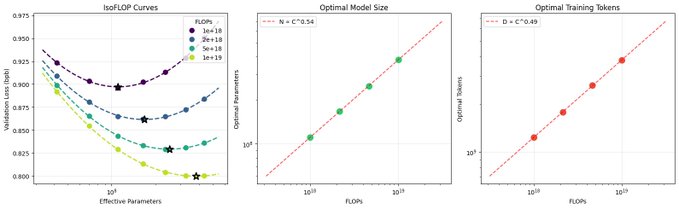
fp8 학습을 활성화하여 "GPT-2 생성 시간"을 4.3% 단축하여 이제 2.91시간이 됩니다. 또한 8개의 H100 스팟 인스턴스 가격을 사용하면 이 GPT-2 재현에 드는 비용은 실제로 약 20달러에 불과합니다. 따라서 매우 고무적인 결과입니다. GPT-2 (7년 전): 출시하기에는 너무 위험하다. GPT-2 (오늘): 새로운 MNIST! :) 이건 분명 1시간보다 훨씬 빨리 끝날 수 있을 거예요. fp8에 대해 몇 마디 더 하자면, 예상보다 비트(Bit) 더 까다로웠고 도입하기까지 시간이 좀 걸렸습니다. 게다가 아직 fp8에 대한 전반적인 지원이 부족하기 때문에 좋은 아이디어인지 100% 확신할 수는 없습니다. 이론상으로는 H100에서 fp8이 FLOPS의 2배를 내지만, 실제로는 그 차이가 훨씬 큽니다. 실제 학습 실행에서 100% 연산 병목 현상이 발생하는 것은 아니며, 추가적인 스케일 변환으로 인한 오버헤드가 있고, GPT-2 규모에서는 GEMM 모델이 충분히 크지 않아 오버헤드를 감수할 만한 가치가 명확하지 않으며, 당연히 정밀도가 낮아질수록 각 단계의 품질이 떨어집니다. 행 단위 스케일링 레시피의 경우 fp8과 bf16의 손실 곡선이 상당히 유사했지만, fp8이 단계적으로 더 느렸습니다. 텐서 단위 스케일링의 경우 손실 곡선이 더 벌어졌지만(즉, 각 단계의 품질이 더 낮음), 적어도 속도 향상(~7.3%)은 얻을 수 있었습니다. 훈련 기간을 늘리는 것(더 많은 단계를 훈련하지만 각 단계의 속도는 더 빨라짐)으로 성능을 회복하는 것처럼 보일 수 있지만, 궁극적으로는 더 나은 결과를 기대할 수 있습니다. 이러한 방법과 훈련 기간을 비트(Bit) 조정해 본 결과, 지금까지 약 5%의 속도 향상을 얻었습니다. torchao는 논문에서 Llama3-8B 모델의 경우 fp8을 적용하여 25%의 속도 향상을 달성했다고 보고했는데(제 결과는 성능 보정을 고려하지 않았을 때 약 7.3%입니다), 이는 제가 처음 기대했던 수준에 더 가깝습니다. 물론 Llama3-8B는 훨씬 더 큰 모델입니다. fp8에 대한 연구는 아직 끝나지 않았을 가능성이 높습니다. 어떤 레이어에 fp8을 적용할지 정확하게 선택하고, 네트워크 전체의 수치 연산에 더 주의를 기울이면 성능을 더욱 향상시킬 수 있을 것입니다.
이 기사는 기계로 번역되었습니다
원문 표시

Andrej Karpathy
@karpathy
02-01
nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node).
GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train
Twitter에서
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유