Stop guessing which LLMs your machine can actually handle.
llmfit analyzes your hardware in seconds to find your perfect local AI match.
P.S. Sharing more practical, no-fluff AI resources with 150K+ engineers here:codenewsletter.ai/subscribe?ut...…
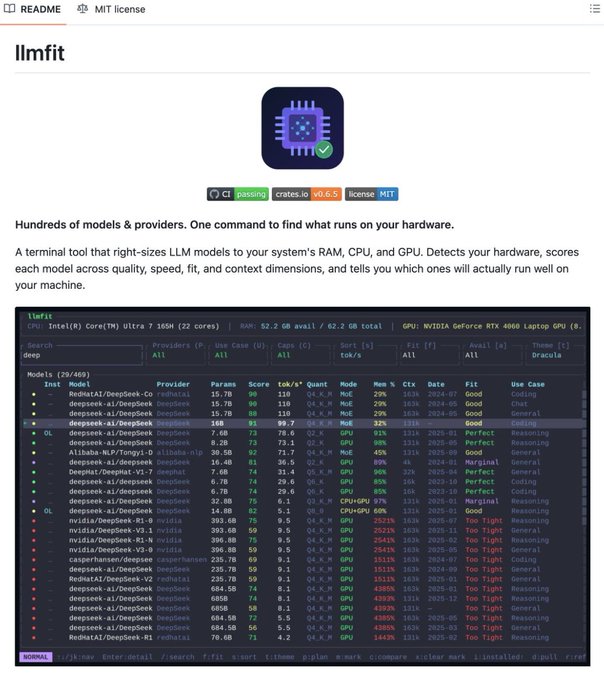
So, Instead of downloading a model and hitting an OOM error, it scans your RAM, CPU, GPU, and VRAM first - then scores every model across 4 dimensions:
1. Quality - param count, model family, quantization penalty
2. Speed - estimated tok/s for your exact backend (CUDA, Metal, ROCm)
3. Fit - memory utilization vs. your available hardware
4. Context - context window vs. your use case
Each model gets a label: Perfect / Good / Marginal / Too Tight.