

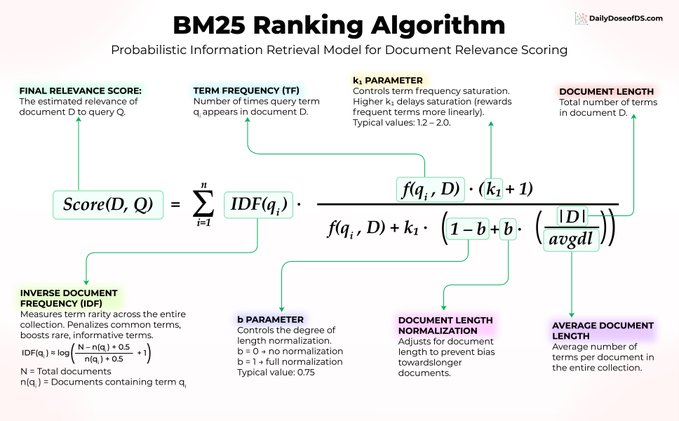
벡터 검색이 항상 정답은 아닙니다. 30년 된 알고리즘이 있는데, 학습, 임베딩, 미세 조정을 전혀 거치지 않았음에도 불구하고 여전히 Elasticsearch, OpenSearch, 그리고 대부분의 실제 검색 시스템에서 사용되고 있습니다. 이 알고리즘은 BM25라고 불리며, 왜 이 알고리즘이 여전히 널리 사용되는지 이해하는 것이 중요합니다. 머신러닝 논문 라이브러리에서 "트랜스포머 어텐션 메커니즘"을 검색한다고 가정해 보겠습니다. BM25는 세 가지 핵심 아이디어를 사용하여 문서의 점수를 매깁니다. 1) 단어 빈도보다 단어 희귀도가 더 중요합니다. 모든 논문에는 "the"와 "is"가 포함되어 있으므로 이러한 단어는 아무런 신호도 전달하지 않습니다. 하지만 "트랜스포머"는 구체적이고 유용한 단어이므로 BM25는 훨씬 높은 가중치를 부여합니다. 공식에서 이는 IDF(qᵢ)로 표현됩니다. 2) 반복은 도움이 되지만, 그 효과는 점차 감소합니다. "어텐션"이라는 단어가 논문에 10번 나타난다면, 이는 강력한 관련성 신호입니다. 하지만 키워드 발생 횟수가 10회에서 100회로 증가해도 점수에는 거의 변화가 없습니다. BM25는 f(qᵢ, D)와 매개변수 k₁에 의해 제어되는 포화 곡선을 적용하여 키워드 스터핑으로 결과가 왜곡되는 것을 방지합니다. 3) 문서 길이 정규화 50페이지 분량의 논문은 5페이지 분량의 논문보다 키워드 검색 결과가 더 많을 것입니다. BM25는 매개변수 b에 의해 제어되는 |D|/avgdl을 사용하여 이를 조정하므로, 문서 길이가 길다고 해서 텍스트 양이 많다는 이유만으로 순위가 높아지는 것을 방지합니다. 세 가지 아이디어. 신경망도, 훈련 데이터도 필요 없습니다. 오랜 시간 검증된 우아한 수학적 원리만 있으면 됩니다. 대부분의 사람들이 간과하는 부분은 바로 이것입니다. BM25는 정확한 키워드 일치에 탁월한데, 이는 임베딩 방식이 실제로 어려움을 겪는 부분입니다. 사용자가 "오류 코드 5012"를 검색할 때 벡터 검색은 의미적으로 유사한 오류 코드를 반환할 수 있습니다. 하지만 BM25는 항상 정확히 일치하는 결과를 보여줍니다. 이것이 바로 하이브리드 검색이 최고의 RAG 시스템에서 기본값으로 자리 잡은 이유입니다. BM25와 벡터 검색을 결합하면 단일 파이프라인에서 의미론적 이해와 정확한 키워드 매칭을 모두 얻을 수 있습니다. 따라서 모든 검색 문제에 GPU를 투입하기 전에 BM25가 이미 해당 문제를 해결하고 있거나, 적어도 두 가지를 결합했을 때 의미론적 검색 성능을 크게 향상시킬 수 있다는 점을 고려해 보세요.
이 기사는 기계로 번역되었습니다
원문 표시
Twitter에서
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유




