최근 제가 쓴 글 중에서 가장 실용적이고 유용한 글 중 하나라고 생각합니다. 비록 엄밀히 말하면 암호화와 직접적인 관련은 없지만, 최근 많은 인기를 얻었던 AI 에이전트 와 클로드 코드 에 대한 제 글과도 맥락이 같습니다.
이 뉴스레터에서 AI에 대해 이야기할 때는 보통 Claude, ChatGPT, Gemini 등과 같은 대형 클라우드 AI 도구를 언급합니다. 이러한 모델은 사용자가 프롬프트를 입력하면 서버로 전송되어 처리된 후 응답이 돌아오는 방식으로 작동합니다. 간단하죠. 웹사이트 인터페이스를 사용하든, Claude Max 구독을 통해 Claude Code에서 심층 코딩을 하든 작동 방식은 동일합니다.
하지만 완전히 여러분의 컴퓨터에서 실행되는 오픈소스 AI라는 또 다른 세계가 있습니다. 바로 로컬 LLM(Local Lifecycle Management)인데, 2026년에는 그 성능이 상당히 향상되었습니다.
예상대로 이 분야는 빠르게 발전하고 있습니다. 지난 2주 동안 GLM-5.1은 주요 코딩 벤치마크에서 Claude Opus 4.6을 능가한 최초의 오픈 소스 모델이 되었습니다. 그리고 오늘 Kimi K2.6이 출시되어 GLM의 자리를 차지했습니다. 툴과 모델은 계속해서 개선되고 있으며, 클라우드와 로컬 환경 간의 격차는 점점 줄어들고 있습니다.
지난 한 주 동안 맥 스튜디오에서 로컬 모델에 대해 배우고 실험해 봤는데, 생각보다 훨씬 성능이 좋아서 (기분 좋게) 놀랐습니다. 물론 아주 복잡한 작업에는 클로드 오푸스 4.7이나 다른 최첨단 모델만큼 좋지는 않지만, 제가 매일 하는 작업에는 로컬 모델이 정말 유용합니다. 게다가 무료이고, 개인 정보도 보호되고, 언제든 사용할 수 있죠.
클라우드 구독을 유지하더라도(저도 그렇습니다), 백업이나 특정 작업을 위해 로컬 환경을 구축해 두는 것은 매우 현명한 선택 중 하나입니다.
게다가 정말 매력적이고 흥미로운 분야이며, 자신만의 모델을 소유하고 운영하는 방법을 배우는 것은 요즘 시대에 정말 유용한 기술입니다.
오늘 포스팅에서 다룰 내용은 다음과 같습니다.
로컬 모델을 실행하는 이유는 무엇인가요?
하드웨어: 무엇이 필요합니까?
소프트웨어 도구
어떤 작업에 어떤 모델을 사용해야 할까요?
시작하기
로컬 모델을 AI 에이전트에 연결하기
마무리 생각
인공지능 학습 여정을 한 단계 더 발전시키고 싶으시다면, 제가 친구 몇 명과 함께 설립한 새로운 회사인 ' The Stoa of AI' 를 확인해 보세요.
저희는 영상 강좌를 제작하고 매주 라이브 워크숍 과 통화를 통해 일상 업무에 AI를 적용하는 실질적인 방법을 보여드립니다.
현재 얼리 액세스 모드로 할인된 가격에 제공 중입니다. 여기에서 확인해 보세요: https://www.skool.com/thestoaofai
로컬 모델을 실행하는 이유는 무엇인가요?
주요 이유는 다섯 가지입니다.
개인 정보 보호. 사용자의 입력 내용, 파일, 대화 내용은 모두 사용자의 컴퓨터에 저장됩니다. 제3자 서버를 사용하지 않습니다. 민감한 데이터, 독점 코드 또는 기밀 문서를 다루는 사용자에게는 매우 중요한 장점입니다. 개인 정보 보호를 중요하게 생각하고 AI가 자신을 감시하거나 (더 나아가 악의적인 세력에게 데이터를 유출하는 것을) 원치 않는 모든 사용자에게도 마찬가지입니다.
비용. 일단 하드웨어만 있으면 추론은 무료입니다. AI를 많이 사용하는 경우, 충분한 시간이 지나면 로컬 모델을 통해 투자 비용을 회수할 수 있습니다. 또한 집에 있는 오래된 기기를 재활용하여 로컬 모델을 실행할 수도 있습니다.
속도 제한이 없습니다. 최첨단 모델은 크레딧을 빠르게 소모합니다. 로컬 폴백이 있는 것은 매우 유용하며, 속도 제한에 걸리지 않는 작업(기존 속도 제한에 포함되지 않는 작업)을 실행하는 모델을 보유하는 것도 마찬가지입니다. 대부분의 사람들은 AI에 대해 획일적인 접근 방식을 취하며, Opus나 Sonnet과 같은 모델을 간단한 작업에 사용하지만, 이러한 모델은 과도한 성능을 요구하며 훨씬 간단한 로컬 모델로도 충분히 동일한 성능을 낼 수 있습니다.
오프라인 접속. 정말 멋진 기능입니다. 모델을 로컬에 다운로드하면 인터넷 연결 없이도 작동합니다. 비행 중이나 외딴 지역에서도 모델과 상호 작용할 수 있고, 인류의 모든 지식에 접근할 수 있는 백업 수단으로 자신의 컴퓨터를 활용할 수 있습니다.
완벽한 제어. 모델을 직접 선택하고 원하는 대로 설정을 조정할 수 있습니다. 서비스 약관 변경으로 인해 예기치 않게 차단되거나 약관 위반(또는 당사 시스템 오류)으로 인해 계정이 갑자기 차단되는 일은 없습니다. 로컬 모델을 실행하면 전체 AI 스택을 완벽하게 제어할 수 있습니다.
마지막 문제는 몇 주 전 Anthropic이 OpenClaw 및 기타 타사 에이전트 프레임워크의 Claude Pro/Max 구독 사용을 차단했을 때 실제로 발생했습니다. 해당 설정을 사용하던 사람들은 갑자기 다른 공급업체로 전환하거나 하루에 50달러에 달할 수 있는 API 사용료를 지불해야 하는 상황에 처하게 되었습니다.
로컬 모델에는 이러한 문제가 없습니다.
서두에서 말씀드렸듯이, 로컬 모델은 가장 복잡한 다단계 추론 문제에서는 최첨단 모델에 미치지 못합니다. 하지만 간단하고 일상적인 코딩, 요약, 초안 작성, 웹 스크래핑, 조사 및 질의응답 작업에서는 제가 요구하는 작업의 70~80%를 처리합니다.
최적의 구성은 클라우드와 로컬 모두입니다. 중요한 작업은 클라우드에, 나머지 모든 작업은 로컬에 저장해야 합니다.
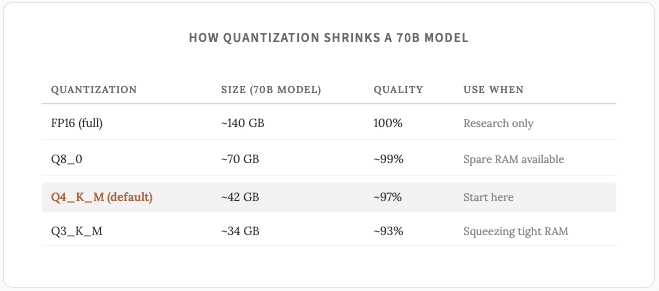
하드웨어 자체에 대해 자세히 알아보기 전에 양자화에 대해 간단히 살펴보겠습니다. 이 용어는 로컬 LLM 환경에서 매우 자주 등장하며 모든 하드웨어 결정에 영향을 미치므로 미리 이해하는 것이 중요합니다.
완전 정밀도 모델은 각 매개변수를 16비트 숫자로 저장합니다. 양자화는 이를 8비트, 4비트 또는 그 이하로 압축합니다. 모델은 크기가 작아지고 속도가 빨라지지만, 정확도가 아주 약간 떨어집니다. 제게 와닿는 음악 비유가 하나 있는데, FLAC은 기술적으로 320kbps MP3 파일보다 음질이 좋지만, 대부분의 사람들은 그 차이를 구분하지 못합니다(저도 마찬가지입니다).
4비트 양자화는 대부분의 작업에서 전체 정밀도와 거의 구별할 수 없는 출력을 생성합니다. Q4_K_M 또는 Q3_K_M과 같은 모델 이름을 접하게 된다면, 이는 4비트 또는 3비트 양자화를 사용했을 뿐 동일한 모델을 나타내는 것임을 알아두세요.
일반적으로 Q4 양자화 모델은 10억 개의 파라미터당 약 0.6~0.7GB의 메모리가 필요합니다(파라미터에 대해서는 지난주 게시물에서 설명했습니다) .
특별한 이유가 없는 한 Q4_K_M 모델을 고수하시는 것을 권장합니다.
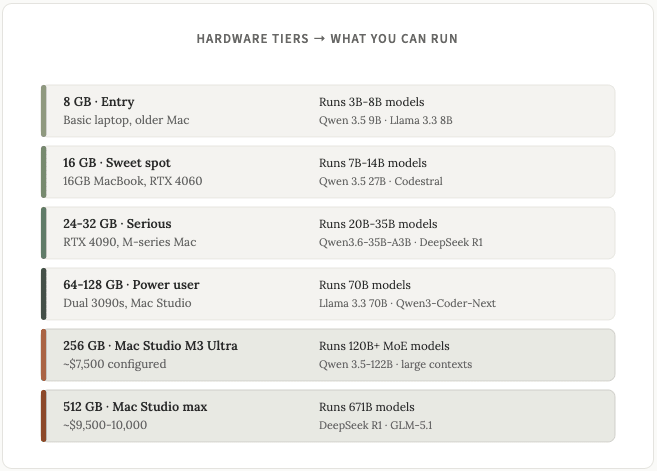
자, 다시 하드웨어 이야기로 돌아가서, 하드웨어에서 LLM을 실행할 때 가장 중요한 요소는 바로 사용 가능한 메모리 용량입니다. PC에서는 VRAM, Mac에서는 통합 메모리가 이에 해당합니다. 그 외의 하드웨어 관련 요소는 모두 부차적인 것입니다.
다음은 하드웨어 사양에 따라 실행할 수 있는 모델 유형을 쉽게 확인할 수 있는 표입니다.
맥은 통합 메모리 덕분에 독보적인 이점을 가지고 있습니다. CPU, GPU, 그리고 뉴럴 엔진이 하나의 메모리 풀을 공유합니다. 512GB의 통합 메모리를 탑재한 맥 스튜디오는 실제로 DeepSeek R1을 6,710억 개의 파라미터로 로컬에서 실행할 수 있습니다.
저는 개인적으로 제 맥 스튜디오(3분기 버전, 약 308GB 메모리 필요)에서 7440억 개의 파라미터를 사용하여 GLM5.1을 실행하고 있습니다.
이것은 흔히 받는 질문인데, 대부분의 경우처럼 답은 "상황에 따라 다릅니다"입니다. 어느 쪽이 무조건 더 좋다고 할 수는 없고, 각각의 상황이나 요구 사항에 따라 장단점이 다릅니다.
고려해야 할 다른 요소들은 다음과 같습니다.
전력 소모와 소음. 맥 스튜디오는 최대 부하 시 약 60W를 소모합니다. 반면 RTX 4090은 450W에 PC의 다른 부품들이 사용하는 전력까지 더하면 훨씬 더 많은 전력을 소모합니다. 하루 종일 추론 작업을 한다면 전기 요금이 상당히 많이 나올 겁니다. 맥은 조용하기도 합니다. RTX 4090을 장착한 PC 워크스테이션은 정말 시끄럽습니다. 제 맥 스튜디오는 책상 위에 놓여 있는데, 거의 소음이 들리지 않습니다.
가격 면 에서 보면, 중고 RTX 3090은 700~900달러 정도에 구할 수 있지만, 이는 그래픽 카드 가격일 뿐입니다. 이를 포함한 PC를 완성하려면 1,500~2,000달러 정도가 필요합니다. 맥의 경우, 24GB 통합 메모리를 탑재한 맥 미니 M4 프로는 완제품 기준으로 1,399달러부터 시작합니다. 또한, 앞서 언급한 전력 소비량 차이 덕분에 맥은 일상적인 사용에 드는 비용도 더 저렴합니다.
최상위 모델인 Mac Studio M3 Ultra(256GB 통합 메모리)는 약 5,999달러입니다. 512GB까지 업그레이드하면 9,500~10,000달러가 됩니다. 하지만 이처럼 고사양에서는 PC 중에서도 비교할 만한 선택지가 없습니다. 671B 파라미터 모델을 실행할 수 있는 PC를 구성하려면 여러 개의 전문가용 GPU가 필요하며 비용은 20,000달러를 훨씬 넘습니다.
귀하의 상황을 고려했을 때, 제가 추천드리는 사항은 다음과 같습니다.
예산이 빠듯하고 이미 PC를 가지고 있다면, 중고 RTX 3090을 장착하세요. 2026년 기준 VRAM 용량 대비 최고의 가성비를 자랑합니다.
1,500달러 미만의 완제품을 원하고 주로 7B-14B 모델을 사용한다면, 24GB Mac Mini M4 Pro(1,399달러)를 추천합니다. 조용하고 효율적이며 조립이 필요 없습니다.
중소형 모델에서 최대한 빠른 응답 속도를 원한다면 RTX 4090 또는 5090을 장착한 PC를 조립하세요. 총 비용은 약 2,500~3,500달러입니다.
30B+ 모델을 실행하거나 조용하고 항상 켜져 있는 기기를 원한다면 48~64GB 용량의 Mac Mini M4 Pro(1,999~2,199달러) 또는 64~128GB 용량의 Mac Studio(2,400~4,500달러)를 고려해 보세요.
전문가용 GPU 없이 가장 큰 규모의 오픈 소스 모델(GLM-5.1, Kimi K2.6, DeepSeek R1 671B)을 실행하려면 256GB 또는 512GB 용량의 Mac Studio가 소비자가 선택할 수 있는 유일한 합리적인 옵션입니다. 가격은 약 6,000달러에서 10,000달러 정도입니다.
이미 가지고 있는 노트북은 어떻게 하죠?
구매를 결정하기 전에 알아두어야 할 점은 M1 맥북 또는 그 이후 모델, 최소 8GB 메모리를 탑재한 기기라면 소형 로컬 모델을 실행할 수 있다는 것입니다. 16GB 메모리를 탑재한 M1 맥북 에어는 7B 모델을 초당 15~25개의 토큰으로 실행할 수 있으며, 메모리 용량이 더 큰 맥북을 사용한다면 더 많은 모델을 실행할 수 있습니다.
이것들은 특별히 고급스럽지는 않겠지만, 간단하고 기본적인 작업에는 충분히 유용할 수 있으며, 더 중요한 것은 추가 비용을 지불하기 전에 지역 모델이 어떻게 작동하는지 감을 잡을 수 있다는 점입니다.
하드웨어가 첫 번째 단계이지만, 하드웨어를 확보한 후에는 자신의 기기에서 모델을 관리하고 실행하는 데 필요한 몇 가지 도구가 필요합니다. 주요 옵션은 다음과 같습니다.
LM Studio는 이 분야를 처음 접하는 분들에게 적합한 시작점입니다. 깔끔하고 사용하기 쉬운 인터페이스를 갖춘 완벽한 데스크톱 애플리케이션입니다. 설치 프로그램을 다운로드하고, 내장된 HuggingFace 모델 라이브러리를 탐색하여 원하는 모델을 클릭한 후 바로 채팅을 시작할 수 있습니다. 터미널 명령어는 전혀 필요하지 않습니다.
이 프로그램에는 실시간 RAM 모니터가 있어 다운로드하기 전에 컴퓨터에서 해당 모델을 실행할 수 있는지 여부를 알려주고, 하드웨어 사양에 따라 다운로드하기에 가장 적합한 모델을 추천해 줍니다.
또한 OpenAI와 호환되는 API를 제공하므로 원하는 경우 스크립트 및 에이전트에 연결할 수 있습니다(예: 로컬 모델에서 Openclaw 또는 Hermes 에이전트를 실행할 수 있습니다).
로컬 모델을 사용하여 무언가를 구축하려는 경우 Ollama가 전반적으로 더 나은 선택이지만, 터미널/명령줄 인터페이스(CLI) 사용에 익숙해야 합니다. LM Studio에 비해 Ollama의 몇 가지 장점은 다음과 같습니다.
Ollama는 LM Studio와 동일한 API 호환성을 가지고 있습니다.
Ollama는 데스크톱 앱도 제공하고 있으며 기능도 있지만, LM Studio에 비하면 기능이 매우 제한적입니다. 실시간 RAM 모니터링, 시각적 파라미터 제어, 모델 비교 기능, HuggingFace 브라우저 등이 없습니다. 간단한 채팅에는 괜찮지만, Ollama의 진가가 발휘되는 분야는 아닙니다. 세련된 GUI를 원한다면 LM Studio를 사용하세요. 헤드리스/스크립팅/상담원 기능을 원한다면 Ollama를 사용하세요. 아니면, 훨씬 더 나은 선택지도 있습니다…
둘 다 설치하셔도 됩니다! 충돌하지 않으니 걱정 마세요. 저는 LM Studio는 새로운 모델을 빠르게 테스트할 때 쓰고, Ollama는 워크플로우에 통합하고 싶은 모든 작업에 사용합니다. 굳이 하나를 고르자면, 개발자가 아닌 초보자라면 LM Studio를, 로컬 모델을 OpenClaw, Hermes 또는 직접 만든 스크립트에 연결하려는 사람이라면 Ollama를 추천합니다.
알아두면 유용한 도구 몇 가지를 더 소개합니다.
Unsloth 는 자체 데이터를 사용하여 모델을 미세 조정할 수 있는 도구로, 로컬 모델 개발에 있어 매우 흥미로운 가능성을 열어줍니다. 3월에 출시된 새로운 Unsloth Studio를 사용하면 문서나 글쓰기 스타일을 기반으로 모델을 학습시킬 수 있습니다. 저는 언젠가 제 모든 뉴스레터(또는 여러 게시물)를 기반으로 모델을 미세 조정하고, Frontier 모델들이 제 어조를 얼마나 잘 표현하는지 비교해 보고 싶습니다.
HuggingFace 는 모델들이 저장되는 저장소입니다. AI를 위한 GitHub라고 생각하시면 됩니다. 직접 상호작용할 필요는 없지만, Local LM이나 Ollama에서 "모델 다운로드"를 할 때, 해당 모델은 대부분 HuggingFace에서 다운로드된다는 것을 알아두시면 됩니다.
Ollama.cpp 와 MLX 는 기본 엔진입니다. Ollama와 LM Studio 모두 추론을 위해 둘 중 하나를 사용합니다. 대부분의 사용자는 이 둘에 대해 생각할 필요가 없습니다.
이 부분은 제가 이 편지를 쓰는 동안에도 두 번이나 업데이트가 안 됐습니다. 아래 내용은 2026년 4월 21일 기준 제 의견입니다. 아마 3개월 안에, 아니면 그보다 더 빨리 이 내용의 절반이 새로운 정보로 대체될 겁니다. 키미 K2.6이 방금 출시됐는데 아직 직접 사용해 보지는 못했지만, GLM-5.1을 사용해 본 결과 키미 K2.6이 나오기 전까지는 GLM-5.1이 가장 좋은 선택이었던 것 같습니다.
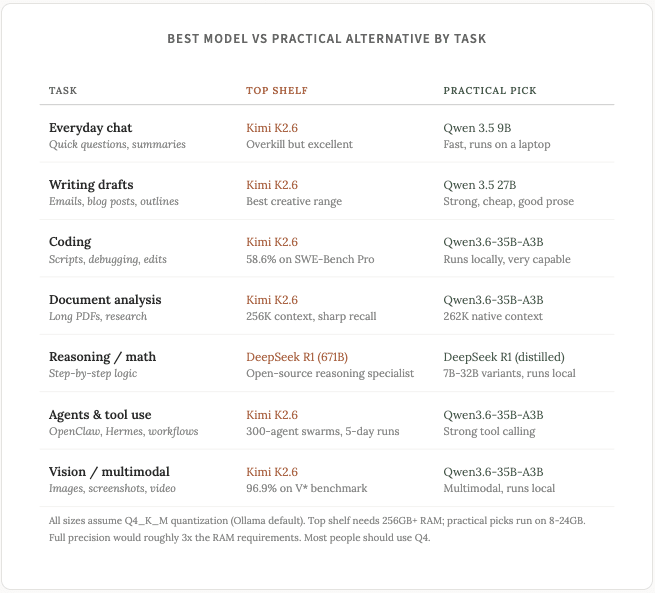
비교 차트를 공유하기 전에 몇 가지 사항을 염두에 두셔야 합니다. 최첨단 개방형 가중치 모델(Kimi K2.6, GLM-5.1)은 거의 모든 면에서 작은 모델보다 성능이 뛰어납니다. 이는 매개변수가 많은 대형 모델의 특성입니다. 하지만 이러한 대형 모델을 로컬에서 실행하려면 고성능 하드웨어가 필요하므로, 심층적인 추론이 필요하지 않은 작업에는 더 작은 모델이 훨씬 저렴한 비용과 낮은 지연 시간으로 충분한 성능을 제공합니다. 따라서 여러분이 스스로에게 던져야 할 실질적인 질문은 "이 작업에 가장 적합한 모델은 무엇인가?"가 아니라 "이 작업을 충분히 잘 처리하는 가장 작은 모델은 무엇인가?"입니다.
벤치마크에 대해 잠깐 언급하겠습니다. 이 글에서 SWE-Bench Pro를 몇 번 언급할 텐데, 코딩 성능에 가장 중요한 벤치마크입니다. SWE-Bench Pro는 모델이 독립적인 함수를 작성할 수 있는지 테스트하는 대신, 실제 오픈 소스 프로젝트의 GitHub 이슈를 모델에 제공하고 이를 수정하도록 합니다. 모델은 코드베이스를 읽고 버그를 이해하고, 수정 코드를 작성하여 기존 테스트를 통과하는 코드를 제출해야 합니다. 50%라는 점수는 모델이 제시된 버그의 절반을 해결했다는 의미입니다.
참고로, 클로드 오푸스 4.6은 53.4%의 점수를 기록했습니다. 새로 출시된 오푸스 4.7은 무려 64.3%라는 놀라운 점수를 얻었죠. 일반적으로 55~60%대의 점수는 최첨단 기술로 여겨지지만, 최첨단 모델들이 계속해서 발전함에 따라 이 수치는 당연히 끊임없이 변화할 것입니다.
코딩 분야에서 최고급 제품으로 꼽히는 두 가지 오픈웨이트 모델이 현재 가장 주목받고 있습니다.
Moonshot AI의 Kimi K2.6 이 오픈 소스 코딩 세계의 새로운 강자로 떠올랐습니다. 오늘 출시된 이 모델은 길고 복잡한 코딩 작업을 위해 특별히 설계되었습니다. 다른 모델들이 한두 시간 만에 일관성을 잃기 시작하는 반면, K2.6은 실제 엔지니어링 작업에서 5일 동안 연속 실행이 가능하다는 것을 입증했습니다.
이 도구는 최대 300개의 하위 에이전트를 병렬로 제어할 수 있습니다(정말 놀랍죠!). 즉, "이 모노레포 전체를 리팩토링해 줘"와 같은 명령을 내리면 수백 개의 전문 워커에 작업을 분산시켜 처리할 수 있다는 뜻입니다. SWE-Bench Pro 벤치마크에서 Claude Opus 4.6보다 우수한 성능(58.6% vs 53.4%)을 보여줍니다. 에이전트 기반의 애플리케이션을 개발하거나 코드베이스 작업을 많이 하는 경우, 현재로서는 이것이 가장 좋은 로컬 모델입니다 (하지만 다시 말씀드리지만, 이 모든 것은 내일 당장 바뀔 수도 있습니다).
Z.ai의 GLM-5.1은 (4월 7일 출시된 구형 버전이지만, "구형"이라고 하기엔 좀 이상하죠) 코딩 품질 면에서는 여전히 훌륭합니다. SWE-Bench Pro에서 58.4%의 점수를 기록했는데, K2.6보다 아주 약간 떨어지는 수준입니다. 최첨단 코딩을 원하지만 Kimi 모델을 실행할 하드웨어가 없다면, GLM-5.1도 좋은 선택입니다.
실용적인 측면에서 볼 때, 4월 16일에 출시된 Qwen3.6-35B-A3B 버전은 대부분의 사용자에게 최적의 성능을 제공할 것입니다. MoE 아키텍처 덕분에 모델 전체 크기가 35B에 달하더라도 토큰당 활성화되는 파라미터는 3B에 불과하여 24GB 메모리 용량의 컴퓨터에서도 빠른 속도로 실행됩니다. 텍스트뿐만 아니라 이미지와 비디오도 처리하며, 최대 1M 토큰까지 지원하는 컨텍스트 창을 통해 전체 코드베이스나 긴 문서를 입력으로 사용할 수 있습니다.
일상적인 코딩, 초안 작성, 요약 및 상담원 워크플로우 작성에 능숙합니다.
이건 좀 뜬금없는 얘기지만, 누군가 클로드 오푸스 4.7이 출시된 날 자기 노트북으로 테스트해봤는데, 로컬 모델이 자전거를 탄 펠리컨을 더 잘 그렸다고 하더라고요 (아주 황당하고 우스꽝스러운 예시지만, 인생에 이런 소소한 재미가 빠질 수 없잖아요?).
하드웨어 사양이 낮은 사용자에게는 Qwen 3.5 9B가 실용적인 선택이며, 8GB 맥북에서도 무리 없이 작동합니다. 복잡한 다중 파일 연산 작업에는 적합하지 않지만, 이메일 수정, 기사 요약, 간단한 질문과 답변 작성 등 일상적인 작업에는 매우 뛰어난 성능을 보여줍니다.
시작하기
로컬 모델을 직접 실행해보고 싶다면 LM Studio와 Ollama 모두에서 시작하는 데 도움이 되는 몇 가지 지침을 아래에 제시합니다.
LM 스튜디오:
LM Studio는 lmstudio.ai 에서 다운로드할 수 있습니다.
설치하세요.
앱을 엽니다.
"검색"을 클릭하고 모델을 검색하세요. 실시간 RAM 모니터에서 해당 모델이 사용 중인 컴퓨터에서 실행 가능한지 여부를 확인할 수 있습니다.
다운로드를 클릭하세요.
완료되면 "모델 불러오기"를 클릭하면 바로 사용할 수 있습니다. LM 스튜디오에서 모델과 직접 채팅하거나 OpenClaw/Hermes와 같은 에이전트에 연결할 수 있습니다(다음 섹션에서 설명하겠습니다).
올라마:
ollama.com 에서 Ollama를 설치하세요(Mac 및 Linux용 한 줄 설치 프로그램).
그런 다음 ollama.com/library 또는 huggingface.co 로 이동하여 모델을 살펴보세요.
모든 모델 목록에는 실행 명령어가 정확하게 나와 있어야 합니다. HuggingFace는 더 다양한 모델을 제공하며 파일 크기를 표시해 주기 때문에 다운로드 전에 RAM 용량과 비교해 볼 수 있습니다.
원하는 모델을 찾았으면 터미널에서 실행하세요. 다음과 같은 화면이 나타날 것입니다.
이런 명령어를 처음 실행하면 모델이 다운로드되고, 그 후에는 하드 드라이브에서 모델을 불러옵니다. 다운로드/로드가 완료되면 터미널에서 바로 모델과 상호 작용할 수 있습니다.
로컬 모델을 사용하는 것은 놀라울 정도로 간단합니다. 처음부터 끝까지 전체 설정 과정은 오래 걸리지 않으며, 일반적으로 가장 오래 걸리는 부분은 모델 자체를 다운로드하는 것입니다(모델에 따라 몇 GB에서 수십/수백 GB까지 다양함).
말 그대로 이것이 바로 여러분이 자신의 기기에서 로컬 LLM을 완벽하게 실행하는 데 필요한 전부입니다. 하드웨어가 있는 사람이라면 누구나 가장 작은 모델 몇 개로라도 한번 시도해 보시길 권장합니다.
로컬 모델을 AI 에이전트에 연결하기
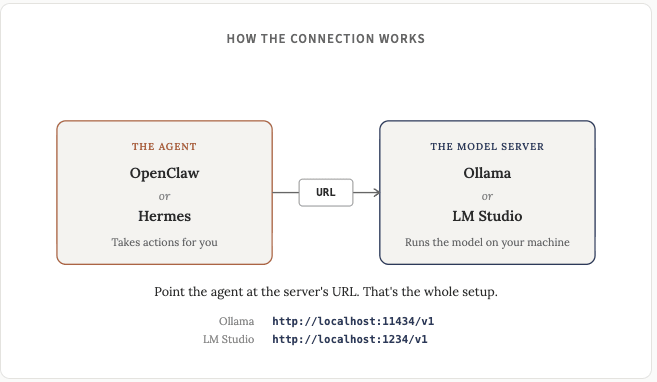
여기서부터 흥미로워집니다. 로컬 챗봇을 실행하는 것도 유용하고 멋지지만, 로컬 모델을 에이전트 프레임워크(Openclaw 또는 Hermes)에 연결하는 것이 진정한 잠재력 발휘입니다.
OpenClaw: OpenClaw를 설치한 다음, 설정 > 구성(또는 openclaw.json)에서 Ollama의 경우 http://localhost:11434/v1, LM Studio의 경우 http://localhost:1234/v1을 가리키는 사용자 지정 공급자를 추가합니다. API 유형을 "openai-completions"로 설정하고 로드된 모델과 일치하는 이름을 지정합니다.
Hermes 에이전트: Hermes를 설치한 다음, `hermes model` 명령어를 실행하여 설정 마법사를 엽니다. "사용자 지정 엔드포인트"를 선택하고 로컬 URL(위와 동일: Ollama는 http://localhost:11434/v1, LM Studio는 http://localhost:1234/v1)을 입력한 후, 로드한 모델을 선택합니다. 나중에 채팅창에서 `/model` 명령어를 사용하여 모델을 변경할 수 있습니다.
Ollama와 LM Studio는 모두 OpenAI 호환 API를 제공하고, OpenClaw와 Hermes도 해당 형식을 지원하므로 결국에는 모든 것이 매우 간단합니다. 한 번 사용법을 익히고 나면 새로운 모델을 시도하는 것이 매우 쉬워질 것입니다.
로컬 LLM에 대한 많은 콘텐츠들이 과장된 경향이 있습니다. 모든 사람이 로컬 모델을 사용해야 한다고 생각하지는 않으며, 이러한 모델의 한계점도 충분히 이해합니다. 하지만 AI에 열정적인 사람이라면 하루 이틀 정도 시간을 내어 로컬 모델을 다뤄보는 것이 큰 도움이 될 것이라고 생각합니다.
로컬 모델은 복잡한 다단계 추론을 위한 Claude Opus 4.7을 대체할 수 없습니다. 최첨단 클라우드 모델만큼 콘텐츠를 잘 작성할 수도 없고, 복잡한 다중 파일 코드베이스를 안정적으로 디버깅할 수도 없습니다.
이 서비스 는 사용자가 요청하는 대부분의 기본 작업을 처리하는 개인적이고 무료이며 항상 이용 가능한 AI 비서를 제공할 뿐만 아니라, 때로는 자전거를 탄 펠리컨 이미지를 더 잘 만들어내기도 합니다.
그리고 많은 사람들에게 그 정도면 충분합니다.
품질 곡선은 분명히 존재하며, 모든 로컬 모델이 동일한 품질을 제공하는 것은 아닙니다. 8비트에서 14비트로 넘어가는 것은 확연한 차이를 보이며, 14비트에서 32비트로 넘어가는 것 또한 마찬가지입니다. 512GB 맥 스튜디오에 Kimi K2.6 또는 GLM-5.1을 설치할 수 있는 하드웨어를 갖추고 있다면, SWE-Bench Pro에서 Claude Opus 4.6보다 우수한 성능을 발휘하는 모델을 사용하게 됩니다. 일반적인 하드웨어의 경우, 2026년 4월 기준으로 24~32GB 구성에서 Qwen3.6-35B-A3B가 최적의 선택입니다. 표준 사양의 컴퓨터에서도 최첨단 기술에 버금가는 품질을 경험할 수 있습니다.
제가 모든 분들께 추천하는 가장 좋은 접근 방식은 가장 어려운 작업은 클라우드에, 나머지 작업(또는 비공개로 유지 해야 하는 작업)은 로컬에 저장하는 것입니다. 둘 중 하나를 선택할 필요는 없습니다.
2026년 4월 현재, 지역 LLM 생태계는 성숙 단계에 접어들었습니다. 지난 몇 달 동안 질적인 면에서 놀라운 도약이 있었고, 이러한 추세가 지속된다면 우리 같은 평범한 사람들이 집에서 활용할 수 있는 AI 기술의 발전은 정말 상상을 초월할 것입니다.
솔직히 말해서, 이 모델들은 아마 여러분이 생각하는 것보다 훨씬 더 뛰어날 겁니다. 그리고 여러분의 컴퓨터에서 실행되고, 거의 제로에 가까운 운영 비용과 데이터 유출 없이 질문에 답해주는 AI를 갖는다는 것은, 요즘 제가 SF 소설의 위대한 작가 중 한 명의 명언을 떠올리게 하는 또 다른 일 중 하나입니다.
면책 조항: 본 뉴스레터의 내용은 투자 조언으로 간주되어서는 안 됩니다 . 저는 금융 자문가가 아니며, 이는 단지 저의 개인적인 의견과 생각일 뿐입니다. 암호화폐 관련 상품 거래 또는 투자 전에 반드시 전문 금융 자문가와 상담하시기 바랍니다. 공유된 링크 중 일부는 제휴 링크일 수 있습니다.