

Trong bài viết này, Vitalik tóm tắt và phân tích nghiên cứu lịch sử nêu trên cũng như tiến trình nghiên cứu và phát triển mới nhất liên quan đến các tuyến kỹ thuật liên quan đến mở rộng , đồng thời giải thích chi tiết về các khả năng mới như rollups bản địa không cần sự tin cậy và L1 trong các điều kiện kỹ thuật mới.
Văn bản gốc: Tương lai có thể có của giao thức Ethereum, phần 2: The Surge (vitalik.eth)
Tác giả: Vitalik.eth
Biên soạn bởi: 183Aaros, Yewlne, LXDAO
Lời của người dịch
“Việc phá vỡ bộ ba mở rộng là khó, nhưng không phải là không thể, và đòi hỏi phải suy nghĩ bằng cách nào đó mà lập luận đó ám chỉ.” - Vitalik Buterin.
Để mở rộng bộ ba bất khả thi về khả năng mở rộng, Ethereum đã có nhiều ý tưởng và nỗ lực kỹ thuật trong các giai đoạn lịch sử khác nhau, từ kênh trạng thái, sharding, đến rollups, Plasma, và giờ đây là trong hệ sinh thái hiện tại “tính sẵn có dữ liệu” quy mô lớn tập trung vào Co. Phải đến lộ trình The Surge vào năm 2023 , Ethereum mới chọn con đường triết lý kỹ thuật “tập trung vào sự mạnh mẽ và phi tập trung của L1 cũng như sự phát triển đa dạng của L2” và có thể vượt qua ba tình huống khó xử. Là phần tiếp theo của bài viết trước “Tương lai có thể có của Giao thức Ethereum (1): Hợp nhất”, trong bài viết này, Vitalik tóm tắt và phân tích các nghiên cứu lịch sử nêu trên cũng như tiến trình nghiên cứu và phát triển mới nhất liên quan đến các lộ trình kỹ thuật liên quan đến mở rộng , và Xây dựng bổ sung về các khả năng mới chẳng hạn như rollups gốc L1 và không cần tin cậy trong các điều kiện kỹ thuật mới.
Tổng quan về bài viết này
Bài viết này có tổng cộng khoảng 11.000 từ và 7 phần. Ước tính sẽ mất 60 phút để đọc xong bài viết này.
- Bổ sung: Bộ ba bất khả mở rộng
- Những tiến bộ hơn nữa trong việc lấy mẫu tính sẵn có dữ liệu
- nén dữ liệu
- phổ quátPlasma
- Hệ thống chứng minh L2 trưởng thành
- Khả năng tương tác chéo L2 và cải thiện trải nghiệm người dùng
- Thực thi mở rộng trên L1
Nội dung văn bản
"Tương lai có thể có của Giao thức Ethereum(2): Sự đột biến"
Đặc biệt cảm ơn Justin Drake, Francesco, Hsiao-wei Wang, @antanttc và Georgios Konstantopoulos
Ban đầu, Ethereum có hai chiến lược mở rộng trong lộ trình của mình. Một (xem bài viết trước đó từ năm 2015) là "sharding": mỗi nút chỉ cần xác minh và lưu trữ một tập hợp con giao dịch nhỏ, thay vì tất cả các giao dịch trong Chuỗi. Các mạng ngang hàng khác (chẳng hạn như BitTorrent) hoạt động theo cách này, vì vậy chúng tôi chắc chắn có thể làm cho blockchain hoạt động theo cách tương tự. Cái còn lại là giao thức Layer 2 : một mạng nằm trên Ethereum và tận dụng tối đa tính bảo mật của nó trong khi vẫn giữ hầu hết dữ liệu và tính toán bên ngoài Chuỗi chính. “Giao thức Layer 2 ” có nghĩa là các kênh trạng thái vào năm 2015, Plasma vào năm 2017 và sau đó rollups vào năm 2019. Rollups mạnh hơn các kênh trạng thái hoặc Plasma, nhưng chúng yêu cầu băng thông dữ liệu trên Chuỗi lượng lớn . May mắn thay, đến năm 2019, nghiên cứu sharding đã giải quyết được vấn đề xác minh “tính sẵn có dữ liệu ” trên quy mô lớn. Kết quả là, hai con đường đã hội tụ và chúng tôi có được lộ trình tập trung vào tổng hợp, đây vẫn là chiến lược mở rộng cho Ethereum .
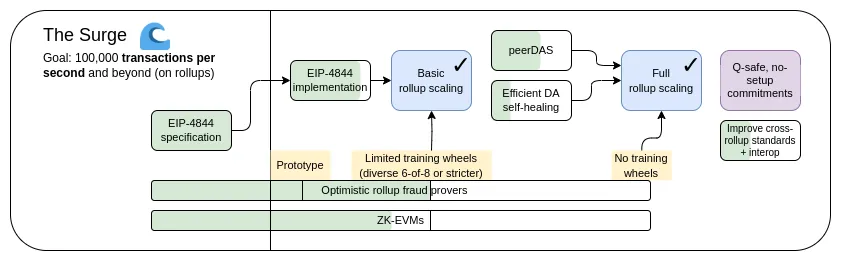
Lộ trình tập trung vào tổng hợp đề xuất một sự phân công lao động đơn giản: Ethereum L1 tập trung vào việc trở thành lớp cơ sở mạnh mẽ và phi tập trung , trong khi L2 có nhiệm vụ giúp mở rộng mở rộng hệ sinh thái. Mô hình này có thể được nhìn thấy ở khắp mọi nơi trong xã hội: hệ thống tòa án (L1) tồn tại không phải để hoạt động cực kỳ hiệu quả mà để bảo vệ các hợp đồng và quyền tài sản, còn các doanh nhân (L2) muốn xây dựng trên một lớp nền tảng vững chắc (L2) và đưa con người đến với nhau. nó. Mang nó lên sao Hỏa (nghĩa bóng và nghĩa đen).
Năm nay, lộ trình tập trung vào tổng hợp đã đạt được những thành công quan trọng: với sự xuất hiện của blob EIP-4844, băng thông dữ liệu Ethereum L1 đã tăng lên đáng kể và nhiều đợt tổng hợp EVM hiện đang ở Giai đoạn 1. Con đường dẫn đến các ứng dụng phân đoạn đa dạng và không đồng nhất đã trở thành hiện thực, trong đó mỗi L2 hoạt động như một "phân đoạn" với các quy tắc và logic nội bộ của riêng nó. Nhưng như chúng ta đã thấy, việc đi theo con đường này có những thách thức riêng. Vì vậy, bây giờ nhiệm vụ của chúng tôi là hoàn thành lộ trình tập trung vào tổng hợp và giải quyết những vấn đề này trong khi duy trì sự mạnh mẽ và phi tập trung của Ethereum L1.
The Surge: Mục tiêu chính
- Hơn 100.000 TPS trên L1+L2
- Giữ L1 phi tập trung và mạnh mẽ
- Ít nhất một số L2 kế thừa đầy đủ các đặc tính cốt lõi của Ethereum(không cần tin cậy, mở, chống kiểm duyệt)
- Tối đa hóa khả năng tương tác giữa L2. Ethereum sẽ giống như một hệ sinh thái chứ không phải 34 blockchain khác nhau.
Nội dung của chương này
- Bổ sung: Bộ ba bất khả mở rộng
- Những tiến bộ hơn nữa trong việc lấy mẫu tính sẵn có dữ liệu
- nén dữ liệu
- phổ quátPlasma
- Hệ thống chứng minh L2 trưởng thành
- Khả năng tương tác chéo L2 và cải thiện trải nghiệm người dùng
- Thực thi mở rộng trên L1
Bổ sung: mở rộng trilemma
Bộ ba mở rộng là một ý tưởng được đề xuất vào năm 2017, chủ yếu thảo luận về sự mâu thuẫn giữa ba thuộc tính sau: phi tập trung (cụ thể hơn: chi phí chạy nút thấp), mở rộng (cụ thể hơn: Nói: khả năng xử lý khối lượng giao dịch cao) và bảo mật (cụ thể hơn: kẻ tấn công sẽ cần phải xâm phạm phần lớn nút của mạng trước khi một giao dịch có thể thất bại).
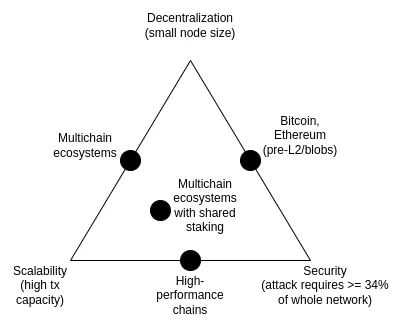
Điều đáng lưu ý là bộ ba bất khả thi không phải là một định lý và bài viết giới thiệu về bộ ba bất khả thi cũng không đưa ra được chứng minh toán học nào . Nó đưa ra một lập luận toán học theo kinh nghiệm: nếu nút hỗ trợ phi tập trung (chẳng hạn như máy tính xách tay của người tiêu dùng) có thể xác minh N giao dịch mỗi giây và có một Chuỗi xử lý k*N giao dịch mỗi giây, thì (i) Mỗi giao dịch là chỉ được nhìn thấy bởi nút 1/k, nghĩa là kẻ tấn công chỉ cần xâm phạm một vài nút để đẩy các giao dịch độc hại đi qua hoặc (ii) nút rất mạnh và khó phi tập trung. Bài viết này không gợi ý rằng việc phá vỡ bộ ba bất khả thi là không thể; thay vào đó, nó nhằm mục đích minh họa tại sao việc phá vỡ bộ ba bất khả thi lại khó khăn - nó đòi hỏi phải suy nghĩ bằng cách nào đó mà lập luận ngụ ý.
Trong những năm qua, một số Chuỗi hiệu suất cao thường tuyên bố rằng bộ ba bất khả thi có thể được giải quyết bằng cách tối ưu hóa nút bằng kỹ thuật công nghệ phần mềm mà không yêu cầu thiết kế tinh tế ở cấp độ cơ sở hạ tầng. Những tuyên bố như vậy là sai lệch, việc chạy nút trên Chuỗi như vậy khó khăn hơn nhiều so với Ethereum. Bài đăng trên blog này đi sâu vào lý do tại sao lại như vậy (và tại sao chỉ riêng kỹ thuật phần mềm máy trạm L1 không thể tự mở rộng Ethereum).
Tuy nhiên, sự kết hợp giữa lấy mẫu tính khả dụng dữ liệu và SNARK sẽ giải quyết được vấn đề nan giải : nó cho phép máy trạm xác minh tính khả dụng của một lượng dữ liệu nhất định và chỉ tải xuống một phần dữ liệu đó với ít hơn lượng tính toán để xác minh xem một số bước tính toán có phù hợp hay không được thực hiện chính xác. SNARK không đáng tin cậy. Lấy mẫu tính khả dụng của dữ liệu có mô hình tin cậy vài-of-N tinh tế, nhưng nó vẫn giữ các thuộc tính cơ bản của nút không thể mở rộng - ngay cả một cuộc tấn công 51% cũng không thể buộc mạng chấp nhận các khối độc hại .
Một phương pháp khác cho bộ ba bất khả thi là kiến trúc Plasma, sử dụng các kỹ thuật khéo léo để đẩy trách nhiệm giám sát tính sẵn có dữ liệu cho người dùng theo cách tương thích khích lệ . Trở lại năm 2017-2019, khi tất cả những gì chúng ta có thể làm để mở rộng điện toán là chống gian lận, các tính năng bảo mật của Plasma rất hạn chế. Khi SNARK trở thành xu hướng chủ đạo, các trường hợp sử dụng kiến trúc Plasma sẽ trở nên rộng rãi hơn trước.
Lấy mẫu dữ liệu sẵn có tiến bộ hơn nữa
Chúng ta đang cố gắng giải quyết vấn đề gì?
Tính đến ngày 13 tháng 3 năm 2024, khi nâng cấp Dencun ra mắt , blockchain Ethereum có 3 "đốm màu" xấp xỉ 125 kB trên mỗi khe 12 giây hoặc băng thông dữ liệu khả dụng là khoảng 375 kB trên mỗi khe . Giả sử rằng dữ liệu giao dịch được xuất bản trực tiếp trên Chuỗi và chuyển ERC20 là khoảng 180 byte, TPS tối đa của rollups trên Ethereum là:
375000/12/180 = 173,6 TPS
Nếu bạn thêm calldata của Ethereum[tối đa theo lý thuyết: 30 triệu gas mỗi khe / 16 gas mỗi byte = 1.875.000 byte mỗi khe], con số này sẽ trở thành 607 TPS. Nếu sử dụng PeerDAS, kế hoạch là tăng mục tiêu số lượng blob lên 8-16, thêm dữ liệu cuộc gọi lên tốc độ 463-926 TPS.
So với Ethereum L1, đây đã là một cải tiến lớn. Nhưng điều này vẫn chưa đủ, chúng tôi còn muốn mở rộng tốt hơn. Mục tiêu trung hạn của chúng tôi là 16 MB mỗi khe cắm , khi kết hợp với các cải tiến về nén dữ liệu tổng hợp sẽ tăng tốc độ lên khoảng 58.000 TPS.
Nó là gì và nó được thực hiện như thế nào?
PeerDAS là cách triển khai "lấy mẫu 1D" tương đối đơn giản. Mỗi đốm màu trong Ethereum là một đa thức bậc 4096 trên trường nguyên tố 253 bit. Chúng tôi phát sóng "thị phần" của đa thức, mỗi thị phần bao gồm 16 đánh giá tại 16 tọa độ liền kề được rút ra từ 8192 nhóm tọa độ. Bất kỳ 4096 trong số 8192 đánh giá nào (sử dụng các tham số hiện được đề xuất: bất kỳ 64 trong số 128 mẫu có thể) đều có thể khôi phục blob.
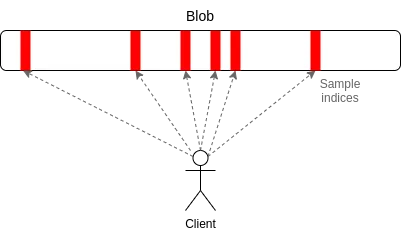
Nguyên tắc hoạt động của PeerDAS là: mỗi máy trạm chỉ giám sát một số mạng con, trong đó mạng con thứ i chịu trách nhiệm phát mẫu thứ i của blob, khi máy trạm cần lấy các đốm màu trên các mạng con khác, nó có thể lắng nghe; các mạng con khác nhau thông qua mạng p2p toàn cầu. Nút trong mạng con sẽ bắt đầu yêu cầu. So với PeerDAS, giải pháp của SubnetDAS thận trọng hơn. Nó chỉ giữ lại cơ chế mạng con và loại bỏ quá trình tìm hiểu lẫn nhau giữa nút. Theo Đề án hiện tại, nút tham gia Bằng chứng cổ phần sẽ áp dụng SubnetDAS, trong khi nút khác (tức là “máy trạm”) sẽ sử dụng PeerDAS.
Về mặt lý thuyết, không gian mở rộng của lấy mẫu một chiều (lấy mẫu 1D) khá lớn: nếu chúng ta tăng số lượng đốm màu tối đa lên 256 (mục tiêu tương ứng là 128), chúng ta có thể đạt được dung lượng mục tiêu là 16 MB. Trong trường hợp như vậy, chi phí băng thông cần thiết để lấy mẫu tính khả dụng dữ liệu trên mỗi nút được tính như sau:
16 mẫu × 128 đốm màu × 512 byte (cỡ mẫu đơn trên mỗi đốm màu) = băng thông/khe 1MB;
Yêu cầu về băng thông này chỉ ở mức giới hạn trong phạm vi có thể chấp nhận được: mặc dù khả thi về mặt kỹ thuật nhưng máy trạm bị hạn chế về băng thông sẽ không thể tham gia lấy mẫu. Chúng ta có thể tối ưu hóa giải pháp này bằng cách giảm số lượng đốm màu và tăng kích thước của từng đốm màu riêng lẻ, nhưng kiểu tái tạo dữ liệu này đắt hơn.
Để cải thiện hơn nữa hiệu suất, có thể sử dụng công nghệ lấy mẫu 2D - lấy mẫu trong một đốm màu duy nhất và giữa các đốm màu khác nhau, sử dụng các đặc điểm tuyến tính của cam kết KZG để "mở rộng" các khối Một tập hợp các đốm màu, tạo ra sê-ri"đốm màu ảo" mới lưu trữ thông tin tương tự thông qua mã hóa dự phòng.
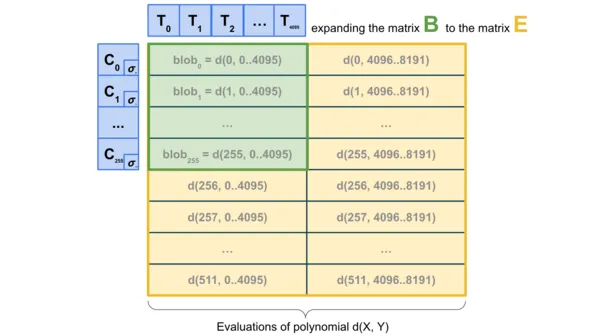
Giải pháp này có một tính năng quan trọng: quá trình mở rộng tính toán cam kết không yêu cầu lấy dữ liệu blob hoàn chỉnh, điều này làm cho nó phù hợp một cách tự nhiên cho việc xây dựng các khối phân tán. Cụ thể, nút chịu trách nhiệm xây dựng các khối chỉ cần giữ cam kết KZG của các đốm màu để xác minh tính khả dụng của các đốm màu này thông qua hệ thống DAS. Tương tự, DAS một chiều (1D DAS) cũng có ưu điểm là xây dựng các khối phân tán.
Các kết nối với nghiên cứu hiện tại là gì?
- Bài đăng gốc giới thiệu tính khả dụng dữ liệu(2018): https://github.com/ethereum/research/wiki/A-note-on-data-availability-and-erasure-coding
- Bài viết tiếp theo: https://arxiv.org/abs/1809.09044
- Bài đăng giải thích về DAS, mô hình: https://www.paradigm.xyz/2022/08/das
- Tính khả dụng 2D với các cam kết của KZG: https://ethresear.ch/t/2d-data-availability-with-kate-commitments/8081
- PeerDAS trên ethresear.ch: https://ethresear.ch/t/peerdas-a-simpler-das-approach-USE-battle-tested-p2p-comComponents/16541 và bài báo: https://eprint.iacr. tổ chức/2024/1362
- Bài thuyết trình về PeerDAS của Francesco: https://www.youtube.com/watch?v=WOdpO1tH_Us
- EIP-7594: https://eips.ethereum.org/EIPS/eip-7594
- SubnetDAS trên ethresear.ch: https://ethresear.ch/t/subnetdas-an-intermediate-das-approach/17169
- Các sắc thái của khả năng phục hồi trong lấy mẫu 2D: https://ethresear.ch/t/nuances-of-data-recoverability-in-data-availability-sampling/16256
Những gì còn lại để làm và sự đánh đổi là gì?
Nhiệm vụ hiện tại là hoàn thành việc phát triển và triển khai PeerDAS. Bước tiếp theo là thúc đẩy nó từng bước một - bằng cách liên tục theo dõi các điều kiện mạng và tối ưu hóa hiệu suất phần mềm để đảm bảo an ninh hệ thống đồng thời tăng đều đặn khả năng xử lý blob của PeerDAS. Đồng thời, chúng ta cần thúc đẩy nhiều nghiên cứu học thuật hơn, xác minh chính thức PeerDAS và các biến thể DAS khác, đồng thời đi sâu vào sự tương tác của chúng với các vấn đề như tính bảo mật của quy tắc lựa chọn fork.
Trong công việc trong tương lai, chúng tôi cần tiến hành nghiên cứu sâu hơn để xác định hình thức triển khai tối ưu của 2D DAS và chứng minh tính bảo mật của nó một cách nghiêm ngặt. Một mục tiêu dài hạn khác là tìm các giải pháp thay thế cho KZG vừa có khả năng chống lượng tử vừa không cần thiết lập đáng tin cậy. Tuy nhiên, chúng tôi vẫn chưa tìm được ứng viên nào phù hợp cho việc xây dựng khối phân tán. Ngay cả phương pháp"bạo lực" tốn kém về mặt tính toán khi sử dụng STARK đệ quy để tạo các hàng và cột và xây dựng lại bằng chứng hợp lệ cũng không hiệu quả lắm - mặc dù nhìn lên, kích thước của STARK sau khi sử dụng STIR chỉ là O( log(n) * log(log( n)) giá trị băm, nhưng lượng dữ liệu trong STARK trong các ứng dụng thực tế vẫn gần bằng kích thước của một đốm màu hoàn chỉnh.
Về lâu dài, tôi cho rằng có một số hướng phát triển khả thi:
- Áp dụng giải pháp DAS 2D lý tưởng
- Tiếp tục sử dụng giải pháp DAS một chiều - mặc dù nó sẽ hy sinh hiệu quả băng thông lấy mẫu và cần chấp nhận giới hạn trên của dung lượng dữ liệu thấp hơn nhưng nó có thể đảm bảo tính đơn giản và ổn định của hệ thống (sự mạnh mẽ)
- (Sự thay đổi lớn) Từ bỏ hoàn toàn việc lấy mẫu tính khả dụng dữ liệu(DA) và chuyển sang Plasma như một giải pháp kiến trúc Layer 2 tập trung vào phát triển
Chúng ta có thể cân nhắc ưu và nhược điểm của các tùy chọn này từ các khía cạnh sau:
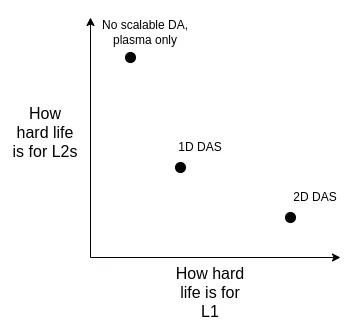
Điều quan trọng cần lưu ý là ngay cả khi chúng tôi quyết định mở rộng quy mô trực tiếp trên L1 thì sự đánh đổi giữa các lựa chọn công nghệ này vẫn tồn tại . Điều này là do nếu L1 hỗ trợ TPS cao, kích thước khối sẽ tăng đáng kể. Trong trường hợp này, nút máy trạm sẽ cần một cơ chế xác minh hiệu quả để đảm bảo rằng khối đó là chính xác. Điều này có nghĩa là chúng tôi phải áp dụng các công nghệ cơ bản ban đầu được sử dụng để tổng hợp (chẳng hạn như ZK-EVM và DAS) trên L1.
Nó tương tác với các phần khác của lộ trình như thế nào?
Việc thực hiện nén dữ liệu(xem bên dưới để biết chi tiết) sẽ làm giảm hoặc trì hoãn đáng kể nhu cầu về DAS hai chiều (2D DAS); nếu Plasma được áp dụng rộng rãi, nhu cầu sẽ giảm hơn nữa. Tuy nhiên, DAS cũng mang đến những thách thức mới cho việc xây dựng các khối phân tán: mặc dù DAS có lợi cho việc tái cấu trúc phân tán nhìn lên, nhưng trong các ứng dụng thực tế, chúng ta cần kết hợp nó với Đề án danh sách đưa vào và sự tích hợp liền mạch có liên quan của cơ chế lựa chọn fork.
nén dữ liệu
Chúng ta đang cố gắng giải quyết vấn đề gì?
Khi tổng hợp, mỗi giao dịch yêu cầu không gian dữ liệu đáng kể trên Chuỗi : giao dịch chuyển ERC20 yêu cầu khoảng 180 byte. Ngay cả với cơ chế lấy mẫu sẵn có dữ liệu lý tưởng, điều này vẫn hạn chế mở rộng của giao thức Lớp 2. Tính dựa trên dung lượng dữ liệu 16 MB mỗi khe thời gian, dễ dàng có được: 16000000/12/180 = 7407 TPS
Ngoài việc tối ưu phần tử số, nếu chúng ta còn giải được bài toán mẫu số - tức là giảm số byte chiếm dụng của mỗi giao dịch trong rollup Chuỗi thì hiệu quả sẽ như thế nào?
Nó là gì và nó được thực hiện như thế nào?
Tôi cho rằng lời giải thích hợp lý nhất là bức ảnh này từ hai năm trước:
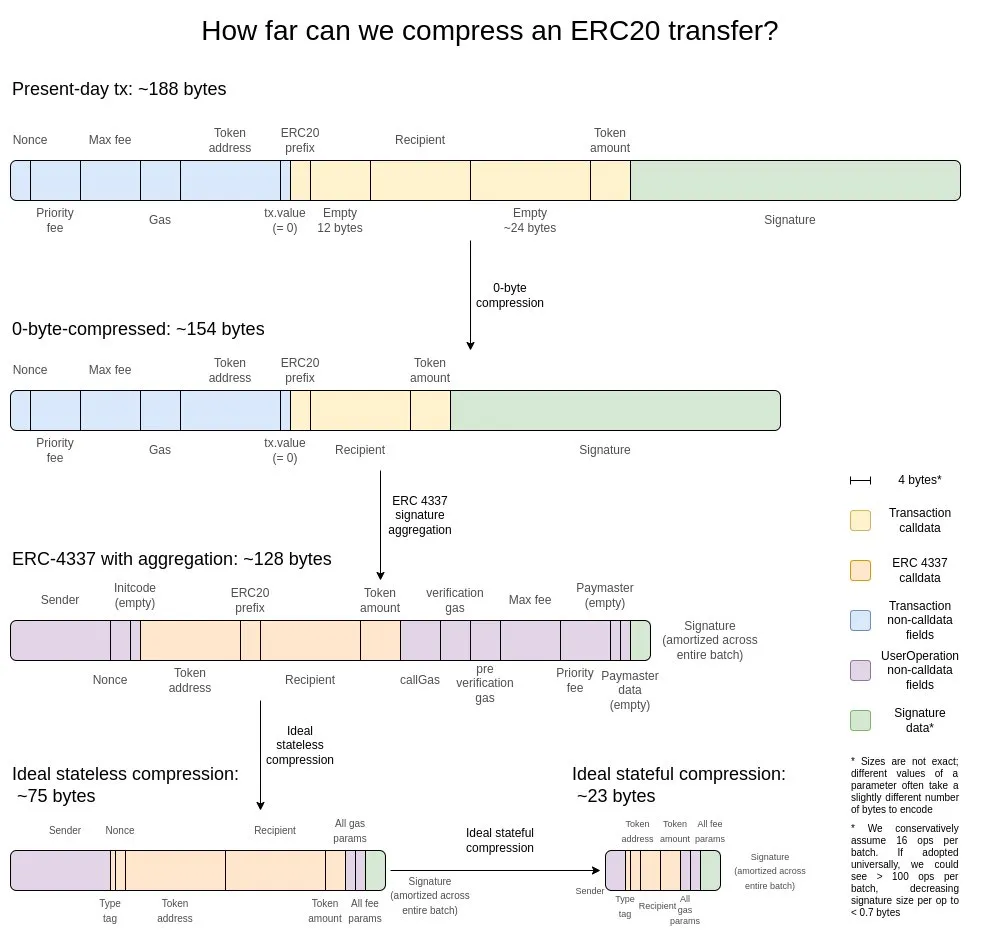
Đầu tiên là phương pháp tối ưu hóa cơ bản nhất - nén 0 byte: sử dụng hai byte để biểu thị độ dài của một chuỗi liên tục gồm 0 byte, từ đó thay thế chuỗi 0 byte ban đầu. Để đạt được sự tối ưu hóa sâu hơn, chúng ta có thể tận dụng các đặc tính sau của giao dịch:
- Tập hợp chữ ký - Di chuyển hệ thống chữ ký từ ECDSA sang BLS, có thể hợp nhất nhiều chữ ký thành một chữ ký duy nhất đồng thời xác minh tính hợp lệ của tất cả các chữ ký gốc. Mặc dù giải pháp này không phù hợp với L1 do chi phí xác minh tính toán cao (ngay cả trong kịch bản tổng hợp), nhưng ưu điểm của nó là rất rõ ràng trong hoàn cảnh hạn chế dữ liệu như L2. Bản chất tổng hợp của ERC-4337 cung cấp một lộ trình kỹ thuật khả thi để đạt được mục tiêu này.
- Cơ chế thay thế con trỏ địa chỉ - Đối với những địa chỉ đã xuất hiện trong lịch sử, chúng ta có thể thay thế địa chỉ 20 byte ban đầu bằng con trỏ 4 byte (trỏ tới vị trí trong bản ghi lịch sử). Việc tối ưu hóa này mang lại lợi nhuận lớn nhất, nhưng thực hiện tương đối phức tạp vì nó yêu cầu lịch sử của blockchain (ít nhất là một phần của lịch sử) phải được tích hợp đáng kể vào tập trạng thái.
- Lược đồ tuần tự hóa tùy chỉnh cho số tiền giao dịch - Hầu hết số tiền giao dịch thực sự chỉ chứa một vài chữ số có nghĩa. Ví dụ: 0,25 ETH được biểu thị trong hệ thống là 250.000.000.000.000.000 wei. Phí cơ bản tối đa (max-basefee) và phí ưu tiên (phí ưu tiên) của gas cũng có đặc điểm tương tự. Dựa trên tính năng này, chúng ta có thể sử dụng định dạng dấu phẩy động thập phân tùy chỉnh hoặc tạo từ điển các giá trị thường được sử dụng, từ đó giảm đáng kể không gian lưu trữ các giá trị tiền tệ.
Các kết nối với nghiên cứu hiện tại là gì?
- Khám phá từ Sequence.xyz: https://sequence.xyz/blog/compressing-calldata
- Hợp đồng được tối ưu hóa cho Calldata cho L2, từ ScopeLift: https://github.com/ScopeLift/l2-optimizooooors
- Một chiến lược thay thế - rollups dựa trên bằng chứng hợp lệ (còn gọi là rollups ZK) đăng rollups khác thay vì giao dịch: https : //ethresear .ch/t/rollup-diff-compression-application-level-compression-strategies-to-reduce- the-l2-data-footprint-on-l1/9975
- Ví BLS - triển khai tổng hợp BLS thông qua ERC-4337: https://github.com/getwax/bls-wallet
Những gì còn lại để làm và sự đánh đổi là gì ?
Nhiệm vụ hiện tại là thực hiện kế hoạch trên. Điều này liên quan đến một số sự đánh đổi quan trọng:
- Di chuyển chữ ký BLS - Việc chuyển đổi sang hệ thống chữ ký BLS yêu cầu đầu tư lượng lớn vào nguồn lực kỹ thuật và sẽ làm giảm khả năng tương thích với phần cứng đáng tin cậy được tăng cường bảo mật (TEE). Một giải pháp thay thế khả thi cho vấn đề này là trình bao bọc ZK-SNARK sử dụng các thuật toán chữ ký khác.
- Triển khai nén động - Việc triển khai các cơ chế nén động như thay thế con trỏ địa chỉ có thể làm tăng đáng kể độ phức tạp của mã máy trạm.
- Xuất bản sự khác biệt trạng thái - Việc chọn xuất bản sự khác biệt trạng thái cho Chuỗi thay vì giao dịch đầy đủ sẽ làm suy yếu kiểm toán của hệ thống đồng thời khiến cơ sở hạ tầng hiện có như Block Explorer không hoạt động bình thường.
Nó tương tác với các phần khác của lộ trình như thế nào?
Bằng cách giới thiệu ERC-4337 và cuối cùng là tiêu chuẩn hóa một số chức năng của nó trong L2 EVM, việc triển khai các công nghệ hội tụ sẽ được tăng tốc đáng kể. Tương tự, việc kết hợp một số chức năng của ERC-4337 vào L1 cũng sẽ thúc đẩy việc triển khai nhanh chóng nó trong hệ sinh thái L2.
Kiến trúc Plasma phổ quát
Chúng ta đang cố gắng giải quyết vấn đề gì?
Ngay cả với sự kết hợp giữa công nghệ nén dữ liệu và lưu trữ blob 16 MB, sức mạnh xử lý 58.000 TPS vẫn không đủ để hỗ trợ đầy đủ các tình huống băng thông cao như thanh toán của người tiêu dùng và mạng xã hội phi tập trung. Vấn đề này trở nên nổi bật hơn khi chúng tôi xem xét việc áp dụng các cơ chế bảo vệ quyền riêng tư vì các tính năng bảo mật có thể làm giảm mở rộng của hệ thống từ 3 đến 8 lần. Hiện tại, đối với các kịch bản ứng dụng có thông lượng cao và nội dung có giá trị thấp, có một tùy chọn là tính hợp lệ. Nó áp dụng mô hình lưu trữ dữ liệu ngoài Chuỗi và triển khai mô hình bảo mật duy nhất: các nhà khai thác không thể trực tiếp đánh cắp tài sản của người dùng, nhưng họ có thể đóng băng tạm thời hoặc vĩnh viễn tiền của người dùng do mất liên lạc. Tuy nhiên, chúng ta có cơ hội xây dựng những giải pháp tốt hơn.
Nó là gì và nó được thực hiện như thế nào?
Plasma là một giải pháp mở rộng quy mô Không giống như rollup, đưa dữ liệu khối hoàn chỉnh vào Chuỗi, người vận hành Plasma tạo các khối ngoài Chuỗi và chỉ ghi lại gốc Merkle của khối trên Chuỗi. Với mỗi khối, nhà điều hành sẽ phân phối một nhánh Merkle cho người dùng để chứng minh sự thay đổi trạng thái (hoặc không thay đổi) liên quan đến tài sản của người dùng. Người dùng có thể rút tài sản của mình bằng cách cung cấp các bản fork Merkle này. Một tính năng chính là các nhánh Merkle này không phải trỏ đến trạng thái mới nhất - điều này có nghĩa là ngay cả trong trường hợp xảy ra lỗi về tính khả dụng dữ liệu , người dùng vẫn có thể truy xuất tài sản bằng cách rút trạng thái mới nhất hiện có mà họ có. Nếu người dùng gửi một nhánh không hợp lệ (chẳng hạn như cố gắng rút tài sản đã được chuyển cho người khác hoặc người điều hành cố gắng tạo tài sản một cách đột ngột), cơ chế thách thức Chuỗi có thể phân xử quyền sở hữu tài sản.
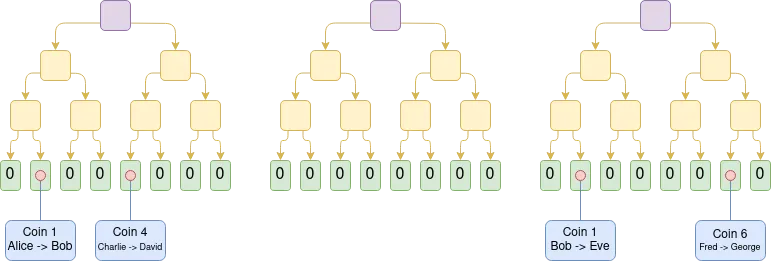
Việc triển khai sớm Plasma bị giới hạn ở các kịch bản thanh toán, gây khó khăn cho việc mở rộng chức năng rộng hơn. Tuy nhiên, nếu chúng tôi giới thiệu SNARK để xác minh từng nút, khả năng của Plasma sẽ được cải thiện đáng kể. Vì cách tiếp cận này về cơ bản có thể loại bỏ khả năng gian lận của hầu hết người vận hành nên cơ chế thách thức có thể được đơn giản hóa rất nhiều. Đồng thời, điều này cũng mở ra những con đường ứng dụng mới cho công nghệ Plasma, cho phép mở rộng sang các loại tài sản đa dạng hơn. Hơn nữa, trong trường hợp nhà điều hành cư xử trung thực, người dùng có thể rút tiền ngay lập tức mà không cần phải chờ thời gian thử thách kéo dài một tuần.
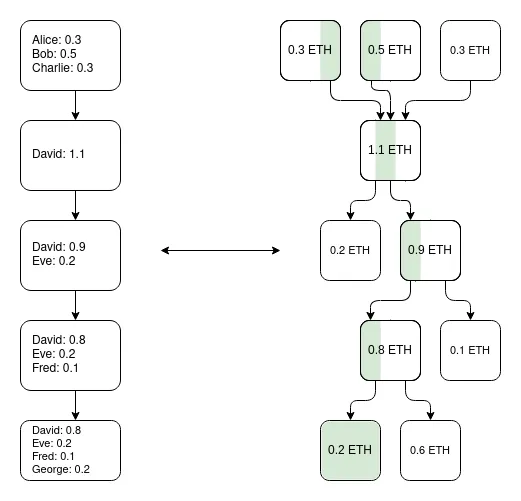
Một thông tin quan trọng: Hệ thống plasma không cần phải hoàn hảo. Ngay cả khi nó chỉ có thể bảo vệ một số tài sản(ví dụ: chỉ token chưa được chuyển trong tuần qua), nó đã cải thiện đáng kể hiện trạng của EVM siêu mở rộng , đây là một xác thực.
Một giải pháp kiến trúc khác là chế độ kết hợp giữa plasma/rollup, trong đó Intmax là một đại diện điển hình. Kiểu kiến trúc này chỉ lưu trữ một lượng rất nhỏ dữ liệu người dùng trên Chuỗi (khoảng 5 byte cho mỗi người dùng), do đó đạt đến điểm cân bằng giữa plasma và rollup về mặt đặc điểm: lấy Intmax làm ví dụ, nó đạt được mở rộng cực cao và quyền riêng tư, nhưng ngay cả trong kịch bản dung lượng dữ liệu 16 MB, thông lượng lý thuyết của nó bị giới hạn ở khoảng 266.667 TPS (phương pháp tính toán: 16.000.000/12/5).
Các kết nối với nghiên cứu hiện tại là gì?
- Giấy Plasma gốc: https://plasma.io/plasma-deprecated.pdf
- Tiền mặt Plasma: https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-checking/1298
- Dòng tiền Plasma: https://hackmd.io/DgzmJIRjSzCYvl4lUjZXNQ?view#🚪-Exit
- Intmax (2023): https://eprint.iacr.org/2023/1082
Những gì còn lại để làm và sự đánh đổi là gì?
Nhiệm vụ cốt lõi hiện nay là đẩy hệ thống Plasma vào hoàn cảnh sản xuất. Như đã đề cập trước đó, mối quan hệ giữa Plasma và Validium không phải là/hoặc: bất kỳ validium nào cũng có thể cải thiện các đặc tính bảo mật của nó dù chỉ một chút bằng cách tích hợp các tính năng của Plasma vào cơ chế thoát của nó. Điểm nổi bật của nghiên cứu bao gồm:
- Tìm các thông số hiệu suất tối ưu cho EVM (được xem xét từ các khía cạnh như giả định về độ tin cậy, chi phí gas trong trường hợp xấu nhất L1 và khả năng chống DoS)
- Khám phá các giải pháp kiến trúc thay thế cho các tình huống ứng dụng cụ thể
Đồng thời, chúng ta cần phải trực tiếp giải quyết vấn đề về mặt khái niệm Plasma phức tạp hơn so với việc tổng hợp, vấn đề này cần được thúc đẩy thông qua con đường kép là nghiên cứu lý thuyết và tối ưu hóa việc triển khai khung chung.
Sự đánh đổi chính của việc áp dụng kiến trúc Plasma là nó phụ thuộc nhiều hơn vào người vận hành và khó đạt được "dựa trên" hơn. Mặc dù kiến trúc plasma/rollup lai thường có thể tránh được nhược điểm này.
Nó tương tác với các phần khác của lộ trình như thế nào?
Tiện ích của giải pháp Plasma càng cao thì áp lực lên lớp L1 càng ít để cung cấp tính khả dụng dữ liệu hiệu suất cao. Đồng thời, việc chuyển các hoạt động trên Chuỗi sang L2 cũng có thể giảm áp lực MEV ở cấp L1.
Hệ thống chứng minh L2 trưởng thành
Chúng ta đang cố gắng giải quyết vấn đề gì?
Hiện tại, hầu hết các bản tổng hợp chưa triển khai cơ chế thực sự không cần sự tin cậy - tất cả đều có ủy ban an toàn có thể can thiệp vào hoạt động của hệ thống bằng chứng (lạc quan hoặc hợp lệ). Trong một số trường hợp, hệ thống chứng minh thậm chí còn bị thiếu hoàn toàn hoặc chỉ có chức năng "tư vấn". Tiến bộ nhất trong lĩnh vực này là: (i) một số bản tổng hợp dành riêng cho ứng dụng (chẳng hạn như Nhiên liệu), đã triển khai các cơ chế không cần tin cậy; (ii) tính đến viết bài này, hai bản tổng hợp EVM hoàn chỉnh - Optimism và Arbitrum, một cột mốc không cần tin cậy một phần được gọi là "giai đoạn 1" đã đạt được. Trở ngại chính cho sự phát triển hơn nữa của rollup là mối lo ngại về các lỗ hổng mã. Để đạt được hoạt động tổng hợp thực sự không cần tin cậy, chúng ta phải giải quyết trực tiếp thách thức này.
Nó là gì và nó được thực hiện như thế nào?
Đầu tiên chúng ta cùng xem lại hệ thống “sân khấu” đã được giới thiệu ở bài viết trước. Mặc dù các yêu cầu đầy đủ chi tiết hơn nhưng các yếu tố chính được tóm tắt dưới đây:
- Giai đoạn 0 : Người dùng phải có khả năng chạy nút một cách độc lập và hoàn thành đồng bộ hóa Chuỗi. Cơ chế xác minh có thể được tập trung hoàn toàn hoặc dựa trên sự tin cậy .
- Giai đoạn 1 : Hệ thống phải triển khai cơ chế chứng minh (không cần sự tin cậy) để đảm bảo rằng chỉ những giao dịch hợp lệ mới được chấp nhận. Một ủy ban an ninh được phép can thiệp vào hệ thống chứng nhận nhưng cần có ngưỡng biểu quyết 75% . Đồng thời, hơn 26% thành viên ủy ban phải đến từ bên ngoài các công ty phát triển lớn. Có thể sử dụng cơ chế nâng cấp yếu hơn (chẳng hạn như DAO), nhưng phải đặt khóa thời gian đủ dài để đảm bảo người dùng có thể rút tiền một cách an toàn trước khi nâng cấp độc hại có hiệu lực.
- Giai đoạn 2 : Hệ thống phải triển khai cơ chế chứng minh (không cần sự tin cậy) để đảm bảo rằng chỉ những giao dịch hợp lệ mới có thể được chấp nhận. Ủy ban bảo mật chỉ có thể can thiệp khi xảy ra lỗi mã rõ ràng , chẳng hạn như hai hệ thống bằng chứng xung đột hoặc một hệ thống bằng chứng duy nhất tạo ra các gốc hậu trạng thái khác nhau cho cùng một khối (hoặc không tạo được một khối trong một khoảng thời gian dài, chẳng hạn như một tuần). Được phép thiết lập cơ chế nâng cấp nhưng chỉ với những khóa có thời gian cực kỳ dài.
Mục tiêu cuối cùng của chúng tôi là đạt đến giai đoạn hai. Thách thức chính khi chuyển sang giai đoạn thứ hai là đảm bảo rằng mọi người có đủ niềm tin vào hệ thống bằng chứng và cho rằng nó đủ tin cậy . Hiện tại có hai con đường triển khai chính:
- Xác minh chính thức : Chúng ta có thể sử dụng các kỹ thuật toán học và khoa học máy tính hiện đại để chứng minh (lạc quan hoặc hợp lệ) rằng hệ thống sẽ chỉ chấp nhận các khối tuân thủ đặc tả EVM. Mặc dù loại công nghệ này đã lịch sử hàng thập kỷ nhưng những đột phá công nghệ gần đây (chẳng hạn như Lean 4) đã cải thiện đáng kể tính hữu dụng của nó và sự phát triển của các bằng chứng được hỗ trợ bởi AI dự kiến sẽ đẩy nhanh hơn nữa quá trình này.
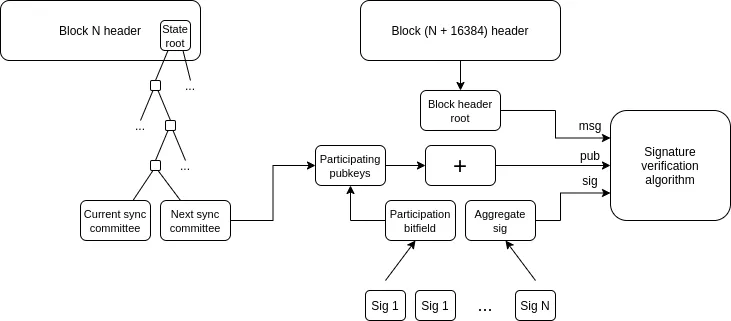
- Cơ chế đa bằng chứng : Xây dựng nhiều hệ thống bằng chứng và gửi tiền vào 2/3 hợp đồng nhiều chữ ký (hoặc ngưỡng cao hơn) được kiểm soát chung bởi các hệ thống này và ủy ban bảo mật (và/hoặc các thành phần khác dựa trên các giả định về độ tin cậy, chẳng hạn như TEE) . Khi các hệ thống chứng nhận khác nhau đạt được thỏa thuận, ủy ban an toàn không có quyền quyết định; khi có sự khác biệt giữa các hệ thống, ủy ban an toàn chỉ có thể chọn một trong các kết quả hiện có và không thể thực thi kế hoạch của riêng mình.
Các kết nối với nghiên cứu hiện tại là gì?
- EVM K Semantics (công việc xác minh chính thức bắt đầu vào năm 2017): https://github.com/runtimeverification/evm-semantics
- Bài trình bày về ý tưởng đa Prover(2022): https://www.youtube.com/watch?v=6hfVzCWT6YI
- Taiko có kế hoạch sử dụng nhiều bằng chứng: https://docs.taiko.xyz/core-concepts/multi-proofs/
Những gì còn lại để làm và sự đánh đổi là gì?
Vẫn còn lượng lớn việc phải làm khi xác minh chính thức. Chúng tôi cần phát triển một phiên bản được xác minh chính thức của Prover SNARK hoàn chỉnh cho EVM. Đây là một dự án cực kỳ phức tạp, mặc dù chúng tôi đang thực hiện nó. Tuy nhiên, có một giải pháp kỹ thuật có thể giảm đáng kể độ phức tạp: trước tiên chúng ta có thể xây dựng Prover SNARK được xác minh chính thức cho một máy ảo tối thiểu (chẳng hạn như RISC-V hoặc Cairo), sau đó triển khai EVM trên máy ảo tối thiểu này ( Tại đồng thời, nó chính thức chứng minh sự tương đương của nó với các thông số kỹ thuật EVM khác).
Về cơ chế chứng minh đa dạng, có hai vấn đề cốt lõi cần được giải quyết: Thứ nhất, chúng ta cần thiết lập sự tin cậy hoàn toàn vào ít nhất hai hệ thống chứng minh khác nhau. Điều này đòi hỏi rằng các hệ thống này không chỉ có đủ an toàn riêng lẻ mà còn nếu chúng bị lỗi thì chúng sẽ bị lỗi vì những lý do khác nhau và không liên quan (để chúng không bị hỏng đồng thời). Thứ hai, chúng ta cần thiết lập độ tin cậy cực cao vào logic cơ bản kết hợp các hệ thống chứng minh này. Phần mã này tương đối nhỏ. Mặc dù có phương pháp để đơn giản hóa hơn nữa - chẳng hạn như gửi tiền vào hợp đồng nhiều chữ ký An Safe với các hợp đồng đại diện cho mỗi hệ thống bằng chứng với tư cách là người ký - giải pháp này sẽ phải chịu chi phí gas Chuỗi cao hơn. Vì vậy, chúng ta cần tìm ra sự cân bằng phù hợp giữa hiệu quả và bảo mật.
Nó tương tác với các phần khác của lộ trình như thế nào?
Việc di chuyển các hoạt động trên Chuỗi sang L2 có thể giảm bớt áp lực MEV lên L1.
Cải thiện khả năng tương tác chéo L2
Chúng ta đang cố gắng giải quyết vấn đề gì?
Một thách thức lớn đối với hệ sinh thái L2 hiện tại là người dùng khó có thể chuyển đổi liền mạch giữa các L2 khác nhau. Điều tồi tệ hơn là các giải pháp có vẻ thuận tiện lại thường giới thiệu lại các phụ thuộc đáng tin cậy - chẳng hạn như cầu nối xuyên chuỗi tập trung, máy trạm RPC, v.v. Nếu chúng tôi thực sự muốn sử dụng L2 như một phần không thể thiếu của hệ sinh thái Ethereum , chúng tôi phải đảm bảo rằng người dùng có thể có được trải nghiệm thống nhất nhất quán với mạng chủ Ethereum khi sử dụng hệ sinh thái L2.
Nó là gì và nó được thực hiện như thế nào?
Những cải tiến về khả năng tương tác chéo L2 trải rộng trên nhiều chiều. Nhìn lên, kiến trúc Ethereum tập trung vào tổng hợp về cơ bản tương đương với phân đoạn thực thi L1. Do đó, chúng ta có thể khám phá những lỗ hổng tồn tại trong hệ sinh thái Ethereum L2 hiện tại trên thực tế bằng cách so sánh mô hình lý tưởng này. Dưới đây là các khía cạnh chính:
- Địa chỉ cụ thể theo Chuỗi : Mã định danh Chuỗi(chẳng hạn như L1, Optimism, Arbitrum , v.v.) phải là một phần không thể thiếu của địa chỉ. Sau khi thực hiện, quá trình chuyển tiền xuyên lớp sẽ trở nên đơn giản: người dùng chỉ cần nhập địa chỉ vào cột “Gửi” và ví có thể tự động xử lý các hoạt động tiếp theo (bao gồm cả việc gọi cầu nối xuyên chuỗi).
- Yêu cầu thanh toán theo Chuỗi cụ thể : Cần thiết lập một cơ chế tiêu chuẩn hóa để đơn giản hóa việc xử lý các yêu cầu như "gửi cho tôi số lượng X token loại Y trên Chuỗi Z." Các kịch bản ứng dụng chính bao gồm:
- Các tình huống thanh toán: bao gồm chuyển khoản cá nhân và thanh toán cho người bán
- Yêu cầu quỹ DApp: như trong ví dụ Polymarket ở trên
- Trao đổi Chuỗi chéo và thanh toán gas : Cần thiết lập một giao thức mở được tiêu chuẩn hóa để xử lý các hoạt động xuyên Chuỗi, chẳng hạn như:
- "Tôi sẽ trả 1 ETH trên Optimism để đổi lấy 0,9999 ETH mà người khác đã trả cho tôi trên Arbitrum "
- "Tôi sẽ trả 0,0001 ETH cho Optimism cho bất kỳ ai sẵn sàng thực hiện giao dịch này trên Arbitrum "
- Máy trạm nhẹ : Người dùng có thể xác thực trực tiếp Chuỗi mà họ tương tác thay vì phụ thuộc hoàn toàn vào nhà cung cấp dịch vụ RPC. Helios được phát triển bởi a16z crypto đã triển khai tính năng này trên mạng chủ Ethereum và bây giờ chúng tôi cần mở rộng tính năng không cần tin cậy này sang mạng L2. ERC-3668 (CCIP-read) cung cấp giải pháp triển khai khả thi.
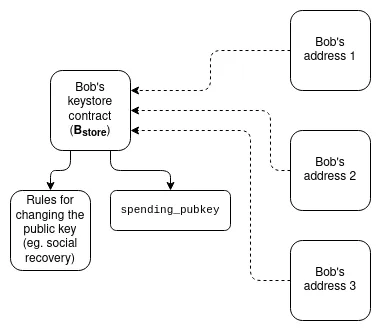
Ví keystore : Hiện tại, nếu bạn muốn cập nhật khóa kiểm soát ví hợp đồng thông minh, bạn phải cập nhật khóa đó trên tất cả N Chuỗi mà ví đó tồn tại. Ví keystore là công nghệ cho phép các khóa chỉ tồn tại ở một nơi (trên L1 hoặc có thể trong tương lai trên L2) và sau đó đọc từ bất kỳ L2 nào có bản sao của ví. Điều này có nghĩa là việc cập nhật chỉ phải được thực hiện một lần. Để nâng cao hiệu quả, ví kho khóa cần L2 để cung cấp cách đọc L1 được chuẩn hóa miễn phí; cho mục đích này, hai Đề án là L1SLOAD và REMOESTATICCALL.
- Ý tưởng "cầu nối token chung" cấp tiến hơn : Hãy tưởng tượng một thế giới trong đó tất cả L2 là một tập hợp các bằng chứng hợp lệ, được gửi tới Ethereum vào mọi khoảng thời gian. Ngay cả trong trường hợp này, muốn di chuyển tài sản một cách "nguyên bản" giữa L2 vẫn sẽ yêu cầu rút tiền và gửi tiền, điều này đòi hỏi phải trả phí gas L1 lượng lớn . Một phương pháp để giải quyết vấn đề này là tạo một bản tổng hợp tối thiểu được chia sẻ có chức năng duy nhất là duy trì số dư của nhiều loại token khác nhau mà mỗi L2 sở hữu và cho phép số dư này được chuyển thông qua sê-ri các hoạt động gửi qua L2 do bất kỳ L2 nào khởi xướng. Cập nhật tổng thể. Điều này sẽ cho phép chuyển khoản chéo L2 diễn ra mà không phải trả phí gas L1 cho lần chuyển và không yêu cầu công nghệ dựa trên nhà cung cấp thanh khoản như ERC-7683.
- Khả năng kết hợp đồng bộ : Cho phép các cuộc gọi đồng bộ giữa một L2 và L1 cụ thể hoặc giữa nhiều L2. Điều này có thể giúp cải thiện hiệu quả tài chính của các giao thức DeFi. Cái trước có thể được thực hiện mà không cần bất kỳ sự phối hợp chéo L2 nào; cái sau yêu cầu sử dụng sắp xếp chia sẻ. dựa trên bản tổng hợp tự nhiên thân thiện với tất cả các công nghệ này.
Các kết nối với nghiên cứu hiện tại là gì?
- Địa chỉ cụ thể theo Chuỗi : ERC-3770: https://eips.ethereum.org/EIPS/eip-3770
- ERC-7683: https://eips.ethereum.org/EIPS/eip-7683
- RIP-7755: https://github.com/wilsoncusack/RIPs/blob/cross-l2-call-standard/RIPS/rip-7755.md
- Thiết kế Scroll khóa Scroll : https://hackmd.io/@haichen/keystore
- Helios: a16z
- ERC-3668 (đôi khi được gọi là đọc CCIP): https://eips.ethereum.org/EIPS/eip-3668
- Đề án về "xác nhận trước dựa trên (được chia sẻ)" của Justin Drake: https://ethresear.ch/t/based-preconfirmations/17353
- L1SLOAD (RIP-7728): https://ethereum-magicians.org/t/rip-7728-l1sload-precompile/20388
- Optimism trong Optimism : https://github.com/ethereum- Optimism/ecosystem-contributions/issues/76
- AggLayer, bao gồm các ý tưởng cầu nối token được chia sẻ: https://github.com/AggLayer
Những gì còn lại để làm và sự đánh đổi là gì?
Nhiều ví dụ trên phải đối mặt với vấn đề nan giải chung về tiêu chuẩn hóa: khi nào cần tiêu chuẩn hóa và ở cấp độ nào. Nếu bạn tiêu chuẩn hóa quá sớm, bạn có nguy cơ tạo ra các giải pháp kém chất lượng; nếu bạn tiêu chuẩn hóa quá muộn, bạn có nguy cơ bị phân tán không cần thiết. Trong một số trường hợp, có những giải pháp ngắn hạn tuy yếu nhưng dễ thực hiện, có những giải pháp dài hạn mất khá nhiều thời gian để thực hiện nhưng cuối cùng lại “đúng”.
Điều độc đáo ở phần này là nhiệm vụ này không chỉ là vấn đề kỹ thuật mà thậm chí có thể chủ yếu là vấn đề xã hội. Họ yêu cầu sự hợp tác của L2, ví và L1. Khả năng giải quyết thành công vấn đề này của chúng tôi là một bài kiểm tra khả năng của chúng tôi trong việc đoàn kết với nhau như một cộng đồng.
Nó tương tác với các phần khác của lộ trình như thế nào?
Hầu hết Đề án này đều là cấu trúc "cấp cao" và do đó ít có tác động đến việc cân nhắc ở cấp độ L1. Ngoại lệ duy nhất là sắp xếp chung, điều này có tác động đáng kể đến MEV.
Mở rộng thực thi trên L1
Chúng ta đang cố gắng giải quyết vấn đề gì?
Nếu L2 trở nên có mở rộng và thành công rất cao, nhưng L1 vẫn chỉ có thể xử lý một số lượng giao dịch rất nhỏ, Ethereum có thể gặp một số rủi ro:
- Tính kinh tế của tài sản ETH sẽ trở nên rủi ro hơn, ảnh hưởng đến tính bảo mật lâu dài của mạng.
- Nhiều L2 được hưởng lợi từ mối quan hệ chặt chẽ với hệ sinh thái tài chính phát triển cao trên L1 và nếu hệ sinh thái này suy yếu đáng kể thì động lực trở thành L2 (chứ không phải L1 độc lập) cũng sẽ yếu đi.
- Sẽ mất nhiều thời gian để L2 đạt được sự đảm bảo an ninh chính xác như L1.
- Nếu L2 không thành công (ví dụ: do hành vi độc hại hoặc nhà điều hành biến mất), người dùng vẫn cần phải thông qua L1 để khôi phục tài sản của mình. Do đó, L1 cần phải đủ mạnh để ít nhất thỉnh thoảng thực sự xử lý được quá trình tắt máy cực kỳ phức tạp và khó hiểu của L2.
Vì những lý do này, việc tiếp tục mở rộng L1 và đảm bảo rằng nó có thể tiếp tục đáp ứng nhu cầu sử dụng tăng trưởng là rất có giá trị.
nó là gì vậy? Nó hoạt động như thế nào?
Cách đơn giản nhất để mở rộng là trực tiếp tăng giới hạn gas . Tuy nhiên, điều này có thể dẫn đến việc tập trung hóa L1, do đó làm suy yếu một đặc điểm quan trọng khác của Ethereum L1 với tư cách là lớp cơ sở mạnh mẽ: độ tin cậy của nó. Hiện đang có cuộc tranh luận về mức độ bền vững của việc tăng gas đơn giản và nó cũng phụ thuộc vào những kỹ thuật khác được triển khai để làm cho các khối lớn hơn dễ xác minh hơn (ví dụ: hết hạn dữ liệu lịch sử , không trạng thái, bằng chứng hiệu lực của L1 EVM). Một khía cạnh quan trọng khác cần cải tiến liên tục là hiệu quả của phần mềm máy trạm Ethereum , ngày nay máy trạm được tối ưu hóa hơn nhiều so với 5 năm trước. Chiến lược tăng giới hạn gas L1 hiệu quả sẽ liên quan đến việc đẩy nhanh tiến độ của các công nghệ xác minh này.
Một chiến lược mở rộng khác liên quan đến việc xác định các khả năng và loại máy tính cụ thể có thể giảm chi phí mà không ảnh hưởng đến phi tập trung của mạng hoặc các thuộc tính bảo mật của mạng. Ví dụ về điều này bao gồm:
- EOF: Định dạng mã byte EVM mới có lợi hơn cho phân tích tĩnh và cho phép triển khai nhanh hơn. Khi tính đến những hiệu quả này, mã byte EOF có thể mang lại chi phí gas thấp hơn.
- Định giá gas đa chiều: Việc thiết lập phí cơ bản và giới hạn cho điện toán, dữ liệu và lưu trữ tương ứng có thể tăng công suất tối đa của Ethereum L1 mà không cần tăng công suất tối đa (từ đó tránh được rủi ro bảo mật mới).
- Giảm chi phí gas cho các mã hoạt động và tiền biên dịch cụ thể : Lịch sử, chúng tôi đã tăng chi phí gas cho một số hoạt động được định giá thấp trong một số vòng để tránh các cuộc tấn công từ chối dịch vụ. Điều chúng tôi làm ít thường xuyên hơn nhưng có thể nỗ lực nhiều hơn là giảm chi phí gas cho các hoạt động được định giá quá cao. Ví dụ: phép cộng rẻ hơn nhiều so với phép nhân, nhưng hiện tại các mã ADD và MUL có giá như nhau. Chúng tôi có thể làm cho ADD rẻ hơn và thậm chí các opcode đơn giản hơn như PUSH cũng có thể rẻ hơn.
- EVM-MAX và SIMD : EVM-MAX ("Mở rộng số học mô-đun") là một Đề án cho phép số học mô-đun số lớn nguyên gốc được thực hiện hiệu quả hơn trong một mô-đun riêng biệt của EVM. Các giá trị được tính toán bởi EVM-MAX chỉ có thể được truy cập bằng các opcode EVM-MAX khác trừ khi được xuất có chủ ý; điều này cho phép các giá trị này được lưu trữ ở định dạng được tối ưu hóa, cung cấp không gian lớn hơn. SIMD ("Một lệnh nhiều dữ liệu") là một Đề án cho phép thực hiện hiệu quả cùng một lệnh trên một tập hợp các giá trị. Sự kết hợp của cả hai tạo ra một bộ đồng xử lý mạnh mẽ cùng với EVM có thể được sử dụng để thực hiện các hoạt động crypto hiệu quả hơn. Điều này đặc biệt hữu ích cho các giao thức bảo mật và hệ thống chứng minh L2, do đó giúp mở rộng quy mô L1 và L2.
Những cải tiến này sẽ được thảo luận chi tiết hơn trong bài đăng trên blog Splurge trong tương lai.
Cuối cùng, chiến lược thứ ba là các bản tổng hợp gốc (hoặc “ rollups được lưu giữ”): về cơ bản, tạo ra nhiều bản sao của EVM chạy song song, tạo thành một mô hình tương đương về mặt chức năng với những gì bản tổng hợp có thể cung cấp nhưng tích hợp nguyên bản hơn vào giao thức.
Các kết nối với nghiên cứu hiện tại là gì?
- Lộ trình mở rộng Ethereum L1 của Polynya: https://polynya.mirror.xyz/epju72rsymfB-JK52_uYI7HuhJ-W_zM735NdP7alkAQ
- Gas gas đa chiều : https://vitalik.eth.limo/general/2024/05/09/multidim.html
- EIP-7706: https://eips.ethereum.org/EIPS/eip-7706
- EOF: https://evmobjectformat.org/
- EVM-MAX: https://ethereum-magicians.org/t/eip-6601-evm-modular-arithmetic-extensions-evmmax/13168
- SIMD: https://eips.ethereum.org/EIPS/eip-616
- Bản rollups: https://mirror.xyz/ohotties.eth/P1qSCcwj2FZ9cqo3_6kYI4S2chW5K5tmEgogk6io1GE
- Phỏng vấn Max Resnick về giá trị của mở rộng L1: https://x.com/BanklessHQ/status/1831319419739361321
- Justin Drake về việc sử dụng SNARK rollups rollups gốc để mở rộng : https://www.reddit.com/r/ethereum/comments/1f81ntr/comment/llmfi28/
Những gì còn lại để làm và sự đánh đổi là gì?
Có ba chiến lược để mở rộng L1, có thể được quảng bá riêng lẻ hoặc song song:
- Cải tiến các kỹ thuật (ví dụ: mã máy trạm, máy trạm không trạng thái, hết hạn dữ liệu lịch sử ) để giúp L1 xác minh dễ dàng hơn, sau đó tăng giới hạn gas .
- Giảm chi phí cho các hoạt động cụ thể và tăng công suất trung bình mà không làm tăng rủi ro trong trường hợp xấu nhất.
- Bản tổng hợp gốc (nghĩa là "tạo N bản sao của EVM chạy song song", đồng thời có khả năng mang lại cho nhà phát triển rất nhiều tính linh hoạt trong các tham số sao chép được triển khai).
Điều cần phải hiểu là đây là những công nghệ khác nhau với sự đánh đổi riêng. Ví dụ: các bản tổng hợp gốc có nhiều điểm yếu giống như các bản tổng hợp thông thường về khả năng kết hợp: bạn không thể gửi một giao dịch để thực hiện các thao tác trên nhiều bản tổng hợp một cách đồng bộ như bạn có thể làm với các hợp đồng trên cùng một L1 (hoặc L2). Việ





