Tác giả: Iris Chen, Tiến sĩ Ni

1. Quy trình AI+3D giảm đáng kể chi phí và tăng hiệu quả
Sự bùng nổ của ChatGPT vào năm 2022 đã gây ra làn sóng AIGC. Generative AI đã có tác động Sự lật đổ đến nhiều ngành công nghiệp. Các lĩnh vực nội dung 3D trong trò chơi, phim và truyền hình, in 3D và các kịch bản khác cũng đang định hình lại cấu trúc ngành dưới ảnh hưởng của Generative. AI. So với CAD cảnh công nghiệp và BIM cảnh kiến trúc theo đuổi độ chính xác, nội dung 3D trong những cảnh này theo đuổi sự sáng tạo nhiều hơn và AI tổng quát có thể được sử dụng nhiều hơn.
Công nghệ tạo 3D đề cập đến việc sử dụng mạng lưới thần kinh độ sâu để tìm hiểu và tạo ra các mô hình 3D của các vật thể hoặc cảnh và trên cơ sở mô hình 3D, cung cấp màu sắc, ánh sáng và bóng tối cho các vật thể hoặc cảnh để làm cho kết quả tạo ra trở nên chân thực hơn, bao gồm cả mô hình AI , Liên kết xương AI, Các hướng nghiên cứu AI như biểu thức, hành động AI và kết xuất AI. Chuỗi công nghiệp nội dung 3D bao gồm lớp cơ bản cung cấp công nghệ, lớp trung gian cung cấp tài sản và lớp ứng dụng phát triển tài sản. Nhà cung cấp công nghệ trong đó lớp cơ bản chủ yếu cung cấp cho ngành các công cụ cơ bản để sản xuất công nghệ tạo 3D. thay thế sản xuất truyền thống ở lớp này.

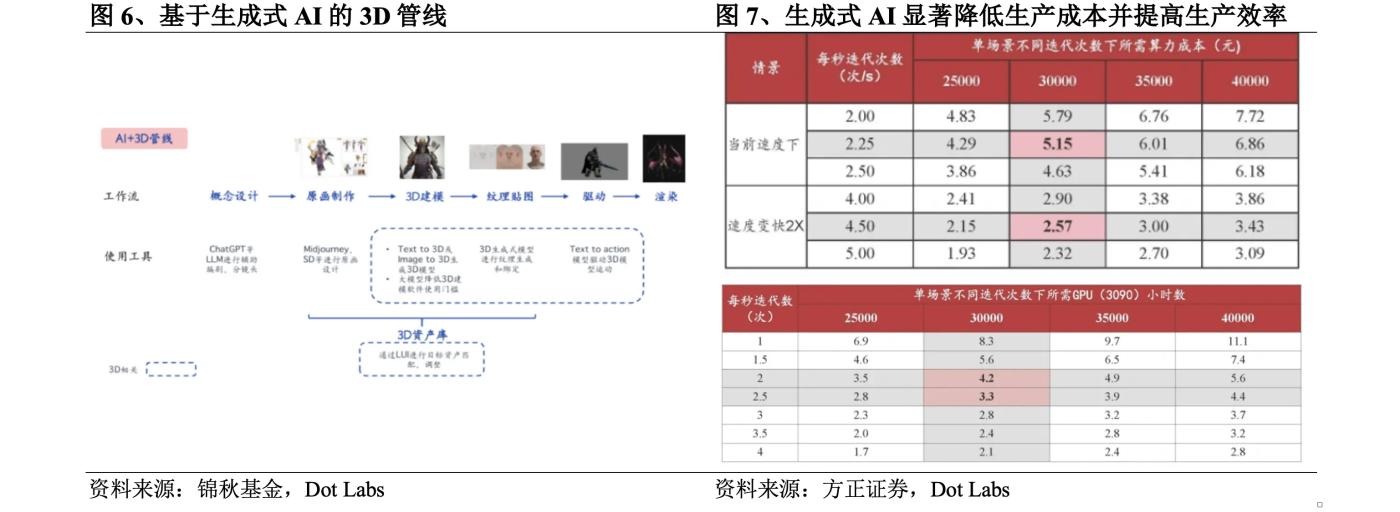
Quy trình 3D truyền thống bao gồm thiết kế ý tưởng, tạo ra tranh gốc, mô hình 3D, lập bản đồ kết cấu, điều khiển và kết xuất. Trong đó, các liên kết liên quan đến 3D như tạo ra tranh gốc, mô hình 3D và lập bản đồ kết cấu có chu kỳ tạo ra dài và phụ thuộc nhiều vào lao động. , đó là chi phí R&D chính. Lấy game 3D làm ví dụ. Các liên kết liên quan đến 3D trong game 3D thường chiếm 60-70% chi phí nghiên cứu và phát triển. Trong đó, liên kết tạo mô hình 3D là cực kỳ tốn kém nếu nhà sản xuất ủy thác cho đội ngũ gia công sản xuất 3D. tài nguyên mô hình cao với hơn 100.000 khuôn mặt, Giá ít nhất phải là 30.000 nhân dân tệ và phải mất 30-45 ngày nếu bạn mua nó từ thư viện tài sản 3D, ngoài vấn đề về tài sản tùy chọn hạn chế, điều này thường xảy ra. cần 5-10 người/ngày dọn dẹp trước khi sử dụng. Theo dữ liệu từ Sketchfab, công ty nội dung 3D lớn nhất thế giới, chi phí ước tính để sản xuất mô hình 3D là khoảng 3-40 USD và thời gian cần thiết là khoảng 2-15 giờ.

AI tạo ra có thể đóng một vai trò trong hầu hết các khía cạnh của quy trình 3D truyền thống. Nhiều studio trò chơi hiện có các thành viên nghệ thuật với Midjourney và Stable Diffusion. Việc áp dụng các mô hình lớn cũng đã hạ thấp ngưỡng cho quy trình tạo mô hình 3D dựa trên AI. có thể giảm chi phí sản xuất nội dung 3D và nâng cao hiệu quả sản xuất. Lấy trò chơi nổi tiếng trên Steam "Phantom Pallu" vào đầu năm 2024 làm ví dụ. Người lập mô hình phải mất một tháng tạo ra mô hình 3D của Pallu (một sinh vật trong trò chơi). cần thêm 20 ngày. Có khoảng 100 loại parlu trong trò chơi. Theo phương pháp sản xuất đường ống 3D truyền thống, phải mất tổng cộng khoảng 5.000 ngày. Tuy nhiên, studio đã sử dụng AI tổng hợp để hoàn thành công việc trong 3 năm.
Theo tính toán của Founder Securities, sử dụng card đồ họa RTX 3090 để lặp lại 30.000 lần bằng phương pháp Zero123, chi phí tạo ra tài sản 3D là khoảng 5 nhân dân tệ trong tương lai, khi phương pháp hoàn thiện và tốc độ lặp lại sẽ nhanh gấp đôi. , chi phí sẽ giảm xuống còn 2,6 nhân dân tệ và một cảnh duy nhất chỉ mất khoảng 3,3-4,2 giờ so với 3-40 đô la Mỹ và 2-15 giờ trước đó, việc áp dụng AI tạo ra giúp giảm đáng kể chi phí sản xuất và cải thiện hiệu quả sản xuất. .
2. Phát triển công nghệ tạo 3D
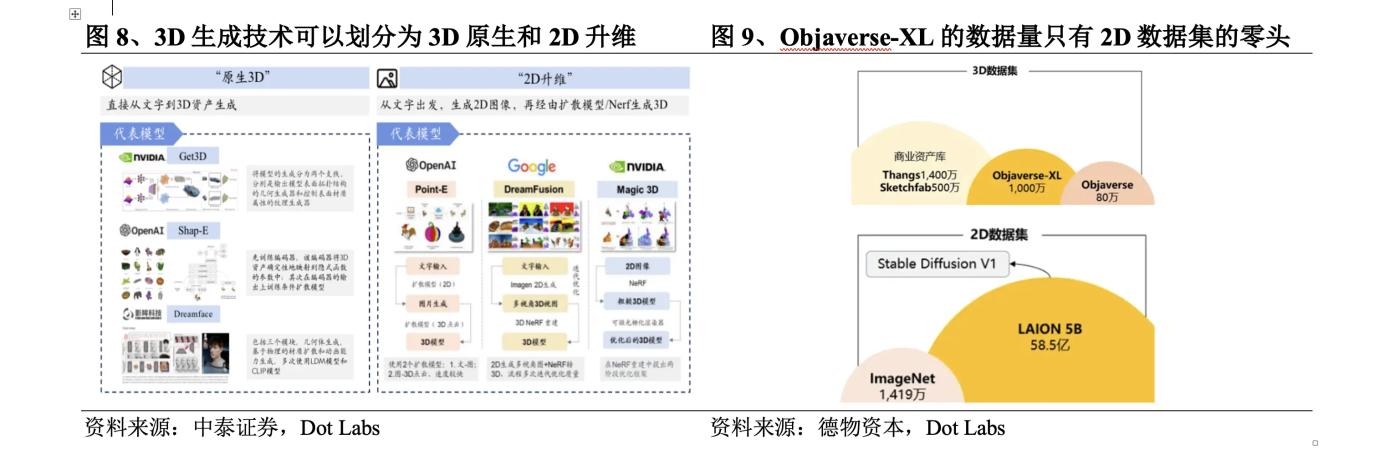
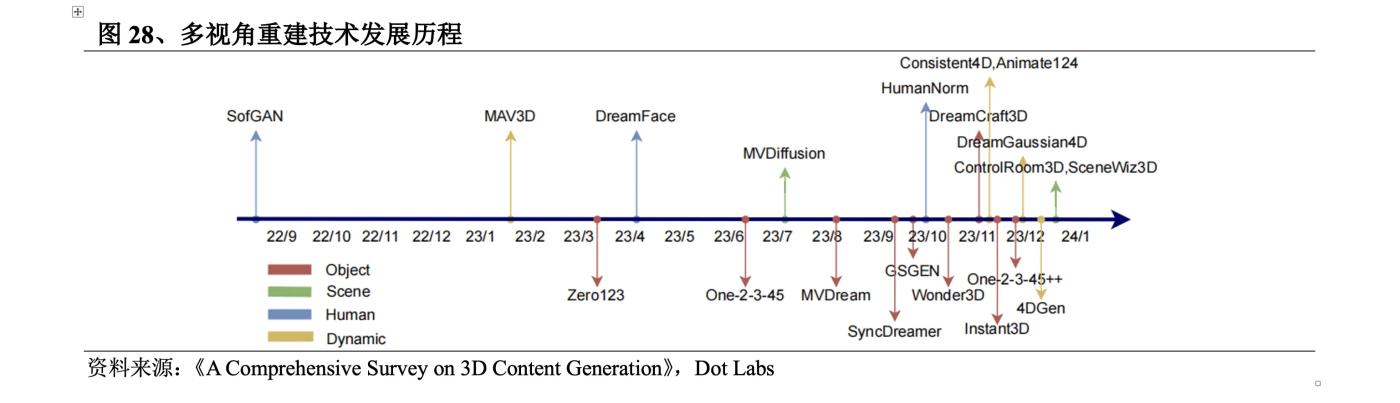
Nghiên cứu về công nghệ tạo 3D lần đầu tiên được thực hiện trong lĩnh vực thị giác máy tính và đồ họa. Ngay từ năm 1970, giáo sư Berthold KP Horn của MIT đã đề xuất Shape fromShading, sử dụng mô hình ánh sáng phản chiếu để khôi phục mô hình 3D dựa trên ánh sáng và thông tin tối trong hình ảnh. Vào năm 2023, công nghệ thế hệ 3D sẽ phát triển bùng nổ và chất lượng, tốc độ cũng như sự phong phú của thế hệ sẽ được cải thiện đáng kể. Cơ hội là: ① Bộ dữ liệu 3D đã phát triển từ ShapeNet quy mô nhỏ ban đầu đến Objaverse (tháng 12 năm 2022) và Objaverse XL. (Tháng 7 năm 2023), trong đó bộ dữ liệu 0bjaverse-XL chứa 10,2 triệu tài sản 3D, nhiều hơn Objaverse; ② Trường thần kinh thể hiện nội dung 3D dưới dạng các tham số mạng thần kinh đã ra đời; của các mô hình đào tạo trước 2D sẽ thúc đẩy việc tái thiết nhiều chế độ xem.
Công nghệ tạo 3D có thể được chia thành hai lộ trình phát triển chính: nâng cao kích thước 3D gốc và 2D. Bản địa 3D thường sử dụng các bộ dữ liệu 3D để đào tạo. Từ đào tạo đến suy luận, nó dựa trên dữ liệu 3D và trực tiếp tạo ra nội dung 3D từ văn bản/hình ảnh. Tuy nhiên, các bộ dữ liệu 3D có thể học được rất hạn chế, ngay cả với mã nguồn mở lớn nhất. Tập dữ liệu 3D Objaverse-XL Lượng dữ liệu chỉ bằng một phần nhỏ so với tập dữ liệu 2D. Để giải quyết vấn đề này, một số nghiên cứu cố gắng sử dụng bộ dữ liệu 2D để đào tạo, từ văn bản đến hình ảnh 2D, sau đó tạo nội dung 3D thông qua mô hình khuếch tán hoặc mô hình NeRF. Đây là cải tiến về chiều 2D.
1. Tuyến đường gốc 3D
Các tuyến gốc 3D được đào tạo bằng cách sử dụng bộ dữ liệu 3D để tạo ra nội dung 3D trực tiếp từ đầu vào văn bản/hình ảnh. Những ưu điểm và nhược điểm chính là:
l Ưu điểm
Tạo chất lượng cao: Vì sử dụng tập dữ liệu 3D nên nó được nhắm mục tiêu cao trong một phạm vi cụ thể và có thể tạo ra nội dung 3D chất lượng cao hơn. Ví dụ: khuôn mặt 3D chất lượng cao hơn 4k có thể được đào tạo thông qua 3D chất lượng cao. dữ liệu khuôn mặt. Đồng thời, nó tránh được các vấn đề về nhiều mặt của việc tăng kích thước 2D.
Tạo nhanh: Chiều 2D thường sử dụng mô hình khuếch tán hoặc mô hình NeRF để hướng dẫn tối ưu hóa biểu diễn 3D, yêu cầu lặp lại nhiều bước và mất nhiều thời gian, trong khi bản gốc 3D có thể được tạo trực tiếp ở dạng 3D từ văn bản/hình ảnh.
Khả năng tương thích mạnh mẽ: Hình học và kết cấu thường được tạo riêng biệt và sau đó có thể được chỉnh sửa trực tiếp trong các công cụ đồ họa tiêu chuẩn.
l Nhược điểm
Không đủ phong phú: Thiếu bộ dữ liệu 3D quy mô lớn, chất lượng cao, chất lượng và tính nhất quán dữ liệu kém, điều này hạn chế trí tưởng tượng của mô hình và gây khó khăn cho việc tạo ra các mục hoặc kết hợp chưa từng thấy trong tập dữ liệu.
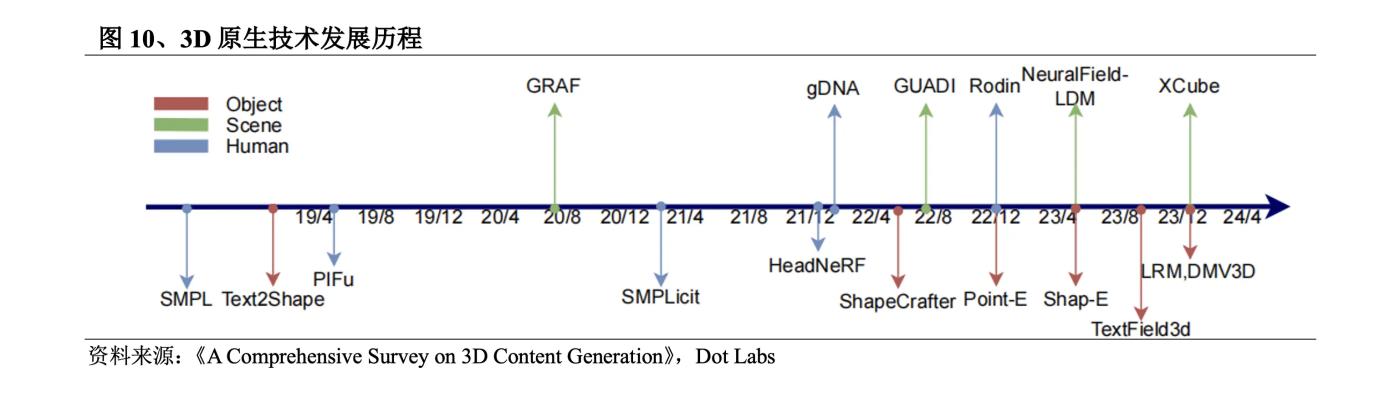
Phương pháp được sử dụng trong những ngày đầu của mô hình gốc 3D bao gồm mô hình VAE, mô hình dòng chảy, mô hình GAN, mô hình EBM, v.v. Trong đó, ưu điểm của mô hình GAN trong việc tạo hiệu ứng khiến nó trở thành mô hình chủ đạo của mô hình 3D gốc cho đến năm 2022. Tuy nhiên, do Đối với vấn đề về lỗi đào tạo trong GAN, việc đào tạo trên dữ liệu nếu không có hệ tọa độ được tiêu chuẩn hóa là điều vô cùng khó khăn và đòi hỏi phần cứng cực cao. Vào tháng 9 năm 2022, Nvidia phát hành Get3D, có thể tạo nội dung 3D với kết cấu có độ trung thực cao và các chi tiết hình học phức tạp. Sau đó, OpenAI phát hành Point-E và Shap-E, phá vỡ giới hạn về số lượng dữ liệu và phụ đề 3D, thu thập hàng triệu tài nguyên 3D và phụ đề văn bản tương ứng, đồng thời hỗ trợ tạo 3D với vốn từ vựng lớn. LRM phổ biến gần đây đạt được khả năng chuyển đổi nhanh chóng từ một hình ảnh sang mô hình 3D có độ trung thực cao bằng cách kết hợp kiến trúc mạng thần kinh hiệu quả và bộ dữ liệu nhiều chế độ xem quy mô lớn đề xuất mô hình khuếch tán bước T để cải thiện LRM và đạt được kết quả cao hơn. chất lượng. Kết quả được tạo ra.
(1) Get3D giàu chi tiết và kết cấu hình học
Vào tháng 9 năm 2022, Nvidia phát hành Get3D. Quá trình tạo Get3D được chia thành hai phần: ① phần nhánh hình học, có thể tạo ra lưới bề mặt với bất kỳ cấu trúc tôpô nào; ② phần nhánh kết cấu, tạo ra trường kết cấu để cho phép truy vấn trên các điểm bề mặt.

Những đột phá cụ thể của phương pháp này là:
lTrước khi phương pháp này ra đời, nội dung được tạo ra bởi công nghệ tạo hình 3D thiếu chi tiết và kết cấu hình học. Theo quy trình tạo của Get3D , các chi tiết hình học của nội dung 3D của nó phong phú hơn và có thể được kết cấu.
lPhương phương pháp kết xuất ngược tiên tiến nhất vào thời điểm đó chỉ có thể tạo một đối tượng 3D tại một thời điểm. Khi được đào tạo trên một GPU Nvidia duy nhất, Get3D có thể tạo ra khoảng 20 đối tượng mỗi giây và tập dữ liệu đào tạo mà nó học được càng lớn và đa dạng thì độ đa dạng và chi tiết của đầu ra càng cao. Theo đội ngũ nghiên cứu của Nvidia , chỉ cần có nó. 2 ngày để huấn luyện mô hình trên khoảng 1 triệu hình ảnh sử dụng GPU A100 .
lCó thể tạo ra số lượng nội dung 3D gần như không giới hạn dựa trên dữ liệu đã được đào tạo. Ví dụ: để tìm hiểu dữ liệu về hình ảnh ô tô 2D , Get3D có thể tạo sê-ri bộ ô tô, xe tải, xe đua và xe tải.

(1) Shap-E cải thiện đáng kể tốc độ phát điện
Vào tháng 5 năm 2023 , OpenAI đã phát hành Shap-E để cải thiện Point-E của mình. Quy trình Shap-E là: ① Huấn luyện bộ mã hóa để tạo ra các biểu diễn tiềm ẩn; ② Huấn luyện mô hình phổ biến về các biểu diễn tiềm ẩn do bộ mã hóa tạo ra.
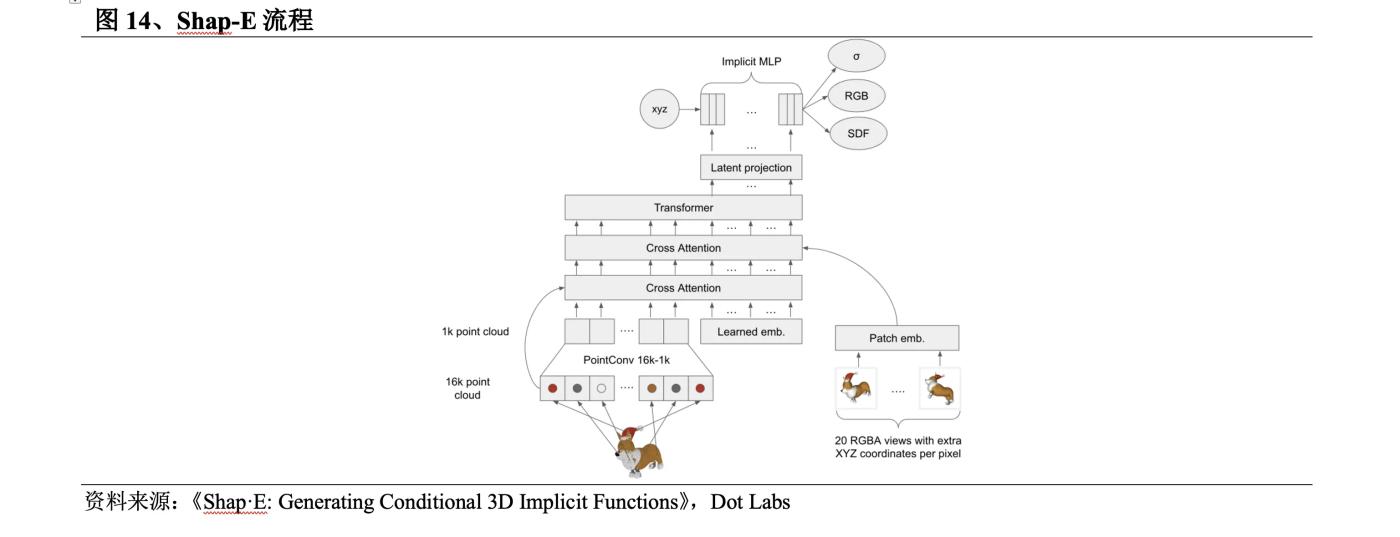
l Shap-E sử dụng biểu diễn ngầm để tạo mô hình 3D với cả trường thần kinh và lưới kết cấu, có thể dễ dàng nhập vào phần mềm 3D để xử lý tiếp theo. So với phương pháp khác, Get3D chỉ có thể tạo lưới và Point-E chỉ có thể tạo các đám mây điểm.
Sau khi đào tạo với dữ liệu tương ứng văn bản và 3D lớn, Shap-E có thể tạo các mô hình 3D phức tạp và đa dạng trong vài giây, nhanh hơn Point-E về tốc độ suy luận và nhanh hơn nhiều so với phương pháp khác.
Nhưng giống như các vấn đề của Point-E , các mẫu của Shap-E có chất lượng kém hơn và bộ mã hóa đôi khi làm mất kết cấu chi tiết.

(1) LRM khởi đầu làn sóng tái cấu trúc các mô hình
Vào tháng 11 năm 2023 , một đội ngũ nghiên cứu từ Adobe Research và Đại học Quốc gia Úc đã giới thiệu mô hình tái thiết quy mô lớn mang tính đổi mới LRM . Quy trình của phương pháp này là: ① Áp dụng mô hình trực quan được đào tạo trước DINO để mã hóa hình ảnh đầu vào; ② Các đặc điểm hình ảnh được chiếu lên không gian ba mặt phẳng 3D bằng bộ giải mã Transformer lớn thông qua chú ý chéo và được biểu diễn bằng mô hình NeRF . ③ Sử dụng nhiều lớp Perceptron MLP dự đoán màu sắc và mật độ điểm để hiển thị khối.
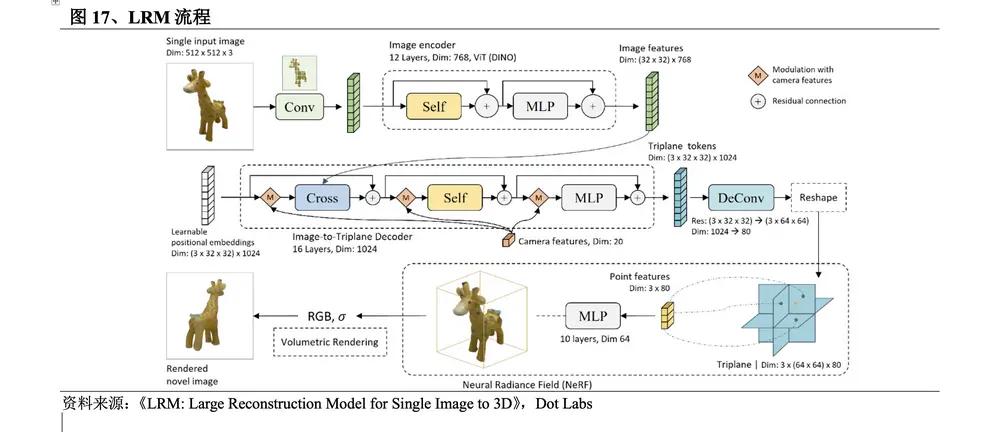
lTiêu thụ thời gian ngắn . Nâng cao chiều 2D chủ yếu sử dụng mô hình khuếch tán để tối ưu hóa biểu diễn 3D thông qua các thuật toán tối ưu hóa. Suy luận là quá trình đào tạo, rất tốn thời gian. Phương pháp gốc 3D khác huấn luyện mô hình khuếch tán trên biểu diễn 3D và suy luận yêu cầu nhiều bước lặp lại. rất tốn thời gian. LRM là mô hình hồi quy huấn luyện trực tiếp suy ra biểu diễn 3D trong một bước và có thể tạo mô hình đối tượng 3D có độ chính xác cao từ một hình ảnh đầu vào chỉ trong 5 giây.
lTính linh hoạt mạnh mẽ . Không giống như phương pháp đào tạo trước đây về các danh mục cụ thể trên dữ liệu nhỏ, LRM áp dụng kiến trúc dựa trên máy biến áp mở rộng cao với 500 triệu tham số có thể học được và được thực hiện bằng cách sử dụng khoảng 1 triệu đối tượng 3D trong dữ liệuObjaverse và MVImgNet . linh hoạt.
lXử lý hình ảnh cảnh thật. LRM cho phép người dùng tạo các mô hình 3D chất lượng cao từ ảnh chụp bằng điện thoại thông minh, mở rộng quá trình dân chủ hóa mô hình 3D và mở ra khả năng thương mại và sáng tạo không giới hạn.
LRM là mô hình tái thiết quy mô lớn đầu tiên, bước đột phá của nó nằm ở việc tạo ra hình ảnh 3D chất lượng cao một cách nhanh chóng và hiệu quả, đã mang lại những thay đổi cho các lĩnh vực thực tế tăng cường, hệ thống thực tế ảo, trò chơi, phim hoạt hình và truyền hình cũng như công nghiệp. thiết kế. Những lợi thế đáng kể của nó về tốc độ và chất lượng tạo ra đã tạo ra một làn sóng các mô hình tái thiết trong lĩnh vực công nghệ thế hệ 3D . Nhiều công trình đã được cải tiến trên cơ sở LRM và lượng lớn các mô hình tái thiết đã xuất hiện.
Lộ trình nâng cao kích thước 2D sử dụng các bộ dữ liệu2D để đào tạo, đầu tiên là từ văn bản đến hình ảnh 2D , sau đó tạo nội dung 3D thông qua mô hình khuếch tán hoặc mô hình NeRF . Những ưu điểm và nhược điểm chính là:
lƯu điểm
Độ phong phú mạnh mẽ: Lượng lớn dữ liệu hình ảnh 2D có thể được sử dụng để đào tạo trước và mô hình 3D được tạo ra phức tạp và giàu trí tưởng tượng hơn.
lNhược điểm
Chất lượng tạo thấp: Bị giới hạn bởi số lượng mẫu, số phối cảnh và sự cân bằng của tài nguyên máy tính, phương pháp nâng cao chiều 2D hiện tại còn thô về độ phân giải và chi tiết kết cấu, đồng thời khả năng trước 3D của mô hình khuếch tán là không đủ, và các kết quả được tạo ra có xu hướng cấu trúc hình học không hợp lý.
Tốc độ tạo chậm: Quá trình đào tạo và suy luận của NeRF đòi hỏi lượng lớn tài nguyên tính toán và yêu cầu lấy mẫu chuyên sâu về không gian 3D , việc này tốn nhiều thời gian.
Khả năng tương thích yếu: Định dạng NeRF không thể chỉnh sửa trực tiếp trong các công cụ 3D như Unity . Nó cần được chuyển đổi thành lưới 3D thông qua Matching Cubes và sau đó chỉnh sửa trong công cụ 3D .
Năm 2018 , trường thần kinh biểu diễn nội dung 3D dưới dạng tham số mạng thần kinh đã ra đời. Mặc dù trường thần kinh vẫn thể hiện dữ liệu3D và phát triển chậm trong giai đoạn 2018-2020 do thiếu dữ liệu học tập, nhưng nó đã đặt nền tảng kỹ thuật cho tính chiều 2D. tăng. Vào năm 2020 , một đội ngũ chung từ Berkeley, Google và UC San Diego đã đề xuất thuật toán NeRF , thuật toán này tạo ra hình ảnh có độ chính xác cao và có thể tạo ra hình ảnh nhận thức 3D về các cảnh lớn, thúc đẩy đáng kể sự phát triển của không gian 2D . đào tạo và yêu cầu về phần cứng Do các vấn đề như yêu cầu cao và hiệu suất phát điện thấp, nó chỉ có thể được sử dụng trong một phạm vi nhỏ các ứng dụng thử nghiệm và giải trí. Vào năm 2022 , các ứng dụng tạo hình ảnh 2D do Stable Diffusion và Dall·E đại diện sẽ phát triển nhanh chóng, điều này sẽ nâng cao giá trị thương mại của chiều 2D và sự phát triển công nghệ sẽ tăng tốc trở lại. Về mặt phát triển công nghệ cụ thể, khám phá ban đầu về chiều 2D là DreamFields do Google phát hành vào cuối năm 2021. Nó đã phát hành DreamFusion được cải tiến trên cơ sở này vào tháng 9 năm 2022 , sử dụng mô hình khuếch tán Imagen để tính toán tổn thất và phương phápSDS cho lấy mẫu, giúp cải thiện đáng kể văn bản thành chất lượng 3D . Sau đó, Nvidia đã phát hành Magic3D , giới thiệu chiến lược tối ưu hóa hai giai đoạn để cải thiện tốc độ và chất lượng thế hệ. ProlificDreamer sử dụng VSD để giải quyết các vấn đề về độ bão hòa quá mức, độ mịn quá mức và độ đa dạng thấp của phương phápSDS . DreamGaussian đã tích hợp 3D Gaussian vào việc tạo nội dung 3D . Kể từ đó, 3D Gaussian đã thay thế phần lớn NeRF . Trong sáu tháng qua, lượng lớn sê-ri cải tiến dựa trên Gaussian 3D đã xuất hiện. 
(1) Dreamfusion phát triển các tính toán tổn thất mới
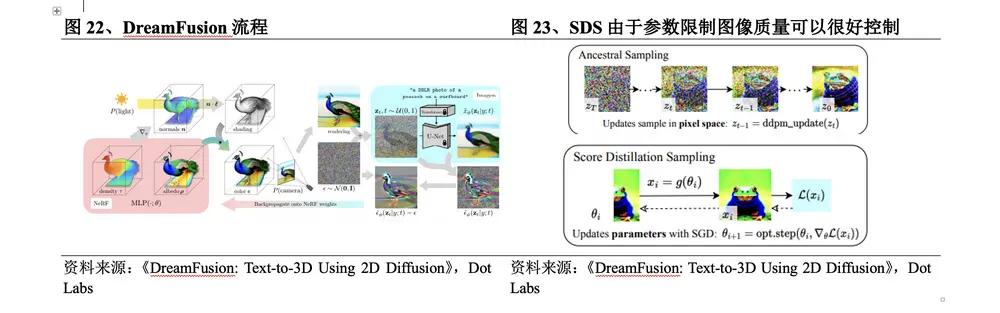
Vào tháng 9 năm 2022 , Google đã phát hành DreamFusion để cải thiện dựa trên DreamFields của mình. Quá trình DreamFusion là: ① Sử dụng NeRF để hiển thị hình ảnh ở vị trí camera được xác định trước và trộn nó với phân phối Gaussian để thu được hình ảnh nhiễu; ② Nhập hình ảnh vào mô hình khuếch tán Imagen và sử dụng tỷ trọng ngẫu nhiên tương tự như NeRF để khởi tạo ③ Chế độ xem được hiển thị lặp lại được sử dụng làm đầu vào Hình ảnh xung quanh cho chức năng SDS . Những đột phá cụ thể của phương pháp này là:
l Tính toán tổn thất thông qua mô hình khuếch tán Imagen của văn bản sang hình ảnh để thay thế CLIP , tương đương với NeRF được tối ưu hóa theo mô hình khuếch tán và tối ưu hóa mô hình 3D .
l Sử dụng phương pháp lấy mẫu hình ảnh mới SDS , việc lấy mẫu được thực hiện trong không gian tham số thay vì không gian pixel. Do hạn chế về tham số, chất lượng của hình ảnh được tạo ra có thể được kiểm soát tốt.
l Trong quá trình tạo ảnh, các tham số sẽ được tối ưu hóa để trở thành mẫu huấn luyện của mô hình khuếch tán. Các tham số được huấn luyện bởi mô hình khuếch tán có đặc điểm đa tỷ lệ, thuận lợi hơn cho việc tạo ảnh tiếp theo và mô hình khuếch tán có thể. dự đoán trực tiếp hướng cập nhật là cần thiết.
Mặc dù DreamFusion cải thiện độ chính xác về cấu trúc của mô hình 3D và tính xác thực của kết xuất nhưng nó đòi hỏi 15.000 lần tối ưu hóa để tạo ra nội dung 3D . Mỗi thế hệ mô hình mất 1,5 lần, quá dài về quy mô, kết xuất và chi tiết cấu trúc. yêu cầu của các ứng dụng ở cấp độ công nghiệp.
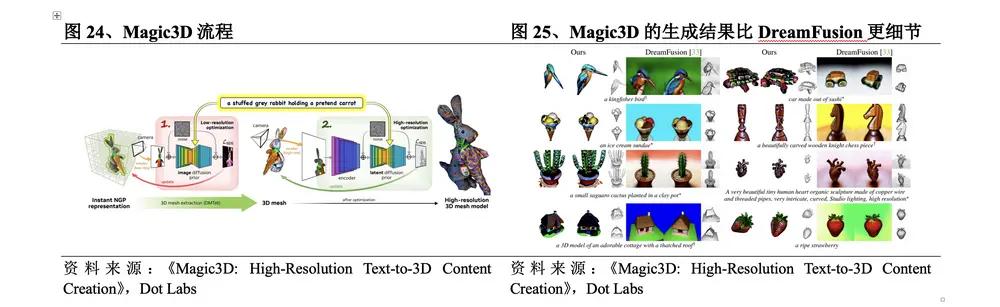
(2) Tối ưu hóa hai giai đoạn Magic3D để tăng chất lượng và tốc độ
Vào tháng 11 năm 2022 , Nvidia đã phát hành Magic3D , một giải pháp tối ưu hóa hai giai đoạn dựa trên DreamFusion . Quy trình Magic3D là: ①Tối ưu hóa độ phân giải thấp . Tính toán tổn thất SDS bằng cách liên tục lấy mẫu và hiển thị các hình ảnh có độ phân giải thấp, sử dụng mô hình tái tạo 3D Instant NGP để đưa ra kết quả và sử dụng DMTet rútlưới 3D ban đầu làm đầu vào của giai đoạn thứ hai; ② Tối ưu hóa độ phân giải cao. Hình ảnh có độ phân giải cao được lấy mẫu và hiển thị theo cùng một phương pháp và được cập nhật bằng cùng một phương pháp để có kết quả cuối cùng. So với DreamFusion , điểm đột phá cụ thể của phương pháp này là:
lChất lượng thế hệ cao hơn. Độ phân giải của Magic3D cao hơn 8 lần so với DreamFusion và các hiệu ứng cụ thể do Magic3D tạo ra cũng chi tiết hơn.
lTạo nhanh hơn. Magic3D có thể tạo mô hình lưới 3D chất lượng cao trong 40 phút, nhanh gấp 2 lần so với DreamFusion .
lKết nối tốt hơn. Vì phương pháp kết xuất của Magic3D có liên quan rất chặt chẽ với đồ họa máy tính truyền thống và kết quả được tạo ra của nó có thể được xem trực tiếp trong phần mềm hình ảnh tiêu chuẩn, nên nó có thể kết nối tốt hơn với tác phẩm tạo 3D truyền thống và có tiềm năng ứng dụng công nghiệp.
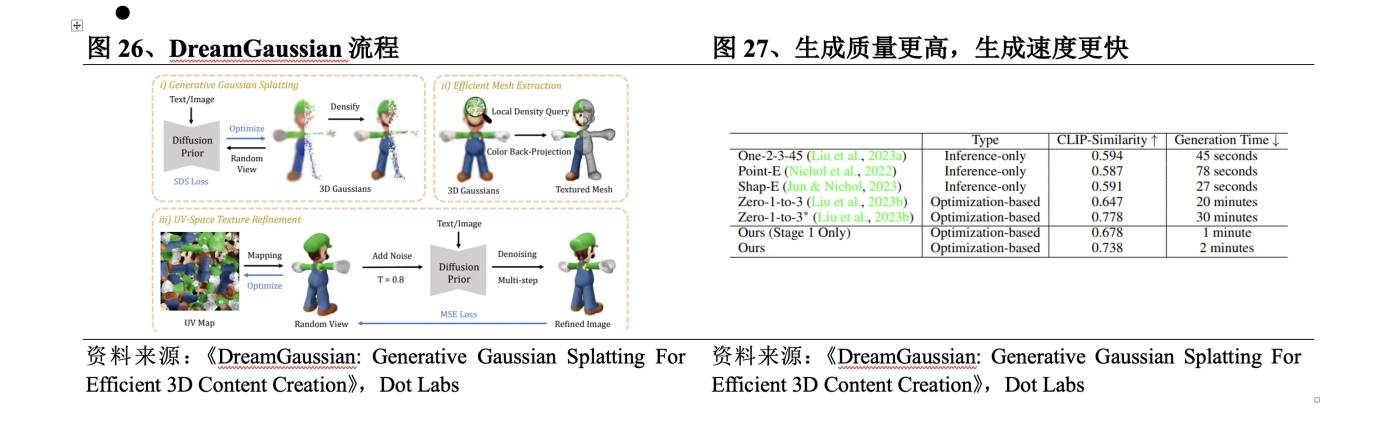
(3) DreamGaussian sử dụng Gaussian 3D để thay thế NeRF
Vào tháng 9 năm 2023 , các tác giả từ Baidu, Viện Công nghệ Nanyang và Đại học Bắc Kinh đã cùng phát hành DreamGaussian . Quy trình DreamGaussian là: ① Sử dụng 3D Gaussian Splatting trong không gian UV để mô hình hóa nội dung được biểu thị bằng văn bản hoặc hình ảnh; ② Sử dụng SDS Loss để tối ưu hóa và rút lưới kết cấu ③ Tinh chỉnh kết cấu của hình ảnh trên lưới thông qua nhiều vòng MSE; Tính toán tổn thất . So với phương pháp dựa trên NeRF , điểm đột phá cụ thể của phương pháp này là:
lChất lượng thế hệ cao hơn. DreamGaussian đã thiết kế một thuật toán rút các mắt lưới từ Gaussian 3D và giai đoạn sàng lọc kết cấu không gian UV để cải thiện hơn nữa chất lượng tạo ra.
lTạo nhanh hơn. Bằng cách điều chỉnh phân đoạn Gaussian phù hợp với cài đặt tạo, giảm đáng kể thời gian tạo của phương pháp chiều 2D , DreamGaussian có thể tạo nội dung 3D với các lưới rõ ràng và ánh xạ kết cấu từ các hình ảnh xem một lần trong 2 phút, tăng tốc khoảng 10 % so với phương pháp hiện có. .
Phương pháp nâng cao chiều 2D ban đầu chủ yếu sử dụng các bộ dữ liệu 2D để đào tạo và chỉ có thể tinh chỉnh kiến thức hình học 3D hạn chế. Vào tháng 3 năm 2023 , Tiến sĩ Liu Ruoshi của Đại học Columbia đã xuất bản Zero123 , phát hiện ra rằng việc đưa thông tin 3D vào mô hình đào tạo trước 2D có thể bù đắp một cách hiệu quả sự thiếu hụt khả năng 3D trước đó của mô hình khuếch tán. Do đó, phương pháp phương pháp tái tạo nhiều chế độ xem tạo ra hình ảnh từ nhiều chế độ xem và sau đó thu được mô hình 3D thông qua tái tạo 3D đã xuất hiện. Sau đó, dựa trên Zero123 , đội ngũ của Giáo sư Su Hao tại Đại học California, San Diego đã đề xuất One-2-3-45 và One-2-3-45++ , sử dụng mô hình khuếch tán để đạt được khả năng khái quát hóa tốt hơn. theo thời gian, dữ liệu3D hạn chế được sử dụng để đạt được các cấu trúc hình học tương đối chính xác và ByteDance phát hành MVDream , VAST phát hành Wonder3D và Meta phát hành MVDiffusion++ .
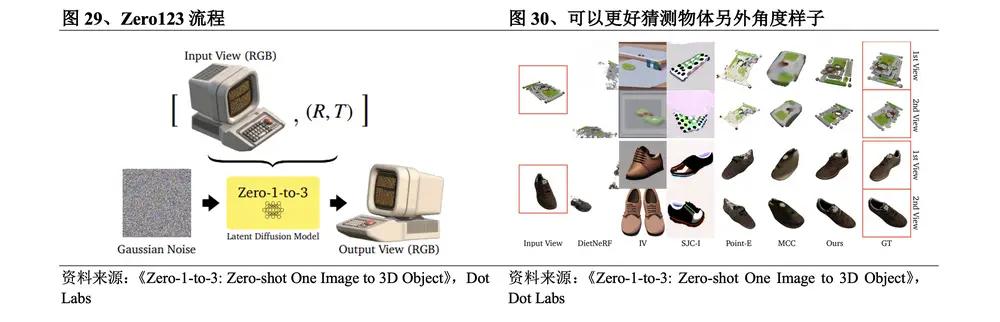
(1) Zero123 cho phép tái tạo nhiều chế độ xem
Vào tháng 3 năm 2023 , đội ngũ nghiên cứu tại Đại học Columbia đã phát hành Zero123 . Quy trình Zero123 là: ①Nhập một hình ảnh RGB duy nhất để mã hóa; ②Khử nhiễu hình ảnh; ③Chọn một góc nhìn camera khác để tạo hình ảnh phối cảnh mới; ④Thêm các hình ảnh nhiều góc nhìn này vào mô hình khuếch tán để đào tạo và tái tạo 3D . Điểm đột phá cụ thể của phương pháp này là mặc dù thứ tự tái tạo 3D và tổng hợp chế độ xem mới bị đảo ngược nhưng danh tính của đối tượng được mô tả trong ảnh đầu vào vẫn được giữ nguyên, do đó có thể sử dụng xác suất quay của đối tượng để tạo mô hình mô phỏng sự không nhất quán ngẫu nhiên gây ra bởi tính tự xác định, nó sử dụng hiệu quả các tiên nghiệm về ngữ nghĩa và hình học đã học được từ mô hình khuếch tán. Mô hình khuếch tán đã biết hình dáng thực sự của vật thể 3D từ nhiều góc độ trong quá trình đào tạo và có thể dự đoán tốt hơn về hình dạng. sự xuất hiện của đối tượng từ các góc độ khác.
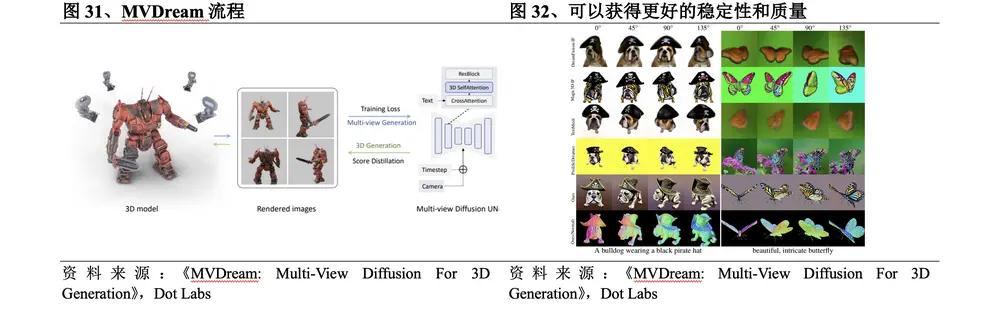
(2) Tinh chỉnh MVDream hỗ trợ thế hệ cá nhân hóa
Vào tháng 8 năm 2023 , ByteDance phát hành MVDream . Quá trình MVDream là: ① Chuyển đổi lớp tự chú ý 2D ban đầu thành 3D bằng cách kết nối các chế độ xem khác nhau trong lớp tự chú ý và thêm phần nhúng camera cho mỗi chế độ xem ② Sử dụng mô hình khuếch tán nhiều chế độ xem làm ưu tiên để tối ưu hóa 3D và 3D được tạo thông qua SDS . Những đột phá cụ thể của phương pháp này là:
l Bằng cách sử dụng các mô hình khuếch tán hình ảnh được đào tạo trước trên dữ liệu mạng quy mô lớn và dữ liệu nhiều chế độ xem được hiển thị từ tài nguyên 3D , mô hình khuếch tán nhiều chế độ xem thu được có thể đạt được cả tính linh hoạt của khuếch tán 2D và tính nhất quán của dữ liệu 3D . So với phương pháp tăng chiều 2D mã nguồn mở hiện tại, có thể đạt được độ ổn định và chất lượng tốt hơn.
l Mô hình khuếch tán nhiều chế độ xem có thể được đào tạo và tinh chỉnh trong cài đặt một vài mẫu, cho phép người dùng thực hiện tạo 3D được cá nhân hóa.
3. Dự kiến sẽ thương mại hóa phương pháp nâng cấp kích thước 2D
Thông qua sự phát triển và hoàn thiện không ngừng, công nghệ thế hệ 3D đã có những tiến bộ vượt bậc về chất lượng, tốc độ và sự phong phú của thế hệ. Nếu những vấn đề sau có thể được giải quyết tốt hơn, công nghệ thế hệ 3D sẽ có một tương lai rất hứa hẹn:
dữ liệudữ liệu . Dữ liệu đào tạo không đầy đủ là nguyên nhân quan trọng hạn chế sự phát triển của công nghệ tạo 3D , chủ yếu là do: ① Lịch sử sản xuất bộ dữ liệu 3D rất ngắn; ② Tài sản3D thường đòi hỏi các nhà thiết kế 3D phải dành lượng lớn thời gian sử dụng phần mềm chuyên nghiệp để tạo; ③ Do kịch bản sử dụng và người sáng tạo có phong cách khác nhau, tài sản3D khác nhau rất nhiều về quy mô, chất lượng và kiểu dáng, do đó làm tăng độ phức tạp của dữ liệu3D ④ Việc lấy dữ liệu3D là bất tiện và lượng lớn dữ liệu3D nằm rải rác trong trò chơi; các công ty, công ty điện ảnh và truyền hình hiệu ứng đặc biệt và các nhà tạo mẫu cá nhân Khó thu thập trong tay. Khám phá cách sử dụng dữ liệu2D để tạo 3D là một giải pháp, nhưng các bộ dữ liệu3D chất lượng cao, quy mô lớn vẫn rất cần thiết.
l phương tiện biểu đạt. Trong công nghệ thế hệ 3D , biểu diễn ngầm có thể mô hình hóa các cấu trúc tôpô hình học phức tạp một cách hiệu quả, tuy nhiên tốc độ tối ưu hóa chậm giúp tối ưu hóa nhanh chóng sự hội tụ, nhưng khó gói gọn các cấu trúc tôpô phức tạp và đòi hỏi lượng lớn tài nguyên lưu trữ. Phương pháp biểu diễn vừa có hiệu quả huấn luyện cao vừa có độ chính xác cao sẽ đưa hiệu ứng tạo 3D lên một tầm cao hơn.
lHệ thống đánh giá . Đánh giá toàn diện nội dung 3D được tạo đòi hỏi sự hiểu biết về các đặc tính vật lý và thiết kế dự định của nó. Hiện tại, đánh giá chất lượng nội dung 3D chủ yếu dựa vào việc chấm điểm thủ công. Việc phát triển chỉ báo mạnh mẽ có thể đo lường toàn diện độ trung thực về hình học và kết cấu có thể thúc đẩy việc tối ưu hóa 3D. công nghệ thế hệ.
lKhả năng kiểm soát . Mục đích của công nghệ tạo 3D là tạo ra lượng lớn nội dung 3D thân thiện với người dùng, chất lượng cao và đa dạng theo cách rẻ tiền và có thể kiểm soát được, nhưng khi nhúng nội dung 3D được tạo vào các ứng dụng thực tế, các vấn đề tương thích không có lợi cho nhà thiết kế 3D. tương tác và Chỉnh sửa, đồng thời phong cách của nội dung được tạo bị giới hạn bởi tập dữ liệu huấn luyện, cần thống nhất nội dung 3D tạo ra bằng phương pháp khác nhau và thiết lập Chuỗi công cụ chứa các chức năng chỉnh sửa phong phú để nâng cao khả năng kiểm soát của công nghệ.
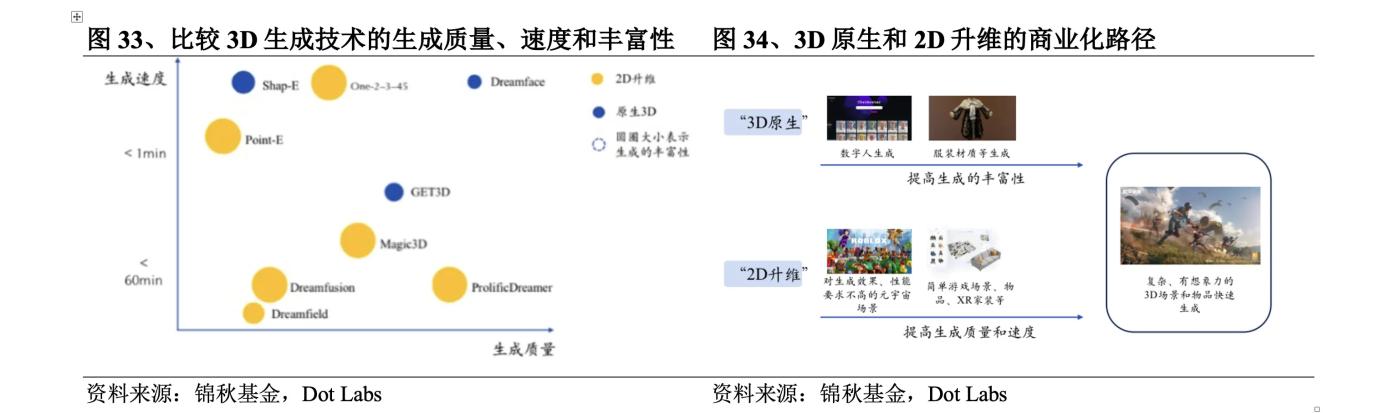
So sánh chất lượng tạo, tốc độ tạo và mức độ phong phú của các công nghệ tạo 3D khác nhau, có thể thấy rằng có một " Bộ ba bất khả thi của blockchain " giữa phương pháp này: phương pháp định tuyến gốc 3D sử dụng bộ dữ liệu3D , về cơ bản đảm bảo chất lượng và tốc độ, nhưng Có những thiếu sót rõ ràng về độ phong phú vì tập dữ liệu quá nhỏ. Lộ phương pháp nâng cao chiều 2D sử dụng các tập dữ liệu2D , có thể đáp ứng tốt các yêu cầu về độ phong phú. Ngoài ra còn có phương pháp như DreamGaussian theo đuổi phương pháp tiêu tối ưu. tốc độ thế hệ.
“Bộ ba bất khả thi của blockchain” khiến công nghệ thế hệ 3D phải đối mặt với những thách thức lớn hơn trong quá trình thương mại hóa. Các kịch bản dành cho chuyên gia có yêu cầu cao hơn về chất lượng sản xuất. Ví dụ: ngành công nghiệp, xây dựng và chăm sóc y tế yêu cầu tạo 3D có độ chính xác cao. Đối với các cảnh dành cho người tiêu dùng thông thường, tốc độ sản xuất được chú trọng hơn. Ưu điểm của phương pháp gốc 3D về chất lượng và tốc độ tạo ra gần với yêu cầu thương mại hóa hơn và có thể đạt được thương mại hóa trước trong các tình huống cụ thể. Ví dụ: Dreamface của Shadow Eye Technology đã có thể thay thế một phần công việc tạo mô hình ban đầu trong lĩnh vực trò chơi và Get3D đang tạo ra các vật phẩm đơn giản trong một số cảnh Metaverse. Ngược lại, phương pháp nâng cao kích thước 2D còn xa mới được thương mại hóa, nhưng chúng ta có thể thấy rằng lượng lớn các kết quả học thuật liên quan đến nâng cao kích thước 2D đã được công bố kể từ nửa cuối năm 2023. Phương pháp nâng cao kích thước 2D có các mức độ vấn đề khác nhau trong về chất lượng phát điện và tốc độ phát điện được cải thiện đáng kể, có thể dự đoán rằng trong năm tới, việc mở rộng chiều không gian 2D sẽ có cơ hội được triển khai bước đầu ở một số bối cảnh không có yêu cầu nghiêm ngặt về chất lượng phát điện, chẳng hạn như Metaverse, Trang trí nhà VR , v.v.
4. Màn hình gắn trên đầu hoàn thiện và mở ra tiềm năng vô hạn
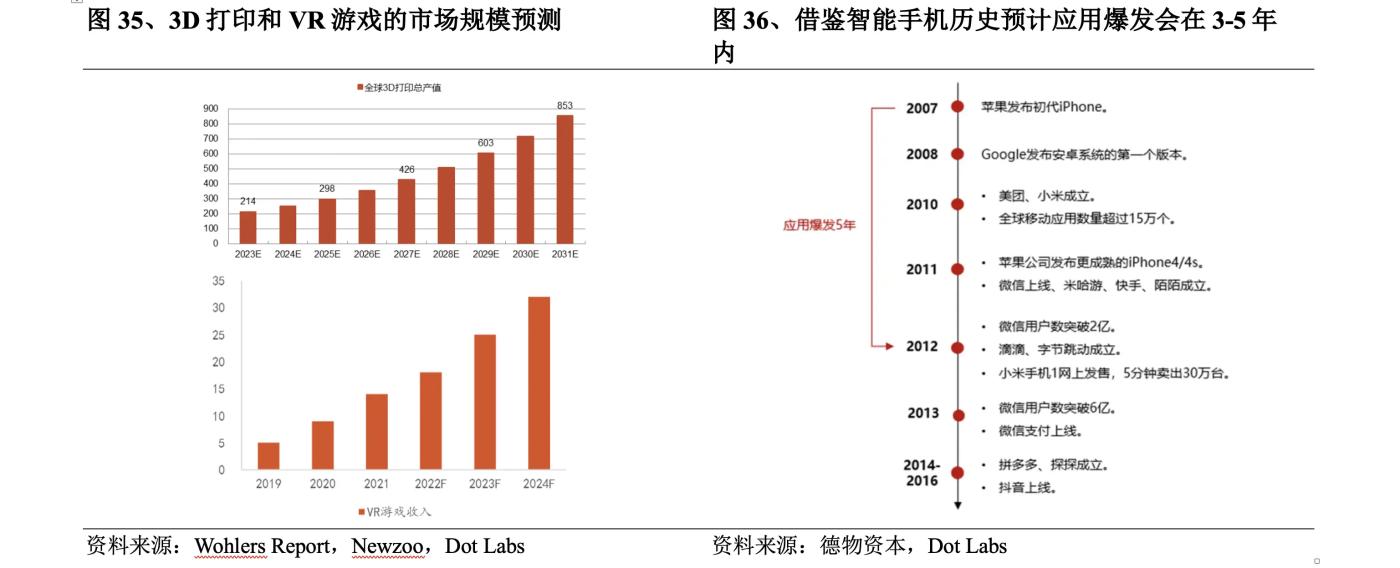
Mặc dù công nghệ thế hệ 3D hiện tại vẫn còn một số vấn đề nhưng không thể phủ nhận rằng không gian ứng dụng của thế hệ 3D trong tương lai là rất lớn, chủ yếu tập trung vào in 3D , trò chơi, phim ảnh, truyền hình và các lĩnh vực khác. Theo dữ liệu từ Wohlers Report , tổng giá trị sản lượng in 3D toàn cầu vào năm 2022 sẽ là 18,2 tỷ USD, tăng trưởng18% so với cùng kỳ năm ngoái và tốc độ tăng trưởng sẽ tiếp tục duy trì ở mức cao. đạt 85,3 tỷ USD vào năm 2031. Theo dự báo của Newzoo , thị trường game VR toàn cầu sẽ ở mức có thể đạt 3,2 tỷ USD vào năm 2024 . Với sự phát triển của các lĩnh vực ứng dụng nội dung 3D xuôi dòng, công nghệ tạo 3D có nhu cầu và kỳ vọng rộng rãi của thị trường.
Từ góc độ dài hạn, tiềm năng lớn hơn của thế hệ 3D nằm ở hoàn thiện màn hình gắn trên đầu. Phần cứng là vật mang công nghệ, sự phát triển của phần cứng sẽ thúc đẩy sự phát triển của công nghệ. Hoàn thiện của thiết bị hiển thị gắn trên đầu được kỳ vọng sẽ mang lại sự bùng nổ của các ứng dụng gốc 3D . Các nhà phát triển có thể sử dụng công nghệ thế hệ 3D để phát triển các ứng dụng hiển thị gắn trên đầu và thúc đẩy sự trưởng thành của hệ sinh thái thiết bị hiển thị gắn trên đầu. Mặc dù xét từ phản hồi của người dùng, thiết bị Vision Pro thế hệ đầu tiên vẫn còn nhiều điểm chưa đạt yêu cầu, nhưng nhìn vào lịch sử phát triển của điện thoại thông minh, dự kiến sự bùng nổ ứng dụng sẽ thành hiện thực trong vòng 3-5 năm tới, và tương lai có thể nhìn thoáng qua nó vẫn đáng để phấn khích.
5. Start-up thế hệ 3D gia nhập thị trường
Giải quyết các vấn đề của công nghệ tạo 3D không thể chỉ dựa vào việc xuất bản một vài bài báo mà còn đòi hỏi sự hiểu biết rõ ràng về các tiêu chuẩn ngành 3D và nhu cầu của người dùng chuyên nghiệp. Ngoài các công ty công nghệ lớn như Nvidia , OpenAI và Google , trong lĩnh vực thế hệ 3D , một số công ty khởi nghiệp thế hệ 3D mới nổi cũng đã nỗ lực rất nhiều về khả năng sử dụng. Kết quả cuối cùng không hẳn là kém hơn so với những gã khổng lồ. Hiệu suất và tương lai của họ xứng đáng với sự mong đợi của thị trường.
l CSM ( Common Sense Machines ): Được thành lập vào năm 2020 tại Massachusetts, Hoa Kỳ, được đồng sáng lập bởi Tejas Kulkarni , cựu nhà khoa học nghiên cứu cấp cao của Google DeepMind và Max Kleiman-Weiner , nhà nghiên cứu tiến sĩ tại MIT và là nhà đầu tư trinh sát tại Sequoia Thủ đô. Công ty cung cấp một nền tảng, CSM.ai , cho phép người dùng chuyển đổi ảnh, văn bản và bản phác thảo vẽ tay thành thế giới 3D hoàn toàn hiện thực. CSM đề xuất một cách sáng tạo khung thứ ba khác với công cụ trò chơi rõ ràng và công cụ trò chơi tiềm ẩn - một công cụ trò chơi học tập tiềm ẩn kết hợp tính linh hoạt và khả năng kiểm soát cao, phát triển công cụ kết xuất thời gian thực dựa trên sự khuếch tán và khởi chạy thế hệ nhanh chóng của độ phân giải cao. công cụ trò chơi. Ứng dụng Cube cho tài sản 3D có độ phân giải cao và hình ảnh kiểu tùy chỉnh. Nó đã huy động được 10,1 triệu USD trong ba vòng tài trợ.
l Luma : Được đồng sáng lập vào năm 2021 bởi cựu kỹ sư Apple AR/CV Amit Jain , người đứng đầu Phòng thí nghiệm Berkeley, Alberto Taiuti và Alex Yu , có trụ sở chính tại California, Hoa Kỳ, nhằm mục đích đơn giản hóa quá trình tạo hình ảnh và video 3D thông qua AI . công nghệ dựa trên NeRF . Genie 1.0 của nó, được phát hành vào tháng 1 năm nay, có thể tạo các mô hình 3D dựa trên văn bản trong 10 giây. Trình tạo video AI mang tính cách mạng của nó, Dream Machine ra mắt trong tháng này, có thể tạo các video chân thực, chất lượng cao dựa trên văn bản và hình ảnh với tốc độ 120 khung hình. 120 giây. Với sức mạnh kỹ thuật vượt trội và triển vọng thị trường rộng lớn, Luma đã huy động thành công hơn 70 triệu USD vốn tài trợ, với các nhà đầu tư lớn bao gồm các công ty đầu tư mạo hiểm có tiếng như Andreessen Horowitz , Matrix Partners và Amplify Partners . Tính đếnnăm 2024 , định giá của Luma đã lên tới 300 triệu USD.
l Polycam : Được thành lập tại California, Hoa Kỳ vào năm 2021 , APP của nó cho phép người dùng sử dụng LiDAR và máy ảnh của iPhone để tạo mô hình 3D . Giới thiệu AI Text Generatoro để tạo kết cấu 3D , trình tạo và trình xem phún xạ Gaussian 3D miễn phí để tái tạo lại phún xạ Gaussian 3D . Polycam có gần 100.000 khách hàng trả tiền, APP đã được tải xuống hơn 10 triệu lần, hơn 20 triệu mô hình 3D đã được tạo ra và hơn 50 lần công việc chỉnh sửa 3D đã được thực hiện. Thu nhập của nó tăng trưởng từ 280.000 USD vào năm 2021 lên 1,8 triệu USD vào năm 2022 , tăng vọt lên 6,5 triệu USD vào năm 2023 và đã vượt 4 triệu USD trong nửa đầu năm nay. thu nhập sẽ đạt mức cao mới. Hoàn thành 18 triệu USD trong vòng tài trợ Series A từ Left Lane Capital , Adjacent , Adobe Ventures và người đồng sáng lập YouTube Chad Hurley .
l Màu vàng : Một công ty tạo nhân vật3D được thành lập vào năm 2023 , được hỗ trợ bởi 5 triệu đô la tài trợ ban đầu từ A16z . Giám đốc điều hành Mandeep Waraich của công ty này từng là người đứng đầu các mô hình lớn và các sản phẩm Core ML của Google . Hầu hết các thành viên trong đội ngũ đều có MIT, Oxford , Stanford và bối cảnh trường có uy tín khác. Sản phẩm đầu tiên, YellowSculpt , đã được phát hành, cho phép tạo 3D nhận biết cấu trúc liên kết, giúp sử dụng và chỉnh sửa dễ dàng hơn. Trong khi hầu hết các công nghệ AI tổng quát hiện nay đều tạo ra các vật thể cứng nhắc thì thế hệ lưới có cấu trúc của Yellow tạo ra các mô hình 3D dễ tạo hoạt ảnh và các lưới kết quả có thể được sử dụng với các công cụ trò chơi hàng đầu như Unity , Unreal và Roblox hoặc với Daz Studio , Dàn tích hợp các công cụ tạo 3D khác như Maya và Blender . Quan hệ đối tác độc quyền với Tafi , nhà phát triển Daz Studio , được thành lập vào tháng 1 năm 2024 , cho phép Yellow tận dụng thư viện 3D của Daz để đào tạo các mô hình một cách an toàn.
6. Kỷ nguyên trí tuệ không gian mã hóa và thế hệ 3D
Trí thông minh không gian là một hoàn cảnh ảo 3D hỗ trợ hiển thị thời gian thực. Nó yêu cầu xác thực danh tính, xác nhận dữ liệu, giao dịch tài sản, quản lý theo quy định, v.v. để hỗ trợ và tư duy phi tập trung của Web 3 chỉ cung cấp cho nó sự an toàn, đáng tin cậy và cởi mở. nền tảng. Hoàn cảnh cơ sở và trí tuệ không gian cũng sẽ trở thành những kịch bản quan trọng cho ứng dụng quy mô lớn của Web 3. Web 3 và trí tuệ không gian đang có sự phát triển củng cố lẫn nhau. Công nghệ tạo 3D quan trọng trong trí tuệ không gian sẽ có những ứng dụng rộng rãi trong hoàn cảnh Internet. của Web 3. và không gian phát triển.
1. Lifeform : Visual DID tiên phong dẫn đầu cơ hội đột phá Web 3
Đi đầu trong Web 3 và trí tuệ không gian, nhận dạng ảo kỹ thuật số đã trở thành một cơ sở hạ tầng quan trọng và còn thiếu trong ngành. Lifeform là nhà cung cấp tiên phong các giải pháp danh tính số phi tập trung ( DID ), cung cấp cho người dùng Web 3 danh tính ảo kỹ thuật số có thể được sử dụng để đăng nhập vào bất kỳ DApp và Metaverse nào. Nó được kỳ vọng sẽ đạt được khả năng tương tác blockchain và mang lại những bước đột phá cho vòng tròn Web 3. của các cơ hội phát triển. Dự án đã tiến hành hai vòng tài trợ với tổng giá trị 400 triệu đô la Mỹ trong một năm. Các tổ chức đầu tư bao gồm Binance, IDG Capital và GeekCartel . Dự án đã nhận được 100.000 người theo dõi trên Twitter ra mắt174 ngày kể từ ngày ra mắt và tính đến thời điểm hiện tại là hàng tháng. khối lượng giao dịch đã vượt quá 3,5 triệu USD, chiếm khoảng 35% thị thị phầnBSC , lầnOpenSea , tokenLFT của nó ra mắt Bybit và Kucoin vào tháng 5 năm nay.
lVisual DID để nâng cao trải nghiệm tâm lý. DID hiện tại lưu thông tin cá nhân của người dùng trên Chuỗi và liên kết ví với danh tính trên Chuỗi thông qua NFT hoặc SBT . Lifeform sử dụng DID trực quan. Ngoài việc tương thích với tiêu chuẩn DID , nó còn cung cấp cho người dùng trình chỉnh sửa và tương ứng. Các giao thức DID , hợp đồng thông minh, v.v., cho phép người dùng tham gia vào các hoạt động Metaverse dưới dạng các nhân vật ảo 3D trực quan, cải thiện trải nghiệm tâm lý và hình ảnh của người dùng.
l Hơn 10 tỷ kết hợp để đáp ứng nhu cầu cá nhân hóa. Sản phẩm AvatarID của Lifeform có hai loại: Phiên bản hoạt hình siêu thực và phong cách hoạt hình dựa trên UE5 . Chỉnh sửa con người ảo của nó bao gồm 7 phần tạo, mỗi phần có hơn 1.000 thành phần và người dùng có thể tạo hơn 10 tỷ kết hợp hình đại diện, và Nó cũng cung cấp lượng lớn các mẫu để giảm bớt khó khăn tạo ra của người dùng và hỗ trợ hình thành NFT sau khi tạo ra hoàn tất.
tên miềnphổ quát đảm bảo tính khả dụng của chuỗi Chuỗi. Không giống như các giải pháp DID khác dựa trên blockchain khác nhau, vốn hạn chế khả năng chuỗi Chuỗi và phạm vi ứng dụng, dịch vụ tên miền phổ quát do Lifeform tạo ra đơn giản hóa việc xác thực và định vị blockchain thông qua hậu tố .btc và là giải pháp đầu tiên hỗ trợ nhiều độ phân giải tên miền nền tảng dành cho blockchain(Bitcoin, Ethereum, BNB Chain , Solana , Base , Avalanche , OPBNB , v.v.), người dùng có thể kiểm soát hoàn toàn thông tin nhận dạng của mình, đảm bảo tính khả dụng toàn cầu của danh tính số. Trong tương lai, chúng tôi có kế hoạch hợp tác với nhiều ví khác nhau, tích hợp SDK tên miền.btc vào ví sàn giao dịch và hỗ trợ tương tác liền mạch trên nhiều mạng lớp 1 và lớp 2 . 
2. Param Labs : Hệ thống kết nối mô-đun đun hệ sinh thái trò chơi Web 3 cải tiến
Param Labs là một studio phát triển blockchain và trò chơi AAA chuyên tạo ra mô-đun hệ sinh thái trò chơi Web3 theo mô-đun, được kết nối với nhau bằng cách cung cấp cho người dùng quyền sở hữu kỹ thuật số để đảm bảo rằng giá trị mà họ tạo ra có thể được trả lại, điều này sẽ thay đổi hoàn toàn trải nghiệm chơi trò chơi của người chơi và nhà phát triển. Dự án hiện đã hoàn thành khoản tài trợ trị giá 7 triệu đô la Mỹ, do Animoca Brands dẫn đầu, với sự tham gia của Delphi Ventures và Cypher Capital . Dự án có khoảng 900.000 người theo dõi trên Twitter , 500.000 người dùng Discord và 300.000 người dùng hoạt động hàng ngày. Nó sẽ sớm được ra mắt trên Bitget và. gate.io đã tung ra token PARAM . Sản phẩm chính của nó là:
l Pixel to Poly : Một nền tảng để sản xuất hàng loạt tài sản Metaverse chuyển đổi hình ảnh 2D do người dùng tải lên thành tài sản3D chất lượng cao, sẵn sàng cho trò chơi và tài sản này có thể được tích hợp vào các trò chơi phổ biến như Fortnite và GTAV , giúp rút ngắn đáng kể thời gian thời gian tạo ra của các nhà phát triển trò chơi và đẩy nhanh quá trình tạo tài sản trong ngành trò chơi 3D . Nền tảng này cũng có các NFT độc đáo để sử dụng trong trò chơi, cung cấp cho người chơi và người sưu tập tài sản kỹ thuật số có giá trị.
l Kiraverse : Một game bắn súng nhiều người chơi miễn phí mà người dùng có thể cá nhân hóa hơn nữa bằng cách nhập IP tùy chỉnh để có trải nghiệm độc đáo, đa IP và đa hệ sinh thái. Được công bố vào tháng 5 năm nay, mối quan hệ hợp tác với hệ sinh thái trò chơi Pixelverse sẽ giúp Pixelverse tích hợp các đặc tính trí tuệ và nhân vật của mình vào Kiraverse , nâng cao cốt truyện của trò chơi và mở rộng vũ trụ của nó. 
3. NeuralAI : Phát triển mạng con Bittensor để đổi mới thế hệ Web 3 3D
NeuralAI tận dụng hệ sinh thái $NEURAL và dapp của mình để cung cấp cho người dùng dịch vụ tạo tài sản3D và cung cấp một thị trường cho phép người dùng giao dịch liền mạch tài sản sáng tạo của họ. Dự án hiện đang phát triển mạng con Bittensor và sắp phát hành dapp đầu tiên, nhằm mục đích trở thành mạng con Bittensor hàng đầu để tạo tài sản 3D . Dự án đã đạt được sự hợp tác chiến lược với Akash Network, thị trường điện toán phi tập trung hàng đầu thế giới và Akash đã cung cấp cho dự án 56 GPU A6000 mạnh mẽ có thể mở rộng theo yêu cầu.
l Mô hình LRM tối ưu hóa số đa giác. Mô hình chính được NeuralAI sử dụng là LRM . Ưu điểm đáng kể của nó là nó có thể tạo ra lưới đếm đa giác được tối ưu hóa, giữ lại các chi tiết trong khi có số lượng đa giác nhỏ hơn. Nó phù hợp để chạy ở FPS cao (khung hình trên giây), đảm bảo rằng mô hình hiệu quả và vẫn chi tiết, lý tưởng cho hoàn cảnh chơi game, đồng thời cho phép các nghệ sĩ 3D thao tác và tinh chỉnh lưới trong quá trình hậu tạo ra bằng phần mềm hoặc thêm trực tiếp vào công cụ trò chơi.
l Mạng con Bittensor giảm chi phí cho việc tạo 3D. Tạo tài sản3D là một quá trình sử dụng nhiều tài nguyên, đòi hỏi sức mạnh tính toán và nguồn nhân lực lượng lớn . Là một mạng học máy phi tập trung, Bittensor có thể phân phối lượng lớn nhiệm vụ điện toán giữa nút toàn cầu. NeuralAI đang phát triển một mạng con chuyên dụng trong mạng Bittensor để cung cấp các giải pháp tốt hơn cho việc tạo tài sản3D . Dự án ước tính rằng việc thuê một nghệ sĩ 3D chuyên nghiệp sẽ tốn 30-100 USD mỗi giờ và đối với một tài sản phức tạp mất 10 giờ để tạo ra, chi phí sẽ là 300-1.000 USD, chưa bao gồm chi phí bổ sung về phần mềm và phần cứng. Trong mạng con Bittensor , Bittensor sẽ sử dụng tokenTAO để thưởng cho người xác thực và thợ đào . Người khích lệ Neural dApps , plug-inNeural hoặc API có thể tạo tài sản TÀI SẢNmiễn phí. chi phí có thể tiết kiệm 90-100% .

7. Cảnh báo rủi ro
Rủi ro thứ nhất: Biến động giá
- Giá tiền crypto rất biến động và giá trong tương lai không thể được đảm bảo hoặc dự đoán.
Rủi ro2 : Tài chính
- Dự án có thể bị phá sản hoặc không có khả năng trả nợ gốc hoặc lãi SWEAT .
Rủi ro3 : Hacker tấn công
- SWEAT có thể bị kẻ xấu đánh cắp và dự án có thể không trả lại được tiền.
Rủi ro4 : Pháp lý
- Một số quốc gia và khu vực nghiêm cấm loại hành vi này và bên dự án có thể không hoàn trả được tiền gốc hoặc lãi SWEAT .