

Tác giả:Pavel Paramonov
Biên dịch: TechFlow
Gần đây, nhà sáng lập của Curve Finance @newmichwill đã tweet rằng mục đích chính của tiền điện tử là DeFi (Tài chính phi tập trung), và AI (Trí tuệ nhân tạo) không cần tiền điện tử. Mặc dù tôi đồng ý rằng DeFi là một phần quan trọng của lĩnh vực tiền điện tử, nhưng tôi không đồng ý với quan điểm rằng AI không cần tiền điện tử.
Với sự xuất hiện của các đại lý AI (AI agents), nhiều đại lý thường đi kèm với một token, điều này khiến mọi người lầm tưởng rằng sự giao nhau giữa tiền điện tử và AI chỉ là những đại lý AI này. Một chủ đề quan trọng khác bị bỏ qua là "AI phi tập trung", điều này liên quan mật thiết đến việc huấn luyện chính các mô hình AI.
Điều khiến tôi không hài lòng với một số câu chuyện là hầu hết người dùng sẽ mù quáng tin rằng một cái gì đó đang trở nên phổ biến thì nó nhất định quan trọng và hữu ích, thậm chí tệ hơn, họ tin rằng mục tiêu duy nhất của những câu chuyện này là khai thác giá trị tối đa (tức là kiếm tiền).
Khi thảo luận về AI phi tập trung, chúng ta trước tiên nên tự hỏi: Tại sao AI lại cần phi tập trung? Và điều này sẽ dẫn đến những hậu quả gì?
Thực tế cho thấy, ý tưởng về sự phi tập trung gần như luôn gắn liền với khái niệm "căn chỉnh cơ chế khuyến khích".
Trong lĩnh vực AI, có nhiều vấn đề cơ bản có thể được giải quyết bằng công nghệ mã hóa, và thậm chí còn có một số cơ chế không chỉ có thể giải quyết các vấn đề hiện có mà còn có thể tăng thêm độ tin cậy cho AI.
Vậy tại sao AI lại cần tiền điện tử?
1. Chi phí tính toán đắt đỏ hạn chế sự tham gia và đổi mới
Dù may hay không may, các mô hình AI quy mô lớn cần rất nhiều tài nguyên tính toán, điều này tự nhiên hạn chế sự tham gia của nhiều người dùng tiềm năng. Hầu hết các trường hợp, các mô hình AI yêu cầu lượng dữ liệu khổng lồ và khả năng tính toán thực tế, những thứ này gần như không thể đáp ứng được bởi một cá nhân.
Vấn đề này đặc biệt rõ ràng trong phát triển mã nguồn mở. Những người đóng góp không chỉ phải đầu tư thời gian để huấn luyện mô hình, mà còn phải đầu tư tài nguyên tính toán, điều này khiến hiệu quả phát triển mã nguồn mở bị giảm sút.
Quả thực, cá nhân có thể đầu tư nhiều tài nguyên để chạy các mô hình AI, giống như người dùng có thể cung cấp tài nguyên tính toán để chạy nút blockchain của riêng họ.
Tuy nhiên, điều này không thể giải quyết triệt để vấn đề, vì sức mạnh tính toán vẫn chưa đủ để hoàn thành các nhiệm vụ liên quan.
Các nhà phát triển độc lập hoặc nhà nghiên cứu không thể tham gia vào việc phát triển các mô hình AI quy mô lớn như LLaMA, chỉ vì họ không thể đáp ứng được chi phí tính toán cần thiết để huấn luyện các mô hình này: hàng nghìn GPU, trung tâm dữ liệu và cơ sở hạ tầng bổ sung.
Dưới đây là một số dữ liệu về quy mô:
→ Elon Musk cho biết, mô hình Grok 3 mới nhất đã sử dụng 100.000 GPU Nvidia H100 để huấn luyện.
→ Giá trị của mỗi chip khoảng 30.000 USD.
→ Tổng chi phí cho các chip AI dùng để huấn luyện Grok 3 khoảng 3 tỷ USD.
Vấn đề này có phần tương tự như quá trình xây dựng một công ty khởi nghiệp, cá nhân có thể có thời gian, kỹ năng kỹ thuật và kế hoạch thực hiện, nhưng ban đầu lại thiếu đủ nguồn lực để hiện thực hóa tầm nhìn của họ.
Như @dbarabander đã chỉ ra, các dự án phần mềm nguồn mở truyền thống chỉ cần những người đóng góp tặng thời gian, trong khi các dự án AI nguồn mở lại cần cả thời gian và lượng tài nguyên lớn, chẳng hạn như sức mạnh tính toán và dữ liệu.
Chỉ dựa vào thiện chí và nỗ lực tình nguyện không đủ để thúc đẩy đủ số cá nhân hoặc nhóm cung cấp những tài nguyên đắt đỏ này. Cần có các cơ chế khuyến khích bổ sung để thúc đẩy sự tham gia.
2. Công nghệ mã hóa là công cụ tốt nhất để đạt được sự căn chỉnh khuyến khích
Sự căn chỉnh khuyến khích (Incentive Alignment) có nghĩa là thiết lập các quy tắc để khuyến khích những người tham gia đóng góp vào hệ thống đồng thời cũng có thể thu được lợi ích cho chính họ.
Công nghệ mã hóa đã có vô số trường hợp thành công trong việc giúp các hệ thống khác nhau đạt được sự căn chỉnh khuyến khích, và một ví dụ nổi bật nhất là ngành công nghiệp mạng lưới cơ sở hạ tầng vật lý phi tập trung (DePIN), nó hoàn toàn phù hợp với ý tưởng này.
Ví dụ, các dự án như @helium và @rendernetwork đã thành công trong việc đạt được sự căn chỉnh khuyến khích thông qua mạng lưới nút phân tán và GPU, trở thành những ví dụ điển hình.
Vậy tại sao chúng ta không thể áp dụng mô hình này vào lĩnh vực AI, để hệ sinh thái của nó trở nên mở hơn và dễ tiếp cận hơn?
Thực tế, chúng ta có thể làm được điều đó.
Cốt lõi của việc thúc đẩy sự phát triển của Web3 và công nghệ mã hóa là "quyền sở hữu".
Bạn sở hữu dữ liệu của mình, bạn sở hữu cơ chế khuyến khích của mình, thậm chí khi bạn nắm giữ một số token, bạn cũng sở hữu một phần của mạng lưới. Trao quyền sở hữu cho những người cung cấp tài nguyên có thể khuyến khích họ cung cấp tài sản của mình cho dự án, với kỳ vọng được hưởng lợi từ thành công của mạng lưới.
Để AI trở nên phổ biến hơn, công nghệ mã hóa là giải pháp tối ưu. Các nhà phát triển có thể tự do chia sẻ thiết kế mô hình giữa các dự án, trong khi những người cung cấp tính toán và dữ liệu có thể đổi lấy phần sở hữu (khuyến khích) bằng cách cung cấp tài nguyên.
3. Sự căn chỉnh khuyến khích gắn liền chặt chẽ với tính xác minh
Nếu tưởng tượng một hệ thống AI phi tập trung với sự căn chỉnh khuyến khích thích hợp, nó nên kế thừa một số đặc điểm của các cơ chế blockchain cổ điển:
Hiệu ứng mạng lưới (Network Effects).
Yêu cầu ban đầu thấp, các nút có thể được thưởng bằng lợi nhuận trong tương lai.
Cơ chế trừng phạt (Slashing Mechanisms) để xử phạt những hành vi xấu.
Đặc biệt là đối với cơ chế trừng phạt, chúng ta cần tính xác minh. Nếu không thể xác minh ai là kẻ xấu, thì không thể trừng phạt họ, điều này sẽ khiến hệ thống dễ bị lợi dụng, đặc biệt là trong trường hợp hợp tác liên nhóm.
Trong hệ thống AI phi tập trung, tính xác minh là rất quan trọng, vì chúng ta không có một điểm tin cậy tập trung. Thay vào đó, chúng ta hướng tới một hệ thống không cần tin tưởng nhưng có thể xác minh. Dưới đây là một số thành phần có thể cần đến tính xác minh:
Giai đoạn Chuẩn mực (Benchmark Phase): Hệ thống vượt trội hơn các hệ thống khác trên một số chỉ số (như x, y, z).
Giai đoạn Suy luận (Inference Phase): Hệ thống chạy chính xác, tức là giai đoạn "suy nghĩ" của AI.
Giai đoạn Huấn luyện (Training Phase): Hệ thống được huấn luyện hoặc điều chỉnh chính xác.
Giai đoạn Dữ liệu (Data Phase): Hệ thống thu thập dữ liệu chính xác.
Hiện có hàng trăm nhóm đang xây dựng các dự án trên @eigenlayer, nhưng gần đây tôi nhận thấy sự quan tâm đến AI đã tăng lên so với trước, và tôi cũng đang suy nghĩ xem điều này có phù hợp với tầm nhìn ban đầu về reStaking của họ hay không.
Bất kỳ hệ thống AI nào nhằm đạt được sự căn chỉnh khuyến khích đều phải có tính xác minh.
Trong trường hợp này, cơ chế trừng phạt tương đương với tính xác minh: nếu một hệ thống phi tập trung có thể trừng phạt những kẻ xấu, điều đó có nghĩa là nó có thể nhận dạng và xác minh sự tồn tại của những hành vi xấu đó.
Nếu hệ thống có tính xác minh, thì AI có thể sử dụng công nghệ mã hóa để truy cập vào nguồn tài nguyên tính toán và dữ liệu toàn cầu, từ đó xây dựng các mô hình lớ
Đội ngũ Hyperbolic đã phát triển một thị trường GPU mở. Ở đây, người dùng có thể thuê GPU để đào tạo mô hình AI, tiết kiệm lên đến 75% chi phí, trong khi các nhà cung cấp GPU có thể chuyển đổi tài nguyên nhàn rỗi thành tiền, thu được lợi nhuận.
Sau đây là tổng quan về cách hoạt động của nó:
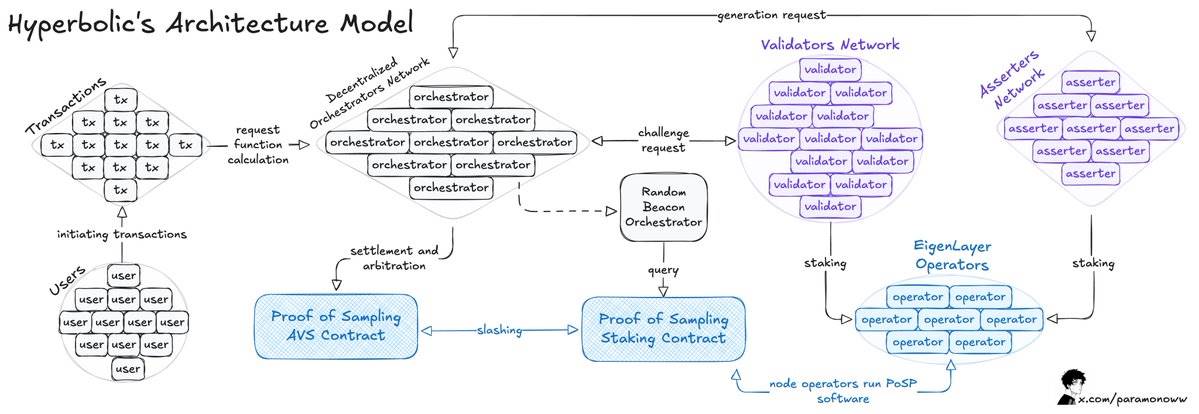
Hyperbolic tổ chức các GPU được kết nối thành các cụm và nút, cho phép khả năng tính toán có thể mở rộng theo nhu cầu.
Mô hình kiến trúc cốt lõi là mô hình "Bằng chứng lấy mẫu" (Proof of Sampling), đặc điểm là xử lý giao dịch thông qua lấy mẫu: bằng cách chọn và xác minh giao dịch ngẫu nhiên, nó giảm tải công việc và nhu cầu tính toán.
Vấn đề chính xuất hiện trong quá trình suy luận (Inference) của AI, mỗi lần suy luận chạy trên mạng đều cần được xác minh, và tốt nhất là nên tránh đáng kể chi phí tính toán do các cơ chế khác gây ra.
Như tôi đã nói trước đây, nếu một hành động có thể được xác minh, thì nếu kết quả xác minh cho thấy hành vi đó vi phạm các quy tắc, nó phải bị phạt (Slashing).
Khi Hyperbolic áp dụng mô hình AVS (Hệ thống Xác minh Thích ứng), nó đã thêm nhiều khả năng xác minh hơn cho hệ thống. Trong mô hình này, các nhà xác minh được chọn ngẫu nhiên để xác minh kết quả đầu ra, từ đó làm cho hệ thống đạt được sự căn chỉnh khích lệ - trong cơ chế này, hành vi không trung thực là không có lợi.
Để đào tạo một mô hình AI và làm cho nó hoàn thiện hơn, chủ yếu cần hai tài nguyên: khả năng tính toán và dữ liệu. Thuê khả năng tính toán là một giải pháp, nhưng chúng ta vẫn cần lấy dữ liệu từ đâu đó và cần đa dạng hóa dữ liệu để tránh các xu hướng có thể xảy ra trong mô hình.
Xác minh dữ liệu từ nhiều nguồn khác nhau cho AI
Nhiều dữ liệu hơn, mô hình tốt hơn; nhưng vấn đề là bạn thường cần dữ liệu đa dạng. Đây là một thách thức chính mà các mô hình AI phải đối mặt.
Các giao thức dữ liệu đã tồn tại hàng thập kỷ. Dù dữ liệu là công khai hay riêng tư, các môi giới dữ liệu vẫn thu thập dữ liệu theo một cách nào đó, có thể trả tiền hoặc không, sau đó bán chúng để thu lợi nhuận.
Các vấn đề chúng ta gặp phải khi thu thập dữ liệu phù hợp cho các mô hình AI bao gồm: điểm đơn lẻ thất bại, cơ chế kiểm duyệt, và thiếu một cách không cần tin tưởng để cung cấp dữ liệu thực sự đáng tin cậy để "nuôi dưỡng" các mô hình AI.
Vậy ai cần loại dữ liệu này?
Trước hết là các nhà nghiên cứu và nhà phát triển AI, họ muốn đào tạo và suy luận mô hình của họ bằng các đầu vào thực tế và phù hợp.
Ví dụ, OpenLayer cho phép bất kỳ ai thêm luồng dữ liệu vào hệ thống hoặc mô hình AI mà không cần cấp phép, và hệ thống có thể ghi lại mỗi dữ liệu có sẵn theo cách có thể xác minh.
OpenLayer cũng sử dụng zkTLS (Giao thức Bảo mật Lớp Truyền tải Zero-Knowledge), điều này đã được mô tả chi tiết trong bài viết trước của tôi. Giao thức này đảm bảo rằng dữ liệu được báo cáo bởi các nhà khai thác thực sự là những gì họ nhận được từ nguồn (có thể xác minh).
Đây là cách hoạt động của OpenLayer:
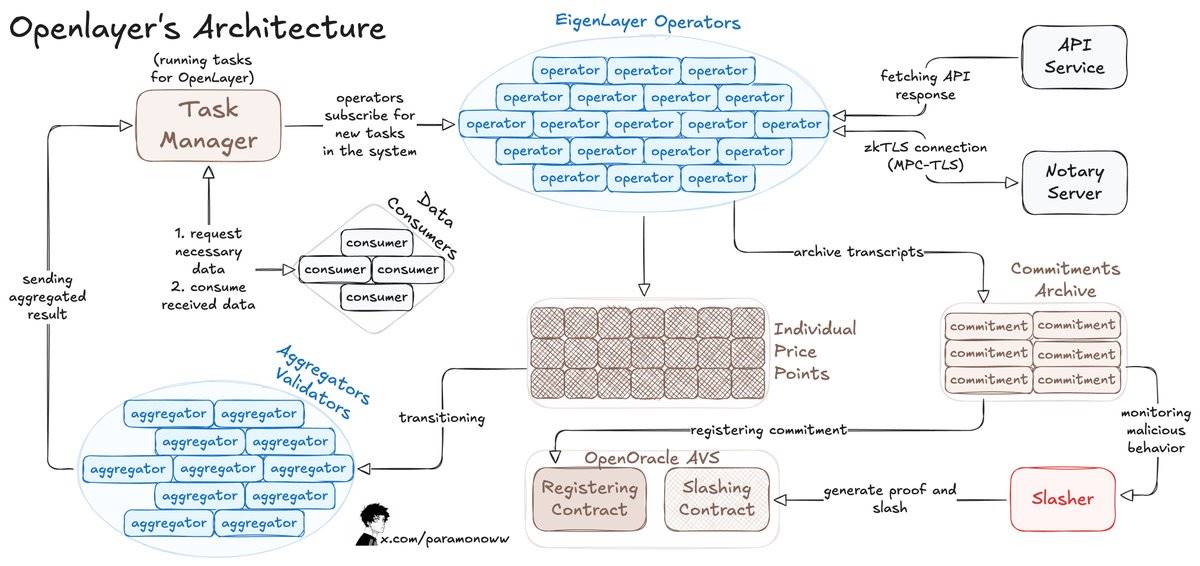
Người tiêu dùng dữ liệu gửi yêu cầu dữ liệu đến hợp đồng thông minh của OpenLayer và truy xuất kết quả thông qua hợp đồng (trên chuỗi hoặc ngoài chuỗi) sử dụng API tương tự như các oracle dữ liệu chính.
Các nhà khai thác đăng ký với EigenLayer để đảm bảo tài sản cầm cố của AVS của OpenLayer và chạy phần mềm AVS.
Các nhà khai thác đăng ký các nhiệm vụ, xử lý và gửi dữ liệu đến OpenLayer, đồng thời lưu trữ phản hồi gốc và bằng chứng trong lưu trữ phi tập trung.
Đối với kết quả thay đổi, các bộ tổng hợp (các nhà khai thác đặc biệt) sẽ chuẩn hóa đầu ra.
Các nhà phát triển có thể yêu cầu dữ liệu mới nhất từ bất kỳ trang web nào và tích hợp nó vào mạng. Nếu bạn đang phát triển một dự án liên quan đến AI, bạn có thể có được dữ liệu đáng tin cậy và thời gian thực.
Sau khi đã thảo luận về quá trình tính toán AI và cách thu thập dữ liệu có thể xác minh, tiếp theo chúng ta cần tập trung vào hai thành phần cốt lõi của mô hình AI: tính toán bản thân và xác minh nó.
Tính toán AI phải được xác minh để đảm bảo tính chính xác
Trong trường hợp lý tưởng, các nút phải chứng minh đóng góp tính toán của họ để đảm bảo hệ thống hoạt động bình thường.
Trong trường hợp tồi tệ nhất, các nút có thể giả vờ cung cấp khả năng tính toán nhưng thực sự không làm bất kỳ công việc thực tế nào.
Yêu cầu các nút chứng minh đóng góp của họ có thể đảm bảo chỉ những người tham gia hợp pháp mới được công nhận, từ đó tránh được hành vi xấu. Cơ chế này rất giống với Bằng chứng công việc (Proof of Work) truyền thống, khác biệt ở chỗ loại công việc mà các nút thực hiện.
Ngay cả khi chúng ta đưa vào hệ thống các cơ chế căn chỉnh khích lệ thích hợp, nếu các nút không thể chứng minh không cần cấp phép rằng họ đã hoàn thành một số công việc, họ có thể nhận được phần thưởng không tương xứng với đóng góp thực tế, thậm chí có thể dẫn đến phân bổ phần thưởng không công bằng.
Nếu mạng không thể đánh giá đóng góp tính toán, một số nút có thể được giao nhiệm vụ vượt quá khả năng của họ, trong khi các nút khác lại ở trạng thái nhàn rỗi, cuối cùng dẫn đến hiệu suất thấp hoặc sự cố hệ thống.
Bằng cách chứng minh đóng góp tính toán, mạng có thể sử dụng các chỉ số tiêu chuẩn (ví dụ: FLOPS, số lượng phép tính số dấu phẩy động trên mỗi giây) để định lượng nỗ lực của mỗi nút. Cách này có thể phân bổ phần thưởng dựa trên công việc thực tế hoàn thành, chứ không chỉ dựa trên việc nút có tồn tại trong mạng hay không.
Đội ngũ đến từ @HyperspaceAI đã phát triển một hệ thống "Bằng chứng FLOPS" (Proof-of-FLOPS), cho phép các nút cho thuê khả năng tính toán chưa sử dụng. Đổi lại, họ sẽ nhận được các điểm "flops", những điểm này sẽ trở thành tiền tệ chung của mạng.
Cách hoạt động của kiến trúc này như sau:
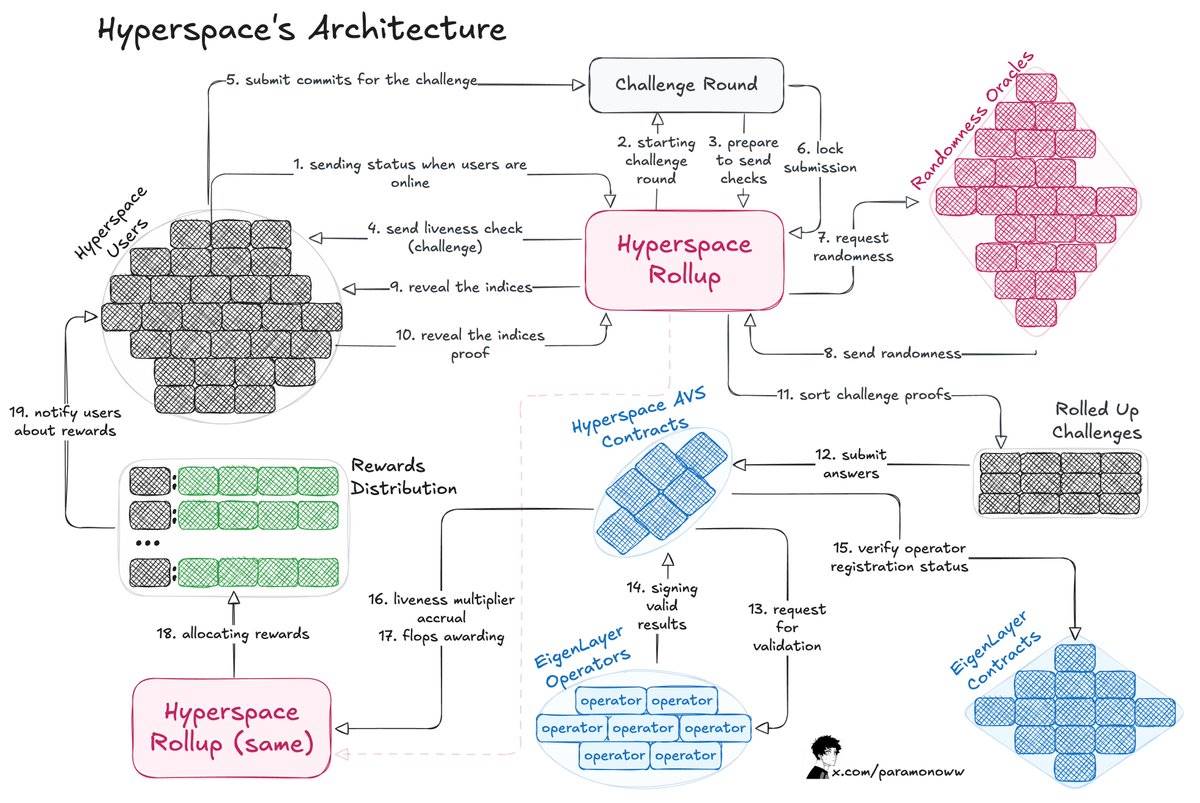
Quy trình bắt đầu bằng việc gửi thách thức cho người dùng, người dùng phản hồi bằng cách gửi cam kết về thách thức.
Hyperspace Rollup quản lý quy trình, đảm bảo tính an toàn của các gửi đi và lấy số ngẫu nhiên từ oracle.
Người dùng công khai chỉ số, hoàn thành quy trình thách thức.
Các nhà khai thác kiểm tra phản hồi và thông báo kết quả hợp lệ cho hợp đồng AVS của Hyperspace, sau đó xác nhận các kết quả này thông qua hợp đồng EigenLayer.
Tính toán bộ nhân hoạt động (Liveness Multipliers) và cấp điểm flops cho người dùng.
Chứng minh đóng góp tính toán cung cấp một bức tranh rõ ràng về khả năng của mỗi nút, do đó hệ thống có thể phân công nhiệm vụ một cách thông minh - giao các nhiệm vụ tính toán AI phức tạp cho các nút hiệu suất cao, trong khi giao các nhiệm vụ nhẹ hơn cho các nút có khả năng thấp hơn.
Phần thú vị nhất là làm thế nào để làm cho hệ thống này có thể xác minh, để bất kỳ ai cũng có thể chứng minh tính chính xác của công việc đã hoàn thành. Hệ thống AVS của Hyperspace liên tục gửi thách thức, yêu cầu số ngẫu nhiên và thực hiện quy trình xác minh nhiều lớp, như được minh họa trong sơ đồ kiến trúc đề cập ở trên.
Các nhà khai thác có thể tham gia hệ thống một cách an tâm vì kết quả đã được xác minh và phân bổ phần thưởng công bằng. Nếu kết quả không chính xác, những kẻ gian lận sẽ chắc chắn bị phạt (Slashing).
Có nhiều lý do quan trọng để xác minh kết quả tính toán AI:
Khuyến khích các nút tham gia và đóng góp tài nguyên.
Phân bổ phần thưởng một cách công bằng dựa trên nỗ lực.
Đảm bảo rằng các đóng góp trực tiếp hỗ trợ các mô hình AI cụ thể.
Phân công nhiệm vụ một cách hiệu quả dựa trên khả năng xác minh của các nút.
Phi tập trung và có thể xác minh của AI
Như



