

작성자: Decentralized.Co
편집자: 테크 플로우 (Techflowpost) TechFlow
트랜잭션 확장성은 항상 이슈 주제였습니다. 지난 몇 주 동안 우리는 모나드가 TPS 확장에 어떻게 도움이 될 수 있는지 탐구해 왔습니다.
다음은 Saurabh Deshpande 가 작성한 Monad의 작동 방식에 대한 자세한 설명입니다.
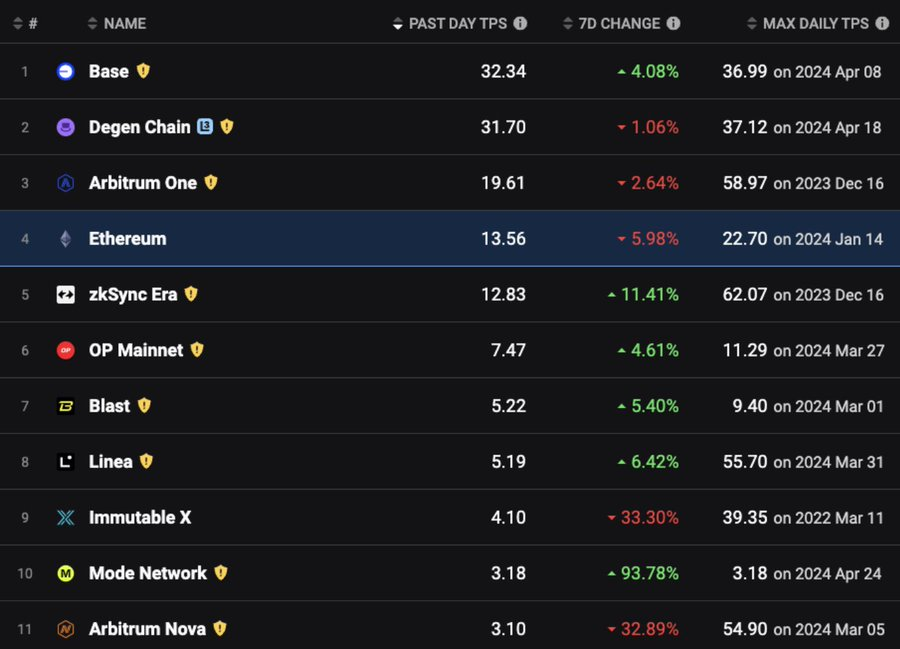
TPS는 우리가 주목하는 지표입니다. 우리는 체인이 더 많은 사용자와 애플리케이션을 지원할 수 있으므로 더 높은 TPS를 지원하기를 원합니다. 아래 차트는 이더 과 L2의 TPS 수치를 보여줍니다. 어떤 체인도 100TPS 표시를 깨뜨린 적이 없습니다. TPS는 규모를 측정하는 데 사용되는 일반적인 용어입니다. TPS는 모든 트랜잭션이 동일하지 않고 복잡도가 다르기 때문에 부정확합니다. 그러나 단순화를 위해 TPS를 규모의 척도로 사용합니다.
TPS를 높이려면 어떻게 해야 할까요?
첫 번째 접근 방식은 솔라나가 그랬던 것처럼 완전히 새로운 시스템을 구축하는 것입니다. 속도에 비해 EVM 호환성이 희생됩니다. 단일 스레드 실행(멀티 코어 CPU와 단일 코어 CPU 비교) 대신 멀티 스레드 실행을 사용하고 트랜잭션을 병렬화하며 다른 합의 메커니즘을 사용합니다.
두 번째 접근 방식은 오프체인 실행을 사용하고 중앙 집중식 순서 통해 이더 확장하는 것입니다.
세 번째 접근 방식은 EVM을 별도의 구성 요소로 분해하고 확장성을 위해 최적화하는 것입니다.
최근 2억 2,500만 달러를 모금한 새로운 EVM 호환 L1인 Monad는 EVM을 직접 사용하는 대신 처음부터 EVM을 구축하고 있습니다. 확장성을 높이기 위해 이 세 번째 접근 방식을 선택했습니다.
우리는 Monads로 인해 발생한 몇 가지 주요 변경 사항에 대해 논의했습니다.
병렬 실행
EVM( 이더 Virtual Machine)은 트랜잭션을 순차적으로 실행합니다. 하나의 트랜잭션이 실행되기 전에 다음 트랜잭션이 기다려야 합니다. 이렇게 생각해보세요. 오토바이 조립 공장의 플랫폼을 생각해 보세요. 여러 대의 트럭이 오토바이 부품을 배송합니다(각 트럭에는 오토바이 50대를 조립하는 데 필요한 모든 부품이 포함되어 있습니다). 조립 공장에서는 하역, 분류, 조립, 적재라는 네 가지 기능을 수행합니다.

현재 EVM 설정에는 플랫폼이 하나만 있으며 로드 및 언로드에 동일한 위치가 사용됩니다. 따라서 트럭이 주차되어 있는 동안 오토바이 부품은 동일한 트럭에 하역, 분류, 조립 및 적재됩니다. 분류팀이 작업하는 동안 다른 팀이 기다리고 있습니다. 따라서 작업을 별도의 슬롯으로 생각하면 각 팀은 4개의 슬롯에서 한 번만 작업합니다. 이로 인해 상당한 비효율성이 발생하므로 보다 효율적인 접근 방식이 필요합니다.
이제 4개의 서로 다른 적재 및 하역 영역이 있는 플랫폼을 상상해 보십시오. 하역 팀이 한 번에 한 대의 트럭만 작업할 수 있더라도 다음 세 개의 트럭을 기다릴 필요는 없습니다. 다음 트럭으로 직접 이동할 수 있습니다.
분류, 조립, 적재 팀도 마찬가지입니다. 하역이 완료되면 트럭은 적재 구역으로 이동하여 적재 팀이 조립된 오토바이를 적재할 때까지 기다립니다. 따라서 하나의 플랫폼과 하역 구역만 있는 창고는 모든 작업을 순차적으로 수행하는 반면, 4개의 플랫폼과 서로 다른 하역 구역을 가진 창고는 병렬화를 수행합니다.
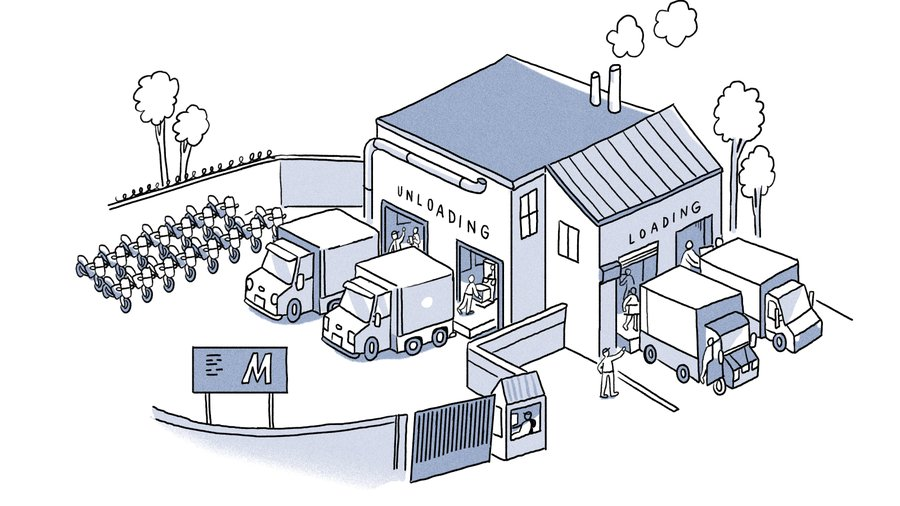
Monads를 여러 트럭 플랫폼이 있는 창고와 동일한 인프라로 생각하십시오. 그러나 그것은 간단하지 않습니다. 트럭에 의존하면 복잡성이 증가합니다. 예를 들어, 트럭 한 대에 오토바이 50대를 조립할 부품이 모두 없으면 어떻게 됩니까? 거래가 항상 독립적인 것은 아닙니다. 따라서 모나드는 병렬로 실행할 때 서로 의존하는 트랜잭션을 처리해야 합니다.
그것을 처리하는 방법? 낙관적 병렬 실행이라는 방법을 구현합니다. 프로토콜은 독립적인 트랜잭션만 병렬로 실행할 수 있습니다. 예를 들어 Joel의 잔액 이 1ETH인 4개의 거래를 생각해 보세요.
Joel은 Saurabh에게 0.2 이더 보냅니다.
시드가 NFT를 민트.
Joel은 Sid에게 0.1 이더 보냅니다.
Shlok PEPE 구매
이러한 모든 트랜잭션은 병렬로 실행되며 보류 중인 결과가 하나씩 제출됩니다. 보류 결과의 출력이 트랜잭션의 원래 입력과 충돌하는 경우 트랜잭션이 다시 실행됩니다. 트랜잭션 2와 4는 서로 독립적이기 때문에 다른 트랜잭션의 입력과 충돌하는 보류 결과가 없습니다. 그러나 트랜잭션 1과 4는 독립적이지 않습니다.
4개의 거래가 모두 동일한 상태에서 시작되므로 초점은 Joel의 1ETH 잔액 에 맞춰져 있습니다. Joel이 0.2 ETH를 보낸 후 잔액 0.8 ETH였습니다. Joel이 Sid에게 0.1 ETH를 보낸 후 그의 잔액 은 0.9 ETH입니다. 결과는 하나씩 제출되므로 출력이 입력과 충돌하지 않는지 확인됩니다. 보류 결과 1을 제출한 후 Joel의 새 잔액 은 0.8 ETH입니다.
이 출력은 트랜잭션 3의 입력과 충돌합니다. 이제 0.8 ETH를 입력하여 3이 다시 실행됩니다. 3번을 실행한 후 Joel의 잔액 은 0.7ETH입니다.
모나드DB
이 시점에서 분명한 질문은 대부분의 거래를 다시 실행할 필요가 없다는 것을 어떻게 알 수 있느냐는 것입니다. 대답은 재실행이 병목 현상이 아니라는 것입니다. 병목 현상은 이더 의 메모리에 액세스하는 것입니다. 이더 상태를 데이터베이스에 저장하는 방식은 상태에 액세스하는 것을 어렵게 만드는 것으로 나타났습니다(시간이 많이 걸리고 따라서 비용이 많이 듭니다). 이것은 Monad의 또 다른 개선 사항입니다: MonadDb. Monads가 데이터베이스를 구성하는 방식은 읽기 작업과 관련된 오버헤드를 줄입니다.
트랜잭션을 다시 실행해야 하는 경우 모든 입력은 이미 캐시 메모리에 있으므로 전체 상태보다 액세스하기 쉽습니다.
솔라나는 테스트넷에서 50,000 TPS를 가졌으나, 현재 메인넷에서는 약 1,000 TPS만 가지고 있습니다. Monad는 내부 테스트넷에서 10,000개의 실제 TPS를 달성했다고 주장합니다. 이것이 항상 실제 성능을 나타내는 것은 아니지만 Monad가 실제 응용 프로그램에서 어떻게 작동하는지 보고 싶습니다.






