

이 글을 시각화하는 훨씬 더 좋은 방법이 있습니다(개념적인 내용과 벤치마크 결과를 시각적으로 더 명확하게 설명하는 동적 그림을 활용했습니다). 원하시면 다음 링크에서 확인하세요: 이진 트라이 그룹 깊이 벤치마크 - 예상보다 좁음
S1 – 요약
이진 트라이는 이더리움 프로토콜 초안 에서 미래의 상태 트리 대체 기술로 제안되었습니다. 하지만 그룹 깊이를 포함한 어떤 이진 트라이 구현체도 대규모 벤치마킹이 완료된 적이 없습니다. 로드맵에 이 기술이 도입됨에 따라, 성능 특성을 평가하는 것은 정보에 기반한 프로토타이핑을 위한 필수 조건입니다. geth 구현체( EIP-7864 )는 디스크 노드에 이진 레벨을 저장하는 방식을 제어하는 --bintrie.groupdepth 매개변수를 제공합니다. 본 연구에서는 최적의 설정을 찾기 위해 8가지 구성을 벤치마킹합니다.
결론적으로, 최적의 성능은 작업 부하에 따라 GD-5 또는 GD-6에서 나타납니다. GD-5는 쓰기 속도에서 GD-4보다 7% 우수한 성능을 보입니다(6.94 Mgas/s 대 6.47 Mgas/s, p < 1e-9). GD-6는 읽기 속도(6.39 Mgas/s)와 혼합 작업 부하에서 GD-4보다 19% 우수한 성능을 보입니다( p < 1e-3). GD-7에서는 GD-6 이후 성능이 저하되는 것을 확인할 수 있습니다.
우리가 테스트한 것
약 4억 개의 상태 항목을 포함하는 동일한 360GB 데이터베이스에서 8가지 그룹 깊이 구성(GD-1~GD-8)을 사용했습니다. 5가지 벤치마크 유형(합성 워크로드 2개(원시 SLOAD/SSTORE) 및 ERC20 계약 워크로드 3개)을 각각 콜드 캐시 프로토콜 하에서 9회씩 실행했습니다. 모든 결과는 중앙값을 사용했으며 , Mann-Whitney U 검정을 통해 유의성을 확인했습니다.
우리가 발견한 것
- 분석 결과는 직관(섹션 4)을 뒷받침합니다 . 즉, 트리 구조가 넓을수록 읽기 속도가 빠릅니다. GD-8은 GD-1보다 두 배 이상 높은 읽기 처리량(5.59Mgas/s 대 2.65Mgas/s)을 달성했습니다. GD-6은 가장 높은 읽기 처리량(6.39Mgas/s)을 기록했으며, GD-5(6.11Mgas/s)와 GD-7(6.04Mgas/s)이 그 뒤를 이었습니다. GD-3부터 GD-8까지는 5.2~6.4Mgas/s 범위의 처리량을 보였습니다.
- 쓰기 성능은 더욱 뚜렷한 최적점을 보여줍니다 (섹션 5): GD-5는 629ms(6.94Mgas/s)로 쓰기 성능 1위를 기록했는데, 이는 GD-4(678ms, 6.47Mgas/s)보다 7% 빠르고 GD-8(982ms, 4.47Mgas/s)보다 55% 빠른 수치입니다. 쓰기 성능의 변곡점은 GD-5와 GD-6 사이(해시/읽기 비율이 1.0을 넘는 지점)에 있습니다.
- 노드 크기는 GD-7에서 페블 블록 경계에 도달합니다 (섹션 5). 각 GD-7 노드는 약 4KB(128 × 32바이트)로 직렬화되는데, 이는 페블 블록 크기와 정확히 일치합니다. 이 경계 아래(GD-6: 약 2KB)에서는 각 노드가 하나의 블록 내에 들어갑니다. 경계 위에서는 읽기 작업에 노드당 두 개의 블록이 필요할 수 있습니다. Gary Rong의 NVMe 벤치마크에 따르면 QD=1에서 8KB 무작위 읽기는 4KB 읽기보다 54% 더 높은 지연 시간(77.8µs 대 50.6µs)을 발생시킵니다. 이러한 노드별 I/O 페널티는 약 37개의 경로 노드에 걸쳐 누적되므로 경로 길이가 더 짧음에도 불구하고 GD-7의 읽기 속도가 GD-6보다 느린 이유를 설명합니다.
- 최적의 성능은 GD-5 또는 GD-6에서 나타납니다 (섹션 6). GD-5는 쓰기 성능에서 GD-4보다 7% 우수하고, GD-6는 읽기 성능(GD-5 대비 +5%)과 혼합 워크로드 성능(GD-4 대비 +19%)에서 우위를 보입니다. GD-7은 모든 벤치마크에서 GD-6보다 성능이 떨어지는 변곡점을 보여줍니다. 이더리움은 읽기 작업이 많기 때문에 GD-6이 기본값으로 적합할 수 있습니다.
이 게시물을 읽는 방법
- 제2장(배경)에서는 이진 트라이와 그룹 깊이 개념을 다룹니다.
- 제3절(방법론)에서는 벤치마크 설정에 대해 자세히 설명합니다.
- 4~6절에서는 읽기, 쓰기, 그리고 그 절충이라는 일련의 과정을 통해 결과를 제시합니다.
- 제7장(패턴)에서는 여러 분야에 걸쳐 나타나는 공통적인 관찰 결과를 살펴봅니다.
- 제8절(결론)에서는 두 가지 권고사항과 미해결 과제를 제시합니다.
시간이 부족하신가요? 그렇다면 4장 "ERC20 읽기: 깊이 있는 이해가 중요한 부분"부터 시작해 보세요 . 이 부분은 그룹 간 깊이 차이가 가장 뚜렷하게 드러나는 부분이며, 나머지 분석의 기초를 다져줍니다.

S2 – 배경
이진 트라이란 무엇인가요?
EIP-7864는 이더리움의 머클 패트리샤 트라이(MPT)를 바이너리 트라이로 대체하는 것을 제안합니다. 바이너리 트라이는 계정 트라이와 모든 스토리지 트라이를 단일 트리로 통합하고, 해싱에 Keccak-256 대신 SHA-256을 사용하며, 256개의 값 그룹에 매핑되는 32바이트 스템을 저장합니다. 이러한 설계는 상태 비저장 클라이언트의 증명 생성 과정을 간소화하고 더욱 효율적인 증명을 가능하게 합니다.
MPT에서 바이너리 트라이로의 전환은 이더리움 상태 계층에 있어 가장 중요한 변화 중 하나입니다. 새로운 구조의 성능 특성은 블록 처리 시간, 동기화 속도 및 검증자 경제성에 직접적인 영향을 미칠 것입니다.
그룹 깊이란 무엇인가요?
트라이는 기본적으로 항상 이진 구조를 가지며, 모든 내부 노드는 정확히 두 개의 자식 노드(왼쪽은 0번 비트, 오른쪽은 1번 비트)를 갖습니다. 그룹 깊이(GD-N) 는 디스크에 저장된 단일 노드에 몇 개의 이진 레벨이 묶이는 지를 제어합니다. GD-N에서는 각 저장된 노드가 N 레벨의 이진 서브트리를 캡슐화하므로 외부에서 볼 때 2^N개의 자식 노드를 가진 것처럼 보입니다 .
- GD-1: 노드당 1개의 바이너리 레벨 → 2개의 자식 포인터, 리프 노드까지의 경로에 256개의 노드
- GD-2: 노드당 2개의 바이너리 레벨 → 4개의 자식 포인터, 경로상 128개의 노드
- GD-3: 노드당 3개의 바이너리 레벨 → 8개의 자식 포인터, 경로상 약 86개의 노드
- GD-4: 노드당 4개의 바이너리 레벨 → 16개의 자식 포인터, 경로상의 64개 노드
- GD-5: 노드당 5개의 바이너리 레벨 → 32개의 자식 포인터, 경로상 약 52개의 노드
- GD-6: 노드당 6개의 바이너리 레벨 → 64개의 자식 포인터, 경로상 약 43개의 노드
- GD-7: 노드당 7개의 바이너리 레벨 → 128개의 자식 포인터, 경로상 약 37개의 노드
- GD-8: 노드당 8개의 바이너리 레벨 → 256개의 자식 포인터, 경로상의 32개 노드
우편번호를 예로 들어 설명하자면, GD-1은 주소를 한 자리씩 읽어들이는 방식(256단계)이고, GD-8은 8자리씩 한꺼번에 읽어들이는 방식(32단계)입니다. 단계 수가 적을수록 디스크 읽기 횟수는 줄어들지만, 각 "번들 노드"의 크기가 커지고 업데이트 비용이 더 많이 듭니다. 그 이유는 노드 내부의 바이너리 서브트리를 다시 해싱해야 하기 때문입니다.
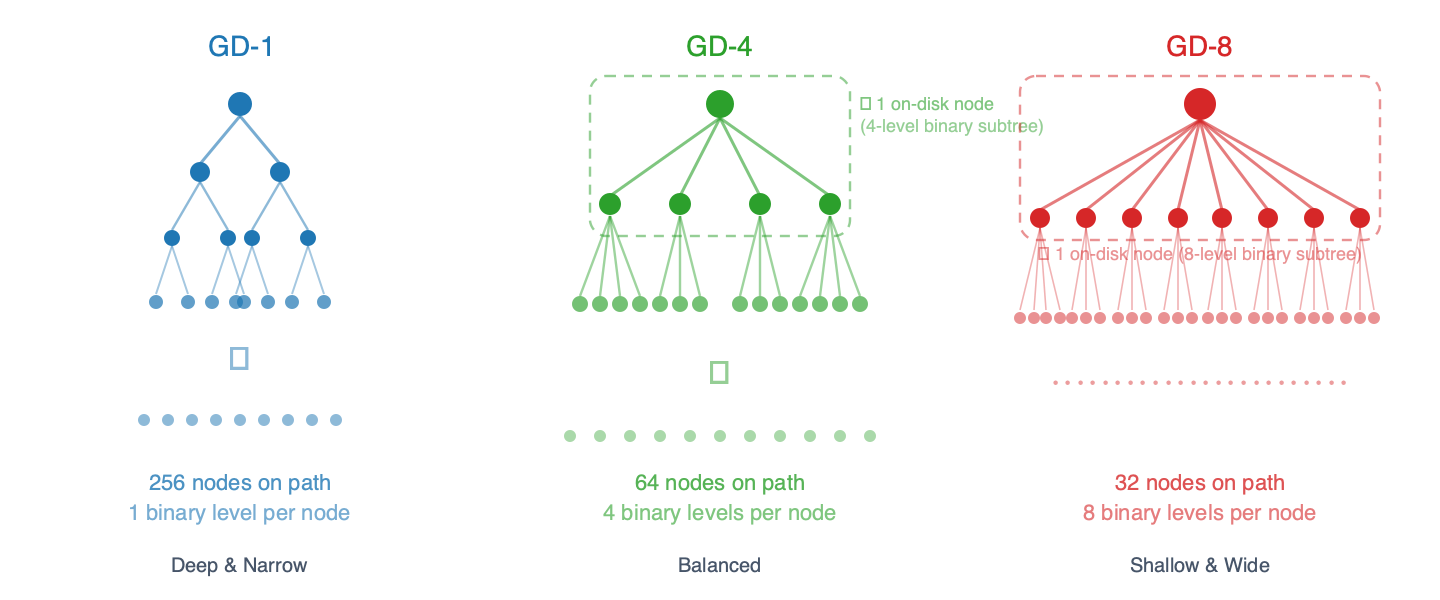
그림 1 – 그룹 깊이에 따른 트리 형태. 각 노드는 N개의 이진 레벨을 내부적으로 묶어 리프 노드까지의 경로에 있는 디스크 노드 수를 줄입니다.
이론적으로는 상충 관계가 명확합니다. 읽기 작업은 트리가 얕을수록 유리합니다(리프 노드에 도달하는 데 필요한 디스크 I/O 작업량이 적음). 반면 쓰기 작업은 노드가 넓을수록 불리합니다(노드 수정 시 내부 해싱 작업이 더 많이 발생함). 문제는 이러한 상충 관계가 성립하는 지점이 어디인가 하는 것입니다.
S3 – 방법론
요약
벤치마크 설정
| 매개변수 | 값 |
|---|---|
| 기계 | QEMU 가상 머신 - 8개의 vCPU, 30GB RAM, 3.9TB SSD, Ubuntu 24.04 LTS |
| 데이터 베이스 | 약 360GB, 약 4억 개의 계정 + 저장 슬롯 |
| 구성 | GD-1, GD-2, GD-3, GD-4, GD-5, GD-6, GD-7, GD-8 (Pebble, geth에서 사용하는 LSM 트리 스토리지 엔진, 블록 크기 4KB) |
| 규약 | 콜드 캐시(OS 페이지 캐시 삭제 + Pebble 캐시=0, 실행 간) |
| 실행 | 구성별 벤치마크당 10회 실행; 첫 번째 실행 제외(잔여 발열량) |
| 가스 타겟 | 블록당 1억 가스 |
통계적 접근 방식
- 유지된 9개 실행에 걸쳐 집계된 실행별 블록 중앙값
- 쌍별 비교를 위한 맨-휘트니 U 검정 (비모수적)
- 효과 크기는 기준선(GD-1) 대비 백분율 차이로 보고됩니다.
- 일관성 평가를 위한 변동 계수(CV%)
벤치마크 분류 체계
a) 합성 벤치마크 - sstore_variants (쓰기) 및 sload_benchmark (읽기). 이러한 벤치마크는 순차적 저장 슬롯을 사용하는 EIP-7702 위임을 사용합니다. 키는 숫자 순차적이므로 트라이에서 접두사 공유가 많이 발생합니다.
b) ERC20 벤치마크 - balanceof (읽기), approve (쓰기) 및 mixed . 이러한 벤치마크는 실제 ERC-20 계약 코드를 사용합니다. 저장 키는 임의 주소의 케칵 해시로, 트라이 전체에 걸쳐 균일하게 분포된 접근 패턴을 생성합니다.
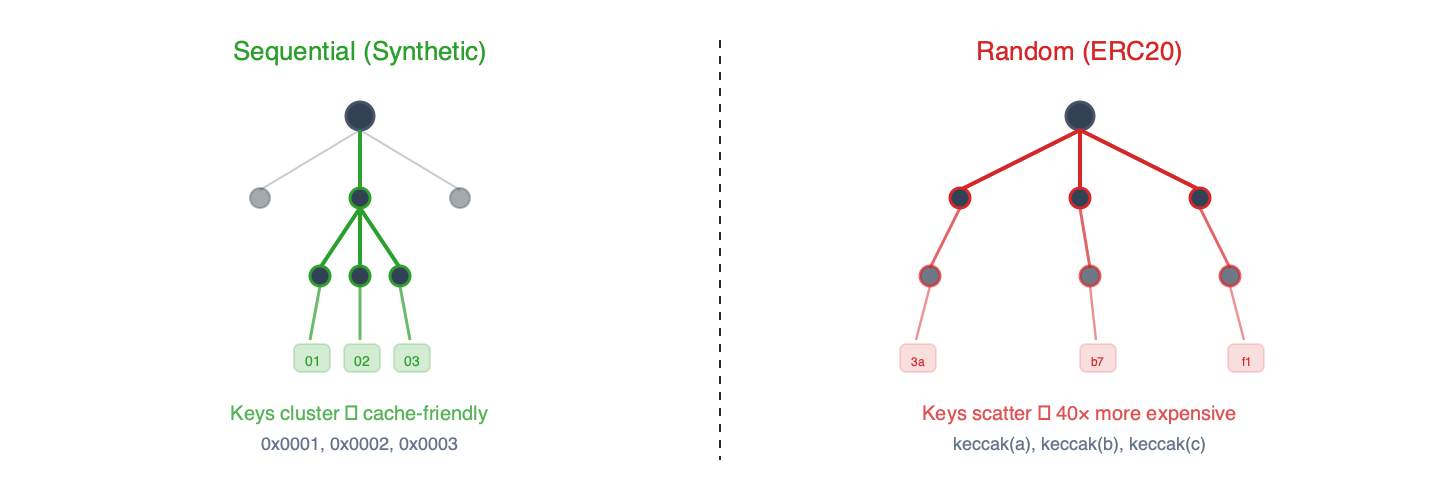
그림 2 – 순차적 키는 트라이 접두사를 공유하고 캐싱의 이점을 누립니다. 케칵 해시 키는 균일하게 분산되어 모든 레벨에서 빈번한 읽기가 발생합니다.
블록 구성 노트
실행 사양 하네스는 모든 벤치마크 트랜잭션을 한 번에(1 초 이내 ) Geth의 멤풀로 전송합니다. Geth의 개발 모드 마이너( dev.period=10 )는 10초의 블록 생성 시간 동안 이 멤풀에서 트랜잭션을 순차적으로 처리합니다. 타이머가 만료되면 처리된 트랜잭션을 채굴합니다. 병목 현상은 가스 용량이 아니라 트라이 연산 시간입니다. 각 ERC20 승인 트랜잭션은 약 440만 가스만 사용하지만(1억 블록 가스 제한에는 약 22개의 트랜잭션이 적합함), 트라이 연산(순회, 업데이트, 해시, 커밋)은 느린 설정에서 단 하나의 트랜잭션을 처리하는 데 거의 전체 시간을 소모합니다. 설정 트랜잭션(간단한 ETH 전송)은 77ms 동안 7개의 트랜잭션을 처리하며, 이는 트랜잭션 오버헤드가 아닌 트라이 비용이 제한 요소임을 확인시켜 줍니다.
검증된 콜드 캐시 드롭(3단계)을 통해 모든 구성에서 이제 블록당 1개의 트랜잭션(중앙값 트랜잭션 수=1)이 처리됩니다. 메커니즘적 설명은 여전히 유효합니다. 10초의 dev.period 시간 예산 역할을 하며, 트라이 연산 비용이 처리할 수 있는 트랜잭션 수를 결정합니다. Mgas/s(처리량)는 구성 간의 가스 차이를 정규화하므로 적절한 비교 지표입니다 . 표시된 원시 ms 값은 해당 구성의 블록 구성에 대한 실제 블록 처리 시간을 나타냅니다.
시즌 4 - 1막: 읽기를 통해 직감을 확인하다
ERC20 읽기: 깊이가 중요한 경우
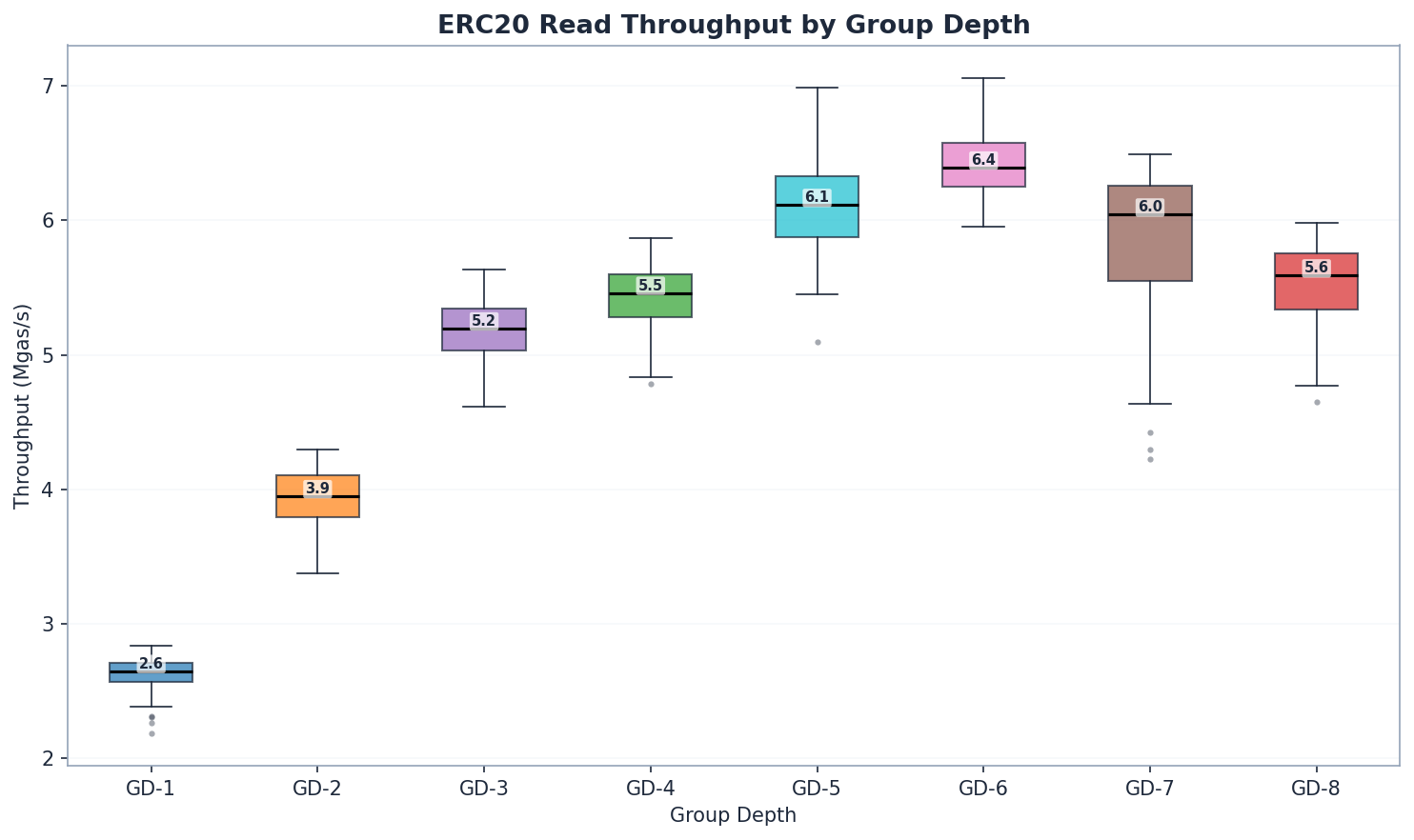
| GD | 상태 읽기(밀리초) | 총합(밀리초) | Mgas/s | GD-1 대비 (Mgas/s) |
|---|---|---|---|---|
| 1 | 5,878 | 6,284 | 2.65 | 기준선 |
| 2 | 3,840 | 4,231 | 3.95 | +49% |
| 3 | 2,866 | 3,213 | 5.20 | +96% |
| 4 | 2,677 | 3,067 | 5.46 | +106% |
| 5 | 2,370 | 2,733 | 6.11 | +131% |
| 6 | 2,248 | 2,623 | 6.39 | +141% |
| 7 | 2,339 | 2,693 | 6.04 | +128% |
| 8 | 2,598 | 2,977 | 5.59 | +111% |
GD-1에서 GD-6으로 갈수록 읽기 처리량이 약 2.4배 증가합니다. GD-6에서 가장 높은 읽기 처리량(6.39 Mgas/s)을 달성했으며, GD-5(6.11)와 GD-7(6.04)이 그 뒤를 이었습니다. 읽기 성능은 GD-1에서 GD-6까지 단조롭게 증가하다가 점차 감소합니다. GD-4(5.46)는 예상대로 경로가 짧아짐에 따라 GD-3(5.20)보다 우수한 성능을 보입니다. GD-7과 GD-8에서는 노드 크기가 커지면서 경로 단축 효과를 상쇄할 수 있게 되어 성능 향상 폭이 줄어듭니다.
합성 데이터베이스와 이렇게 극적인 차이가 나는 이유는 무엇일까요? Keccak은 키를 균일하게 분산시켜 루트에서 리프까지 전체 경로를 탐색하도록 강제합니다. GD-1은 256단계를 탐색해야 하지만, GD-8은 32단계만 탐색하면 됩니다. 모든 단계가 잠재적인 디스크 탐색입니다. 무작위 접근은 이러한 깊이에 따른 성능 저하를 여실히 보여줍니다.
GD-3(3,213ms, 5.20Mgas/s)와 GD-4(3,067ms, 5.46Mgas/s)는 읽기 성능에서 유사한 양상을 보이며, 예상대로 GD-4가 더 짧은 경로(노드 수 64개 vs 약 86개) 덕분에 약간 앞서 있습니다. GD-3의 더 작은 노드 직렬화 크기(GD-4의 약 512바이트 대비 약 256바이트)는 Pebble의 4KB 블록 크기와 잘 어우러져, 트리 형태가 매우 다름에도 불구하고 두 서버의 성능 차이가 5% 이내로 유지됩니다. Pebble 블록 크기와의 상호작용은 추가적인 연구가 필요한 부분입니다(미해결 과제 #3 ).
슬롯당 비용: 합성 읽기 비용은 슬롯당 약 0.02ms입니다. ERC20 읽기 비용은 슬롯당 약 0.4~1.0ms입니다(블록당 상태 읽기 시간(state_read_ms) / 저장 슬롯 수(storage_slots_read)로 계산). 이는 무작위 접근 패턴에 비해 40배의 페널티가 발생합니다 .
이 40배 비율은 NVMe 측정 결과와 일치합니다. Gary Rong의 디스크 페이지 읽기 벤치마크에 따르면 무작위 4KB 읽기 속도는 77MB/s인 반면 순차 읽기 속도는 3,306MB/s(43배)로 나타나며, 이는 성능 저하가 Pebble 오버헤드보다는 I/O 액세스 패턴에 의해 좌우됨을 확인시켜 줍니다.
랜덤 액세스가 예외가 아닌 기본인 이유. 바이너리 트라이는 모든 계정과 스토리지를 단일 트리로 통합합니다. 계정 잔액, 스토리지 슬롯, 코드 청크 등 모든 키는 SHA256 해시를 통해 256비트 키 공간으로 저장됩니다. 단일 컨트랙트의 스토리지 슬롯은 트리의 여러 경로에 분산될 수 있습니다. 따라서 랜덤 액세스는 바이너리 트라이의 기본 액세스 패턴이며, 예외적인 경우가 아닙니다. 인위적인 순차 벤치마크는 통합 트라이 배포 환경에서 발생할 수 없는 비현실적인 최상의 경우를 나타냅니다.
지금까지는 범위가 넓을수록 좋다는 것이 어느 정도까지는 사실입니다. GD-6은 읽기 성능에서 가장 우수하며, GD-7과 GD-8은 그보다 성능이 떨어지는 경향을 보입니다. 그다음 쓰기 성능을 테스트했습니다.
시즌 5 – 2막: 놀라운 글쓰기
이것이 이번 연구에서 가장 중요한 발견입니다.
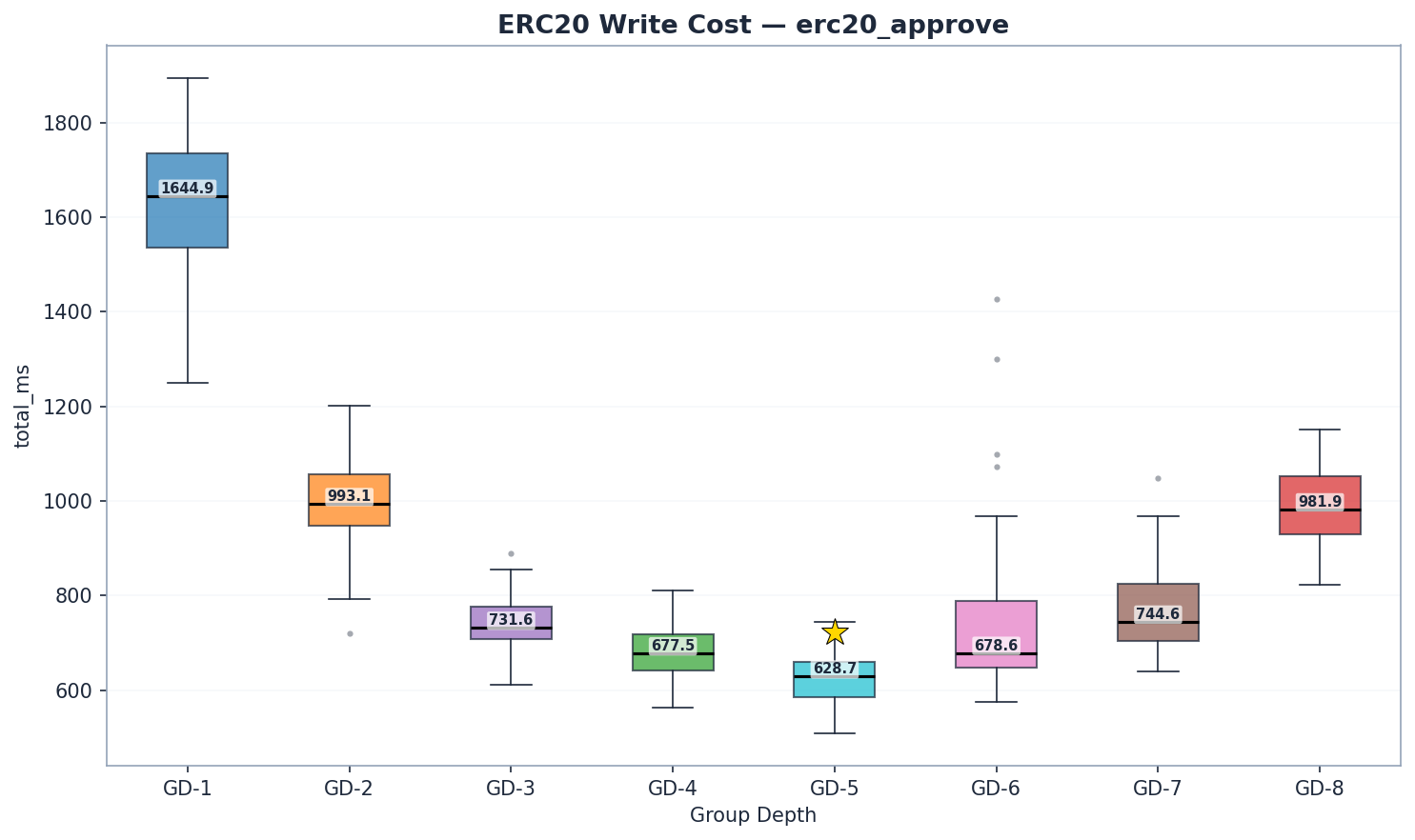
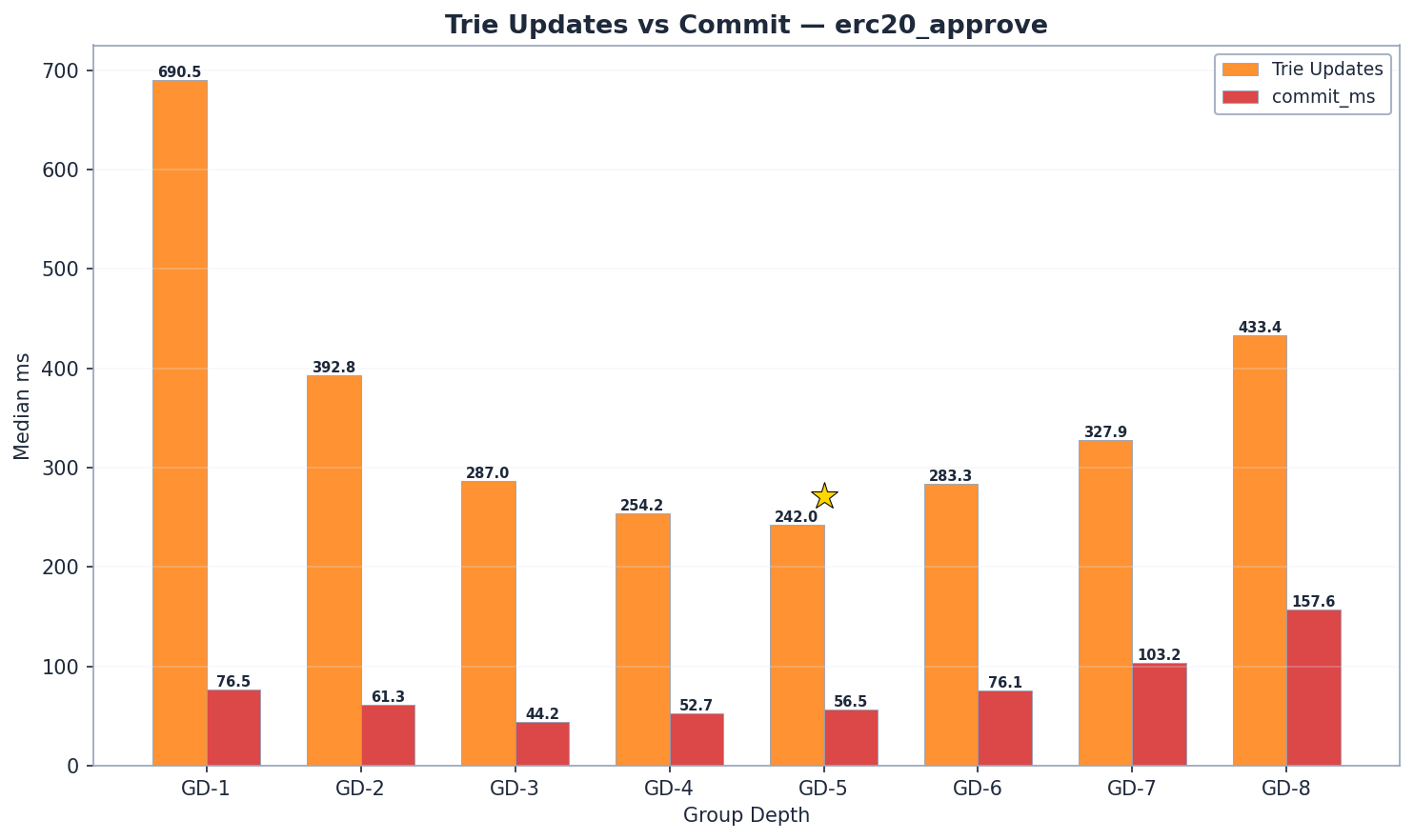
| GD | 상태 읽기 | 트라이 업데이트 | 저지르다 | 총 | Mgas/s |
|---|---|---|---|---|---|
| 1 | 812 | 691 | 77 | 1,645 | 2.67 |
| 2 | 483 | 393 | 61 | 993 | 4.42 |
| 3 | 349 | 287 | 44 | 732 | 5.95 |
| 4 | 313 | 254 | 53 | 678 | 6.47 |
| 5 | 271 | 242 | 57 | 629 | 6.94 |
| 6 | 272 | 283 | 76 | 679 | 6.41 |
| 7 | 264 | 328 | 103 | 745 | 5.81 |
| 8 | 313 | 433 | 158 | 982 | 4.47 |
trie_updates = state_hash_ms (AccountHashes + AccountUpdates + StorageUpdates) — 해싱뿐 아니라 전체 트라이 변형 및 재해싱 단계를 포함합니다. 모든 구성은 검증된 콜드 캐시 프로토콜(실행 간 OS 페이지 캐시 삭제)을 사용하여 실행됩니다. 3단계 CV는 대부분 Mgas/s에서 10% 미만으로 측정 값이 신뢰할 수 있음을 확인시켜 줍니다.
GD-5가 쓰기 속도 부문 챔피언입니다. 6.94 Mgas/s로 GD-4(6.47 Mgas/s, p < < 1e-9)보다 7% 빠르고 GD-8(4.47 Mgas/s)보다 55% 빠릅니다. GD-6(6.41 Mgas/s)은 GD-4에 바짝 뒤쳐져 3위를 차지했습니다. GD-7(5.81 Mgas/s)은 GD-6 이후에도 속도 향상 추세가 계속됨을 보여줍니다.
구성 요소별 분석이 모든 것을 말해줍니다.
- 읽기 속도: GD-5(271ms)는 GD-4(313ms)보다 13% 빠릅니다. GD-6(272ms)은 GD-5와 비슷한 수준이며, GD-7(264ms)이 가장 빠른 읽기 속도를 보입니다. 하지만 블록당 가스 생산량은 변동될 수 있으므로 공정한 비교를 위해서는 밀리초 단위의 읽기 속도와 초당 가스 생산량(Mgas/s)을 함께 고려해야 합니다.
- 트라이 업데이트: GD-5(242ms)는 GD-4(254ms)보다 5% 짧습니다 . GD-6은 283ms로 완만하게 상승(GD-5 대비 +17%)했지만, 이전 데이터에서 나타났던 것처럼 급격한 변화는 보이지 않습니다. GD-7(328ms)과 GD-8(433ms)은 이러한 변곡점이 지속됨을 확인시켜 줍니다.
- 커밋: GD-5(57ms)는 GD-4(53ms)보다 약간 높습니다. GD-6(76ms, GD-5 대비 +33%)과 GD-7(103ms)은 완만한 증가를 보입니다. 실제 커밋 시간 급증은 GD-8(158ms)에서 발생하는데, 이는 약 8KB 노드 x 32개 경로 노드 = 약 256KB의 직렬화 작업(쓰기당) 때문입니다.
쓰기 변곡점은 GD-5와 GD-6 사이에 있습니다. 해시/읽기 비용 비율이 GD-6(283/272 = 1.04)에서 1.0을 넘어서면서 트라이 업데이트 비용이 읽기 비용을 초과하기 시작합니다. Mgas/s 기준으로 GD-5(6.94)는 GD-4(6.47)보다 7%, GD-6(6.41)보다 8% 앞서 있습니다.
이유는 무엇일까요? 내부 서브트리
그룹 깊이 g g 에 있는 각 트라이 노드는 모든 쓰기 작업 시마다 다시 해싱해야 하는 2^g - 1 2 g − 1개의 노드를 가진 내부 이진 서브트리를 포함합니다.
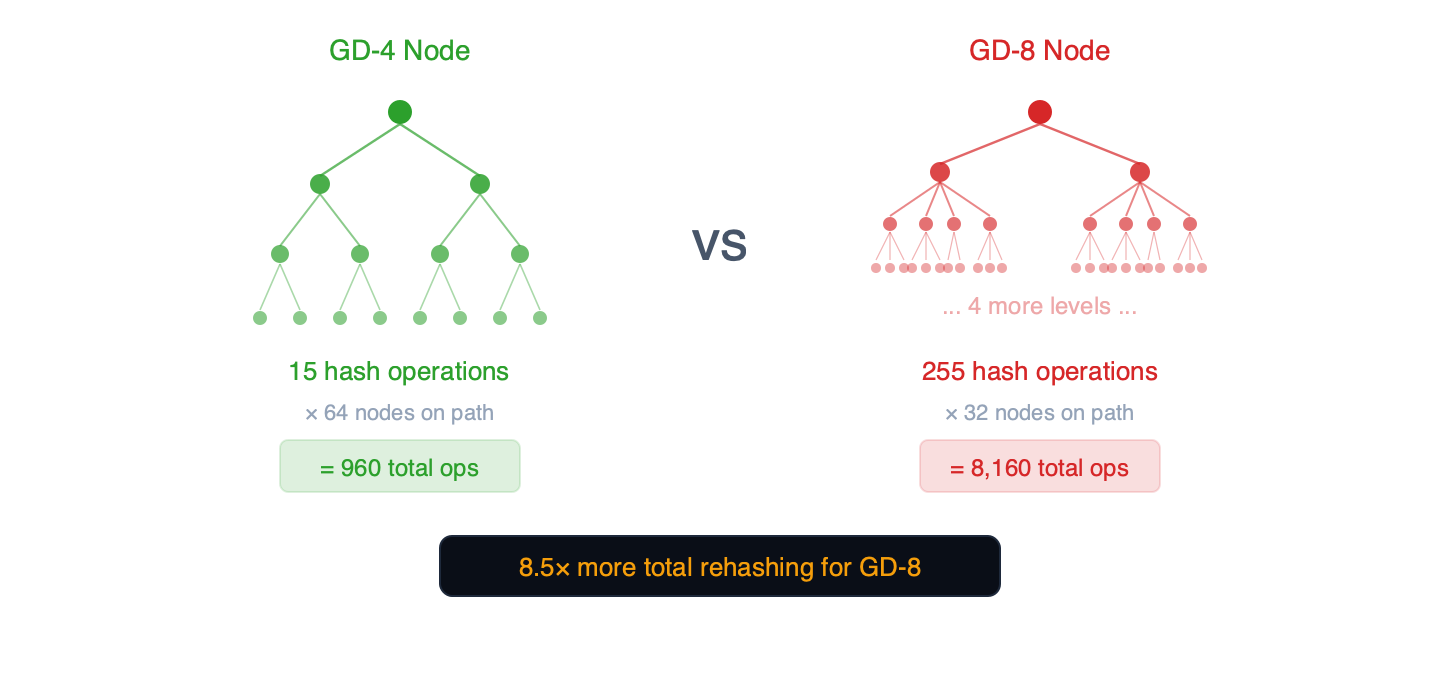
그림 3 – 각 트라이 노드는 내부 이진 서브트리를 포함합니다. 노드 폭이 넓을수록 쓰기 작업당 해싱량이 기하급수적으로 증가합니다.
- GD-4 노드: 내부 해시 연산 15개 x 경로상 노드 64개 = 총 960개 연산
- GD-5 노드: 내부 해시 연산 31개 x 경로상 노드 약 52개 = 총 연산 약 1,612개
- GD-8 노드: 내부 해시 연산 255개 x 경로상 노드 32개 = 총 8,160개 연산
GD-5는 쓰기 성능의 최적점을 찾습니다. 경로 길이가 GD-4보다 19% 짧고(노드 수: 약 52개 vs 64개), 각 노드의 31개 내부 작업은 관리 가능한 수준을 유지합니다. GD-6(노드당 내부 노드 수: 63개)에서는 재해싱 비용이 GD-5의 242ms에서 283ms로 17% 소폭 증가합니다. GD-7(해싱 328ms, 커밋 103ms)은 GD-6 이후에도 변곡점이 계속됨을 확인시켜 줍니다. 쓰기 성능의 변곡점은 GD-5와 GD-6 사이, 해시/읽기 비율이 1.0을 넘는 지점에 있습니다.
참고: 17배 비율(내부 해시 연산 255회 대 15회)은 데이터 구조에서 도출된 이론적인 상한값입니다. 저희 벤치마크 결과는 이 메커니즘을 뒷받침합니다. GD-8 트라이 업데이트 비용은 GD-4보다 1.71배 더 높으며(433ms 대 254ms), 이는 임의 쓰기 작업이 각 노드의 내부 서브트리 일부를 수정한다는 사실과 일치합니다. geth 구현은 정확한 재해싱 알고리즘에 대한 공식적인 출처입니다.
노드 직렬화 크기
각 트라이 노드는 최대 2^N개의 자식 포인터(각 32바이트)를 저장합니다. GD-4 노드는 16 × 32 = 약 512바이트입니다 . GD-7 노드는 128 × 32 = 약 4KB 로, 페블 블록 크기와 정확히 같습니다. GD-8 노드는 256 × 32 = 약 8KB 입니다. 이러한 크기 차이는 연쇄적인 영향을 미칩니다.
- 페블 블록 경계: GD-6 노드(~2KB)는 단일 4KB 페블 블록 내에 들어갑니다. GD-7 노드(~4KB)는 블록을 포화시키며, 키 오버헤드를 고려하면 두 블록에 걸쳐 있을 가능성이 높고, 노드 페치당 I/O가 두 배로 증가할 수 있습니다. 이는 GD-7의 읽기 역전 현상을 부분적으로 설명합니다. GD-6보다 경로 노드 수가 14% 적음에도 불구하고(37개 대 43개), GD-7은 조회당 총 약 148KB(37개 × 4KB)를 읽는 반면 GD-6은 약 86KB(43개 × 2KB)를 읽습니다.
- 페블 캐시 효율성: 주어진 캐시 예산 내에서 더 적은 수의 GD-8 노드가 적합합니다.
- 쓰기 증폭: 직렬화된 노드의 크기가 커질수록 LSM 압축 오버헤드가 증가합니다.
- 커밋 비용: 198%의 커밋 지연(158ms 대 53ms)은 수정된 노드당 16배 더 많은 데이터를 직렬화하는 것을 부분적으로 반영합니다.

그림 4 – 읽기의 경우 하향 순회만 중요합니다(GD-8 선호). 쓰기의 경우 재해싱과 커밋이 중요합니다(GD-4 선호). 읽기 = 1단계만. 쓰기 = 1단계 + 2단계 + 3단계.
시즌 6 – 3막: 절충
판결
| 표준 | GD-4 | GD-5 | GD-6 | GD-7 | GD-8 |
|---|---|---|---|---|---|
| 판독값(Mgas/s) | 5.46 | 6.11 | 6.39 | 6.04 | 5.59 |
| 쓰기량(Mgas/s) | 6.47 | 6.94 | 6.41 | 5.81 | 4.47 |
| 혼합(Mgas/s) | 5.13 | 6.09 | 6.27 | 5.87 | 5.43 |
| 부문별 수상 | 0/3 | 1/3 | 2/3 | 0/3 | 0/3 |
GD-6은 읽기 및 혼합 벤치마크에서 우위를 점하고, GD-5는 쓰기에서 우위를 점합니다. GD-5는 쓰기 성능에서 GD-4보다 7% 앞서며(p < 1e -9), GD-6은 읽기 성능에서 GD-5보다 5% 앞서고, 혼합 벤치마크에서는 GD-4보다 19% 앞서며( p < 1e-3), GD-7은 변곡점을 지나 모든 세 가지 벤치마크에서 GD-6보다 성능이 떨어집니다. 이더리움 워크로드는 읽기 작업이 많으므로 GD-6이 기본 설정으로 적합할 수 있으며, 쓰기 작업이 많은 시나리오에서는 GD-5가 최적일 수 있습니다.
혼합된 업무량
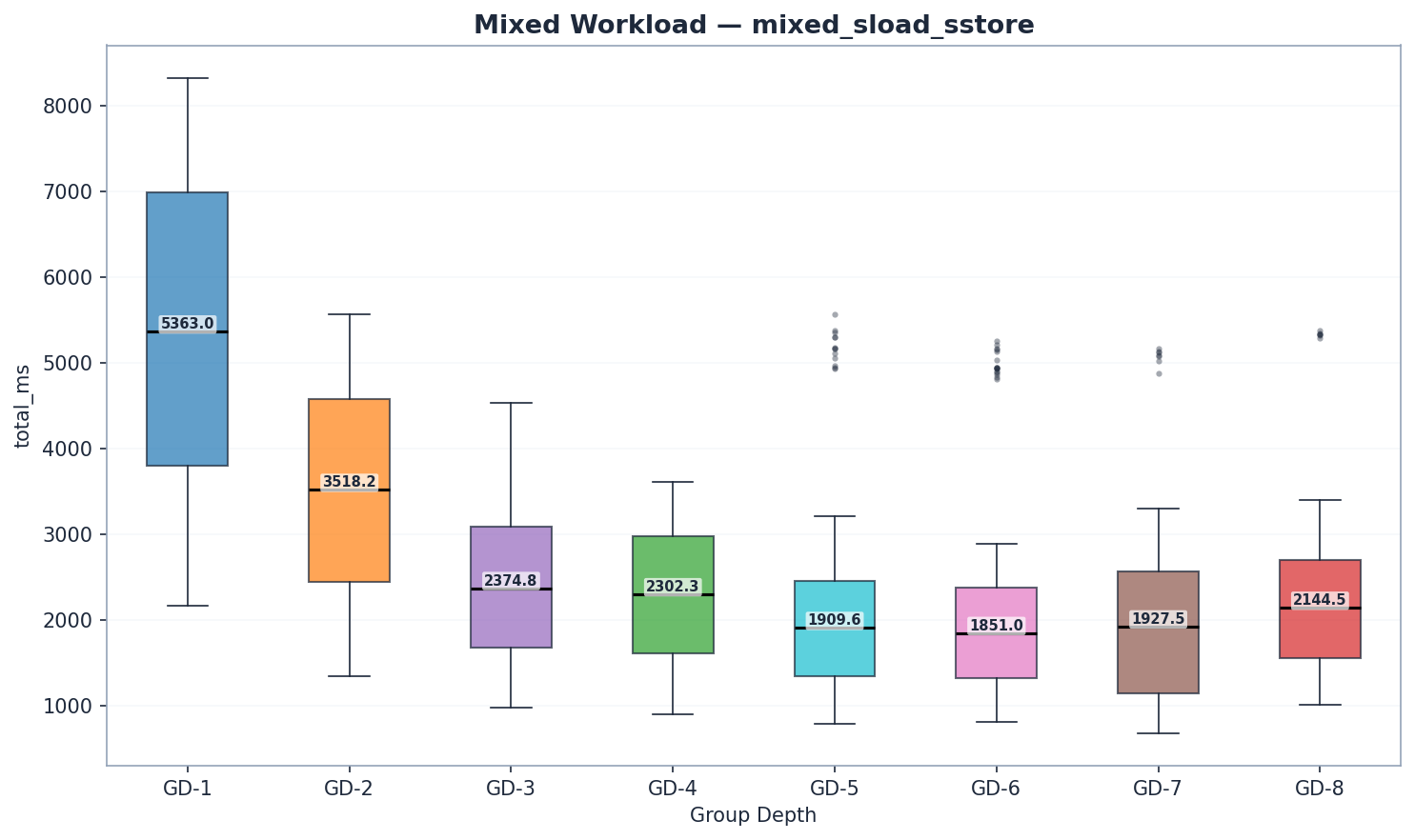
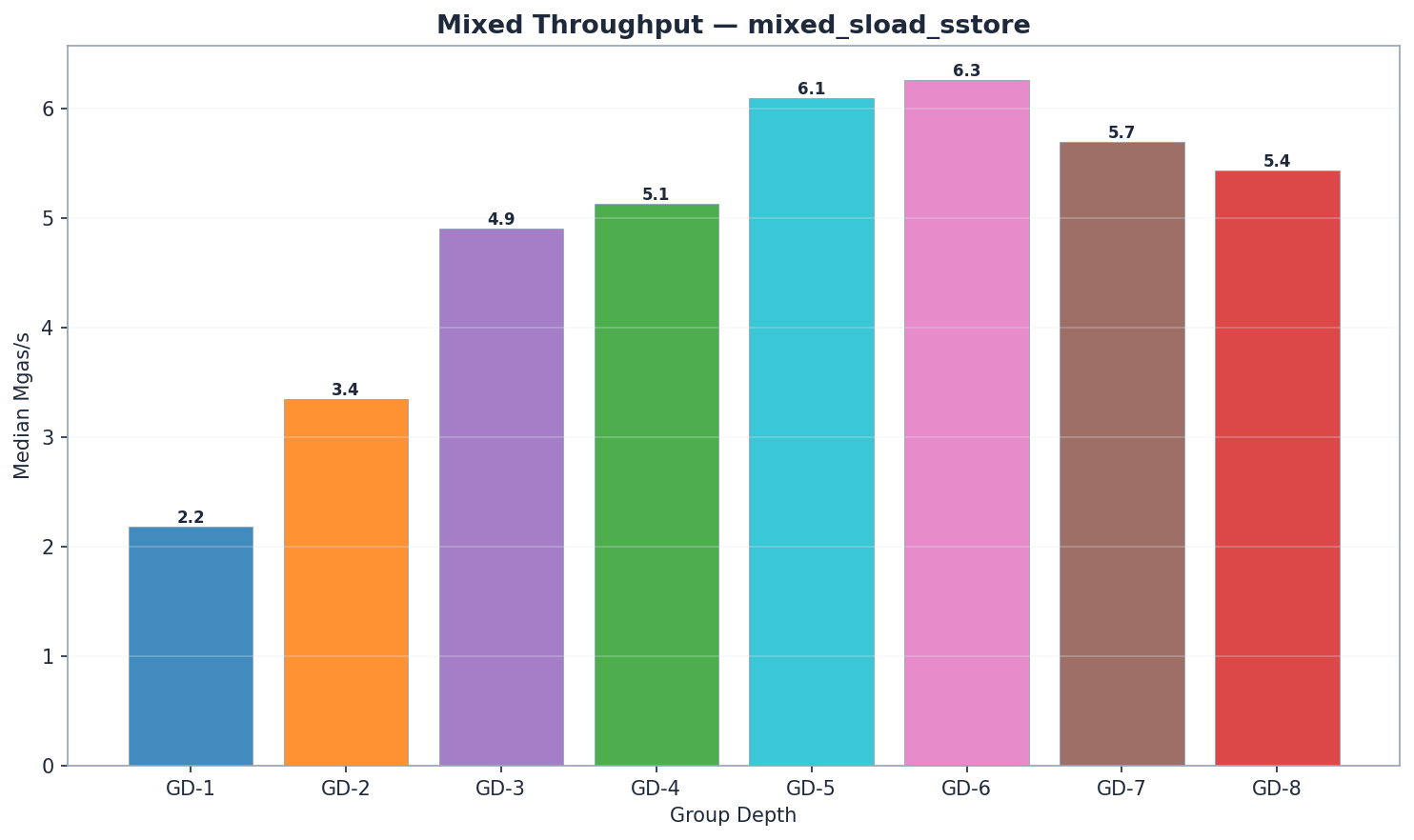
| GD | 상태 읽기 | 트라이 업데이트 | 저지르다 | 총밀리초 | Mgas/s |
|---|---|---|---|---|---|
| 1 | 4,711 | 345 | 53 | 5,363 | 2.18 |
| 2 | 3,003 | 217 | 44 | 3,518 | 3.35 |
| 3 | 1,981 | 145 | 39 | 2,375 | 4.90 |
| 4 | 1,893 | 138 | 43 | 2,302 | 5.13 |
| 5 | 1,512 | 124 | 48 | 1,910 | 6.09 |
| 6 | 1,440 | 141 | 54 | 1,851 | 6.27 |
| 7 | 1,055 | 218 | 73 | 1,529 | 5.87 |
| 8 | 1,612 | 221 | 87 | 2,145 | 5.43 |
GD-7의 혼합 벤치마크는 블록당 처리된 트랜잭션 수가 더 적었습니다(884만 대 약 1,180만 가스). Mgas/s는 이러한 차이를 보정하므로 처리량 비교는 여전히 유효합니다. GD-7 혼합의 원시 ms 값은 다른 구성과 직접 비교할 수 없습니다.
GD-6는 혼합 워크로드에서 6.27 Mgas/s로 가장 우수한 성능을 보였으며, GD-5(6.09 Mgas/s, +3%)가 그 뒤를 바짝 쫓았습니다. 두 DD-6 모두 GD-4(5.13 Mgas/s)보다 19~22% 높은 성능을 나타냈습니다. GD-6의 읽기 속도 우위(state_read 1,440ms vs GD-5 1,512ms)는 트라이 업데이트 시간(141ms vs 124ms)과 커밋 시간(54ms vs 48ms)이 약간 더 길다는 단점을 상쇄했습니다. GD-7(5.87 Mgas/s)은 GD-6보다 6% 낮은 성능을 보이며 변곡점을 확인시켜 줍니다. 참고: GD-7 혼합 워크로드는 블록당 8.84M gas를 사용하는 반면, 다른 모든 워크로드는 11.80M gas/block을 사용합니다. 유효한 비교 기준은 ms가 아닌 Mgas/s입니다.
해결되지 않은 질문: 최적의 그룹 깊이는 궁극적으로 실제 이더리움 블록의 읽기/쓰기 비율에 따라 달라집니다. 벤치마크 결과에서 블록 처리 시간의 대부분은 상태 읽기에 할애되지만, 메인넷에서의 정확한 읽기/쓰기 비율은 체계적으로 측정되지 않았습니다. 메인넷의 읽기 및 쓰기 접근 패턴에 대한 과거 분석을 통해 이 권장 사항을 더욱 구체화할 수 있을 것입니다.
구성 요소 분석을 통해 익숙한 패턴이 드러납니다.
- 읽기 성능: GD-7은 가장 짧은 원시 읽기 시간(1,055ms)을 보이지만, 블록당 가스 소모량은 더 낮습니다. Mgas/s 기준으로 GD-6(6.27)이 가장 우수합니다. GD-5(1,512ms)와 GD-6(1,440ms)은 GD-4(1,893ms)보다 읽기 속도가 빠릅니다.
- 트라이 업데이트: GD-5가 가장 빠르고(124ms), 그 뒤를 GD-4(138ms)와 GD-6(141ms)이 따릅니다. GD-7(218ms)과 GD-8(221ms)은 내부 서브트리가 더 크기 때문에 업데이트가 늦어집니다.
- 커밋: GD-3이 39ms로 가장 빠른 속도를 보였고, GD-4(43ms)와 GD-5(48ms)가 그 뒤를 바짝 쫓았습니다. GD-7(73ms)과 GD-8(87ms)은 더 넓은 노드의 직렬화 성능 저하를 보여줍니다.
S7 – 교차 절단 패턴
시간은 어디로 가는 걸까?
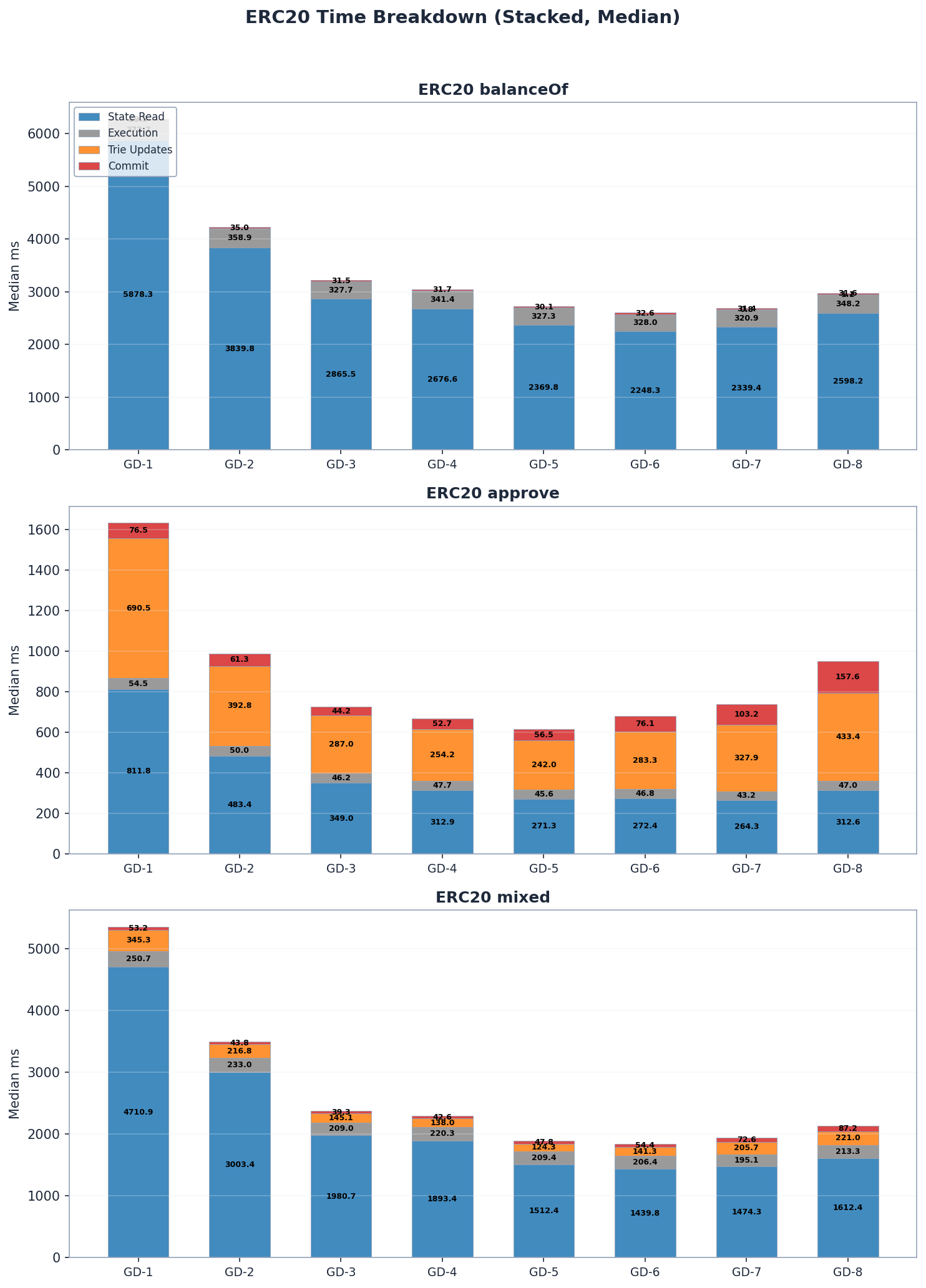
모든 그룹 깊이 구성에서 ERC20 블록 처리 시간의 대부분은 상태 읽기에 소요되며, 전체 시간의 50~85%를 차지합니다. 트라이 업데이트 및 커밋 비용은 읽기 전용 벤치마크(balanceOf)에서는 무시할 수 있을 정도로 작지만, 쓰기(approve)에서는 주요 비용 요소가 됩니다. 특히 내부 서브트리 재해싱 비용이 가장 많이 드는 그룹 깊이가 클수록 이러한 경향이 두드러집니다.
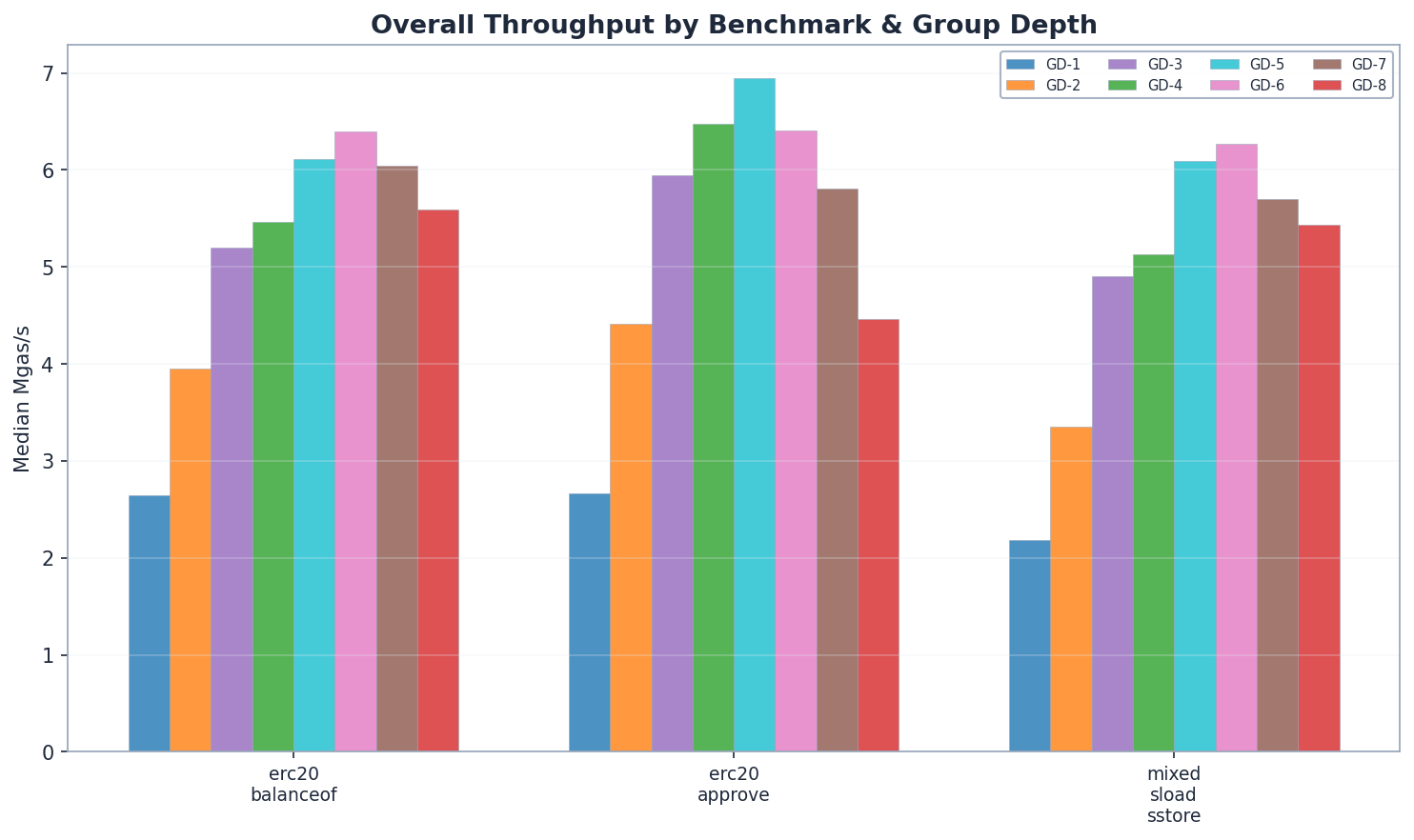
전체 처리량
하드웨어 컨텍스트: NVMe I/O 특성
Gary Rong이 NVMe(Samsung 990 Pro)에서 수행 한 디스크 페이지 읽기 벤치마크는 우리 결과를 해석하는 데 필요한 하드웨어적 맥락을 제공합니다.
- 랜덤 읽기 vs 순차 읽기: 4KB 랜덤 읽기 = 77MB/s(50.6µs) vs 순차 읽기 = 3,306MB/s – 43배의 차이이며, 이는 슬롯당 40배의 페널티와 거의 일치합니다.
- 페이지 크기는 중요합니다. 16KB 크기의 임의 읽기는 4KB 크기보다 2.3배 높은 처리량(174MB/s 대 77MB/s)을 달성하면서 지연 시간은 1.8배에 불과합니다. 그룹 깊이가 넓을수록 노드 크기가 커지므로 더 큰 Pebble 블록 크기를 활용하면 성능 향상을 기대할 수 있습니다.
- 큐 깊이는 성능에 큰 영향을 미칩니다. QD=1에서 QD=8로 변경하면 4KB 랜덤 처리량이 8.7배(77MB/s에서 673MB/s) 향상됩니다. 병렬 EVM을 사용하면 구성 간 읽기 지연 시간 차이를 줄여 이러한 성능 향상을 실현할 수 있습니다.
- 지연 시간 증가율이 선형 이하입니다. 4KB에서 64KB로 증가하면 데이터 크기는 16배 늘어나지만, 지연 시간은 2.3배(50.6µs에서 117.3µs)만 증가합니다. NVMe의 내부 병렬 처리 덕분에 대용량 I/O 요청도 놀라울 정도로 효율적으로 처리됩니다.
이 측정은 파일 시스템 캐시를 우회하는 직접 페이지 읽기 방식을 사용하며, 이는 당사의 콜드 캐시 프로토콜과 유사합니다. 벤치마크 하드웨어(Samsung 990 Pro)는 QEMU VM의 가상 디스크와 다르므로 절대적인 수치는 일치하지 않지만, 비율은 그룹 깊이 최적화와 관련된 NVMe의 기본적인 특성을 보여줍니다.
S8 – 결론
권장 사항: GD-5 또는 GD-6 (업무량에 따라 다름)
작업 부하 프로필에 따라 최적의 깊이는 GD-5 또는 GD-6입니다 .
- 읽기 중심/혼합 워크로드(기본 권장 사항): GD-6. GD-5 대비 읽기 성능은 5% 향상(6.39 vs 6.11 Mgas/s), 혼합 워크로드 성능은 3% 향상(6.27 vs 6.09 Mgas/s)을 보였습니다. 이더리움은 읽기 중심 워크로드이므로 GD-6이 기본 권장 사항입니다.
- 쓰기 작업량이 많은 워크로드: GD-5. GD-4 대비 쓰기 성능이 7% 향상되었고(6.94 vs 6.47 Mgas/s), GD-6 대비 8% 향상되었습니다(6.94 vs 6.41 Mgas/s).
- GD-7은 변곡점을 확인시켜 줍니다. 세 가지 벤치마크 모두에서 GD-6보다 성능이 떨어졌으며(읽기 -5%, 쓰기 -9%, 혼합 -6%), 이는 최적의 시점이 GD-5 또는 GD-6임을 입증합니다.
이 권장 사항은 이진 트라이의 모든 상태 접근을 제어하는 3단계 메커니즘에 기반합니다.
- 횡단 – 뿌리에서 잎으로 내려가는 방식. 비용은 나무 깊이에 비례합니다. 폭이 넓은 나무에 유리합니다 (GD-8: 32단계 vs GD-5: 약 52단계 vs GD-4: 64단계).
- 재해싱(Rehash) – 루트로 돌아가는 경로상의 모든 노드의 내부 서브트리를 다시 계산합니다. 비용은 노드당 2^g - 1 / 2g − 1 에 비례합니다. 트리의 폭이 좁을수록 유리합니다 (GD-4: 노드당 15회 연산, GD-5: 노드당 31회 연산, GD-8: 노드당 255회 연산).
- 커밋 – 수정된 노드를 직렬화하여 디스크에 기록합니다. 비용은 노드 크기에 비례합니다. 트리 구조가 좁을수록 효율적입니다.
GD-5는 쓰기 작업에서 순회 거리와 재해싱 시간 사이의 균형을 최솟값으로 만듭니다. 경로 길이는 GD-4보다 19% 짧으며(노드 수 약 52개 vs 64개), 각 노드의 31개 내부 작업은 여전히 관리 가능한 수준입니다. GD-6에서는 재해싱 비용이 GD-5의 242ms에서 283ms로 17% 소폭 증가하지만, 읽기 및 혼합 워크로드 성능은 여전히 향상됩니다. 쓰기 작업의 변곡점은 GD-5와 GD-6 사이(해시/읽기 비율이 1.0을 넘는 지점)에 있으며, 읽기 작업은 GD-6에서 정점을 찍습니다.
그룹 규모에 관계없이 공통적으로 나타나는 다섯 가지 패턴
패턴 1: 상태 읽기가 지배적입니다. 그룹 깊이나 벤치마크 유형에 관계없이 블록 처리 시간의 50~85%가 디스크에서 상태를 읽는 데 소요됩니다.
state_read_ms스토리지 슬롯 읽기뿐만 아니라 통합 트라이의 계정 및 코드 조회도 포함됩니다.
패턴 2: 임의 접근은 슬롯당 약 40배 더 비쌉니다. 케칵 해시 키(ERC20)는 슬롯당 0.4~1.0ms의 비용이 드는 반면, 순차 접근(합성)은 슬롯당 0.02ms의 비용이 듭니다. 이러한 차이는 케칵 분산 키에 대한 페블 블록 캐시 미스로 인해 발생합니다.
독립적인 NVMe 페이지 읽기 벤치마크는 무작위 I/O와 순차 I/O가 이러한 성능 저하의 거의 대부분을 설명한다는 것을 확인시켜 줍니다(자세한 내용은 7절 하드웨어 컨텍스트 참조).
패턴 3: 캐시 적중률이 약 37~39%에서 정체됩니다. 그룹 깊이가 증가함에도 불구하고, 케칵 해시를 사용하는 워크로드의 경우 스토리지 캐시 적중률은 약 39%를 넘지 못합니다. 256비트 키 공간은 상위 레벨 트라이 노드를 공유하는 경우를 제외하고는 의미 있는 캐시 재사용을 하기에 너무 희소합니다.
패턴 4: 읽기 작업에서는 트라이 업데이트가 무시할 수 있을 정도로 미미하지만, 쓰기 작업에서는 지배적입니다. balanceOf(순수 읽기): trie_updates < < 1.3ms. approve(읽기 + 쓰기): trie_updates 최대 691ms(GD-1). 이러한 비대칭성으로 인해 노드 폭 트레이드오프는 쓰기 워크로드에서만 중요합니다.
패턴 5: 실행 간 교차 검증(CV)은 대부분 Mgas/s에서 10% 미만입니다 . 3단계에서 콜드 캐시 삭제(120회 이상 성공, 실패 0회)를 검증한 결과, 8가지 구성 모두에서 재현 가능한 결과를 얻었습니다. 이전 단계와의 개선을 통해 콜드 캐시 방법론의 타당성이 입증되었습니다.
미해결 질문
페블 블록 크기 상호작용. 모든 테스트는 4KB 블록을 사용했습니다. NVMe 페이지 읽기 벤치마크 결과, 16KB 블록을 사용한 무작위 읽기는 4KB 블록을 사용한 읽기보다 처리량이 2.3배(174MB/s 대 77MB/s) 높으면서 지연 시간은 1.8배(89.7µs 대 50.6µs)에 불과했습니다. 직렬화된 노드의 크기가 4KB를 초과하는 넓은 그룹 깊이의 경우, 더 큰 페블 블록을 사용하면 성능 향상에 상당한 도움이 될 수 있습니다.
동시 블록 처리. 이러한 벤치마크는 블록을 순차적으로 처리합니다. 병렬 실행 엔진은 트라이 업데이트를 코어 전체에 분산시켜 그룹 깊이가 넓어질수록 발생하는 노드별 재해싱 페널티를 줄일 수 있습니다. NVMe 큐 깊이 벤치마크에 따르면 QD=8은 QD=1에 비해 4KB 랜덤 처리량을 8.7배 향상시킵니다(673MB/s 대 77MB/s). 병렬 실행으로 인해 유효 I/O 큐 깊이가 증가하면 그룹 깊이에 따른 읽기 지연 시간 차이가 크게 줄어들 수 있습니다.
이더리움 실행 사양 프레임워크에서 벤치마크를 실행했습니다. 방법론, 원시 데이터 및 재현 스크립트는 실행 사양 저장소 에서 확인할 수 있습니다.





