Đã đến lúc mở rộng quy mô thời gian tính toán theo cách phi tập trung. không chỉ là một paradigm huấn luyện sau này cho mà còn là một bài học đắng cay đã được điều chỉnh
Bài viết này được dịch máy
Xem bản gốc

Noam Brown
@polynoamial
04-17
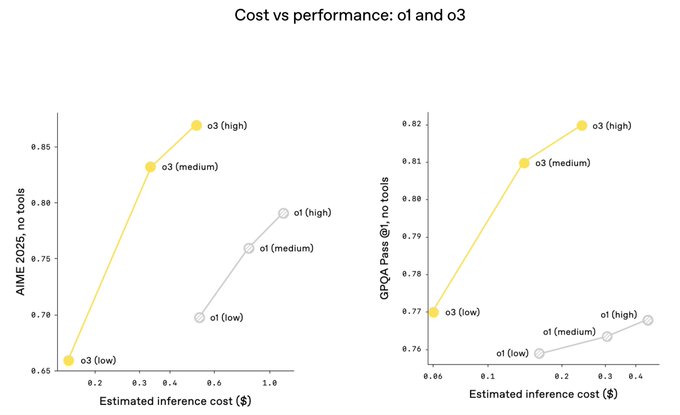
Our new @OpenAI o3 and o4-mini models further confirm that scaling inference improves intelligence, and that scaling RL shifts up the whole compute vs. intelligence curve. There is still a lot of room to scale both of these further.
Từ Twitter
Tuyên bố từ chối trách nhiệm: Nội dung trên chỉ là ý kiến của tác giả, không đại diện cho bất kỳ lập trường nào của Followin, không nhằm mục đích và sẽ không được hiểu hay hiểu là lời khuyên đầu tư từ Followin.
Thích
Thêm vào Yêu thích
Bình luận
Chia sẻ
Nội dung liên quan