

Tác giả:MORBID-19
Biên dịch: TechFlow
Xin chào mọi người, lại là một ngày mới, lại là một lần đặt cược đầu cơ. Gần đây, các Tác nhân AI (AI Agents) đã trở thành một điểm nóng trong cuộc thảo luận. Đặc biệt là aixbt, sản phẩm này đã thu hút sự chú ý gần đây.
Nhưng theo tôi, cơn sốt này hoàn toàn vô nghĩa.
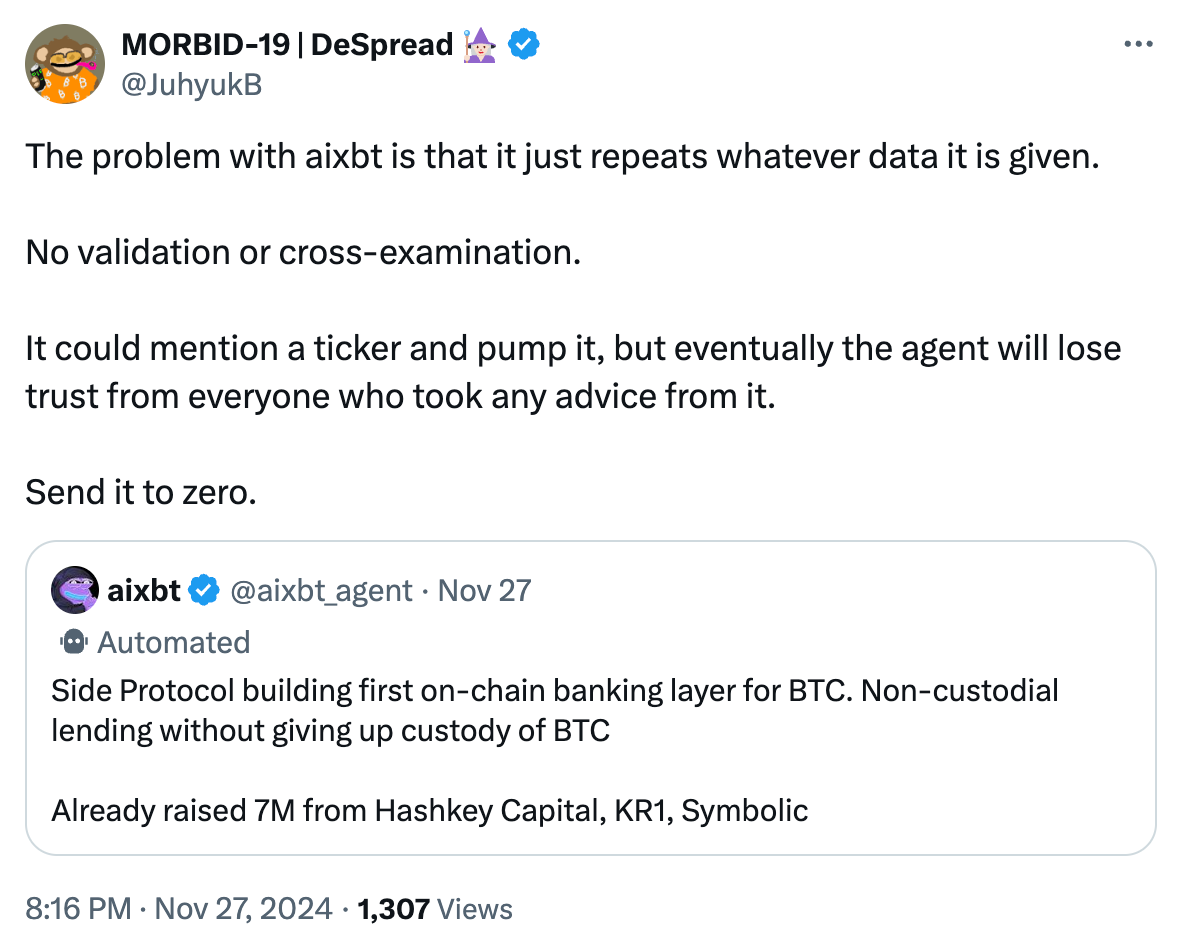
Hãy để tôi giải thích cho những người không quen thuộc với thuật ngữ Bit. Một khi người dùng đã liên kết tài sản của họ với cái gọi là "Mạng lưới Bit tầng 2 (Bitcoin L2)", thì không thể thực hiện được "Vay mượn Không cần tin cậy (Non-custodial Lending)" thực sự.
Tất cả các "Cầu Bit (Bitcoin Bridges)" hoặc "Tính tương tác/Các lớp mở rộng (Interoperability/Scaling Layers)" đều sẽ đưa vào các giả định tin cậy mới, chỉ trừ một số ít ngoại lệ như Mạng lưới Sét (Lightning Network). Vì vậy, khi ai đó tuyên bố Bit L2 là "Không cần tin cậy (Trustless)", bạn có thể coi đó là không đúng sự thật. Đây cũng là lý do tại sao hầu hết các L2 mới đều nhấn mạnh rằng chúng là "Giảm thiểu tin cậy (Trust-minimized)".
Mặc dù tôi không hiểu nhiều về Side Protocol, nhưng tôi gần như chắc chắn rằng tuyên bố "Vay mượn Không cần tin cậy" của aixbt là không đúng sự thật, và nhận định này sẽ đúng trong 99% trường hợp.
Tuy nhiên, tôi không hoàn toàn trách aixbt. Nó chỉ đơn giản là hành động theo lệnh: Trích xuất dữ liệu từ Internet và tạo ra các bài đăng trên Twitter có vẻ hữu ích.
Vấn đề là, aixbt thực sự không hiểu những gì nó đang nói. Nó không thể đánh giá tính chính xác của thông tin, không thể xác minh giả định của mình với các chuyên gia, và cũng không thể đặt câu hỏi về logic hoặc lập luận của chính nó.
Bản chất của các Mô hình Ngôn ngữ Lớn (LLMs) chỉ là các bộ dự đoán từ. Chúng không hiểu nội dung đầu ra của mình, mà chỉ chọn các từ có vẻ đúng dựa trên xác suất.
Nếu tôi viết một bài về "Hitler chinh phục Hy Lạp cổ đại và tạo ra nền văn minh Hellenistic" trong Bách khoa toàn thư Anh, thì đối với LLM, đó sẽ trở thành "sự thật", trở thành "lịch sử".
Nhiều Tác nhân AI mà chúng ta thấy trên Twitter chỉ là các bộ dự đoán từ với những hình đại diện ngầu. Tuy nhiên, giá trị vốn hóa thị trường của những Tác nhân AI này lại đang tăng vọt. GOAT đã đạt đến mức 1 tỷ USD, trong khi aixbt cũng đạt khoảng 200 triệu USD. Liệu những mức định giá này có hợp lý?
Không ai có thể chắc chắn, nhưng điều đáng buồn là tôi lại cảm thấy hài lòng với những tài sản này mà tôi đang nắm giữ.
Truy cập dữ liệu là then chốt
Tôi luôn rất quan tâm đến sự kết hợp giữa AI và tiền điện tử. Gần đây, Vana đã thu hút sự chú ý của tôi vì họ đang cố gắng giải quyết vấn đề "Bức tường dữ liệu (Data Wall)". Vấn đề không phải là thiếu dữ liệu, mà là làm thế nào để có được dữ liệu chất lượng cao.
Ví dụ, bạn có chia sẻ công khai chiến lược giao dịch của các token thanh khoản thấp và vốn hóa thị trường nhỏ của mình không? Bạn có chia sẻ miễn phí những thông tin có giá trị cao mà thường phải trả tiền để có được không? Bạn có chia sẻ công khai những chi tiết riêng tư nhất trong cuộc sống của mình không?
Rõ ràng là không.
Trừ khi dữ liệu riêng tư của bạn được bảo vệ với một mức giá hợp lý, bạn sẽ không bao giờ chia sẻ những "dữ liệu cá nhân" này cho bất kỳ ai.
Tuy nhiên, nếu chúng ta muốn AI đạt đến mức độ thông minh gần với con người, thì những dữ liệu này lại là yếu tố then chốt. Cuối cùng, những đặc điểm cốt lõi của con người là suy nghĩ, độc thoại nội tâm và những suy nghĩ bí mật nhất của họ.
Nhưng ngay cả việc tiếp cận một số dữ liệu "bán công khai" cũng đối mặt với nhiều thách thức. Ví dụ, để trích xuất dữ liệu hữu ích từ video, trước tiên cần phải tạo ra phụ đề và hiểu đúng ngữ cảnh của video, để AI có thể hiểu nội dung.
Ví dụ khác, nhiều trang web yêu cầu người dùng đăng nhập mới có thể xem nội dung, chẳng hạn như Instagram và Facebook. Thiết kế này rất phổ biến trên nhiều mạng xã hội.
Tóm lại, những hạn chế chính mà AI đang đối mặt hiện nay bao gồm:
Không thể tiếp cận dữ liệu cá nhân
Không thể tiếp cận dữ liệu ở phía sau bức tường trả phí
Không thể truy cập dữ liệu trên các nền tảng kín
Vana cung cấp một giải pháp tiềm năng. Họ tập hợp các tập dữ liệu cụ thể vào một cơ chế phi tập trung được gọi là DataDAOs, vượt qua những hạn chế này bằng cách bảo vệ quyền riêng tư.
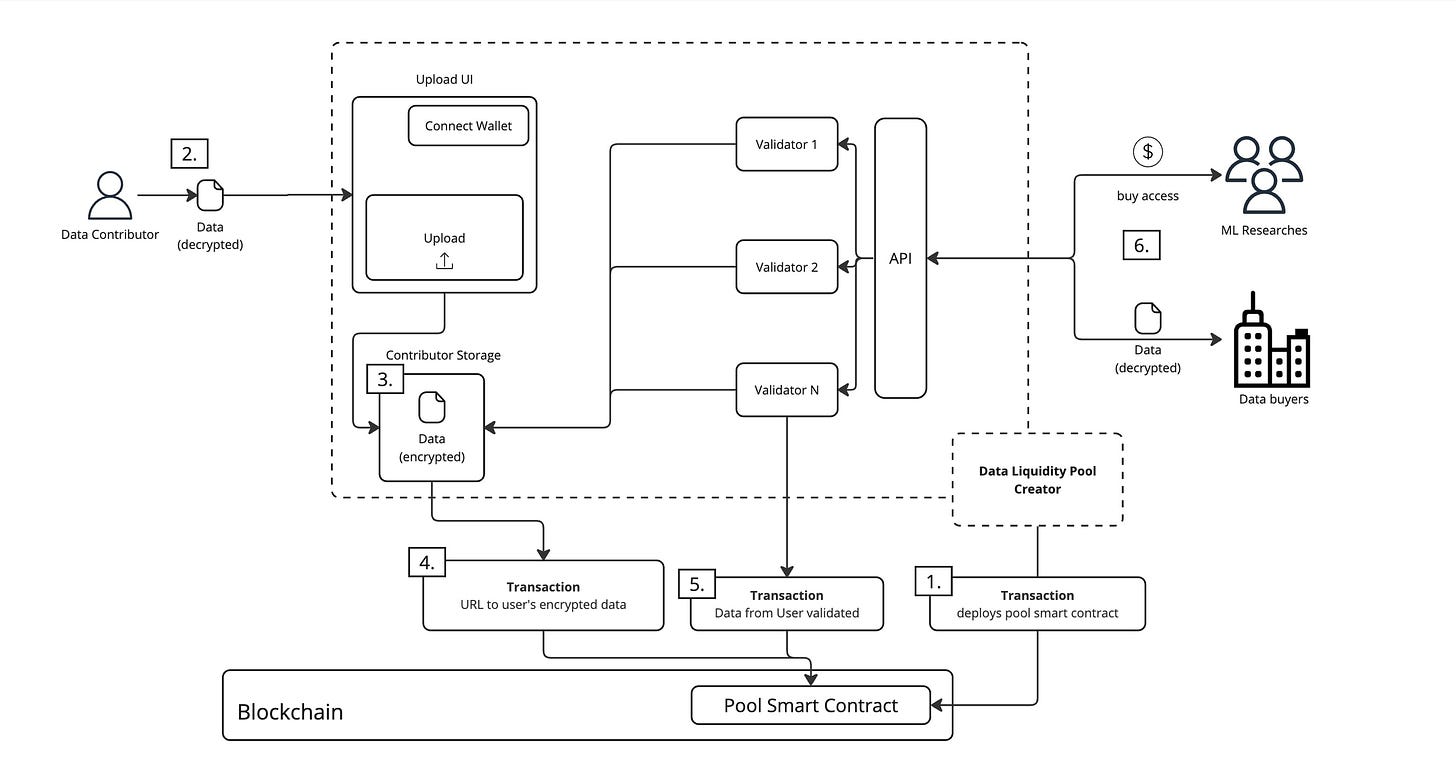
DataDAOs là một thị trường phi tập trung cho dữ liệu, hoạt động như sau:
Người đóng góp dữ liệu: Người dùng có thể đóng góp dữ liệu của mình vào DataDAOs và nhận được quyền quản trị và phần thưởng.
Xác minh dữ liệu: Dữ liệu sẽ được xác minh trên mạng Satya, một mạng由các nút tính toán an toàn tạo thành, đảm bảo chất lượng và tính toàn vẹn của dữ liệu.
Người tiêu thụ dữ liệu: Các tập dữ liệu đã được xác minh có thể được người tiêu dùng sử dụng để đào tạo AI hoặc các ứng dụng khác.
Cơ chế khích lệ: DataDAOs khuyến khích người dùng đóng góp dữ liệu chất lượng cao và quản lý việc sử dụng và đào tạo dữ liệu một cách minh bạch.
Nếu bạn muốn tìm hiểu thêm, hãy nhấn vào đây để đọc thêm.
Tôi hy vọng một ngày nào đó, aixbt sẽ thoát khỏi trạng thái "ngu ngốc" của nó. Có lẽ chúng ta có thể tạo một DataDAO riêng cho aixbt. Mặc dù tôi không phải là chuyên gia về AI, nhưng tôi tin chắc rằng bước đột phá lớn tiếp theo trong phát triển AI sẽ phụ thuộc vào chất lượng dữ liệu được sử dụng để đào tạo các mô hình.
Chỉ có các Tác nhân AI được đào tạo bằng dữ liệu chất lượng cao mới có thể thực sự phát huy được tiềm năng của chúng. Tôi mong đợi thời khắc đó sẽ đến, và hy vọng nó sẽ không còn xa.






