

Một
Cùng ngày với việc Elon Musk công bố Grok3 được huấn luyện bằng 200.000 thẻ, hai bài báo cáo với hướng đi "ngược lại" với "phép màu" của ông Musk cũng được công bố trong cộng đồng công nghệ.
Trong danh sách tác giả của hai bài báo cáo này, mỗi bên đều có một cái tên quen thuộc:
Lương Văn Phong, Dương Chí Lân.


Ngày 18 tháng 2, DeepSeek và Mặt Trăng Tối gần như đồng thời công bố các bài báo cáo mới nhất của họ, và chủ đề trực tiếp "va chạm" - đều là thách thức cơ chế chú ý, lõi của kiến trúc Transformer, để nó có thể xử lý hiệu quả hơn các ngữ cảnh dài hơn. Và điều thú vị hơn là, những ngôi sao kỹ thuật nổi tiếng, những người sáng lập của hai công ty này, đều xuất hiện trong các bài báo cáo và báo cáo kỹ thuật của riêng họ.
Bài báo cáo được công bố bởi DeepSeek có tựa đề: "Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention".
Theo bài báo cáo, kiến trúc mới NSA (Chú ý thưa bản địa) mà họ đề xuất, trong các bài kiểm tra chuẩn, so với cơ chế chú ý đầy đủ, có độ chính xác tương tự hoặc cao hơn; khi xử lý chuỗi 64k token, tốc độ có thể tăng lên 11,6 lần, huấn luyện cũng hiệu quả hơn, cần ít tính toán hơn; và thể hiện xuất sắc trong các nhiệm vụ xử lý ngữ cảnh siêu dài (như tóm tắt sách, sinh mã, nhiệm vụ suy luận).
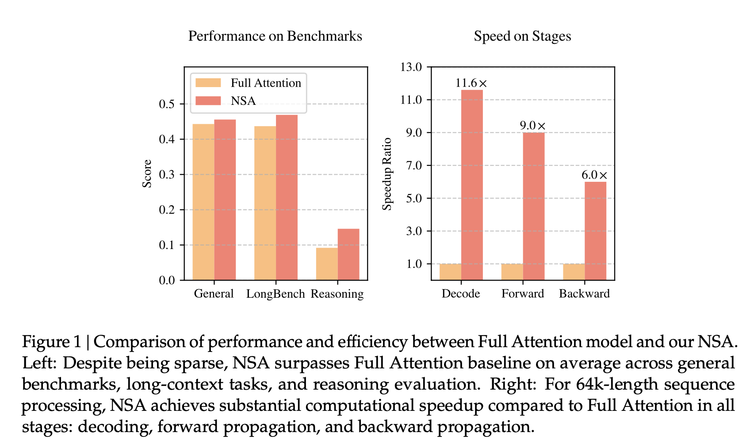
So với những đổi mới về thuật toán mà mọi người vẫn thường ca ngợi, lần này DeepSeek đã đưa tay vào cải tạo cơ chế chú ý (attention) cốt lõi.
Transformer là nền tảng cho sự phát triển của tất cả các mô hình lớn ngày nay, nhưng thuật toán cốt lõi của nó, cơ chế chú ý, vẫn còn những vấn đề bẩm sinh: lấy đọc sách làm ví dụ, "cơ chế chú ý đầy đủ" truyền thống, để hiểu và tạo ra, sẽ đọc mỗi từ trong văn bản và so sánh nó với tất cả các từ khác. Điều này khiến cho việc xử lý văn bản càng dài càng phức tạp, kỹ thuật càng bị nghẽn, thậm chí bị sụp đổ.
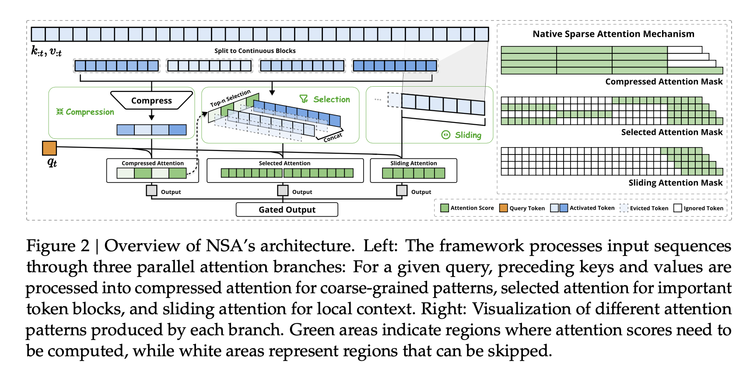
Trước đây, giới học thuật luôn cung cấp các hướng giải quyết, NSA thông qua tối ưu hóa kỹ thuật và thực nghiệm trong môi trường thực tế, đã tạo ra một kiến trúc gồm ba bước có thể sử dụng trong giai đoạn huấn luyện:
Nó bao gồm, 1) Nén ngữ nghĩa - không còn nhìn từng từ, mà chia thành một nhóm, tức là "Block", vừa giữ được ngữ nghĩa toàn cục vừa giảm chiều dài chuỗi xuống 1/k, đồng thời giới thiệu mã hóa vị trí để giảm thiểu mất mát thông tin, từ đó giảm độ phức tạp tính toán từ O(n²) xuống O(n²/k).
2) Lựa chọn động - mô hình dựa trên một cơ chế chấm điểm nào đó, chọn ra những từ quan trọng nhất trong văn bản để tính toán chi tiết. Chiến lược lấy mẫu quan trọng này có thể giảm 75% lượng tính toán mà vẫn duy trì 98% thông tin chi tiết.
3) Cửa sổ trượt - nếu như hai điểm trên là tóm tắt và nhấn mạnh, thì cửa sổ trượt là xem xét thông tin ngữ cảnh gần đây, để duy trì tính liên tục, và thông qua kỹ thuật tái sử dụng bộ nhớ cấp phần cứng có thể giảm 40% tần suất truy cập bộ nhớ.
Mỗi ý tưởng trong số này không phải là phát minh của DeepSeek, nhưng có thể tưởng tượng nó như một công việc kiểu ASML - những yếu tố kỹ thuật này đã tồn tại, rải rác ở khắp nơi, nhưng kỹ thuật là kết hợp chúng thành một giải pháp có thể mở rộng quy mô, một kiến trúc thuật toán mới, chưa ai làm trước. Bây giờ có người thông qua năng lực kỹ thuật mạnh mẽ đã tạo ra một "máy quang khắc", để mọi người có thể sử dụng nó để huấn luyện mô hình trong môi trường công nghiệp thực tế.
Còn Mặt Trăng Tối trong bài báo cáo công bố cùng ngày, đề xuất một kiến trúc rất nhất quán về mặt ý tưởng cốt lõi: MoBA. (MoBA: MIXTURE OF BLOCK ATTENTION FOR LONG-CONTEXT LLMS)
Từ tên của nó, có thể thấy nó cũng sử dụng phương pháp chia "từ" thành "Block". Sau khi "chia Block", MoBA có một mạng lưới kiểm soát giống như một "nhân viên sàng lọc thông minh", nó chịu trách nhiệm chọn ra Top-K Block liên quan nhất với một "Block", chỉ tính toán chú ý cho những Block được chọn này. Trong quá trình thực hiện, MoBA còn kết hợp các biện pháp tối ưu hóa như FlashAttention (làm cho tính toán chú ý hiệu quả hơn) và MoE (mô hình hỗn hợp chuyên gia).
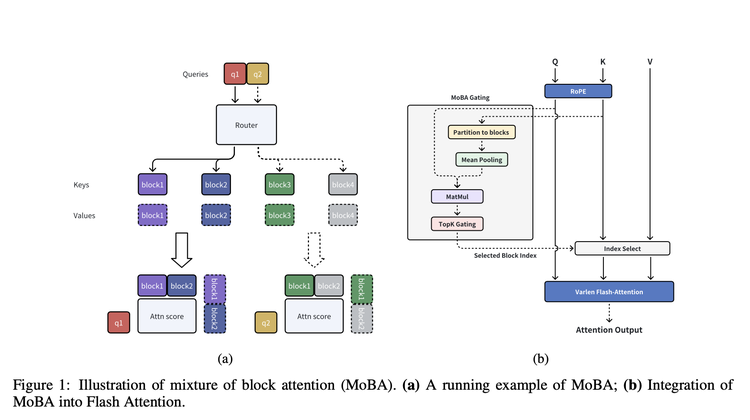
So với NSA, nó nhấn mạnh hơn vào tính linh hoạt, không hoàn toàn rời khỏi cơ chế chú ý đầy đủ phổ biến nhất hiện nay, mà thiết kế một cách chuyển đổi tự do, cho phép các mô hình này có thể chuyển đổi giữa cơ chế chú ý đầy đủ và cơ chế chú ý thưa, cung cấp thêm không gian thích ứng cho các mô hình chú ý đầy đủ hiện có.
Theo bài báo cáo, độ phức tạp tính toán của MoBA có ưu thế rõ rệt khi độ dài ngữ cảnh tăng lên. Trong kiểm tra 1M token, MoBA nhanh hơn cơ chế chú ý đầy đủ 6,5 lần; đến 10M token, thì tăng tốc 16 lần. Hơn nữa, nó đã được sử dụng trong sản phẩm của Kimi để xử lý nhu cầu xử lý ngữ cảnh siêu dài của người dùng hàng ngày.
Một trong những lý do quan trọng khiến Dương Chí Lân được chú ý khi thành lập Mặt Trăng Tối là ảnh hưởng và số lượng trích dẫn của các bài báo cáo của ông, nhưng trước K1.5, bài báo cáo cuối cùng của ông dừng lại vào tháng 1 năm 2024. Còn Lương Văn Phong, mặc dù xuất hiện với tư cách tác giả trong báo cáo kỹ thuật quan trọng nhất của DeepSeek, nhưng danh sách tác giả của những báo cáo này gần như tương đương với danh sách nhân viên của DeepSeek, hầu hết mọi người đều được liệt kê. Trong khi đó, tác giả của bài báo cáo NSA chỉ có vài người. Điều này cho thấy tầm quan trọng của hai công việc này đối với các nhà sáng lập của hai công ty, và ý nghĩa của việc hiểu rõ hướng đi kỹ thuật của hai công ty này.
Một chi tiết khác có thể làm nổi bật tầm quan trọng này là, một số người dùng đã phát hiện rằng hồ sơ nộp bài báo cáo NSA trên arxiv cho thấy, nó được nộp vào ngày 16 tháng 2, và người nộp chính là Lương Văn Phong.

Hai
Đây không phải lần đầu tiên Mặt Trăng Tối và DeepSeek "va chạm". Cùng với việc R1 được công bố, Kimi đã hiếm khi công bố báo cáo kỹ thuật K1.5, trước đây công ty này không ưu tiên trình bày các suy nghĩ kỹ thuật của mình. Lúc đó, hai bài báo cáo này cùng nhắm vào các mô hình suy luận được thúc đẩy bởi RL. Thực ra, nếu đọc kỹ hai báo cáo kỹ thuật này, trong bài báo cáo K1.5 của Mặt Trăng Tối, họ đã chia sẻ chi tiết hơn về cách huấn luyện một mô hình suy luận, thậm chí về mức độ thông tin và chi tiết, nó còn vượt trội hơn bài báo cáo R1. Nhưng sau đó, làn sóng DeepSeek đã che mờ một số thảo luận về bài báo cáo này.
Một điểm có thể làm bằng chứng là, gần đây OpenAI hiếm khi công bố một bài báo cáo giải thích về khả năng suy luận của các mô hình o của họ, đồng thời đề cập đến tên của DeepSeek-R1 và Kimi k1.5. "DeepSeek-R1 và Kimi k1.5 thông qua nghiên cứu độc lập cho thấy, sử dụng phương pháp học chuỗi suy luận (COT), có thể cải thiện đáng kể hiệu suất tổng thể của mô hình trong các thách thức toán học và lập trình." Tức là, đây là hai mô hình suy luận mà OpenAI tự chọn để so sánh.

"Điều kỳ diệu nhất của kiến trúc mô hình lớn này, theo cảm nhận của tôi, là nó dường như tự chỉ ra hướng tiến lên, khiến những người khác từ những góc độ khác nhau đưa ra những hướng tiến tương tự."
Giáo sư Chương Minh Tinh từ Đại học Thanh Hoa, người tham gia nghiên cứu cốt lõi của MoBa, chia sẻ trên Zhihu.
Ông cũng cung cấp một so sánh rất thú vị.
"DeepSeek R1 và Kimi K1.5 đều hướng tới ORM dựa trên RL, nhưng R1 bắt đầu từ Zero, "tinh khiết" hơn ho
Hiện nay, DeepSeek có ảnh hưởng lâu dài hơn các đối thủ khác đối với Mặt Trăng, nó mang lại thách thức toàn diện từ lộ trình công nghệ đến tranh giành người dùng: một mặt, nó chứng minh rằng ngay cả khi cạnh tranh về sản phẩm, khả năng mô hình cơ bản vẫn là quan trọng nhất; mặt khác, một phản ứng dây chuyền ngày càng rõ ràng là sự kết hợp giữa tìm kiếm WeChat của Tencent và Yuanbao, đang sử dụng đà của DeepSeek R1 để bù đắp một chiến dịch tiếp thị mà họ đã bỏ lỡ trước đó, cuối cùng cũng nhắm đến Kimi và Douban.
Cách tiếp cận để đối phó với Mặt Trăng cũng trở nên đáng chú ý. Trong đó, mã nguồn mở là một bước cần phải thực hiện. Và nhìn vào, lựa chọn của Mặt Trăng dường như là muốn thực sự phù hợp với triết lý mã nguồn mở của DeepSeek - hầu hết các dự án mã nguồn mở mới xuất hiện sau DeepSeek dường như chỉ là phản ứng bản năng, họ vẫn đang sử dụng triết lý mã nguồn mở từ thời kỳ Llama trước đây để theo dõi. Trên thực tế, mã nguồn mở của DeepSeek đã khác với trước đây, không còn là mã nguồn mở kiểu phòng thủ làm rối đối thủ như Llama, mà là một chiến lược cạnh tranh mang lại lợi ích rõ ràng.
Gần đây, Mặt Trăng được cho là đã đưa ra mục tiêu "lấy kết quả SOTA (state-of-the-art) làm mục tiêu", điều này dường như là chiến lược gần nhất với mô hình mã nguồn mở mới này, sẽ mở ra mô hình và phương pháp kiến trúc mạnh nhất, điều này sẽ mang lại ảnh hưởng mà nó luôn khao khát trong lĩnh vực ứng dụng.
Dựa trên các bài báo của cả hai bên, MoBA đã được sử dụng trong các mô hình và sản phẩm của Mặt Trăng, NSA cũng vậy, thậm chí nó cho phép bên ngoài có thể dự đoán rõ ràng hơn về các mô hình tiếp theo của DeepSeek. Vì vậy, điểm đáng chú ý tiếp theo là, liệu Mặt Trăng và DeepSeek sẽ huấn luyện ra các mô hình thế hệ tiếp theo bằng MoBA và NSA của riêng họ, rồi lại "đâm xe" vào nhau, và lần này sẽ là bằng cách mã nguồn mở - đây có thể là điểm mà Mặt Trăng đang chờ đợi.




