Nếu bài luận này bị cắt bớt bởi máy khách email của bạn, bạn có thể đọc phiên bản trực tuyến tại đây . Ngoài ra, vui lòng đọc chú thích này: 1
GIỚI THIỆU
Dữ liệu là hào nước mới
Ngày càng có sự đồng thuận rằng dữ liệu không phải là dầu mỏ mới hay vàng mới; mà là thứ gì đó tốt hơn. Dữ liệu là hào nước mới.
Chúng ta đang ở giữa một cuộc tranh giành đất đai đáng chú ý trong lĩnh vực phần mềm. Các LLM đang thay đổi cách xây dựng phần mềm, mở ra những thị trường mới rộng lớn trước đây chưa được công nghệ khai thác (đặc biệt là trong dịch vụ) và khiến nhiều công ty đương nhiệm trông già nua. Đây là cơ hội cho các công ty nắm bắt thị phần và nhiều công ty khởi nghiệp đang làm chính xác điều đó.
Các công ty khởi nghiệp đi đầu trong làn sóng AI đang báo cáo tốc độ tăng trưởng chưa từng thấy trước đây. Bolt đã tăng lên 20 triệu đô la ARR trong 2 tháng; Cursor đã tăng từ 1 triệu đô la lên 100 triệu đô la ARR trong 21 tháng; OpenAI có doanh thu hàng tỷ đô la (và hãy nhớ rằng, GPT-3 đã được phát hành cách đây chưa đầy 5 năm). Có rất nhiều câu chuyện về sự tăng trưởng vượt bậc.
Cơ hội lớn; môi trường tuyệt vời. Công ty phải làm gì? Moats.
Một số hào nước được biết đến và yêu thích: hiệu ứng mạng, chi phí khóa người dùng và chuyển đổi, thương hiệu và định vị, sức mạnh quy trình, IP độc đáo, quy mô kinh tế. Những cái khác thì mơ hồ hoặc đáng ngờ. 2
Nhưng với sự ra đời của AI, một loại hào mới đã nổi lên: hào dữ liệu. Và đây không phải là sự trùng hợp ngẫu nhiên.
Các công ty AI có sự cộng hưởng đặc biệt với hào dữ liệu, vì dữ liệu và AI là hai mặt của một đồng xu. LLM đòi hỏi lượng dữ liệu khổng lồ để đào tạo, tinh chỉnh, học tập, lập luận. Và LLM mở khóa giá trị của dữ liệu như hầu như không có công nghệ nào trước đây. Đây là sự kết hợp hoàn hảo trong mô hình kinh doanh. 3
Tất cả các hào cũ vẫn còn hiệu lực — ví dụ như thương hiệu hoặc hiệu ứng mạng. Bạn có thể (và nên) xây dựng chúng. Nhưng chúng trực giao và độc lập với AI, theo cách mà hào dữ liệu không như vậy. Hào dữ liệu củng cố lợi thế của AI và lợi thế của AI củng cố hào dữ liệu.
Hào dữ liệu là gì?
Mọi người đều đang nói về cách xây dựng hào dữ liệu. Hào dữ liệu nằm trong không khí. 4
Thật không may, phần lớn cuộc trò chuyện này không được đặt đúng chỗ. Có rất nhiều suy nghĩ không đầy đủ, không nhất quán hoặc đơn giản là lỗi thời về hào dữ liệu và cách chúng hoạt động.
Những sai lầm kinh điển trong mạch này bao gồm việc nghĩ rằng dữ liệu là một hào nước khi nó không phải; phụ thuộc quá nhiều vào các hào nước dữ liệu yếu ; nhầm lẫn các hào nước khác (như quy mô) với hào nước dữ liệu; hiểu sai các thuộc tính nào của dữ liệu góp phần tạo nên “tính hào nước” của nó; không phân biệt được giữa hào nước phần mềm và hào nước dữ liệu; và không nhận ra khi nào hào nước dữ liệu mất hiệu quả. The Underpants Gnomes vẫn bất bại. 5
Sẽ có các nghiên cứu tình huống! Suy đoán tràn lan! Kết luận trái ngược với trực giác! Những cách diễn đạt khéo léo mà tôi hy vọng sẽ lan truyền! Và những lời bình luận mỉa mai! 6 Đọc tiếp.
Kiểm soát và vòng lặp
Chúng ta hãy bắt đầu với một số phân loại.
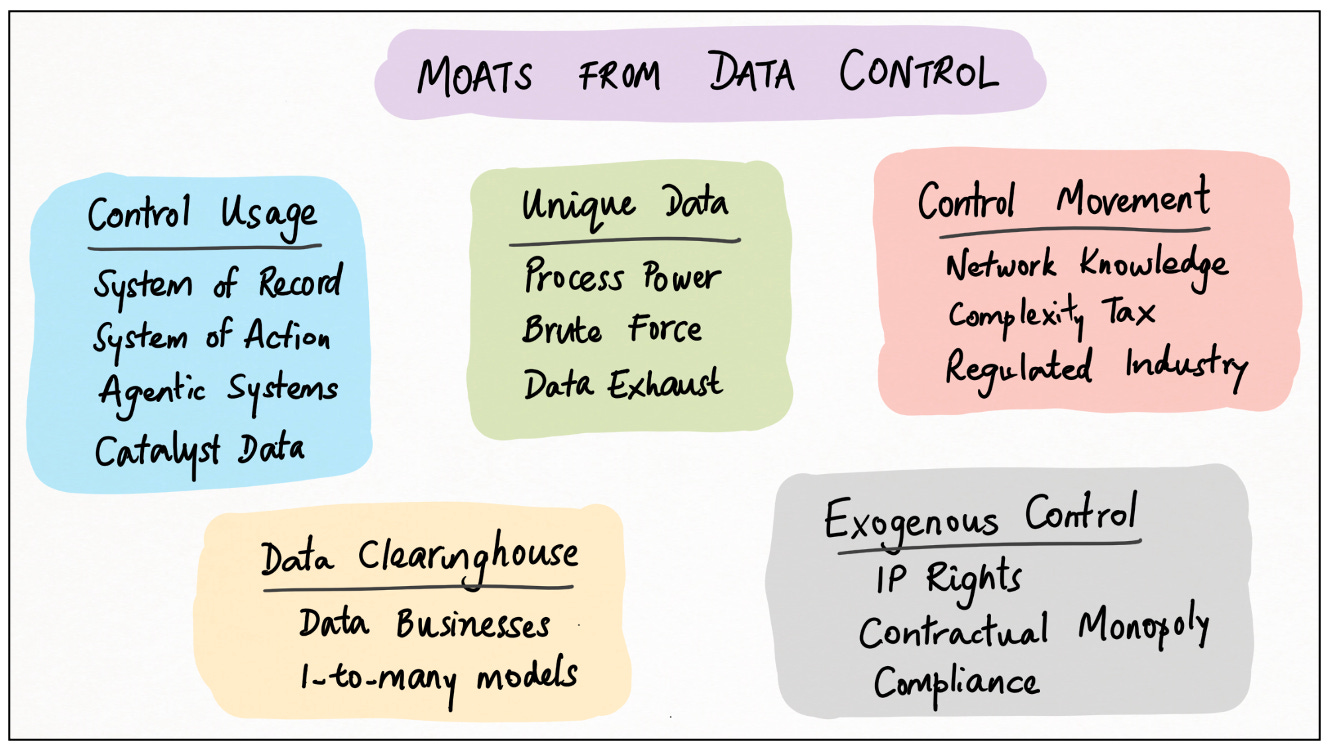
Tôi cho rằng có hai và chính xác là hai loại hào dữ liệu. Tôi gọi chúng là kiểm soát dữ liệu và vòng lặp dữ liệu ; mọi loại lợi thế dữ liệu đều có thể được đưa vào một hoặc cả hai loại này.
Kiểm soát dữ liệu. Nếu bạn có quyền kiểm soát duy nhất đối với một tài sản quan trọng, bạn có một hào nước. Trong thế giới dữ liệu, quyền kiểm soát này có nhiều dạng khác nhau: tính duy nhất, tổng hợp, di chuyển, sử dụng, hồ sơ, hành động, xúc tác và nhiều dạng khác. Chúng ta sẽ tìm hiểu về kiểm soát dữ liệu trong Phần một của bài luận này.
Vòng lặp dữ liệu. Nhiều hào kinh doanh nổi tiếng dựa vào vòng phản hồi tích cực 7 giúp tăng tốc một số động lực kinh doanh cốt lõi — ví dụ, lực hấp dẫn của thị trường, hiệu ứng mạng lưới người dùng, việc áp dụng giao thức. Một số hào dữ liệu thể hiện cùng một mô hình. Chúng ta sẽ tìm hiểu về vòng lặp dữ liệu trong Phần hai của bài tiểu luận này,
PHẦN MỘT: KIỂM SOÁT DỮ LIỆU
Kiểm soát dữ liệu thực sự có nghĩa là kiểm soát giá trị của dữ liệu; hào nước xuất hiện khi không ai khác có thể truy cập vào giá trị này.
Có một số cách để thực hiện điều này: bạn có thể kiểm soát việc sản xuất và sở hữu dữ liệu (duy nhất); bạn có thể kiểm soát việc di chuyển dữ liệu, cả bên trong lẫn bên ngoài; hoặc bạn có thể kiểm soát việc sử dụng dữ liệu, thông qua các phương tiện công nghệ hoặc các phương tiện khác. Tạo giá trị; vận chuyển giá trị; trích xuất giá trị: mỗi cách tiếp cận này đều có thể dẫn đến hào dữ liệu.
Điều kiện tiên quyết ở đây là dữ liệu được kiểm soát phải có ý nghĩa . Nếu không, “kiểm soát” là vô nghĩa: bạn không thể kiếm tiền từ phí cầu đường trên một con đường không dẫn đến đâu cả.
Dữ liệu độc quyền và duy nhất
Được rồi, vậy là bạn tạo ra, nắm bắt hoặc sở hữu dữ liệu độc đáo. Có thể dữ liệu đó là về cách sử dụng sản phẩm, hoặc hành vi của khách hàng, hoặc động lực của ngành, hoặc thứ gì đó khác. Bạn có hào không? Có lẽ là không.
Dữ liệu duy nhất không cần thiết cũng không đủ để thiết lập hào dữ liệu. Nó không cần thiết vì, như chúng ta sẽ thấy, có những phương pháp khác (thường tốt hơn): kiểm soát chuyển động hoặc sử dụng dữ liệu và xây dựng vòng lặp dữ liệu. Và nó không đủ, nhờ vào tiêu chí "có ý nghĩa" được đề cập ở trên. Tiêu chí này bao gồm những gì?
Dữ liệu phải cung cấp giá trị đáng kể cho bạn hoặc khách hàng của bạn. Một delta nhỏ về giá trị có nghĩa là bạn có thể bị vượt qua bởi một người nào đó vượt trội hơn bạn ở các mặt khác, ngay cả khi không có dữ liệu này; một delta lớn có nghĩa là bạn không thể.
Dữ liệu phải thực sự mang tính cạnh tranh . Việc bạn sử dụng dữ liệu này phải ngăn chặn người khác sử dụng dữ liệu này hoặc ít nhất là không nhận được cùng giá trị từ dữ liệu này.
Dữ liệu không được có sự thay thế chức năng . Các đối thủ cạnh tranh không thể đạt được kết quả tương tự bất kể họ sử dụng dữ liệu nào , tương tự hay không.
Hầu hết các tập dữ liệu thậm chí không đáp ứng được một trong những điều kiện này, chứ đừng nói đến cả ba. Nhưng nếu cả ba điều kiện đều được đáp ứng — nếu bạn có dữ liệu độc đáo, có giá trị cao, không thể thay thế mà chỉ bạn mới có thể sử dụng — thì bạn có thể có một hào nước. 8
Trong lịch sử, có một số cách để có được dữ liệu như vậy:
Là sản phẩm phụ của hoạt động kinh doanh cốt lõi của bạn. (Đôi khi được gọi là dữ liệu khí thải, tương tự như khí thải từ động cơ đốt trong). Một ví dụ điển hình ở đây là dữ liệu thị trường chứng khoán, được NYSE và NASDAQ thu thập như một sản phẩm phụ của hoạt động kinh doanh trao đổi cốt lõi của họ. Nhưng đây không phải là hào dữ liệu. Một hoạt động kinh doanh cốt lõi lớn hơn có thể tạo ra nhiều dữ liệu khí thải hơn (hoặc tốt hơn), nhưng ngược lại thì không đúng: Doanh số bán dữ liệu của NYSE không mang lại cho hoạt động kinh doanh trao đổi của họ bất kỳ khả năng phòng thủ "bổ sung" nào. 9
Qua sức mạnh của quy trình . Nhiều doanh nghiệp dữ liệu lâu đời tuân theo mẫu này. Hãy nghĩ đến dữ liệu báo cáo tài chính của Factset , hoặc dữ liệu xếp hạng của Moody , hoặc dữ liệu tiêu thụ phương tiện truyền thông của Nielsen : tất cả đều phụ thuộc vào nhiều thập kỷ kinh nghiệm làm việc với các tập dữ liệu cụ thể và nội bộ hóa tất cả các sắc thái của chúng. Đây là một hào nước; cho dù bạn muốn gọi nó là hào nước dữ liệu hay hào nước quy trình thì đó là vấn đề ngữ nghĩa.
Thông qua việc đầu tư thời gian và nguồn lực một cách thô bạo . Một số ví dụ về mô hình này bao gồm các công cụ tìm kiếm thu thập dữ liệu trên web, các công ty hậu cần và giao hàng lập bản đồ đường bộ và xe taxi robot ghi lại tương tác giữa người lái và môi trường. Trong mỗi trường hợp, các công ty thu thập dữ liệu trở thành nền tảng cho công nghệ của họ và do đó là mô hình kinh doanh của họ, mà những công ty khác không thể dễ dàng sao chép. Đây là những hào dữ liệu thực sự. Nhưng …
Brute Force đã chết ...
Lý thuyết kinh doanh đằng sau sức mạnh thô bạo là “chi phí đầu tư của tôi là rào cản gia nhập của bạn”. Các công ty dành thời gian và nguồn lực để thu thập dữ liệu trước khi đối thủ của họ làm điều đó và sử dụng dữ liệu đó để giành được sự thống trị thị trường.
Thật không may, cách này hiện nay không còn hiệu quả nữa:
LLM giúp việc thu thập dữ liệu dễ dàng hơn. Không chỉ dễ hơn một chút, mà dễ hơn gấp bội. Bạn không cần hàng trăm người quản lý làm việc hàng nghìn giờ, chỉ cần bảo một tác nhân AI đi lấy dữ liệu cho bạn. Các công ty đã dành nhiều năm xây dựng các đường ống dữ liệu phức tạp do con người làm trung gian giờ đây phải cạnh tranh với những công ty mới thành lập có thể sao chép 99% công việc của họ với 1% chi phí. Dữ liệu tổng hợp là một cách chạy trốn khác xung quanh các phương pháp tấn công brute-force. 10
Vốn cho việc thu thập dữ liệu rất rẻ. Thị trường tài trợ đã hoàn toàn tiếp thu “bài học cay đắng” và “hiệu quả vô lý của dữ liệu”. Do đó, vốn để tài trợ cho việc thu thập dữ liệu bằng vũ lực rẻ hơn bao giờ hết. Vũ lực cuối cùng là một canh bạc về thời điểm thị trường và chi phí vốn; thay đổi những điều đó, và chiến thuật sẽ tan biến. 11
Kiến thức lan tỏa, khả năng tăng lên. Cơ sở hạ tầng quy mô toàn cầu mà Google xây dựng vào những năm 2000, cho phép họ thu thập và lập chỉ mục toàn bộ internet một cách nhanh chóng , là một hào nước lớn đối với họ (mặc dù PageRank nhận được tất cả công lao). Ngày nay, có hàng chục công ty có thể làm như vậy và rẻ hơn nhiều. Kiến thức lan tỏa, các công cụ được cải thiện, các công ty siêu quy mô phục vụ mọi thứ có thể tính toán được và Định luật Moore tiến về phía trước một cách không thể tránh khỏi. Lợi thế của ngày hôm qua là hàng hóa của ngày hôm nay.
Sử dụng định nghĩa mở rộng về "dữ liệu" làm nổi bật hiệu ứng này. Studio Ghibli đã dành nhiều thập kỷ tỉ mỉ hoàn thiện phong cách hình ảnh tuyệt đẹp mà không studio hoạt hình nào khác có thể sao chép: bản chất của sức mạnh thô bạo để tạo ra nội dung độc đáo.
Và vào tháng trước, ChatGPT đã mở cửa cho bất kỳ ai cũng có thể sáng tạo tác phẩm nghệ thuật theo phong cách Ghibli.

... Sức mạnh vũ phu muôn năm!
Dữ liệu phân mảnh
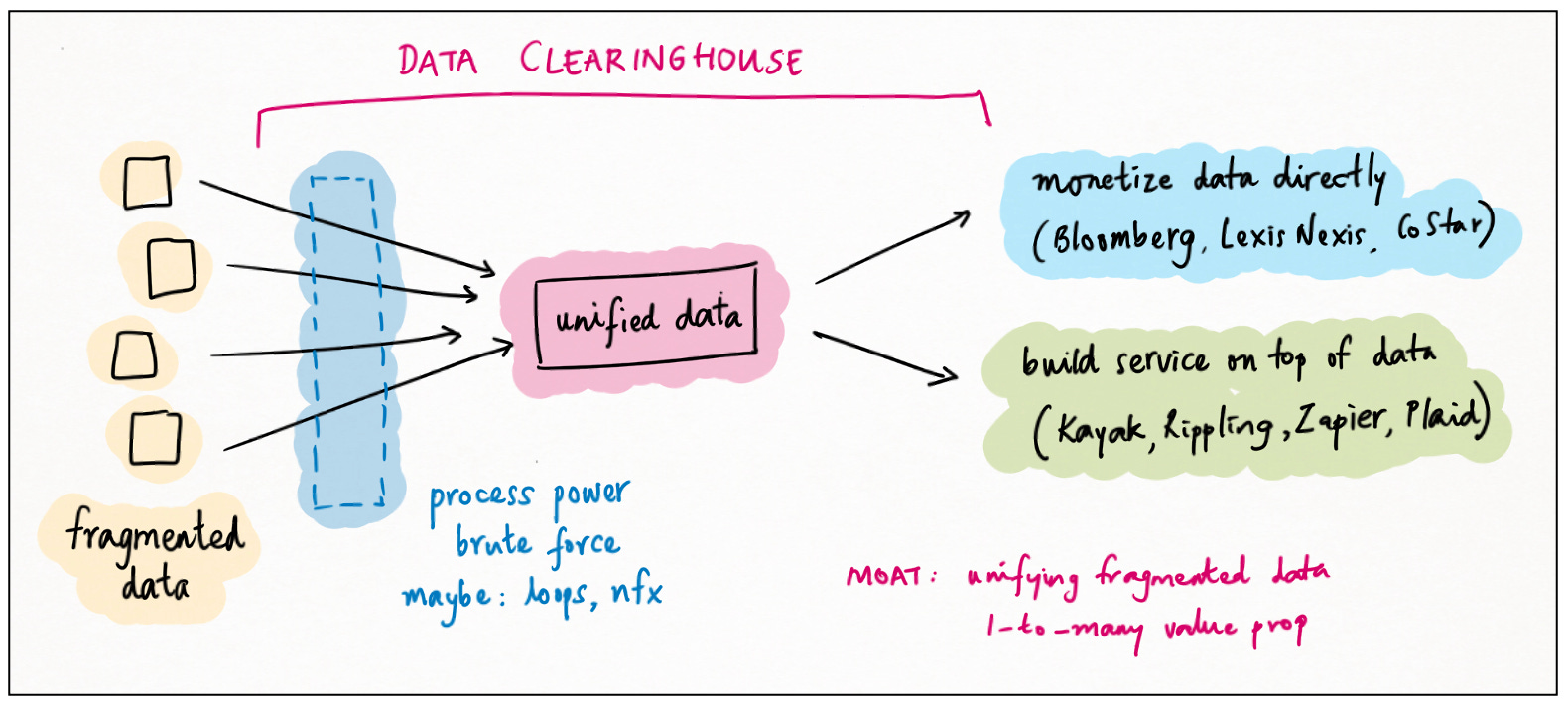
Thông tin tạo ra hành động
Về cơ bản, đây là dữ liệu làm nền tảng cho hành động . Các quy tắc và quy định phải được tuân thủ và chúng chủ yếu mang tính quyết định: chúng dẫn trực tiếp đến hành động. Thông tin chuyến bay vừa cần thiết vừa đủ cho hành động đặt vé; thông tin tình báo bán hàng cũng vậy để tiến hành tiếp cận. Thông tin tạo ra hành động. 12
Việc hợp nhất dữ liệu thực sự khó khăn, khiến nó trở thành một hào nước tốt. Và việc hợp nhất dữ liệu với một lớp hành động ở trên cùng thường đòi hỏi chuyên môn hóa miền, khiến nó thậm chí còn hào nước hơn.
Làm giàu doanh số cho thấy ranh giới thay đổi theo thời gian như thế nào. Sự tiến triển từ D&B đến Clearbit đến ZoomInfo đến Apollo đến Clay là câu chuyện về giá trị được nắm bắt từ việc thống nhất dữ liệu phân mảnh, làm cho nó có thể truy cập bằng API, khai thác hiệu ứng mạng, thêm quy trình làm việc và phân lớp trong các hành động AI.
Kiểm soát di chuyển dữ liệu
Đây là một phạm trù mơ hồ. Một phần là do ranh giới: di chuyển dữ liệu kết thúc ở đâu và sử dụng dữ liệu bắt đầu ở đâu? Và một phần là do sự chồng chéo: các công ty có loại kiểm soát này thường đạt được điều đó thông qua sự kết hợp của các chiến thuật, cả dữ liệu và phi dữ liệu. Hãy cùng xem một số ví dụ!
Visa có lẽ là công ty có hiệu ứng mạng lưới nổi tiếng nhất trong tất cả các doanh nghiệp 13. Một tuyên bố hấp dẫn (và có lẽ là khiêu khích) là hiệu ứng mạng lưới của họ phần lớn dựa trên việc kiểm soát chuyển động dữ liệu.
Hãy cân nhắc: khi tôi mua thứ gì đó bằng thẻ tín dụng, tiền thực sự không chảy. Thay vào đó, dữ liệu chảy : tên khách hàng và xác minh, thông tin chi tiết về giao dịch, hạn mức tín dụng, số dư chưa thanh toán, ID ngân hàng và thương gia, lịch trình thanh toán. Tiền chảy chậm hơn nhiều, và cũng không phải theo kiểu 1-1.
Mạng lưới Visa điều phối tất cả những điều này — trên toàn bộ người tiêu dùng, thương gia, cổng thanh toán, bộ xử lý thanh toán, ngân hàng thu mua, ngân hàng phát hành, v.v. Các nút và cạnh là hiệu ứng mạng; kiến thức (và quyền kiểm soát) của các nút và cạnh này là hào dữ liệu.
Bất kỳ doanh nghiệp trung gian nào cũng dễ bị mất vai trò trung gian. Trong trường hợp của Visa, các thương gia có thể giao tiếp trực tiếp với các ngân hàng để hỏi về điểm tín dụng của khách hàng. Nhưng họ không làm vậy! Visa kiểm soát tương tác đó. Visa kiểm soát hầu như mọi hoạt động di chuyển dữ liệu trên toàn mạng. Việc tách biệt sự phức tạp (to lớn) của mạng chính xác là điều thu hút những người tham gia và ngăn họ đào tẩu; theo một cách rất thực tế, kiểm soát dữ liệu là nền tảng của hiệu ứng mạng.
Amadeus và Sabre giống như Visa chuyên dụng cho ngành du lịch, kiểm soát luồng dữ liệu (hàng tồn kho, đặt chỗ, danh tính) giữa các hãng hàng không, khách sạn, dịch vụ cho thuê xe, đại lý du lịch và đơn vị tổng hợp, và tất nhiên là cả khách du lịch. Change Healthcare là Visa cho ngành chăm sóc sức khỏe, kiểm soát luồng dữ liệu (và thanh toán) giữa bệnh nhân, nhà cung cấp dịch vụ chăm sóc sức khỏe, công ty bảo hiểm và các chương trình thanh toán của chính phủ.
Các doanh nghiệp được xây dựng dựa trên việc kiểm soát việc di chuyển dữ liệu bên ngoài có lợi nhuận, nhưng hiếm. Phổ biến hơn là các doanh nghiệp quản lý luồng dữ liệu nội bộ cho khách hàng của họ. Họ có hào không?
Thông thường là không. Quản lý việc di chuyển dữ liệu không giống như kiểm soát nó. Di chuyển dữ liệu là công việc mà 99% các công cụ phần mềm thực hiện và hầu hết các công cụ như vậy rõ ràng là không có hào.
Ngoại lệ là luồng dữ liệu trong các ngành được quản lý chặt chẽ . Ví dụ, trong lĩnh vực chăm sóc sức khỏe, dữ liệu bệnh nhân rất nhạy cảm và bạn không thể tùy tiện truy cập hoặc di chuyển dữ liệu. Vì vậy, bạn có các công ty như Epic , chuyên quản lý quyền truy cập dữ liệu nội bộ (đây cũng là hiệu ứng hệ thống lưu trữ; xem bên dưới) và các công ty như Datavant , chuyên vận chuyển dữ liệu giữa các tổ chức trong khi vẫn đảm bảo an toàn và tuân thủ quyền riêng tư (thông qua hiệu ứng tiêu chuẩn dữ liệu; xem lại bên dưới). Không dễ để loại bỏ những công ty này: lợi ích hạn chế và bất lợi lớn, vì vậy hầu hết khách hàng sẽ trung thành thay vì thay đổi. 14
Sử dụng dữ liệu
Loại kiểm soát dữ liệu cuối cùng là mạnh nhất: khi bạn kiểm soát việc sử dụng dữ liệu. Đây là một tiểu thể loại lớn, bao gồm các hệ thống ghi chép và hành động, dữ liệu xúc tác và hào dữ liệu ngoại sinh.
Hệ thống ghi chép
Hệ thống ghi chép (“SoR”) là một trong những hào dữ liệu lâu đời nhất, nổi tiếng nhất và hiệu quả nhất.
Trong bất kỳ tổ chức lớn nào, thông tin đều bị phân tán. Thông tin nằm rải rác trên các tệp Excel và cơ sở dữ liệu, email và kênh Slack, PDF và deck, hướng dẫn sử dụng và sổ tay chính sách, hợp đồng và hồ sơ.
Có khả năng bảo vệ đáng kể khi sở hữu nền tảng tổng hợp tất cả thông tin phân tán này. Một nền tảng như vậy được gọi là "hệ thống lưu trữ" và mục tiêu là để nó trở thành "nguồn duy nhất của sự thật" cho tổ chức. Dữ liệu được truyền vào SoR; các truy vấn được gửi đến SoR; các câu trả lời đến từ SoR. Nếu nó nằm trong SoR, bạn có thể cho rằng nó đúng; nếu không, bạn không thể. 15
Ví dụ điển hình của SoR là Salesforce , nơi tập hợp mọi thứ mà doanh nghiệp cần biết về khách hàng và kênh bán hàng của họ: ngày tháng, thông tin liên hệ, lịch sử tương tác, giai đoạn kênh, giá trị mong đợi, tiến trình từ cơ hội đến chốt, chiến dịch tiếp thị, dịch vụ khách hàng và quản lý trường hợp, v.v. (nhiều hơn nữa). Toàn bộ tổ chức bán hàng chạy trên Salesforce; họ không thể hoạt động mà không có nó.
Salesforce có những phép loại suy trong các lĩnh vực khác. Thật vậy, điều này là điển hình đối với SoR. Thật không thực tế và không hiệu quả khi thống nhất tất cả dữ liệu của một tổ chức trong một SoR duy nhất; thay vào đó, có các SoR riêng biệt cho từng chức năng. Salesforce hướng đến chức năng bán hàng; Oracle thực hiện quản lý tài chính, Workday thực hiện nguồn nhân lực, Quickbooks thực hiện kế toán, Ariba thực hiện chuỗi cung ứng, v.v. Mỗi SoR này hoạt động như nguồn duy nhất của sự thật cho chức năng cụ thể của chúng. 16 17 18
Có thể thấy rõ điều này qua những năm thành lập của một số công ty SoR sau:
SAP: 1972
Tiên tri: 1977
Sử thi: 1979
Quickbooks: 1983
Ariba: 1996
Zoho: 1996
Lực lượng bán hàng: 1999
Thật đáng kinh ngạc. Đây là những doanh nghiệp tồn tại rất lâu — đặc biệt là với tốc độ thay đổi của phần mềm; họ hẳn phải có những hào kinh tế đáng kinh ngạc .
Tại sao SoR lại có độ bám dính cao như vậy?
Salesforce không phải là, chúng ta có thể nói, một sản phẩm được yêu thích rộng rãi. Không ai đam mê phiên bản Salesforce của họ. Nhưng họ không thể sống thiếu nó; Salesforce bám dính như địa ngục.
Tại sao vậy? Bởi vì Salesforce kiểm soát việc sử dụng dữ liệu . Nếu bạn cần dữ liệu "chính xác" về khách hàng tiềm năng và khách hàng của mình, bạn phải lấy dữ liệu từ Salesforce 19. Nếu không có Salesforce, bạn không thể làm bất cứ điều gì : bạn không thể gửi email cho khách hàng tiềm năng, cập nhật trạng thái của họ, hiểu nhu cầu của họ, chốt hợp đồng, hỗ trợ họ sau khi chốt, lập mô hình đường ống của bạn, chạy chiến dịch, bất cứ điều gì . Salesforce độc quyền dữ liệu bán hàng nội bộ của bạn.
Hơn nữa, vị trí đặc quyền này có nghĩa là hầu hết các phiên bản Salesforce đều có nhiều năm "sợi dây chuyền công việc" bám chặt vào chúng. Cả hai đều mang tính thủ tục: các quy tắc mà nhân viên bán hàng, tiếp thị và thành công của khách hàng phải tuân theo — và mang tính công nghệ: Salesforce có toàn bộ kho ứng dụng với các công cụ của bên thứ ba để đọc, viết, sửa đổi, trực quan hóa, trình bày và phân tích dữ liệu của mình.
Salesforce không tuyệt vời, nhưng nghĩ đến khối lượng công việc cần phải bỏ ra để trích xuất một phiên bản, xuất toàn bộ dữ liệu của nó, tải nó ở nơi khác, sao chép toàn bộ chức năng ứng dụng đó, chuyển đổi toàn bộ người dùng và quay lại luồng sản xuất đầy đủ, khiến hầu hết những người chuyển đổi đều cảm thấy sợ hãi. Và điều này đúng với hầu hết các SoR quy mô lớn, đó là lý do tại sao chúng được bảo vệ chặt chẽ như vậy. 20
Không còn dính nữa?
Và rồi đến LLM. Hóa ra việc xuất dữ liệu từ SoR chỉ là loại nhiệm vụ tẻ nhạt mà các tác nhân AI giỏi thực hiện.
Một trong những động thái đưa ra thị trường yêu thích của tôi trong những năm gần đây là nơi những người phá vỡ SoR tiềm năng đề nghị tự mình thực hiện tất cả công việc di chuyển: chúng tôi sẽ xuất dữ liệu, đưa vào hệ thống mới, thêm vào các móc ứng dụng mới, v.v. Hiểu biết sâu sắc chính ở đây là đây không phải là "rủi ro", mà chỉ là "chi phí" và các nhà cung cấp sẵn sàng trả chi phí đó để đổi lấy nhiều năm LTV.
Trớ trêu thay, có lẽ sẽ tốt hơn cho GTM này nếu chi phí không giảm quá nhiều. Khó khăn trong việc di chuyển SoR dẫn đến tỷ lệ churn thấp và LTV cao, điều này biện minh cho khoản đầu tư vào việc thực hiện công việc di chuyển với tư cách là nhà cung cấp — nhưng nếu chi phí di chuyển giảm quá nhiều, những người khác cũng có thể làm như vậy với bạn; churn sẽ tăng trở lại, nghĩa là LTV giảm và chẳng mấy chốc bạn sẽ phải chạy đua xuống đáy. Độ nhớt dữ liệu là bạn của bạn, cho đến khi nó không còn là bạn nữa.
Hệ thống hành động
Systems of Record có độc quyền về dữ liệu nội bộ. Việc kiểm soát này khiến chúng vừa có giá trị vừa có thể bảo vệ được. Nhưng nếu chúng có thể làm được nhiều hơn thì sao?
Rốt cuộc, giá trị của dữ liệu nằm ở giá trị của những gì có thể làm được với nó. Bạn không muốn SoR của mình là nơi dữ liệu chết 21 ; bạn muốn hành động dựa trên dữ liệu.
Suy nghĩ này dẫn đến loại hào dữ liệu tiếp theo, có lẽ còn mạnh mẽ hơn: Hệ thống hành động (“SoA”).
Hệ thống hành động không chỉ lưu trữ dữ liệu thụ động; chúng cho phép các hành động trên đó. Điểm mấu chốt và điều khiến SoA khác biệt so với SoR là mức độ cụ thể của các hành động này: mức độ lớp hành động gắn kết tốt với lớp dữ liệu và chức năng của người dùng.
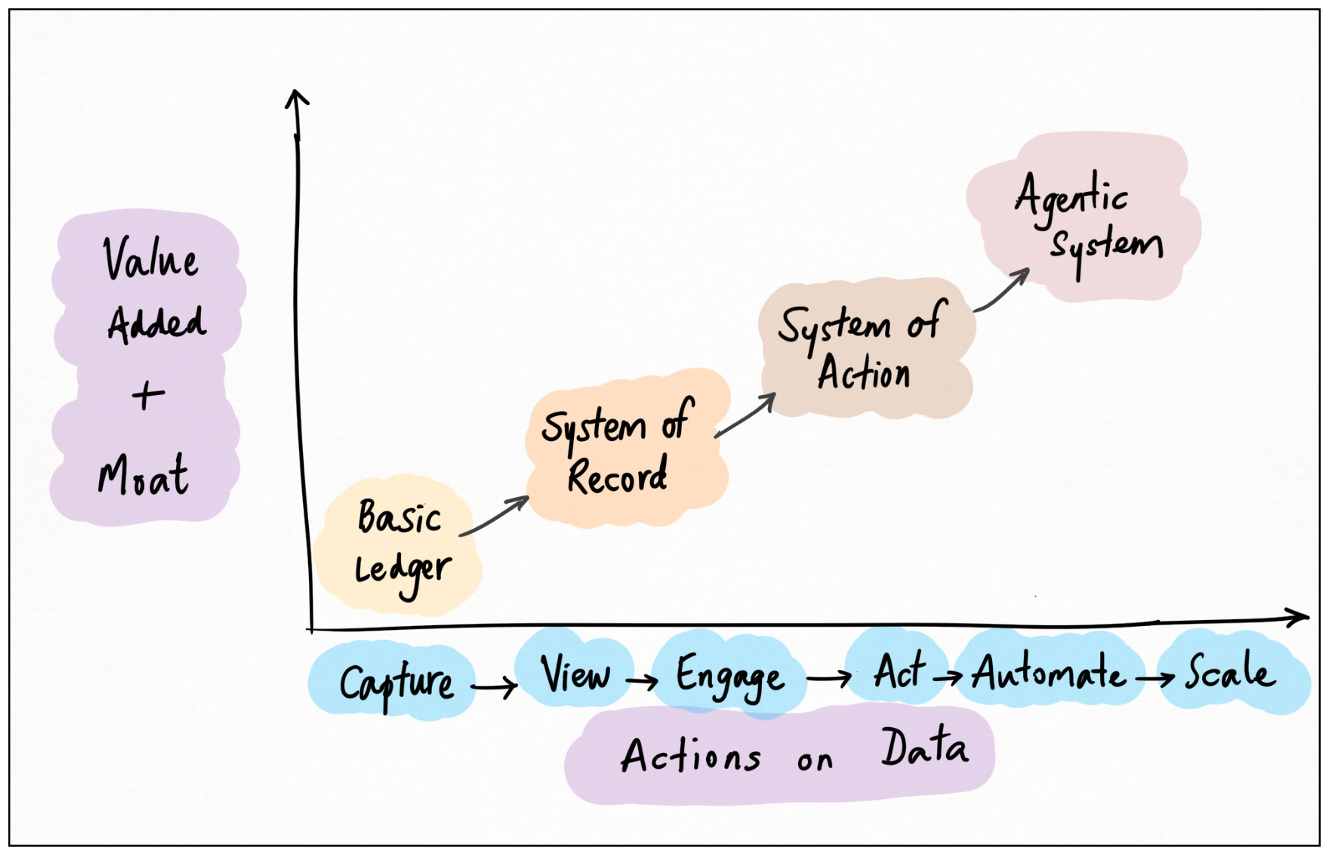
Hệ thống Agentic
Bước tiếp theo hiển nhiên là hệ thống sẽ tự hành động. Đợi đã... tôi đang nghe nhạc của ai thế?

Thực tế là những người có bằng LLM rất giỏi lập trình.
Cách tiếp cận nào sẽ chiến thắng? Đó là câu hỏi trị giá mười tỷ đô la 22. Tôi thích bản tóm tắt này về luận điểm phá vỡ:
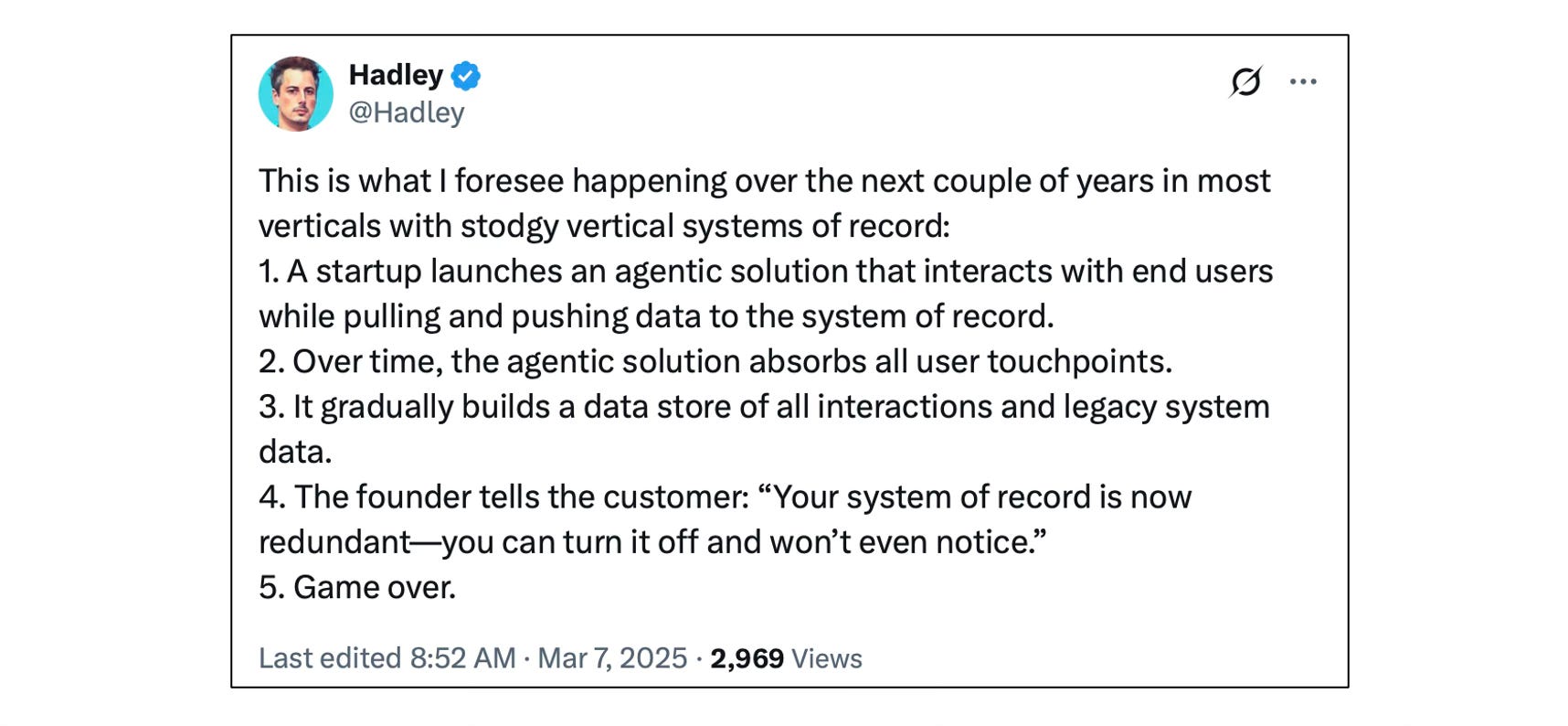
Luận điểm phản biện là chủ sở hữu SoR sẽ chặn các ứng dụng này, tự xây dựng chúng và nhanh chóng thực hiện bất kỳ cải tiến nào hướng đến người dùng; và việc họ đi trước về dữ liệu và phân phối sẽ đủ để giành chiến thắng trên thị trường. 23
Kiểm soát ngoại sinh
Bộ hào dữ liệu tiếp theo là một danh mục bao quát mà tôi gọi là kiểm soát ngoại sinh . Trong mô hình này, bạn kiểm soát việc sử dụng dữ liệu, không phải thông qua bất kỳ thuộc tính nào của dữ liệu, thậm chí không phải của phần mềm quản lý dữ liệu, mà thay vào đó là thông qua các biện pháp khuyến khích hoặc trừng phạt bên ngoài. Sau đây là một số ví dụ:
Quyền sở hữu trí tuệ : không quan trọng dữ liệu là duy nhất hay bị phân mảnh trong SoR, được bảo vệ bằng quyền xử lý hay không có bất kỳ quyền nào ở trên: nếu bạn có quyền sở hữu trí tuệ độc quyền đối với việc sử dụng dữ liệu, bạn sẽ kiểm soát được dữ liệu. Hãy xem xét Chỉ số S&P 500: dữ liệu cơ bản là công khai và bản thân chỉ số này rất dễ sao chép, nhưng S&P Global kiếm được khoảng 1 tỷ đô la một năm từ việc cấp phép dữ liệu này — cho các nhà quản lý tài sản (để đánh giá chuẩn và ETF), các sàn giao dịch (cho các sản phẩm phái sinh liên kết với chỉ số) và các ngân hàng (cho các sản phẩm có cấu trúc). 24
Độc quyền theo hợp đồng : nơi bạn chiếm một nguồn dữ liệu chính thông qua một hợp đồng có lợi. Không thể trong một thị trường hiệu quả, nhưng thị trường dữ liệu không hiệu quả; các tập dữ liệu thường bị định giá sai (rất nhiều). Thật không may, hào này chỉ là tạm thời: nếu dữ liệu có giá trị, hợp đồng gần như chắc chắn sẽ được đàm phán lại khi gia hạn. Chiến lược tốt nhất ở đây là sử dụng hào hợp đồng của bạn để mua thời gian thiết lập các nguồn bảo vệ khác; IQVIA đã làm chính xác điều này đối với dữ liệu dược phẩm, trong khi Neustar không làm được điều này đối với dữ liệu viễn thông.
Moats về Quy định và Tuân thủ : Nếu chính phủ yêu cầu mọi người sử dụng một tập dữ liệu cụ thể, thì đó là moats cho công ty sở hữu, kiểm soát hoặc triển khai dữ liệu đó. Một nghiên cứu điển hình ở đây là chương trình ENERGY STAR: các công ty như ICFI , Leidos , DNV và Guidehouse tạo ra doanh thu hàng năm khổng lồ khi cung cấp các chứng nhận này cho cả khách hàng trong khu vực chính phủ và tư nhân. Các mô hình tương tự tồn tại đối với các chương trình khác như CAFE, chất lượng không khí và nước, nhãn FDA ...
Bạn sẽ nhận thấy rằng kiểm soát ngoại sinh thường liên quan đến hành động của chính phủ. Và hành động của chính phủ có tính quán tính mạnh: khó bắt đầu, nhưng thậm chí còn khó dừng lại hơn khi đã bắt đầu. Các hào dữ liệu do nhà nước tài trợ! 25
Dữ liệu chất xúc tác
Một hương vị cụ thể của dữ liệu duy nhất đáng được nêu ra là dữ liệu xúc tác : dữ liệu có giá trị đến từ việc cho phép hoặc kích hoạt việc sử dụng dữ liệu khác. Thể loại này thú vị vì nó là một loại "kiểm soát gián tiếp" — bạn không cần phải kiểm soát trực tiếp dữ liệu được kích hoạt, nó có thể không phải là duy nhất hoặc độc quyền đối với bạn, nhưng bạn kiểm soát khả năng trích xuất giá trị từ nó — nghĩa là bạn có thể nắm bắt được nền kinh tế không cân xứng.
Sau đây là một vài ví dụ; trong mỗi trường hợp, “kích hoạt” là từ đồng nghĩa với “làm tăng đáng kể giá trị của”.
Google : dữ liệu ý định của người dùng kích hoạt dữ liệu kết quả tìm kiếm
Amazon : dữ liệu lịch sử mua hàng kích hoạt dữ liệu danh sách sản phẩm
Acxiom : dữ liệu hồ sơ khách hàng kích hoạt danh sách tiếp thị cơ bản
Bất kỳ công ty truyền thông xã hội nào : lịch sử người xem kích hoạt nội dung mới
CUSIP, DUNS, LiveRamp, Datavant: mã định danh duy nhất kích hoạt thông tin tình báo bị cô lập
FICO, Nielsen, các công ty xếp hạng, IQVIA: các chuẩn mực đồng thuận kích hoạt dữ liệu hiệu suất không được neo giữ
Trong mỗi ví dụ, tập dữ liệu thứ hai có một số giá trị cơ bản trong chính nó, nhưng trở nên có giá trị hơn nhiều khi bổ sung thêm tập dữ liệu thứ nhất. Thật vậy, bạn có thể lập luận rằng các công ty trên đã phát triển để thống trị các ngành công nghiệp tương ứng của họ chính xác là vì họ là những công ty đầu tiên tìm ra cách mở khóa giá trị của các tập dữ liệu "được kích hoạt". 26
Một khía cạnh thú vị của dữ liệu chất xúc tác là, theo kinh nghiệm, nó dường như dẫn đến thị trường người chiến thắng giành tất cả hoặc ít nhất là người chiến thắng giành hầu hết. Đây một phần là thiên kiến sống sót: sau cùng, bạn không bao giờ nghe thấy các tập dữ liệu chất xúc tác không dẫn đến kết quả to lớn.
Nhưng nó cũng phản ánh hai mô hình. Đầu tiên, dữ liệu xúc tác, khi hoạt động, có xu hướng hoạt động thực sự tốt — nó bổ sung giá trị đáng kể cho các tài sản dữ liệu (chưa được khai thác nhưng thường rất sinh lợi). Thứ hai, dữ liệu xúc tác thường hoạt động đồng bộ với nhiều vòng lặp dữ liệu khác nhau: tiêu chuẩn ngành, chuẩn mực đồng thuận, hiệu ứng mạng lưới người dùng, v.v. Chúng ta sẽ khám phá điều này chi tiết hơn sau trong bài luận này.
Kiểm soát dữ liệu, tóm tắt
Sau đây là biểu đồ hữu ích tóm tắt những gì chúng ta đã học được cho đến nay:
Phần xen kẽ
Tôi viết các bài khám phá chuyên sâu, không thường xuyên và độc đáo về các chủ đề mà tôi có chuyên môn đáng kể: dữ liệu, đầu tư và khởi nghiệp. Tìm hiểu thêm tại đây .
PHẦN HAI: VÒNG LẶP DỮ LIỆU
Loại chính thứ hai của hào dữ liệu là vòng lặp dữ liệu : một quá trình phản hồi tích cực liên kết dữ liệu và giá trị kinh doanh trong một chu kỳ lành mạnh . Dữ liệu cải thiện doanh nghiệp và doanh nghiệp cải thiện dữ liệu (với một số giá trị của từ “cải thiện”), và bánh đà quay đủ nhanh để không đối thủ cạnh tranh nào có thể bắt kịp.
Đối với nhiều người, đây là dạng quen thuộc nhất của hào dữ liệu 27. Đây cũng là dạng bị hiểu lầm nhiều nhất. Một số vòng lặp dữ liệu tạo ra hào dữ liệu mạnh và chắc chắn. Một số khác yếu, có quy mô hạn chế hoặc lỗ hổng ẩn. Một số khác nữa thì hiệu quả, nhưng chúng không phải là hào dữ liệu chút nào; chúng dựa vào quy mô hoặc hiệu ứng mạng và bạn có thể loại bỏ phần dữ liệu mà không bị mất mát.
Có ba nhóm chính của vòng lặp dữ liệu: vòng lặp số lượng , vòng lặp học tập và vòng lặp sử dụng/giá trị . Chúng ta hãy tìm hiểu sâu hơn về từng nhóm này.
Vòng lặp số lượng
Vòng lặp số lượng là họ vòng lặp dữ liệu đơn giản nhất: dữ liệu thu hút dữ liệu . Điều này có thể xảy ra thông qua một số cơ chế khác nhau:
Vòng lặp Nội dung do Người dùng tạo (UGC)
Đây là vòng lặp thúc đẩy Facebook, Youtube, Instagram, TikTok, X và thậm chí cả LinkedIn . Tất cả các nền tảng này đều lưu trữ nội dung do người dùng tạo miễn phí: ảnh, video, bài đăng, sơ yếu lý lịch. Nội dung này thu hút những người dùng khác, những người đăng nhiều nội dung hơn nữa. Càng nhiều nội dung, càng nhiều người dùng; ngoài ra, càng nhiều nội dung, các đề xuất càng tốt và do đó, càng nhiều người dùng. Sự hiện diện của tất cả những người dùng này (và sự chú ý của họ!) thu hút các nhà quảng cáo , những người trợ cấp cho tất cả những điều này.
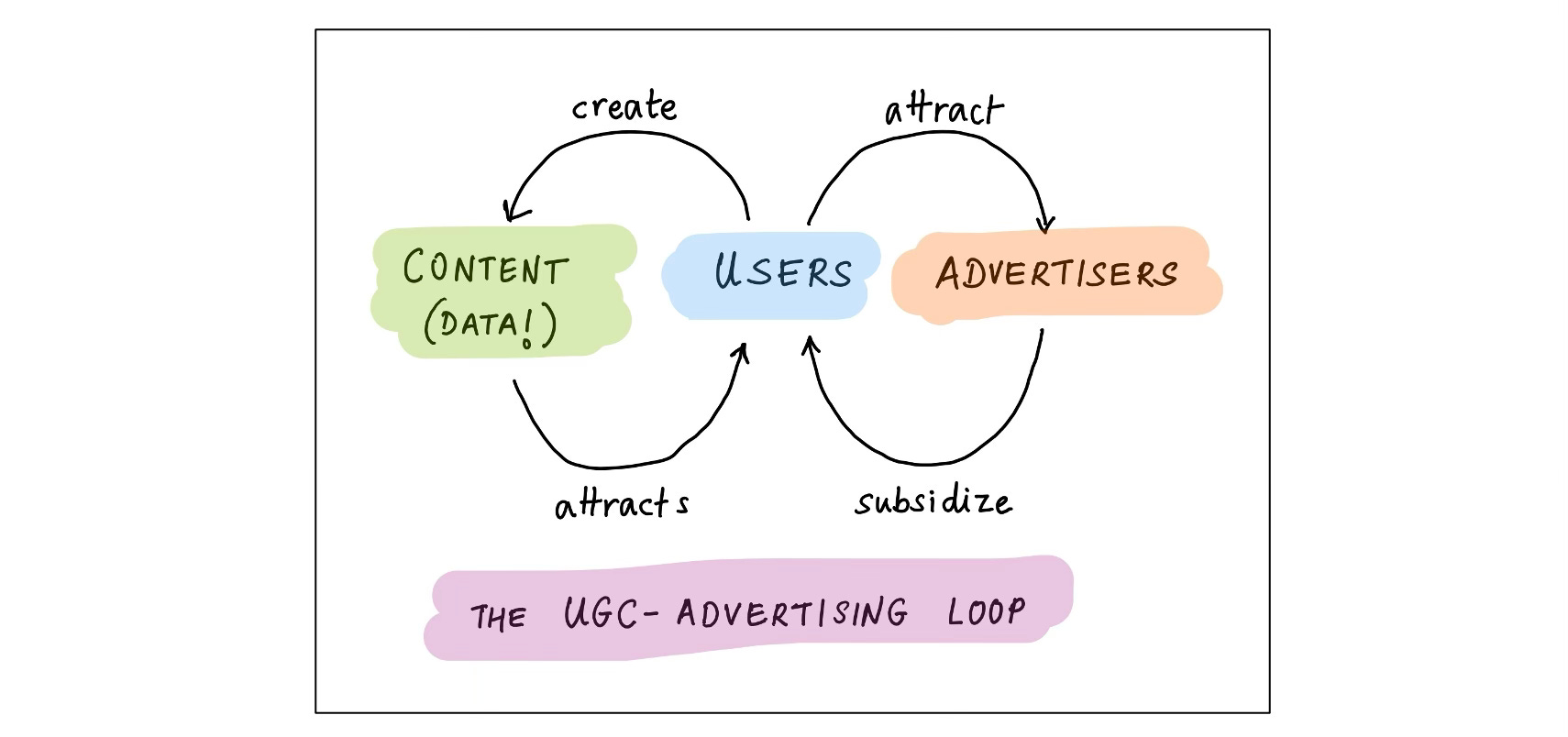
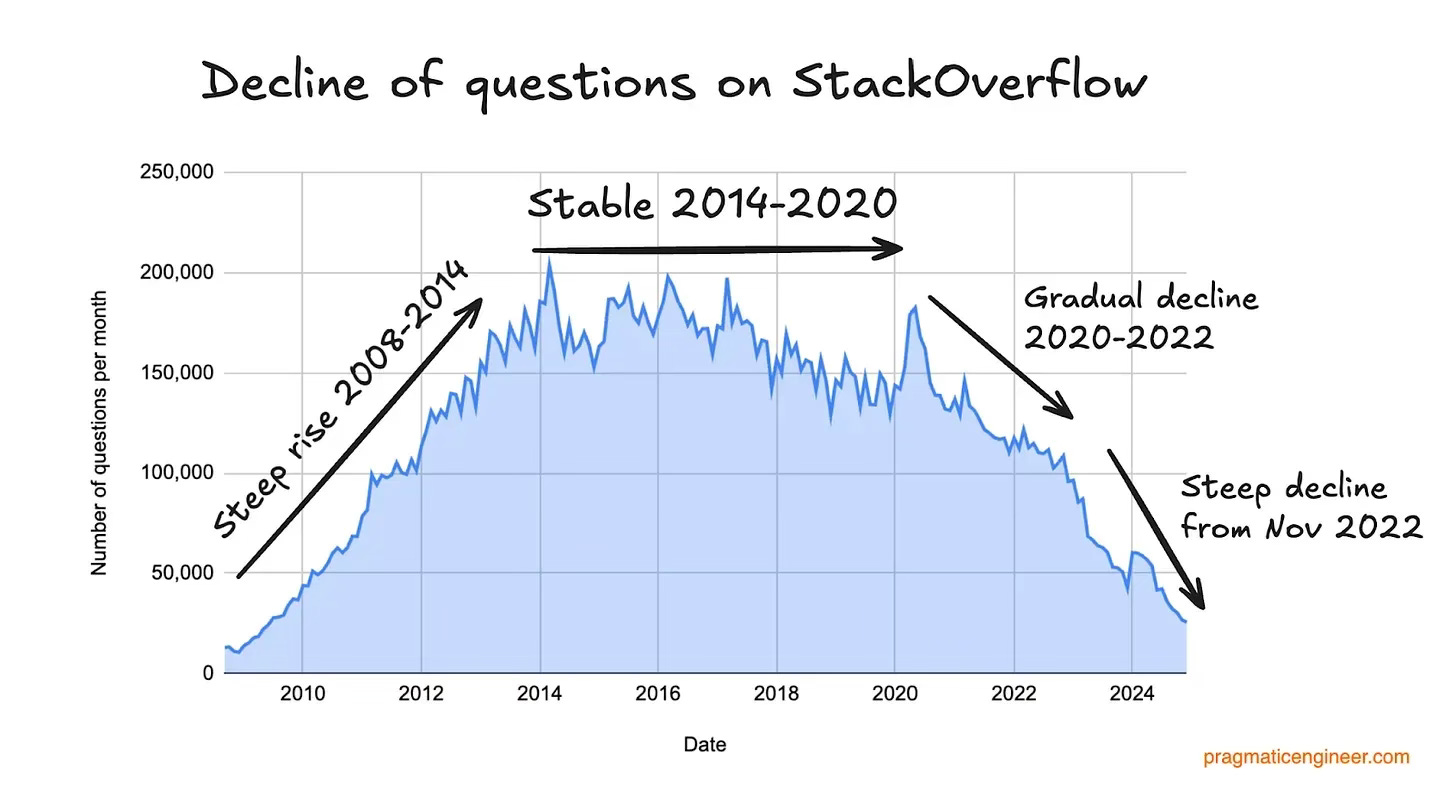
Cũng hấp dẫn không kém là các công ty đã sụp đổ sau khi đạt đến quy mô không tầm thường khi sử dụng vòng lặp này. Hãy xem xét MySpace, Tumblr, Quora, Vine, Digg và có lẽ là Stack Overflow 28. Điều gì đã xảy ra với hào dữ liệu (được cho là) của họ?
Có nhiều lý do khác nhau — thất bại là điều không thể tránh khỏi! — M&A thảm khốc (MySpace của News Corp, Tumblr của Yahoo), không kiếm tiền hiệu quả (tường phí của Quora), tự gây tổn thương (lệnh cấm NSFW của Tumblr), sai lầm về sản phẩm và nợ kỹ thuật (hầu hết), và cạnh tranh với kẻ săn mồi đỉnh cao là Facebook (tất cả). 29 30
Nhưng về cơ bản, đây chỉ là những tác nhân kích hoạt. Vấn đề với vòng lặp dữ liệu UGC là nó có thể đảo ngược nhanh như tốc độ nó được xây dựng . Mọi người đều đi đến nơi có ánh sáng rực rỡ nhất; và ngược lại, mọi người đều chạy trốn khỏi thị trấn ma. Những bước đi sai lầm, nếu không được đảo ngược nhanh chóng, sẽ trở thành bản án tử hình; động lực là một người bạn thất thường. Vì vậy, hào nước này là lừa dối : dễ bị tổn thương hơn vẻ bề ngoài của nó.
Vòng lặp Tối ưu hóa công cụ tìm kiếm (SEO)
Khi đã được mở rộng, vòng lặp UGC cổ điển có xu hướng dẫn đến "khu vườn có tường bao" nội dung, nơi người dùng không bao giờ rời đi hoặc thực sự muốn rời đi. Nhưng có một vòng lặp khác rất giống, nơi người dùng liên tục được thu hút lại và SEO là động cơ của việc thu hút lại này.
Đây là vòng lặp dữ liệu SEO . Người dùng tạo nội dung hoặc chính nền tảng tạo nội dung theo chương trình; những người dùng khác, đang tìm kiếm nội dung cụ thể đó , sẽ tìm đường đến nền tảng thông qua Google hoặc một công cụ tìm kiếm khác. 31
Cụm từ "tìm kiếm nội dung cụ thể đó" rất quan trọng. Không giống như vòng lặp UGC, vòng lặp SEO hướng đến nhiệm vụ chứ không phải hướng đến nguồn cấp dữ liệu . Nội dung phải hữu ích và thực sự trả lời truy vấn tìm kiếm của người dùng.
Một số ví dụ về nội dung hữu ích là gì? Đó là một phạm vi rộng:
Reddit và Quora trả lời những câu hỏi cụ thể
Expedia , Booking , Kayak , v.v. cung cấp thông tin và hành động du lịch
Yelp và TripAdvisor cung cấp đánh giá dịch vụ
Zillow tính giá nhà
Glassdoor và LinkedIn đề cập đến nhiều khía cạnh khác nhau của cuộc sống nghề nghiệp
Các công ty này kiếm tiền theo những cách khác nhau. Các nền tảng ngang rộng có xu hướng kiếm tiền thông qua quảng cáo, trong khi các nền tảng dọc chủ yếu thực hiện tiếp thị liên kết hoặc tạo khách hàng tiềm năng. Và sau đó có một số ít kiếm tiền thông qua đăng ký hoặc dịch vụ. Đặc biệt, tạo khách hàng tiềm năng đủ sinh lợi — hãy nghĩ đến bảo hiểm, sản phẩm tài chính, dịch vụ pháp lý, chăm sóc sức khỏe, giáo dục, du lịch, bảo trì nhà cửa — đến mức có cả một ngành công nghiệp nhỏ của các danh mục dịch vụ tồn tại chỉ để tổng hợp dữ liệu nhà cung cấp, thu hút lưu lượng truy cập của Google và lấy phí giới thiệu.
Trong mỗi trường hợp, việc thêm nhiều dữ liệu hơn sẽ giúp các trang web này có nhiều quyền tìm kiếm hơn, dẫn đến nhiều lưu lượng truy cập hơn và do đó (trực tiếp hoặc gián tiếp) nhiều dữ liệu hơn. Bánh đà được mở khóa, hào nước được thiết lập.
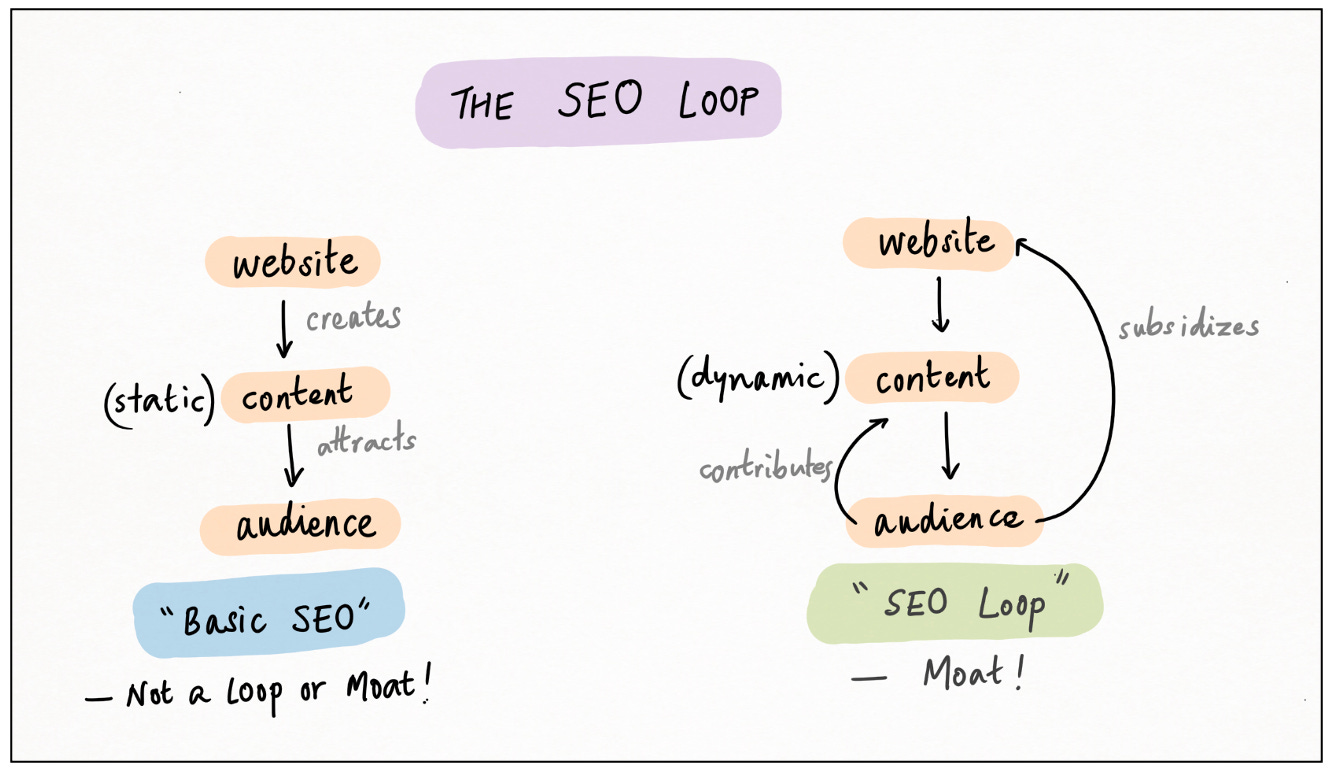
Nhưng kỷ nguyên này có thể sắp kết thúc , cùng với hào nước này. Một lý do là quá bão hòa: có quá nhiều AI ngoài kia, tìm kiếm của Google đơn giản là ít hữu ích hơn 32 33 . Một lý do khác là sự trung gian hóa : LLM đã thay thế tìm kiếm cho các truy vấn thông tin thuần túy và các tác nhân có thể sớm làm như vậy đối với các truy vấn điều hướng và giao dịch. Điều này sẽ bỏ qua toàn bộ kênh tìm kiếm-học-chọn-mua mà vòng lặp SEO được xây dựng trên đó. 34 Một trở ngại cuối cùng đối với vòng lặp SEO là việc di chuyển nội dung đằng sau các bức tường phí và thông tin đăng nhập . Mọi người đang khóa các tài sản dữ liệu của họ; tạm biệt, web hoàn toàn mở.
Stack Overflow đưa ra một câu chuyện cảnh báo. Biểu đồ các câu hỏi hàng tháng được đăng trên trang web lập trình phổ biến này, do Gergely Orosz tạo ra dựa trên dữ liệu từ Theodore Smith , nói lên tất cả: