도 향상 외에도, 운영상 더욱 중요한 결과는 테일 동작 개선입니다. 가지치기된 데이터베이스는 블록 삽입 및 프리페치에 대한 P99 지연 시간을 크게 줄여 검증 중 발생하는 긴 지연 시간을 감소시킵니다. 이러한 지연은 종종 작업 부하가 급증할 때 노드가 체인 헤드에 비해 뒤처지는 원인이 됩니다.
이것이 주(州)의 성장에 어떤 의미를 갖는가?
저희 실험 결과에 따르면, 이더리움이 로컬에 저장된 상태를 최근 접근한 데이터의 롤링 윈도우로 안전하게 제한할 수 있다면 클라이언트는 다음과 같은 이점을 얻을 수 있을 것입니다.
- 하드웨어 요구 사양이 낮아졌습니다 .
- 현재 상태 운영이 주요 병목 현상이므로 처리량을 높일 수 있는 여유 공간이 더 필요합니다 .
- 테일 레이턴시 개선으로 부하 시 복원력이 향상되었습니다 .
하지만 여기서 부족한 부분은 실제 상태 만료 구현 방식입니다. 프로토콜 내 구현이든 프로토콜 외 구현이든, 만료된 상태를 표시하고 삭제하고 다시 활성화하는 과정에서 추가적인 지연 시간이 발생합니다. 메인넷 워크로드를 사용한 실험 결과는 긍정적이지만, 구체적인 만료 방식을 제안하기 전에 이러한 장단점을 엔드투엔드 관점에서 평가해야 합니다.
향후 계획
- 최악의 상황에서 비활성 상태를 제거하는 것이 얼마나 도움이 되는지(또는 실패하는지)를 측정합니다.
- 다른 EL 고객사를 대상으로 동일한 벤치마킹을 반복하고 결과를 비교하십시오.
- 만료 규칙의 다양한 변형(예: 6개월 만료 기간, 계약 저장 공간만 정리, 계정만 정리)을 살펴보고 벤치마크 결과가 어떻게 달라지는지 확인하십시오.