구글 연구소는 LLM 추론 효율성을 최적화하기 위해 TurboQuant 압축 알고리즘을 도입했습니다.

이 기사는 기계로 번역되었습니다
원문 표시
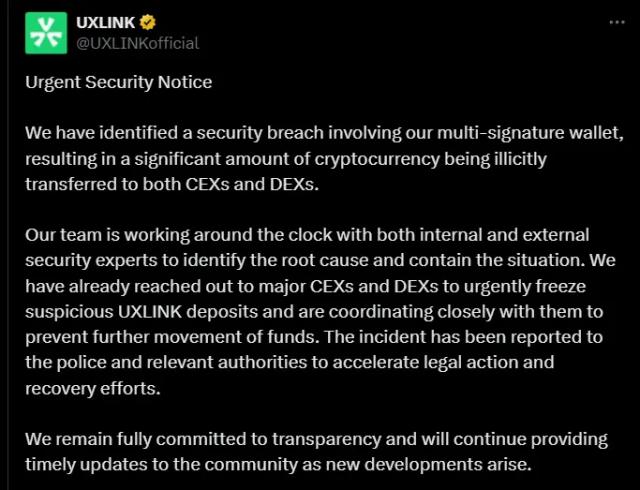
ME 뉴스에 따르면, 구글 리서치는 3월 26일(UTC+8)에 TurboQuant라는 새로운 압축 알고리즘을 발표했습니다. 이 알고리즘은 대규모 언어 모델(LLM)의 추론 효율성을 최적화하는 것을 목표로 하며, LLM 키-값 캐시의 메모리 사용량을 최소 6배 줄이고, 추론 속도를 최대 8배까지 향상시키며, 정밀도 손실을 0으로 줄인다고 합니다. 해당 기사는 이 기술을 "AI 효율성의 새로운 기준을 제시하는 기술"이라고 설명했습니다. (출처: ME)

출처
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유