


[ 소개] 볼륨에 미쳐라! 초당 500개에 가까운 토큰을 출력할 수 있는 세계에서 가장 빠른 대형 모델 Groq이 하룻밤 사이에 폭발적으로 증가했습니다.
잠에서 깨어난 초당 500개의 토큰을 출력할 수 있는 Groq 모델은 인터넷의 모든 화면을 휩쓸었습니다.
"세계에서 가장 빠른 LLM"이라고 할 수 있습니다!
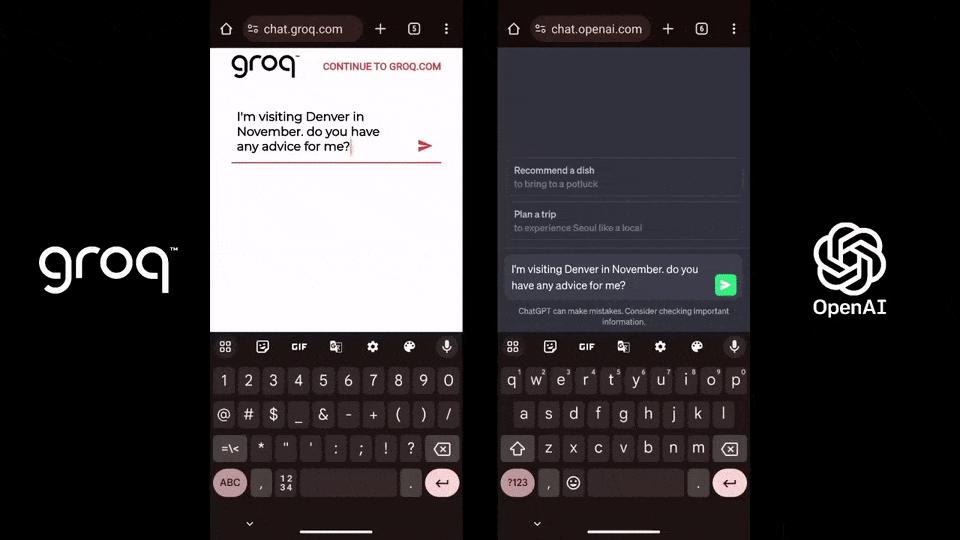
이에 비해 ChatGPT-3.5는 초당 40개의 토큰만 생성합니다.
일부 네티즌들은 간단한 코드 디버깅 문제를 완료하는 데 걸리는 시간을 확인하기 위해 GPT-4와 Gemini를 비교 벤치마킹하기도 했습니다.
놀랍게도 Groq은 출력 속도 면에서 Gemini보다 10배, GPT-4보다 18배 더 빨라 두 제품을 완전히 압도했습니다. (하지만 답변 품질 측면에서는 Gemini가 더 낫습니다.)
결론은 누구나 무료로 사용할 수 있다는 것입니다!
Groq 홈페이지에서 현재 두 가지 모델, 즉 Mixtral 8x7B-32k와 Llama 270B-4k를 단품으로 구매할 수 있습니다.
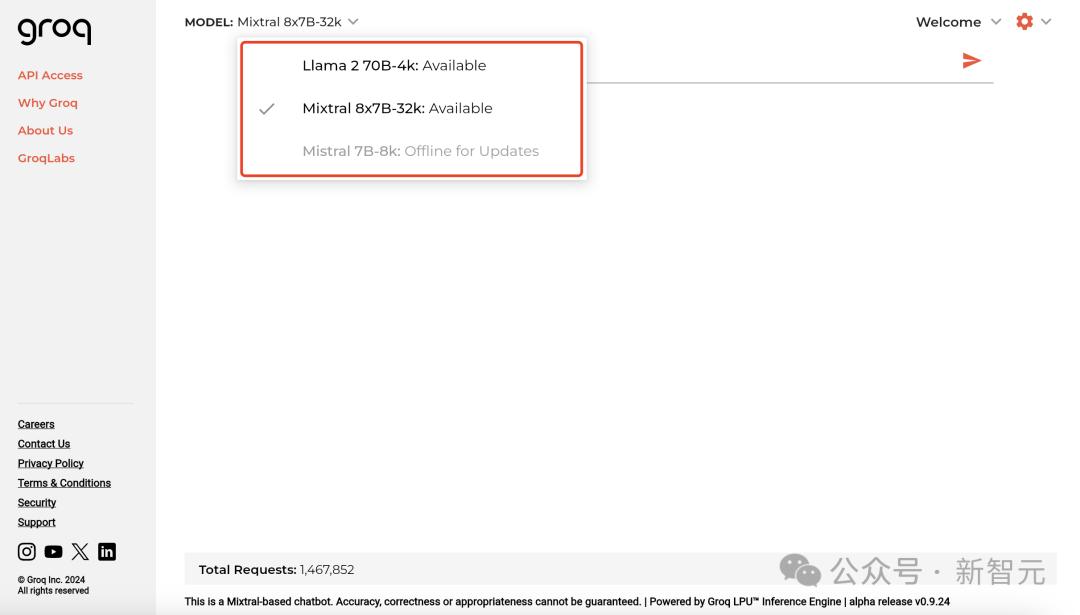
주소: https://groq.com/
한편, 개발자는 Groq API를 사용할 수 있으며, OpenAI API와 완벽하게 호환됩니다.
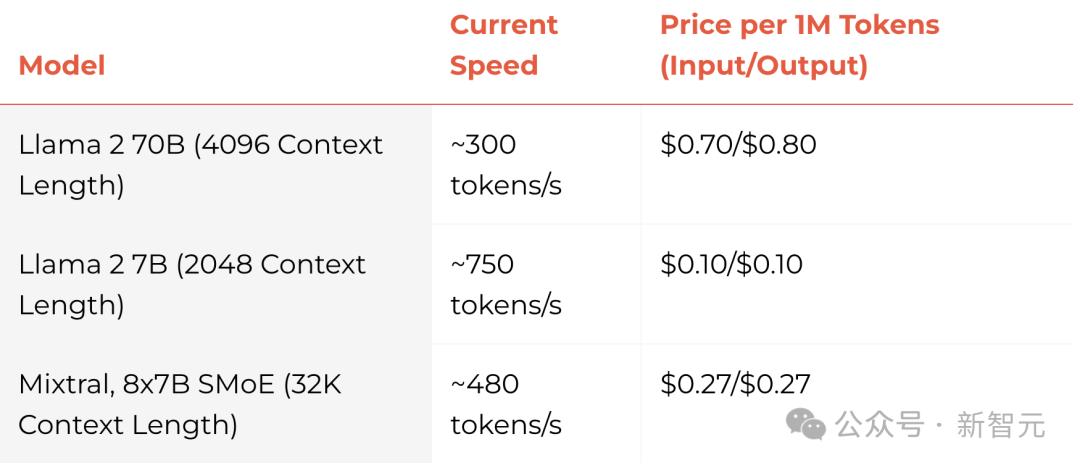
믹스트랄 8x7B SMoE는 최대 480 토큰/S까지 가능하며, 가격은 100만 토큰에 0.27달러입니다. 극단적인 경우에는 라마2 7B로 750 토큰/S도 달성할 수 있습니다.
현재 1백만 토큰 무료 체험판도 제공하고 있습니다.
그루크의 갑작스러운 폭발적 성장의 가장 큰 공로는 GPU가 아니라 자체 개발한 LPU(언어 처리 장치)에 있습니다.
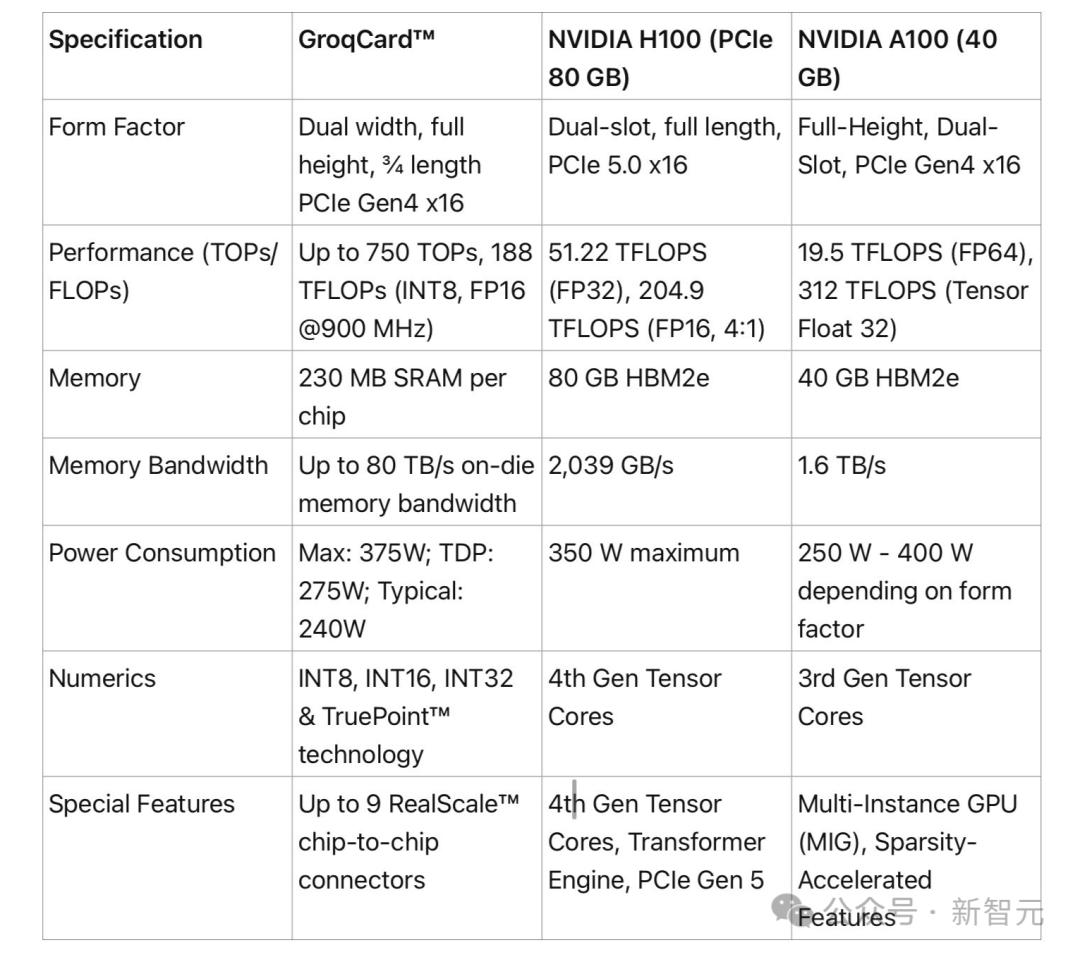
단일 카드의 RAM 용량은 230MB에 불과하고 가격은 개당 2만 달러입니다. LLM 작업에서 LPU는 NVIDIA의 GPU보다 10배 빠른 성능을 발휘합니다.

얼마 전 벤치마크 테스트에서 Groq LPU 추론 엔진에서 실행되는 Llama 2 70B는 차트 상위권을 휩쓸었으며, LLM 추론 성능 면에서 상위 클라우드 제공업체보다 18배 더 빨랐습니다.
넷플릭스 빅 웨이브 데모
Groq의 로켓과 같은 생성 속도는 많은 사람들에게 충격을 주었습니다.
네티즌들은 직접 만든 데모를 공개했습니다.
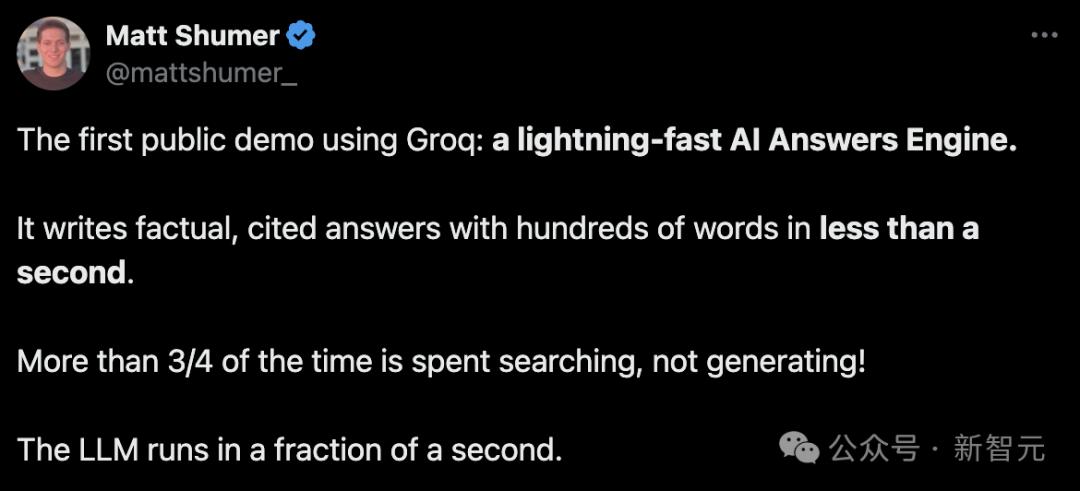
수백 단어의 사실적인 답변을 1초도 안 되는 시간에 따옴표로 생성합니다.
사실, 콘텐츠 생성이 아닌 검색이 처리 시간의 4분의 3 이상을 차지합니다!
'간단한 피트니스 프로그램 만들기'라는 동일한 프롬프트에 대한 Groq과 ChatGPT의 나란한 응답을 속도 차이로 비교해보았습니다.

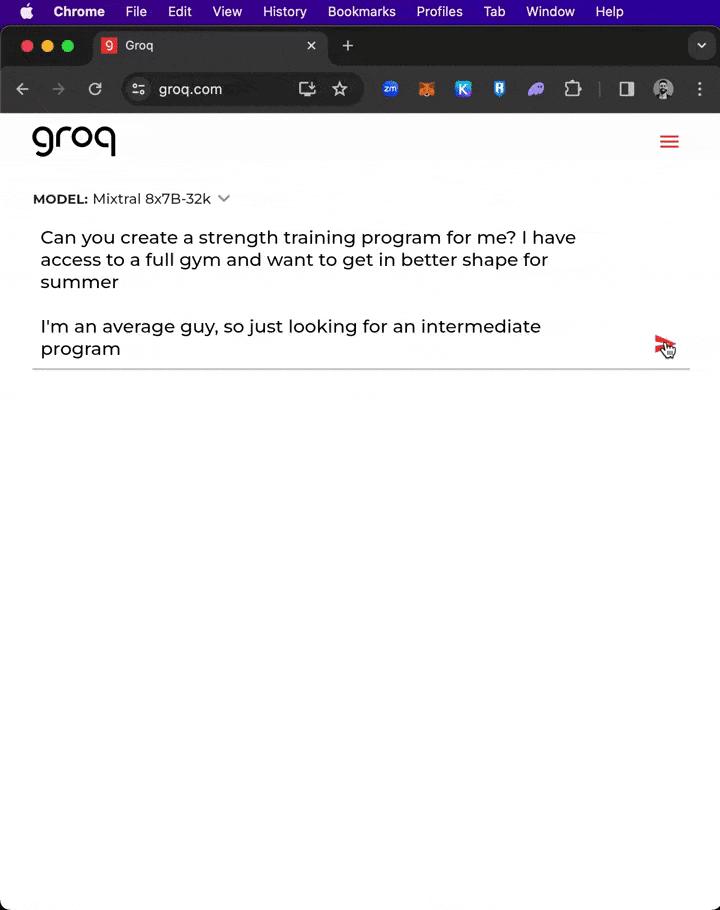
300단어 이상의 '거대한' 프롬프트에 직면했을 때 Groq는 1초 이내에 저널 논문의 초기 개요와 작성 계획을 작성했습니다!

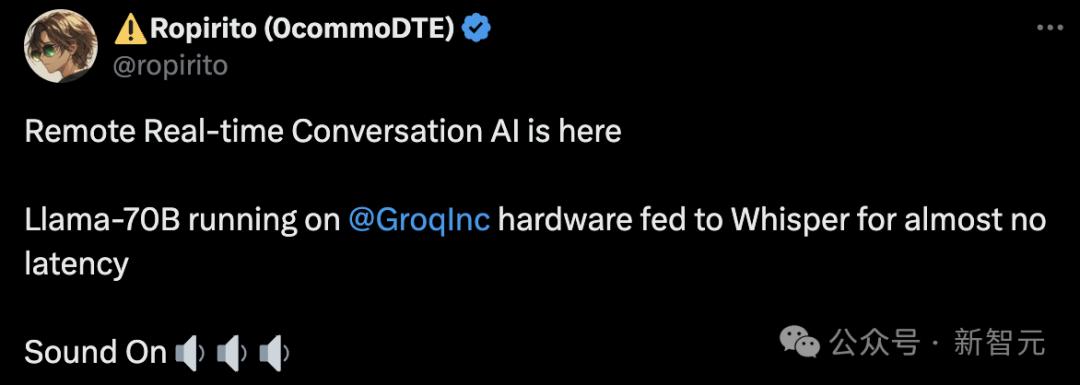
Groq은 원격 실시간 AI 대화를 완벽하게 지원합니다. GroqInc 하드웨어에서 Llama 70B를 실행한 다음 거의 지연 시간 없이 Whisper에 제공했습니다.
GPU는 더 이상 존재하지 않나요?
Groq 모델이 놀랍도록 빠른 속도로 응답할 수 있는 이유는 바로 그 배후에 있는 회사 Groq(동명의 회사)에서 개발한 고유한 하드웨어인 LPU 덕분입니다.
결코 기존의 GPU가 아닙니다.

간단히 말해, Groq은 텐서 스트림 프로세서(TSP)라는 새로운 유형의 처리 장치를 자체적으로 개발했으며 이를 '언어 처리 장치' 또는 LPU로 정의했습니다.
이는 그래픽 렌더링을 위해 설계된 병렬 프로세서로, 수백 개의 코어를 포함하고 있어 AI 연산에 일관된 성능을 제공합니다.

논문 주소: https://wow.groq.com/wp-content/uploads/2024/02/GroqISCAPaper2022_ ASoftwareDefinedTensorStreaming멀티프로세서대규모머신러닝용.pdf
특히, LPU는 GPU와는 매우 다르게 작동합니다.
시간적 명령 집합 컴퓨터(TISC) 아키텍처를 사용하므로 고대역폭 메모리(HBM)를 사용하는 GPU처럼 메모리에서 데이터를 자주 로드할 필요가 없습니다.
이 기능은 HBM 부족을 방지할 뿐만 아니라 비용도 효과적으로 절감할 수 있습니다.
이 설계는 모든 클럭 사이클을 효율적으로 활용할 수 있어 안정적인 지연 시간과 처리량을 보장합니다.
LPU는 에너지 효율 측면에서도 장점이 있습니다. 멀티스레드 관리의 오버헤드를 줄이고 코어 리소스의 활용도가 떨어지는 것을 방지함으로써 LPU는 와트당 더 높은 컴퓨팅 성능을 달성할 수 있습니다.
현재 Groq은 모델 추론을 위한 다양한 머신 러닝 개발 프레임워크(PyTorch, TensorFlow, ONNX 등)를 지원할 수 있지만, LPU 추론 엔진을 사용한 ML 트레이닝은 지원하지 않습니다.
한 사용자는 "요청과 응답 처리 측면에서 Groq의 LPU가 NVIDIA의 GPU보다 성능이 뛰어나다"고 말하기도 했습니다.

고속 데이터 전송에 의존해야 하는 NVIDIA GPU와 달리, Groq의 LPU는 시스템에서 고대역폭 메모리(HBM)를 사용하지 않습니다.
GPU가 사용하는 메모리보다 약 20배 빠른 SRAM을 사용합니다.
AI의 추론 계산에는 모델 학습에 비해 훨씬 적은 데이터가 필요하다는 점을 고려할 때, Groq의 LPU는 에너지 효율이 더 높습니다.
추론 작업을 수행할 때 외부 메모리에서 더 적은 데이터를 읽고 NVIDIA의 GPU보다 더 적은 전력을 소비합니다.
LPU는 GPU와 같은 극단적인 스토리지 속도 요구 사항이 없습니다.
AI 처리 시나리오에서 Groq의 LPU를 사용하는 경우, NVIDIA GPU를 위한 특별한 스토리지 솔루션을 구성할 필요가 없을 수도 있습니다.

Groq의 혁신적인 칩 설계는 여러 TSP를 원활하게 연결하여 GPU 클러스터에서 흔히 발생하는 병목 현상을 방지하고 확장성을 크게 향상시킵니다.
즉, 더 많은 LPU가 추가될수록 성능이 선형적으로 확장되어 대규모 AI 모델의 하드웨어 요구 사항을 단순화하고 개발자가 시스템을 재구성할 필요 없이 애플리케이션을 더 쉽게 확장할 수 있습니다.

Groq은 자사의 기술이 강력한 칩과 소프트웨어를 통해 추론 작업에서 GPU의 역할을 대체할 수 있다고 주장합니다.
넷플릭스의 정확한 사양을 비교한 차트입니다.
이 모든 것이 무엇을 의미할까요?
개발자에게는 실시간 AI 애플리케이션에 매우 중요한 성능을 정확하게 예측하고 최적화할 수 있다는 것을 의미합니다.
향후 AI 애플리케이션을 위한 서비스의 경우, LPU는 잠재적으로 GPU에 비해 엄청난 성능 향상을 제공할 수 있습니다!
A100과 H100의 공급이 매우 부족하다는 점을 고려할 때, 이러한 고성능 대체 하드웨어를 보유한다는 것은 스타트업에게 큰 이점이 될 것입니다.
OpenAI는 현재 제품 확장 시 직면하는 연산 능력 부족 문제를 해결하기 위해 전 세계 정부와 투자자들로부터 7조 달러의 자금을 유치하기 위해 노력하고 있습니다.

0.8초의 응답 시간으로 2배의 처리량 달성
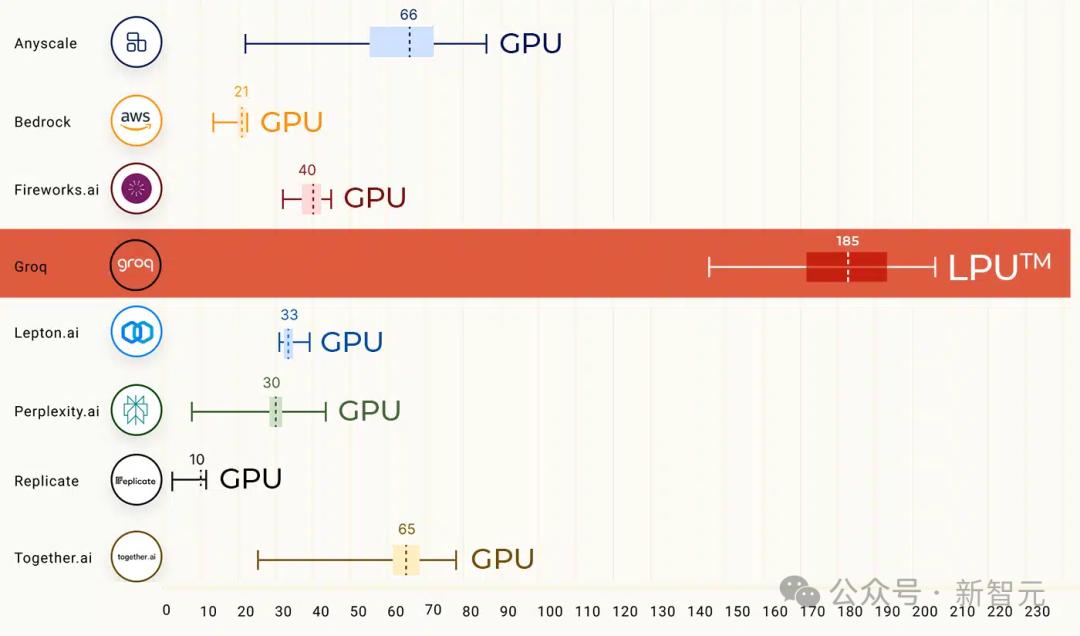
얼마 전, Groq의 솔루션은 ArtifialAnalysis.ai의 LLM 벤치마크에서 8가지 주요 성능 지표를 능가했습니다.
여기에는 지연 시간 대 처리량, 시간 경과에 따른 처리량, 총 응답 시간 및 처리량 분산이 포함되었습니다.
Groq은 오른쪽 하단의 녹색 사분면에서 가장 우수한 결과를 얻었습니다.
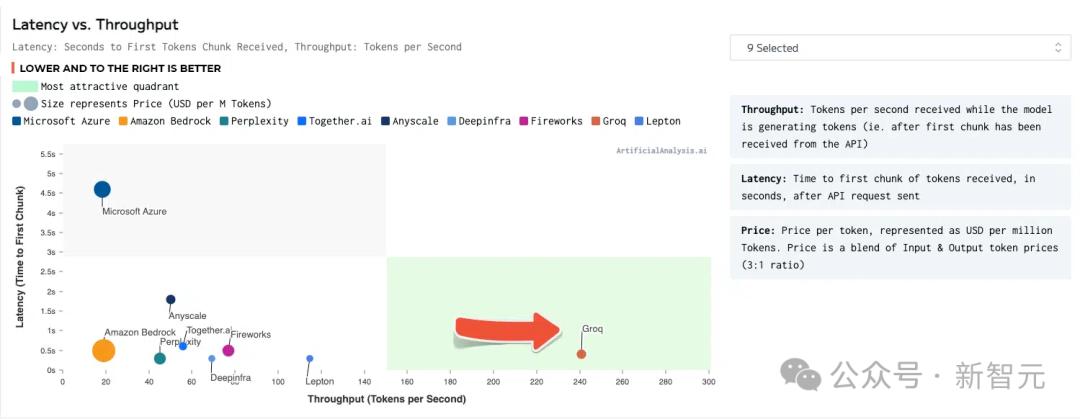
출처: ArtifialAnalysis.ai
Llama 2 70B는 Groq LPU 추론 엔진에서 가장 잘 작동하며 초당 241개의 토큰 처리량을 달성하여 다른 대형 플레이어보다 두 배 이상 많은 처리량을 기록했습니다.
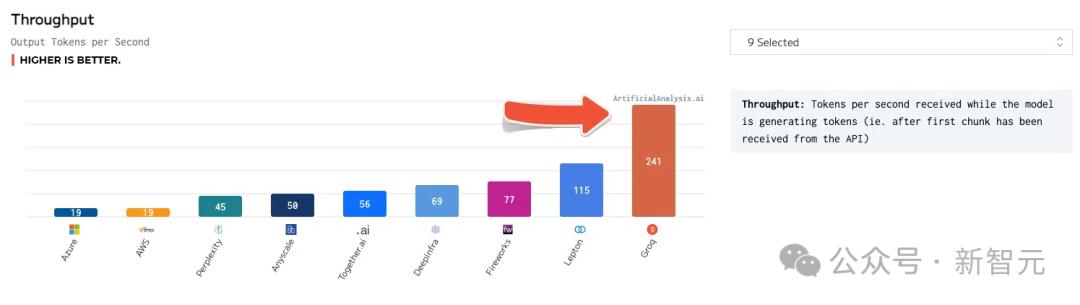
총 응답 시간
Groq은 또한 응답 시간이 가장 짧아 100개의 토큰을 받은 후 단 0.8초 만에 결과를 출력합니다.
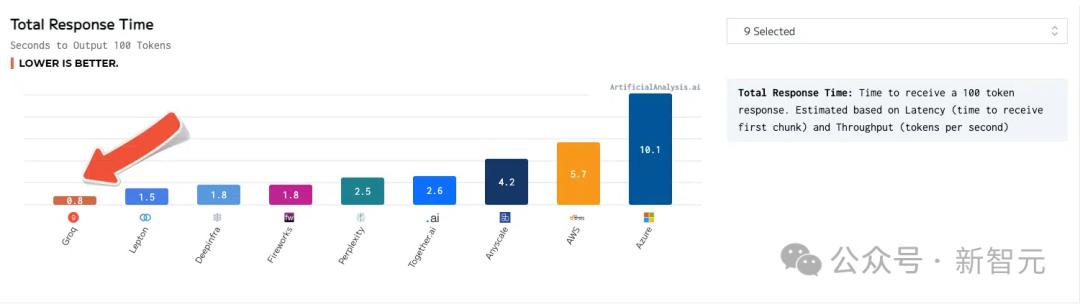
또한, Groq은 초당 300개의 토큰을 처리할 수 있는 여러 내부 벤치마크를 실행하여 속도에 대한 완전히 새로운 기준을 다시 한 번 세웠습니다.
Groq의 CEO 조나단 로스는 "Groq은 '가진 자와 가지지 못한 자'를 없애고 AI 커뮤니티의 모든 사람이 성공할 수 있도록 돕기 위해 존재합니다."라고 말했습니다. 그리고 '속도'는 개발자의 아이디어를 비즈니스 솔루션으로 전환하고 원시 앱을 변화시키는 핵심 요소이기 때문에 추론은 이러한 목표를 달성하는 데 있어 핵심입니다."라고 말합니다.

230MB RAM이 장착된 카드의 경우 20만 달러
앞서 눈치 채셨겠지만, LPU 카드의 메모리는 230MB에 불과합니다.

그리고 가격은 미화 20,000달러 이상입니다.

더 넥스트 플랫폼에 따르면, 위의 테스트에서 Groq은 실제로 라마 2 70B에서 추론을 수행하기 위해 576개의 GroqChip을 사용했습니다.

일반적으로 GroqRack에는 9개의 노드가 장착되며, 이 중 8개는 계산 작업을 담당하고 1개는 백업 노드로 남겨둡니다. 하지만 이번에는 9개의 노드 모두 연산 작업에 사용되었습니다.

이에 대해 웹 마스터는 Groq LPU가 직면 한 주요 문제 중 하나는 고대역폭 메모리 (HBM)가 전혀 장착되어 있지 않고 HBM3보다 최대 20 배 빠른 초고속 정적 랜덤 액세스 메모리 (SRAM)의 작은 (230MiB) 블록 만 장착되어 있다는 점이라고 말했습니다.
즉, 단일 AI 모델 실행을 지원하려면 완전히 로드된 서버 랙 4개에 해당하는 약 256개의 LPU를 구성해야 합니다. 각 랙은 8개의 LPU 유닛을 수용할 수 있으며, 각 유닛은 또 다른 8개의 LPU를 포함합니다.
반면, 이러한 모델을 상당히 효율적으로 실행하려면 서버 랙 밀도의 1/4에 해당하는 H200 하나만 있으면 됩니다.
이 구성은 하나의 모델만 실행해야 하고 사용자 수가 많은 시나리오에서 사용하면 좋은 성능을 발휘할 수 있습니다. 그러나 여러 모델을 동시에 실행해야 하는 경우, 특히 높은 수준의 LoRA를 사용하는 등 많은 모델 미세 조정이나 작업이 필요한 경우에는 이 구성이 더 이상 적합하지 않습니다.
또한 로컬 배포가 필요한 시나리오의 경우, 동일한 모델을 사용하는 여러 사용자를 중앙 집중화할 수 있다는 것이 주요 장점인 Groq LPU의 이러한 구성의 이점이 분명하지 않습니다.
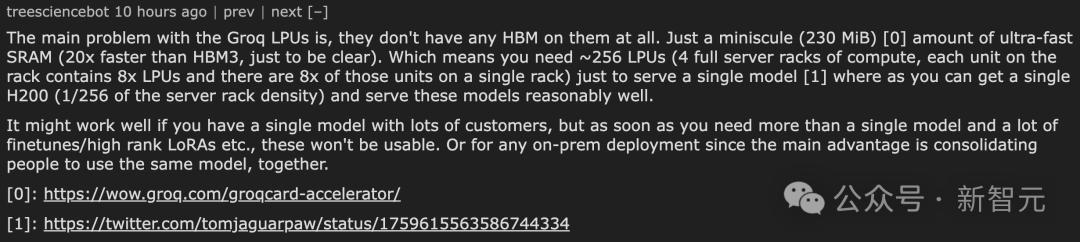
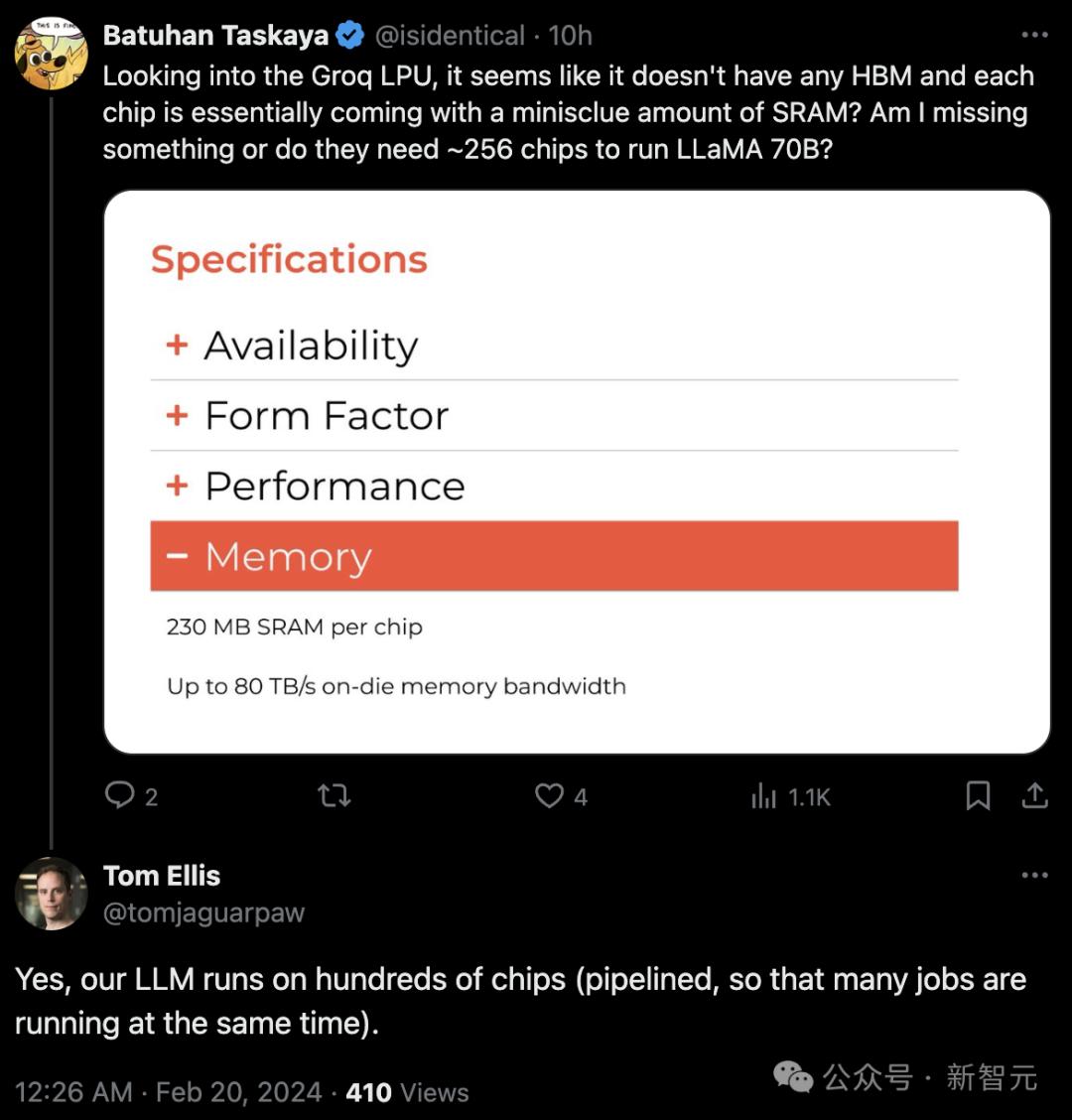
또 다른 사용자는 "Groq LPU에는 HBM이 없는 것 같고 각 칩에는 기본적으로 소량의 SRAM이 제공되나요? 즉, Llama 70B를 실행하려면 약 256개의 칩이 필요하다는 건가요?"라고 말했습니다.
공식적인 답변을 받을 줄은 몰랐습니다. 예, 저희 LLM은 수백 개의 칩으로 실행됩니다.
또한 LPU의 카드 가격에 대한 질문도 있었는데, "그러면 제품이 H100보다 터무니없이 비싸지 않나요?"라는 질문이었습니다.

머스크 그로크, 소리는 같지만 단어는 다릅니다.
얼마 전, Groq은 벤치마크 결과를 공개해 큰 화제를 불러일으킨 바 있습니다.
그리고 이번에는 최신 AI 모델인 Groq이 빠른 반응 속도와 GPU를 대체할 수 있는 새로운 기술로 다시 한 번 소셜 미디어를 뜨겁게 달구고 있습니다.
그러나 Groq을 개발한 회사는 대형 모델의 시대 이후 새롭게 등장한 스타가 아닙니다.
2016년에 설립되어 직접 Groq이라는 이름을 등록했습니다.

CEO이자 공동 설립자인 조나단 로스는 Groq을 설립하기 전에는 구글 직원이었습니다.
그는 구글 텐서 프로세싱 유닛(TPU)으로 알려진 1세대 TPU 칩의 핵심 요소를 설계하고 구현하는 프로젝트에 20%의 비율로 참여했습니다.
그 후 Ross는 유명한 '문 팩토리' 프로젝트의 초기 단계인 Google X Labs의 신속 평가팀에 합류하여 Google의 모회사인 알파벳을 위한 새로운 Bets(단위)를 설계하고 인큐베이팅했습니다.

아마도 대부분의 사람들은 머스크의 Grok과 Groq 모델의 이름을 혼동하고 있을 것입니다.

사실 머스크가 이 이름을 사용하지 못하도록 설득하는 데 어려움이 있었습니다.
지난해 11월, 머스크의 시조인 AI 모델 Grok(철자가 다른)이 주목을 받기 시작하자 Groq의 개발팀은 머스크에게 다른 이름을 선택해 달라고 유머러스하게 요청하는 블로그 게시물을 올렸습니다:
저희 이름을 좋아하시는 이유를 잘 알고 있습니다. 로켓, 초고속철도, 한 단어로 된 모회사 이름 등 빠른 것을 선호하시며, Groq LPU 추론 엔진은 LLM 및 기타 생성형 AI 애플리케이션을 실행하는 가장 빠른 방법 중 하나이기 때문입니다. 하지만 서둘러 이름을 변경해 달라고 요청해야 합니다.

그러나 머스크는 두 모델 이름의 유사성에 대해서는 답변하지 않았습니다.
참조:
https://x.com/JayScambler/status/1759372542530261154?s=20
https://x.com/gabor/status/1759662691688587706?s=20
https://x.com/GroqInc/status/1759622931057934404?s=20
이 글은 WeChat 공개 번호 '신지식인 위안'(ID: AI_era) 의 글이며, 36 Krypton의 peach sleepy가 편집하고 허가를 받아 게시했습니다.





